【AI学习】KV-cache和page attention
目录
带着问题学AI
KV-cache
KV-cache是什么?
之前每个token生成的K V矩阵给缓存起来有什么用?
为啥缓存K、V,没有缓存Q?
KV-cache为啥在训练阶段不需要,只在推理阶段需要?
KV cache的过程图解
阶段一:KV cache的prefill阶段
阶段二:KV cache的decode阶段
prefill阶段,K V是一把计算得到吗?
decode阶段,K V是一把计算得到吗?
KV cache的内存问题?
瓶颈分析
page attention
传统KV cache浪费显存的原因有哪些?
vLLM是什么?是解决什么问题的?
page attention是怎么解决内存利用率低的问题的?
什么是虚拟内存?
page attention的改进1:利用虚拟内存和页管理,将利用率从20-40%提升到90%
page attention的改进2:利用sharing KV blocks(共享block), 减少内存占用。
还能优化beam search里的显存占用?
附录
带着问题学AI
今天来学习下transform模型中一个推理加速的算法--page attention。
一、KV-cache
KV-cache是什么?
是在推理阶段,decode为了节省计算量,将每个token在transform时乘以Wk,Wv这俩参数矩阵的结果(K、V)缓存下来。
如果每生成一个token,都要将之前所有的token去乘以Wk,Wv这俩参数矩阵,计算代价非常大。所有缓存起来就叫KV-Cache.
之前每个token生成的K V矩阵给缓存起来有什么用?
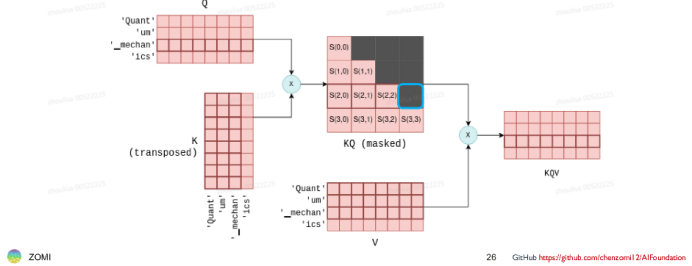
试想如果每次都不存,后边每生成一个token,根据attention公式,需要计算attention值要将Q乘以K的转置,每增加一个token,X多一行,则Q多一行,K多一行,V多一行。但其实第0到n-1行的K、V是不变的。没有必要每次都重新计算整个K、V矩阵(乘以Wk,Wv)。如果有缓存,直接将第0到n-1行拿来用即可,省去了重新全部计算的过程。--减少计算,以空间换时间
为啥缓存K、V,没有缓存Q?
根据attention计算公式,生成第n个token,都依赖Q的第n个向量和K\V前n个向量(即之前的所有KV)。即第n个token的生成,和Q之前的n个向量无关。所以不需要缓存Q。
下图是生成第3个token(_machan)的过程:
KV-cache为啥在训练阶段不需要,只在推理阶段需要?
因为训练阶段,Wk,Wv这些参数的值是要根据迭代不断变化的。缓存起来没有用,下次就变了。但是推理阶段,Wk,Wv这些参数的值已经是确定了的,不会变化。
KV cache的过程图解
阶段一:KV cache的prefill阶段
把整段 prompt 输入模型执行,采用 KV cache 技术,Prefill阶段中会把prompt的token计算得到的K\V保存在cache K和cache V中。这样后面的token计算attention时,就不需要对前面 token 重复计算,可以节省推理时间。
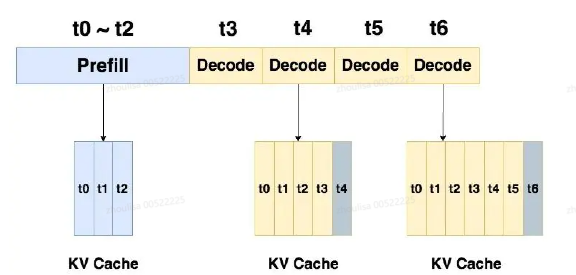
假设 prompt 中含有 3 个 token,prefill 阶段结束后,这三个 token 相关的 KV 值都被装进了cache。即计算输入的所有token的KV,缓存起来
阶段二:KV cache的decode阶段
Decode 阶段根据 prompt 的 prefill 结果,一个 token 一个 token 地生成 response;
采用 KV cache 每一个 decode 把对应 response的 token KV 值存入 cache 中,能加速计算,节省后续token的K\V计算量;
t4 与 cache 中 t0~t3 的 KV 值计算完 attention 后,就把自己的 KV 值也装进 cache 中。
prefill阶段,K V是一把计算得到吗?
prefill阶段是计算prompt的token的attention,可以一把计算,K=X*Wk, 这里X是所有prompt的token,Wk是已经确定的参数矩阵。所以可以一把计算出K,这就对算力要求比较高。矩阵V同理。
decode阶段,K V是一把计算得到吗?
不行。decode阶段,因为下一个token的生成依赖下一个Q的向量和之前所有的KV向量,每次都得一个token一个token的计算。所以是只能串行计算,所以有计算瓶颈。所以才有KV cache算法,用空间换时间,节约计算。
KV cache的内存问题?
从上述过程中,可以发现 KV cache 推理时特点:
1. 随着推理序列变长,KV cache 也变大,对 GPU 显存造成压力
2. 由于输出的序列长度无法预先知道,所以很难提前为 KV cache 量身定制存储空间。
显存会有大量的碎片页,导致内存资源浪费。为了解决KV cache的内存bound问题,提出了一些算法。
瓶颈分析
LLM 推理 Prefill & Decoding 阶段 Roofline Model 近似如下,其中:
1. 三角Prefill(计算密集型):设Batch size=1,Sequence Length越大计算强度越大,通常属于Compute Bound
2. 原型Decoding:Batch size越大,计算强度越大,理论性能峰值越大,通常属于Memory Bound
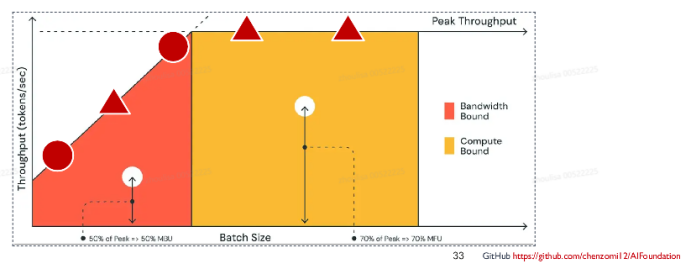
备注:Roofline模型是一种用于理解和分析高性能计算(HPC)应用程序性能的可视化工具。它提供了一种直观的方法来展示应用程序的计算能力和内存带宽之间的关系,并帮助识别性能瓶颈。
二、page attention
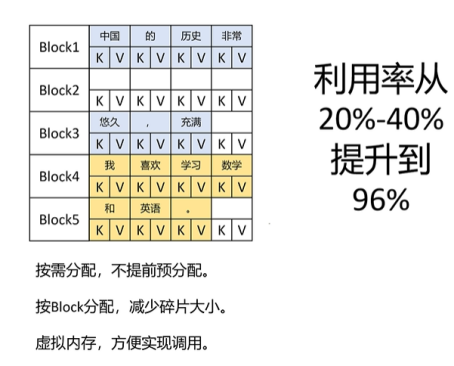
以13B的模型为例,在推理时,参数占显存65%, KV cache占显存的30%。但是KV cache里实际的显存利用率只有30%-40%, 大部分KV cache里的显存都被浪费了。

传统KV cache浪费显存的原因有哪些?
1、在大模型生成时,并不知道要生成多少token,即不知道输出序列会是多长。所以总是按照生成参数里设置的最大的token数来预分配KV cache. 比如模型最大token数是1000,但是实际只生成100个token时就输出终止符结束了,这样有大量被预分配的KV cache显存被浪费了
2、假设一个样本真的可以输出1000个token,但在它输出第一个token的时候,剩下的token的预分配空间还未用到,但是显存已经被预分配占用了。这时其他的请求也无法被响应。而未被响应的请求,有可能只需要输出10个token就结束了。本来可以和正在进行输出的样本并行处理。因此,这也是显存的浪费。
3、显存之间的碎片。即使最大生成长度一致,但是因为prompt的长度不同,每次预分配的KV cache大小也不同。当一个请求生成完毕,释放缓存,但是下一个请求的prompt的长度大于释放的这个请求的prompt长度,所以无法放入被释放的缓存中。这种无法被使用的缓存就是碎片。

vLLM是什么?是解决什么问题的?
vLLM是什么?
vLLM 是一个旨在提高大语言模型(Large Language Models, LLMs)推理效率的开源库。它特别针对现代硬件(如GPU和TPU)进行了优化,以便能够更高效地运行大型语言模型。vLLM的主要目标是通过优化内存使用、加速计算过程以及支持先进的技术特性来提升语言模型的服务性能。
解决什么问题?
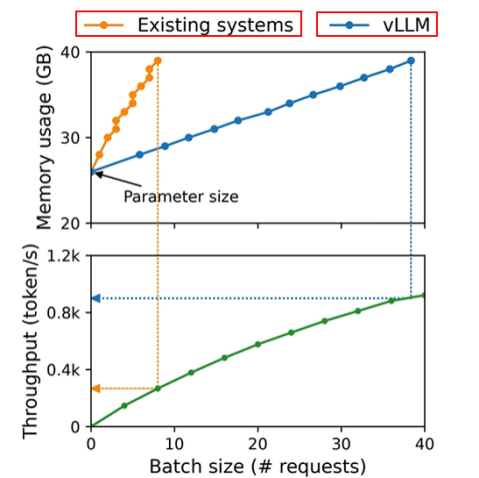
vLLM就是解决了传统KV cache里的显存资源浪费的问题。vLLM和既有系统相比,内存占用更少,吞吐率更高。对比见下图
page attention是怎么解决内存利用率低的问题的?
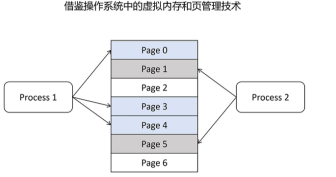
其实类似的问题,操作系统也遇到过。page attention是借鉴操作系统的虚拟内存和页管理技术。
操作系统给每个程序怎么预分配内存?程序关闭后怎么回收内存?内存碎片怎么处理?怎么最大化的利用内存?操作系统是利用虚拟内存和页管理技术来解决的。操作系统分配内存是按照最小单元页来分配,每个页是4K,物理内存被分为很多页。每个进程要用的内存被映射到不同页上。
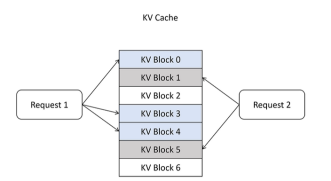
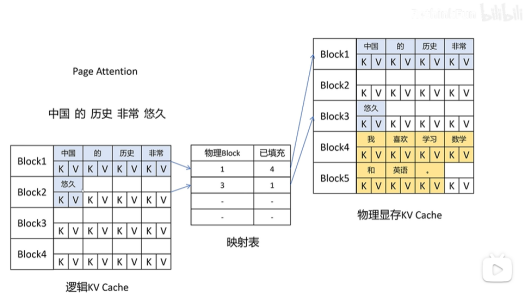
page attention把显存也划分为KV block, 显存按照KV block来管理KV cache,每个请求需要的KV cache被划分到显存不同的KV block里。比如每个KV block里可以缓存4个token的KV向量。
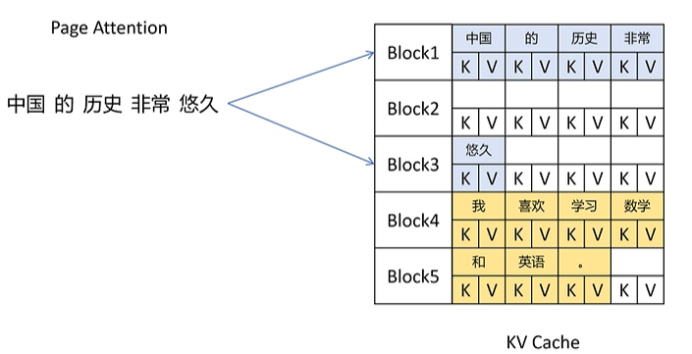
比如“中国的历史非常悠久”,被划分到2个block里,这俩block在物理显存里可以是不连续的。随着大模型的推理,产生了新的token,比如“中国的历史非常悠久,”的逗号,它会继续存在未被填满的block里。直到当前block被填满。
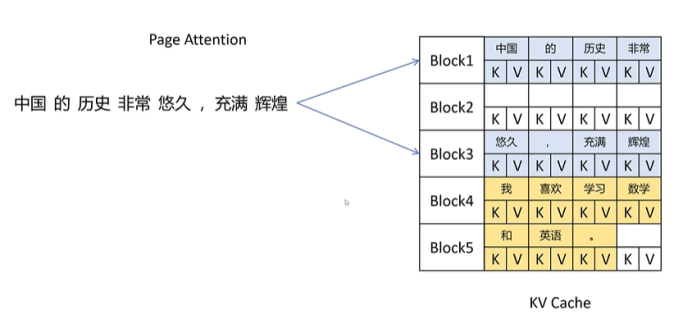
可以发现,vLLM克服了传统KV cache预分配的问题,它是按需分配,不提前占用。并且是按块分配,这样就减少了内存碎片。因为都是按照4个token占用1个block进行分配,碎片最大只有3个token的kv cache。
什么是虚拟内存?
虚拟内存是每个请求都有一个逻辑的KV cache。在逻辑的KV cache里,显存是连续的,vLLM的框架会在后台维护一个逻辑KV cache到实际显存上KV block的映射表。类似操作系统的虚拟内存和物理内存的映射,用户态只感知虚拟内存,不感知物理内存。用户态预先分配的内存都是虚拟内存,感知到的内存是连续的,实际物理内存是可以不连续的,只不过用户不感知。
根据映射表,在进行page attention计算时,会自动找到物理显存上block的KV 向量进行计算,每个请求都有自己的逻辑内存的KV cache,其中的prompt和生成的新token的KV向量看起来好像都是放在连续的缓存上,方便程序操作。
vLLM框架内部维护了映射表,在进行page attention计算时,会根据映射表找到物理显存上block的KV 向量。
page attention的改进1:利用虚拟内存和页管理,将利用率从20-40%提升到90%
page attention的改进2:利用sharing KV blocks(共享block), 减少内存占用。
当我们在利用大模型进行生成时,有时候会想用一个prompt生成多个不同的输出,比如我们想让大模型对一句中文生成多个不同的英文翻译(一个问题,多个答案)。
在vLLM的sampling参数里,可以设置N为大于一的一个整数来实现这个功能。这样同一个prompt会产生2个不同的序列。比如,请把这句话翻译为英文:色即是空。生成2个序列,但是这2个序列,在显卡的显存里只存放了一份prompt token的kv block,每个block都标记着自己现在被2个序列引用着,只有当引用数为0时,这个block占用的显存才会被释放。
接着,第一个序列开始生成,他生成的第一个token是color,这时会触发copy on write机制,也就是它发现自己要继续写入的block的引用数是2,表示该block被2个序列引用着,所以它不能直接写入,必须自己拷贝一份来写,拷贝一份后,在自己的拷贝上写入color这个token的kv cache。然后,原来那个block的引用数就减为1了。新拷贝的这个block的引用数变为1,表明被1个序列引用。接着序列2生成自己的下一个token是matter,写入block。然后两个序列就各自往下生成,完全一样的block(4个token都一样),则保持共享;不同的则各自占用block。就是共享的这部分block,就节省了一份显存。
还能优化beam search里的显存占用?
kv block的共享,还可以优化beam search里的显存占用,原理也是相同的block(4个token都一样),多beam共享。
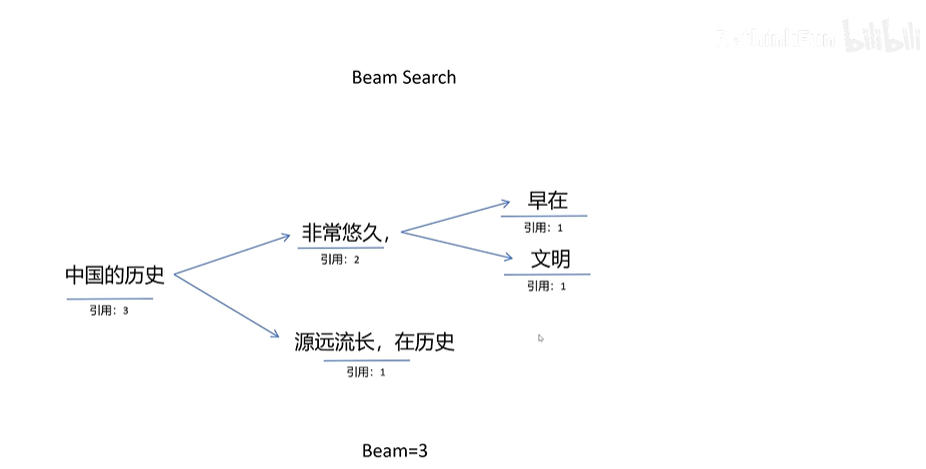
beam search是什么?
Beam Search(集束搜索/束搜索) 是一种用于序列生成任务的启发式搜索算法,它广泛应用于自然语言处理(NLP)中的机器翻译、语音识别、文本摘要等任务。相比于贪心搜索(Greedy Search),Beam Search能够在一定程度上探索更多的可能性,从而找到更好的解。
附录
讲解视频:
【大模型推理】大模型推理 Prefill 和 Decoder 阶段详解_哔哩哔哩_bilibili
怎么加快大模型推理?10分钟学懂VLLM内部原理,KV Cache,PageAttention_哔哩哔哩_bilibili
文档:图解大模型计算加速系列之:vLLM核心技术PagedAttention原理
zomi github: https://github.com/chenzomi12/aiinfra/blob/main/05Infer/01Foundation/01Introduction.pptx