NumPy 比较、掩码与布尔逻辑
文章目录
- 比较、掩码与布尔逻辑
- 示例:统计下雨天数
- 作为通用函数(Ufuncs)的比较运算符
- 使用布尔数组
- 计数条目
- 布尔运算符
- 布尔数组作为掩码
- 使用关键字 and/or 与运算符 &/| 的区别
比较、掩码与布尔逻辑
本文介绍如何使用布尔掩码来检查和操作 NumPy 数组中的值。
当你想根据某些条件提取、修改、计数或以其他方式处理数组中的值时,就会用到掩码:例如,你可能希望统计所有大于某个值的元素,或者移除所有高于某个阈值的异常值。
在 NumPy 中,布尔掩码通常是完成此类任务最高效的方法。
示例:统计下雨天数
假设你有一组数据,表示某个城市一年中每天的降水量。
例如,这里我们将使用 Pandas 加载 2015 年西雅图的每日降雨统计数据:
import numpy as np
from vega_datasets import data# Use DataFrame operations to extract rainfall as a NumPy array
rainfall_mm = np.array(data.seattle_weather().set_index('date')['precipitation']['2015'])
len(rainfall_mm)
365
该数组包含 365 个数值,表示 2015 年 1 月 1 日至 12 月 31 日每天的降雨量(单位:毫米)。
作为初步的可视化,我们可以通过下图(使用 Matplotlib 生成)查看雨天的直方图:
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('seaborn-v0_8-whitegrid')
plt.hist(rainfall_mm, 40);
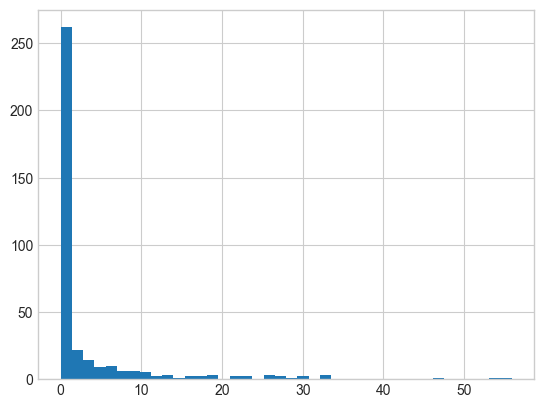
这个直方图让我们对数据有了一个大致的了解:尽管这座城市以多雨著称,但实际上 2015 年西雅图大多数日子的降雨量几乎为零。
不过,这并不能很好地展示我们想要了解的信息:比如,这一年中有多少个下雨天?下雨天的平均降水量是多少?有多少天的降水量超过了 10 毫米?
一种方法是手动回答这些问题:我们可以遍历数据,每当遇到落在某个范围内的数值时就递增计数器。
但正如本章多次讨论的那样,从编写代码和计算结果的效率来看,这种方法都非常低效。
我们在NumPy 数组上的计算:通用函数中看到,NumPy 的 ufunc 可以用来替代循环,对数组进行快速的逐元素算术运算;同样地,我们也可以使用其他 ufunc 对数组进行逐元素比较,然后操作结果来回答我们关心的问题。
我们暂且把数据放在一边,先来讨论 NumPy 中的一些通用工具,看看如何利用掩码快速回答这类问题。
作为通用函数(Ufuncs)的比较运算符
NumPy 数组上的计算:通用函数 介绍了通用函数(ufuncs),并重点讲解了算术运算符。我们看到,对数组使用 +、-、*、/ 等运算符会进行逐元素操作。
NumPy 还实现了诸如 <(小于)和 >(大于)这样的比较运算符,并将它们作为逐元素的通用函数。
这些比较运算符的结果总是一个布尔类型的数据数组。
所有六种标准的比较操作都可供使用:
x = np.array([1, 2, 3, 4, 5])
x < 3 # less than 小于
array([ True, True, False, False, False])
x > 3 # greater than 大于
array([False, False, False, True, True])
x <= 3 # less than or equal to 小于等于
array([ True, True, True, False, False])
x >= 3 # greater than or equal to 大于等于
array([False, False, True, True, True])
x != 3 # not equal 不等于
array([ True, True, False, True, True])
x == 3 # equal 等于
array([False, False, True, False, False])
也可以对两个数组进行逐元素比较,并包含复合表达式:
(2 * x) == (x ** 2) # 等式判断
array([False, True, False, False, False])
如同算术运算符一样,NumPy 中的比较运算符也是以通用函数(ufuncs)的形式实现的;例如,当你写下 x < 3 时,NumPy 在内部实际上调用的是 np.less(x, 3)。
下表总结了常用的比较运算符及其对应的 ufunc:
| 运算符 | 对应的 ufunc | 运算符 | 对应的 ufunc |
|---|---|---|---|
== | np.equal | != | np.not_equal |
< | np.less | <= | np.less_equal |
> | np.greater | >= | np.greater_equal |
就像算术通用函数(ufuncs)一样,这些比较运算符同样适用于任意大小和形状的数组。
下面是一个二维数组的示例:
rng = np.random.default_rng(seed=1701)
x = rng.integers(10, size=(3, 4))
x
array([[9, 4, 0, 3],[8, 6, 3, 1],[3, 7, 4, 0]])
x < 6
array([[False, True, True, True],[False, False, True, True],[ True, False, True, True]])
在每种情况下,结果都是一个布尔数组,NumPy 提供了许多直接的方法来处理这些布尔结果。
使用布尔数组
给定一个布尔数组,你可以进行许多有用的操作。
我们将使用前面创建的二维数组 x 进行演示:
print(x)
[[9 4 0 3][8 6 3 1][3 7 4 0]]
计数条目
要统计布尔数组中 True 条目的数量,可以使用 np.count_nonzero:
# 小于6的条目数
np.count_nonzero(x < 6)
8
我们可以看到,有八个数组元素小于 6。
另一种获取此信息的方法是使用 np.sum;在这种情况下,False 会被当作 0,True 会被当作 1:
np.sum(x < 6)
np.int64(8)
np.sum 的好处在于,和其他 NumPy 聚合函数一样,这种求和操作也可以沿着行或列进行:
# 每一行小于6的条目数
np.sum(x < 6, axis=1)
array([3, 2, 3])
这将统计矩阵每一行中小于 6 的值的数量。
如果我们想快速检查某一行是否有任意值为 True,或者所有值都为 True,可以使用(你猜对了)np.any 或 np.all:
# 是否有大于8的值?
np.any(x > 8)
np.True_
# 是否有小于0的值?
np.any(x < 0)
np.False_
# 所有值都小于10吗?
np.all(x < 10)
np.True_
# 所有值都等于6?
np.all(x == 6)
np.False_
np.all 和 np.any 也可以沿特定轴进行操作。例如:
# 是否每行的值都小于8?
np.all(x < 8, axis=1)
array([False, False, True])
这里,第三行的所有元素都小于 8,而其他行则不是如此。
最后需要提醒一点:正如在 聚合:最小值、最大值以及所有其他内容 中提到的,Python 内置的 sum、any 和 all 函数与 NumPy 版本的语法不同,尤其是在多维数组上使用时,可能会出错或产生意外结果。在这些示例中,请确保使用的是 np.sum、np.any 和 np.all!
布尔运算符
我们已经看到如何统计降雨量小于 20 毫米的天数,或者降雨量大于 10 毫米的天数。 但如果我们想知道降雨量大于 10 毫米且小于 20 毫米的天数有多少天呢?这时可以用 Python 的按位逻辑运算符 &、|、^ 和 ~ 来实现。 与标准算术运算符类似,NumPy 也重载了这些运算符,使其可以对(通常是布尔型)数组进行逐元素操作。
例如,我们可以这样解决这类复合问题:
np.sum((rainfall_mm > 10) & (rainfall_mm < 20))
np.int64(16)
这告诉我们有 16 天的降雨量在 10 到 20 毫米之间。
这里的括号非常重要。由于运算符优先级规则,如果去掉括号,这个表达式会被如下方式计算,这将导致错误:
rainfall_mm > (10 & rainfall_mm) < 20
Let’s demonstrate a more complicated expression. Using De Morgan’s laws, we can compute the same result in a different manner:
让我们展示一个更复杂的表达方式——利用德摩根定律,用另一种方式得出相同的结果:
np.sum(~( (rainfall_mm <= 10) | (rainfall_mm >= 20) ))
np.int64(16)
将比较运算符与布尔运算符结合应用于数组,可以实现高效且多样的逻辑操作。
下表总结了按位布尔运算符及其对应的通用函数 ufunc:
| 运算符 | 对应的 ufunc | 运算符 | 对应的 ufunc |
|---|---|---|---|
& | np.bitwise_and | | | np.bitwise_or |
^ | np.bitwise_xor | ~ | np.bitwise_not |
利用这些工具,我们可以开始回答关于天气数据的许多问题。
以下是结合掩码与聚合操作时可以计算的一些结果示例:
print("Number days without rain: ", np.sum(rainfall_mm == 0))
print("Number days with rain: ", np.sum(rainfall_mm != 0))
print("Days with more than 10 mm: ", np.sum(rainfall_mm > 10))
print("Rainy days with < 5 mm: ", np.sum((rainfall_mm > 0) &(rainfall_mm < 5)))
Number days without rain: 221
Number days with rain: 144
Days with more than 10 mm: 34
Rainy days with < 5 mm: 83
布尔数组作为掩码
在前一节中,我们介绍了如何直接对布尔数组进行聚合计算。
更强大的用法是将布尔数组用作掩码,从而选择数据中的特定子集。让我们回到之前的 x 数组:
x
array([[9, 4, 0, 3],[8, 6, 3, 1],[3, 7, 4, 0]])
假设我们想要获取数组中所有小于 5 的值组成的数组。正如我们之前看到的,我们可以很容易地为这个条件获得一个布尔数组:
x < 5
array([[False, True, True, True],[False, False, True, True],[ True, False, True, True]])
现在,要从数组中选取这些值,我们只需用这个布尔数组进行索引;这被称为掩码操作(masking operation):
x[x < 5]
array([4, 0, 3, 3, 1, 3, 4, 0])
返回的是一个一维数组,包含所有满足该条件的值;换句话说,就是所有在掩码数组中对应位置为 True 的值。
随后,我们可以对这些值进行任意操作。 例如,我们可以对西雅图降雨数据计算一些相关统计量:
# construct a mask of all rainy days
rainy = (rainfall_mm > 0)# construct a mask of all summer days (June 21st is the 172nd day)
days = np.arange(365)
summer = (days > 172) & (days < 262)print("Median precip on rainy days in 2015 (mm): ",np.median(rainfall_mm[rainy]))
print("Median precip on summer days in 2015 (mm): ",np.median(rainfall_mm[summer]))
print("Maximum precip on summer days in 2015 (mm): ",np.max(rainfall_mm[summer]))
print("Median precip on non-summer rainy days (mm):",np.median(rainfall_mm[rainy & ~summer]))
Median precip on rainy days in 2015 (mm): 3.8
Median precip on summer days in 2015 (mm): 0.0
Maximum precip on summer days in 2015 (mm): 32.5
Median precip on non-summer rainy days (mm): 4.1
通过结合布尔运算、掩码操作和聚合操作,我们可以非常快速地回答关于数据集的这类问题。
使用关键字 and/or 与运算符 &/| 的区别
一个常见的困惑点是关键字 and 和 or 与运算符 & 和 | 之间的区别。
什么时候应该用前者,什么时候用后者?
区别在于:and 和 or 作用于整个对象,而 & 和 | 作用于对象中的每个元素。
当你使用 and 或 or 时,相当于让 Python 把整个对象当作一个布尔实体来处理。
在 Python 中,所有非零整数都会被判断为 True。因此:
bool(42), bool(0)
(True, False)
bool(42 and 0)
False
bool(42 or 0)
True
当你对整数使用 & 和 | 时,表达式会作用于元素的位表示,对组成该数字的每一位分别执行按位与或按位或操作:
bin(42)
'0b101010'
bin(59)
'0b111011'
bin(42 & 59)
'0b101010'
bin(42 | 59)
'0b111011'
注意,二进制表示的对应位会逐一比较,从而得出结果。
当你在 NumPy 中拥有一个布尔值数组时,可以将其视为一串比特,其中 1 = True,0 = False,而 & 和 | 的操作方式与前面的示例类似:
A = np.array([1, 0, 1, 0, 1, 0], dtype=bool)
B = np.array([1, 1, 1, 0, 1, 1], dtype=bool)
A | B
array([ True, True, True, False, True, True])
但是如果你对这些数组使用 or,它会尝试判断整个数组对象的真值,这并不是一个明确定义的值:
A or B
---------------------------------------------------------------------------ValueError Traceback (most recent call last)Cell In[38], line 1
----> 1 A or BValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
类似地,当你对一个数组进行布尔表达式运算时,应使用 | 或 &,而不是 or 或 and:
x = np.arange(10)
(x > 4) & (x < 8)
array([False, False, False, False, False, True, True, True, False,False])
尝试对整个数组求真或求假会导致和之前一样的 ValueError 错误:
(x > 4) and (x < 8)
---------------------------------------------------------------------------ValueError Traceback (most recent call last)Cell In[40], line 1
----> 1 (x > 4) and (x < 8)ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()