2.7.4制药CMC统计应用之单个总体非独立测量的未来所有值的耐受区间
本文是《Statistical Applications for Chemistry Manufacturing and Controls CMC in the Pharmaceutical Industry》第2章2.7.4节python解决方案
预测区间计算的替代也可以用来构建(2.23)的耐受区间。特别是,包含未来值的100P%的100(1-α)%双侧耐受区间为:
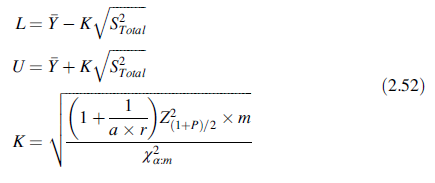
其中m的定义在(2.50),S2Total定义在(2.46)。对于本例,包含90%未来值的95%耐受区间为
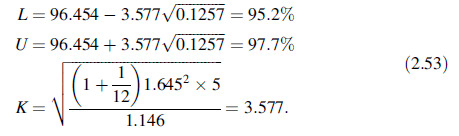
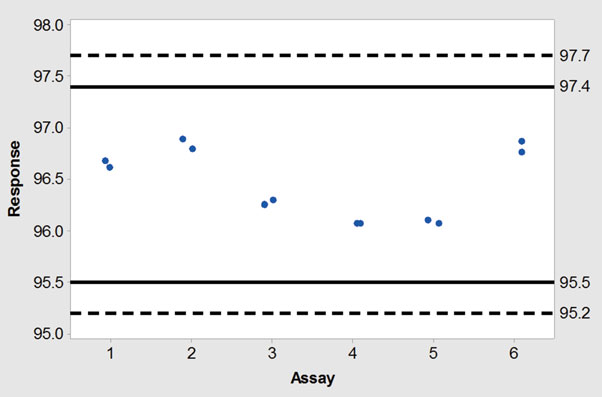
Hoffman 和Kringle推荐的耐受区间为95.1到97.8%。
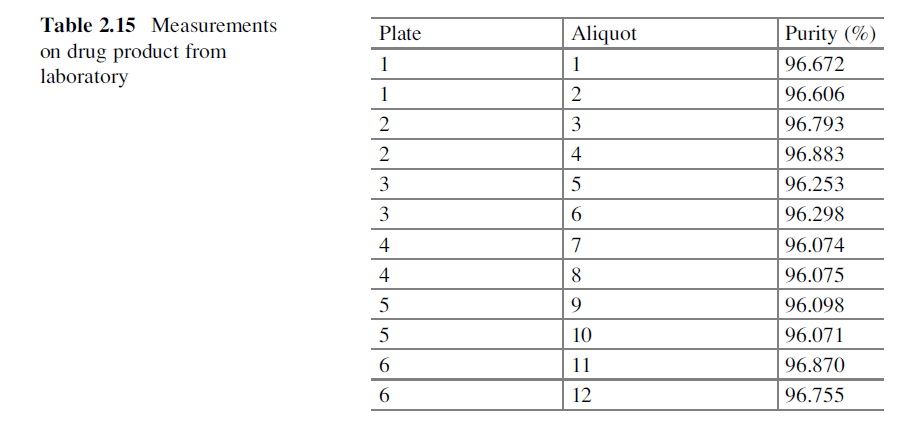
以 表15的纯度数据为例,计算未来所有值的$100(1-\alpha)$%双侧耐受区间为:
import numpy as np
from scipy import stats
import statsmodels.api as sm
from statsmodels.formula.api import ols
import pandas as pd
y1 = [96.672, 96.606, 96.793, 96.883, 96.253, 96.298, 96.074, 96.075, 96.098, 96.071, 96.870, 96.755]
x1 = [1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6]
x2 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
data = {"y1":y1,"x1":x1,"x2":x2}
data=pd.DataFrame(data)
model = ols('data.y1 ~ C(data.x1)', data=data).fit()
anova_table = sm.stats.anova_lm(model, typ=2)
anova_table
>>> anova_table.sum_sq[0]
1.2452319999999861
>>> anova_table.sum_sq[1]
0.014218000000000348
>>> anova_table.df[0]
5.0
>>> anova_table.df[1]
6.0
sve=anova_table.sum_sq[1]/anova_table.df[1]
sva=anova_table.sum_sq[0]/anova_table.df[0]
a1=anova_table.df[0] + 1
n = (anova_table.df[1]/(anova_table.df[0]+1))+1
tpe= (sva + (n-1)*sve)/n
m =(tpe**2)/((sva**2)/(anova_table.df[0]*n**2) + (anova_table.df[0]*sve**2)/(a1*n**2))
#n1 =len(y1)
#ne=n1
y1_mean=np.mean(y1)
#sv1=np.var(y1)*n1/(n1-1)
P=0.90
α=0.05
a=6
r=2
svt=sva/r+(r-1)*sve/r
#m=svt**4/((sva**4/((r**2)*(a-1)))+((r-1)*sve**4)/(r**2*a) )
K=( (1+1/(a*r))*(stats.norm.ppf((1+P)/2))**2*m/stats.chi2(m).ppf(α) )**0.5
L=y1_mean-K*(svt)**0.5
U=y1_mean+K*(svt)**0.5
>>> L
95.19778351614887
>>> U
97.71021648385111
#a <- dfa + 1
#n <- (dfe/(dfa+1))+1
#tpe <- (msa + (n-1)*mse)/n
#m <- (tpe^2)/((msa^2)/(dfa*n^2) + (dfa*mse^2)/(a*n^2))
图2.11是预测区间和耐受区间的图。预测区间用实线,耐受区间用虚线。因为数据的变异大部分来自单元,因些需要收集更多的单元来减少区间宽度。