传统的将自然语言转化为嵌入向量的核心机制是:,将离散的语言符号转化为连续的语义向量,其核心依赖“上下文决定语义”的假设和神经网络的特征提取能力。
传统的将自然语言转化为嵌入向量的核心机制是:,将离散的语言符号转化为连续的语义向量,其核心依赖“上下文决定语义”的假设和神经网络的特征提取能力。
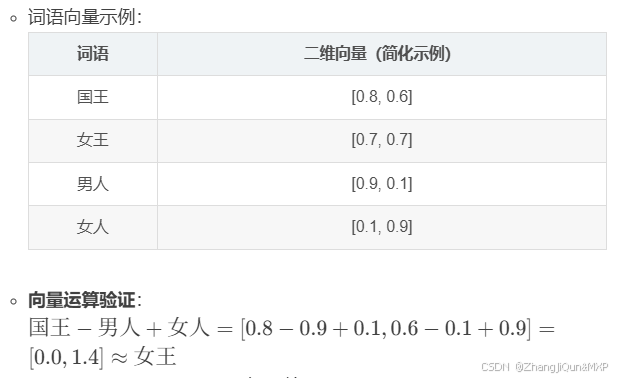
传统的将自然语言转化为嵌入向量(Word Embedding)的核心机制是分布式语义假设(Distributional Semantics Hypothesis),即“上下文相似的词,语义也相似”。其原理是通过神经网络或统计方法,将词语映射到低维连续向量空间,使语义关联的词在向量空间中距离相近。以下是具体机制、原理及示例:
一、核心机制与原理
1. 分布式表示(Distributional Representation)
- 核心思想:词语的语义由其周围的上下文决定。例如,“国王”和“女王”可能共享类似的上下文(如“统治”“国家”),因此它们的嵌入向量在空