vanna+deepseek+chainlit 实现自然语言转SQL的精度调优
先说目前遇到的问题吧,单表数据SQL 生成准确度是可以的,但是复杂SQL以及多表联查时,生成的SQL就一言难尽了。
目前的解决方案:
一、数据训练后台
创建后台来管理三类训练数据,DDL 、SQL、DOC文档。
使用三个集合,来分别管理这三类数据

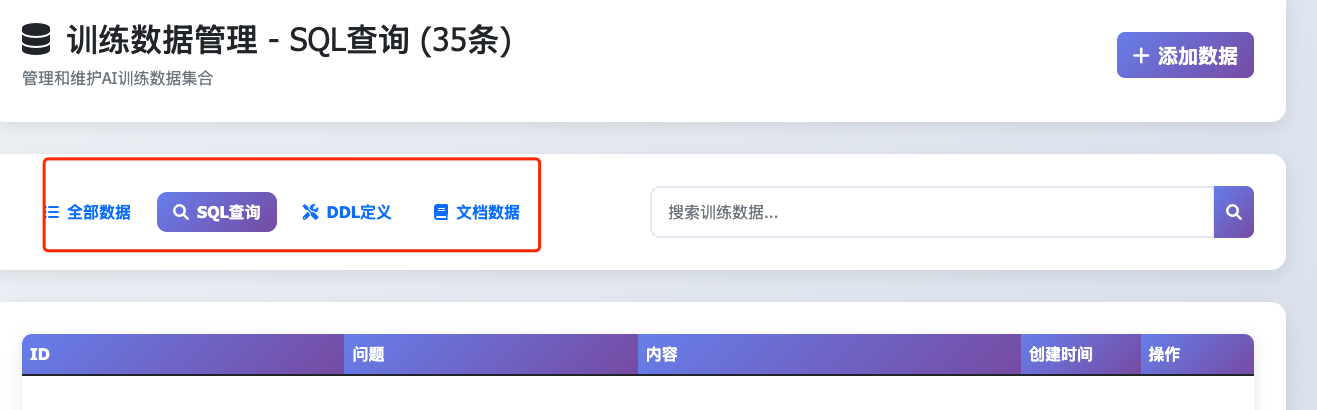
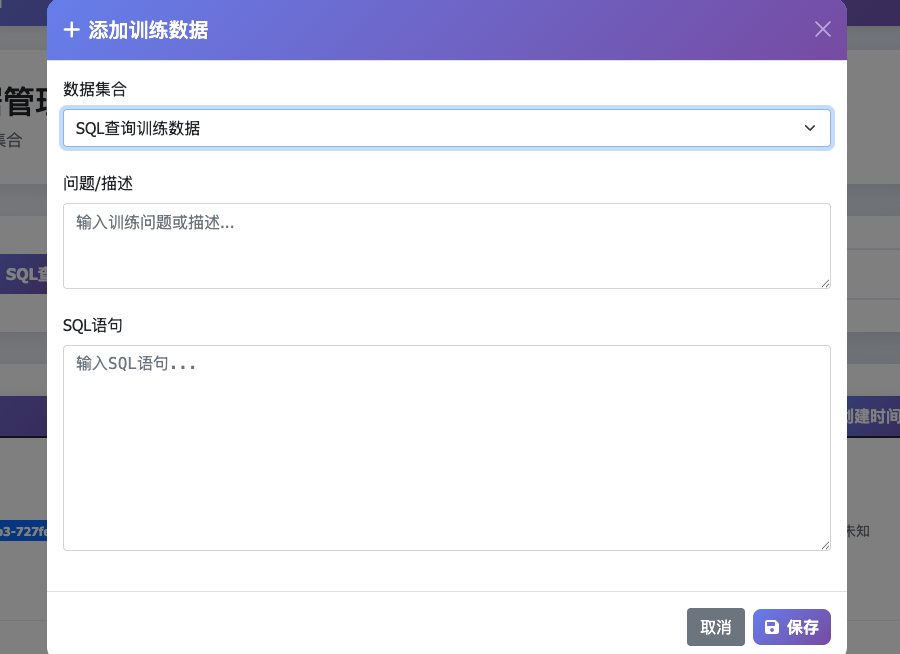
添加训练SQL:
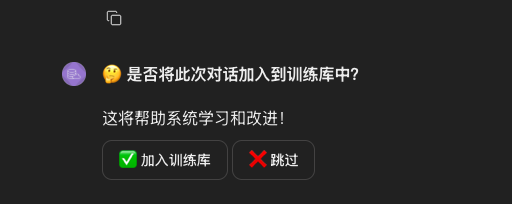
二、前端与用户交互,询问是否将本次对话加入到训练库中
前端与用户交互,询问是否将本次对话加入到训练库中,如果确认,则给用户回显当前训练库中相似度最高的前3条SQL供用户预览,然后二次确认是否需要将本次对话加入到训练库中
三、对于复杂SQL 如多表查询
对于复杂SQL 如多表查询,生产SQL,主要是基于训练的SQL生成。
用户提问,然后对于训练库数据召回。
- ≥99.5%相似度:直接使用训练库中的SQL
- 80%-99.5%相似度:基于已有SQL让大模型微调
- <80%相似度:正常生成流程(DDL+SQL+DOC交给大模型生成)
后续我会把源码放出来。。。