【LLIE专题】NTIRE 2025 低照度图像增强第二名方案

Towards Scale-Aware Low-Light Enhancement via Structure-Guided Transformer Design(2025,NTIRE)
- 专题介绍
- 一、研究背景
- 二、SG-LLIE方法
- 1.和Retinexformer方案对比
- 2.总体方案及创新点
- 3.详细方案
- 3.1 结构先验提取
- 3.2 网络结构
- 3.3 损失函数
- 三、实验结果
- 1.定量实验
- 2.定性实验
- 3.消融实验
- 四、总结
Transformer Design(2025,NTIRE))
本文将对 Towards Scale-Aware Low-Light Enhancement via Structure-Guided Transformer Design,这篇暗光增强算法进行讲解。参考资料如下:
[1] SG-LLIE 文章
[2] SG-LLIE代码
专题介绍
在低光照环境下,传统成像设备往往因画面昏暗、细节丢失而受限。LLIE(低照度暗光增强)技术应运而生,它通过提升图像亮度、对比度,减少噪点并恢复色彩细节,让暗夜变得清晰可见。
LLIE技术从传统方法如直方图均衡化、Retinex模型等起步,近年来借助深度学习,尤其是卷积神经网络(CNN),GAN模型,扩散模型实现了质的飞跃。这些算法能自动学习图像特征,精准处理低光照图像,效果显著优于传统技术。
本专题将聚焦LLIE技术的核心原理、应用案例及最新进展,让我们一起见证LLIE如何点亮暗夜,开启视觉新视界!欢迎一起探讨交流!
系列文章如下
【1】ZeroDCE
【2】HVI
【3】CLIP-LIT
【4】GLARE
【5】Retinexformer
一、研究背景
现有低光照图像增强(LLIE)技术多依赖直接映射(端到端直接学习)或语义、光照图引导,但因 LLIE 不适定性及语义提取困难,在极低光照下效果受限。为此,作者提出 SG - LLIE,一种结构先验引导的多尺度 CNN - Transformer 混合框架。其采用光照不变边缘检测器提取结构先验,在 UNet 编码器的编解码结构上构建 CNN - Transformer 混合结构引导特征提取器(HSGFE)模块,并在 HSGFE 中引入结合结构先验调节增强过程的结构引导 Transformer 模块(SGTB)。实验证明,该方法在多个基准测试中实现定量指标和视觉质量最优,在 NTIRE 2025 低光照增强挑战赛中获第二名。
二、SG-LLIE方法
1.和Retinexformer方案对比
之前我们介绍过Retinexformer这篇基于光照引导的暗光图像增强方案。我们可以简单介绍下两种方案差异:
Retinexformer 创新性地将照明先验引入 Transformer,指导反射增强,生成明亮图像,证实物理先验在深度学习模型中的潜力。不过,作者认为Retinexformer 通过轻量级神经网络获取照明,缺乏光照分量真实值监督,导致在现实场景泛化性差,易出现不自然颜色强度与对比度问题。基于此,作者探索将更稳健的物理先验融入 LLIE 深度学习模型,旨在克服现有局限,优化增强效果 。说白了就是Retinexformer先验太过于简单,鲁棒性不足;作者提出了更强的先验。但是网络结构思想基本一致,都结合了CNN多尺度特征提取和Transformer基于先验引导的注意力机制的思想。
2.总体方案及创新点
本文提出 SG-LLIE,一种结构先验引导的尺度感知 CNNTransformer 框架用于低光照图像增强。该方案基于 UNet 编码器 - 解码器架构,在各层级引入混合结构引导特征提取器(HSGFE)模块。HSGFE 模块通过光照不变边缘检测器提取稳定结构先验,借助结构引导 Transformer 块(SGTB)将其融入恢复过程,并结合扩张残差密集块(DRDB)和语义对齐尺度感知模块(SAM)实现多尺度特征融合。
其创新点在于:
- 一是构建结构先验引导的多尺度 CNN-Transformer 混合框架;
- 二是先提取鲁棒结构先验,再通过结构引导交叉注意力将其整合到定制 Transformer,优化增强指导;
- 三是模型在量化指标和视觉效果表现优异,在 NTIRE 2025 低光图像增强挑战赛中取得高排名,竞争力突出。
3.详细方案

SG-LLIE的整体框架如上图所示。该结构是类似U-Net的架构。在编码器和解码器的每一层,采用了混合结构引导特征提取器(HSGFE)模块。在每个HSGFE中,包含了扩张残差密集块(DRDB)和语义对齐尺度感知模块(SAM),以及结构引导变压器块(SGTB)模块。采用Pixel Unshuffle进行下采样,Pixelshuffle进行上采样。SGTB模块中首先基于颜色不变边缘检测器提取结构先验,然后将这些先验作为Transformer的指导进行特征整合。
3.1 结构先验提取
为提取结构先验,作者采用了《Zero-shot day-night domain adaptation with a physics prior 》和《Lita-gs: Illuminationagnostic novel view synthesis via reference-free 3d gaussian splatting and physical priors》两篇文章中提出的颜色不变卷积(CIConv)。CIConv通过可学习的尺度感知变换来生成一个归一化的边缘响应图,该图反映与任务相关的结构。在基于Kubelka-Munk (KM) 反射模型导出的颜色不变表示中,论文采用W表示法,因为它在不同的光照、阴影和反射条件下能提供稳健的边缘检测:
W o u t = C I C o n v ( I i n ) , ( 1 ) W_{out }=CIConv\left(I_{in }\right), (1) Wout=CIConv(Iin),(1)
其中 I i n I_{in } Iin表示输入的低照度(LL)图像。 W o u t W_{out } Wout表示结构先验,随后将其整合到结构引导变换器模块(SGTB)中用于指导。CIConv的公式可表示为:
C I C o n v ( I i n ) = l o g ( W 2 ( I i n ) + ϵ ) − μ S σ S ( 2 ) CIConv\left(I_{i n}\right)=\frac{log \left(W^{2}\left(I_{i n}\right)+\epsilon\right)-\mu_{\mathcal{S}}}{\sigma_{\mathcal{S}}} (2) CIConv(Iin)=σSlog(W2(Iin)+ϵ)−μS(2)
其中 μ s \mu s μs、 σ s \sigma_{s} σs 和 ϵ \epsilon ϵ分别指样本均值、标准差和小扰动。
为计算 W ( I i n ) W(I_{i n}) W(Iin),首先使用高斯颜色模型(高斯颜色模型(Gaussian Color Model)是一种用于图像边缘检测的经典方法,核心思想是利用高斯核函数对图像的颜色(或灰度)信息进行滤波,通过计算像素点在空间和颜色维度上的梯度变化来检测边缘。)获得初始边缘检测器,记为E。然后,使用E推导出第二阶段的边缘检测器,记为W,如下所示:
W = W x 2 + W λ x 2 + W λ λ x 2 + W y 2 + W λ y 2 + W λ y 2 + W λ λ y 2 , W=\sqrt{W_{x}^{2}+W_{\lambda x}^{2}+W_{\lambda \lambda x}^{2}+W_{y}^{2}+W_{\lambda y}^{2}+W_{\lambda y}^{2}+W_{\lambda \lambda y}^{2}}, W=Wx2+Wλx2+Wλλx2+Wy2+Wλy2+Wλy2+Wλλy2,
W x = E x E , W λ x = E λ x E , W λ λ x = E λ λ x E ( 4 ) W_{x}=\frac{E_{x}}{E}, W_{\lambda x}=\frac{E_{\lambda x}}{E}, W_{\lambda \lambda x}=\frac{E_{\lambda \lambda x}}{E} (4) Wx=EEx,Wλx=EEλx,Wλλx=EEλλx(4)
这里高斯颜色模型之后采用第二阶段边缘检测器的目的是:初始边缘检测器 E 基于高斯颜色模型生成,虽然能检测基本边缘,但对光照变化、阴影和反射等复杂条件的鲁棒性不足。低光图像常存在光照不均、噪声干扰等问题,单一的高斯模型难以准确捕获多尺度、多方向的结构信息。通过 E 推导的第二阶段边缘检测器 W,是对初始边缘信息的二次增强与细化。
- 多维度特征融合W 的计算公式包含光谱强度的一阶空间导数 ( W x , W y ) (W_x, W_y) (Wx,Wy)和二阶空间导数 ( W λ λ x , W λ λ y ) (W_{\lambda\lambda x}, W_{\lambda\lambda y}) (Wλλx,Wλλy),能同时捕捉边缘的位置、方向和曲率信息。例如,二阶导数对图像局部曲率敏感,可检测到更细微的结构变化(如纹理、弱边缘),而一阶导数主要响应边缘强度。
- 光照不变性增强基于 Kubelka-Munk 反射模型的 “W” 表示法,通过对数变换和归一化(CIConv 公式中的 log \log log和标准化操作),降低了光照强度变化对边缘检测的影响。即使在低光或不均匀光照下,W 也能稳定表示图像的固有结构。
公式(4)中各项代表了光谱强度的空间导数。

上图是经过上面方案提取的结构先验,可以看出,该方案提取的结构先验能够稳定表示不同光照条件下图像的边缘和结构信息。证明了这个先验在增强领域的巨大潜力。
3.2 网络结构
上面介绍了网络整体结构,这里主要介绍重要模块。
-
HSGFE模块:在编码和解码过程的每个层级,都部署了HSGFE模块,用于特征表示学习和结构先验的整合。
- HSGFE模块构成:
- 扩张残差密集块(Dilated Residual Dense Block, DRDB):首先通过DRDB处理特征以增强局部表示。
- 结构引导Transformer块(Structure-Guided Transformer Block, SGTB):接着,在SGTB中,将在3.1节提取的结构先验显式地注入特征流。
- 语义对齐尺度感知模块(Semantic-Aligned Scale-Aware Module, SAM):最后,并入SAM以进一步适应尺度多样性并自适应地融合来自不同尺度的表示。
- HSGFE模块构成:
-
SGTB模块构成:如上图网络结构中SGTB的放大图所示,它由三个主要组件构成:
1. 通道级自注意力(Channel-wise Self-Attention, CSA)。 该模块主要是为了增强特征通道间联系。
CSA表示为: F o u t = C S A ( L N ( F i n ) ) + F i n F_{out} = CSA(LN(F_{in})) + F_{in} Fout=CSA(LN(Fin))+Fin,其中 F i n , F o u t ∈ R H × W × C F_{in}, F_{out} \in \mathbb{R}^{H \times W \times C} Fin,Fout∈RH×W×C 分别是输入输出特征图。
2. 结构引导交叉注意力(Structure-Guided Cross Attention, SGCA)。该模块主要为了解决传统低光增强模型经常扭曲输入图像原始结构细节的问题。通过将结构先验融入注意力机制可以更好地保持空间一致性。
输入特征 F i n ∈ R H × W × C F_{in} \in \mathbb{R}^{H \times W \times C} Fin∈RH×W×C首先被重塑为序列 X ∈ R H W × C X \in \mathbb{R}^{HW \times C} X∈RHW×C。(Query, Q) 由 X X X 线性投影产生: Q = X W Q T Q = XW_Q^T Q=XWQT。 (Key, K p K_p Kp) 和 (Value, V p V_p Vp) 则由结构先验提供(下标p代表先验)。论文中获取这两个表示的方法是: K p = X p W K p T , V p = X p W V p T K_p = X_p W_{K_p}^T,V_p = X_p W_{V_p}^T Kp=XpWKpT,Vp=XpWVpT,其中 X p X_p Xp是处理后的结构先验特征序列, W K p T , W V p T W_{K_p}^T,W_{V_p}^T WKpT,WVpT是可学习的参数矩阵。这里的表述我们可以知道 K p K_p Kp 和 V p V_p Vp是基于结构先验图 W o u t W_{out} Wout(经过适当处理以匹配维度)生成的。 结构引导注意力机制公式为: A t t e n t i o n ( Q , K p , V p ) = s o f t m a x ( Q ⋅ K p T λ ) ⋅ V p Attention(Q, K_p, V_p) = softmax(\frac{Q \cdot K_p^T}{\lambda}) \cdot V_p Attention(Q,Kp,Vp)=softmax(λQ⋅KpT)⋅Vp。其中 λ \lambda λ 是一个可学习的参数,用于自适应地调整矩阵乘法的尺度。
通过这种方式,交叉注意力机制不仅能建立远程依赖关系,还能将结构信息直接融入当前的特征表示中。从这里可以看出,这个结构和Retinexformer中光照引导的注意力模块非常像。
3. 前馈网络(Feed-Forward Network, FFN)。
此外,在每个机制之前都应用了层归一化(Layer Normalization),并应用了三个残差连接以保留残差信息。 -
尺度自适应神经架构(SAM)
现实场景中图像分辨率各异(如 6000 × 4000 或 2992 × 2000),给一致的特征表示带来挑战(不同分辨率物体尺度不同)。SAM 利用金字塔式特征提取和跨尺度动态融合来解决此问题。这种结构经常用于图像分割和目标检测网络中,主要是为了提取多尺度特征。
输入特征图 F i n , 0 ∈ R H × W × C F_{in,0} \in \mathbb{R}^{H \times W \times C} Fin,0∈RH×W×C经过双线性插值生成两个降采样特征: F i n , 1 ∈ R H 2 × W 2 × C F_{in,1} \in \mathbb{R}^{\frac{H}{2} \times \frac{W}{2} \times C} Fin,1∈R2H×2W×C和 F i n , 2 ∈ R H 4 × W 4 × C F_{in,2} \in \mathbb{R}^{\frac{H}{4} \times \frac{W}{4} \times C} Fin,2∈R4H×4W×C。 这些多分辨率特征图通过卷积层独立处理,得到相应的金字塔表示: Y i n , 0 , Y i n , 1 , Y i n , 2 Y_{in,0}, Y_{in,1}, Y_{in,2} Yin,0,Yin,1,Yin,2。然后进行跨尺度融合:为每个尺度特定的特征图分配一个可学习的权重矩阵 α i ( i = 0 , 1 , 2 ) \alpha_i (i = 0,1,2) αi(i=0,1,2)。这些权重通过对三个特征图分别应用全局平均池化得到。池化后的特征再通过一个多层感知器 (MLP) 以促进自适应有效的跨尺度交互,得到融合权重 β 0 , β 1 , β 2 = M L P ( α 0 , α 1 , α 2 ) \beta_0, \beta_1, \beta_2 = MLP(\alpha_0, \alpha_1, \alpha_2) β0,β1,β2=MLP(α0,α1,α2) 。 最终的融合特征图 F f F_f Ff计算如下: F f = F i n , 0 + β 0 ⊙ Y i n , 0 + β 1 ⊙ Y i n , 1 + β 2 ⊙ Y i n , 2 F_f = F_{in,0} + \beta_0 \odot Y_{in,0} + \beta_1 \odot Y_{in,1} + \beta_2 \odot Y_{in,2} Ff=Fin,0+β0⊙Yin,0+β1⊙Yin,1+β2⊙Yin,2,其中 ⊙ \odot ⊙ 表示逐元素乘法。
3.3 损失函数
损失函数 ,基于三个不同尺度的输出图像—— I ^ 1 \hat{I}_{1} I^1、 I ^ 2 \hat{I}_{2} I^2和 I ^ 3 \hat{I}_{3} I^3——设计损失函数,这些图像分别对应于解码器不同级别下的三种不同分辨率的输出图像:
L t o t a l = ∑ i = 1 3 L C ( I i , I ^ i ) + λ ⋅ ∑ i = 1 3 L P ( I i , I ^ i ) + γ ⋅ ∑ i = 1 3 L M S − S S I M ( I i , I ^ i ) , \begin{aligned} L_{total }= & \sum_{i=1}^{3} L_{C}\left(I_{i}, \hat{I}_{i}\right)+\lambda \cdot \sum_{i=1}^{3} L_{P}\left(I_{i}, \hat{I}_{i}\right) \\ & +\gamma \cdot \sum_{i=1}^{3} L_{MS-SSIM}\left(I_{i}, \hat{I}_{i}\right), \end{aligned} Ltotal=i=1∑3LC(Ii,I^i)+λ⋅i=1∑3LP(Ii,I^i)+γ⋅i=1∑3LMS−SSIM(Ii,I^i),
其中 L 1 L_{1} L1、 L P L_{P} LP和 L M S − S S I M L_{MS - SSIM} LMS−SSIM分别表示Charbonnier损失、感知损失和多尺度结构相似性(MSSSIM)损失。加权因子设置为 λ = 0.01 \lambda = 0.01 λ=0.01和 γ = 0.4 \gamma = 0.4 γ=0.4。
三、实验结果
作者使用由NTIRE 2025低光增强挑战赛提供的数据集。该数据集包含219张训练图像、46张验证图像和30张测试图像。此外,还使用了NTIRE 2024低光增强挑战赛的训练集进行微调。
1.定量实验
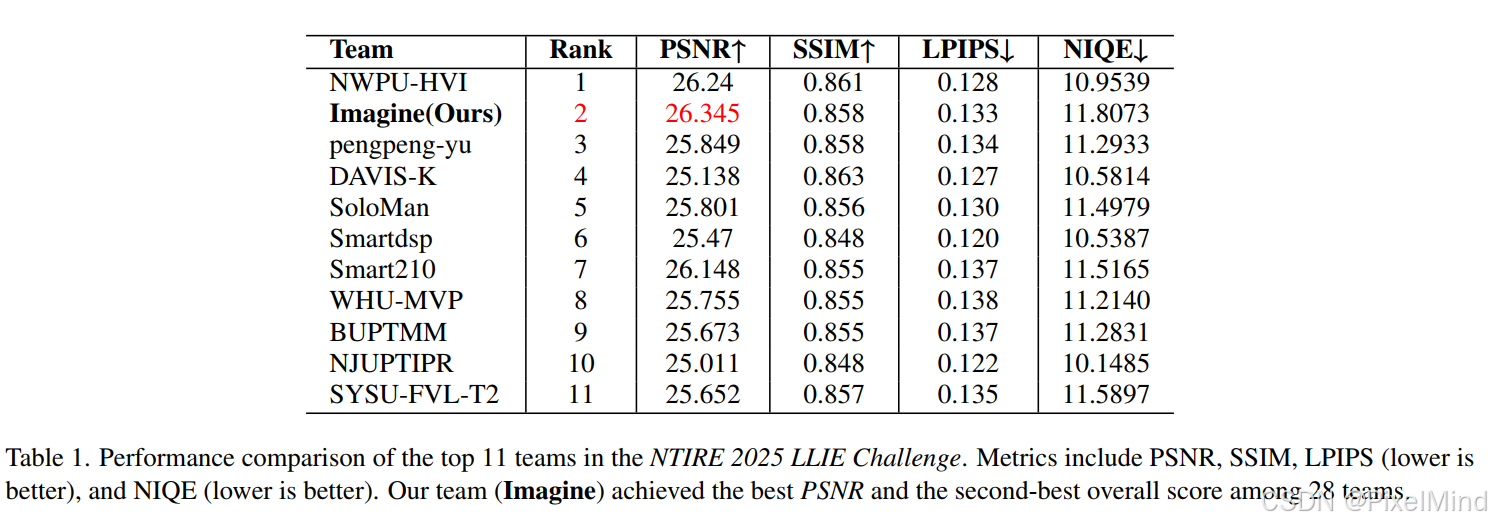
定性实验1如上图所示,在NTIRE2025 LLIE比赛的多个参赛队伍中取得了第二名的成绩。
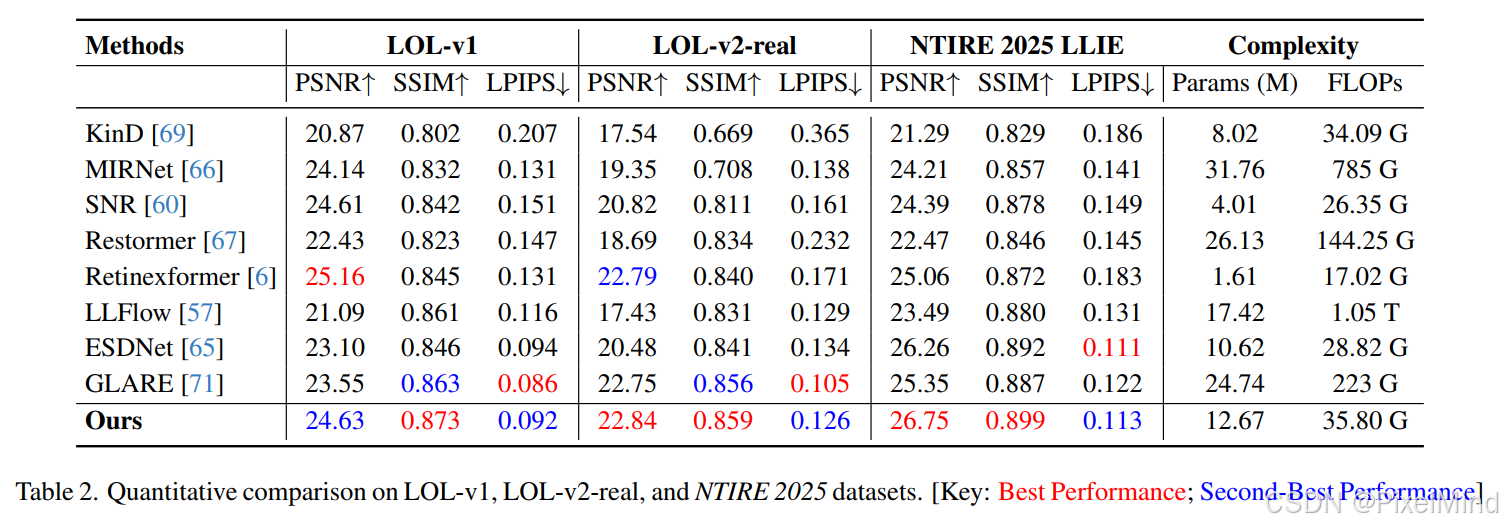
在多个LLIE基准数据集上,和多种LLIE方案对比,本文方案同样取得了非常好的结果。
2.定性实验

定量实验可以看出,本文方案增强后在保留细节方面更具有优势。
3.消融实验

消融实验也证明了本文SGCA、SGTB模块的有效性,以及损失函数MS-SSIM的有效性。
四、总结
本文是NTIRE2025暗光增强比赛中的第二名,提出了一种结构引导先验的增强方法,网络结构类似于Retinexformer。
感谢阅读,欢迎留言或私信,一起探讨和交流。
如果对你有帮助的话,也希望可以给博主点一个关注,感谢。