win10+TensorRT+OpenCV+Qt+YOLOV8模型部署教程
目录
一、部署环境说明:
二、基于yolov8在自定义数据集上进行训练
三、基于TensorRT将onnx模型转为.engine 或者.trt格式的模型
四、基于VS2019生成动态链接库配置
五、基于Qt creator调用yolov模型实现检测
一、部署环境说明:
- 系统:win10专业版
- TensorRT版本:TensorRT-8.5.2.2
- OpneCV版本:OpenCV4.7.0
- ultralytics版本:ultralytics-8.3.88
- CUDA版本:11.7
- CUDNN版本:8.6.5
- QT Creator版本:16.0.1(QT 版本为6.8.3)
二、基于yolov8在自定义数据集上进行训练
(1)图像数据制作,标签制作
通常采用labelme标注工具进行数据标注,数据保存格式选择为yolo。
(2)模型训练
- 在Github上下载ultralytics,链接:GitHub - ultralytics/ultralytics: Ultralytics YOLO11 🚀
- 使用anaconda 安装python虚拟环境。
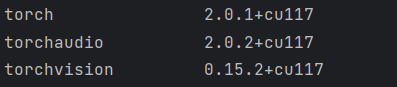
- 在python虚拟环境中安装GPU版本的torch。注意安装的时候需要VPN翻墙安装,不要使用清华源,因为清华源没有GPU版本的torch。torch环境配置如下:
4.使用pycharm 打开ultralytics工程文件,根目录下创建train,py文件,文件内容如下:
from ultralytics import YOLOif __name__ == '__main__':# Load a COCO-pretrained YOLOv8n modelmodel = YOLO("yolov8s.pt")results = model.train(data="Number.yaml", epochs=100, imgsz=640)#增加随机旋转5.训练模型的配置文件.yaml需要根据实际路径设置图像路径。
(3)模型转onnx模型
转换代码如下:
from ultralytics import YOLO# Load a YOLOv8 model
model = YOLO("D:\\ultralytics-8.3.88\\runs\detect\\train1\\weights\\best.pt")
model.export(format="onnx", opset=12, dynamic=True, imgsz=640)三、基于TensorRT将onnx模型转为.engine 或者.trt格式的模型
- 下载tensorRT,下载链接:TensorRT SDK | NVIDIA Developer
- 将下载后的文件进行解压,在系统环境中配置,如下图所示。

3.进入tensorRT的bin目录下,并将onnx模型拷贝到bin目录下
4.输入命令行代码,即可获得best.engine。
trtexec.exe --onnx=best.onnx --saveEngine=best.engine --buildOnly --minShapes=images:1x3x640x640 --optShapes=images:4x3x640x640 --maxShapes=images:8x3x640x640四、基于VS2019生成动态链接库配置
- 新建一个动态链接库的工程项目。
2.配置opencv,cuda, tenorRT的属性表
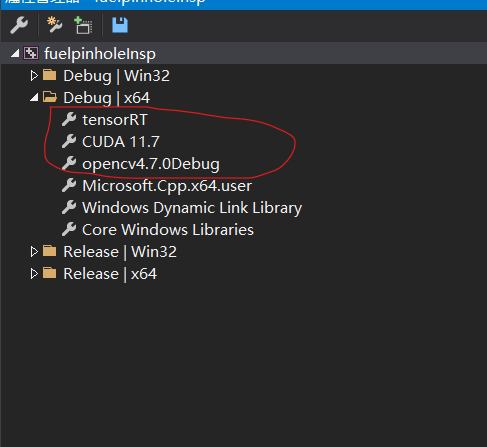
(1)TensorRT配置表如下:
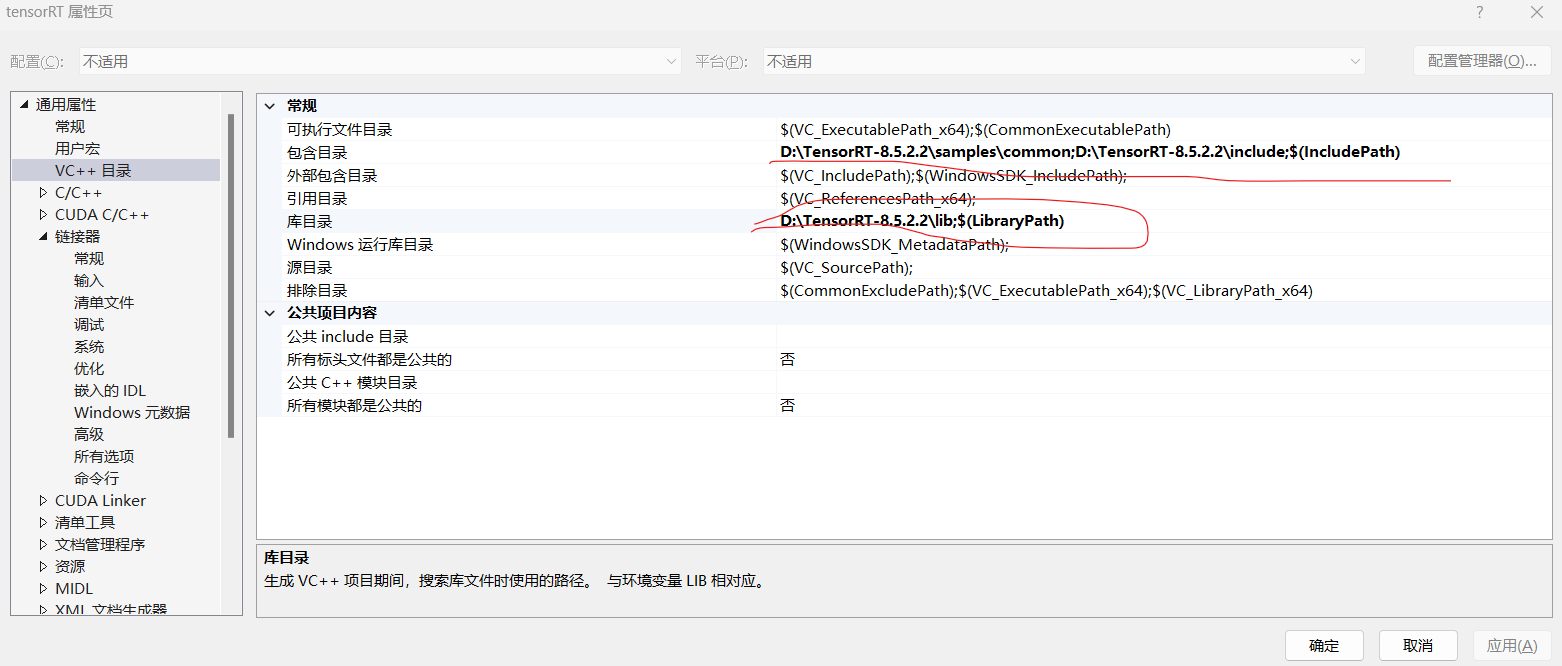
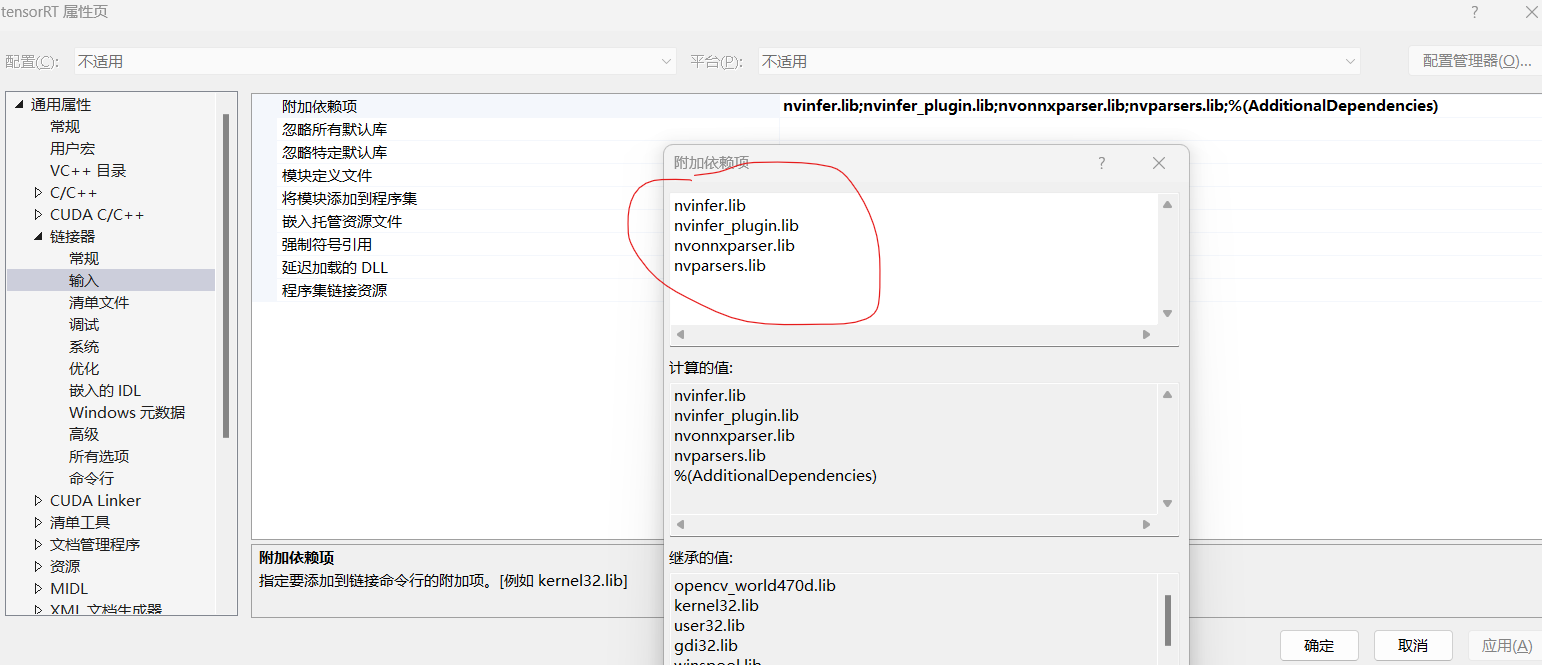
附件依赖项:
nvinfer.lib
nvinfer_plugin.lib
nvonnxparser.lib
nvparsers.lib
(2)OpenCV配置表如下:
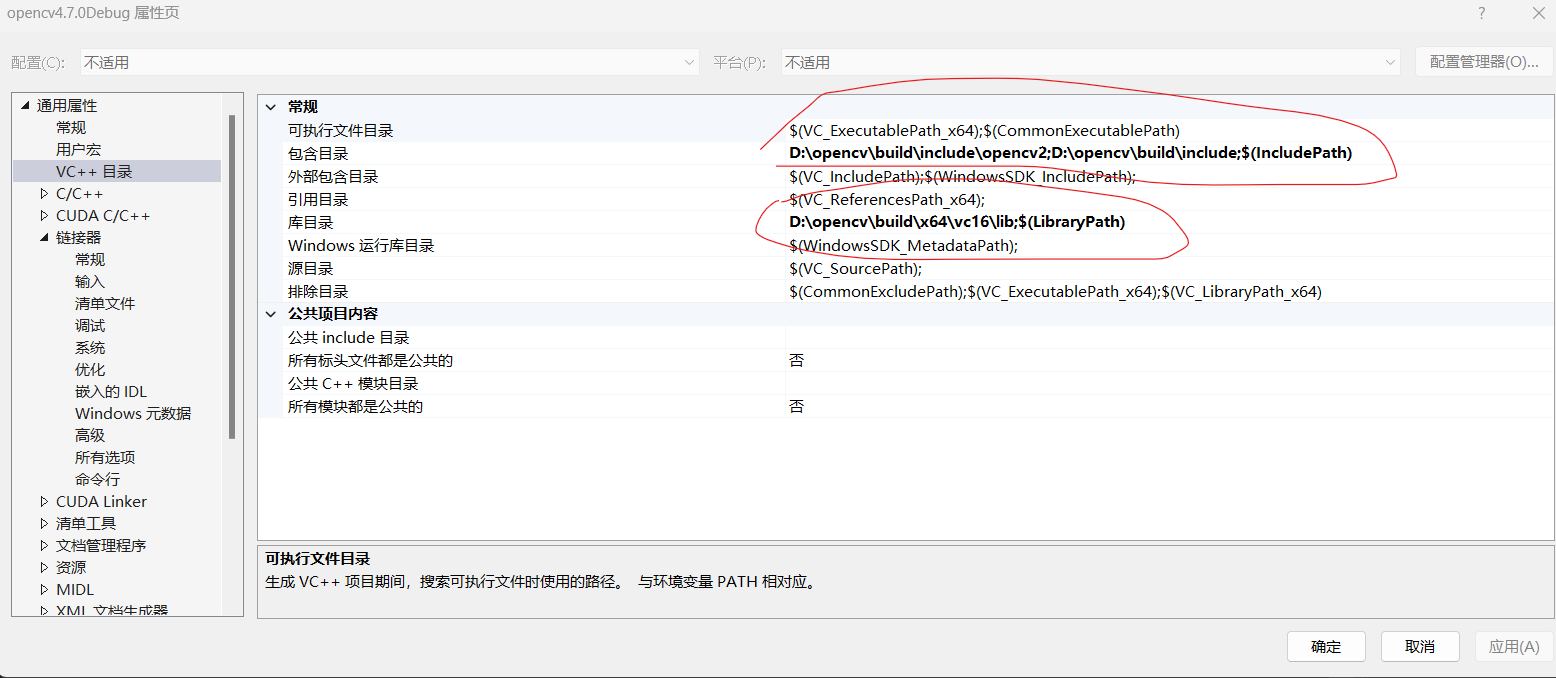
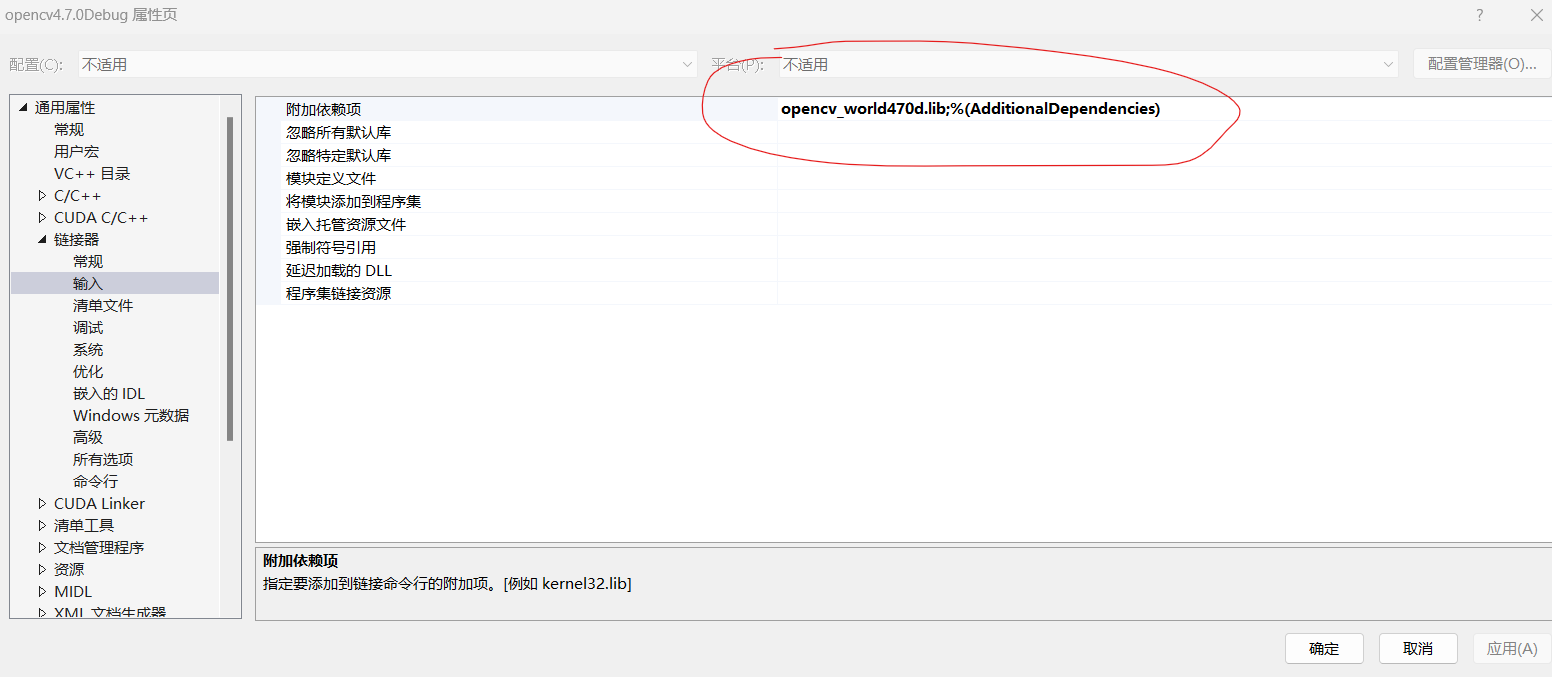
(3)CUDA配置表如下:
直接拷贝CUDA安装目录下现成的文件,一般在CUDA的默认安装地址:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\extras\visual_studio_integration\MSBuildExtensions\CUDA 11.7.props(4)解决方案文件配置
- 下载TensorRT-Alpha,下载链接:TensorRT-alpha
2.下载后解压TensorRT-Alpha
3. 按照下图进行文件配置
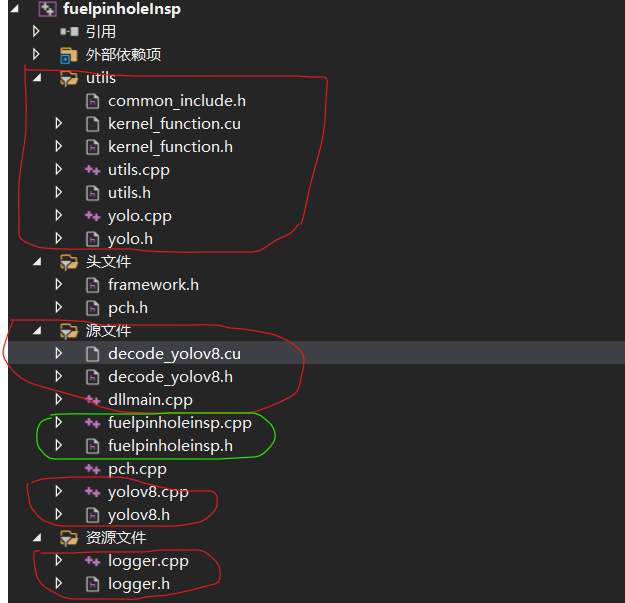
上图中红色圈中的为添加的现有文件,绿色圈的文件为新建的文件。其中utils中所有文件是从TensorRT-Alpha中直接拷贝过来,如图:
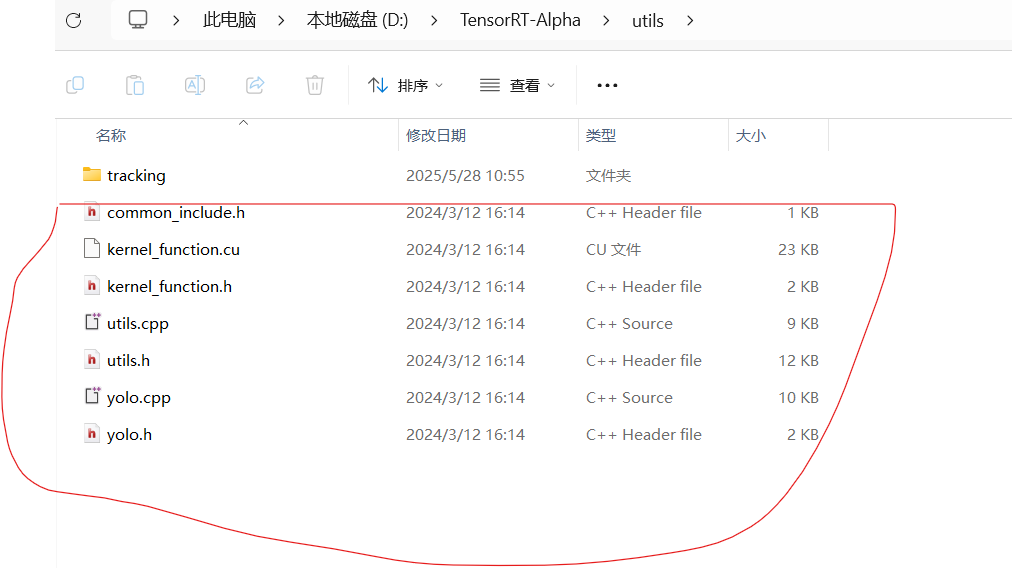
其中源文件中的红色圈中的文件为yolov8文件夹中直接拷贝,如图所示:
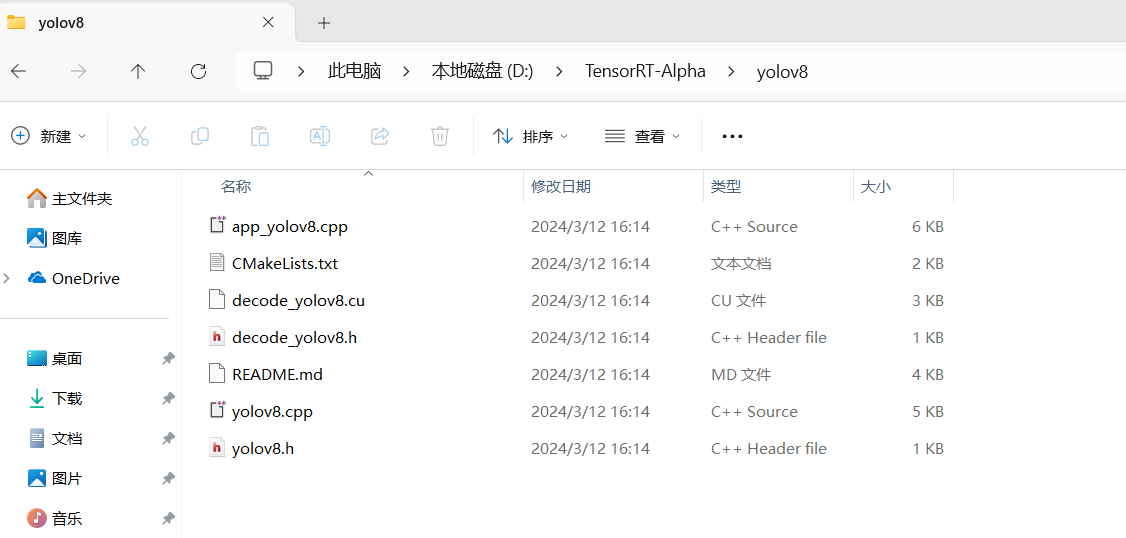
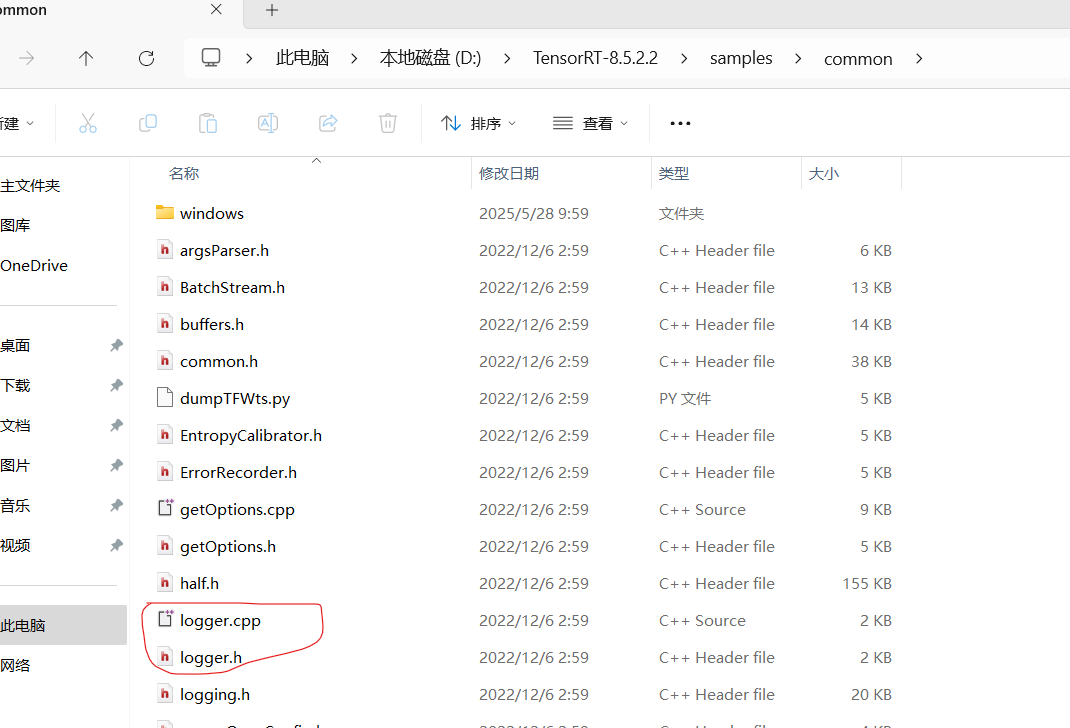
资源文件中文件为TensorRT-8.5.2.2文件夹中直接拷贝过来,如下图所示
4.源文件项中新建的fuelpinhole.h文件的内容如下:
#pragma once#define FUELPINHOLEINSP_API _declspec(dllexport)#include <iostream>#include <string>#include <vector>#include <algorithm>#include <random>#include <opencv2/opencv.hpp> //opencv header file#include <chrono>#include"../utils/yolo.h"#include"yolov8.h"// 定义输出结构体typedef struct {float prob;cv::Rect rect;int classid;}Object;enum InputType {IMAGE,VIDEO,CAMERA};int total_batches = 0;int delay_time = 1;bool is_show = false;bool is_save = false;extern "C"{utils::InitParameter param;FUELPINHOLEINSP_API YOLOV8* LoadDetectPinHoleModel(const std::string& model_path, const std::string& file_path, const int& type, const int& cameraID);FUELPINHOLEINSP_API YOLOV8* LoadDetectPinHoleModel_v1(const std::string& model_path, int src_h, int src_w);FUELPINHOLEINSP_API bool YoloDetectPinHoleInfer(const cv::Mat& src, std::vector<Object>& vecObj, YOLOV8* model,bool isShow);void _setParameters(utils::InitParameter& initParameters);void _task(YOLOV8* yolo, const utils::InitParameter& param, std::vector<cv::Mat>& imgsBatch, const int& delayTime, const int& batchi,const bool& isShow, const bool& isSave, std::vector<Object>& vecObj);}
5.源文件项中新建的fuelpinhole.cpp文件的内容如下:
#include "../pch.h"#include "fuelpinholeinsp.h"void _setParameters(utils::InitParameter& initParameters){initParameters.class_names = utils::dataSets::fuelpinhole;initParameters.num_class = 1; //!!!!initParameters.batch_size = 1;initParameters.dst_h = 640;initParameters.dst_w = 640;initParameters.input_output_names = { "images", "output0" };initParameters.conf_thresh = 0.25f;initParameters.iou_thresh = 0.45f;initParameters.save_path = "";}void _task(YOLOV8* yolo, const utils::InitParameter& param, std::vector<cv::Mat>& imgsBatch,const int& delayTime, const int& batchi, const bool& isShow, const bool& isSave, std::vector<utils::Box>& box){auto beforeTime = std::chrono::steady_clock::now();utils::DeviceTimer d_t0; yolo->copy(imgsBatch); float t0 = d_t0.getUsedTime();utils::DeviceTimer d_t1; yolo->preprocess(imgsBatch); float t1 = d_t1.getUsedTime();utils::DeviceTimer d_t2; yolo->infer(); float t2 = d_t2.getUsedTime();utils::DeviceTimer d_t3; yolo->postprocess(imgsBatch); float t3 = d_t3.getUsedTime();//sample::gLogInfo <<// //"copy time = " << t0 / param.batch_size << "; "// "preprocess time = " << t1 / param.batch_size << "; "// "infer time = " << t2 / param.batch_size << "; "// "postprocess time = " << t3 / param.batch_size << std::endl;std::vector<std::vector<utils::Box>> objectss = yolo->getObjectss();box = objectss[0];if (isShow) {utils::show(objectss, param.class_names, delayTime, imgsBatch, beforeTime);}if (isSave)utils::save(yolo->getObjectss(), param.class_names, param.save_path, imgsBatch, param.batch_size, batchi);yolo->reset();}YOLOV8* LoadDetectPinHoleModel_v1(const std::string& model_path,int src_h,int src_w){// set utils params //_setParameters(param);param.src_h = src_h;//应该是需要原始图像大小进行坐标转换param.src_w = src_w;YOLOV8* model = new YOLOV8(param);std::vector<unsigned char> trt_file = utils::loadModel(model_path);if (trt_file.empty()){sample::gLogError << "trt_file is empty!" << std::endl;return nullptr;}// init modelif (!model->init(trt_file)){sample::gLogError << "initEngine() ocur errors!" << std::endl;return nullptr;}model->check();return model;}YOLOV8* LoadDetectPinHoleModel(const std::string& model_path, const std::string& file_path, const int& type, const int& cameraID){// set utils params //_setParameters(param);// sourceutils::InputStream source;// pathstd::string video_path;std::string image_path;// camera' idint camera_id = 0;switch (type){case InputType::IMAGE:source = utils::InputStream::IMAGE;image_path = file_path;break;case InputType::VIDEO:source = utils::InputStream::VIDEO;video_path = file_path;break;case InputType::CAMERA:source = utils::InputStream::CAMERA;camera_id = 0;break;default:break;}// input paramsint delay_time = 1; // w or hint total_batches = 1;cv::VideoCapture capture, capture1;// set input paramsif (!utils::setInputStream(source, image_path, video_path,camera_id, capture, total_batches, delay_time, param)){sample::gLogError << "read the input data errors!" << std::endl;return nullptr;}// build and read modelYOLOV8* model = new YOLOV8(param);std::vector<unsigned char> trt_file = utils::loadModel(model_path);if (trt_file.empty()){sample::gLogError << "trt_file is empty!" << std::endl;return nullptr;}// init modelif (!model->init(trt_file)){sample::gLogError << "initEngine() ocur errors!" << std::endl;return nullptr;}model->check();return model;}bool YoloDetectPinHoleInfer(const cv::Mat& src, std::vector<Object>& vecObj, YOLOV8* model,bool isShow){std::vector<cv::Mat> imgs_batch;imgs_batch.reserve(param.batch_size);imgs_batch.emplace_back(src.clone());std::vector<utils::Box> box;_task(model, param, imgs_batch, delay_time, 0, isShow, is_save, box);for (auto b : box){Object tmp;tmp.classid = b.label;tmp.prob = b.confidence;int x = (int)(b.left + b.right) / 2.;int y = (int)(b.top + b.bottom) / 2.;int w = (int)(b.right - b.left);int h = (int)(b.bottom - b.top);tmp.rect = cv::Rect(x, y, w, h);vecObj.emplace_back(tmp);}return true;}6.通过utils.cpp和utils.h中可以修改模型的类别名称,类别数量,显示颜色配置
7.通过项目的生成依赖项->生成自定义 选择CUDA ,如下图所示
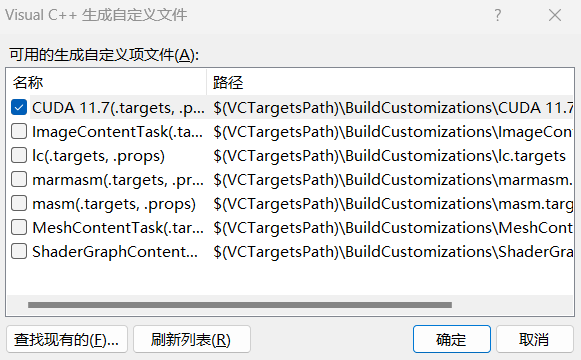
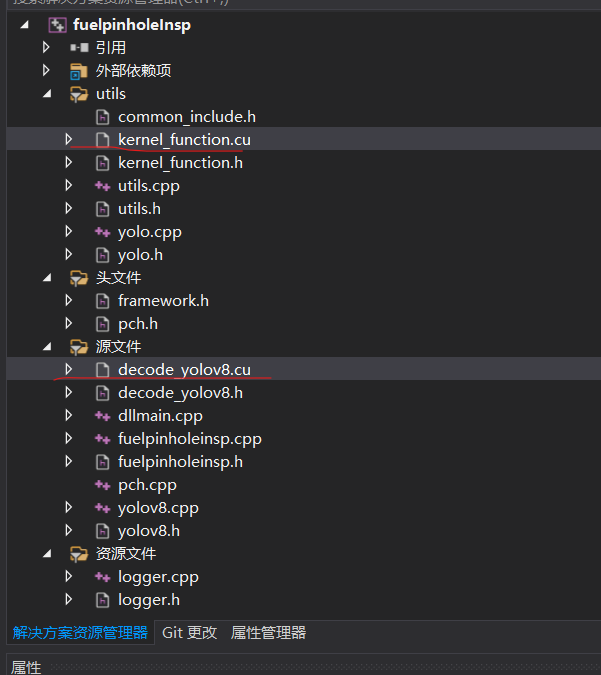
8.选择.cu文件,右键选择属性,项类型选CUDA C/C++
9.设置预编译头
10.建议禁用代码安全检查
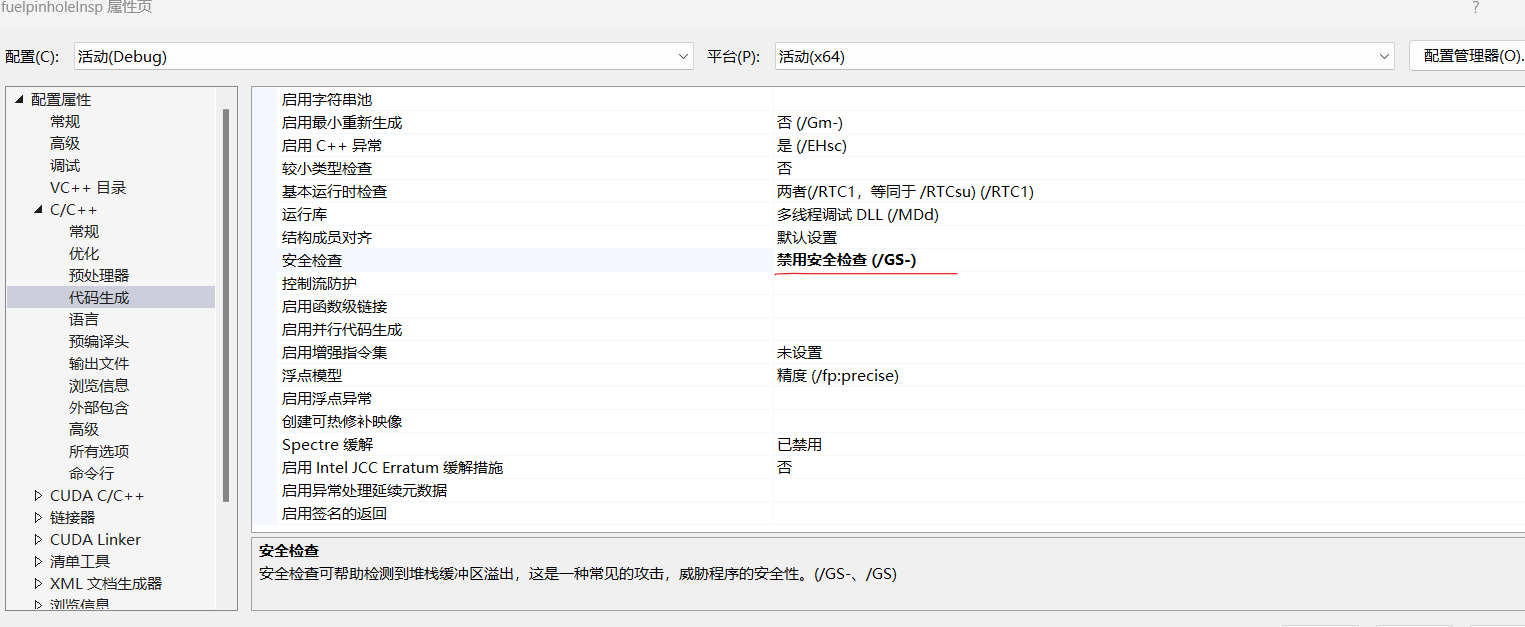
11.最后点击生成解决方案,在debug中生成dll,和lib库文件。
五、基于Qt creator调用yolov模型实现检测
(1)使用QT creator创建工程项目
(2)创建include文件夹,将动态链接库中属性表中的包含头文件(tensorRT,CUDA)的内容全部拷贝进来。创建lib库,同样将动态链接库中属性表中的库文件拷贝进来。
(3)将配置动态链接库时的添加的utils,yolo文件都拷贝到这个工程里面。
(4)将生成的.engine模型文件拷贝到qt工程目录下。
(5)配置QT的pro文件,如下:
INCLUDEPATH += D:/opencv/build/includeDEPENDPATH += D:/opencv/build/includeINCLUDEPATH += $$PWD/includeDEPENDPATH += $$PWD/includewin32:CONFIG(release, debug|release): LIBS += -LD:/opencv/build/x64/vc16/lib/ -lopencv_world470else:win32:CONFIG(debug, debug|release): LIBS += -LD:/opencv/build/x64/vc16/lib/ -lopencv_world470dLIBS += -L$$PWD/lib/ -lfuelpinholeInspLIBS += -L$$PWD/lib/ -lcudadevrtLIBS += -L$$PWD/lib/ -lcudartLIBS += -L$$PWD/lib/ -lnvinferLIBS += -L$$PWD/lib/ -lnvinfer_pluginLIBS += -L$$PWD/lib/ -lnvonnxparserLIBS += -L$$PWD/lib/ -lnvparsers(6)添加动态链接库的头文件fuelpinholeinsp.h
#pragma once#define FUELNOZZLEINSP_API _declspec(dllexport)#include <iostream>#include <string>#include <vector>#include <algorithm>#include <random>#include <opencv2/opencv.hpp> //opencv header file#include <utils/yolo.h>#include <src/yolov8.h>using namespace cv;using namespace std;// 定义输出结构体typedef struct {float prob;cv::Rect rect;int classid;}Object_nozzle;extern "C"{FUELNOZZLEINSP_API YOLOV8* LoadDetectNozzleModel(const std::string& model_path, const std::string& file_path, const int& type, const int& cameraID);FUELNOZZLEINSP_API YOLOV8* LoadDetectNozzleModel_v1(const std::string& model_path,int src_h,int src_w);FUELNOZZLEINSP_API bool YoloDetectNozzleInfer(const cv::Mat& src, std::vector<Object_nozzle>& vecObj, YOLOV8* model,bool isShow);}头文件名称不重要,重要的是头文件中的#define FUELNOZZLEINSP_API _declspec(dllexport)声明。
(7)将生成的动态链接库lib放在lib中,将dll放在exe的同目录下。
(8)编写mainwindow.h文件
在mainwindow.h中定义如下:
private:Ui::MainWindow *ui;YOLOV8* model_pinhole;(9)在mainwindow.cpp中添加代码
//初始化模型,图像大小
string eName_Detect_pinhole =”d:\\best.engine”;model_pinhole = LoadDetectPinHoleModel_v1(eName_Detect_pinhole,975,892);//指定输入图像的大小,h,w,注意设置的图像大小,和用来测试的图像大小必须保持一致。//调用模型进行识别vector<Object_pinhole> vecObj = {};cv::Mat frame = cv::imread("D:\\data\\test.png");bool InferDetectflag = YoloDetectPinHoleInfer(frame, vecObj, model_pinhole,true);
//最后一个标志位可设置是否显示弹窗画面(10)qmake编译,后运行程序,即可看到弹出的识别结果。注意初始化设置的图像大小,和用来测试的图像大小必须保持一致。
参考链接如下:
YOLOV8+TensorRT8.6.1.6+Win10+QT5.9.9推理部署(打包为dll)_yolov8的tensorrt推理封装为dll-CSDN博客
部署实战 | 手把手教你在Windows下用TensorRT部署YOLOv8_yolov8 tensorrt部署-CSDN博客