DFORMER: RETHINKING RGBD REPRESENTATION LEARNING FOR SEMANTIC SEGMENTATION 论文浅析
文章目录
- 概要
- 文章研究思路
- 整体架构流程
- 主要组成部分
- RGB-D预训练
- 分层编码器
- 全局感知注意力GAA
- 局部增强注意力LEA
- 特定任务解码器
- 实验部分
- 预训练对比
- RGB-D语义分割
- 数据集和实施细节
- 对比实验结果
- 显著性检测
- 数据集和实施细节
- 对比实验结果
概要
本文提出了 DFormer,这是一种新颖的 RGB-D 预训练框架,用于学习 RGB-D 分割任务的可转移表示。 DFormer 有两项新的关键创新:
1) 与以前使用 RGB 预训练主干对 RGB-D 信息进行编码的工作不同,我们使用来自 ImageNet-1K 的图像深度对对主干进行预训练,因此 DFormer 被赋予了编码 RGB-D 表示的能力;
2) DFormer 由一系列 RGB-D 块组成,这些块通过新颖的构建块设计为编码 RGB 和深度信息而量身定制。 DFormer 避免了 RGB 预训练主干在深度图中对 3D 几何关系的不匹配编码,这在现有方法中广泛存在,但尚未得到解决。
我们使用轻量级解码器头在两个流行的 RGB-D 任务上微调预训练的 DFormer,即 RGB-D 语义分割和 RGB-D 突出目标检测。 实验结果表明,我们的 DFormer 在这两个任务上实现了最先进的性能,而计算成本不到当前最佳方法在 2 个 RGB-D 语义分割数据集和 5 个 RGB-D 显著目标检测数据集上的一半。
(1)论文地址:https://arxiv.org/pdf/2309.09668
(2)Github代码:https://github.com/VCIP-RGBD/DFormer
文章研究思路
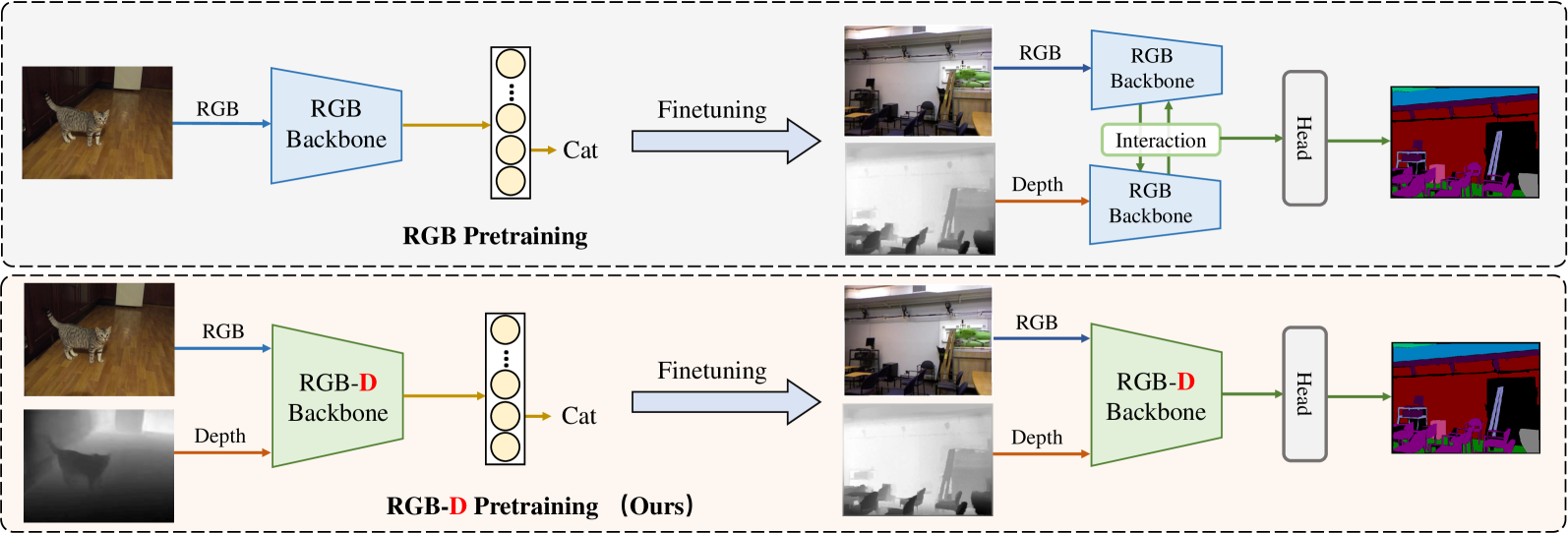
图1(顶部)显示了当前主流 RGB-D 方法, 可以观察到,RGB 图像和深度图的特征分别从两个单独的 RGB 预训练主干中提取,并在每个阶段进行融合,这种方法存在3个问题:
- RGB-D 任务中的 backbone 将图像深度对作为输入, 这与 RGB 预训练中只输入图像不一致, 模型在训练时面临巨大的数据分布差异,导致输入数据在模型训练过程中反映的信息的广泛程度和代表性分布变化;
- 在微调过程中,RGB 分支和深度分支之间密集地执行交互,这可能会破坏预训练 RGB 主干内的表示分布;
- 与标准 RGB 方法相比,RGB-D 网络中的双主干带来了更多的计算成本,而标准 RGB 方法效率不高。
本文认为,导致这些问题的一个重要原因是预训练方式: 在预训练期间需要考虑深度信息。图1(底部)是RGB-D 预训练,我们以RGB-图像深度影像对作为输入,并在编码器构建RGB和深度特征之间的交互,以避免预训练和微调输入不一致的影响;此外,我们观察到深度信息只需要部分通道进行编码,因此微调中图像深度对采用统一训练backbone。本文的贡献包括:
- 提出了一种新颖的 RGB-D 预训练框架,称为 DFormer, 采用一种新的交互方法,将 RGB 和深度特征融合在一起,为 RGB-D 下游任务提供可转移的表示;
- 在本文框架DFormer中,图像深度对统一训练主干,使用一部分通道编码深度信息,这是减少模型大小的有效方式;
- DFormer 在两个 RGB-D 分割数据集和五个 RGB-D 显著目标检测数据集上的计算成本不到当前最佳方法的一半,实现了新的最先进的性能。
整体架构流程
图2是DFormer 的整体架构,它遵循流行的编码器-解码器框架:分层编码器旨在生成高分辨率的粗略特征和低分辨率的精细特征,并采用轻量级解码器将这些视觉特征转换为特定于任务的预测。
给定一个 RGB 图像和相应的深度图,它们首先由两个平行的词干层分别处理,该词干层由两个内核大小3×3和步幅 2的卷积组成。 然后,将 RGB 特征和深度特征馈送到分层编码器中,以编码多尺度特征在{1/4,1/8,1/16,1/32}的原始图像分辨率。 接下来,我们使用 ImageNet-1K 的图像深度对和分割目标来预训练这个编码器,以生成可转移的 RGB-D 表示。 最后,我们将视觉特征从预训练的 RGB-D 编码器发送到解码器以产生与输入图像尺度一致的逐像素预测。

主要组成部分
RGB-D预训练
RGB-D 预训练的目的是赋予主干实现 RGB 和深度模态之间的交互的能力,并生成具有丰富语义和空间信息的可转移表示。 为此,我们首先应用一个深度估计器,例如 Adabin(Bhat 等人,2021)在 ImageNet-1K 数据集上(Russakovsky 等人,2015)生成大量图像深度对。 然后,我们在 RGB-D 编码器的顶部添加一个分类器头,以构建用于预训练的分类网络。 特别是,来自最后一个阶段的 RGB 特征沿空间维度展平并馈送到分类器头中。 标准交叉熵损失被用作我们的优化目标,并且网络在 RGB-D 数据上进行了 300 个 epoch 的预训练,就像 ConvNext 一样(Liu 等人,2022). 沿用前作(Liu 等人,2022;Guo et al.,2022b)、AdamW(洛什奇洛夫和胡特尔,2019)学习率为 1E-3 且权重衰减为 5E-2 作为我们的优化器,批量大小设置为 1024。 文章附录中描述了 DFormer 的每个变体的更具体设置。
分层编码器
该构建模块主要由全局感知注意力(GAA)模块和局部增强注意力(LEA)模块组成,并建立了RGB和深度模态之间的交互。GAA模块融合了深度信息,旨在从全局视角增强物体定位的能力,而LEA模块采用大核卷积来捕捉来自深度特征的局部线索,从而细化RGB表示的细节。交互模块的详细信息如下图所示。
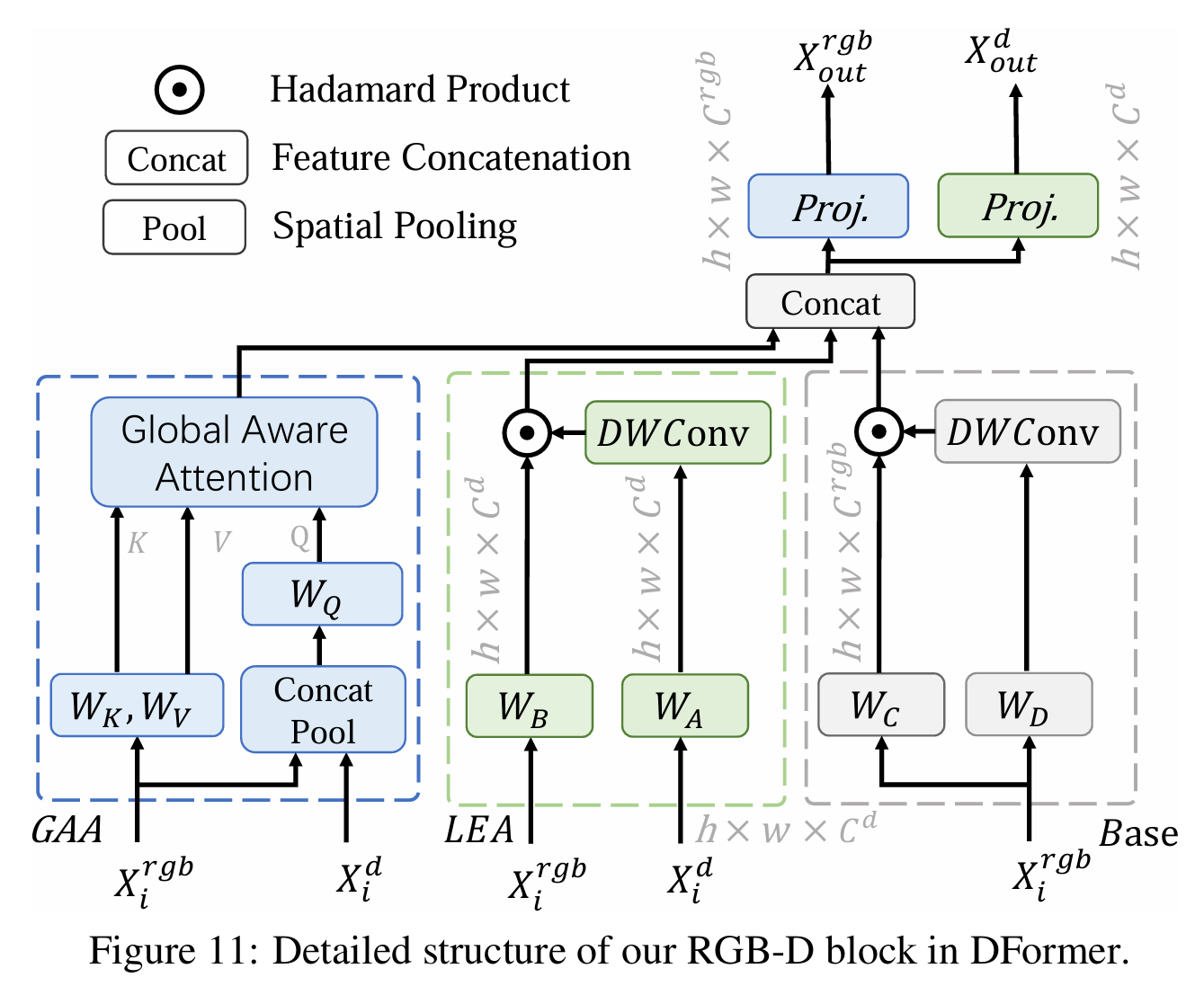
全局感知注意力GAA
我们的GAA通过融合深度和RGB特征,在整个场景中建立关系,增强了3D感知,并进一步帮助捕捉语义物体。与引入像素或令牌增加时会导致二次计算增长的自注意力机制(Vaswani等,2017)不同,GAA中的查询(Q)被下采样到固定大小,因此可以减少计算复杂度。表8表明,融合深度特征与Q是足够的,无需将其与K或V结合,这会增加计算量,但并不会提高性能。因此,Q来自于RGB特征和深度特征的连接,而键(K)和值(V)则从RGB特征中提取。GAA及下文LEA的核心实现在DFormer-main\models\encoders\DFormer.py\attention类中。
class attention(nn.Module):def __init__(self, dim, num_head=8, window=7, norm_cfg=dict(type="SyncBN", requires_grad=True), drop_depth=False):super().__init__()# ... [初始化代码] ...if window != 0:self.short_cut_linear = nn.Linear(dim // 2 * 3, dim // 2)self.kv = nn.Linear(dim, dim)self.pool = nn.AdaptiveAvgPool2d(output_size=(7, 7)) # 自适应池化下采样# ... [其他初始化] ...def forward(self, x, x_e):# ... [前置代码] ...if self.window != 0:# GAA核心实现开始short_cut = torch.cat([x, x_e], dim=3) # RGB和深度特征拼接 [X_rgb, X_d]short_cut = short_cut.permute(0, 3, 1, 2) # 池化下采样 (Pool_{k×k})short_cut = self.pool(short_cut).permute(0, 2, 3, 1)# 线性变换生成Qshort_cut = self.short_cut_linear(short_cut) # K和V仅从RGB特征提取b = x.permute(0, 2, 3, 1)kv = self.kv(b) # 线性变换得到K和V# 注意力计算kv = kv.reshape(B, H * W, 2, self.num_head, C // self.num_head // 2).permute(2, 0, 3, 1, 4)k, v = kv.unbind(0)short_cut = short_cut.reshape(B, -1, self.num_head, C // self.num_head // 2).permute(0, 2, 1, 3)m = short_cutattn = (m * (C // self.num_head // 2) ** -0.5) @ k.transpose(-2, -1)attn = attn.softmax(dim=-1)attn = ((attn @ v).reshape(B, self.num_head, self.window, self.window, C // self.num_head // 2).permute(0, 1, 4, 2, 3).reshape(B, C // 2, self.window, self.window))# 上采样操作 (UP(·))attn = F.interpolate(attn, (H, W), mode="bilinear", align_corners=False).permute(0, 2, 3, 1)# GAA核心实现结束# ... [后置代码] ...
局部增强注意力LEA
我们还设计了 LEA 模块来捕获更多的局部细节,这可以看作是对 GAA 模块的补充。 与之前大多数使用加法和串联来融合 RGB 特征和深度特征的作品不同。 我们对深度特征进行深度卷积,使用一个大内核,并将生成的特征用作注意力权重,通过一个简单的 Hadamard 产品重新权衡 RGB 特征,其灵感来自(Hou 等人,2022). 这是合理的,因为具有相似深度值的相邻像素通常属于同一对象,因此 3D 几何信息可以很容易地嵌入到 RGB 特征中。 LEA的计算过程可以定义为:

class attention(nn.Module):def __init__(self, dim, num_head=8, window=7, norm_cfg=dict(type="SyncBN", requires_grad=True), drop_depth=False):super().__init__()# ... [初始化代码] ...# LEA专用层self.e_conv = nn.Conv2d(dim // 2, dim // 2, 7, padding=3, groups=dim // 2) # 深度卷积self.e_fore = nn.Linear(dim // 2, dim // 2) # 线性变换self.e_back = nn.Linear(dim // 2, dim // 2) # 线性变换# ... [其他初始化] ...def forward(self, x, x_e):# ... [前置代码] ...# LEA核心实现# 深度特征处理: DConv_{k×k}(Linear(X_d))x_e_transformed = self.e_back(self.e_conv(self.e_fore(x_e).permute(0, 3, 1, 2) # 线性变换).permute(0, 2, 3, 1) # 深度卷积)# Hadamard乘积: ⊙ Linear(X_rgb)cutted_x = self.q_cut(x) # RGB特征线性变换lea_output = cutted_x * x_e_transformed # Hadamard乘积# LEA核心实现结束# ... [后置代码] ...
特定任务解码器
对于我们的 DFormer 到下游任务的应用,我们只需要在预训练的 RGBD 主干之上添加一个轻量级解码器,以构建特定于任务的网络。 在相应的基准数据集上进行微调后,特定于任务的网络能够生成出色的预测,而无需使用融合模块等额外设计。
以RGB-D语义分割为例,参考SegNext(Guo等,2022a),我们采用了一种轻量级的分割头(Hamburger head)(Geng等,2021)来聚合我们预训练编码器最后三个阶段的多尺度RGB特征。需要注意的是,我们的解码器仅使用X_rgb特征,而其他方法(Zhang等,2023a;Wang等,2022;Zhang等,2023b)通常设计模块,将两种模态特征X_rgb和X_d融合用于最终预测。我们的实验将表明,由于我们强大的RGB-D预训练编码器,X_rgb特征能够有效地从深度模态中提取3D几何线索。因此,传递深度特征X_d到解码器并非必要。
实验部分
预训练对比
使用在不同类型训练数据上预训练的骨干网络对深度图进行编码。(a) 使用RGB数据进行预训练。(b) 使用深度图进行预训练。在微调过程中,我们仅使用深度图作为输入,以观察哪种骨干网络效果更好。我们在底部可视化了来自两个骨干网络的一些特征。显然,使用深度图进行预训练的骨干网络能够生成更具表现力的特征图。

RGB-D语义分割
数据集和实施细节
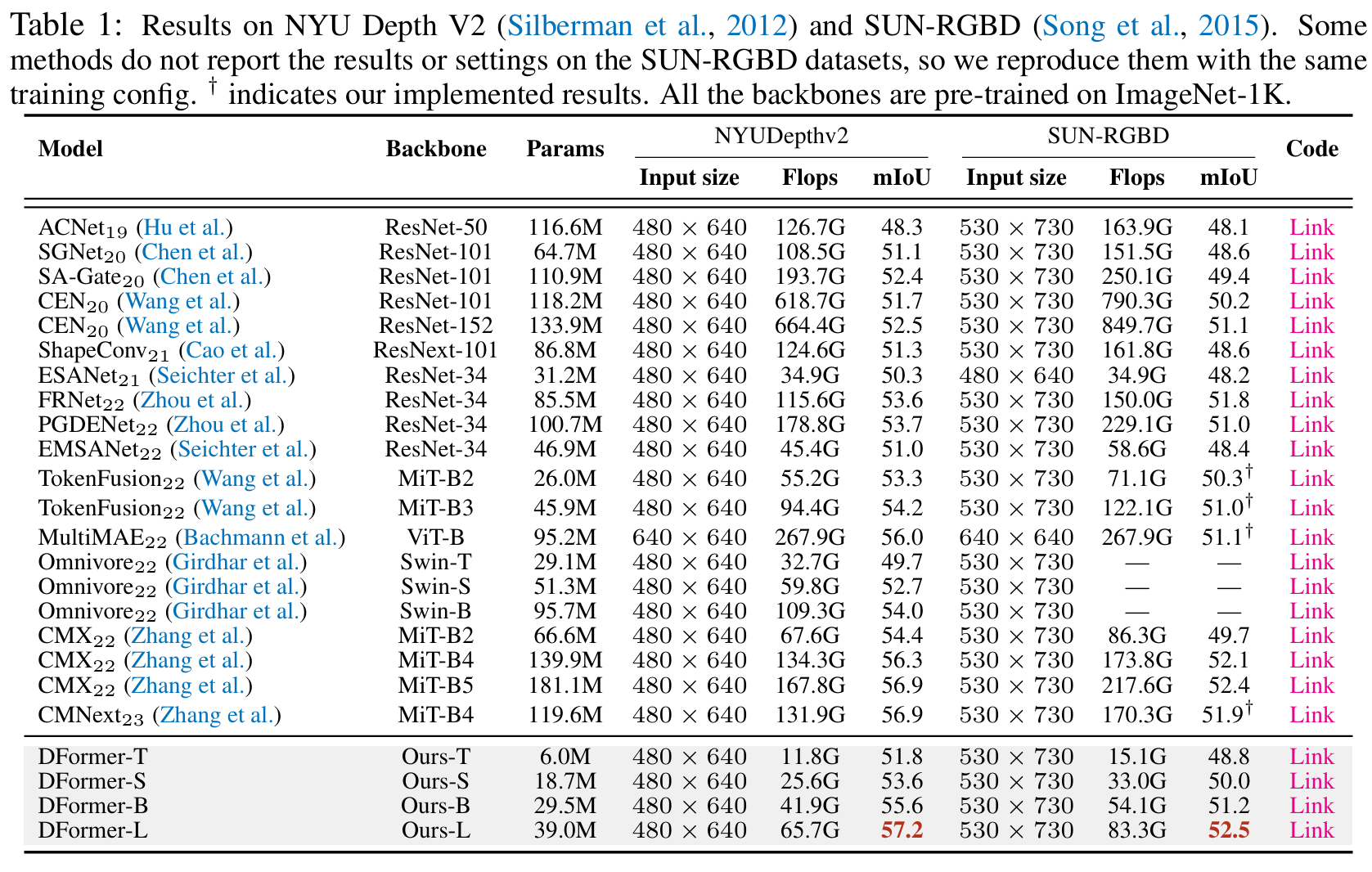
遵循 RGB-D 语义分割方法的常用实验设置(Xie 等人,2021;Guo et al.,2022 年a),我们在两个广泛使用的数据集: NYUDepthv2(Silberman 等人,2012)和 SUN-RGBD(Song 等人,2015)上微调和评估 DFormer. 关注 SegNext,我们使用 一个轻量级的头部Hamburger(Geng 等人,2021),作为解码器来构建我们的 RGB-D 语义分割网络。 在微调过程中,我们只采用两种常见的数据增强策略,即随机水平翻转和随机缩放(从 0.5 到 1.75)。 训练图像将被裁剪并调整为480×640和480×480分别用于 NYU Depthv2 和 SUN-RGBD 基准测试。交叉熵损失被用作优化目标。 我们使用 AdamW(Kingma & Ba,2015)作为我们的优化器,初始学习率为 6E-5 和 Poly Decay 时间表。 权重衰减设置为 1e-2。 在测试过程中,我们采用平均交并比 (mIoU) 作为衡量分割性能的主要评估指标,该指标是跨语义类别的平均。 基于最近的工作(Zhang 等人,2023 年一;Wang et al.,2022;Zhang et al.,2023b),我们采用具有 scale 的多尺度 (MS) 翻转推理策略{0.5,0.75,1,1.25,1.5}.
对比实验结果
所有 backbone 都在 ImageNet-1K 上进行了预训练, 如表 1 所示,与其他方法相比,DFormer 实现了更好的性能和计算权衡。 特别是,DFormer-L 在 39.0M 参数和 65.7G Flops 下产生 57.2% 的 mIoU,而最近最好的 RGB-D 语义分割方法,即 CMX (MiT-B2),使用 66.6M 参数和 67.6G Flops 时仅达到 54.4% mIoU。 值得注意的是,我们的 DFormer-B 可以在一半参数(29.5M、41.9G vs 66.6M、67.6G)的情况下比 CMX (MIT-B2) 高出 1.2% mIoU。 此外,我们的 DFormer 和 CMNext 的语义分割结果之间的定性比较(Zhang 等人,2023b)在图 .附录 14 进一步证明了我们方法的优势。 此外,SUN-RGBD 上的实验(Song 等人,2015)与其他方法相比,我们的 DFormer 也具有类似的优势。 这些持续的改进表明,我们的 RGB-D 主干可以更有效地在 RGB 和深度特征之间建立交互,从而以更低的计算成本产生更好的性能。
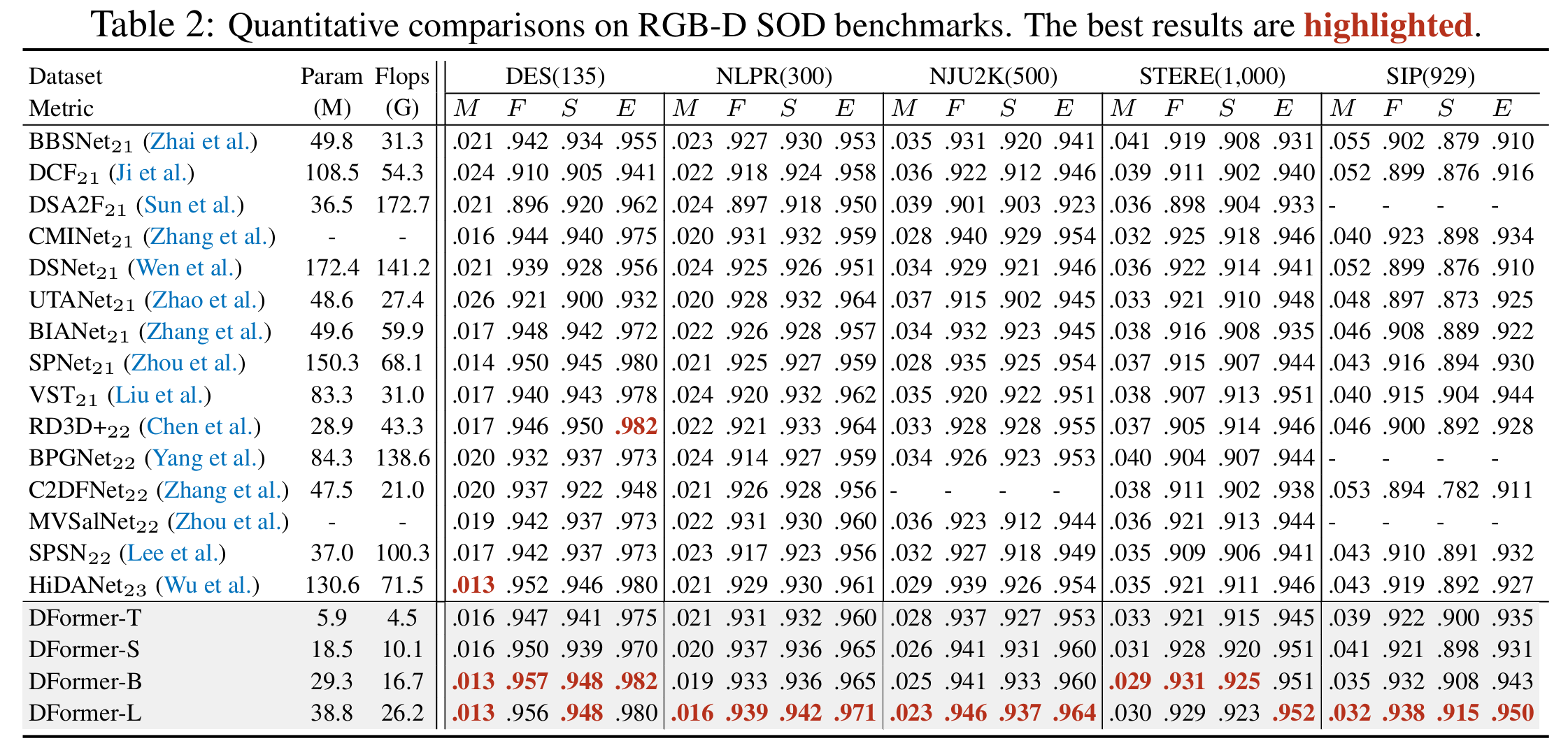
显著性检测
数据集和实施细节
我们在五个流行的 RGB-D 显著对象检测数据集上微调和测试了 DFormer。 微调数据集由 2,195 个样本组成,其中 1,485 个样本来自 NJU2K-train(Ju 等人,2014)其他 700 个样本来自 NLPR 训练(Peng 等人,2014). 该模型在五个数据集上进行评估,即 DES(Cheng 等人,2014)(135),NLPR-test (Peng 等人,2014)(300),NJU2K-test (Ju 等人,2014)(500),STERE(Niu 等人,2012)(1,000) 和 SIP(Fan 等人,2020)(929). 对于绩效评估,我们采用了这项任务的四个黄金指标,即结构度量 (S)(Fan 等人,2017)、平均绝对误差 (M)(Perazzi 等人,2012)、最大 F 度量 (F)(Margolin 等人,2014)和最大 E 测量值 (E)(Fan 等人,2018).
对比实验结果
我们将 DFormer 与 5 个常用测试数据集上的 11 种最近的 RGB-D 显著目标检测方法进行了比较。 如表 2 所示,我们的 DFormer 能够以最小的计算成本超越所有竞争对手。 更重要的是,我们的 DFormer-T 产生的性能与最近最先进的方法 SPNet 相当(周 et al.,2021 年a)计算成本不到 10%(5.9M、4.5G 与 150.3M、68.1G)。 这一显著的改进进一步证明了 DFormer 的强大性能。