大模型的开发应用(七):大模型的分布式训练
分布式训练与分布式部署
- 0 前言
- 1 分布式训练的原理
- 1.1 数据并行(Data Parallelism)
- 1.2 模型并行(Model Parallelism)
- (1)张量并行
- (2)流水线并行
- 1.3 混合并行(Hybrid Parallelism)
- 1.4 选择策略对比表
- 2 ZeRO(零冗余优化器)
- 2.1 混合精度训练时显存占用分析
- 2.2 分片(Partition)
- 2.3 ZeRO 中的分片与张量并行的区别( ZeRO-3 的工作机制)
- 1. 张量并行 (Tensor Parallelism) - 以 Megatron-LM 的列并行为例
- 2. ZeRO分片 (ZeRO Sharding) - 主要展示 ZeRO 阶段3
- 3. 总结对比 (张量并行 vs. ZeRO分片)
- 2.4 ZeRO-3 + QLoRA
- 2.5 ZeRO-1、 ZeRO-2的过程
- 2.6 ZeRO-1、ZeRO-2、ZeRO-3 的对比
- 3 ZeRO-Offload
- 4 在 LLaMA-Factory 和 Xtuner 中进行分布式微调
- 4.1 DeepSpeed框架介绍
- 4.2 LLaMA-Factory
- 实验一:数据并行
- 实验二:ZeRO-2
- 实验三:ZeRO-2 + ZeRO-Offload
- 实验四:ZeRO-3
- 实验总结
- 4.3 Xtuner
- 4.4 关于ZeRO节约显存的疑问
- 5 实战:用两张 RTX 4070 训练 8B 模型
- 参考文献:
0 前言
现代大模型(如GPT-3、LLaMA等)的参数量达千亿级别,单卡GPU无法存储完整模型,在训练时,除了模型参数占用显存,梯度和优化器状态同样占用显存,因此有必要使用分布式的方式进行模型的训练和推理。此外,训练大模型需要海量计算(如GPT-3需数万GPU小 时),分布式训练可加速训练过程。
本文参考了知乎作者 basicv8vc 的文章:DeepSpeed之ZeRO系列:将显存优化进行到底
1 分布式训练的原理
1.1 数据并行(Data Parallelism)
- 原理:复制整个模型到多个设备(GPU/节点),每个设备处理不同的数据子集(批次分片)。
- 通信:AllReduce:主流实现(如PyTorch DDP, Horovod),各设备单独计算梯度,然后汇总到一台设备求平均,最后广播到其他设备实现梯度同步。
- 优点:实现简单,适合模型小、数据量大场景。
- 缺点:每个设备需存储完整模型副本,大模型显存压力大。
- 典型框架:
torch.nn.DataParallel, PyTorch DDP, TensorFlowMirroredStrategy.
AllReduce 是一种在分布式计算环境中常用的集体通信操作,特别是在深度学习的分布式训练中。它用于将多个进程或设备(如GPU)中的数据进行聚合,并将结果分发回所有参与的进程或设备,这样每个进程或设备最终都拥有相同的结果。这个过程对于同步参数更新特别有用,可以确保所有工作节点上的模型权重保持一致。以下是 AllReduce 操作的一般过程:
-
初始化:所有参与的进程或设备开始时持有自己本地的数据(例如,梯度信息)。这些数据通常是模型训练过程中产生的,并且需要被同步到所有其他进程或设备上。
-
Reduce 阶段:在这个阶段,所有进程或设备将自己的数据发送给一个或多个指定的接收者(根据所使用的具体算法,这可能是单个进程或一组进程),并在那里执行归约操作(比如求和、求平均等)。常见的实现方式包括树形结构(如二叉树)、环形结构等。
-
Broadcast 阶段:一旦完成了归约操作并得到了全局的结果,这个结果需要被广播给所有的进程或设备。这意味着每个参与者都会接收到同样的归约结果。
-
更新本地数据:最后,所有进程或设备用从 Broadcast 阶段接收到的全局结果来更新自己的本地数据。
在深度学习框架中,比如 TensorFlow 和 PyTorch,都提供了对 AllReduce 操作的支持,通常通过集成诸如 NCCL(NVIDIA Collective Communications Library)这样的库来优化 GPU 间的通信效率。
值得注意的是,AllReduce 的具体实现和性能可能会受到网络拓扑、通信带宽、延迟以及参与的节点数量等因素的影响。因此,在实际应用中选择合适的 AllReduce 算法和配置是至关重要的。
1.2 模型并行(Model Parallelism)
- 原理:将模型按层或算子拆分到不同设备,数据流经所有设备完成计算。
- 类型:
-
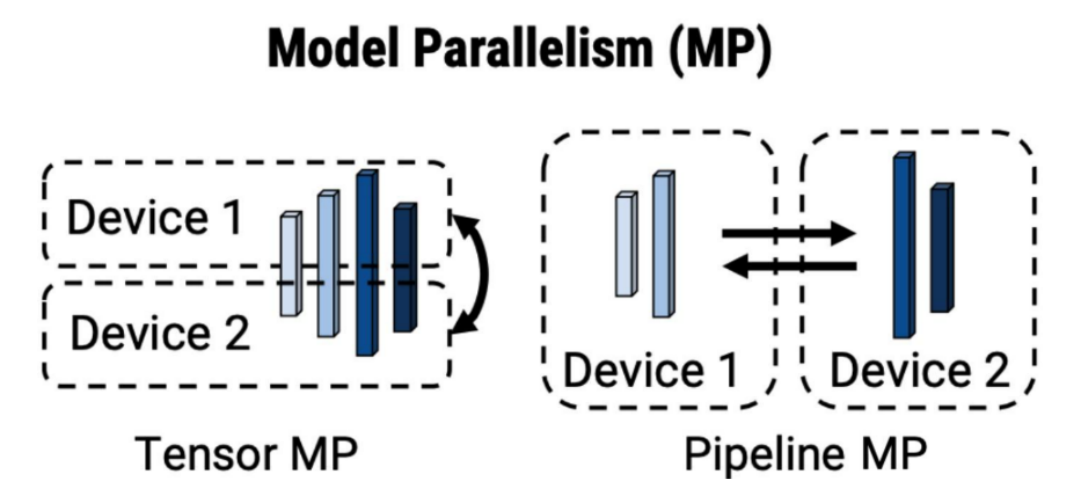
-
Tensor Parallelism(张量并行):横向切割算子(如矩阵乘法分块),如Megatron-LM的列并行(拆分权重矩阵)。
-
Pipeline Parallelism(流水线并行):纵向切割模型层(如将ResNet的50层分配到4个设备)。
-
- 优点:支持超大模型(单卡无法放下)。
- 缺点:通信开销大,计算设备利用率低(存在等待时间)。
- 典型框架:Megatron-LM(张量并行),GPipe(流水线并行)。
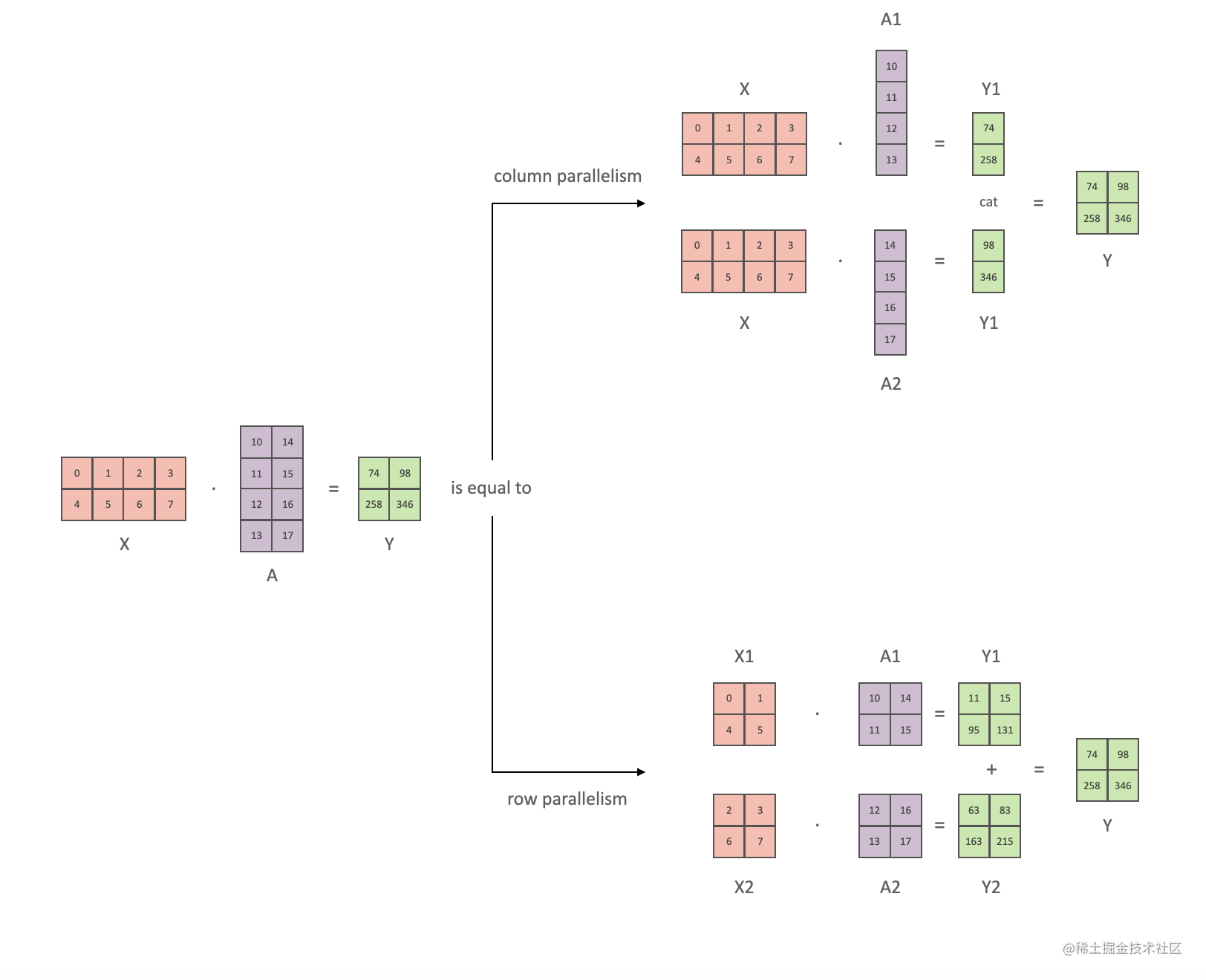
(1)张量并行
张量并行会把模型参数分配到不同的设备上,一般可以分为按列切分和按行切分,如下图所示(图片来源:大模型分布式训练并行技术(四)-张量并行):
现代大模型几乎都是解码器架构的,它由若干个解码器子层堆叠而成,而解码器子层又主要是由Attention层和MLP层(即 FFN 层)构成。
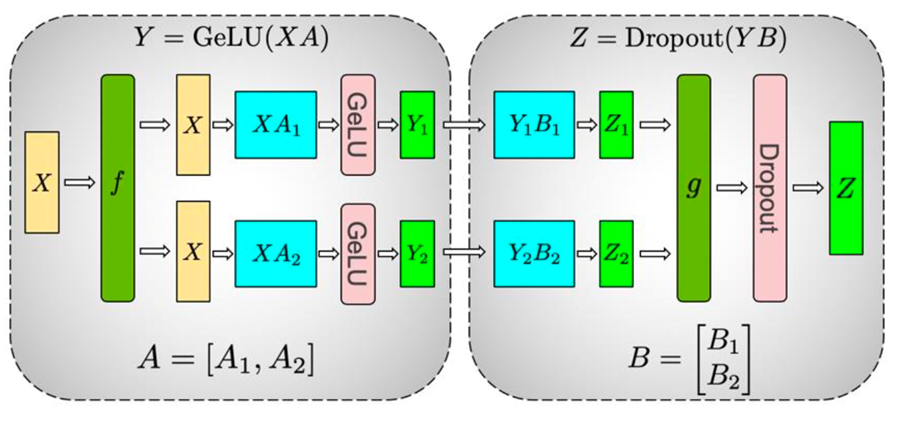
我们先说 MLP 层的张量并行。
MLP层数学表达如下:Y = GeLU(XA) ,Z = Dropout(YB)
对MLP层使用张量并行,过程如下图所示,权重A矩阵竖向着切,B矩阵横向切分,最后进行合并:
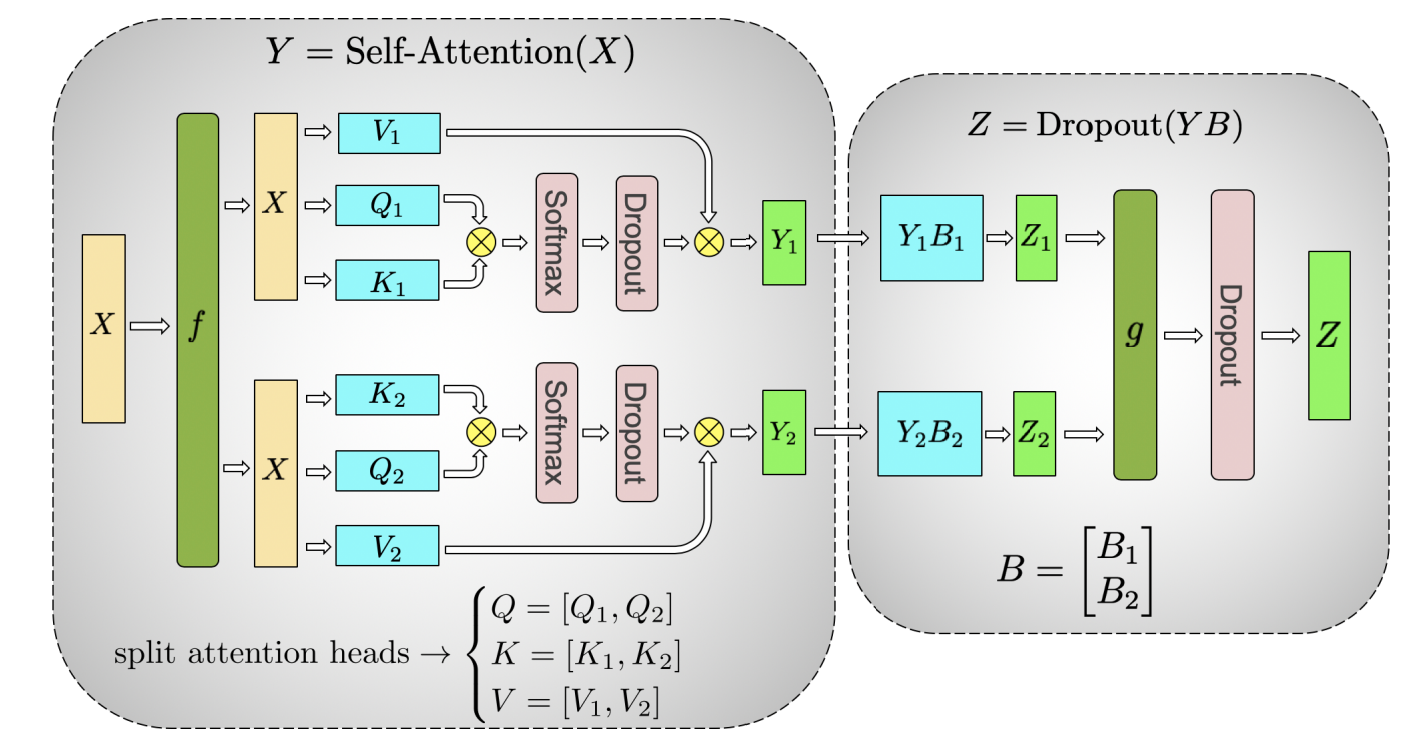
Attention层数学表达如下:Y = Self-Attention(X) ,Z = Dropout(YB)
多头注意力每个头都是独立的,将不同的头放在不同的设备上,即对输入数据进行切分,把输入数据 X 分发到不同设备上进行 QKV 的计算,每个设备中用于计算 QKV 的模型权重都是相同的,即这个过程没有切分模型权重;对于 Z = Dropout(YB) ,则是对权重矩阵 B 进行横向切分。对Attention层进行张量并行,过程如下图所示:
(2)流水线并行
流水线并行就是将模型的不同层放到不同设备上,分的时候都是整层整层的分,也就是不对任何一层的参数进行切分,对于某一特定层,是把这层参数完整地放到一个GPU中。
假设我们有4个GPU,每个GPU对应一个进程(worker),我们可以把模型分成4个模块,不同的模块放到不同的GPU中,训练的时候,我们可以把每个batch的数据分成4份,每份就是一个 micro batch。
朴素的流水线策略是这样的:前向传播时,第一个模块处理整个 batch 的数据,此时其他三个模块空闲,即此时有3个GPU空闲;处理结束后把第一个模块的输出送入第二个模块,然后第二个模块开始处理数据,其他三个模块空闲;依次类推,每个模块都在等着前面的模块把特征传递过来。反向传播时,也是类似的,第4个模块处理反向传播时,前面3个模块都空闲,等处理结束,把梯度传递给第3个模块,此时第1、2、4模块都空闲,每个模块都在等着后一个模块把梯度传递给自己。这种并行方式,每个模块处理数据时,其他三个模块都空闲,意味着每个时刻都有3个GPU空闲。这种方案确实“流水”了,但没有“并行”。
为了能把各个GPU充分利用起来,减少各个GPU的空闲时间,谷歌提出了一种被称为 GPipe 的并行方案:
前向传播:在第 t1 时刻,让第一个模块处理第一个micro batch,处理结束后,会获得第一个模块的输出;第 t2 时刻,将第一个模块的输出放到第二个模块中,同时第一个模块开始处理第二个micro batch;第 t3 时刻,将第二个模块的输出放到第三个模块,随后把第一个模块的输出放入第二个模块,同时第一个模块开始处理第三个micro batch;第 t4 时刻,将第三个模块的输出放到第四个模块,第二个模块的输出放到第三个模块,随后把第一个模块的输出放入第二个模块,同时第一个模块开始处理第三个micro batch,此时4个模块同时在处理数据,即4个GPU同时在工作;第 t8 时刻,最后一个 micro batch 的前向传播也处理完了,那么可以开始进行反向传播了。
我们假设,反向传播处理每个 micro batch 的时间是正向传播的两倍。反向传播:在第 t8 时刻,第4个模块开始处理第一个 micro batch 的反向传播;第 t10 时刻,第一个 micro batch 的反向传播结束,将梯度传递给第3个模块,随后第4个模块开始处理第二个 micro batch 的反向传播;依次类推,过程和前面前向传播一致。
GPipe的过程如下图所示:
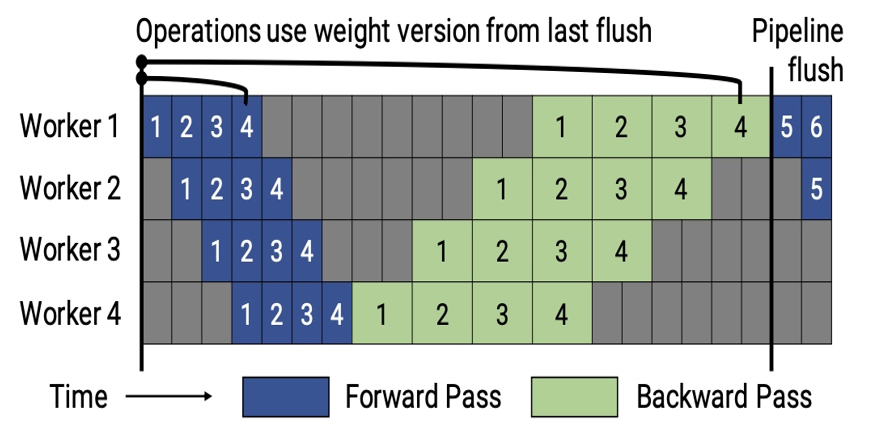
流水线并行还有很多改进算法,关于流水线并行,了解到这里即可,不用深究。如果后续有需要,可以看这篇文章。
1.3 混合并行(Hybrid Parallelism)
- 原理:组合多种并行策略(如数据并行+模型并行)。
- 常见组合:3D并行(数据并行 + 张量并行 + 流水线并行),用于千亿级大模型(如GPT-3)。
- 优点:极致的扩展性和显存优化。
- 缺点:实现复杂,需精细调优。
- 典型框架:DeepSpeed + Megatron(3D并行),PyTorch Fully Sharded Data Parallel (FSDP)。
1.4 选择策略对比表
| 场景需求 | 推荐策略 | 典型案例 |
|---|---|---|
| 中小模型(单卡可放下) | 数据并行 (AllReduce) | ResNet/BERT多卡训练 |
| 单层过大(如大矩阵乘法) | 张量并行 | Megatron-LM中的Transformer层 |
| 模型层数极多 | 流水线并行 | GPT-3, T5 |
| 超大规模模型训练 | 3D并行 + ZeRO | 千亿参数大模型(如Bloom) |
| 资源有限(显存不足) | ZeRO-Offload + CPU卸载 | 消费级显卡训练大模型 |
2 ZeRO(零冗余优化器)
ZeRO(Zero Redundancy Optimizer) 是微软开源的 DeepSpeed 框架中的核心优化技术,旨在解决大规模深度学习模型训练中的 显存瓶颈问题,显著降低单卡/节点的显存占用,从而支持训练超大规模模型(如百亿甚至万亿参数级别)。
总体而言,这部分的内容比较复杂,特别是涉及ZeRO工作机制的部分,需要花时间理解。
2.1 混合精度训练时显存占用分析
对于数值类型为 FP32 的大模型,训练时,为了加快训练速度和降低显存占用,常常使用混合精度训练。若有一个参数量是 Φ \Phi Φ 的模型,且数据类型是 FP32,假设我们对其进行全量微调,使用混合精度训练,优化器使用 AdamW,那么它的显存占用该如何计算?
训练时,显存占用主要分两块,一块是模型状态,一块是激活值。
模型状态包含了模型权重、模型梯度、优化器状态。在混合精度训练时,模型会转换成 FP16,同时在优化器中维护一套 FP32 的模型权重副本,模型在反向传播后,会得到一套 FP16 梯度,AdamW 优化器还会为每个参数的梯度增加一阶动量(momentum)和二阶动量(variance),两种动量都是 FP32,也就是说,在混合精度训练时,模型权重和梯度都是 FP16 精度,优化器的权重副本、一阶动量、二阶动量都是 FP32 精度。
先不考虑分布式,那么在混合精度训练时,模型状态占用的显存为 2 Φ + 2 Φ + 4 Φ + 4 Φ + 4 Φ = 16 Φ 2 \Phi+2 \Phi+4 \Phi+4 \Phi+4 \Phi=16 \Phi 2Φ+2Φ+4Φ+4Φ+4Φ=16Φ,单位为字节。公式中的五项分别是模型权重、梯度、优化器中的权重副本、一阶动量、二阶动量,后三项被称为优化器状态,可以看到,优化器状态占比达到 75%。假设我们考虑分布式数据并行,那么每张卡上都会有一个模型,每张卡上都会更新参数,因此都会有一个优化器,所以每张卡都会占用 16 Φ 16 \Phi 16Φ G 的显存。
1G的空间可以存储 1024x1024x1024=1073741824 字节(10.73亿字节),如果一个参数用一个字节表示,那么 1B 的参数量耗费的显存大概是 0.93 G,为了方便计算,四舍五入为 1G。在 FP32 精度下,一个参数占四个字节,那么 1B 的参数量耗费的显存是 4G,FP16下则为 2G。GPT-2含有1.5B个参数,那么按照上面的公式,会占用 24B 的显存,约为 24 G。
激活值这块不太好计算,跟模型架构相关,而激活值可以采用梯度检查点技术,大大减少显存占用。
总的来说,模型状态占据了显存的大头,而 AdamW 优化器状态优势模型状态的大头。
2.2 分片(Partition)
如果有N张卡,在数据并行的情况下,系统中就存在N份模型参数,其中N-1份都是冗余的,我们有必要让每张卡都存一个完整的模型吗?系统中能否只有一个完整模型,每张卡都存 1/N 参数,卡数越多,每张卡的显存占用越少,这样的话,就能训练更大规模的模型了。
针对模型状态的存储优化(去除冗余),ZeRO使用的方法是分片(partition),即每张卡只存 1 N \frac{1}{N} N1 的模型状态量,这样系统内只维护一份模型状态。
-
首先进行分片操作的是模型状态中的Adam,也就是下图中的 P o s P_{os} Pos,这里os指的是optimizer states。模型参数(parameters)和梯度(gradients)仍旧是每张卡保持一份,此时,每张卡的模型状态所需显存是 4 Φ + 12 Φ N 4\Phi + \frac{12\Phi}{N} 4Φ+N12Φ 字节,当 N N N 比较大时,趋向于 4 Φ B 4\Phi B 4ΦB,也就是原来 16 Φ B 16\Phi B 16ΦB 的 1 4 \frac{1}{4} 41。这就是 ZeRO-1。
-
如果继续对模型梯度进行分片,也就是下图中的 P o s + g P_{os+g} Pos+g,模型参数仍旧是每张卡保持一份,此时,每张卡的模型状态所需显存是 2 Φ + 2 Φ + 12 Φ N 2\Phi + \frac{2\Phi + 12\Phi}{N} 2Φ+N2Φ+12Φ 字节,当 N N N 比较大时,趋向于 2 Φ B 2\Phi B 2ΦB,也即是原来 16 Φ B 16\Phi B 16ΦB 的 1 8 \frac{1}{8} 81。这就是 ZeRO-2。
-
如果继续对模型参数进行分片,也就是下图中的 P o s + g + p P_{os+g+p} Pos+g+p,此时每张卡的模型状态所需显存是 16 Φ N \frac{16\Phi}{N} N16Φ 字节,当 N N N 比较大时,趋向于 0 0 0。这就是 ZeRO-3。
下图中Memory Consumption 第二列给出了一个示例: K = 12 , Φ = 7.5 B , N = 64 K = 12, \Phi = 7.5B, N = 64 K=12,Φ=7.5B,N=64,可以看到显存优化相当明显。
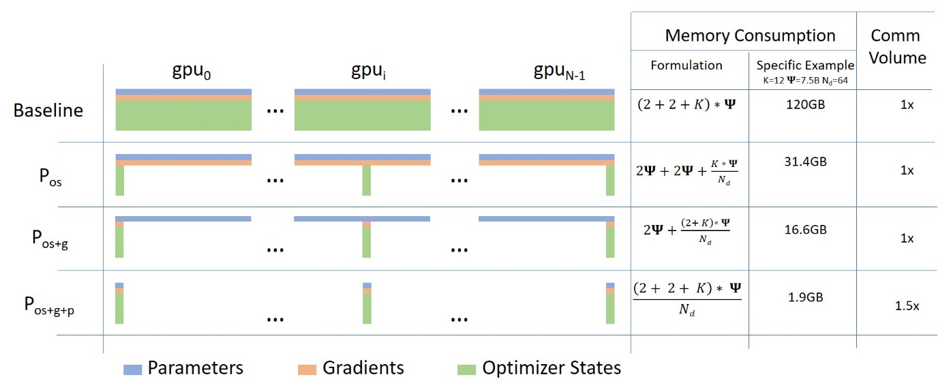
可以看到,前两个分片策略都还是数据并行,因为模型参数还没拆分, P o s + g + p P_{os+g+p} Pos+g+p 分片策略则是把模型权重也拆分到了多张卡上,已经算是模型并行了。所以,ZeRO 是一种混合并行策略,在数据并行的基础上进行模型并行。
注意,这里的分片并不是像前面介绍的流水线并行那样按层分片,也不是标准的张量并行,而是一种非常特殊的分片,我们接下来详细介绍。
2.3 ZeRO 中的分片与张量并行的区别( ZeRO-3 的工作机制)
我们用一个非常具体的矩阵乘法(GEMM)例子来说明 张量并行 (Tensor Parallelism) 和 ZeRO分片 (ZeRO Sharding) 在运作机制上的核心区别。
场景:
- 模型层:一个简单的全连接层 (Linear Layer),计算
Y = X * W。 - 输入
X: 维度4x4(4个样本,每个样本4维特征) - 权重
W: 维度4x8(输入4维,输出8维) - 输出
Y: 维度4x8 - 使用 2个GPU (GPU0, GPU1) 进行并行。
1. 张量并行 (Tensor Parallelism) - 以 Megatron-LM 的列并行为例
- 核心思想: 拆分计算。 将矩阵乘法
X * W的计算负载分担到多个 GPU 上。 - 参数分片策略:
- 将权重矩阵
W按列(输出维度)切割成 2 等份。 W = [W_left, W_right],其中W_left维度为4x4,W_right维度为4x4。- 分配:
- GPU0 存储
W_left(4x4)。 - GPU1 存储
W_right(4x4)。
- GPU0 存储
- 将权重矩阵
- 正向传播计算过程 (
Y = X * W):- 广播输入
X: 输入X(4x4) 广播给 GPU0 和 GPU1。 - 局部计算:
- GPU0 计算:
Y_part0 = X * W_left。 结果维度4x4。 - GPU1 计算:
Y_part1 = X * W_right。 结果维度4x4。
- GPU0 计算:
- 组合结果得到完整输出
Y:- 在计算输出的下一层(或者在本层输出前),需要将
Y_part0和Y_part1组合成完整的Y(4x8)。 - 这通常通过
All-Gather通信操作实现:GPU0 把Y_part0发给 GPU1,GPU1 把Y_part1发给 GPU0。结果每个 GPU 都拥有了完整的Y = [Y_part0, Y_part1](4x8)。
- 在计算输出的下一层(或者在本层输出前),需要将
- 广播输入
- 关键点:
- 计算是协作式的:每个 GPU 只计算一部分输出 (
Y_part0或Y_part1),单独无法得到完整Y。 - 通信发生在计算过程中(步骤3),为了组合计算结果。
- 通信量主要取决于输入
X和输出Y的大小。 - 目标是加速计算本身(并行计算矩阵乘法的各个部分)。
- 计算是协作式的:每个 GPU 只计算一部分输出 (
2. ZeRO分片 (ZeRO Sharding) - 主要展示 ZeRO 阶段3
- 核心思想: 减少冗余存储。 将模型状态(参数、梯度、优化器状态)分片存储,节省每个 GPU 的内存。
- 数据并行。 将4个样本分成两份,即两个 micro-batch,每个 micro-batch 的维度为
2x4,且每个 GPU 单独处理一个 micro-batch。 - 参数分片策略:
- 将权重矩阵
W(4x8) 按照其行优先或列优先展开后的整体看作一个向量(比如按行展开成一个长度为32的向量),然后将这个向量均匀地切分成 2 等份。 - 分成
shard0(包含W的前 16 个元素) 和shard1(包含W的后 16 个元素)。切片可以跨越原始维度,不一定按逻辑维度对齐。 - 分配:
- GPU0 存储
shard0(16个参数)。 - GPU1 存储
shard1(16个参数)。
- GPU0 存储
- 注意:实际实现分片粒度通常更粗(如按参数张量维度切分),但原理一样。ZeRO-3 会同时分片参数本身。
- 将权重矩阵
- 要分清两组概念:完整 与 分片 是对权重参数而言的,全局 与 局部 是对数据集而言的,全局是相对于所有数据(即两个micro-batch),局部是指在单个micro-batch上操作。
- 正向传播计算过程 (
Y = X * W):- 重建完整参数
W:- 为了计算
Y = X * W,每个 GPU 都需要完整的W矩阵。 - GPU0 和 GPU1 执行
All-Gather通信操作:GPU0 把shard0发给 GPU1,GPU1 把shard1发给 GPU0。 - 结果:GPU0 和 GPU1 都临时拥有了完整的
W矩阵 (4x8)。
- 为了计算
- 独立计算完整输出
Y:- GPU0 使用完整的
W和输入X(这里的输入是指一个 micro-batch ) 计算完整的Y0 = X * W(2x8)。 - GPU1 同样使用完整的
W计算完整的Y1 = X * W(2x8)。
- GPU0 使用完整的
- 丢弃非本地分片参数:
- 计算完成后,GPU0 丢弃
shard1,只保留shard0。 - GPU1 丢弃
shard0,只保留shard1。
- 计算完成后,GPU0 丢弃
- 重建完整参数
- 反向传播计算梯度 (
dL/dW = X^T * dL/dY):- 重建完整参数
W(如果需要?):- 计算参数梯度
dL/dW通常需要W本身(例如某些非线性激活的梯度计算会依赖W)。如果需要,则All-Gather再次发生(步骤同正向步骤1)。
- 计算参数梯度
- 计算完整局部梯度:
- 每个 GPU 使用完整的
W(如果需要)、完整的上游梯度dL/dY(每个 GPU 在自己的 micro-batch 上独立计算出来的) 和输入X(自己的 micro-batch) 独立计算出一个完整的参数梯度张量dL/dW_local(4x8)。dL/dW_local是基于该 GPU 上的局部数据计算出来的。
- 每个 GPU 使用完整的
- ReduceScatter 梯度:
- 每个 GPU 拥有一个完整的局部梯度
dL/dW_local(4x8)。 - GPU0 和 GPU1 执行
Reduce-Scatter通信操作:目的是将全局梯度dL/dW(4x8) 按分片规则(前16元素和后16元素)分布存储并求平均。- GPU0 将
dL/dW_local的shard0(前16元素) 发送给 GPU0,将shard1(后16元素) 发送给 GPU1。 - GPU1 同样将
dL/dW_local的shard0发送给 GPU0,将shard1发送给 GPU1。
- GPU0 将
- 结果:
- GPU0 接收所有发送给
shard0的碎片(来自 GPU0 和 GPU1 的dL/dW_local的前16元素),求平均得到全局梯度dL/dW的shard0(即dL/dW_shard0),所谓全局,指的是全部输入数据,它覆盖了两个 micro-batch 的数据。 - GPU1 接收所有发送给
shard1的碎片(来自 GPU0 和 GPU1 的dL/dW_local的后16元素),求平均得到全局梯度dL/dW的shard1(即dL/dW_shard1)。
- GPU0 接收所有发送给
- 完成后,每个 GPU 只存储自己负责的那部分全局梯度。
dL/dW_local传递给下游后被丢弃。
- 每个 GPU 拥有一个完整的局部梯度
- 重建完整参数
- 更新权重参数:
- 每个 GPU 计算自己所在分片上梯度的一阶动量(momentum)和二阶动量(variance),按照 Adam 算法更新分片参数
- GPU0 只计算
dL/dW_shard0的一阶动量和二阶动量,然后按照 Adam 算法更新shard0参数(前16个参数)。 - 同理,GPU1 只计算
dL/dW_shard1的一阶动量和二阶动量,然后按照 Adam 算法更新shard1参数(后16个参数)。
- GPU0 只计算
- 每个 GPU 计算自己所在分片上梯度的一阶动量(momentum)和二阶动量(variance),按照 Adam 算法更新分片参数
- 关键点:
- 计算是独立的:在获得完整参数
W后,每个 GPU 都能独立完成整个矩阵乘法 (Y = X * W),计算出完整的输出Y(针对其本地数据)。 - 通信发生在计算前后(步骤1和反向步骤3),目的是 重建完整参数 和 分布聚合梯度。
- 通信量主要取决于参数
W和梯度dL/dW的大小。 - 目标是节省内存(每个 GPU 只存储部分参数/梯度/优化器状态)。
- ZeRO-3 中,因为参数也被分片了,所以更新完参数后,不需要参数同步。
- 计算是独立的:在获得完整参数
3. 总结对比 (张量并行 vs. ZeRO分片)
| 特征 | 张量并行 (Tensor Parallelism) | ZeRO分片 (ZeRO Sharding) |
|---|---|---|
| 主要目标 | 加速计算 (并行化大矩阵运算) | 节省内存 (减少参数/梯度/优化器状态冗余存储) |
| 计算方式 | 协作计算:每个GPU只计算输出的一部分。 | 独立计算:每个GPU需重建完整参数后计算整体输出/梯度。 |
| 是否依赖完整参数 | 否:每个GPU只看到部分参数,永远不持有完整参数。 | 是:计算时需要临时重建完整参数(All-Gather)。 |
| 通信目的 | 组合局部结果 (得到完整层输出) | 重建完整参数 (All-Gather) 或 分布聚合梯度/参数 (Reduce-Scatter/All-Gather) |
| 通信触发时机 | 计算过程之中 (层内通信) | 计算过程之前/之后 (层间通信) |
| 参数物理存储 | 按逻辑维度切分 (如行、列)。 | 将参数视为大向量均匀切分。 |
| 通信量主要来源 | 输入(X)/输出(Y)大小相关。 | 参数(W)/梯度(dL/dW)大小相关。 |
| 内存优势 | 可以显著减少当前计算所需的峰值激活值内存 (因为只计算局部输出)。 | 可以线性减少参数、梯度、优化器状态内存(ZeRO-1/2/3)。 |
一句话直击核心:
- 想象张量并行是几个工人(GPU)合作组装一辆汽车(计算层输出),每个工人只负责组装一部分零件(部分计算)。
- 想象ZeRO分片是几个仓库管理员(GPU)各自保管一部分汽车蓝图(参数分片)。当工程师(GPU自己)需要按蓝图组装一辆车(计算层输出)时,必须先从所有管理员那里借来全套蓝图(
All-Gather参数),组装完后立刻把借来的蓝图还回去(丢弃非本地分片),同时管理员只保管和自己有关的那部分维修指南更新记录(梯度分片)。管理员从不组装车,工程师组装车也不需要其他工程师帮忙。
2.4 ZeRO-3 + QLoRA
前面介绍的分片规则是在全量微调的情况下的,但大模型中用的最多的是 QLoRA 微调,在 QLoRA 微调的情况下,ZeRO-3 是否要对主模型分片,还是说只对低秩适配器进行分片。
我问了一下 GPT-4o 和 DeepSeek,得到的结论是,主模型参数仍然需要分片,并且NF4量化是在分片前完成,但主模型没有对应的优化器状态(参数副本、一阶动量、二阶动量)和梯度,只有适配器有对应的优化器状态和梯度。主模型分片后,当需要前向传播时,通过通信动态收集所需分片,过程和 ZeRO-3 没差。
显存占用对比:
| 组件 | LoRA without ZeRO | LoRA + ZeRO-3 | QLoRA + ZeRO-3 |
|---|---|---|---|
| 主模型参数 | 全精度存储 | 分片存储(全精度) | 分片存储(4-bit 量化) |
| 适配器参数 | 全精度存储 | 分片存储(全精度) | 分片存储(全精度) |
| 优化器状态 | 仅适配器 | 分片存储(仅适配器) | 分片存储(仅适配器) |
| 梯度 | 仅适配器 | 分片存储(仅适配器) | 分片存储(仅适配器) |
2.5 ZeRO-1、 ZeRO-2的过程
上面介绍了 ZeRO-3 的工作机制,掌握了 2.3 节之后,对 ZeRO 的分片算是有了深入的理解了,我们这里简单讲一下ZeRO-1与 ZeRO-2。
在ZeRO-1中,只有优化器状态被分片。正向传播和反向传播与普通数据并行无异,反向传播后,每个GPU会得到对应micro-batch上的完整局部梯度(是完整的,但却是局部的),然后使用 All-Reduce 操作将所有 GPU 上的梯度进行求和与平均,得到全局聚合后的梯度。虽然每个 GPU 拥有全局聚合后的完整梯度副本,但仅对分片相关的参数进行更新(例如只更新参数的 1/N 部分),更新按照 Adam 算法。更新完成后,通过All-Gather 操作将所有 GPU 的参数更新结果汇总,确保每个 GPU 在下一轮迭代中拥有完整的、更新后的模型参数副本。它和普通数据并行有两个区别:1.每张卡只更新部分参数;2.更新后还要把每张卡的更新结果汇总,实现参数同步。
在 ZeRO-2 中,梯度和优化器状态都被分片。正向传播与普通数据并行无异,反向传播时,每个GPU会得到对应micro-batch上的完整局部梯度,然后通过 Reduce-Scatter 将梯度分片分发出去,每个GPU得到对应分片上的全局梯度,然后使用优化器更新参数,参数更新后,不同分片之间通过All-Gather同步参数。它和ZeRO-1的区别只有梯度,ZeRO-1是每张卡上都有一份完整的全局梯度副本,而ZeRO-2是每张卡上只有分片的全局梯度副本。
2.6 ZeRO-1、ZeRO-2、ZeRO-3 的对比
下面是 ZeRO-1、ZeRO-2、ZeRO-3 的对比:
| 特性 | ZeRO-1 (Optimizer State Partitioning) | ZeRO-2 (Gradient Partitioning) | ZeRO-3 (Parameter Partitioning) |
|---|---|---|---|
| 分区对象 | 仅优化器状态( P o s P_{os} Pos) | 优化器状态 + 梯度( P o s + P g P_{os} + P_g Pos+Pg) | 优化器状态 + 梯度 + 参数( P o s + P g + P p P_{os} + P_g + P_p Pos+Pg+Pp) |
| 参数存储 | 每个GPU存完整参数副本 | 每个GPU存完整参数副本 | 分片存储:每个GPU存参数的 1/N |
| 梯度存储 | 每个GPU存完整梯度 | 分片存储:梯度计算后通过 ReduceScatter 分片保存 | 分片存储:梯度计算后通过 ReduceScatter 分片保存 |
| 优化器状态存储 | 分片存储:每个GPU存 1/N 的优化器状态 | 分片存储:每个GPU存 1/N 的优化器状态 | 分片存储:每个GPU存 1/N 的优化器状态 |
| 正向传播 | 无通信,本地计算 | 无通信,本地计算 | AllGather 参数 → 计算 → 丢弃非本地分片 |
| 反向传播 | 计算完整局部梯度 → AllReduce 聚合梯度 | 计算完整局部梯度 →ReduceScatter 分片全局梯度 | 计算完整局部梯度 → ReduceScatter 分片全局梯度 |
| 参数更新 | 本地更新完整参数 | 本地更新完整参数 | 本地更新分片参数(无需同步) |
| 内存节省关键 | 优化器状态减少至 1/N | 梯度 + 优化器状态减少至 1/N | 参数 + 梯度 + 状态均减少至 1/N |
| 通信开销 | 低(仅梯度 AllReduce) | 中(AllGather + ReduceScatter) | 高(频繁 AllGather 远程参数) |
| 适用模型规模 | 十亿级(~1B) | 百亿级(~10-100B) | 千亿/万亿级(>100B) |
作为AI应用开发工程师,我们一般都是对20B以下模型进行微调,而 ZeRO-3 的通信开销高,虽然节约显存,但会导致训练时间变长,因此一般推荐使用 ZeRO-2 的方式,这样在显存和通信之间达到了一个平衡。
3 ZeRO-Offload
在提出 ZeRO 的论文《ZeRO: Memory Optimizations Toward Training Trillion Parameter Models》中提到过 CPU-Offload,其主要思想是:当GPU显存(HBM)不足以容纳某些张量(特别是优化器状态,如Adam的动量和方差)时,将这些张量卸载(Offload)到CPU的主内存(RAM)中存储,在需要优化器状态和权重参数时,将存储在CPU RAM中的优化器状态临时拷贝回GPU,计算完成后,将更新后的优化器状态(如果需要保留)再次拷贝回CPU RAM存储,而模型参数和梯度则始终保留在GPU上(尤其是使用ZeRO-2或ZeRO-3进行分片时)。
本质上,这种 Offload 策略是显存不足时利用更大的CPU RAM作为“溢出”存储,核心的优化器计算(如Adam更新)仍然在GPU上进行,CPU主要扮演存储角色。这使得每次更新参数时,都需要在CPU和GPU之间传输卸载的张量(通常是优化器状态),对于像Adam这样需要维护两个额外状态(动量、方差)的优化器,这个传输量是参数量的3倍(参数本身、动量、方差),所以导致通信开销大,这是主要的性能瓶颈。
21年发表的《ZeRO-Offload: Democratizing Billion-Scale Model Training》则提出了一种系统性的、革命性的Offload方案,该方案不仅仅把CPU当作被动存储,而是将CPU视为一个计算资源,与GPU协同工作。它精细地划分了训练计算图,将计算密集度相对较低但内存密集度高的部分(主要是优化器步骤)卸载到CPU上执行,同时保留计算密集度高的部分(前向传播和反向传播)在GPU上执行。接下来我们介绍一下 ZeRO-Offload 的原理。
下面的示意图中,圆形节点表示状态信息,比如模型参数、梯度、激活值、优化器状态,矩形节点表示计算操作,比如前向计算、后向计算、参数更新、精度转换,箭头表示数据流向。
我们先来说一下单卡的情形。下图是某一层的一次迭代过程(iteration/step),使用了混合精读训练,优化器使用 Adam,优化器状态都是FP32。可以看到,前向计算(FWD)需要用到上一层的激活值(activation)和本层的参数(parameter),反向传播(BWD)需要用到本层参数和本层激活值计算梯度,这里激活值、参数和梯度都是FP16,参数更新(Param Update)需要用到反向传播时计算得到的梯度,以及模型状态(32位参数、动量、方差),精度转换(float2half,中间的2指的是to的意思)需要FP32的参数。
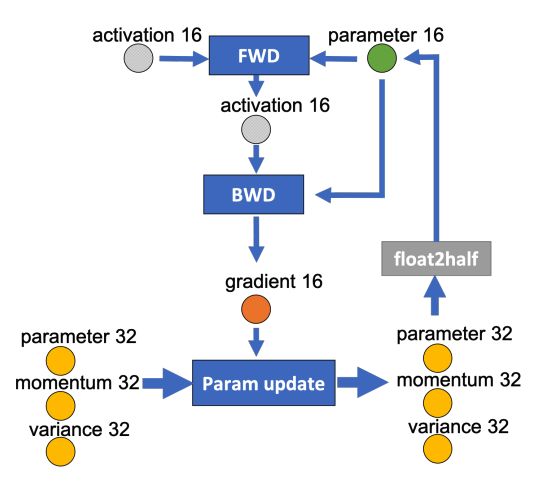
接下来我们给箭头加上通信量,假设这一层的参数量为 M,那么在混合精度训练的过程中,FP16 参数、梯度所占空间大小均为 2M 字节,FP32 参数、动量、方差所占空间均为 4M 字节,示意图如下:
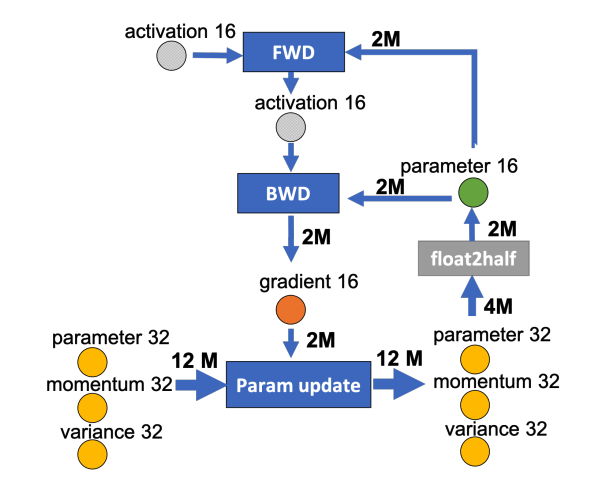
我们现在要做的就是沿着边把数据流图切分为两部分,分布对应GPU和CPU,计算节点(矩形节点)落在哪个设备,哪个设备就执行计算,数据节点(圆形)落在哪个设备,哪个设备就负责存储,被切开的箭头指向了CPU与GPU之间的通信方向,这些箭头上的数据量之和,就是CPU和GPU的通信数据量。示意图如下:
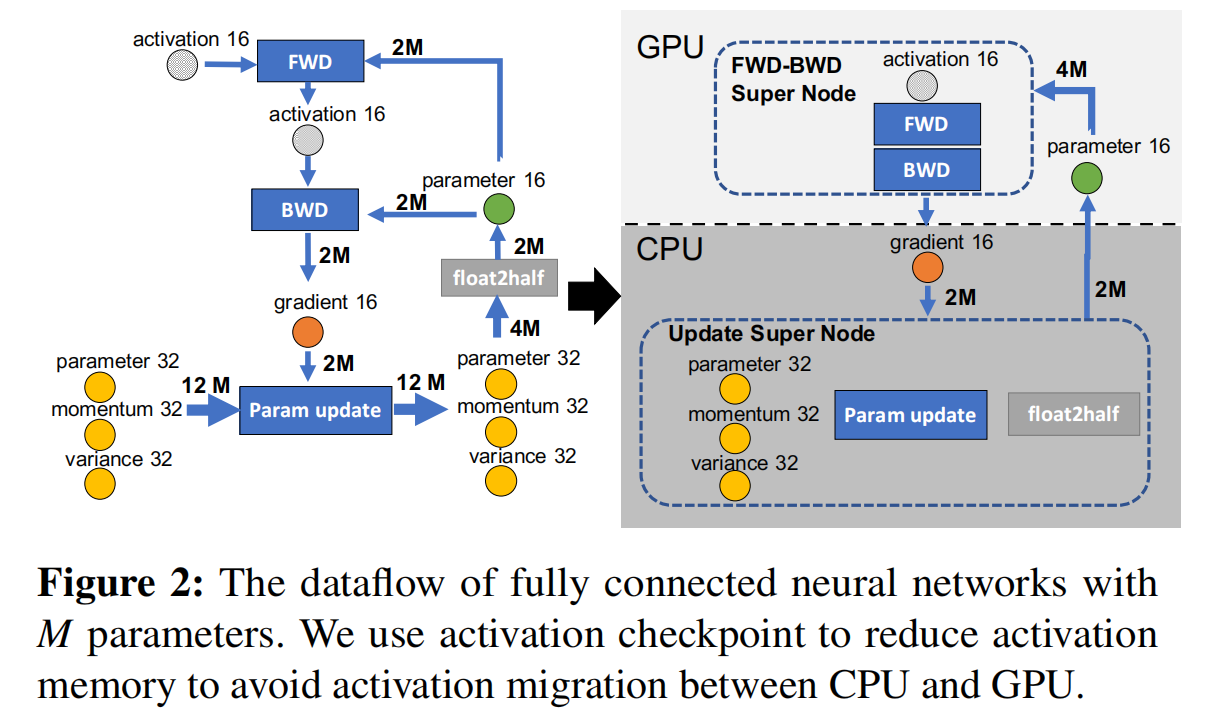
图中有四个计算类节点:FWD、BWD、Param update 和 float2half,前两个计算复杂度大致是 O(MB) , B 是batch size,后两个计算复杂度是 O(M)。为了不降低计算效率,将前两个节点放在GPU,后两个节点不但计算量小还需要和Adam状态打交道,所以放在CPU上,Adam状态自然也放在内存中。为了简化数据图,将前两个节点融合成一个节点FWD-BWD Super Node,将后两个节点融合成一个节点Update Super Node。如上图右边所示,沿着 gradient 16 和 parameter 16 两个箭头切分。
现在的计算流程是,在GPU上面进行前向和后向计算,将梯度传给CPU,进行参数更新,再将更新后的参数传给GPU。为了提高效率,可以将计算和通信并行起来,GPU在反向传播阶段,可以待梯度值填满bucket(bucket是一个缓存容器)后,一边计算新的梯度一边将bucket传输给CPU。当反向传播结束,CPU基本上已经有最新的梯度值了,同样的,CPU在参数更新时也同步将已经计算好的参数传给GPU,如下图所示(下图橙色块画错了,应该是 CPU->GPU):
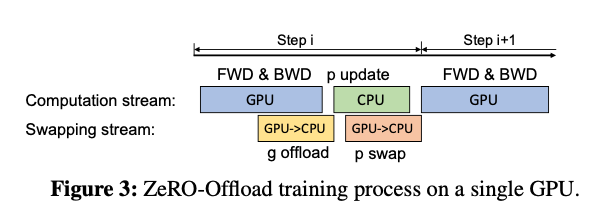
现在我们讨论一下多卡的情况。在多卡场景下,ZeRO-Offload 利用了 ZeRO-2 (也可以是 ZeRO-3,但不能是 ZeRO-1,因为 ZeRO-1没有对梯度分片),由于 ZeRO-2 是将Adam状态和梯度进行了分片,每张卡只保存 1 N \frac{1}{N} N1 ,而 ZeRO-Offload 做的同样是将这 1 N \frac{1}{N} N1 的Adam状态和梯度都offload到内存,在CPU上进行参数更新。注意:在多卡场景,利用CPU多核并行计算,每张卡至少对应一个CPU进程,由这个进程负责进行局部参数更新。 并且CPU和GPU的通信量和 N 无关,因为每张卡与CPU传输的只是局部参数,总的传输量是固定的,由于利用多核并行计算,每个CPU进程只负责 1 N \frac{1}{N} N1 的计算,随着卡数增加,每个CPU进程处理的参数量变少,反而节省了CPU计算时间。
下面是在DGX-2服务器(NVIDIA DGX-2™ 是英伟达推出的高性能AI服务器,有16张V100显卡,总显存达到512G,且使用了NVswitch技术,使芯片间通信效率达300GB/s)上,各种并行方式能训练的最大尺寸模型:
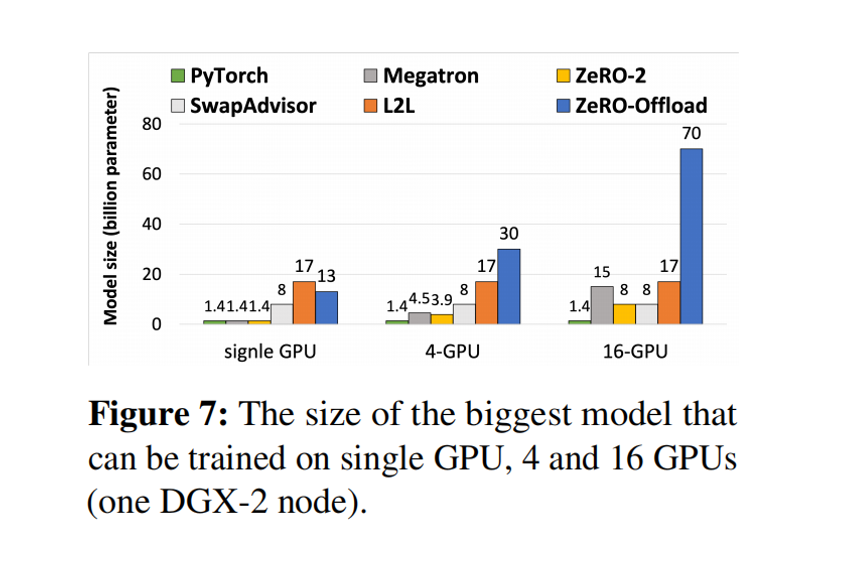
可以看到,GPU越多,ZeRO-Offload的能力就越夸张。
关于 ZeRO-Offload 中的梯度,它是不是在GPU有也有一份呢?不是的,ZeRO-Offload 中的梯度存储机制如下
-
GPU 的短期持有:
- 在反向传播阶段,GPU 会计算梯度并通过 reduce-scatter 操作在 GPU 上完成梯度平均。
- 此过程中,梯度短暂存在于 GPU 显存中(用于计算和平均操作),但不会长期保存,当梯度被传输到CPU后,GPU 释放该梯度分片的显存。
-
CPU 的长期存储:
- 平均后的梯度仅属于每个 GPU 的特定分区,这些分区会被卸载(offload)到 CPU 内存中。
- CPU 内存持久保存这些梯度,用于后续优化器状态更新。
-
关键结论:
- ❌ GPU 不会长期保存梯度副本(仅在计算过程中暂时持有)。
- ✅ CPU 是梯度的唯一持久化存储位置(卸载后的梯度用于更新优化器状态)。
- 🔄 梯度在 GPU 计算后即被转移到 CPU,不存在 GPU 和 CPU 同时保存同一份完整梯度的情况。
4 在 LLaMA-Factory 和 Xtuner 中进行分布式微调
4.1 DeepSpeed框架介绍
DeepSpeed 是由 Microsoft 开发的一个开源的深度学习优化库,它的核心目标是让大规模深度学习模型的训练变得更高效、更快速、更具成本效益,并且更容易上手,特别是针对那些参数量达到数十亿甚至万亿级别的超大模型(如 GPT-3、Turing-NLG、MT-NLG 等)。
简单来说,它就是一个集成了 ZeRO 和 ZeRO-Offload 技术的分布式训练框架,让训练“庞然大物”变得可行、高效。
当然,像 LLaMA-Factory、Xtuner 这些大模型训练框架已经把 DeepSpeed 集成进去了,我们不需要去学这个框架了。
4.2 LLaMA-Factory
现在我租了两张P40的显卡,每张卡的显存都是24G,现在我们在 LLaMA-Factory 上测试一下分布式微调。这里我们做四个实验,第一个是不使用 ZeRO 技术,用最原始的数据并行,第二个是使用 ZeRO-2,但不使用 ZeRO-Offload 技术,第三个是使用 ZeRO-2 和 ZeRO-offload,第四个是使用 ZeRO-3,但不使用 ZeRO-Offload。我们并不是要训练完,而是对比三种方式的显存、CPU、内存的资源占用情况。
实验一:数据并行
第一个实验的参数配置如下:
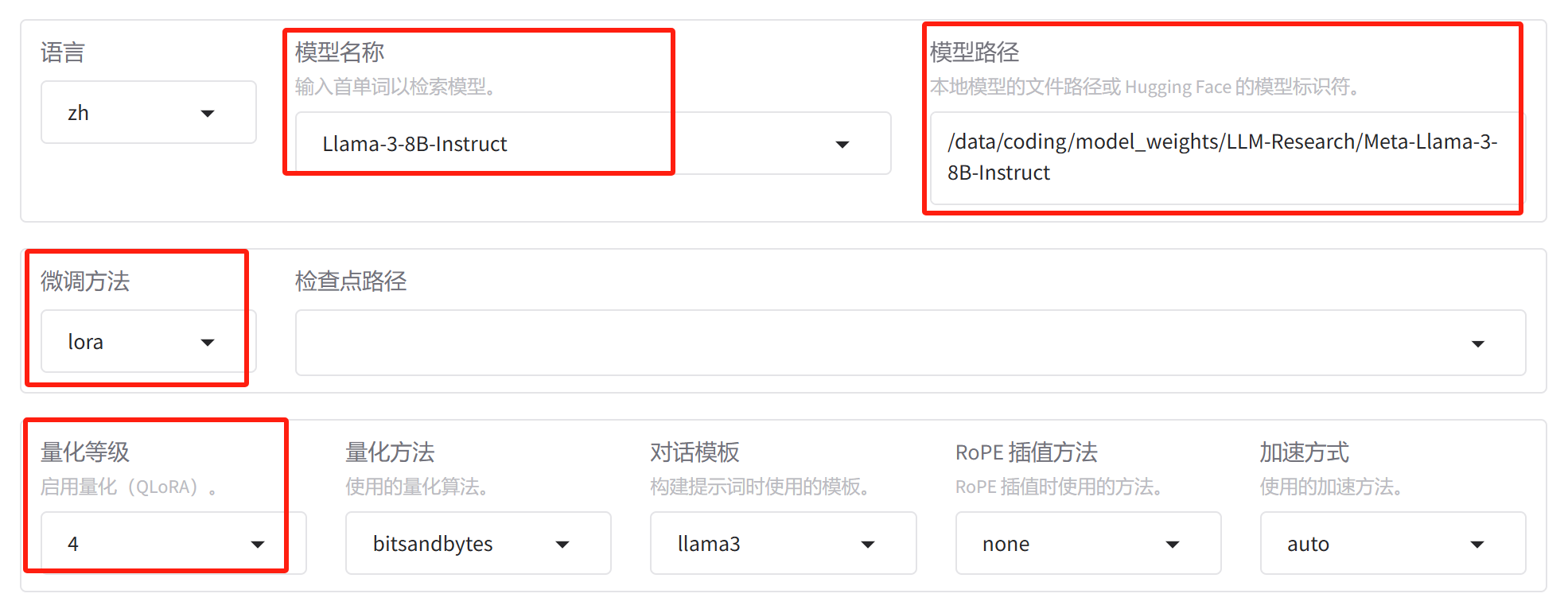
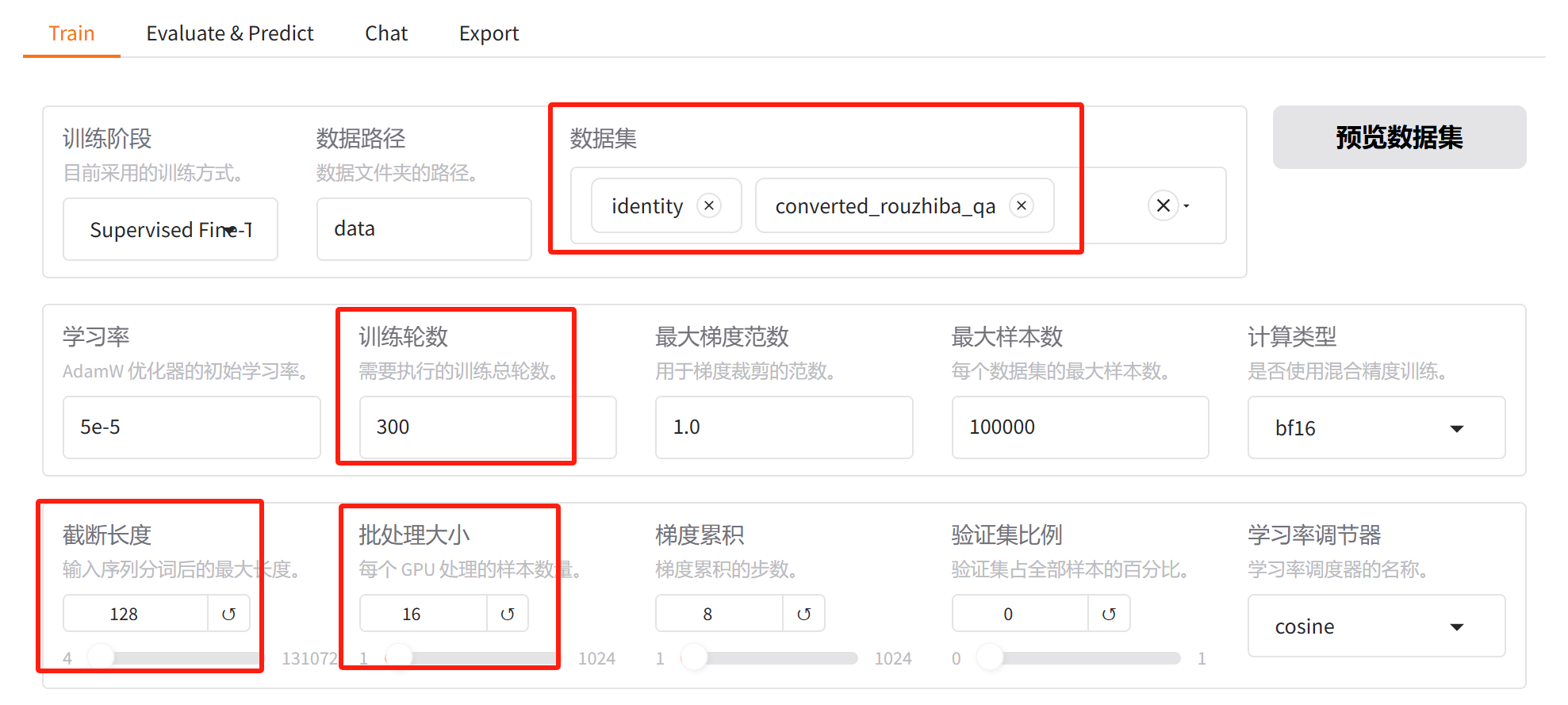
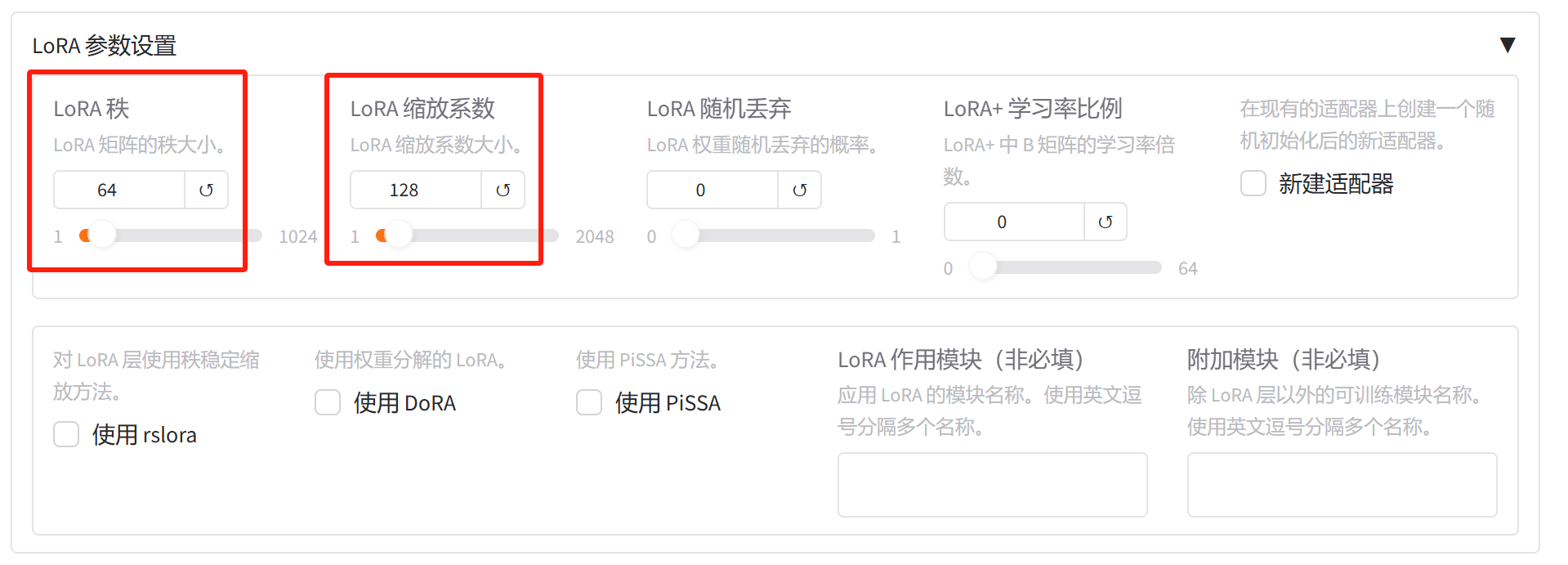
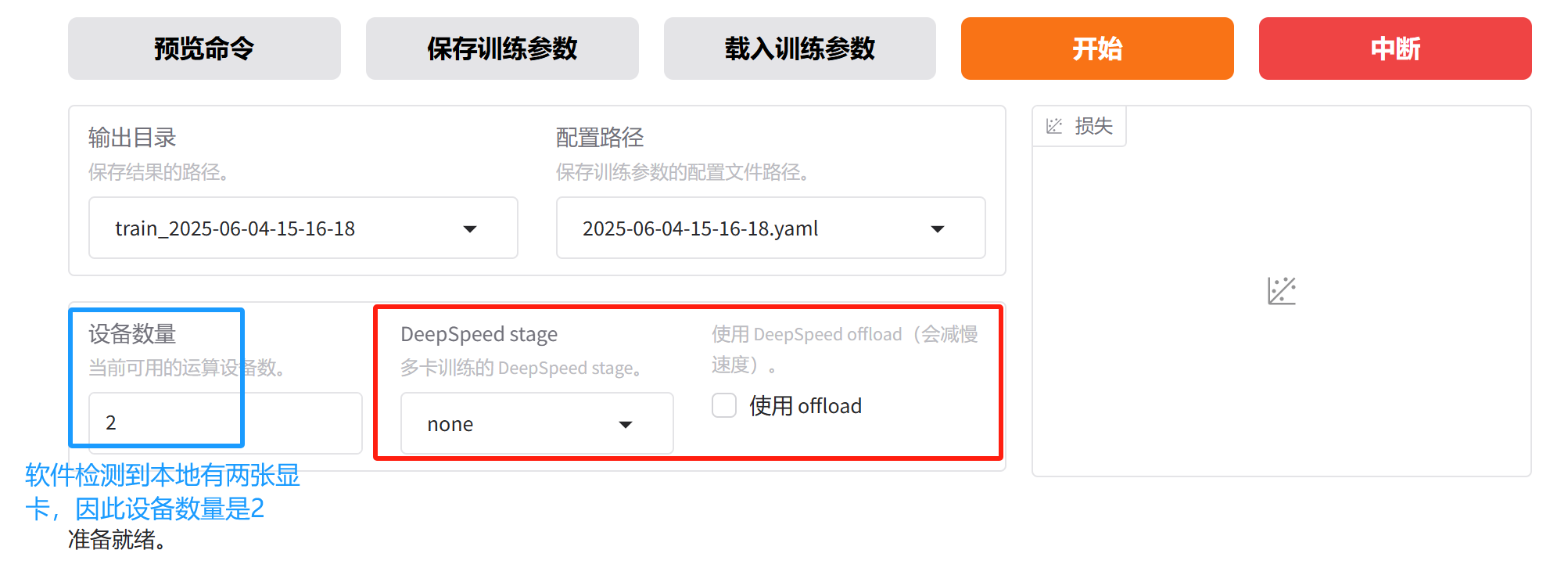
接下来点击开始。
打开一个新的终端,输入 nvitop 查看资源占用情况:
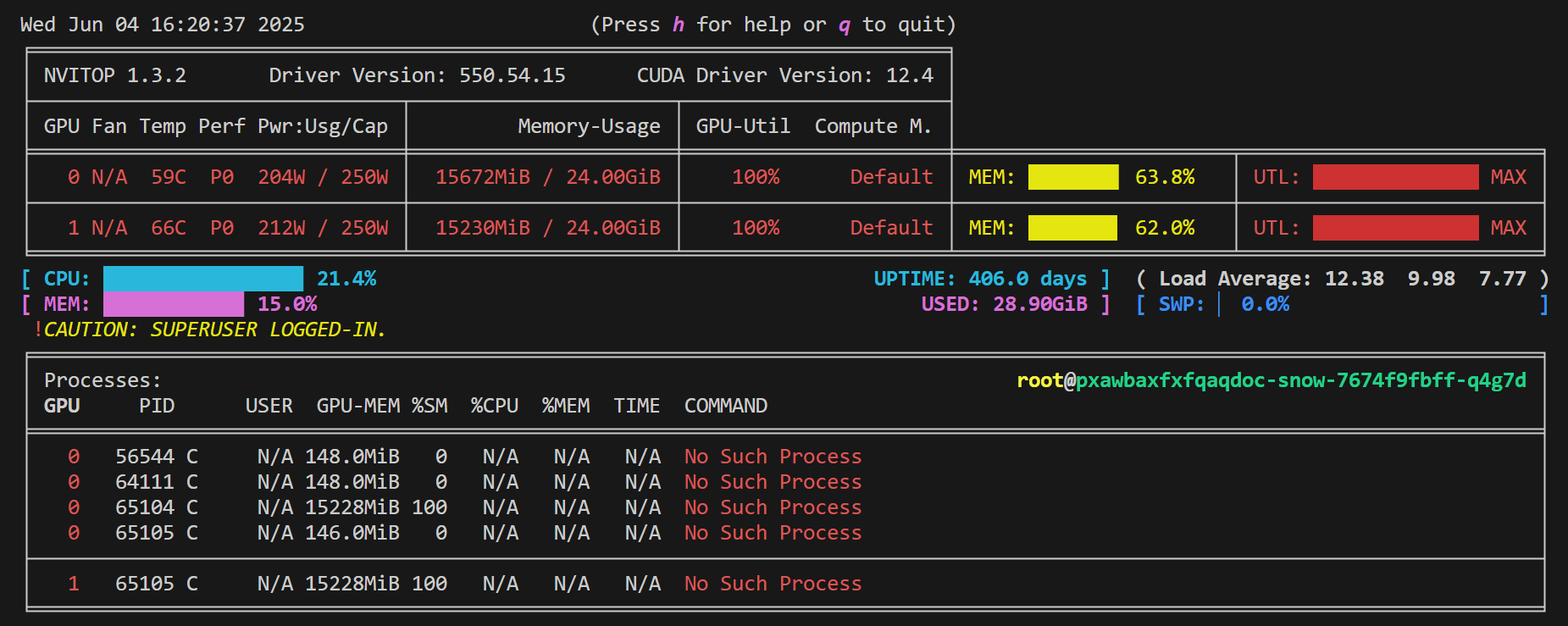
可以看到,两块GPU的显存占用都超过了 60%,内存占用只有 15%,CPU利用率只有 21.4%,当然,这些数值都会有小范围的波动,但波动幅度都比较小。
实验二:ZeRO-2
这里使用了 ZeRO,需要安装 deepspeed:pip install deepspeed
参数配置和实验一一致,只有最后的 DeepSpeed Stage,我们选择 ZeRO-2,然后点击开始。
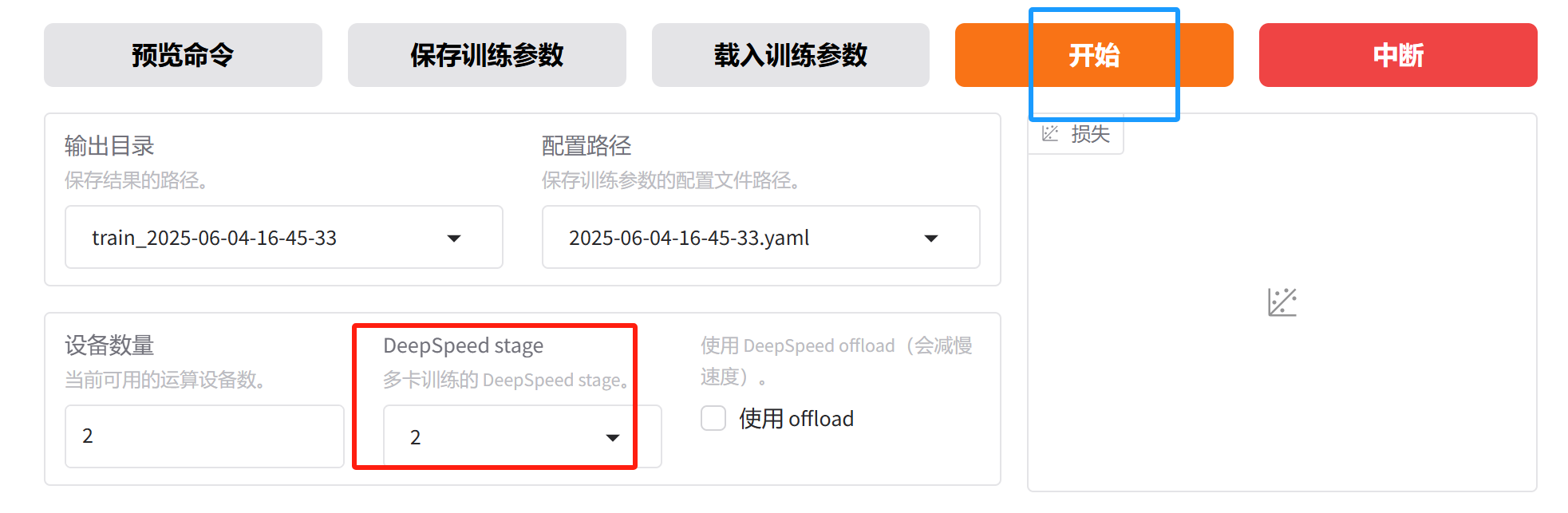
资源占用情况如下:
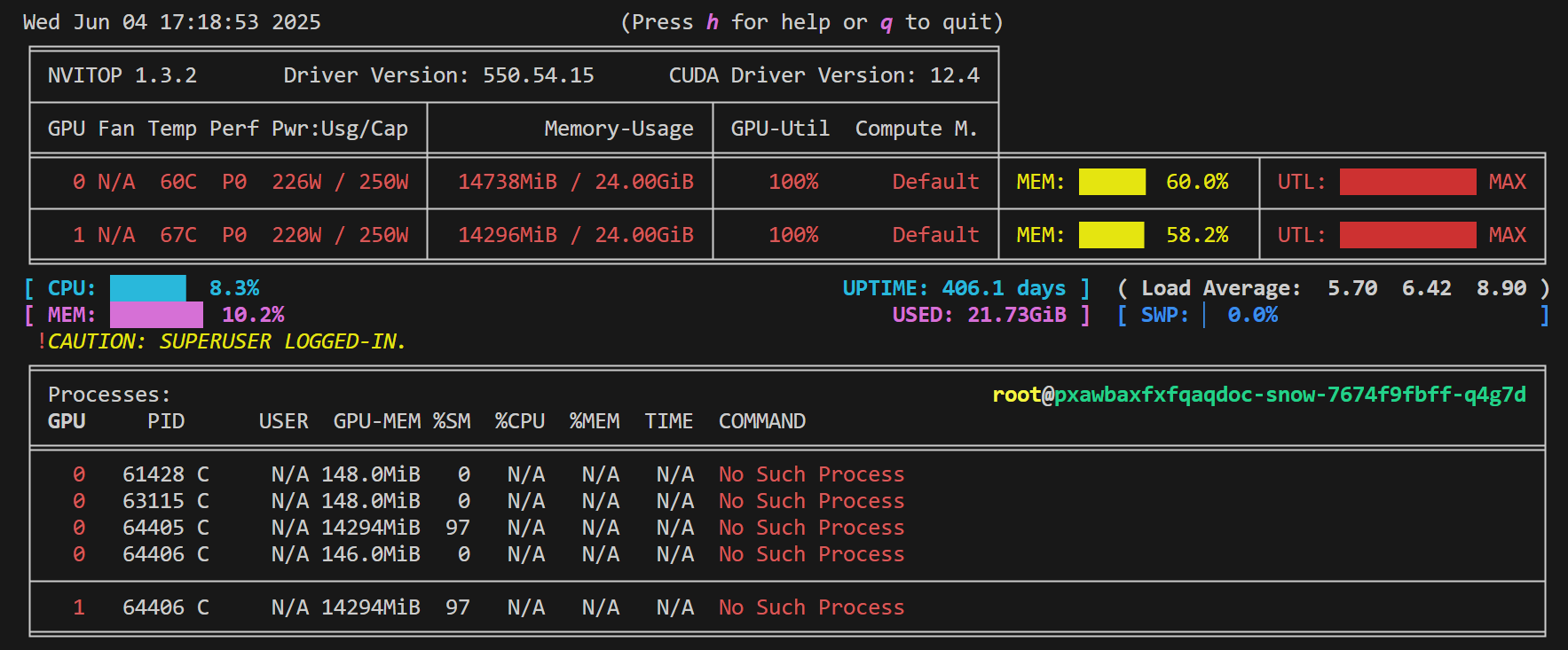
好像并没有节约多少资源。这是因为微调用的是QLoRA,可训练参数只有 167772160,对应梯度占用的显存为0.313G,优化器状态为1.878(权重副本、一阶动量、二阶动量各占0.626G),梯度和优化器状态被分片,每张卡只能节约 (0.313 +1.878) / 2 = 1.0955 G,这是理论值,实际上每张卡节约了934M显存,为啥不一样,我也不知道,但实际值和理论值很接近了。
实验三:ZeRO-2 + ZeRO-Offload
参数配置和实验二一致,只有最后的 DeepSpeed Stage,我们选择 ZeRO-2,并使用 offload,然后点击开始。
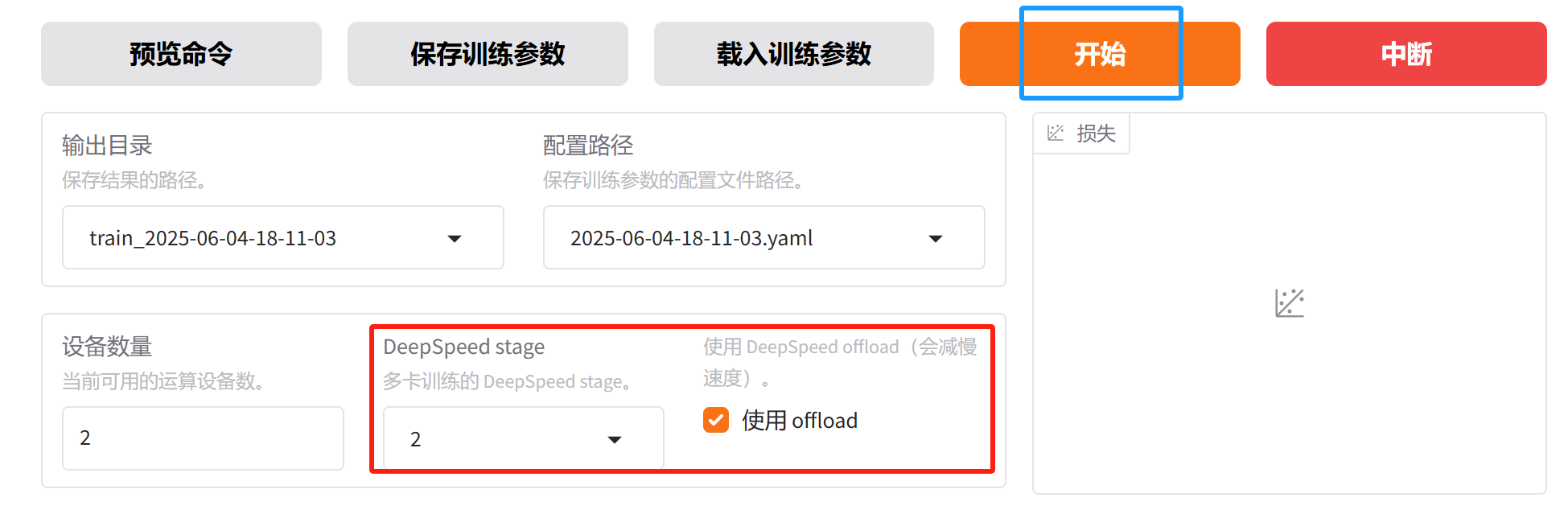
资源占用情况如下:
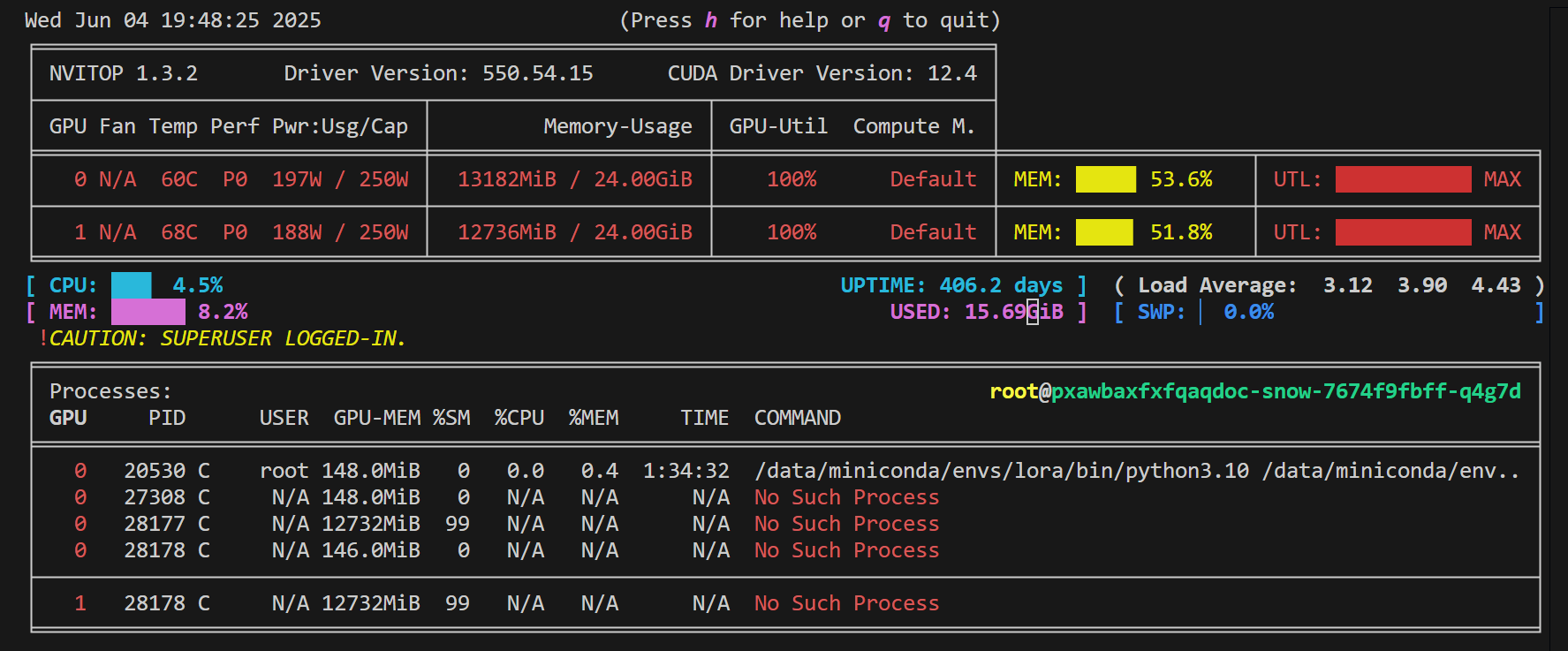
可以看到,使用 ZeRO-2 + ZeRO-Offload,相比于纯 ZeRO-2,每张卡的显存节约了 1.5 G。
实验四:ZeRO-3
参数配置和实验二一致,只有最后的 DeepSpeed Stage,我们选择 ZeRO-3,然后点击开始。
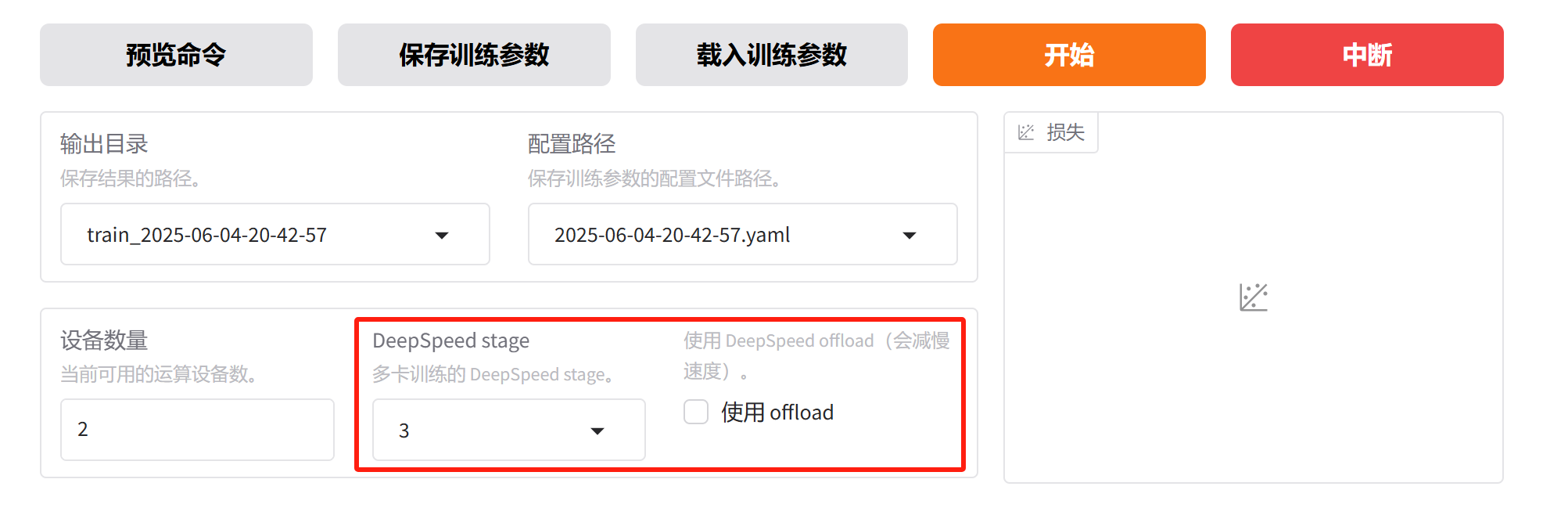
报错!
[rank0]: NotImplementedError: Cannot copy out of meta tensor; no data! Please use torch.nn.Module.to_empty() instead of torch.nn.Module.to() when moving module from meta to a different device.
我问了AI,回复说要修改模型加载方式,这个在 WebUI 界面上没法改。
我看 Hugging Face 上介绍 PEFT 的教程中,有一节专门介绍了 DeepSpeed,上面有个案例是讲 QLoRA + ZeRO3 微调 Llama-2-70b 的,里面讲了环境要求:bitsandbytes>=0.43.3、accelerate>=1.0.1、transformers>4.44.2、trl>0.11.4 和 peft>0.13.0。而我的 LLaMA-Factory 环境中,trl 为 0.9.6,peft 为0.12.0,而我的 llamafactory 0.9.2 又要求 trl<=0.9.6,>=0.8.6,所以我的环境暂时是无法满足要求的。我自己估计应该是这个原因,导致我的服务器上无法实现 QLoRA + ZeRO3,反正工作中也基本用不到 ZeRO-3,那这个就先不管它了。
我换成 Qwen1.5-0.5B-Chat,这个模型比较小,然后改成全量微调,对比了纯数据并行和使用 ZeRO-3 的显存占用情况,相对于纯数据并行,ZeRO-3 显存节约还是很明显的。
实验总结
在使用 QLoRA 微调的时候,由于可训练参数比较少,使用 ZeRO 确实能节约显存,但节约的不是很多。我用 8B 的模型做实验,使用 ZeRO-2 比原始的数据并行,每张卡显存也就少了不到1个G,ZeRO-3 我没跑通,我也不知道能省多少显存。
4.3 Xtuner
Xtuner 的文档中,有介绍使用 DeepSpeed 对大模型进行分布式微调:
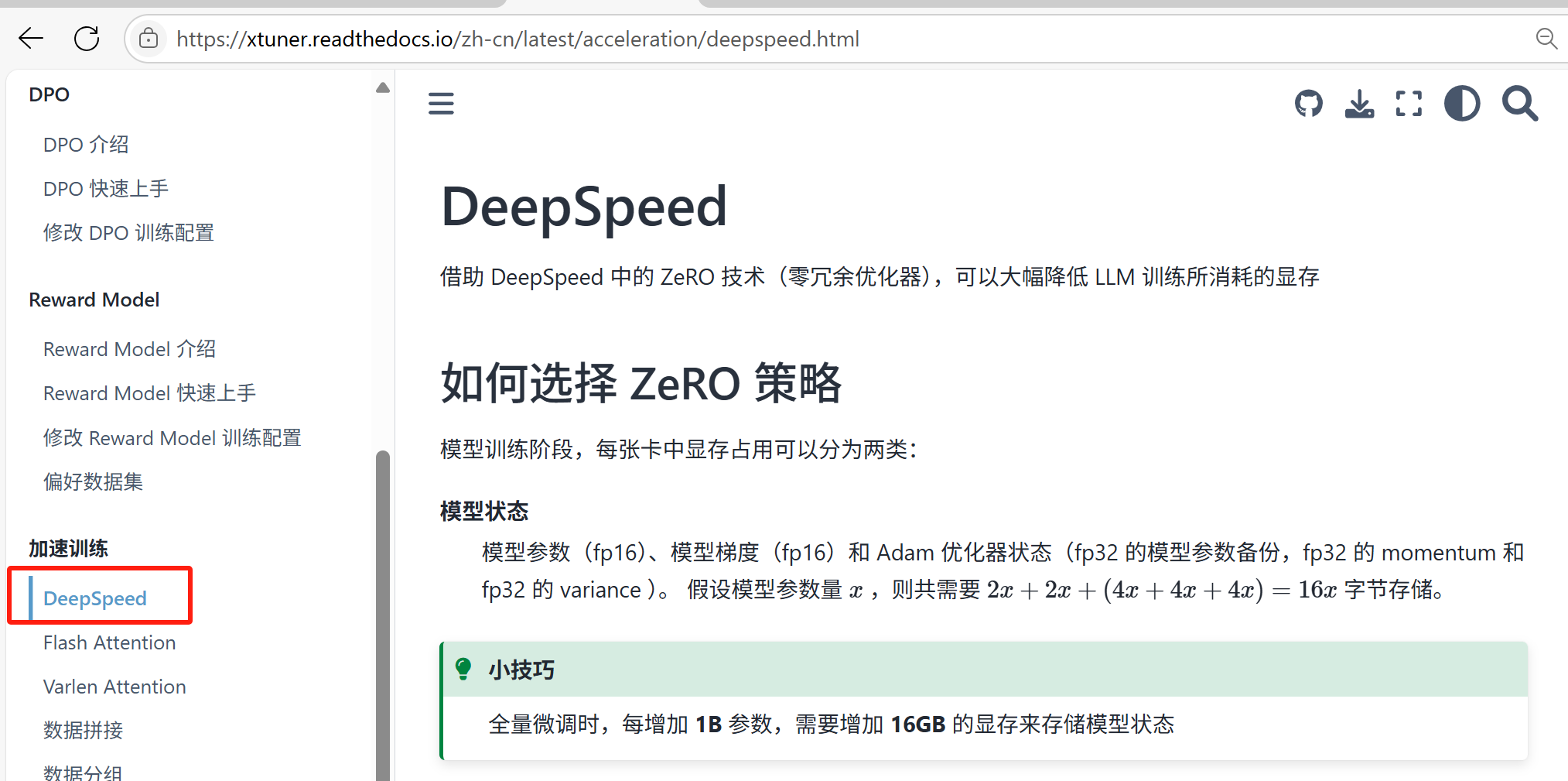
下面介绍了使用 ZeRO 策略训练
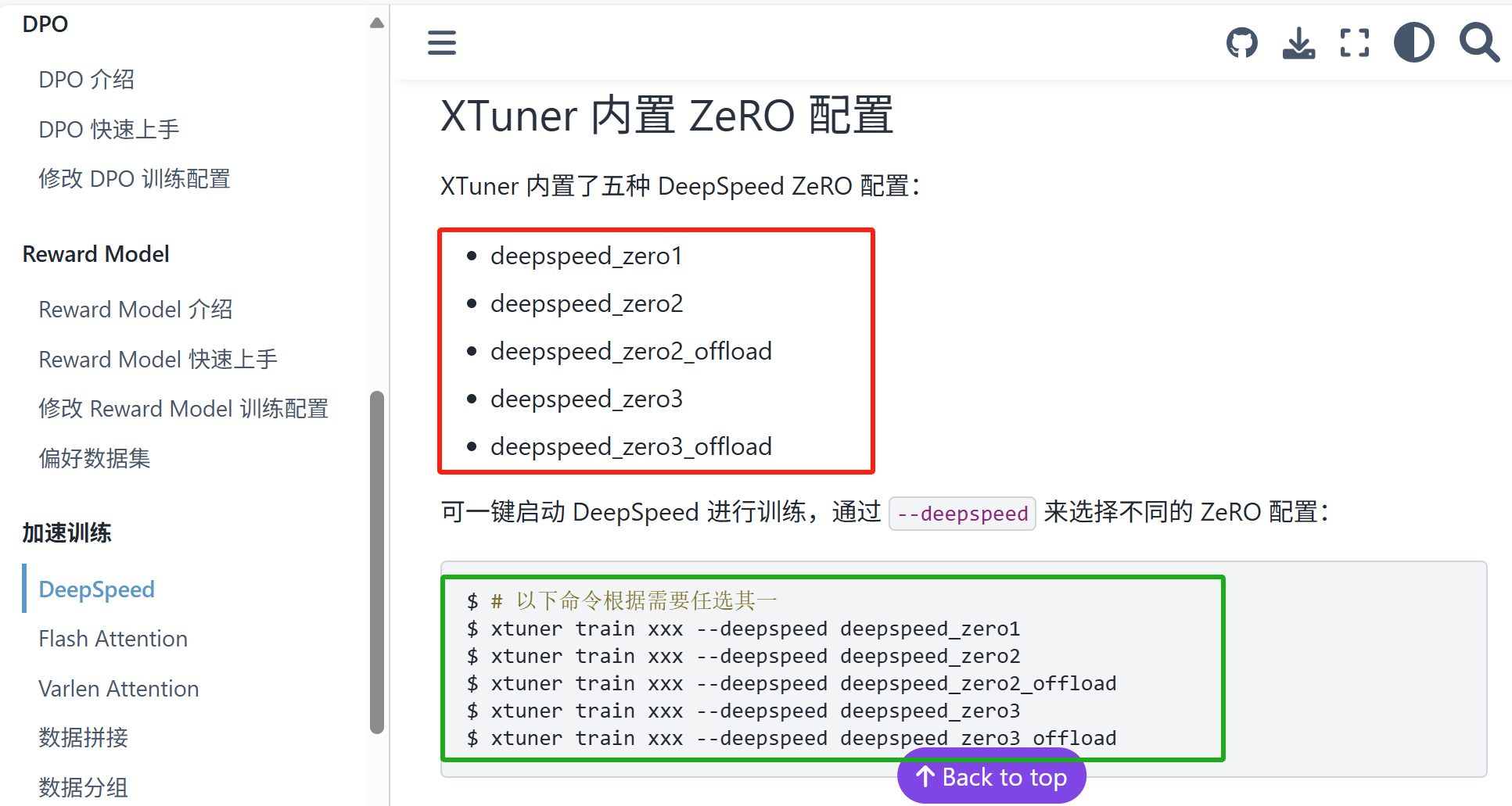
文档写的稍微还是有点混乱的,上图中绿色框的命令,是没办法调用多卡的,没有多卡的情况下,ZeRO 怎么分片?我也不知道他们怎么实现的,但单卡使用 ZeRO 就是能运行。官方文档还有个错误,就是配置文件没有加后缀 .py。
真正的分布式训练,命令如下:
# 假设使用 ZeRO-2 策略优化
NPROC_PER_NODE=${GPU_NUM} xtuner train xxx --deepspeed deepspeed_zero2
在 Xtuner 的环境中,需要提前安装 DeepSpeed,否则会报错。
我租了两张 RTX 3060,每张卡的显存12G,把上篇文章的配置文件拿过来(模型是Qwen1.5-0.5B-chat),并使用 ZeRO-2 显存优化方式,在终端输入:
NPROC_PER_NODE=2 xtuner train qwen1_5_0_5b_chat_qlora_alpaca_e3.py --deepspeed deepspeed_zero2
显存占用情况如下:
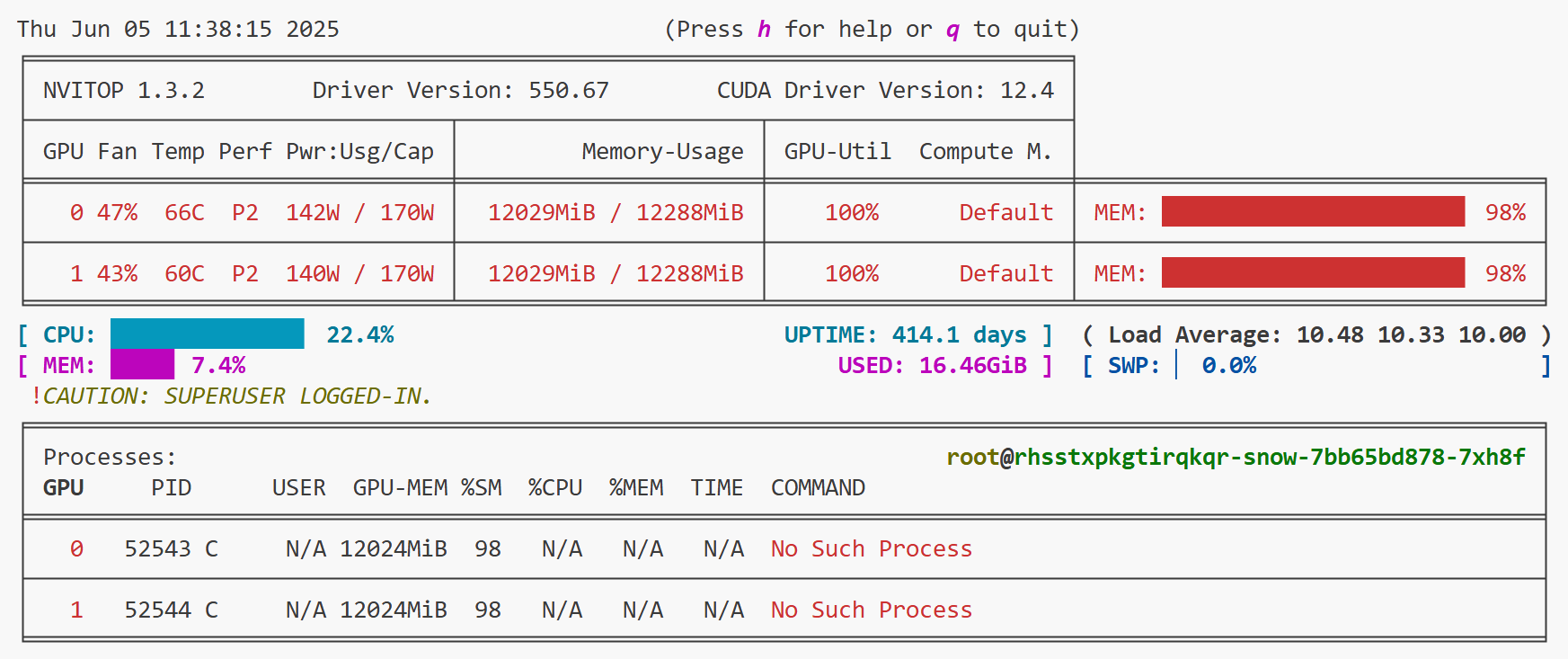
我们这里用的显卡型号和上篇文章一样,上篇文章是单卡,显存占用是 88%,这里每张卡的显存占用为98%。两次实验使用的配置文件完全一致,按理说,使用 ZeRO-2 应该更节约显存才对,但这里每张卡的显存占用增加了10%。
为啥我用了 deepspeed,显存占用却比单卡还更多?
我问了 DeepSeek,它的回答大致意思是,在 ZeRO-2 优化时,需要在每个GPU的显存中预留通信缓冲区,以实现梯度的收集和参数同步,而这个通信缓冲区是多卡训练特有的开销,大小与模型参数总量紧密相关,模型越大,需要的通信缓冲区越大。类似于你要在两个仓库(GPU)之间频繁搬运货物(梯度/状态),ZeRO帮你把需要频繁搬运的货物种类分开放(分片),节省了每个仓库存储这些特定货物的空间。但为了快速搬运,你需要在这两个仓库里都建一些转运站台(通信缓冲区)。如果仓库本身不算很大,建这些转运站台占掉的空间,可能比你通过分开放置货物节省的空间还要多,于是,单看每个仓库里用于“工作”的面积占比,好像反而变小了。
此外,在多卡(数据并行)设置下,PyTorch的 DistributedDataParallel 或者 DeepSpeed 本身会引入一些额外的内部管理开销(虽然通常较小,但占用非零显存),即分布式开销,单卡训练没有这部分开销。
ZeRO-2 会对梯度和优化器状态进行分片,分片后每张卡的显存会下降,但这部分节约下来的显存,未必能抵消 通信缓冲区 + 分布式开销 带来的额外显存,如果抵消不了,那么每张卡的显存占用就会增加,如同这里的实验一样。所以,并不是ZeRO没起作用,而是新增的“分布式税”更高。因为我们这边用的是QLoRA微调,可训练参数只有 167772160,对应梯度占用的显存为0.313G,优化器状态为1.878(权重副本、一阶动量、二阶动量各占0.626G),梯度和优化器状态被分片,每张卡只能节约 (0.313 +1.878) / 2 = 1.0955 G,从这里的实验来看, 通信缓冲区 + 分布式开销 比 1.0955 G 大很多。在两个场景下,使用 ZeRO 的优势最明显,一是模型足够大,分片的收益远高于缓冲区成本;二是GPU太小,模型塞不下,只能用分布式,通过ZeRO-3把模型也分片。
为何前面使用 LLaMA-Factory 的时候,使用ZeRO-2节约的显存接近理论值,按理说,只要用了 ZeRO 都会存在通信缓冲区,并且 LLaMA-Factory的实验用的是 8B 的模型,通信缓冲区更大才对,为何实际节约的显存,和理论值只差了一百多兆?我也不知道。
我还实验了一下 ZeRO-3,发现在 Xtuner 上,QLoRA+ZeRO-3 是可以运行的(LLaMA-Factory跑不了),最开始报的是显存不足的错误,我把 batch_size 改小后,能跑了。为啥模型相同、batch-size 相同、配置相同,而ZeRO-2能跑,ZeRO-3就显存不足,原因我也不明白。
4.4 关于ZeRO节约显存的疑问
- LLaMA-Factory 使用 DeepSpeed 的实验二,为啥每张卡节约的显存,理论值和实际值不一样?
- Xtuner 使用 DeepSpeed:使用单卡训练,没有使用DeepSpeed,显存占用88%;使用两张卡,使用 ZeRO-2 优化,每张卡的显存占用量为98%。两次实验参数配置完全一样,显卡型号一样,为何使用 ZeRO-2 优化后,每张卡的显存占用反而上升了?刚刚的解释来自于DeepSeek,这个解释无法回答
疑问1理论值和实际值差距为何小。 - Xtuner 使用 DeepSpeed:为啥为啥模型相同、batch-size 相同、配置相同,而ZeRO-2能跑,ZeRO-3就显存不足?
5 实战:用两张 RTX 4070 训练 8B 模型
假如我们手上有两张 RTX 4070,每张卡的显存为12G,此时我们要训练 Meta-Llama-3-8B-Instruct,这个模型的数据类型是 bf16,也就是说,光参数占的显存就有 16G,训练的时候还有梯度和优化器状态,所以单张卡是无法训练的。如果没办法更换显卡,那只能考虑使用分布式训练。
大模型的分布式训练优先选择 ZeRO 方案,而模型参数单张卡放不下,那么必须拆分参数,因此优化方案选择 ZeRO-3 或者 ZeRO-3-Offload。
这里选用 Xtuner,参数配置时,我设置 batch_size 为16,max_length 为128。
最开始我选择的是 ZeRO-3 方案,因为 offload 会降低训练速度,终端命令为:
NPROC_PER_NODE=2 xtuner train llama3_8b_instruct_qlora_alpaca_e3.py --deepspeed deepspeed_zero3
报错说显存不足。
接下来我使用ZeRO-3-Offload,命令为:
NPROC_PER_NODE=2 xtuner train llama3_8b_instruct_qlora_alpaca_e3.py --deepspeed deepspeed_zero3_offload
这回终于跑起来了。
显存占用情况为:
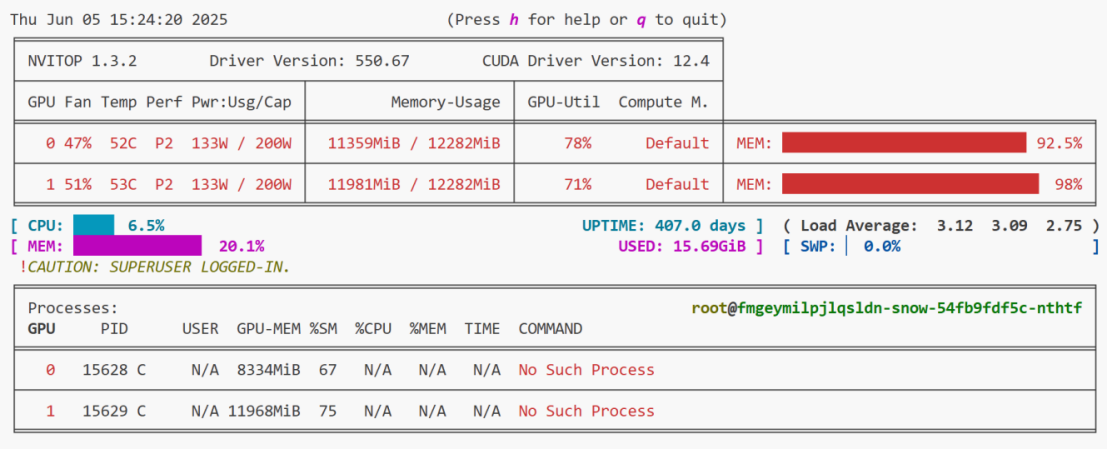
显存占用率一直在跳变,并且幅度还挺大,一会儿90+5,一会儿80+%,一会儿60+%:
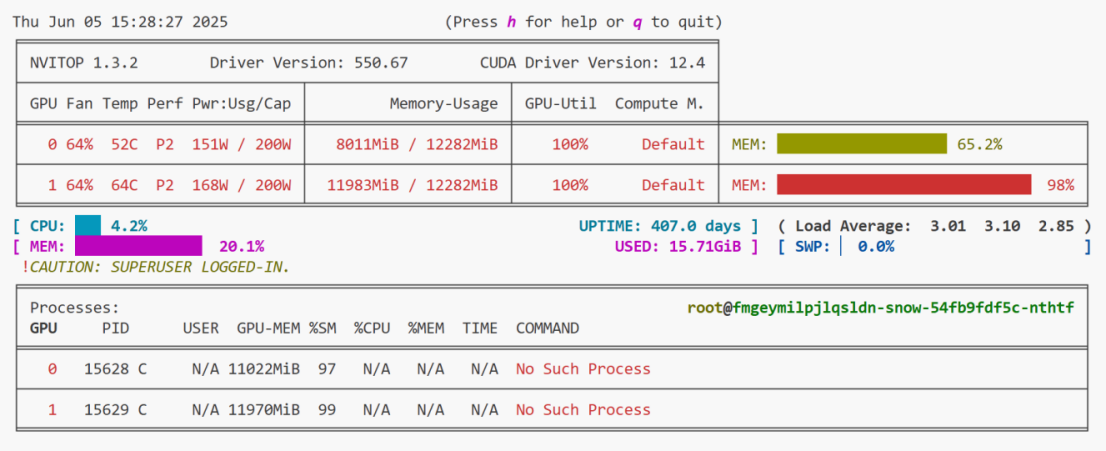
不管怎么样,我们实现了仅用两张12G的显卡对8B的大模型进行微调,虽然跑的慢了一些,但实实在在地跑起来了。
新建一个终端,输入下面地命令实现训练过程可视化(需要在配置文件中配置可视化方式为 tensorboard):
tensorboard --logdir=/data/coding/xtuner/work_dirs/llama3_8b_instruct_qlora_alpaca_e3/20250605_150852/vis_data
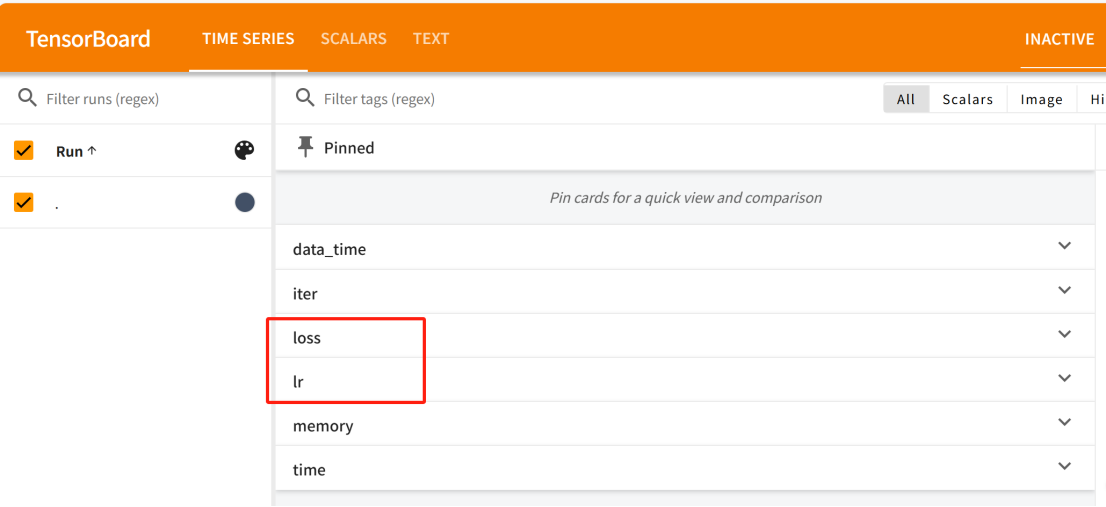
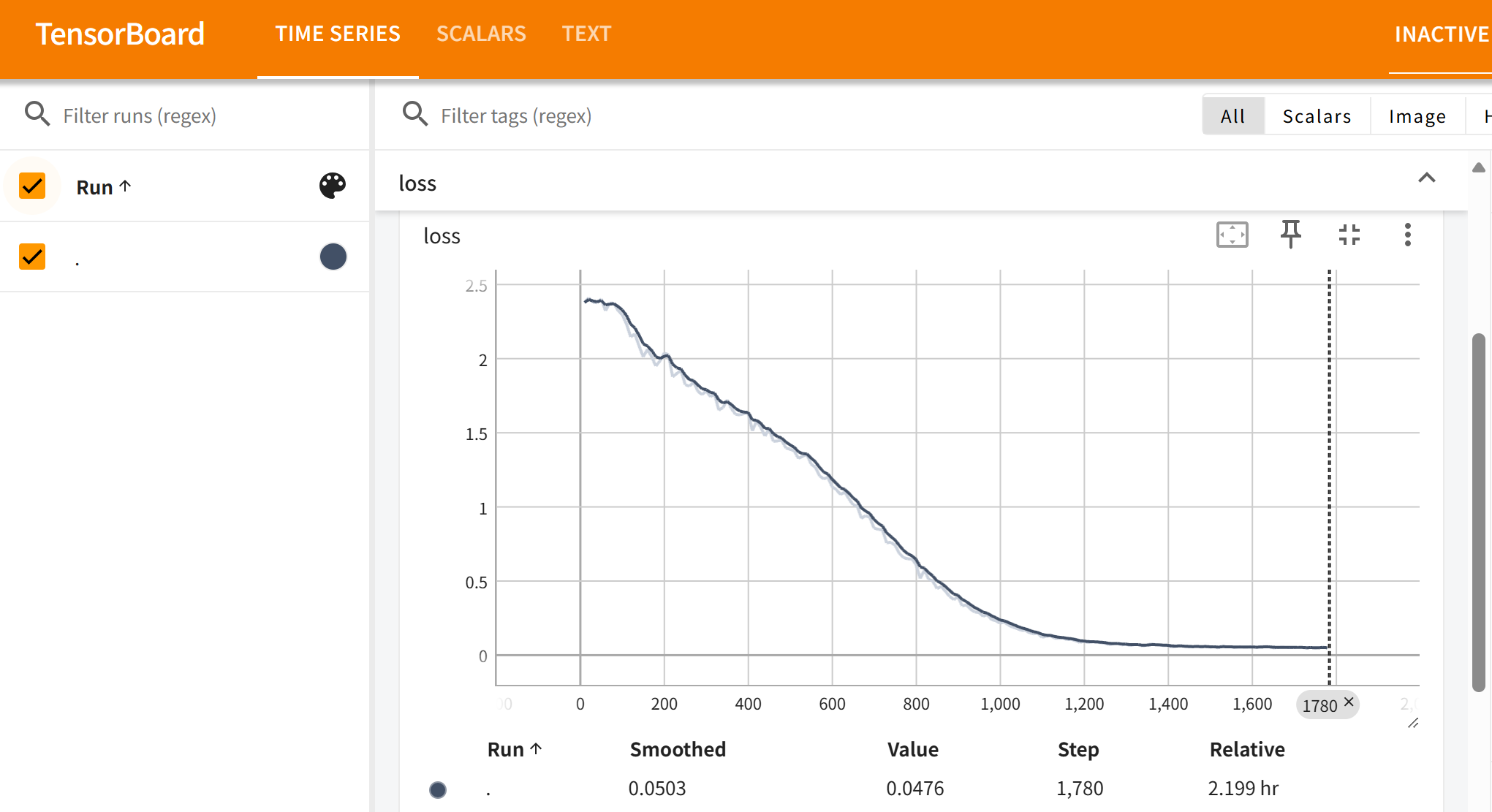
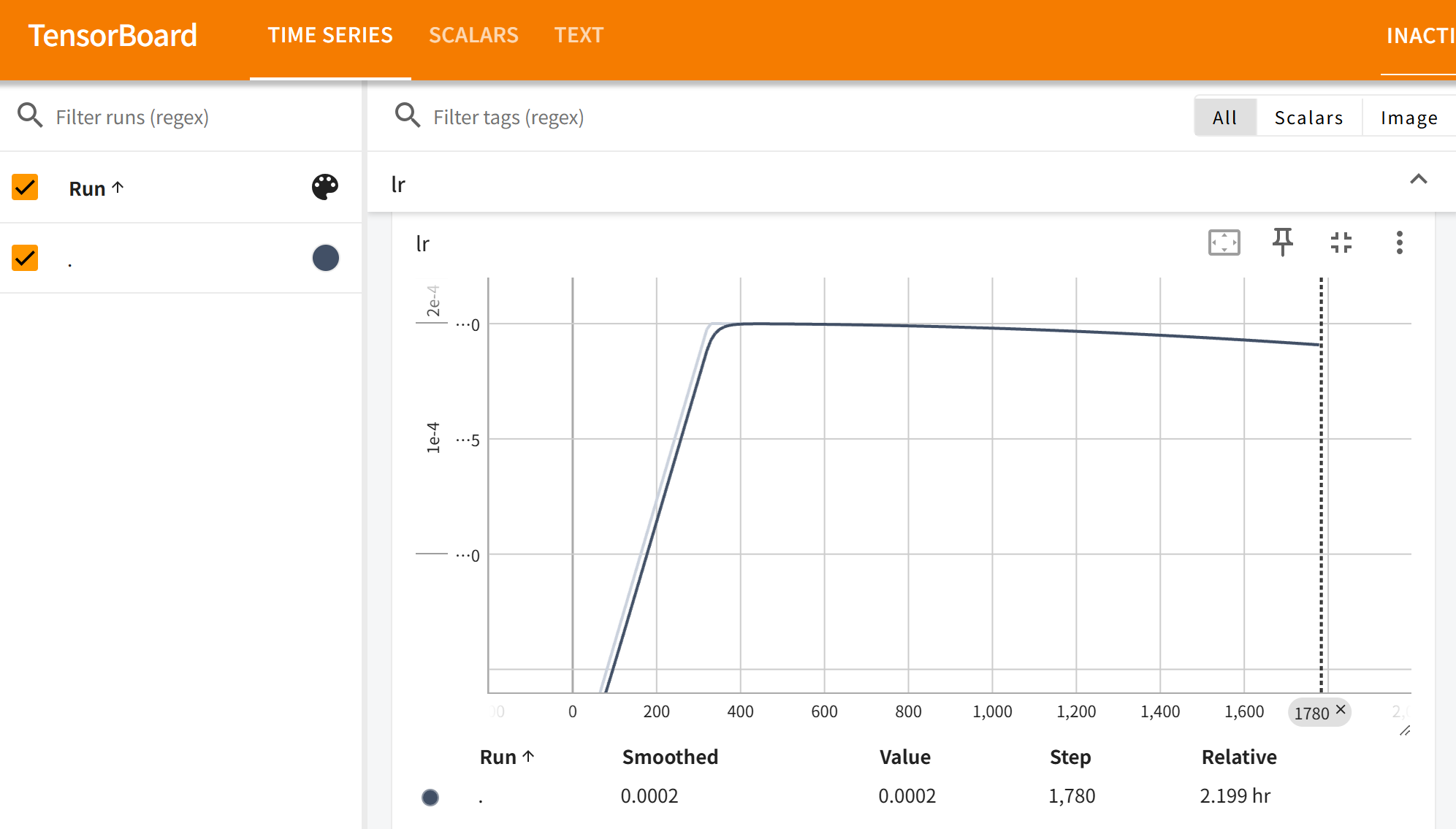
我们这里只关注 loss 和 lr,其他没啥意义:
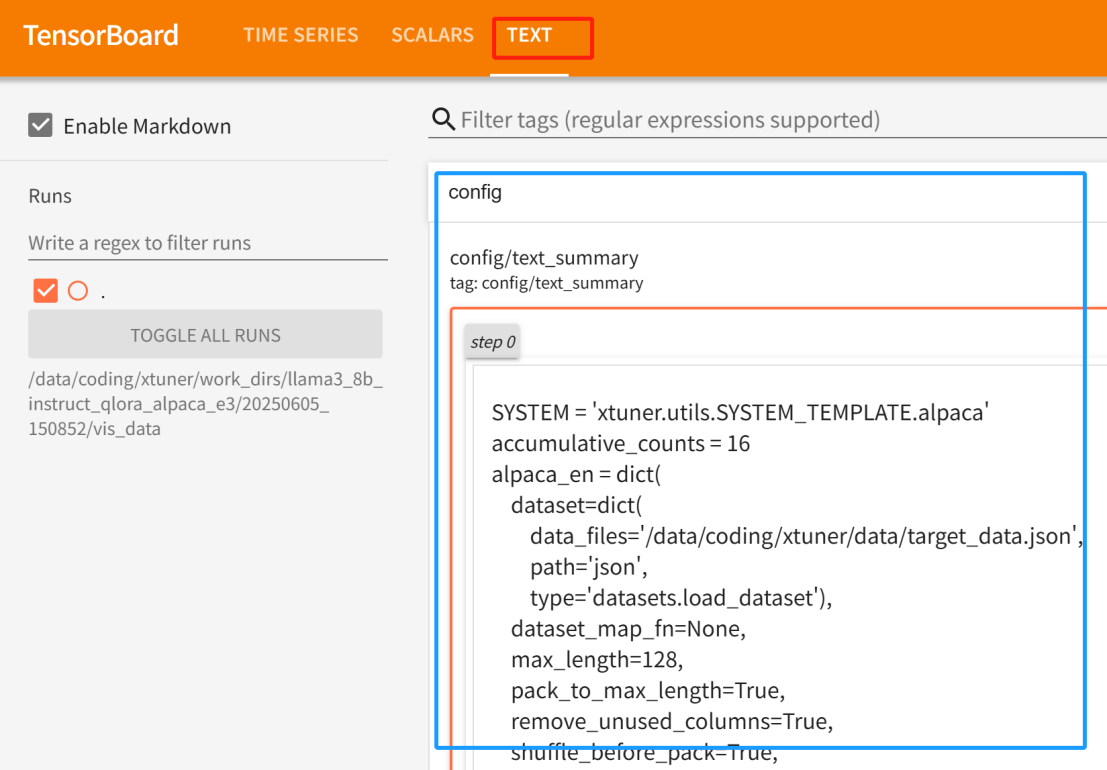
TEXT选项卡保存本次训练的配置信息:
训练完成后,进行转化与合并。
转化命令为:
xtuner convert pth_to_hf llama3_8b_instruct_qlora_alpaca_e3.py /data/coding/xtuner/work_dirs/llama3_8b_instruct_qlora_alpaca_e3/iter_1500.pth /data/coding/xtuner/adapter_save_dir/llama
合并的时候,因为单张GPU存不下,所以我们将其放到CPU中进行合并,命令为:
CUDA_VISIBLE_DEVICES="" xtuner convert merge /data/coding/model_weights/LLM-Research/Meta-Llama-3-8B-Instruct /data/coding/xtuner/adapter_save_dir/llama /data/coding/model_weights/LLM-Research/llama3-8b-qlora
如果出现 All done!,说明合并完成,可以进行部署了。
至此,我们实现了用小显存的GPU训练大尺寸的模型。
参考文献:
DeepSpeed之ZeRO系列:将显存优化进行到底,basicv8vc,https://www.zhihu.com/collection/546426509