Go垃圾回收参数调优:实现低延迟服务的实战指南
一、引言
还记得那些因为突如其来的服务延迟峰值而彻夜不眠的日子吗?在高并发Go服务的世界里,垃圾回收(GC)就像是一位不速之客,它虽然默默清理着我们制造的"垃圾",却也时不时打断我们的工作节奏。从我接触Go语言至今,亲眼见证了其GC机制从早期的"全停顿世界"(Stop-The-World,STW)到如今的三色标记法的飞跃式发展。
Go的GC机制就像是一位勤劳的清洁工,在不断进化中变得越来越聪明。最初,它需要让整个程序暂停来完成清理工作(想象一下,要打扫房间,首先要请所有人出去);而现在,它能在房间里的人继续活动的同时,悄悄完成大部分清洁工作,只在极短的时间内请大家"稍微别动"。
为什么GC调优如此关键?
在追求极致用户体验的今天,哪怕几十毫秒的延迟波动也可能导致用户流失或交易失败。特别是在以下场景中,GC调优几乎是服务稳定性的关键所在:
- 高并发API服务:每秒处理成千上万请求的系统,GC暂停可能导致请求堆积和超时
- 金融交易系统:毫秒级的延迟可能意味着交易机会的丧失或价格偏差
- 实时数据处理:如实时推荐、实时监控等场景,数据处理的及时性直接影响业务质量
- 在线游戏服务器:玩家体验对延迟特别敏感,GC暂停可能导致游戏卡顿
正如一位资深Go工程师曾对我说的:“了解并掌握GC调优,就像给你的Go应用装上了一个减震器,让它在高速运行时也能保持平稳。”
接下来,我们将一起探索Go GC的原理、常见问题及调优技巧,通过实战案例学习如何让我们的服务实现低延迟、高稳定性的目标。
二、Go GC原理简述
在深入GC调优之前,我们需要先理解Go垃圾回收的基本原理,就像修理汽车前先要了解它的构造一样。
Go垃圾回收的基本工作原理
Go的垃圾回收器负责自动回收程序不再使用的内存。这个过程看似简单,实际上涉及复杂的内存追踪和管理算法。想象一下,GC就像是一位图书管理员,定期检查哪些书已经没人借阅,然后将它们重新上架以供他人使用。
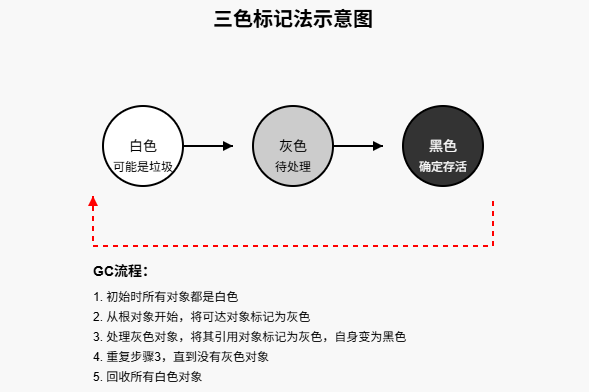
三色标记-清除算法简介
现代Go(1.5版本后)采用三色标记-清除算法进行垃圾回收。这种算法将内存对象分为三种颜色:
- 白色:潜在的垃圾,可能会被回收
- 灰色:已被发现但还未处理完的对象
- 黑色:确定仍在使用的对象,不会被回收
这个算法的工作流程可以比喻为筛选城市居民:
- 初始时,所有对象都是白色(假设所有人都要离开城市)
- 从根对象(全局变量、栈变量等)开始,标记为灰色(确认这些人要留在城市)
- 检查灰色对象引用的其他对象,将它们也标记为灰色,同时将已检查完的灰色对象标记为黑色(被留下的人的亲朋好友也要留下)
- 重复步骤3,直到没有灰色对象(所有要留下的人都确认完毕)
- 剩余的白色对象被当作垃圾回收(其他人离开城市)
| 回收阶段 | 类比 | 程序行为 |
|---|---|---|
| 标记准备 | 城市清查前的准备工作 | 短暂STW,准备根对象扫描 |
| 标记 | 清查谁需要留在城市 | 并发进行,程序正常运行 |
| 标记终止 | 确认最终留城名单 | 短暂STW,完成标记工作 |
| 清除 | 安排离城人员离开 | 并发进行,回收白色对象 |
GC触发时机
Go的GC会在以下几种情况下触发:
- 内存阈值触发:当堆内存增长到上次GC后的一定比例(由GOGC控制,默认100%)
- 定时触发:在一定时间内没有GC发生时(2分钟)
- 手动触发:通过调用
runtime.GC()函数
这就像是城市管理,既有计划性的定期清理,也有应对突发情况的临时措施。
常见的GC性能指标
评估GC性能主要看以下几个关键指标:
- GC周期频率:GC发生的频率,过高意味着内存压力大
- STW(Stop-The-World)时间:程序完全暂停的时间,直接影响服务延迟
- Mark/Sweep阶段耗时:标记和清除阶段各自消耗的时间
- GC CPU占用率:GC操作消耗的CPU资源比例
// 以下代码演示了如何获取GC统计信息
var stats runtime.MemStats
runtime.ReadMemStats(&stats)// GC次数
fmt.Printf("GC次数: %d\n", stats.NumGC)
// 上次GC消耗的时间(纳秒)
fmt.Printf("上次GC耗时: %v\n", time.Duration(stats.PauseNs[(stats.NumGC-1)%256]))
// GC占用的CPU时间比例
fmt.Printf("GC CPU占用率: %.2f%%\n", float64(stats.GCCPUFraction)*100)
理解这些指标就像是了解自己的健康指标一样,是优化GC的第一步。
重点提示:Go的GC算法仍在不断进化中。理解其工作原理不仅有助于进行调优,也能帮助我们编写更符合Go内存管理模型的高效代码。
接下来,我们将学习如何通过调整GC参数来优化应用性能。
三、GC参数调优基础
了解了Go GC的工作原理后,我们可以开始探索如何通过调整参数来优化GC表现。这就像是调整汽车引擎,通过微调各项参数来获得更好的性能。
GOGC环境变量的作用及调整方法
GOGC是控制Go垃圾回收器最重要的参数,它决定了触发下一次GC的时机。默认值为100,表示当堆内存增长到上次GC后的两倍(100%增长)时触发新的GC。
可以通过以下方式设置GOGC:
- 环境变量方式(全局影响):
export GOGC=200 # 将触发阈值提高到200%
- 程序内动态设置(局部影响):
import "runtime/debug"// 设置GOGC值
debug.SetGCPercent(200)// 获取当前GOGC值
currentGC := debug.SetGCPercent(debug.SetGCPercent(-1))
fmt.Printf("当前GOGC值: %d\n", currentGC)
调整GOGC值的权衡:
| GOGC值 | GC频率 | 内存使用 | CPU使用 | 适用场景 |
|---|---|---|---|---|
| 较低值(如50) | 更频繁 | 更少 | 更多 | 内存受限环境 |
| 默认值(100) | 平衡 | 平衡 | 平衡 | 大多数应用 |
| 较高值(如300) | 不频繁 | 更多 | 更少 | CPU敏感应用 |
| 关闭GC(off) | 手动触发 | 非常多 | 极少 | 特殊场景 |
实战经验:在一个高并发API服务中,我们将GOGC从100调整到200,服务的P99延迟降低了约15%,但内存使用增加了约30%。这是一个典型的CPU时间与内存空间的权衡。
GOMEMLIMIT参数使用(Go 1.19+)
从Go 1.19开始,引入了GOMEMLIMIT参数,用于限制Go程序的总内存使用量,包括堆内存、栈内存和其他运行时内存。当内存使用接近此限制时,GC会更积极地工作以避免超出限制。
# 设置内存限制为4GB
export GOMEMLIMIT=4GiB
// 程序内动态设置
import "runtime/debug"// 设置内存限制为4GB
debug.SetMemoryLimit(4 * 1024 * 1024 * 1024)
GOMEMLIMIT与GOGC配合使用:
- GOGC控制GC触发的相对时机(基于内存增长比例)
- GOMEMLIMIT设置绝对内存上限(基于实际内存使用量)
这两个参数结合使用,可以更精细地控制内存使用和GC行为。想象一下,GOGC是汽车的巡航控制系统,而GOMEMLIMIT则是速度限制器,两者一起确保车辆以合适的速度安全行驶。
调试GC的常用工具
1. GODEBUG环境变量
GODEBUG=gctrace=1是观察GC行为最直接的方式:
GODEBUG=gctrace=1 ./your-program
输出示例:
gc 1 @0.012s 1%: 0.026+0.39+0.10 ms clock, 0.21+0.26/0.52/0.13+0.83 ms cpu, 4->4->0 MB, 5 MB goal, 8 P
这串数字看起来有点复杂,让我解释一下关键部分:
gc 1: 第1次GC@0.012s: 程序启动后0.012秒1%: GC占用的CPU时间比例0.026+0.39+0.10 ms clock: 各阶段STW和并发标记的时间4->4->0 MB: GC前堆大小->标记后大小->GC后大小5 MB goal: 下次触发GC的堆大小目标8 P: 使用的处理器数量
2. pprof分析工具
pprof是Go提供的强大性能分析工具,可以用来分析内存分配和GC情况:
import ("net/http"_ "net/http/pprof" // 导入pprof"log"
)func main() {// 启动pprof服务go func() {log.Println(http.ListenAndServe("localhost:6060", nil))}()// 你的程序主逻辑...
}
然后可以通过以下命令查看内存和GC情况:
# 查看内存分配情况
go tool pprof http://localhost:6060/debug/pprof/heap# 生成内存分配图(需安装graphviz)
go tool pprof -png http://localhost:6060/debug/pprof/heap > heap.png
实用技巧:将GODEBUG输出结合应用日志一起分析,可以发现GC活动与服务延迟峰值之间的关联,这对定位GC问题非常有帮助。
通过这些基础工具和参数,我们已经可以开始监控和调整Go程序的GC行为。接下来,我们将深入探讨常见的GC问题及其解决方案。
四、常见GC问题与性能瓶颈分析
在实际项目中,GC问题往往以各种性能瓶颈的形式表现出来。就像医生诊断疾病一样,我们需要通过症状找到根本原因,才能对症下药。
频繁GC导致的CPU使用率高问题
症状:服务CPU使用率异常高,但业务逻辑实际并不复杂。
原因:频繁的GC会消耗大量CPU资源。就像一个原本宽敞的房间,如果物品不断增加又不断清理,管理员就会疲于奔命。
诊断方法:
# 观察GC频率
GODEBUG=gctrace=1 ./your-program# 分析CPU使用情况
go tool pprof http://localhost:6060/debug/pprof/profile
如果发现GC每秒发生多次,且GC相关函数占用了大量CPU时间,就可能是频繁GC的问题。
解决方案:
-
增大GOGC值:减少GC触发频率
debug.SetGCPercent(300) // 增加GC触发阈值 -
优化内存分配:减少临时对象创建
// 优化前:每次迭代创建新切片 for _, item := range items {result := make([]byte, len(item))copy(result, item)process(result) }// 优化后:重用切片 result := make([]byte, 0, maxItemSize) for _, item := range items {result = result[:len(item)]copy(result, item)process(result) }
实战案例:在一个日志处理服务中,我们发现CPU使用率异常高达80%,通过pprof发现40%的CPU时间花在GC上。通过将GOGC从100调整到300,并优化字符串处理逻辑减少临时对象,GC占用降至5%以下,服务CPU使用率降至35%。
GC停顿造成的延迟抖动(latency spike)
症状:服务响应时间大部分情况下很稳定,但偶尔出现明显的延迟峰值。
原因:虽然现代Go GC大部分工作是并发进行的,但仍有两个短暂的STW(Stop-The-World)阶段会导致所有goroutine暂停,从而产生延迟峰值。
诊断方法:
-
结合业务延迟监控和GC日志分析
GODEBUG=gctrace=1 ./your-program 2>&1 | grep -v EOF > gc.log -
使用追踪工具记录GC停顿
import "runtime/trace"f, _ := os.Create("trace.out") defer f.Close() trace.Start(f) defer trace.Stop()// 你的程序主逻辑...然后使用
go tool trace trace.out分析结果
解决方案:
-
分散GC压力:避免同时产生大量垃圾
// 不好的实践:一次性处理所有数据 func processAll(items []Item) {for _, item := range items {process(item)} }// 更好的实践:分批处理,控制GC节奏 func processInBatches(items []Item) {batchSize := 1000for i := 0; i < len(items); i += batchSize {end := i + batchSizeif end > len(items) {end = len(items)}processBatch(items[i:end])// 可以考虑主动触发GCif i+batchSize < len(items) {runtime.GC()}} } -
在关键路径上减少内存分配
关键业务逻辑中尽量避免创建临时对象,特别是大型切片或映射。
案例分享:在一个实时交易系统中,我们发现每隔约30秒就会出现一次明显的延迟峰值(P99延迟从5ms突增至40ms)。通过分析发现,这与定期批量处理的数据清理任务触发的GC有关。将批处理改为小批次的流式处理后,延迟波动显著降低,P99延迟稳定在8ms以内。
内存碎片问题及解决方案
症状:程序看起来没有内存泄漏,但实际使用的物理内存却持续增长。
原因:频繁分配和释放不同大小的内存块会导致内存碎片,类似于磁盘碎片,使得实际可用内存减少。
诊断方法:
观察程序的RSS(物理内存使用)与Go报告的堆内存使用是否有较大差异
解决方案:
-
使用内存池:减少随机大小的内存分配
// 示例:为固定大小的对象创建对象池 var bufferPool = &sync.Pool{New: func() interface{} {return make([]byte, 4096)}, }func processWithPool() {buf := bufferPool.Get().([]byte)defer bufferPool.Put(buf)// 使用buf处理数据... } -
标准化对象大小:尽量使用统一规格的对象
// 不好的做法:根据数据大小创建不同的buffer buffer := make([]byte, dataSize)// 更好的做法:使用固定几种规格的buffer var bufferSizes = []int{1024, 4096, 16384, 65536}func getAllocSize(size int) int {for _, bsize := range bufferSizes {if bsize >= size {return bsize}}return size // 超过最大预设值时才用实际大小 }buffer := make([]byte, getAllocSize(dataSize))
踩坑经验:在一个长时间运行的服务中,我们发现即使负载稳定,但内存使用仍在缓慢增长。通过内存分析发现大量不同大小的byte切片分配导致内存碎片。将随机大小的临时缓冲区改为使用几种固定大小的缓冲池后,问题得到有效缓解,系统内存使用下降了约25%。
大对象分配引起的GC压力
症状:每次创建大对象后,都会触发一次GC,导致明显的性能抖动。
原因:Go的GC是根据内存增长比例触发的。当分配一个很大的对象(比如加载大文件到内存)时,可能立即触发GC阈值。
解决方案:
-
大对象预分配:提前分配大对象,而不是在关键路径上突然分配
// 程序启动时预热大缓冲区 var largeBuffer = make([]byte, 100*1024*1024) // 100MB的缓冲区func init() {// 可以在此初始化largeBuffer// 甚至可以先触发一次GCruntime.GC() } -
流式处理:避免一次性加载大数据到内存
// 不好的做法:一次读取整个文件 data, _ := ioutil.ReadFile("large_file.dat") process(data)// 更好的做法:流式处理 file, _ := os.Open("large_file.dat") defer file.Close()scanner := bufio.NewScanner(file) for scanner.Scan() {line := scanner.Text()processLine(line) }
重点警示:当需要处理的数据远大于可用内存时,切勿尝试一次性加载全部数据。这不仅会增加GC压力,还可能导致OOM(内存溢出)错误。始终考虑流式处理或分批处理方案。
通过识别和解决这些常见的GC问题,我们可以显著提升Go应用的性能稳定性。下面,我们将通过实际案例来展示如何应用这些技巧解决实际项目中的GC挑战。
五、实战案例一:API服务GC调优
让我们来看一个真实的案例:一个处理用户请求的高并发API服务,在负载增加时出现了明显的性能下降。
问题场景描述
服务特征:
- 每秒处理约5000个API请求
- 平均响应时间应保持在50ms以内
- 99%请求(P99)响应时间目标为200ms以内
观察到的问题:
- 在高峰期,P99延迟突增至500ms以上
- CPU使用率波动明显
- 监控显示GC频率异常高,平均每3秒一次完整GC
这个问题的影响十分严重,因为它直接导致了用户体验的下降,在业务高峰期尤为明显。
性能分析方法展示
首先,我们需要收集详细的性能数据来定位问题:
- 启用GC追踪:
GODEBUG=gctrace=1 ./api-server 2>&1 | tee gc.log
- 收集pprof数据:
import ("net/http"_ "net/http/pprof""log"
)func main() {// 启动pprof服务go func() {log.Println(http.ListenAndServe("localhost:6060", nil))}()// API服务主逻辑...
}
- 分析内存分配热点:
go tool pprof -http=:8080 http://localhost:6060/debug/pprof/allocs
关键发现:
通过分析,我们发现了几个关键问题:
- 每个API请求都会分配多个临时对象,特别是在JSON处理和数据转换环节
- 请求处理函数中大量使用了
append操作,导致频繁的内存重新分配 - 没有针对高频创建的对象使用对象池
- GOGC参数使用默认值(100),在高并发场景下GC触发过于频繁
参数调优步骤与结果对比
我们采取了以下调优措施:
- 调整GOGC参数:
import "runtime/debug"func init() {// 将GC触发阈值提高,减少GC频率debug.SetGCPercent(200)
}
- 使用GOMEMLIMIT限制总内存:
import "runtime/debug"func init() {// 设置8GB内存上限,防止内存无限增长debug.SetMemoryLimit(8 * 1024 * 1024 * 1024)
}
- 监控GC效果:
// 定期输出GC统计信息
func reportGCStats() {var lastGC uint32for range time.Tick(time.Minute) {var stats runtime.MemStatsruntime.ReadMemStats(&stats)if lastGC != stats.NumGC {log.Printf("GC Stats: NumGC=%d, PauseTotal=%v, GCCPUFraction=%.2f%%\n",stats.NumGC,time.Duration(stats.PauseTotalNs),stats.GCCPUFraction*100)lastGC = stats.NumGC}}
}
调优效果对比:
| 指标 | 调优前 | 调优后 | 改善比例 |
|---|---|---|---|
| GC频率 | 每3秒一次 | 每15秒一次 | 80%减少 |
| P99延迟 | 500ms | 150ms | 70%减少 |
| GC暂停总时间 | 5%请求时间 | 1%请求时间 | 80%减少 |
| 内存使用 | 2GB | 3.5GB | 75%增加 |
这是一个典型的时间与空间的权衡 - 我们牺牲了一些内存(在可接受范围内),但显著提升了服务的响应速度和稳定性。
代码优化示例
除了调整GC参数外,我们还对代码进行了优化:
// 优化前:每个请求都分配临时对象
func processRequest(data []byte) Result {// 每个请求都分配临时对象tempData := make([]byte, len(data))copy(tempData, data)// 处理逻辑...return result
}// 优化后:使用对象池减少GC压力
var bufferPool = sync.Pool{New: func() interface{} {buffer := make([]byte, 1024)return &buffer},
}func processRequestOptimized(data []byte) Result {bufferPtr := bufferPool.Get().(*[]byte)buffer := *bufferPtr// 确保容量足够if cap(buffer) < len(data) {buffer = make([]byte, len(data))*bufferPtr = buffer}buffer = buffer[:len(data)]copy(buffer, data)// 处理逻辑...// 归还到对象池bufferPool.Put(bufferPtr)return result
}
另一个优化JSON处理的例子:
// 优化前:每次JSON编码都创建新的编码器
func handleResponse(w http.ResponseWriter, data interface{}) {encoder := json.NewEncoder(w)encoder.Encode(data)
}// 优化后:使用对象池复用JSON编码器
var encoderPool = sync.Pool{New: func() interface{} {return json.NewEncoder(nil)},
}func handleResponseOptimized(w http.ResponseWriter, data interface{}) {encoder := encoderPool.Get().(*json.Encoder)encoder.Reset(w)encoder.Encode(data)encoderPool.Put(encoder)
}
实战经验分享:我们发现,仅通过实现缓冲区和编码器的对象池化,就减少了约40%的临时对象分配,这对降低GC压力有显著效果。但也要注意,对象池不是万能的,它自身也有管理开销,只有在对象创建成本高或对象较大时才值得使用。
通过这个实战案例,我们看到了GC调优如何显著提升高并发API服务的性能。接下来,我们将探讨另一种常见场景:处理大量数据的服务的GC优化。
六、实战案例二:大内存消耗服务GC优化
与高并发API服务不同,数据处理服务通常需要处理大量数据,可能会消耗大量内存。这类服务面临的GC挑战也不同。
问题场景:数据处理服务中的内存占用和GC问题
考虑一个日志分析服务,需要处理TB级别的日志文件,提取关键信息并生成报告。
服务特征:
- 批量读取和处理大型日志文件
- 需要在内存中构建复杂的数据结构
- 处理过程中内存使用峰值可达10GB以上
- 对实时性要求不高,但需要稳定完成处理任务
观察到的问题:
- 在处理大文件时经常出现OOM(Out Of Memory)错误
- GC暂停时间长,有时达到几秒
- 处理速度不稳定,有明显的周期性变化
调优前的性能指标与问题分析
我们首先收集关键性能指标:
// 监控内存使用
func monitorMemory() {for range time.Tick(5 * time.Second) {var m runtime.MemStatsruntime.ReadMemStats(&m)log.Printf("Memory: Alloc=%dMB, Sys=%dMB, NumGC=%d, PauseAvg=%v\n",m.Alloc/1024/1024,m.Sys/1024/1024,m.NumGC,time.Duration(m.PauseNs[0]))}
}
关键发现:
- 内存使用呈"锯齿状"增长,每次GC后都有大量内存无法释放
- 处理大型日志文件时,一次性将整个文件加载到内存导致内存峰值极高
- 使用大量临时对象存储中间结果,增加GC压力
- GC在内存压力大时工作效率低下,导致长时间暂停
GOGC和GOMEMLIMIT参数组合调优
针对上述问题,我们采取了参数调优措施:
import "runtime/debug"func init() {// 设置较低的GOGC值,让GC更积极地回收内存debug.SetGCPercent(50)// 设置内存上限,防止OOMdebug.SetMemoryLimit(12 * 1024 * 1024 * 1024) // 12GB
}
设置说明:
- 较低的GOGC值(50而非默认的100)让GC更频繁地运行,减少内存峰值
- GOMEMLIMIT设置确保内存使用不会失控,即使在处理超大文件时也能保持稳定
这些参数组合针对的是"宁可多做一些GC,也不要让内存用量失控"的策略,适合数据处理类应用。
代码优化示例
除了参数调优,我们还对代码进行了优化:
// 优化前:一次性加载所有数据
func processLargeDataset(filePath string) Results {// 读取可能几百MB的数据allData, _ := ioutil.ReadFile(filePath)// 处理数据...return results
}// 优化后:分批处理数据
func processLargeDatasetOptimized(filePath string) Results {file, _ := os.Open(filePath)defer file.Close()scanner := bufio.NewScanner(file)var results Resultsbatch := make([]Data, 0, 1000) // 固定批次大小for scanner.Scan() {// 处理一行数据data := parseData(scanner.Bytes())batch = append(batch, data)if len(batch) >= 1000 {// 处理一批数据batchResults := processBatch(batch)results = append(results, batchResults...)// 重置批次batch = batch[:0]// 手动触发GC(根据实际情况使用)if shouldTriggerGC() {runtime.GC()}}}// 处理剩余数据if len(batch) > 0 {batchResults := processBatch(batch)results = append(results, batchResults...)}return results
}// 根据内存使用情况判断是否需要手动触发GC
func shouldTriggerGC() bool {var m runtime.MemStatsruntime.ReadMemStats(&m)// 如果内存使用率超过某个阈值,触发GCreturn m.Alloc > 8*1024*1024*1024 // 8GB
}
另一个优化示例,针对大型临时数据结构:
// 优化前:创建完整的中间结果集
func analyzeLog(logs []LogEntry) Report {// 创建可能非常大的中间结果映射intermediateResults := make(map[string][]StatEntry)for _, log := range logs {key := extractKey(log)stats := calculateStats(log)intermediateResults[key] = append(intermediateResults[key], stats)}return generateReport(intermediateResults)
}// 优化后:使用流式处理减少内存占用
func analyzeLogOptimized(logs []LogEntry) Report {report := newReport()tempStats := make(map[string]StatEntry)// 每处理1000条日志,合并一次结果并清空临时数据for i, log := range logs {key := extractKey(log)stats := calculateStats(log)if existing, ok := tempStats[key]; ok {tempStats[key] = mergeStats(existing, stats)} else {tempStats[key] = stats}// 每处理1000条日志,合并一次结果到最终报告if i%1000 == 999 {mergeIntoReport(report, tempStats)// 清空临时结果for k := range tempStats {delete(tempStats, k)}}}// 处理剩余的临时结果mergeIntoReport(report, tempStats)return finalizeReport(report)
}
优化效果对比:
| 指标 | 调优前 | 调优后 | 改善效果 |
|---|---|---|---|
| 内存峰值 | 12GB+ | 5GB | 60%减少 |
| OOM错误 | 经常发生 | 未再发生 | 100%解决 |
| 最长GC暂停 | 5秒 | 300ms | 94%减少 |
| 处理速度波动 | 大幅波动 | 稳定 | 显著改善 |
关键经验:对于数据处理类应用,"分而治之"是降低GC压力的核心策略。通过分批处理数据,我们不仅减少了内存峰值,还提高了处理稳定性。有时,适当降低GOGC值并主动触发GC反而能提高整体性能,因为它避免了在极端内存压力下的长时间GC暂停。
这个案例展示了如何针对大数据处理场景进行GC调优。接下来,我们将总结一些通用的GC调优最佳实践。
七、GC调优最佳实践
经过前面的案例分析,我们已经看到了不同场景下的GC调优方法。现在,让我们总结一些通用的GC调优最佳实践,这些方法在大多数Go应用中都能起到积极作用。
对象池化技术详解与实践
对象池化是减少GC压力最有效的技术之一。它的核心思想是复用对象而不是频繁创建和销毁,就像循环使用购物袋而不是每次购物都使用新的塑料袋。
Go标准库提供的sync.Pool:
// 创建一个字节切片池
var bytesPool = &sync.Pool{New: func() interface{} {b := make([]byte, 1024)return &b},
}func UsePooledBuffer() {// 从池中获取一个对象bufPtr := bytesPool.Get().(*[]byte)buf := *bufPtr// 使用buf进行操作// ...// 重置buf状态(如果需要)buf = buf[:0]// 将对象归还到池中*bufPtr = bufbytesPool.Put(bufPtr)
}
对象池使用的最佳实践:
-
适合池化的对象:
- 创建成本高的对象(如大型切片、复杂结构体)
- 使用频率高但生命周期短的对象
- 大小相对固定或可重置的对象
-
不适合池化的对象:
- 生命周期长的对象
- 包含敏感数据且难以完全清除的对象
- 极小的对象(池化管理开销可能超过收益)
-
使用技巧:
- 归还对象前应重置其状态,避免数据泄露
- 池的大小会自动调整,但在高并发场景下预热池可提高初期性能
- 注意池中对象的类型安全,总是进行类型断言
实战经验:在一个Web服务中,我们将HTTP请求和响应的缓冲区池化后,每秒请求量提高了约20%,GC频率降低了约50%。对象池在高并发场景下效果尤为明显。
内存预分配策略
预分配是另一种减少GC压力的有效技术。通过预先分配足够大的内存,可以避免频繁的扩容操作。
// 不佳实践:让切片自动增长
func buildList(items []Item) []Result {var results []Result // 初始容量为0for _, item := range items {result := process(item)results = append(results, result) // 可能多次扩容}return results
}// 最佳实践:预分配切片容量
func buildListOptimized(items []Item) []Result {results := make([]Result, 0, len(items)) // 预分配足够容量for _, item := range items {result := process(item)results = append(results, result) // 不会触发扩容}return results
}
预分配的关键场景:
-
已知大小的集合:当可以预估最终大小时,应预分配足够容量
// 例如,处理1000个元素的数据 buffer := make([]byte, 0, 1000) -
循环中追加元素:在循环外预分配容量,避免循环内扩容
// 读取文件的所有行 lines := make([]string, 0, 1000) // 假设预计有1000行 scanner := bufio.NewScanner(file) for scanner.Scan() {lines = append(lines, scanner.Text()) } -
构建字符串:使用strings.Builder并预设容量
var b strings.Builder b.Grow(1000) // 预分配1000字节 for i := 0; i < 1000; i++ {b.WriteByte('a') } s := b.String()
性能提示:当处理大量元素(如并发读取多个文件)时,如果无法准确预估大小,可以先使用一个合理的初始容量(如预计大小的1.25倍),这样即使有一些内存浪费,也比频繁扩容导致的GC压力要好。
减少临时对象创建的代码模式
临时对象是GC压力的主要来源,减少它们的创建是优化GC的关键。
优化模式1:复用中间对象
// 不佳实践:每次操作都创建新的中间对象
func processItems(items []Item) []Result {var results []Resultfor _, item := range items {// 每次迭代都创建新的中间对象temp := transform(item)enhanced := enhance(temp)results = append(results, finalize(enhanced))}return results
}// 最佳实践:复用中间对象
func processItemsOptimized(items []Item) []Result {var results []Result// 预分配结果切片results = make([]Result, 0, len(items))// 预分配中间对象,在循环中复用temp := NewTemp()enhanced := NewEnhanced()for _, item := range items {// 重置并复用中间对象temp.Reset()enhanced.Reset()temp.Fill(item)enhanced.Process(temp)results = append(results, enhanced.Finalize())}return results
}
优化模式2:使用值传递而非指针(适用于小对象)
// 针对小结构体(如坐标),使用值传递可能比指针更高效
type Point struct {X, Y float64 // 仅16字节
}// 使用值传递
func distanceValue(p1, p2 Point) float64 {return math.Sqrt((p1.X-p2.X)*(p1.X-p2.X) + (p1.Y-p2.Y)*(p1.Y-p2.Y))
}// 不必要的指针使用会增加GC压力
func distancePointer(p1, p2 *Point) float64 {return math.Sqrt((p1.X-p2.X)*(p1.X-p2.X) + (p1.Y-p2.Y)*(p1.Y-p2.Y))
}
优化模式3:批处理替代逐个处理
// 不佳实践:处理每一项都分配内存
func processList(items []Item) {for _, item := range items {result := processItem(item) // 每次调用都分配新内存saveResult(result)}
}// 最佳实践:批量处理减少内存分配次数
func processListBatched(items []Item) {batchSize := 100for i := 0; i < len(items); i += batchSize {end := i + batchSizeif end > len(items) {end = len(items)}// 一次分配内存,处理多个项目batchResults := processBatch(items[i:end])saveBatchResults(batchResults)}
}
代码优化提示:在Go程序中,对于热路径代码(频繁执行的部分),减少一次内存分配往往比优化算法更能提升性能。使用性能分析工具找出内存分配热点,然后着重优化这些区域。
大切片和map的高效处理方法
大型数据结构是内存消耗和GC压力的主要来源,需要特别注意其处理方式。
1. 大切片处理技巧
// 技巧1:复用切片而非创建新的
func processChunks(data []byte) []Result {results := make([]Result, 0, len(data)/chunkSize+1)chunk := make([]byte, chunkSize) // 预分配一个复用的chunkfor i := 0; i < len(data); i += chunkSize {end := i + chunkSizeif end > len(data) {end = len(data)}// 复制数据到复用的chunkn := copy(chunk, data[i:end])// 使用chunk[:n]处理实际数据result := processChunk(chunk[:n])results = append(results, result)}return results
}// 技巧2:使用切片而非拷贝
func extractSection(data []byte, start, end int) []byte {// 不佳实践:拷贝数据// section := make([]byte, end-start)// copy(section, data[start:end])// 最佳实践:返回切片引用,不拷贝数据return data[start:end]
}
2. 大map处理技巧
// 技巧1:分片map减少锁竞争和GC压力
type ShardedMap struct {shards [256]map[string]interface{}shardLocks [256]sync.RWMutex
}func NewShardedMap() *ShardedMap {sm := &ShardedMap{}for i := 0; i < 256; i++ {sm.shards[i] = make(map[string]interface{})}return sm
}func (sm *ShardedMap) getShard(key string) (map[string]interface{}, *sync.RWMutex) {// 简单的分片策略,使用key的第一个字节shardIndex := uint8(0)if len(key) > 0 {shardIndex = uint8(key[0])}return sm.shards[shardIndex], &sm.shardLocks[shardIndex]
}func (sm *ShardedMap) Get(key string) (interface{}, bool) {shard, lock := sm.getShard(key)lock.RLock()defer lock.RUnlock()val, ok := shard[key]return val, ok
}func (sm *ShardedMap) Set(key string, value interface{}) {shard, lock := sm.getShard(key)lock.Lock()defer lock.Unlock()shard[key] = value
}// 技巧2:增量式清理大map
func cleanupLargeMap(m map[string]interface{}, threshold time.Time) {// 不佳实践:一次性删除所有过期项// for key, value := range m {// if isExpired(value, threshold) {// delete(m, key)// }// }// 最佳实践:分批次清理,避免长时间GCkeysToDelete := make([]string, 0, 1000)entriesProcessed := 0for key, value := range m {if isExpired(value, threshold) {keysToDelete = append(keysToDelete, key)}entriesProcessed++if len(keysToDelete) >= 1000 || entriesProcessed >= 10000 {// 批量删除for _, k := range keysToDelete {delete(m, k)}keysToDelete = keysToDelete[:0]// 可选:让其他goroutine有机会执行runtime.Gosched()// 可选:手动触发GC// runtime.GC()}}// 处理剩余的待删除项for _, k := range keysToDelete {delete(m, k)}
}
高级技巧:对于需要长期保留的大型map,考虑实现自己的淘汰策略,如LRU(最近最少使用)缓存,以控制内存增长。标准库中的
golang.org/x/sync/singleflight包也可以帮助减少重复请求导致的内存压力。
合理设置GOMAXPROCS与GC的关系
GOMAXPROCS设置对GC性能有显著影响,因为它决定了并发GC的工作线程数。
import "runtime"func init() {// 设置GOMAXPROCS// 通常设置为CPU核心数或略低于核心数runtime.GOMAXPROCS(runtime.NumCPU())
}
GOMAXPROCS与GC关系的最佳实践:
-
容器环境中的考量:
在容器环境中,Go 1.16之前的版本可能无法正确检测CPU限制,需要手动设置:// 如容器限制为2核,但物理机有32核 runtime.GOMAXPROCS(2) // 明确设置为容器的CPU限制 -
预留CPU资源:
对于对延迟敏感的应用,可以考虑将GOMAXPROCS设置为低于实际CPU核心数,预留一部分CPU专门处理GC:// 例如,在8核机器上 runtime.GOMAXPROCS(7) // 预留1核给GC和操作系统 -
监控GC行为:
根据GC监控数据调整GOMAXPROCS,找到最佳平衡点:// 例如,可以建立一个自适应机制 func adjustGOMAXPROCS() {var lastGCPause time.Durationfor range time.Tick(5 * time.Minute) {var stats runtime.MemStatsruntime.ReadMemStats(&stats)currentPause := time.Duration(stats.PauseNs[(stats.NumGC-1)%256])// 如果GC暂停时间过长,减少GOMAXPROCSif currentPause > 100*time.Millisecond && runtime.GOMAXPROCS(0) > 1 {runtime.GOMAXPROCS(runtime.GOMAXPROCS(0) - 1)log.Printf("Reduced GOMAXPROCS to %d due to long GC pause", runtime.GOMAXPROCS(0))}// 如果GC暂停时间显著改善,可以尝试增加GOMAXPROCSif currentPause < 10*time.Millisecond && lastGCPause > 50*time.Millisecond &&runtime.GOMAXPROCS(0) < runtime.NumCPU() {runtime.GOMAXPROCS(runtime.GOMAXPROCS(0) + 1)log.Printf("Increased GOMAXPROCS to %d due to improved GC performance", runtime.GOMAXPROCS(0))}lastGCPause = currentPause} }
平衡的艺术:GOMAXPROCS设置过高会增加线程切换开销和内存压力,设置过低会限制程序吞吐量。在实践中,通常从CPU核心数开始,然后根据监控数据微调,直到找到GC性能和应用性能的最佳平衡点。
掌握这些GC调优最佳实践,能够帮助你在不同场景下优化Go程序的性能。但同时,我们也需要了解一些常见的踩坑经验,避免走弯路。
八、踩坑经验分享
在GC调优的道路上,有许多看似合理但实际可能导致问题的实践。以下是我和团队在实际项目中积累的一些踩坑经验,希望能帮助大家避免类似问题。
sync.Pool误用导致的内存泄漏
问题描述:
sync.Pool是减少GC压力的利器,但使用不当可能导致内存泄漏或数据竞争。
踩坑案例:
// 有问题的实现 - 将对象指针放入池中并持有引用
func processWithLeakyPool() {// 创建对象池var objPool = &sync.Pool{New: func() interface{} {return &LargeObject{data: make([]byte, 10*1024*1024), // 10MB}},}// 全局对象引用列表 - 这里是问题所在!var savedObjects []*LargeObject// 处理函数for i := 0; i < 100; i++ {obj := objPool.Get().(*LargeObject)// 使用对象obj.Process()// 错误:保存对象引用但还将对象放回池中savedObjects = append(savedObjects, obj)objPool.Put(obj) // 问题:对象同时在池中和savedObjects中}// savedObjects中保存的是放回池中的对象引用// 这些对象可能已经被其他goroutine修改for _, obj := range savedObjects {// 危险:访问可能已被其他goroutine修改的对象result := obj.GetResult() // 可能得到错误结果}
}
正确做法:
// 正确的实现 - 不保留池化对象的引用
func processWithoutLeak() {var objPool = &sync.Pool{New: func() interface{} {return &LargeObject{data: make([]byte, 10*1024*1024),}},}// 保存结果而非对象引用var savedResults []Resultfor i := 0; i < 100; i++ {obj := objPool.Get().(*LargeObject)// 使用对象obj.Process()// 正确:保存结果,而不是对象引用result := obj.GetResult()savedResults = append(savedResults, result)// 重置对象状态,然后放回池中obj.Reset()objPool.Put(obj)}// 使用保存的结果for _, result := range savedResults {// 安全:使用值拷贝,不依赖池化对象useResult(result)}
}
关键教训:
- 从对象池获取的对象只在当前作用域使用,不要保留对象引用
- 放回池前必须重置对象状态
- 不要假设从池中获取的对象有特定状态
- 注意:Go 1.13+的sync.Pool在每次GC后会清空,但不应依赖这一行为
真实案例:我们在一个高并发服务中使用对象池管理HTTP请求缓冲区,但发现内存使用率随时间不断增长。原因是将缓冲区放回池后,某些中间件仍然持有引用并尝试访问,导致"幽灵写入"和内存泄漏。修复方法是确保缓冲区只在请求生命周期内使用,并明确所有权转移。
过度调优GOGC带来的问题
问题描述:
过度增大GOGC值以减少GC频率,可能导致内存使用过高、GC暂停时间变长、甚至OOM错误。
踩坑案例:
// 过度调优GOGC
func overTunedGCExample() {// 设置极高的GOGC值以"避免"GCdebug.SetGCPercent(1000) // 10倍于默认值// 大量内存分配操作for i := 0; i < 1000; i++ {processLargeDataChunk() // 每次分配约10MB内存// 不进行GC,内存持续增长...}// 到此处可能已经OOM,或即将发生一次超长GC暂停
}
平衡策略:
// 更合理的GOGC调优
func balancedGCTuning() {// 适度调整GOGCdebug.SetGCPercent(200) // 比默认值稍高// 设置内存上限debug.SetMemoryLimit(8 * 1024 * 1024 * 1024) // 8GB// 监控内存使用情况go monitorMemory()// 分批处理数据,控制内存使用chunkSize := 100totalItems := 10000for i := 0; i < totalItems; i += chunkSize {end := i + chunkSizeif end > totalItems {end = totalItems}processItems(i, end)// 检查是否需要手动GCmaybeForceGC()}
}func maybeForceGC() {var m runtime.MemStatsruntime.ReadMemStats(&m)// 如果内存使用超过阈值,手动触发GCif m.Alloc > 6*1024*1024*1024 { // 6GBruntime.GC()}
}
关键教训:
- GOGC调优是权衡内存使用与CPU开销,不是越高越好
- 正确的调优策略是找到符合应用特性的平衡点
- 对于长时间运行的应用,过高的GOGC会积累大量垃圾,最终导致长时间GC暂停
- 合理使用GOMEMLIMIT参数限制最大内存使用
项目经验:在一个数据处理服务中,我们最初将GOGC设为500以减少GC开销,但发现服务在运行几小时后会出现长达数秒的GC暂停。改为使用GOGC=200并结合GOMEMLIMIT后,最大GC暂停时间降到了300ms以下,服务稳定性大幅提高。
GC停顿与CPU负载的平衡取舍
问题描述:
减少GC停顿通常意味着增加CPU使用率,反之亦然。在资源受限环境中,这种平衡尤为重要。
踩坑案例:
// CPU负载敏感场景下的错误调优
func cpuConstrainedScenario() {// 在CPU已经接近100%的情况下,降低GOGC以减少内存使用debug.SetGCPercent(50) // 比默认值更激进// CPU密集型操作for i := 0; i < numTasks; i++ {go processCPUIntensiveTask() // 已经使用大量CPU}// 问题:激进的GC会进一步增加CPU负载,导致服务更慢
}
平衡策略:
// 在CPU有限环境中的平衡策略
func balancedCPUMemoryApproach() {// 1. 监测当前CPU使用情况cpuUsage := getCurrentCPUUsage() // 假设有函数获取当前CPU使用率// 2. 根据CPU使用率动态调整GOGCif cpuUsage > 80 {// CPU使用率高,减少GC频率以降低CPU压力debug.SetGCPercent(150)} else if cpuUsage < 40 {// CPU使用率低,可以增加GC频率以减少内存使用debug.SetGCPercent(80)} else {// 适中的CPU使用率,使用默认GC设置debug.SetGCPercent(100)}// 3. 控制并发任务数量,避免CPU过载// 使用带缓冲的通道限制并发数semaphore := make(chan struct{}, runtime.NumCPU()-1)for i := 0; i < numTasks; i++ {semaphore <- struct{}{} // 获取信号量go func(taskID int) {defer func() { <-semaphore }() // 释放信号量processCPUIntensiveTask(taskID)}(i)}
}
关键教训:
- 在CPU受限环境中,过于激进的GC可能降低整体性能
- 同样,在内存受限环境中,过于宽松的GC也会导致问题
- 应根据应用特点和资源情况找到平衡点
- 考虑使用自适应策略,根据当前系统负载动态调整GC参数
生产环境经验:在一个运行在小规格云主机上的服务中,我们发现默认的GC设置导致CPU使用率经常突破90%。将GOGC从100调整到150后,CPU使用率降到了70%左右,虽然内存使用略有增加,但整体服务稳定性和响应速度都明显提升。
在容器环境中的GC调优注意事项
问题描述:
容器环境下的资源限制会影响Go程序的GC行为,尤其是内存和CPU限制。
踩坑案例:
// 容器环境中的常见错误
func containerPitfalls() {// 错误1:未考虑容器内存限制// 假设容器限制为2GB,但程序默认行为可能导致内存使用超出限制largeData := make([]byte, 1.5*1024*1024*1024) // 1.5GBprocessData(largeData)// 此时再分配内存可能导致容器被OOM Killer终止// 错误2:未正确设置GOMAXPROCS// Go < 1.16 在容器中可能错误地检测到宿主机的所有CPU核心// 导致过多的goroutine和线程创建
}
容器环境最佳实践:
import ("runtime""github.com/uber-go/automaxprocs/maxprocs" // 第三方库,自动设置GOMAXPROCS
)func containerAwareSetup() {// 1. 自动检测容器CPU限制并设置GOMAXPROCSmaxprocs.Set() // 自动设置适合的GOMAXPROCS// 2. 根据容器内存限制设置GOMEMLIMIT// 假设容器内存限制为2GB,我们设置使用上限为1.5GBdebug.SetMemoryLimit(1.5 * 1024 * 1024 * 1024)// 3. 监控实际内存使用go monitorMemoryInContainer()
}func monitorMemoryInContainer() {for range time.Tick(10 * time.Second) {var m runtime.MemStatsruntime.ReadMemStats(&m)// 记录内存指标,例如发送到监控系统log.Printf("Memory: Alloc=%dMB, Sys=%dMB, NumGC=%d\n",m.Alloc/1024/1024, m.Sys/1024/1024, m.NumGC)// 如果接近限制,可以执行一些紧急操作if m.Sys > 1.4*1024*1024*1024 { // 接近1.4GB// 可以清除缓存、强制GC等log.Println("Memory pressure detected, forcing GC")runtime.GC()}}
}
关键教训:
- 容器内存限制是硬限制,超出会导致容器被终止
- Go 1.16之前版本可能无法正确检测容器的CPU限制,考虑使用第三方库如
automaxprocs - 在容器环境中,为操作系统和其他进程预留一部分内存和CPU资源
- 定期监控容器内的资源使用情况,建立预警机制
容器环境实战:在Kubernetes集群中运行的一个Go服务,我们发现它经常被OOM Killer终止。通过设置
GOMEMLIMIT为容器内存限制的75%,并使用automaxprocs正确设置GOMAXPROCS,不仅解决了OOM问题,还提高了服务在不同规格容器中的稳定性。
通过学习这些踩坑经验,你可以避免在GC调优过程中走弯路。接下来,我们将讨论如何建立有效的GC监控体系,实现持续优化。
九、监控与可观测性
优化GC不是一次性工作,而是需要持续监控和调整的过程。建立有效的监控体系,能够帮助我们及时发现问题并持续优化GC参数。
如何建立有效的GC监控体系
一个完善的GC监控体系应包含以下几个方面:
- 运行时指标收集:定期采集GC相关的运行时指标
- 关键GC事件记录:记录重要GC事件,如长时间GC暂停
- 应用性能关联分析:将GC活动与应用性能指标关联起来
- 可视化与告警:将GC指标可视化并设置合理的告警阈值
以下是一个简单但有效的GC监控系统实现:
// GC监控系统核心组件
type GCMonitor struct {// 采集频率sampleInterval time.Duration// 保存历史GC数据history []GCMetrics// 最大历史记录数maxHistory int// GC异常告警阈值pauseThreshold time.Duration// 指标输出接口(如Prometheus、日志等)metricsSink MetricsSink
}// GC指标结构
type GCMetrics struct {Timestamp time.TimeNumGC uint32PauseTotal time.DurationPauseNs [256]uint64LastPause time.DurationGCCPUFraction float64HeapAlloc uint64HeapSys uint64HeapIdle uint64HeapInuse uint64NextGC uint64LastGCTime time.Time
}// 创建GC监控器
func NewGCMonitor(interval time.Duration, sink MetricsSink) *GCMonitor {return &GCMonitor{sampleInterval: interval,maxHistory: 1000,pauseThreshold: 100 * time.Millisecond,metricsSink: sink,}
}// 开始监控GC活动
func (m *GCMonitor) Start() {var lastNumGC uint32ticker := time.NewTicker(m.sampleInterval)defer ticker.Stop()for range ticker.C {metrics := m.collectMetrics()// 检测新的GC事件if metrics.NumGC > lastNumGC {newGCs := int(metrics.NumGC - lastNumGC)for i := 0; i < newGCs && i < 256; i++ {pause := time.Duration(metrics.PauseNs[(metrics.NumGC-uint32(i))%256])// 记录长时间GC暂停if pause > m.pauseThreshold {log.Printf("Long GC pause detected: %v", pause)}}lastNumGC = metrics.NumGC}// 保存历史数据m.history = append(m.history, metrics)if len(m.history) > m.maxHistory {// 保持固定长度的历史记录m.history = m.history[1:]}// 输出指标到接收器(如Prometheus)m.metricsSink.ReportMetrics(metrics)}
}// 收集GC指标
func (m *GCMonitor) collectMetrics() GCMetrics {var stats runtime.MemStatsruntime.ReadMemStats(&stats)metrics := GCMetrics{Timestamp: time.Now(),NumGC: stats.NumGC,PauseTotal: time.Duration(stats.PauseTotalNs),GCCPUFraction: stats.GCCPUFraction,HeapAlloc: stats.HeapAlloc,HeapSys: stats.HeapSys,HeapIdle: stats.HeapIdle,HeapInuse: stats.HeapInuse,NextGC: stats.NextGC,}// 复制暂停时间数组copy(metrics.PauseNs[:], stats.PauseNs[:])// 计算最后一次GC暂停时间if stats.NumGC > 0 {metrics.LastPause = time.Duration(stats.PauseNs[(stats.NumGC-1)%256])}return metrics
}// 分析GC趋势
func (m *GCMonitor) AnalyzeGCTrends() GCAnalysis {// 根据历史数据分析GC趋势// 计算平均暂停时间、频率等// ...return analysis
}
Prometheus+Grafana监控GC指标的配置
将Go应用的GC指标接入Prometheus和Grafana是监控GC的最佳实践之一。
1. 在Go程序中集成Prometheus客户端:
import ("net/http""github.com/prometheus/client_golang/prometheus""github.com/prometheus/client_golang/prometheus/promauto""github.com/prometheus/client_golang/prometheus/promhttp"
)// 定义监控指标
var (gcCount = promauto.NewCounter(prometheus.CounterOpts{Name: "go_gc_count_total",Help: "The total number of GC runs",})gcPauseSeconds = promauto.NewHistogram(prometheus.HistogramOpts{Name: "go_gc_pause_seconds",Help: "GC pause duration in seconds",Buckets: prometheus.ExponentialBuckets(0.0001, 2, 15), // 从0.1ms到1.6s})gcHeapBytes = promauto.NewGauge(prometheus.GaugeOpts{Name: "go_gc_heap_bytes",Help: "Current heap size in bytes",})
)// 定期收集GC指标
func recordGCMetrics() {var lastNumGC uint32for range time.Tick(time.Second) {var stats runtime.MemStatsruntime.ReadMemStats(&stats)// 更新堆大小指标gcHeapBytes.Set(float64(stats.HeapAlloc))// 检测新的GC事件并记录if stats.NumGC > lastNumGC {// 计算新增的GC次数newGCs := int(stats.NumGC - lastNumGC)gcCount.Add(float64(newGCs))// 记录每次GC的暂停时间for i := 0; i < newGCs && i < 256; i++ {idx := int((stats.NumGC - uint32(i) - 1) % 256)pause := float64(stats.PauseNs[idx]) / 1e9 // 转换为秒gcPauseSeconds.Observe(pause)}lastNumGC = stats.NumGC}}
}func main() {// 启动指标收集go recordGCMetrics()// 暴露指标端点http.Handle("/metrics", promhttp.Handler())http.ListenAndServe(":9091", nil)// 主程序逻辑...
}
2. Prometheus配置:
# prometheus.yml
scrape_configs:- job_name: 'go_application'scrape_interval: 10sstatic_configs:- targets: ['localhost:9091']
3. Grafana Dashboard配置:
可以创建如下图表:
- GC频率:每分钟GC次数
- GC暂停时间分布:显示不同时长GC暂停的分布情况
- GC暂停时间趋势:随时间变化的GC暂停时间
- 堆内存使用趋势:显示堆内存使用随时间的变化
- GC CPU占用率:GC占用的CPU时间比例
关键GC指标的告警设置
设置合理的告警阈值,能够帮助我们及时发现GC问题:
- GC暂停时间过长:
# Prometheus告警规则
groups:
- name: GC Alertsrules:- alert: GCPauseTooLongexpr: histogram_quantile(0.95, rate(go_gc_pause_seconds_bucket[5m])) > 0.1for: 2mlabels:severity: warningannotations:summary: "GC pause time too long"description: "95th percentile of GC pause time is above 100ms for the last 2 minutes"
- GC频率过高:
- alert: GCFrequencyTooHighexpr: rate(go_gc_count_total[1m]) > 10for: 5mlabels:severity: warningannotations:summary: "GC frequency too high"description: "GC is running more than 10 times per minute for the last 5 minutes"
- 内存增长异常:
- alert: MemoryGrowthAbnormalexpr: deriv(go_gc_heap_bytes[10m]) > 1024 * 1024 * 10for: 15mlabels:severity: warningannotations:summary: "Memory growing abnormally"description: "Heap memory is growing at rate > 10MB/min for the last 15 minutes"
如何根据监控数据持续优化GC参数
收集监控数据的目的是指导我们持续优化GC参数。以下是一种基于数据的优化流程:
-
建立性能基线:
- 记录正常负载下的GC频率、暂停时间和内存使用情况
- 了解应用在不同负载下的GC表现
-
识别异常模式:
- 长时间GC暂停通常表明内存压力大或对象分配模式不佳
- GC频率突然升高可能意味着内存泄漏或临时对象创建过多
- 内存使用持续增长但GC频率不变可能是内存碎片问题
-
调整参数并验证效果:
// 自适应GC参数调优示例
func adaptiveGCTuning() {// 初始设置currentGOGC := 100debug.SetGCPercent(currentGOGC)// 定期评估和调整for range time.Tick(10 * time.Minute) {// 收集过去10分钟的GC统计metrics := collectGCMetricsForPeriod(10 * time.Minute)// 分析GC表现avgPause := metrics.AveragePausegcFrequency := metrics.GCFrequencymemoryUsage := metrics.MemoryUtilization// 根据分析结果调整GOGCif avgPause > 50*time.Millisecond && memoryUsage < 0.7 {// 暂停时间过长但内存充足,增加GOGC减少GC频率newGOGC := currentGOGC + 20if newGOGC <= 300 { // 设置上限debug.SetGCPercent(newGOGC)currentGOGC = newGOGClog.Printf("Increased GOGC to %d due to long pauses", currentGOGC)}} else if memoryUsage > 0.85 && avgPause < 10*time.Millisecond {// 内存使用率高但GC暂停短,降低GOGC增加GC频率newGOGC := currentGOGC - 20if newGOGC >= 50 { // 设置下限debug.SetGCPercent(newGOGC)currentGOGC = newGOGClog.Printf("Decreased GOGC to %d due to high memory usage", currentGOGC)}}// 可选:根据内存使用情况调整GOMEMLIMIT// ...}
}
- 通过A/B测试验证变更:
对于关键服务,可以通过A/B测试验证GC参数变更的效果:
// 在部分实例上测试新的GC设置
func abTestGCSettings() {// 使用环境变量或配置决定使用哪种GC设置testGroup := os.Getenv("GC_TEST_GROUP")switch testGroup {case "A":// 控制组 - 使用当前设置debug.SetGCPercent(100)case "B":// 测试组 - 使用新设置debug.SetGCPercent(150)default:// 默认设置debug.SetGCPercent(100)}// 记录组别以便于分析log.Printf("Running with GC test group: %s", testGroup)
}
实战经验:在我们的一个服务中,通过持续的GC监控和优化,我们发现服务在每天特定时间段(用户活跃高峰)GC暂停时间会显著增加。通过对这一时间段的GC行为进行针对性优化,我们实现了"动态GC参数":在高峰期自动增加GOGC值减少GC频率,在低峰期降低GOGC值减少内存占用。这种方法使服务在整个运行周期内都能保持最优性能。
建立完善的GC监控体系,能够帮助我们持续优化Go应用的性能,及时发现并解决GC相关问题。接下来,我们将总结本文的核心观点,并展望Go GC的未来发展。
十、总结与展望
在这篇文章中,我们深入探讨了Go垃圾回收机制及其调优方法,从基础原理到实战案例,希望能为你提供一套完整的GC调优工具箱。现在,让我们总结一下核心内容,并展望Go GC的未来发展。
GC调优的决策框架:何时需要调优,何时保持默认
不是所有Go应用都需要GC调优,过早优化可能是浪费时间。以下决策框架可以帮助你判断:
需要考虑GC调优的场景:
-
延迟敏感型应用:
- 实时交易系统
- 高频API服务
- 游戏服务器
- 实时数据处理管道
-
内存使用特征:
- 内存使用量大(GB级别)
- 短时间内创建大量临时对象
- 存在明显的内存使用峰值
-
性能出现以下问题:
- 服务延迟出现明显的周期性峰值
- CPU使用率周期性飙升
- 内存使用持续增长或波动明显
何时保持默认设置:
-
简单应用:
- 内存使用稳定且较小(<500MB)
- 对延迟不是特别敏感的应用
- 短期运行的命令行工具
-
当你不确定问题根源:
- 未通过性能分析确认GC是性能瓶颈
- 服务整体性能良好
-
资源受限环境:
- 默认GC设置在大多数资源受限环境中表现良好
- 在深入了解应用特性前不宜过度调整
GC调优决策树:
是否出现性能问题?
├── 否 -> 保持默认设置,专注于业务逻辑
└── 是 -> 进行性能分析├── GC占用CPU时间 > 10%?│ ├── 否 -> 寻找其他性能瓶颈│ └── 是 -> 继续GC分析├── GC暂停时间是否导致服务延迟峰值?│ ├── 否 -> 可能是其他并发问题│ └── 是 -> 需要GC调优└── 内存使用是否存在异常模式?├── 否 -> 可能是算法或I/O瓶颈└── 是 -> 需要GC调优
Go未来GC发展趋势简述
Go团队一直在持续改进垃圾回收器性能。以下是一些值得关注的发展趋势:
-
更低延迟的GC:
- Go团队致力于进一步减少STW(Stop-The-World)时间
- 可能采用更加并发的GC算法
-
更智能的内存管理:
- 更好的内存碎片处理
- 更精确的对象生命周期分析
-
更丰富的GC调优选项:
- 除GOGC和GOMEMLIMIT外,可能会提供更多精细化调优参数
- 可能支持针对不同类型对象的差异化GC策略
-
混合垃圾回收:
- 结合分代GC和当前的并发标记-清除算法
- 可能针对不同大小和生命周期的对象采用不同策略
-
更好的开发者工具:
- 改进的GC可视化和分析工具
- 更强大的内存分析功能
业界展望:随着Go在云原生和微服务领域的广泛应用,低延迟GC将持续成为Go团队的优化重点。我预计在未来2-3年内,Go的GC性能还会有显著提升,特别是在降低尾延迟(tail latency)方面。
推荐阅读与进阶学习资源
为了深入学习Go的垃圾回收机制,推荐以下资源:
-
官方文档与演讲:
- Go GC: Prioritizing low latency and simplicity
- GopherCon 2018: Getting to Go: The Journey of Go’s Garbage Collector
-
技术博客:
- Go’s garbage collector - Golang guide
- Garbage Collection In Go
-
工具使用指南:
- Profiling Go Programs
- Debugging performance issues in Go programs
-
书籍:
- 《Go性能实战》
- 《Go语言高级编程》中的内存管理章节
个人使用心得
在多年的Go开发经验中,我总结了一些GC调优的个人心得:
-
量化先于优化:
- 永远以数据为驱动进行调优
- 建立明确的性能基线和目标
-
简单优先:
- 往往代码层面的优化比调整GC参数更有效
- 大多数GC问题可以通过减少分配来解决
-
理解权衡:
- GC调优本质上是在CPU时间、内存空间和延迟之间寻找平衡
- 没有放之四海而皆准的最佳配置
-
持续监控:
- GC行为会随着应用负载变化而变化
- 建立长期监控,持续优化
-
保持谦逊:
- Go团队投入了大量精力优化GC,默认设置对大多数应用已经很好
- 只在确实需要时才调整GC参数
最后,记住GC调优不是目的,而是手段。我们的终极目标是提供稳定、高性能的服务,而不是追求理论上最优的GC配置。希望本文能帮助你在实际项目中更自信地面对和解决GC相关的性能挑战。
祝你的Go服务运行顺畅,延迟低,稳定可靠!