Linux 基础IO(中)
目录
前言
理解文件系统
了解磁盘
块的概念
文件系统的结构
文件目录
软硬链接
1.概念
2.作用
结尾
前言
本篇是linux基础IO的第二篇,其实说是基础,但是本篇开始将会涉及一些硬件的内容还有比较底层的东西,相对来说比较抽象不好理解,大家需要多看多记多思考!!
理解文件系统
如果一个文件没有被打开,只能静静的在磁盘上放着
所以磁盘上有大量文件,也是必须要被静态管理起来的,方便我们随时打开
——文件系统
了解磁盘
1.磁盘的物理结构

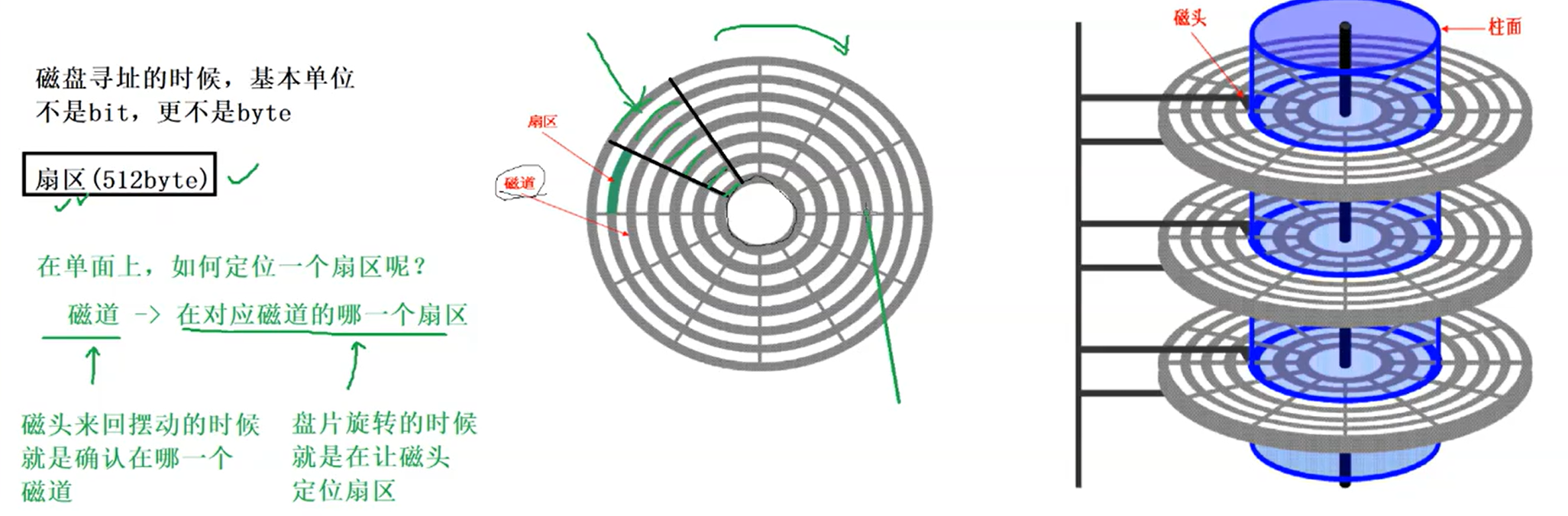
[^] 柱面相当于磁道
通过磁头、柱面(磁道)、扇区定位
磁头==面数 磁头是共进退的
如何在磁盘中,定位器任何一个扇区?
答:先定位在哪一个磁道(柱面),再定位磁头(定位盘面),最后再定义在哪一个扇区
(Track、cylinder) (head) (sector)
磁盘中定义去任何一个(任何多个)扇区,采用的硬件基本的定位方式:CHS定位法
2.磁盘的逻辑结构

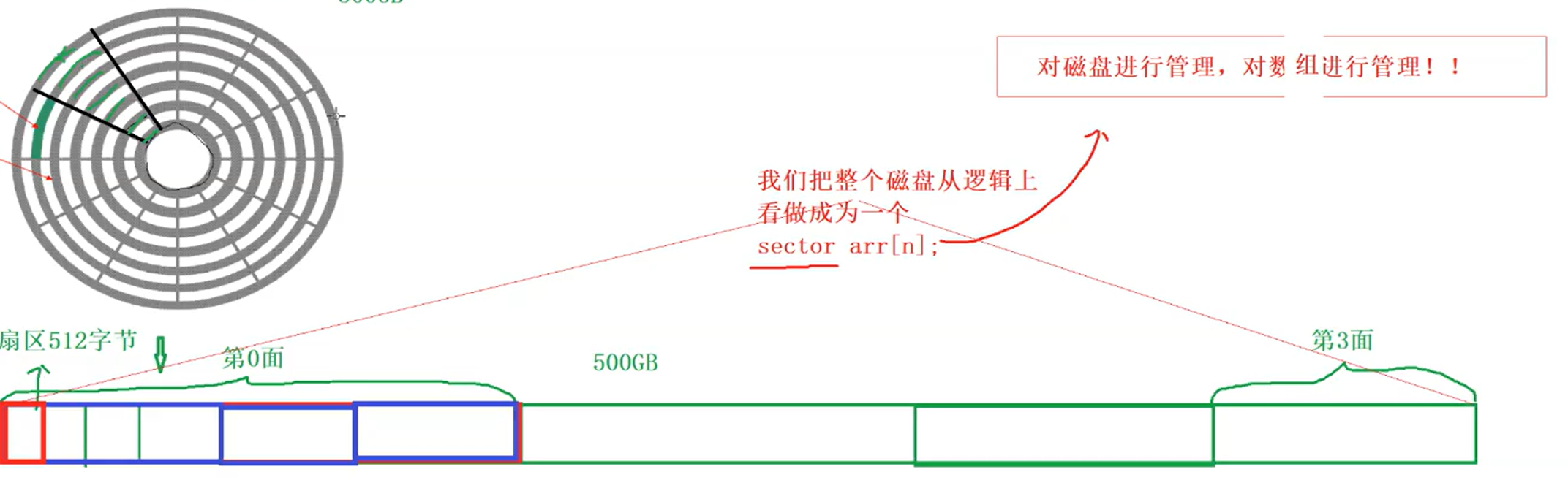
所以在逻辑上我们把磁盘看作线性结构,我们要找到一个扇区,只需要知道这个扇区的下标就算定位了一个扇区(在操作系统内部,我们称这种地址位LBA【逻辑块】地址)
那如何把软件上使用的LBA地址转换成对应硬件磁盘上的CHS定位法呢?
e.g.

为什么操作系统要进行逻辑抽象呢?直接用CHS定位法不行吗?
1.这样便于管理
2.不想让操作系统的代码和硬件强耦合(底层硬件发生变化时不会影响操作系统)
虽然对应的磁盘的访问基本单位是512字节,但是依旧很小:操作系统的文件系统定制的进行多个扇区的读取 ->1KB,2KB,4KB(8个扇区)为基本单位,你哪怕只想读取/修改1bit,也必须将4KB load到内存中,进行读取或修改,如有必要,再写回磁盘
优化:局部性原理
内存是被划分成了4kb大小的空间 ——页框
磁盘中的文件尤其是可执行文件——按照4kb大小划分好的块——页帧
块的概念
其实硬盘是典型的“块”设备,操作系统读取硬盘数据的时候,其实是不会⼀个个扇区地读取,这样效率太低,⽽是⼀次性连续读取多个扇区,即⼀次性读取⼀个”块”(block)。
硬盘的每个分区是被划分为⼀个个的”块”。⼀个”块”的⼤⼩是由格式化的时候确定的,并且不可以更改,最常⻅的是4KB,即连续⼋个扇区组成⼀个 ”块”。”块”是⽂件存取的最⼩单位。
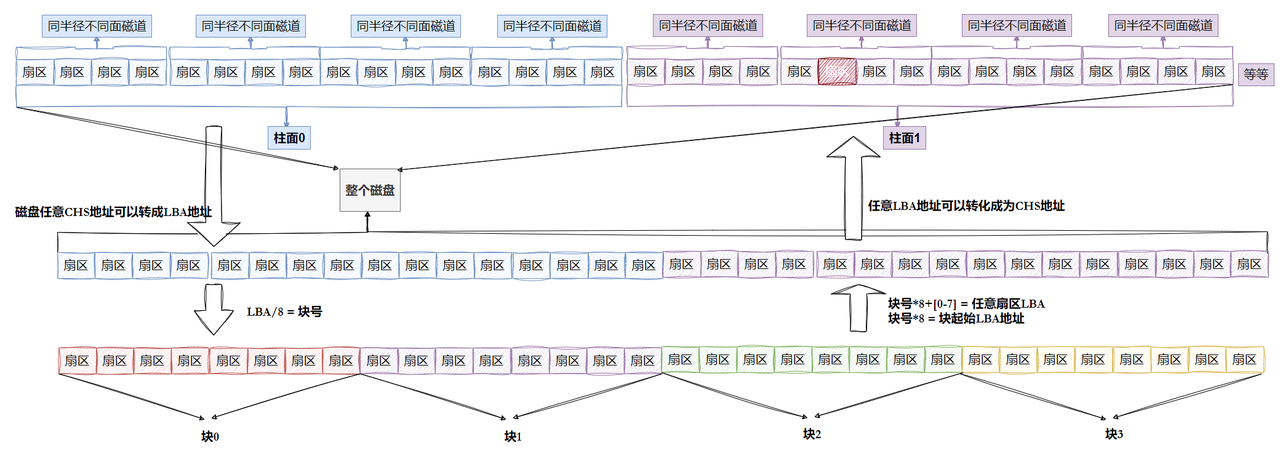
到⽬前为⽌,相信⼤家还有两个问题:
-
我们已经知道硬盘是典型的“块”设备,操作系统读取硬盘数据的时候,读取的基本单位是”块”。“块”⼜是硬盘的每个分区下的结构,难道“块”是随意的在分区上排布的吗?那要怎么找到“块”呢?
-
还有就是上⾯提到的存储⽂件属性的inode,⼜是如何放置的呢?
⽂件系统就是为了组织管理这些的!!
还需要有一些策略堆磁盘进行管理 —— 文件系统
文件系统的载体是分区
文件系统的结构
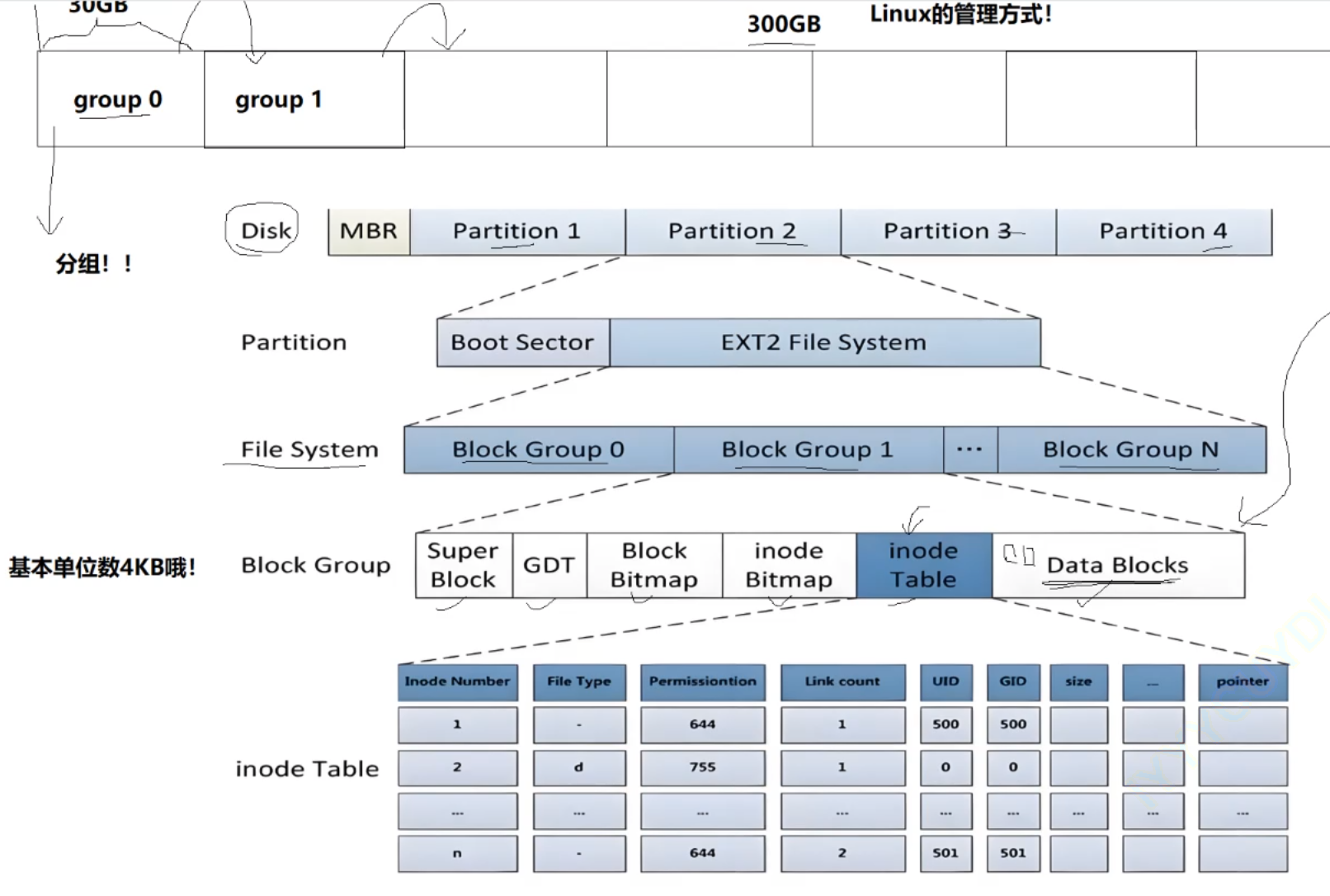
文件系统管理的分治思想:
-
Super Block:保存的是整个文件系统的信息,每个组都有是为了备份,因为它一旦损坏,文件系统会挂掉(如果有一天这个常用的super block坏了,可以从其他分组的super block拷过来,完成文件系统的恢复)

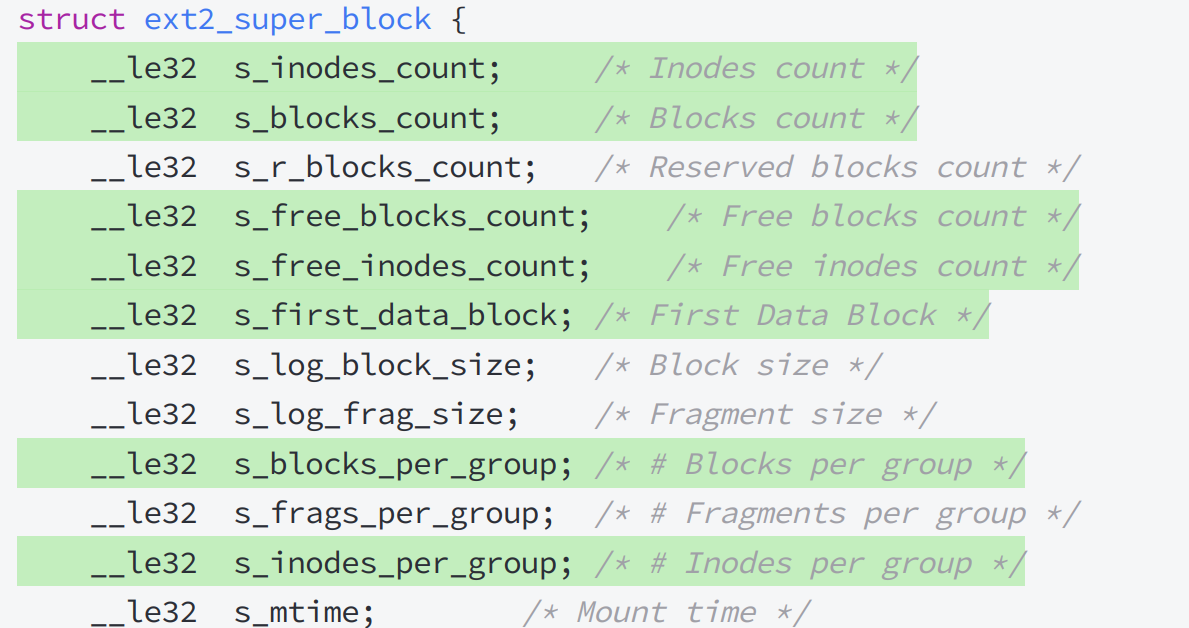
Linux中任何正常文件,都要有自己的属性集合,属性类型都一样,但是内容可以不一样

-
Linux的文件属性和文件内容是分批存储的,而保存文件属性用的是Inode块,文件的大小、文件的权限、文件的拥有者、文件的所属组、文件的相关时间信息都在inode中,inode是固定大小;保存文件内容用的是data block,随着应用类型的变化,大小也在变化
一个文件,一个inode,基本包含了文件的所有属性,但是文件名这一属性并不在inode中存储的,inode大小要保持一致,但是文件名的字符串大小很可能是不一样的,会影响
inode为了进行区分彼此,每一个inode都有自己的id,并且是跨组的,也就是说每个组中inode的id不能和其他组重复了,但不跨分区,也就是在不同的分区中id可以重复,但是在同一个分区内部inode的id都是唯一的(数据块也同理)

[^] 前面的数字就是每一个文件对应的inode的id
所以有inode编号的情况下,通过/每个组有多少个inode找到所在组,再%这个组inode个数就能找到inode在这个组的位置,然后所对应的inode Bitmap位图的位置也知道了
-
inode table保存了分组内部所有的可用(已使用+没有使用)inode ,其中有4kb的数据块,一个数据块会保存32个inode(4096/128)
-
Data blocks保存的是分组内部所有文件的数据块
通过inode可以找到在Data blocks中对应文件的数据内容,这是因为在inode结构体中有一个存储该文件对应Data blocks编号的数组


EXT2_N_BLOCKS的大小是15
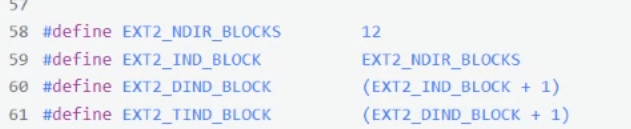
那这样我们的文件只能填写15个数据块,每个数据块才4kb,岂不是文件最多只能有15*4=60kb的大小?,所以对应的inode中的数组并不是直接每个下标单纯对应一个数据块,而是前12是单纯一一对应的,而后三个分别是一级、二级、三级索引:
一级索引指向的4kb的block,这个block中不保存当前文件的数据内容,保存的是我这个文件的下一个新的数据块的地址,而下一个数据块才开始保存数据内容,所以一个数据块编号也就是指针4个字节的话,我们就多出的1024个数据块:指针数量=单个指针大小索引块大小=数据块大小4096字节/4字节的指针=1024个指针
二级索引指向的数据块中保存的也是下一个数据块的地址,而下一个数据块保存的也是再下一个数据块的地址,这个再下一个的数据块再保存数据内容,也就是多了1024*1024的数据块(大概有100万个了)
三级索引指向的数据块中保存的也是下一个数据块的地址,而下一个数据块保存的也是再下一个数据块的地址,而这再下一个数据块保存的还是再下下个数据块的地址,然后这个再下下个的数据块才开始保存数据内容,也就是多了1024 * 1024 * 1024个数据块(大概有10亿个了)
如果一个分组只有10个G,但是文件数据超过10G怎么办?我们之前提过,inode和data blocks都是跨组的(全局的),也就是说,我们可以用其他的组的data blocks来存剩余的数据
-
inode Bitmap为inode对应的位图结构,位图中比特位的位置和当前文件对应的inode的位置是一一对应的
-
Block Bitmap为数据块对应的位图结构,位图中比特位的位置和当前data block对应的数据块是一一对应的关系
-
Group Descriptor Table:GDT为块组描述表,对应分组的宏观的属性信息,每个块组描述符存储一个块组的描述信息,如在这个块组中从哪里开始是inode Table,从哪里开始是Data Blocks,空闲的inode和数据块还有多少个等等
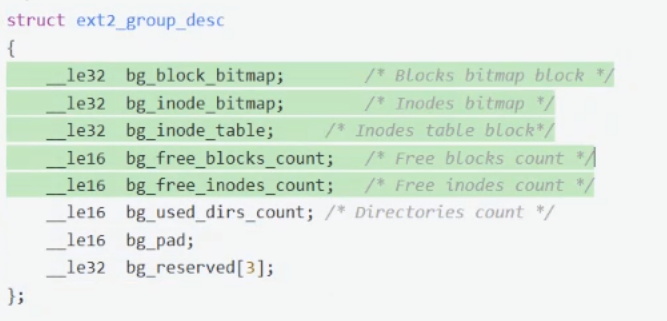
-
在使用这个分区之前,需要将上面前四个用于管理的块清零 ,全部信息都应该提前写到对应的分组里,对应的整个文件系统里,这个过程叫做——格式化,格式化的本质就是写入文件系统的管理信息(就是上面的前四个用于管理的块)
-
查找一个文件时,统一使用的是:inode编号(可跨组 ),具体的操作上面有
-
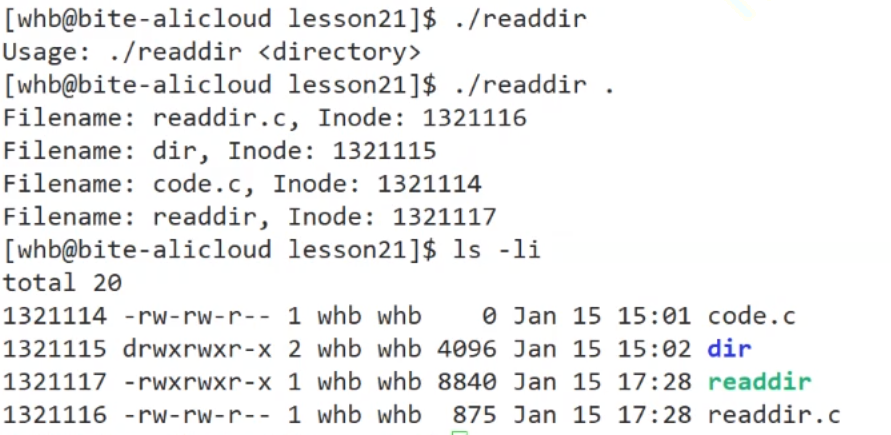
回答上面inode中不存文件名:因为目录的数据块放的是当前目录下的文件名和inode的映射关系
-
删除只需要该位图结构从1到0就可以了,所以删除很快,但是创建是需要实打实写入Data blocks还要inode的,所以会慢
操作系统也需要对文件系统做管理,通过把分组每个组内部前四个用于管理的块(存储了信息)加载到内存中,super Block加载进来,文件系统的信息就知道了,用链表链起每个super Block,这样一来,对文件系统的管理转换成了对链表的增删查改(管理的本质),GDT加载进来,每个分组的信息就知道了,同样的两个位图块加载进来,在内存中对位图做修改从1-0(删除),再在合适的时机将数据统一刷新到磁盘上——删除,上面所有的操作都在内存中进行的,由操作系统完成
文件目录
详细解释上面的10
可是最开始的路径从哪⾥来?
• 所以Linux为什么要有根⽬录, 根⽬录下为什么要有那么多缺省⽬录?
• 你为什么要有家⽬录,你⾃⼰可以新建⽬录?
• 上⾯所有⾏为:本质就是在磁盘⽂件系统中,新建⽬录⽂件。⽽你新建的任何⽂件,都在你或者系统指定的⽬录下新建,这不就是天然就有路径了嘛!
• 系统+⽤⼾共同构建Linux路径结构
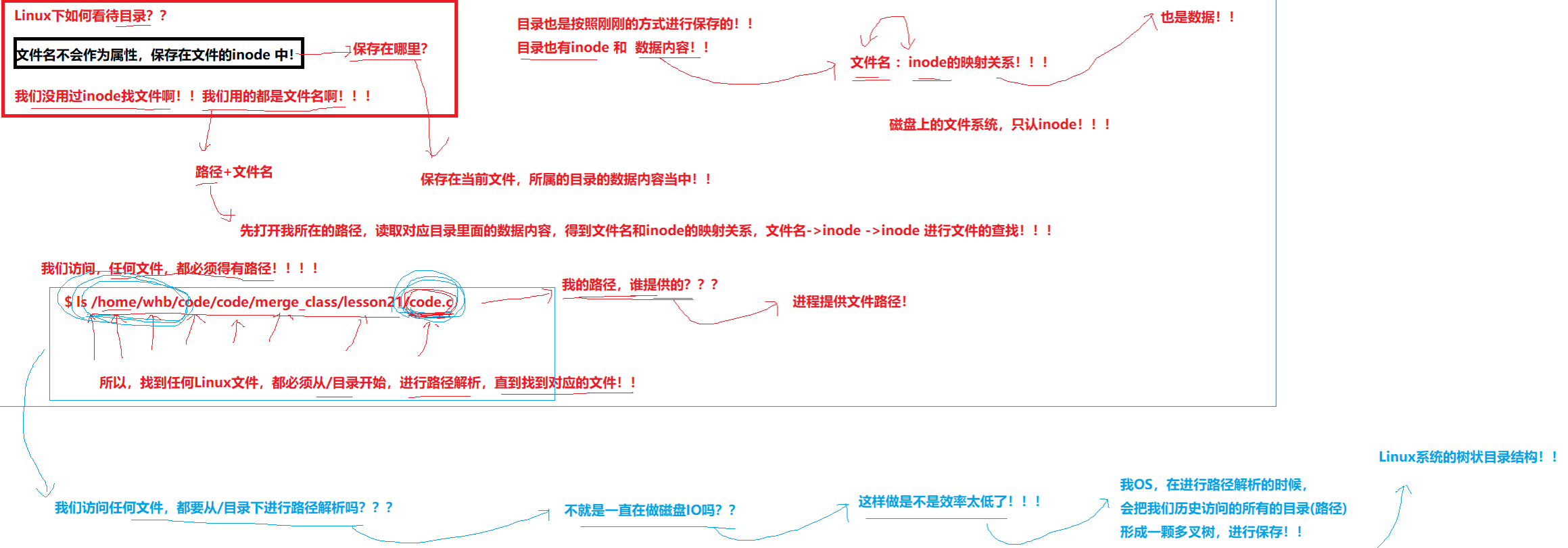
进而延申出路径缓存

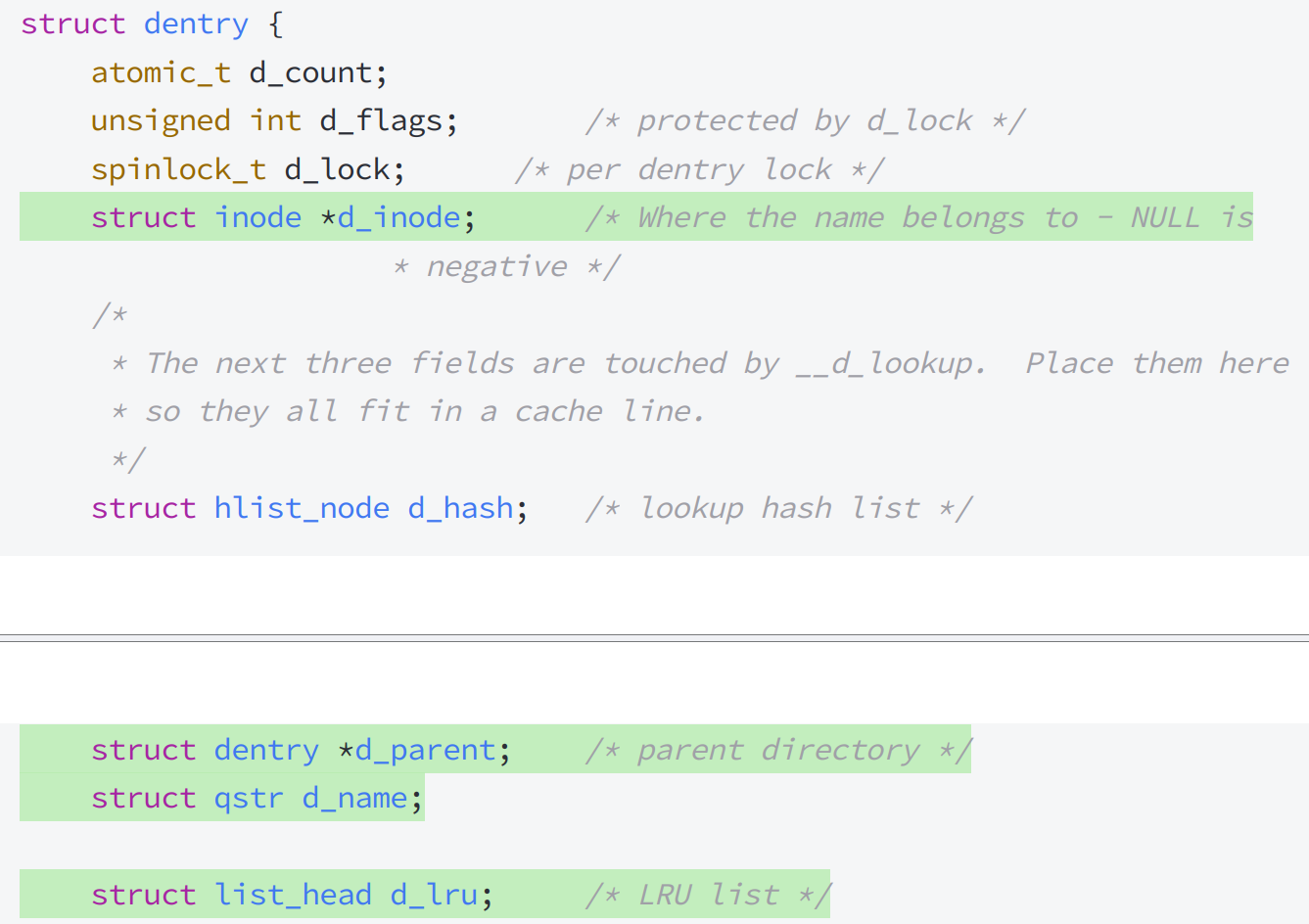
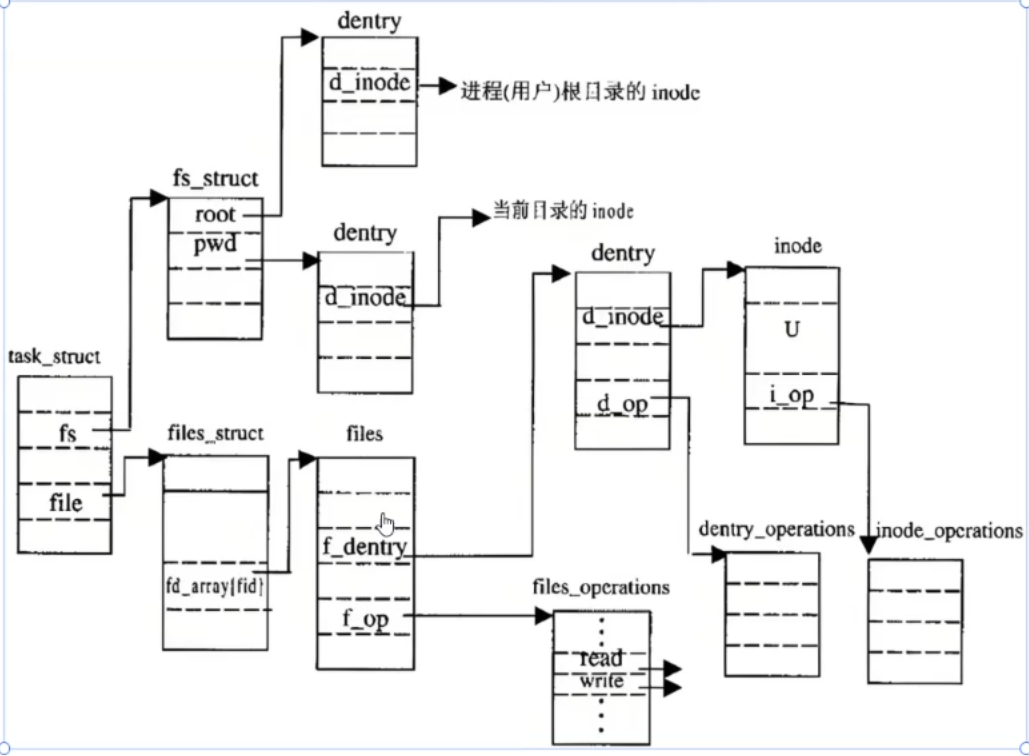
struct dentry:和pcb、task_struct一样,属于内存级数据结构(只在操作系统内存中创建,不会在磁盘中保存)
struct dentry中有lru淘汰链表,可以淘汰掉最近较少访问的文件,进而提高struct dentry中树状结构的查找对应的文件效率,还有hash哈希方便快速查找

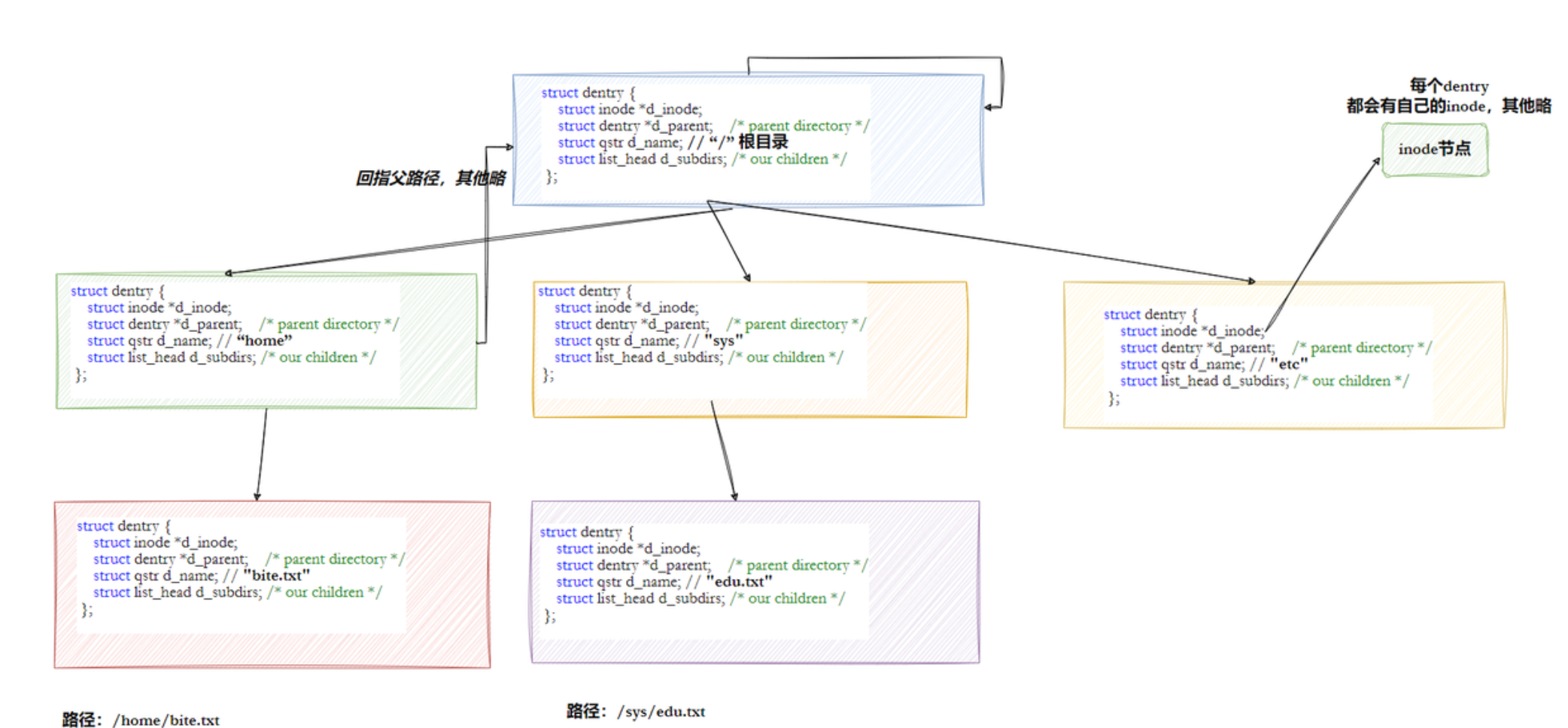
这样一来,我们看起来可以通过打开文件在struct dentry中记录的inode可以从磁盘文件系统的分区分组中找到对应的文件数据,真的是这样吗?我们前面说了inode是不跨分区的,也就是我们单从inode是没有办法判断这个文件数据在那个分区的(因为不同区inode可以相同);通过这个问题,我们引出了挂载分区这个概念

我们磁盘分了区然后格式化了,我们还不可以直接使用这个分区,我们能使用的分区一定是要先和特定的一个目录进行关联,通过进入这个目录,就相当于进入这个分区——这就是挂载
df -h:查看系统当中的文件系统,对应的一些属性
从挂载分区我们可以知道,所有的分区都和路径有关,我们其实不需要知道到底在哪个分区,因为一开始的文件路径会有一个挂载点,它已经帮助我们规定好了要在那个分区,当然我们的struct dentry中有记录文件路径是哪个分区的,这样就不需要每次打开文件都得判断在哪个分区了

struct dentry和struct file的联系
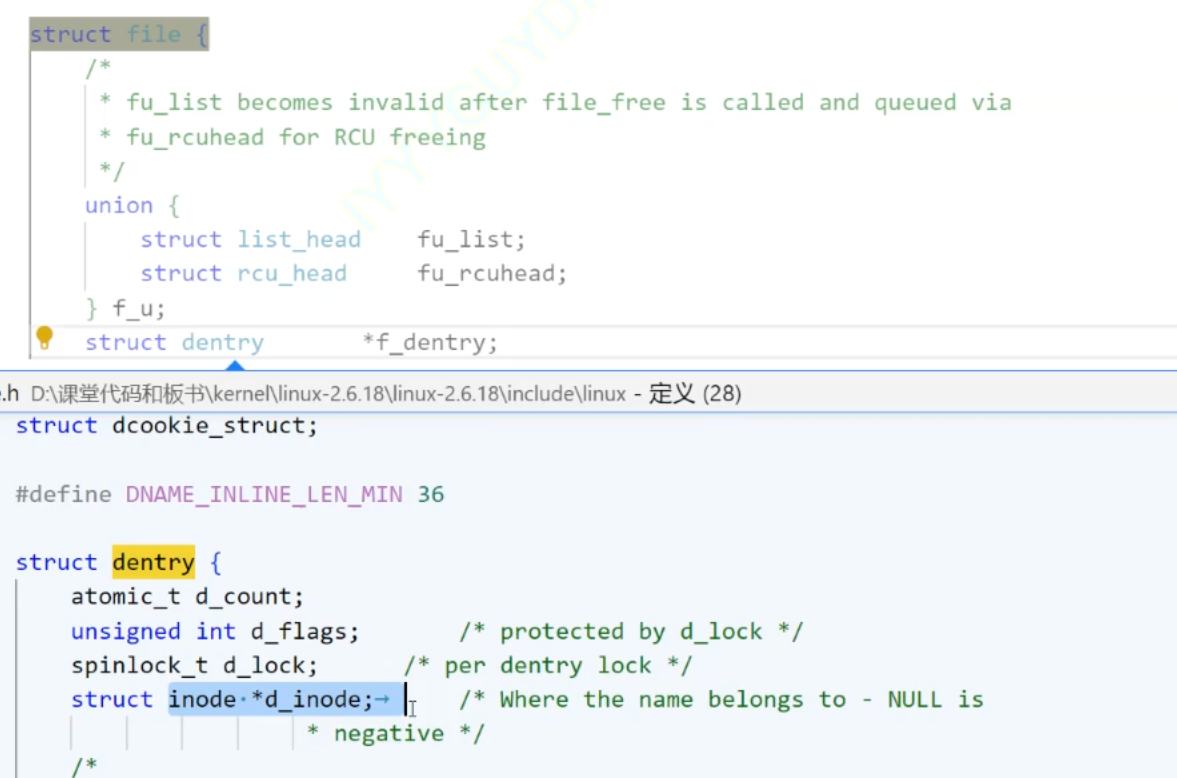
而struct inode中是存储文件的除了文件名之外的属性
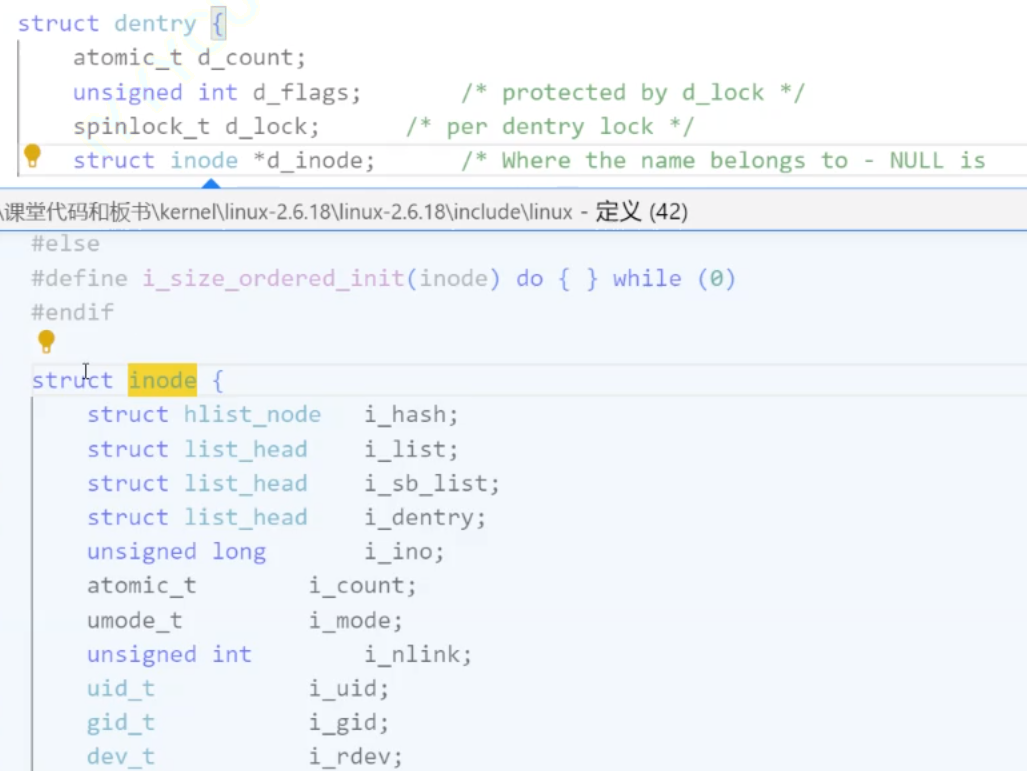
总结图:

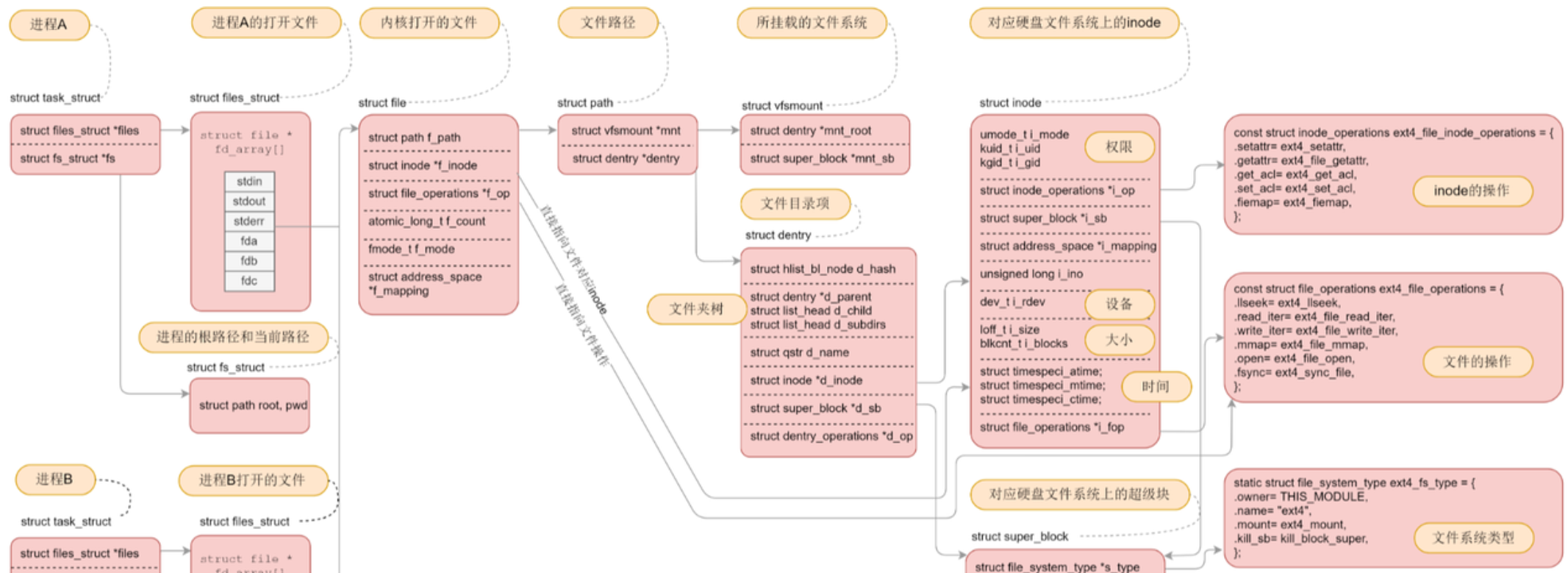
软硬链接
1.概念
软硬链接的建立
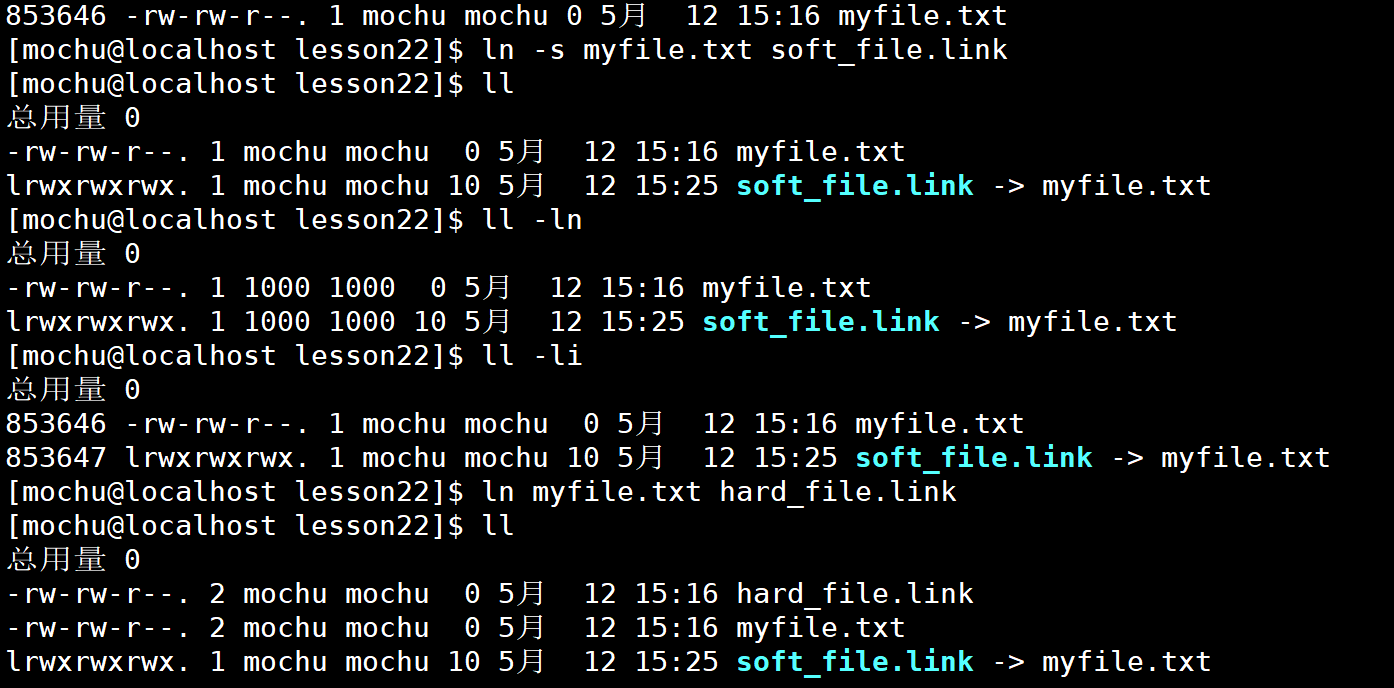
有独立inode的这种链接文件 —— 软链接
inode和链接前文件相同的这种链接文件 —— 硬链接

所以软硬链接的区别:是否具有独立的inode
软链接具有独立的inode——可以被当作独立文件看待
硬链接没有独立的inode——没有创建新文件(没有分配独立的inode)所以不能当作独立文件
(建立硬链接就是在指定路径下,新增文件名和inode编号的映射关系)
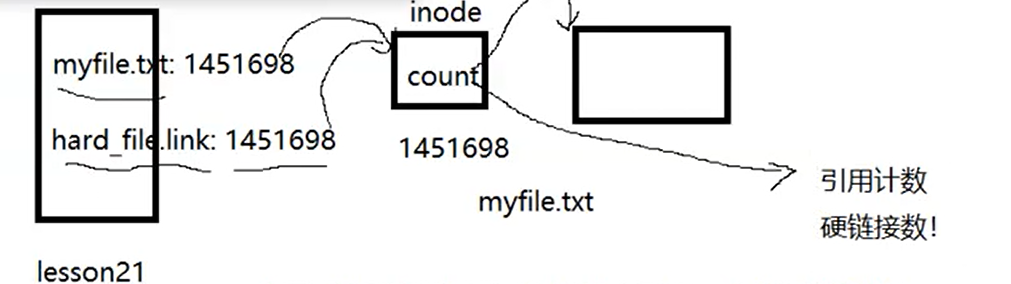
所以在上面的文件信息中我们看到的数字2表示这个inode被两个文件所指向,它的硬链接数变为2了,因为有引用计数所以什么时候一个文件被真正的删除呢?答:当一个文件的硬链接数先加载到内存中删除再加载回磁盘变成0的时候,这个文件才算真正被删除
而当我们把源文件删除时,软链接形成的文件会报红错误,说明此时软链接失效了,原因是软链接形成的独立文件是通过路径来找这个源文件的(软链接相当于我们在wind下的快捷方式),因为软链接的文件内容保存的是目标文件的路径
2.作用
软链接的作用:相当于快捷方式
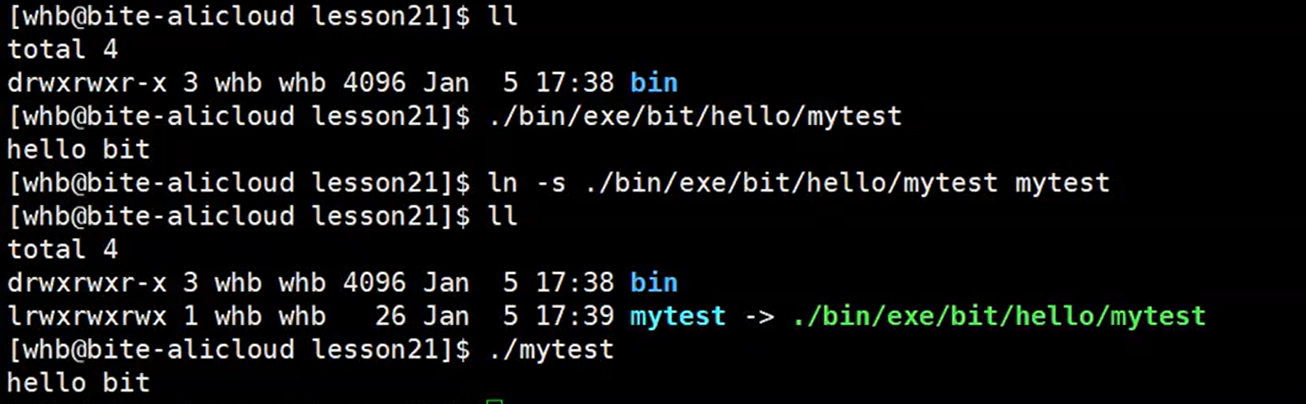
可以在任意路径下对某一路径下的可执行程序文件形成软链接,然后就可以在当前目录下如同快捷方式一样打开这个软链接就相当于打开了这个可执行程序文件
硬链接的作用:
可以对文件进行备份
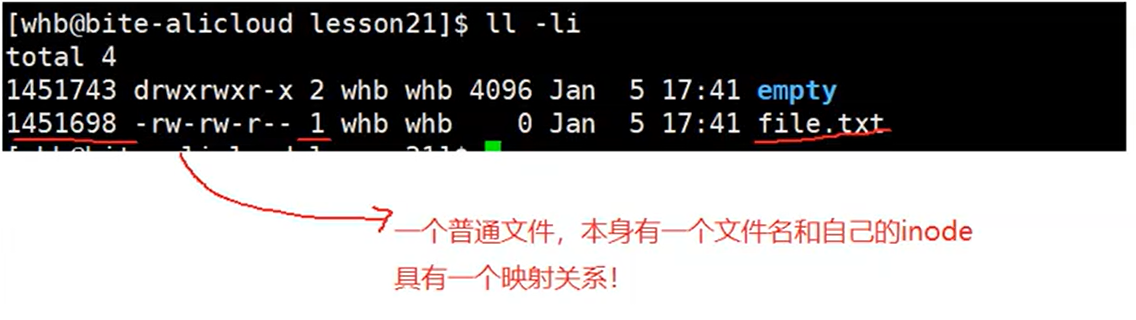
普通文件的硬链接数我们清楚了,可这个目录的硬链接数为什么一开始创建后的硬链接数就是2呢?
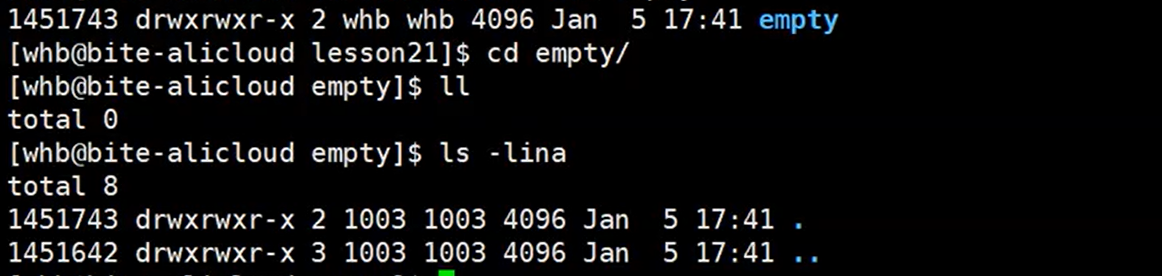
如图,因为任何一个被创建的目录一开始都会有.和..文件,而.这个文件的inode可以看到和我们的目录是一样的,也就是说它就是一个该目录的硬链接,所以硬链接数为2,而..这个文件则是上一级目录的硬链接
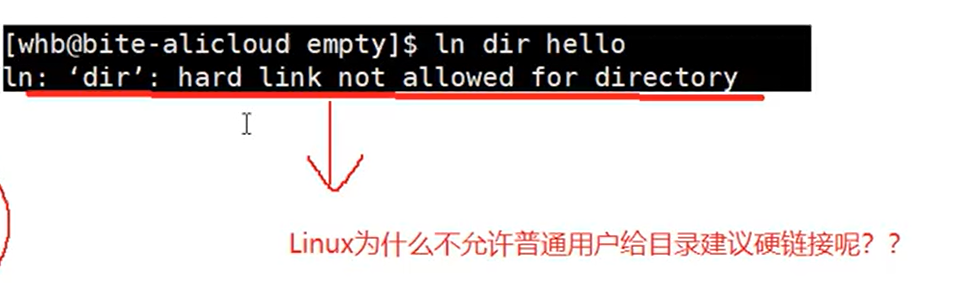
Linux 不允许普通用户给目录创建硬链接,主要基于以下考量:
-
防止循环引用与无限循环:硬链接与原文件共享 inode 号,若允许目录硬链接,可能形成目录树的环形结构(如目录指向自身或父目录)。文件系统在执行遍历、删除等操作时会陷入无限循环,导致系统崩溃或文件系统损坏。软链接虽也可能引发循环,但系统可通过检测(如连续遇到 8 个符号链接后停止遍历)规避,而硬链接因共享 inode,现行数据结构与算法难以防范此类死循环。(防止路径环问题,.和..名字特殊,做特殊处理即可,方便命令操作),软链接不也可以直接指向根目录嘛,所以软链接形成的文件是特殊类型的,可以区分
-
简化目录管理与维护:目录的 dentry 结构(包含文件名、父目录指针等)依赖父目录地址计算杂凑值。若存在目录硬链接,同一目录有多个父目录引用,会使文件系统在管理目录链接数、删除 / 重命名目录时逻辑复杂,难以准确处理 inode 的多父关系,还可能导致大量系统空间浪费(尤其目录含大量子项时)。
-
保障文件系统安全与稳定:禁止普通用户创建目录硬链接,可避免用户误操作破坏文件系统结构。虽超级用户可用
ln -d创建,但属于受控操作,普通用户无此权限,从而保护文件系统的整体稳定性。
综上,该限制是为了维护文件系统结构完整性、操作安全性及管理简便性,同时软链接等替代方案已能满足用户对目录引用的需求。
最后我们再次说明文件的三个时间:

结尾
通过本篇的学习,我们初步了解了文件系统相关的内容,并且了解了软硬链接,这些内容都是为我们下一篇深入理解动静态库做的准备!!