TOIS24-可解释推荐|特征增强神经协同推理

论文 https://dl.acm.org/doi/10.1145/3690381
代码 https://github.com/Xiaoyu-SZ/FencrCode
最后一篇神经符号集成的论文了,24年底发表于TOIS,有很详细的实验分析。流程:逻辑规则借鉴RRL是自适应学习的,借鉴LINN架构进行规则逻辑运算编码,使用FM编码逻辑表达式,计算与逻辑常量真向量的相似度,并且使用了逻辑正则化,背景知识详细讲解了两个的机制。
动机
尽管现有推荐系统在准确性上取得了巨大成功,但其可解释性仍是提升用户信任和系统透明度的关键瓶颈 。基于逻辑规则的推断因其简洁、透明且符合人类认知,被认为是提高推荐模型可解释性的有效途径 。
然而,先前利用逻辑规则解释用户偏好的工作,往往只侧重于规则的构建(WWW22以及上一篇帖子的两个工作),而忽略了特征嵌入在捕捉特征间隐式关系方面的强大能力 。另一方面,一些结合了嵌入表示的逻辑推理方法虽然能赋予模型逻辑属性或利用预定义知识,却难以生成显式的、可供解释的推荐规则 。因此,本文的核心动机在于解决这一矛盾,即同时实现推荐模型的高推荐效果(通过利用特征嵌入)和高模型内在可解释性(通过学习显式的逻辑规则),弥补现有研究未能有效兼顾这两者的空白 。
贡献
提出了一种名为特征增强神经协同推理 (FENCR) 的新型端到端可解释推荐方法 ,它能够同时学习用于表示的特征嵌入和用于推理的显式逻辑规则 。为实现这一目标,设计了基于特征交互的神经逻辑模块,以在特征向量上有效表征合取 (∧) 和析取 (∨) 等逻辑运算 。
更重要的是,FENCR模型能够以数据驱动的方式自动提取代表性的逻辑规则 ,这些规则(例如购物场景下的“用户收入 ∧ 物品价格” 或求职场景下的“用户经验 ∨ 用户学历” 等直观形式)可以作为模型内在的、无需额外数据或先验知识的透明解释 。
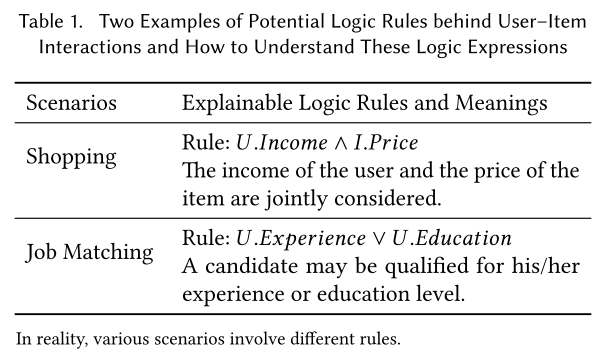
背景知识
RRL (Rule-Based Representation Learner)
RRL是一个自适应的规则学习模型 。其目标是在保持分类准确率的同时,自动学习用于分类的可解释规则 。FENCR从中借鉴了通过训练权重矩阵来动态学习规则中包含的特征的思想 。
逻辑层是RRL进行规则学习的关键部分,它是一个多层神经网络,每一层都包含一定数量的合取节点和析取节点 。权重矩阵W代表了当前层与前一层之间的连接关系 。给定当前层第t个节点的权重向量Wt和前一层的输出 h(元素为二值),当权重W和输入h都二值化后,合取和析取操作定义为 :
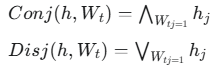
权重矩阵W的取值(0或1)决定了前一层的输出 hj 是否参与到当前节点的逻辑运算中 。通过以自监督的方式学习W,模型能够通过选择表达式中的元素来获取用于分类的逻辑规则 。例如,给定一个合取节点和四维输入 h=(h1,h2,h3,h4),如果对应的权重 W=(0,1,1,0),那么该节点代表的规则就是 h2∧h3,其中 hi 可以是变量或表达式 。
为了在神经网络中训练这些逻辑值,RRL使用了逻辑激活函数来实现合取层和析取层 :
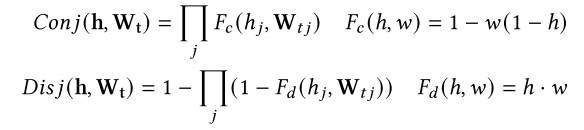
LINN (Logic-Integrated Neural Network)
LINN(出自NLR )是一个神经符号框架,它将逻辑运算(主要是AND (∧),OR (∨),NOT (¬))扩展到向量空间进行操作 。FENCR沿用了其在向量上建模逻辑运算的思想 。
LINN包含三个主要组成部分:逻辑算子、相似度模块和逻辑正则化器 。
逻辑变量 (Logic Variables):使用潜向量(latent vectors)表示 。
逻辑算子 (Logic Operators):由双层MLP网络表示,∧和∨共享相同的结构但有不同的参数
![]()
相似度模块 (Similarity Module):用于基于余弦相似度衡量两个向量之间的相似性 ,判断这个逻辑表达式在当前模型状态下的“真值”或“成立程度”:
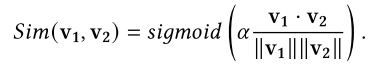
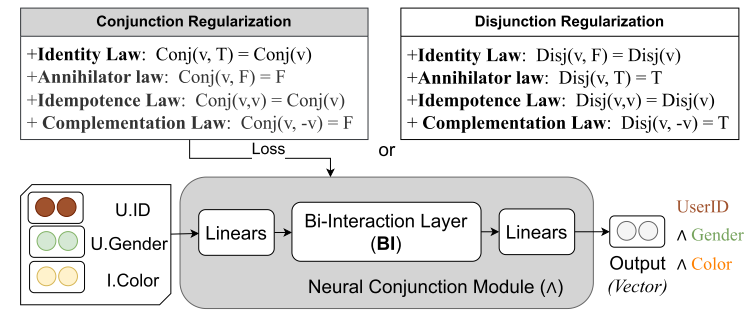
逻辑正则化器 (Logic Regularizers):这是一组基于逻辑定律的损失项,以一种自监督的方式,促使神经网络学习到的逻辑算子(如AND、OR、NOT的神经模块)的行为符合已知的逻辑定律和属性。
模型
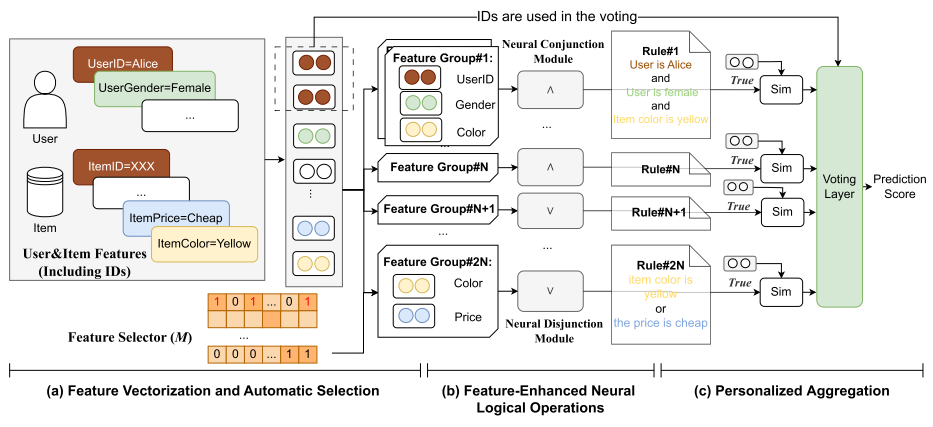
(1)特征矢量化与自动选择,在学习特征的表示,并以数据驱动的方式为规则选择特征 。
(2)特征增强神经逻辑运算,在向量上执行逻辑运算 合取 (∧) 和析取 (∨),每种运算占所有学习规则的一半,融入了因子分解机结构来表征这些逻辑符号
(3)个性化聚合。使用协同信号(用户和物品的ID嵌入)来聚合多条生成的规则
特征矢量化与自动选择
首先是将原始的离散或类别型特征向量化,其次是自动地、以数据驱动的方式选择哪些特征应该被包含在最终学习到的逻辑规则中
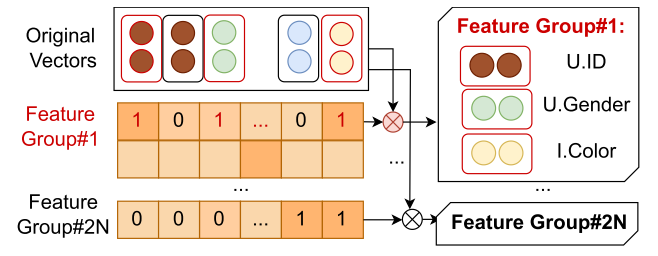
首先初始化用户项目和内容特征的嵌入,对于每一个用户-物品对,它们的所有相关特征![]() 会被转换成一个嵌入向量的集合
会被转换成一个嵌入向量的集合![]()
FENCR模型旨在自动学习2N条逻辑规则(N条合取规则和N条析取规则)。这个阶段的核心任务是以数据驱动的方式,自动学习并决定哪些特征向量应该被包含在这2N条规则对应的2N个特征组,使用RRL的方法使用可训练的矩阵M,然而前向传播过程中,M需要被离散化(即转换为0/1矩阵 M)以实现明确的特征选择,所以使用Gumbel-Softmax应用于M中的每个元素,使得模型能够在训练过程中做出类别型决策(选择或不选择某个特征)
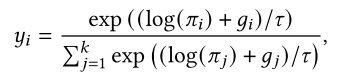

特征增强神经逻辑运算
将神经模块用于在向量上表示逻辑运算的想法最初是在NLR,然而基于MLP的结构在对包含多个、且长度可变的特征集进行交互建模时是低效的,因此使用因子分解机(将复杂度从 O(k2) 降到 O(k)),编码两种逻辑运算——合取 (∧) 和析取 (∨)
FM模型的核心是计算特征向量两两之间的元素级点积之和。由于FENCR需要向量作为输出,将“对元素级乘积求和”的过程称为双向交互层 (BI),其输出是一个向量。给定一个包含k个特征向量的特征组,BI层的计算公式为:
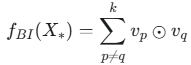
FENCR将BI层嵌入到一个更复杂的MLP结构中,形成最终的神经逻辑模块。合取模块和析取模块共享相同的结构。合取模块完整计算流程和公式如下:
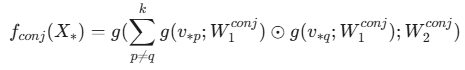
首先,特征组中的每一个输入向量都会经过一个双层MLP,对所有经过第一步变换后的向量应用双向交互层 (BI),计算它们两两之间的元素级乘积之和,最后,将BI层得到的交互向量再通过另一个双层MLP进行变换,得到最终的输出向量,输出向量直接解释为一条逻辑规则的执行结果 。这条规则的具体内容由输入特征组 X 中包含的特征和模块的类型(合取或析取)共同决定 。
个性化聚合
为了生成最终的推荐分数,模型首先评估每个规则的结果,然后利用用户和物品的ID嵌入作为协同信号来指导对多个规则结果的聚合。
评估:对于每个逻辑运算模块的输出向量,会计算它与一个预定义的、代表逻辑常量真 (True)的向量 T 之间的相似度:
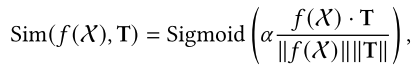
仅仅用几十条规则来刻画数百万用户的偏好是困难的。因此,FENCR引入了个性化权重来聚合来自多条规则的分数,以形成最终的预测。使用一个线性网络(MLP)作用于用户和物品的ID嵌入上来生成个性化的局部权重 。
![]()
最终的推荐预测分数 s^ 是通过将2N条规则各自与“真”向量T的相似度分数进行加权求和得到的,权重就是刚刚生成的个性化权重 w。
![]()
每条规则的重要性不再是全局固定的,而是根据当前用户和物品的特性(通过它们的ID嵌入体现)动态生成的。
逻辑正则化器
为了保持逻辑属性,需要引入额外的约束 即逻辑正则化器,它们被加入到总损失函数中,以指导神经逻辑模块的训练 。FENCR期望其神经模块满足四种常见的逻辑定律,也就是针对合取 (Conjunction) 的正则化器和针对析取 (Disjunction) 的正则化器,将逻辑定律转化为可计算的损失项 :
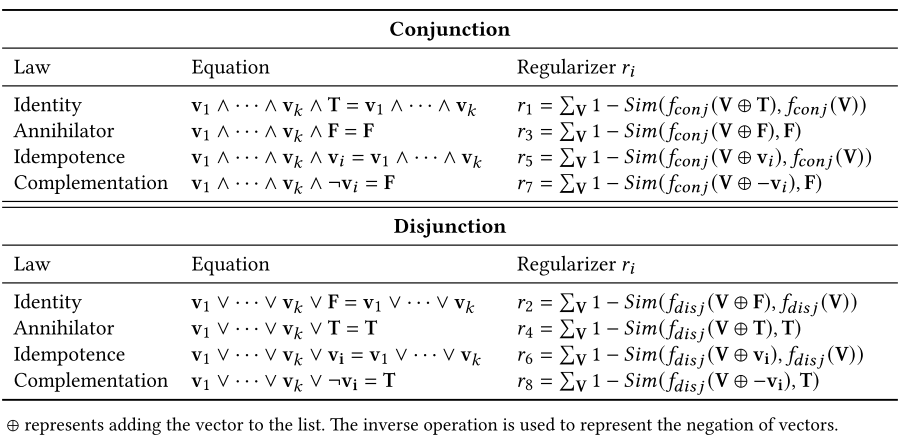
单位律 (Identity Law): 一个逻辑表达式与逻辑常量“真 (True)”进行合取(AND)运算,其结果应等于其自身
零律 (Annihilator Law):一个逻辑表达式与逻辑常量“假 (False)”进行合取(AND)运算,其结果应等于假
幂等律 (Idempotence Law):一个合取表达式再与其自身的任意一个组成部分进行合取运算,结果应保持不变。
互补律 (Complementation Law):一个合取表达式与其任意一个组成部分的否定进行合取运算,结果应为假。析取部分的正则化器与合取部分遵循相同的逻辑定律,但规则相反。
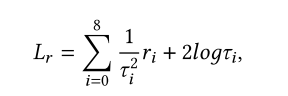
FENCR的总损失函数 L 由三部分组成 :推荐任务损失 Lt (BPR),逻辑约束损失 Lr ,以及防止模型过拟合的 l2 正则化项。
![]()
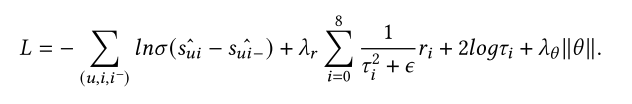
讨论
与其他先前工作的比较概览
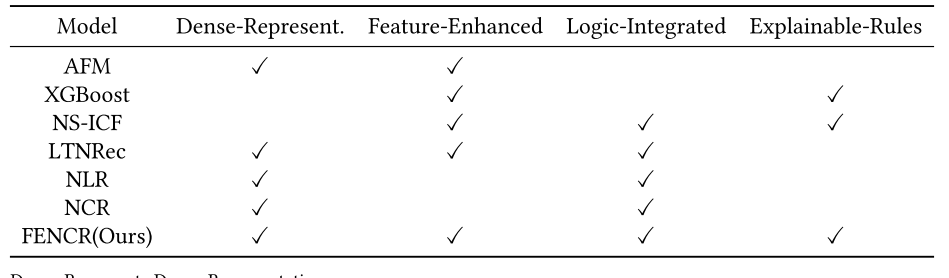
- Dense-Represent.:在逻辑运算中是否使用嵌入向量来表示变量。
- Feature-Enhanced:是否将内容特征融入模型。
- Logic-Integrated:是否将逻辑符号融入模型。
- Explainable-Rules:是否能总结出显式的规则作为模型解释。
未来工作:
与语言模块协作 (Collaborating Language Modules): FENCR使用稠密的潜向量表示,这使其能很容易地与语言建模模块协作,例如,通过直接用文本嵌入替换特征嵌入,从而将文本数据有效地整合到推荐过程中。
可控推荐 (Controllable Recommendation): 由于逻辑规则是可编辑的,FENCR允许对推荐结果进行人工干预。例如,开发者可以通过固定选择器矩阵M的特定行,或在训练M时基于先验知识加入软约束,来影响推断过程,使其优先考虑关于特定已知特征集的推理。
细粒度用户建模 (Fine-Grained User Modeling): 通过分析学习到的规则上的个性化权重分布,可以发现某些规则可能对特定的用户群体更有效。通过研究用户间的规则权重分布,可以将用户行为划分为更精细的类别,从而实现更细粒度的用户建模,并可能利用这种增强的理解来进一步改进推荐。
应用于工业级海量特征 (On Industrial-Level Massive Features): 论文讨论了将模型应用于具有海量特征的数据集时面临的主要限制,即随着特征数量的增加,选择器矩阵M和嵌入表E的大小也会线性增加。此外,如何增加规则数量N也值得考虑。在工业级的海量特征上探索该工作的应用是一个有趣的未来方向。
实验部分
为了验证其关键模块的有效性,论文进行了消融研究(见论文表8)。结果显示,移除特征选择器 (Feature Selector) 或逻辑正则化项 (Logic Regularization) 都会导致模型性能显著下降。分析了不同输入(仅用户特征/仅物品特征)、不同聚合策略(仅用户嵌入/仅物品嵌入/全局权重)以及不同规则数量N对性能的影响。
可解释性实验
Case Study:学习到的逻辑规则来提供模型内在的 (model-intrinsic) 解释,因为这些规则本身就是模型用来生成推荐结果的结构的一部分。

淘宝案例#3:是一条析取(Disjunctive, ∨, OR)规则。 根据论文的解释,析取符号 ∨ 表示只要满足其中一些条件,就会导致用户做出(正面的)决策。之所以向用户26905推荐物品670415,是因为满足了以下条件中的至少一个:
这件物品就是670415本身(一种高度个性化的匹配)。
该用户的消费层级是中等。
该用户的店铺等级是高的。
该用户是大学生。
该物品的类目ID是6261。
该物品的价格在0-1000范围内。
为了展示规则权重的个性化,论文在图6中展示了6条不同规则在RSC2017数据集所有样本上的权重分布。分析发现,不同的规则展现出截然不同的权重分布。例如,规则(a)在所有实例中几乎都保持很高的权重,说明它是一条普适性很强的规则。而规则(e)和(f)则只在特定数据上有效,在其他数据上权重很低。这证明了FENCR的个性化聚合机制是有效的:模型能够为不同的用户-物品对动态地、个性化地评估每条规则的重要性,而不是对所有情况都一视同仁。
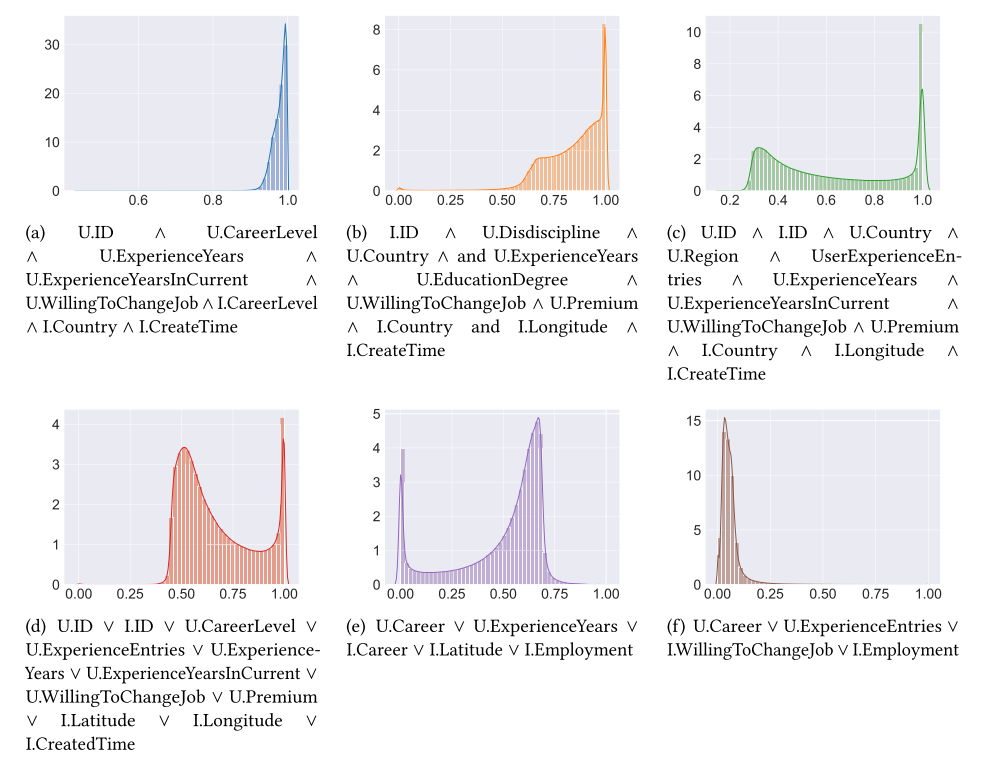
特征出现情况:通过分析学习到的规则中特征的出现频率和共现情况。论文统计了不同特征在所有生成的规则中出现的频率:
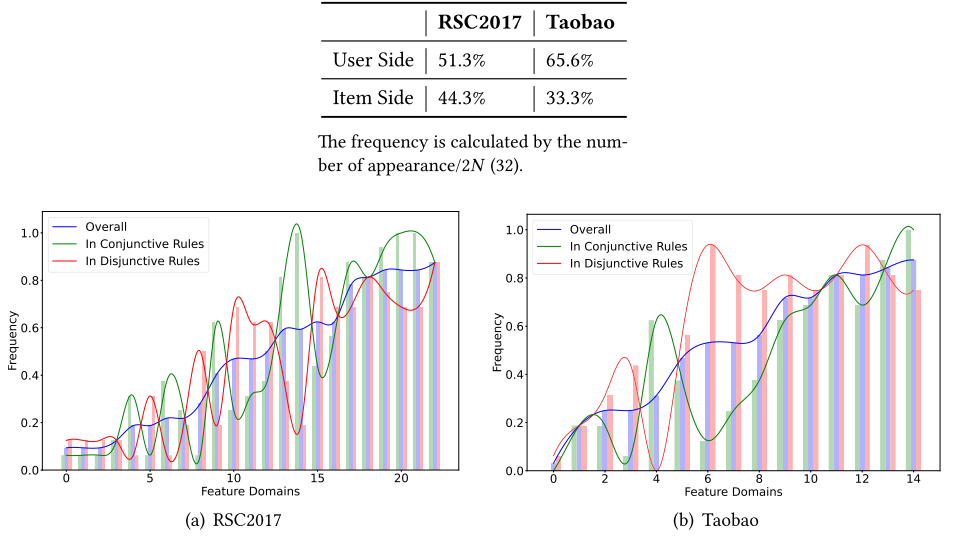
在淘宝(广告)数据集中,最常出现的特征是“用户消费层级”、“用户店铺等级”和“用户是否为大学生”。这也合理地反映了用户的消费能力和习惯是广告推荐的关键。
论文还分析了特征对在合取规则和析取规则中共同出现的情况,某些特征(如ID、国家、地区)更倾向于以**合取(AND)**的方式与其他特征一起出现,这表明它们需要与其他特征同时被考虑才能形成一个有效的推荐决策。
而另一些特征(如用户职业等级、用户学历、物品是否付费)则更常出现在**析取(OR)**规则中,这表明它们作为独立的条件就足够“强大”,能够独立地对推荐决策做出贡献。
总结
其使用了RRL和LINN的架构并进行增强,同时设计了八个逻辑约束来指导神经逻辑模块的训练,同时论文的实验分析部分很全!
1. 逻辑定义与获取:
定义: 逻辑知识被定义为由用户和物品的特征(属性)构成的合取或析取规则。
获取: 规则是自适应学习的。论文设计了一个可训练的特征选择器矩阵M,通过数据驱动的方式自动决定哪些特征应该被包含在每条规则中。
2. 逻辑编码与表示:
所有特征(包括ID和内容特征)首先被编码为稠密的嵌入向量。
逻辑运算(AND/OR)由基于特征交互的神经逻辑模块实现。这些模块的结构融入了因子分解机 (FM) 的思想,使其能够有效地在特征向量组上操作并捕捉特征间的二阶交互。每个模块的输出是一个代表该规则结果的向量。
3. 逻辑如何影响模型:
每个规则模块的输出向量首先通过与一个固定的“真”向量T计算相似度,得到一个标量分数。
然后,所有规则的分数通过一个个性化的加权聚合来得到最终的推荐预测。这些权重是由一个MLP基于用户和物品的ID嵌入计算得出的。
此外,模型的训练还受到一组逻辑正则化器的约束,这些正则化器引导神经逻辑模块的行为更符合逻辑定律。