[AI绘画]sd学习记录(一)软件安装以及文生图界面初识、提示词写法
目录
- 一、安装软件
- 运行界面
- 二、文生图各部分模块
- 1. 下载新模型 & 画出第一张图
- 2. 提示词输入
- 2.1 设置
- 2.2 扩展模型
- 2.3 扩展模型权重调整
- 2.4 其他提示词输入
- 2.5 负向提示词
- 2.6 生成参考
- 3. 采样方法
- 4. 噪声调度器
- 5. 迭代步数
- 6. 提示词引导系数 CFG Scale
一、安装软件
软件安装:https://mp.weixin.qq.com/s/JCN5H7op35wfQpyvSMAeow,教程非常详细,按照步骤一步步操作即可。
运行界面
启动器
绘图UI界面
二、文生图各部分模块
1. 下载新模型 & 画出第一张图
我们的启动器自带模型下载功能,但下载体验不是很好,个人更倾向于把它当成一个检索台,真正下载时可以点击"复制链接"然后去对应网址下载(绝大多数是huggingface链接,需要科学上网),然后保存到安装目录model下的对应子文件夹中。例如下载的stable diffusion模型应放到models/Stable_diffusion文件夹,其他类型同理。
也可以去huggingface或https://civitai.com/等开源平台直接下载。
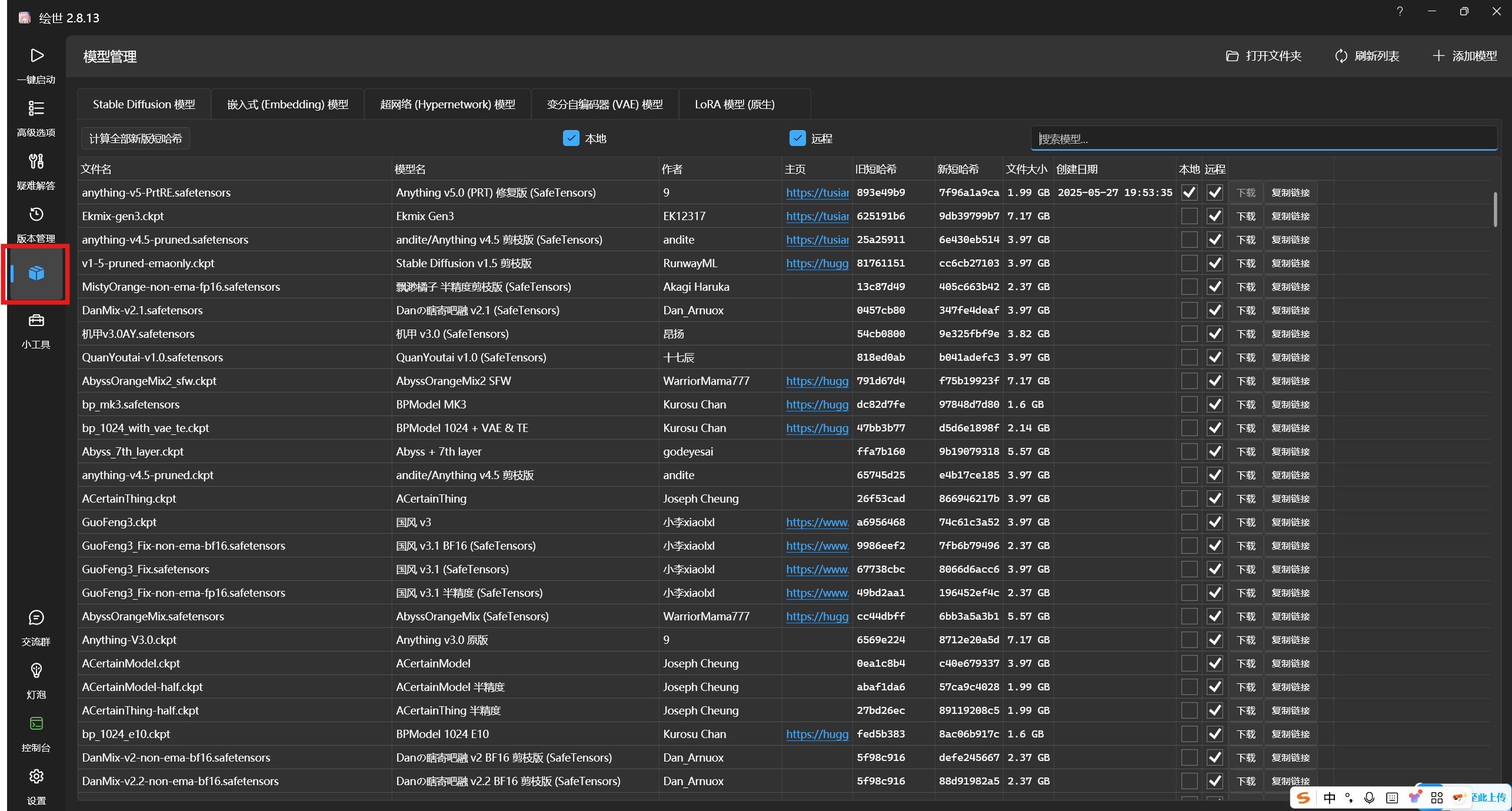
如图所示,根据下载文件的类型,需放到不同的目录文件夹下。
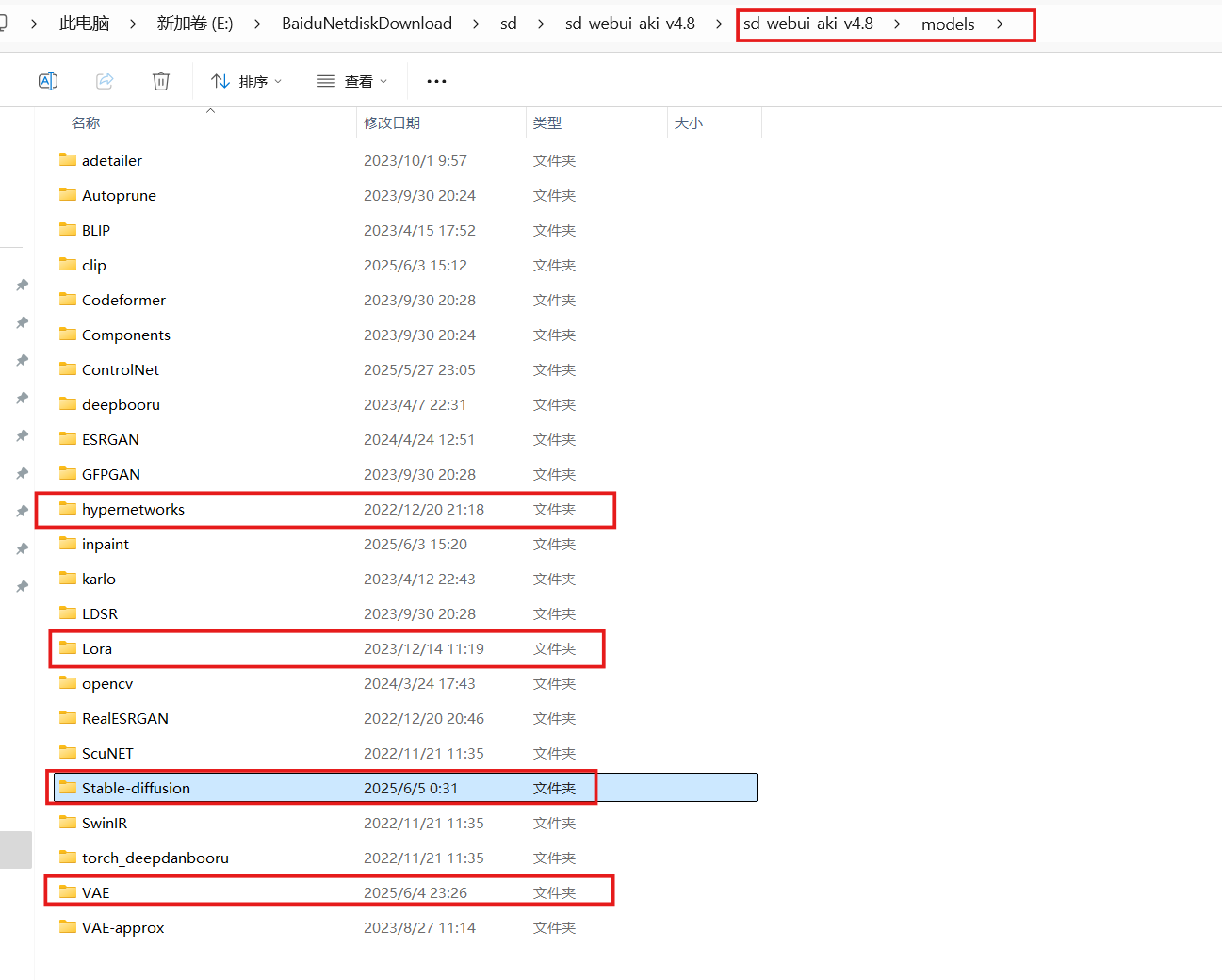
下载完成后,在左上角点击刷新,即可切换到新下载的模型。
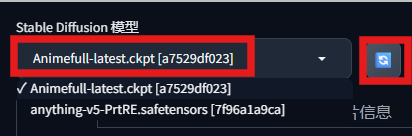
切换到想要的模型后,在正向提示词框中输入你想要绘制的内容,在反向提示词框中输入你不希望出现的元素,然后点击橙色的生成按钮,就可以绘制出你的第一张AI图像了!

比如:在正向提示词里输入简单的"a cat"
你就能成功得到一只猫咪!

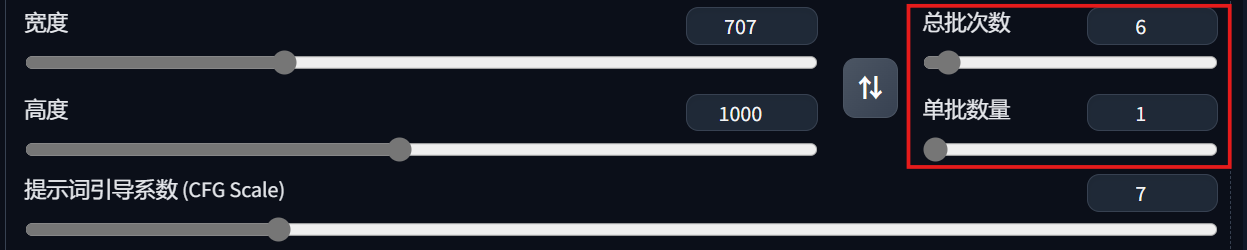
在宽度和高度区域可以设置想要生成的图片尺寸(我选择了707x1000,模拟A4纸1: 2 \sqrt{2} 2的长宽比)

在这里可以设置总批次数和单批数量(总共生成a次,每次b张,最终会有a*b张图片。注意单批数量很消耗显存,4GB显存建议设为1,8GB显存不要超过3)
接下来是界面顶部的三个重要参数:SD模型,VAE模型和CLIP终止层数。SD模型决定整个生成的基调,需要根据你的创作领域选择合适的模型,上面提到的下载功能主要就是用来获取这些SD模型。
"外挂 VAE 模型"的作用是修正色彩偏差、强化风格特征、修复细节丢失,不同的VAE会让同样的提示词生成出在色调、质感上截然不同的图像。软件自带两个VAE模型,简介如下:
animevae.pt:
专为二次元风格优化的VAE,非常适合生成动漫和插画,能让色彩更加鲜亮,线条更加清晰硬朗。vae-ft-mse-840000-ema-pruned.safetensors:
通用型VAE(常被称为"SD 1.5官方VAE"),对写实和二次元都有良好适配性,细节还原度高,尤其擅长解决"画面发灰"问题。
CLIP负责文本与图像的语义对齐,其终止层数直接影响文本与图像的关联强度,控制模型对提示词的理解深度。层数设置越低,创作自由度越高,但可能导致提示内容丢失甚至被完全忽略;层数越高,模型会更加关注提示词的细节,生成内容也会更贴合提示词要求。
不过要注意,如果你的提示词过于简单模糊(例如仅有"a girl"),不建议将CLIP层数设太高,否则因为"过度抠细节",可能导致画面崩坏,产生奇怪的"古神级"作品。

例如我只输入简单的"a cat",将CLIP层数设为12,看看结果:完全进入古神领域了

CLIP层数设为8时:

CLIP层数设为4时:

CLIP层数设为1时:可以看到,提示词"a cat"中的"a"甚至已经被忽略了

因此,当你的提示词非常明确或希望AI绘画结果更加贴合提示词、减少发散时,可以适当提高CLIP层数;反之则可以降低CLIP层数以获得更有创意的结果。
2. 提示词输入
2.1 设置
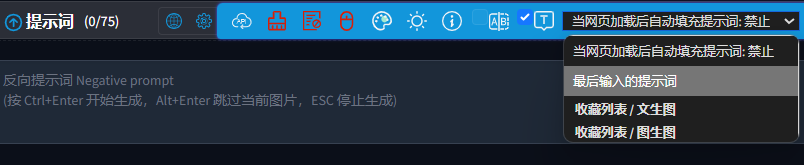
提示词右侧的小按钮从左到右分别是:语言、设置、历史记录、收藏列表、翻译关键词、复制关键词、删除关键词,将鼠标悬停在按钮上时会显示详细说明。

当鼠标停留在设置按钮上时,右侧会弹出一系列设置选项。调色盘图标用于更换界面样式,可以选择一个你喜欢的风格。再往右的太阳图标则用于切换深色与浅色主题,个人认为深色主题更加美观。


浅色主题预览效果:
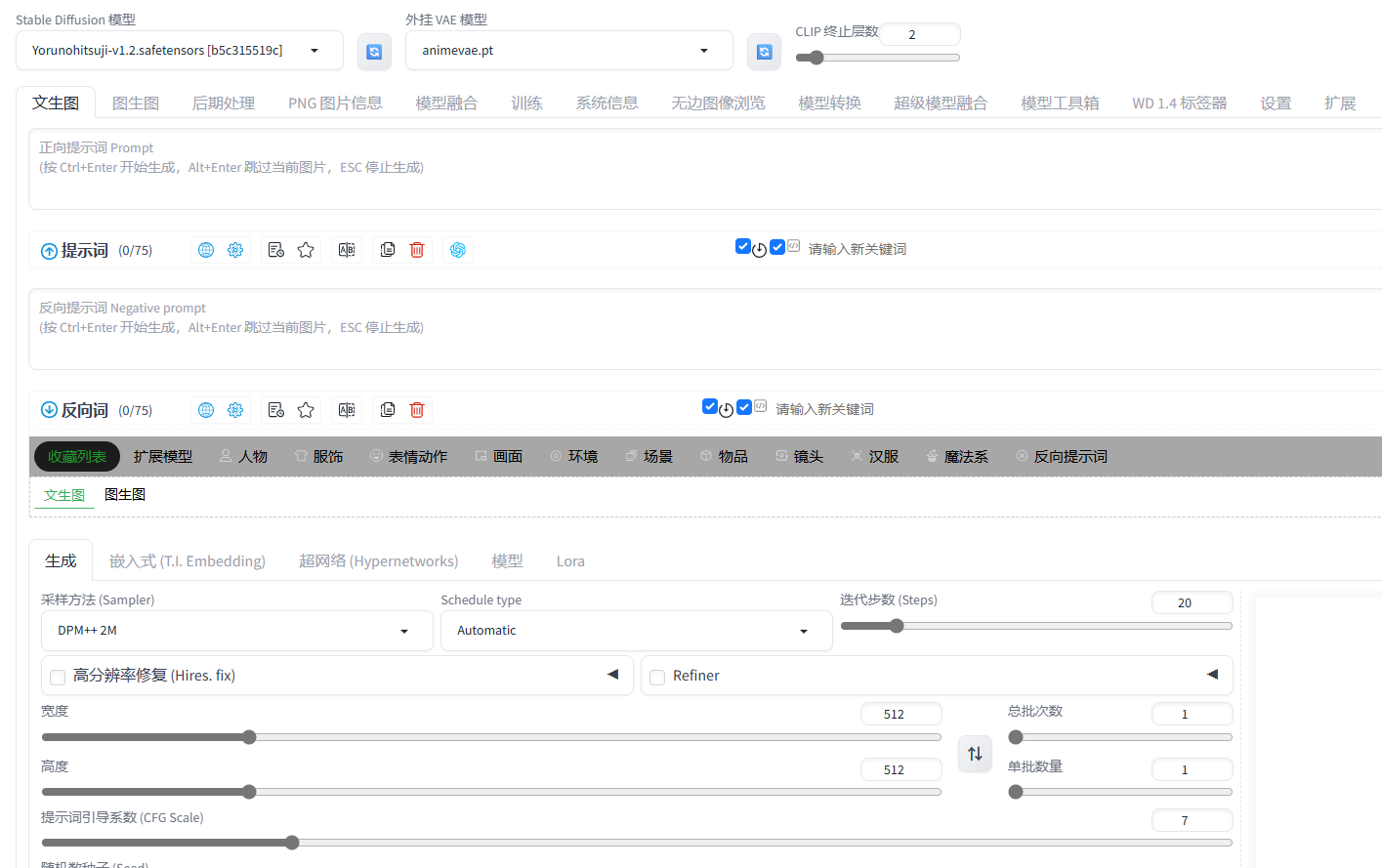
强烈建议将设置修改为"最后输入的提示词",否则软件卡顿或刷新后,你精心编写的提示词可能会丢失,需要重新输入。
2.2 扩展模型
点击提示词左侧的箭头,会出现如下界面,这是内置了GitHub上开源仓库的快捷选择界面,能帮助你快速添加常用提示词!

首先简单介绍一下扩展模型的概念:它们是加载在基础大模型之上的辅助模型,通过添加少量可训练参数来适应特定任务,简单来说就是能快速转变生成风格。这些模型可以在启动器的模型下载界面获取。主要有三种类型的扩展模型:
- Lora:最常用且实用的扩展模型!可以快速为图像添加特定风格(如汉服、动漫脸)或特定属性(如手绘质感)。你界面中看到的
badhandv4、EasyNegative等就是Lora文件(其中EasyNegative系列专门用于减少画面瑕疵、优化构图,属于"反向优化"Lora)。 - Embedding(嵌入式):通过注入特定语义影响绘图风格或元素,例如让人物更符合某种审美标准,体积小且针对性强。
- Hypernetworks(超网络):调整模型生成逻辑,影响整体风格走向,影响范围比Lora更大,但新手较少使用。
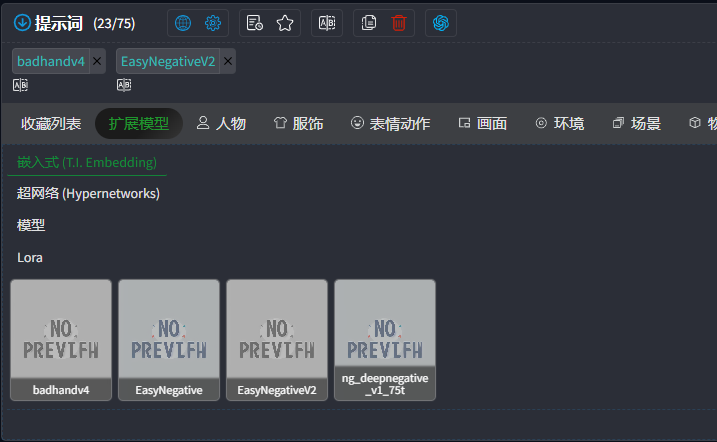
从图中可以看到,软件已预置了4个Lora模型,它们的作用分别是:
- badhandv4:专门优化手部绘制,解决AI绘图中常见的"手部畸形、比例怪异、细节混乱"问题,让人物手部更加自然合理,是修复手部的"必备"Lora。
- EasyNegative:将众多通用负面提示词(如画面杂乱、比例失调、画风怪异等)打包整合,只需添加它就能让AI自动避开这些常见瑕疵,简化了负面提示词的输入过程,提升整体出图质量。
- EasyNegativeV2:EasyNegative的升级版,规避画面问题的能力更精准,对色彩和质感的优化也有明显提升,能让画面细节更加干净、风格更加统一。
- ng_deepnegative_v1_75t:更深度的负面效果优化,除了基础画面瑕疵,还能抑制一些"诡异风格、不合理元素"(如奇怪的光影、不自然的装饰),让画面更符合正常审美,特别适合追求高品质出图的场景。
但是当你下载了很多模型后,请不要一股脑全部使用,需要注意以下几点:
按需精简选择:
如果只是绘制普通人物,通常badhandv4+ 1个通用负向Lora(如EasyNegativeV2)就足够了。叠加太多负向Lora可能导致画面"过度优化"(如色彩变得寡淡、细节被过度压制),这是新手容易忽视的问题。谨慎控制权重:
每个Lora后面的:权重值不宜设置过高(建议在0.3-0.8之间)。所有Lora的权重总和最好不要超过1.5,否则模型难以平衡各种效果,容易导致画面变得奇怪。搭配正向提示词测试:
添加多个Lora后,一定要用不同的正向提示词进行测试,观察负向Lora是否会"误伤"你想要的风格效果。如果发现画面变得僵硬或风格被过度压制,可以减少Lora数量或降低权重。
2.3 扩展模型权重调整
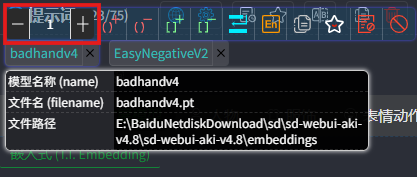
调整权重:将鼠标悬停在模型上会显示选项框,第一个选项就是权重调整,可以方便地调整数值,默认为1。
Lora模型的权重设置建议根据模型类型(正向/负向)、功能强度、与基础模型的兼容性来调整,以下是不同情况的推荐范围:
负向优化类Lora(如修手、去瑕疵):
推荐权重:0.3 - 0.8
这类Lora主要用于"抑制"各种瑕疵(如手部畸形、画面杂乱),权重过高可能导致过度优化(如画面变模糊、细节丢失)。badhandv4(修手)建议设置为0.5-0.7,手部问题严重时可提高到0.8;EasyNegativeV2(通用去瑕疵)建议设置为0.4-0.6;ng_deepnegative_v1_75t(深度去瑕疵)因效果较强,建议控制在0.3-0.5。同时使用多个负向Lora时,总权重建议不超过1.5(例如badhandv4:0.6 + EasyNegativeV2:0.6 + ng_deepnegative:0.3),否则可能让画面失去活力和细节。
正向风格类Lora(如特定画风、角色):
推荐权重:0.7 - 1.2
这类Lora需要足够的强度才能"覆盖"基础模型的默认风格,权重过低则效果不明显。动漫风格Lora(如anime_style)建议设置为0.8-1.0;特定角色Lora(如character_name)建议设置为0.9-1.2以保证角色特征明显;混合风格Lora(如"赛博朋克+古风")建议控制在0.7-0.9以避免风格冲突。如果基础模型与Lora风格差异较大(如用写实模型加载动漫Lora),可能需要更高权重(如1.0-1.2)。但要注意,权重过高可能导致风格溢出(如皮肤质感异常、光影不自然),这时需要通过反向提示词进行修正(如添加bad anatomy, strange lighting)。
以下是括号语法,这是通用的"权重调节语言":
这里可以选择收藏词条、禁用词条或删除词条,建议将常用的标记为收藏以便快速访问。
收藏后,可以在收藏列表中快速选择使用:
经过我多次反复实验,对于这部分功能,我个人只推荐使用badhandv4这一个模型,其他模型无论给多高权重都带来的是负面提升…效果反而不如单独使用badhandv4。
2.4 其他提示词输入
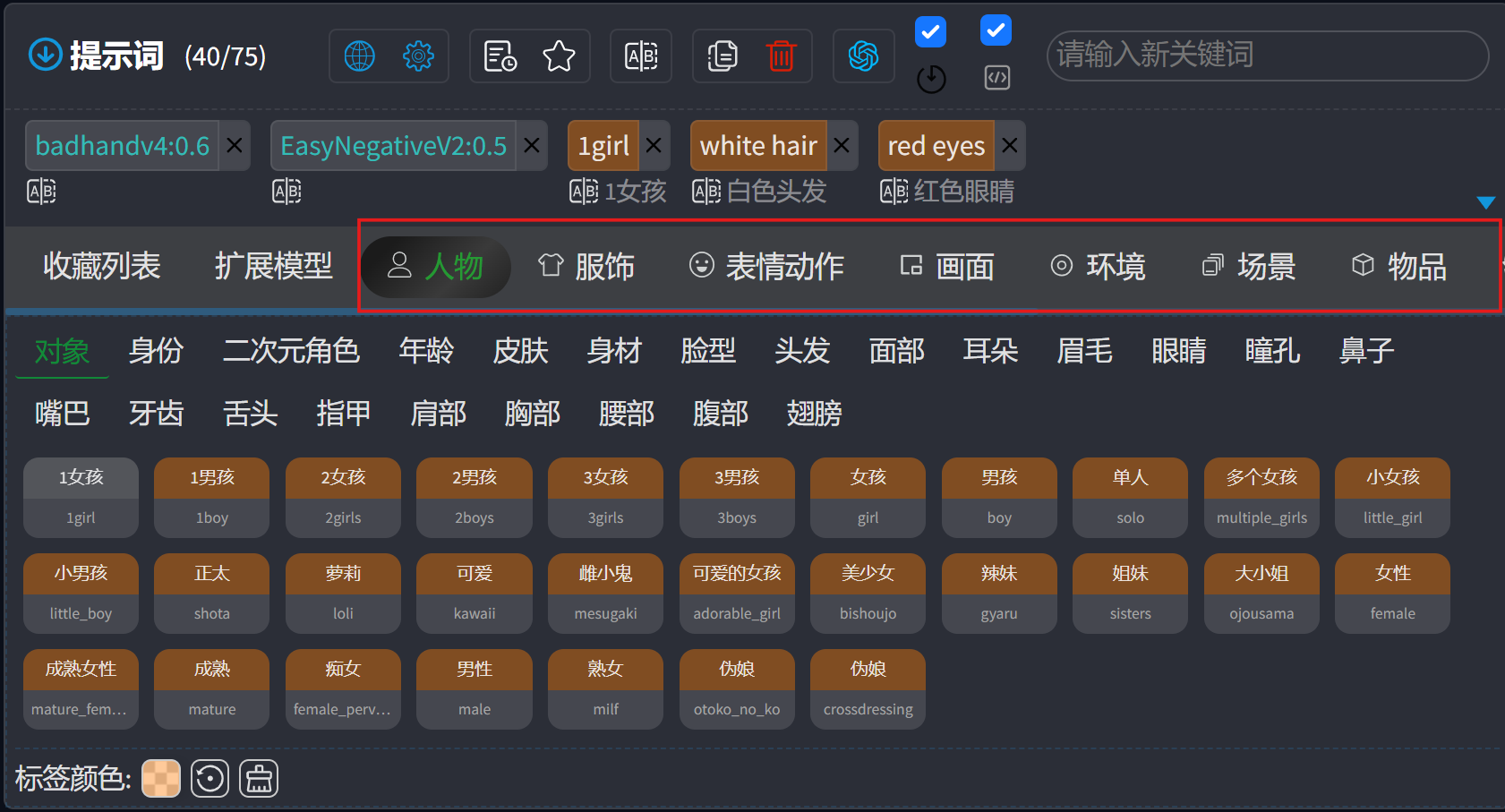
其他提示词分类直观易懂,都提供了中英文对照,包含成百上千个可选关键词供你挑选:
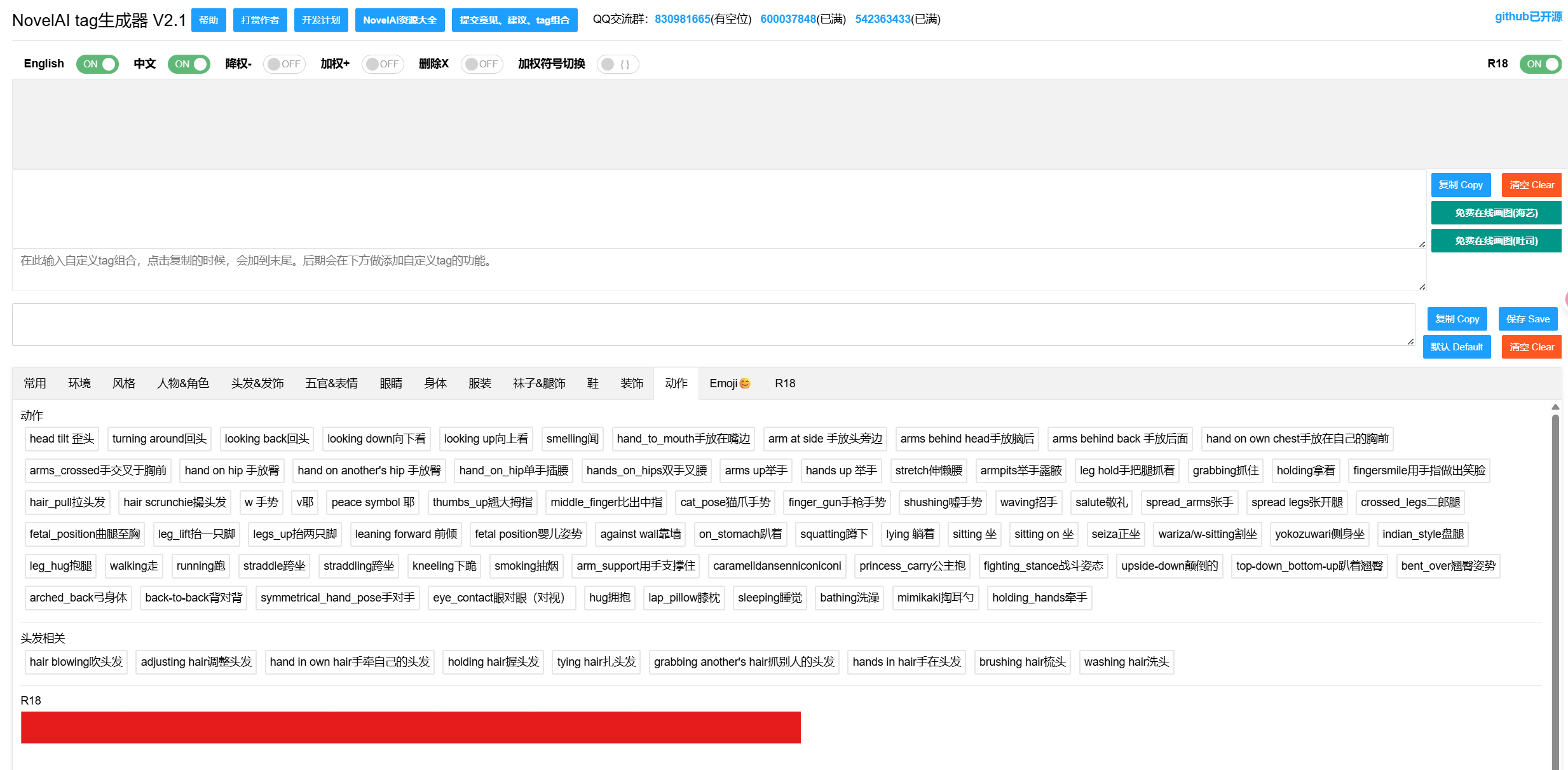
另外推荐一个非常实用的网站:https://wolfchen.top/tag/
这是一个专门用于生成标签的网站,使用体验相当不错:
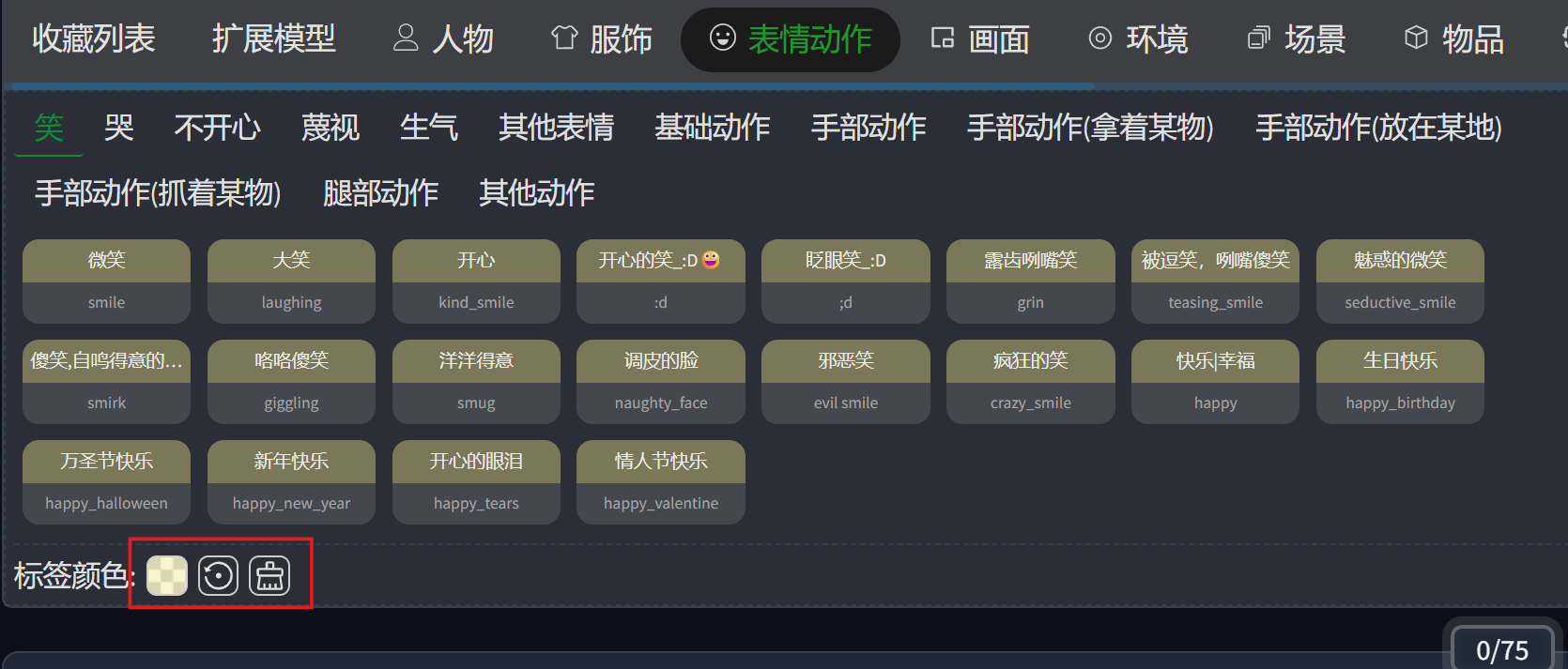
每种类型的标签都有独特的颜色标识,方便区分,你可以在这里切换不同提示词类别的颜色或重置全部颜色设置:
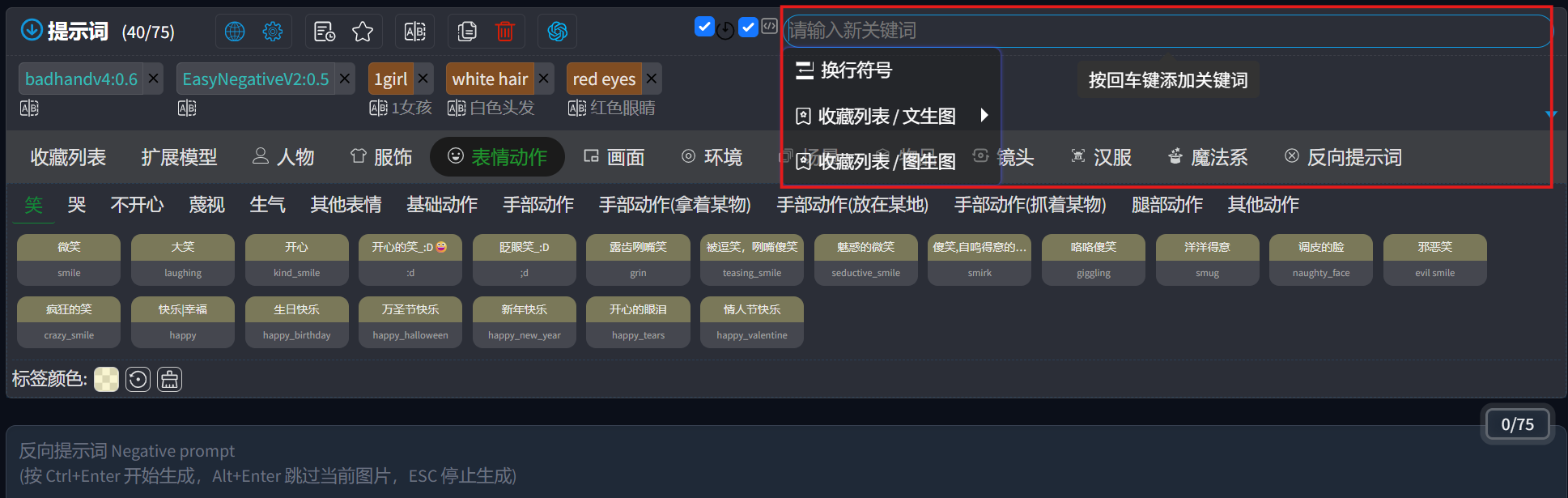
此处可以手动添加自定义提示词,按回车键即可添加到列表中:
2.5 负向提示词
负向提示词用于指定你不希望在图像中出现的元素或特征。例如,如果你希望角色不要笑,但尝试多次生成都是笑脸,可以将"笑"添加到反向提示词;如果不想出现天空,就把"天空"加入反向提示词。
除了排除不需要的元素,反向提示词还有个重要功能:优化画面质量。软件已经为我们整理好了常用的负面标签并转化为Embedding,这里重点介绍一下:
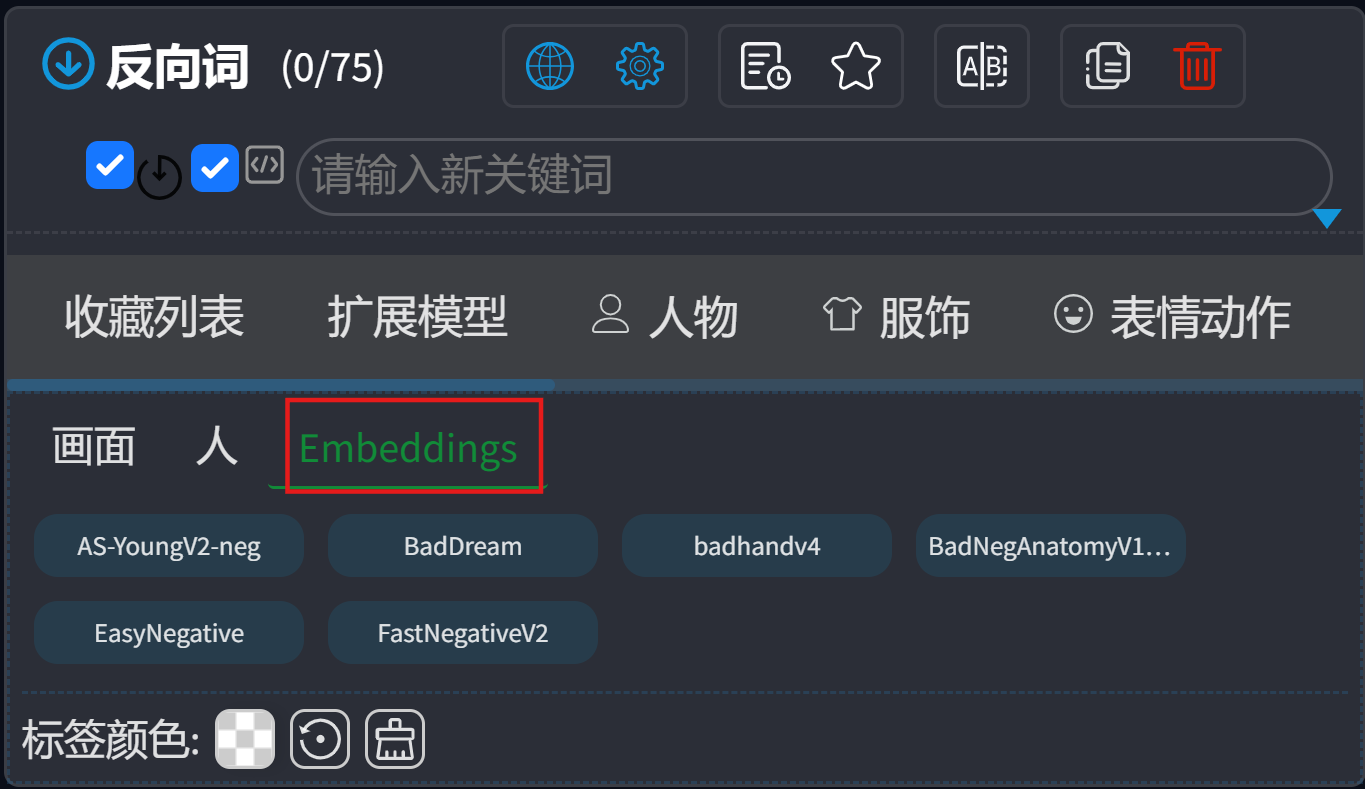
Embedding是一种"预训练关键词集合",它将大量负面描述(如画面杂乱、比例失调、画风诡异等)"打包"成一个模型。将它放入反向提示词,AI就会自动规避这些常见瑕疵,让生成的图像更加符合预期效果。
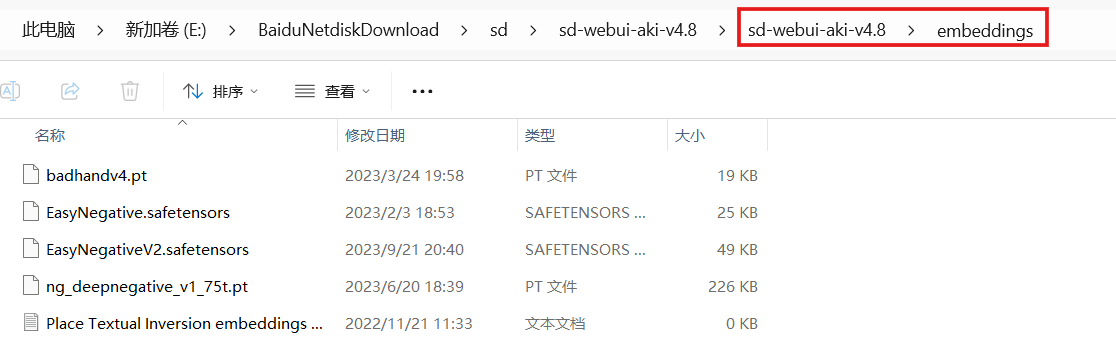
软件内置了6个Embedding,功能如下:
- AS-YoungV2-neg:专门针对"AS-YoungV2"风格(年轻女性画风)进行反向优化,减少该风格下常见的瑕疵(如面部不自然、色彩怪异等)。
- BadDream:抑制"诡异梦境感"元素,避免画面出现奇怪的扭曲或不合理的光影效果,防止图像看起来像"噩梦场景"。
- badhandv4:专门优化手部绘制!解决AI绘图中最令人头疼的"手部畸形、比例奇怪"问题,添加到反向提示词能大幅降低手部崩坏的概率(与同名Lora功能互补,一个是反向词Embedding,一个是模型插件)。
- BadNegAnatomyV1:抑制"人体结构错误",如奇怪的肢体比例或骨骼扭曲,让人物/生物的身体结构更加合理自然。
- EasyNegative:通用型负面合集,涵盖众多基础瑕疵(画面杂乱、模糊、比例失调等),新手必备,添加它能解决约80%的"常见错误"。
- FastNegativeV2:EasyNegative的升级版,优化更加精准,对色彩和细节的把控更好,特别适合追求高质量出图的场景。
这类Embedding一般不需要调整权重。我个人选择了以下几个作为常用反向提示词:
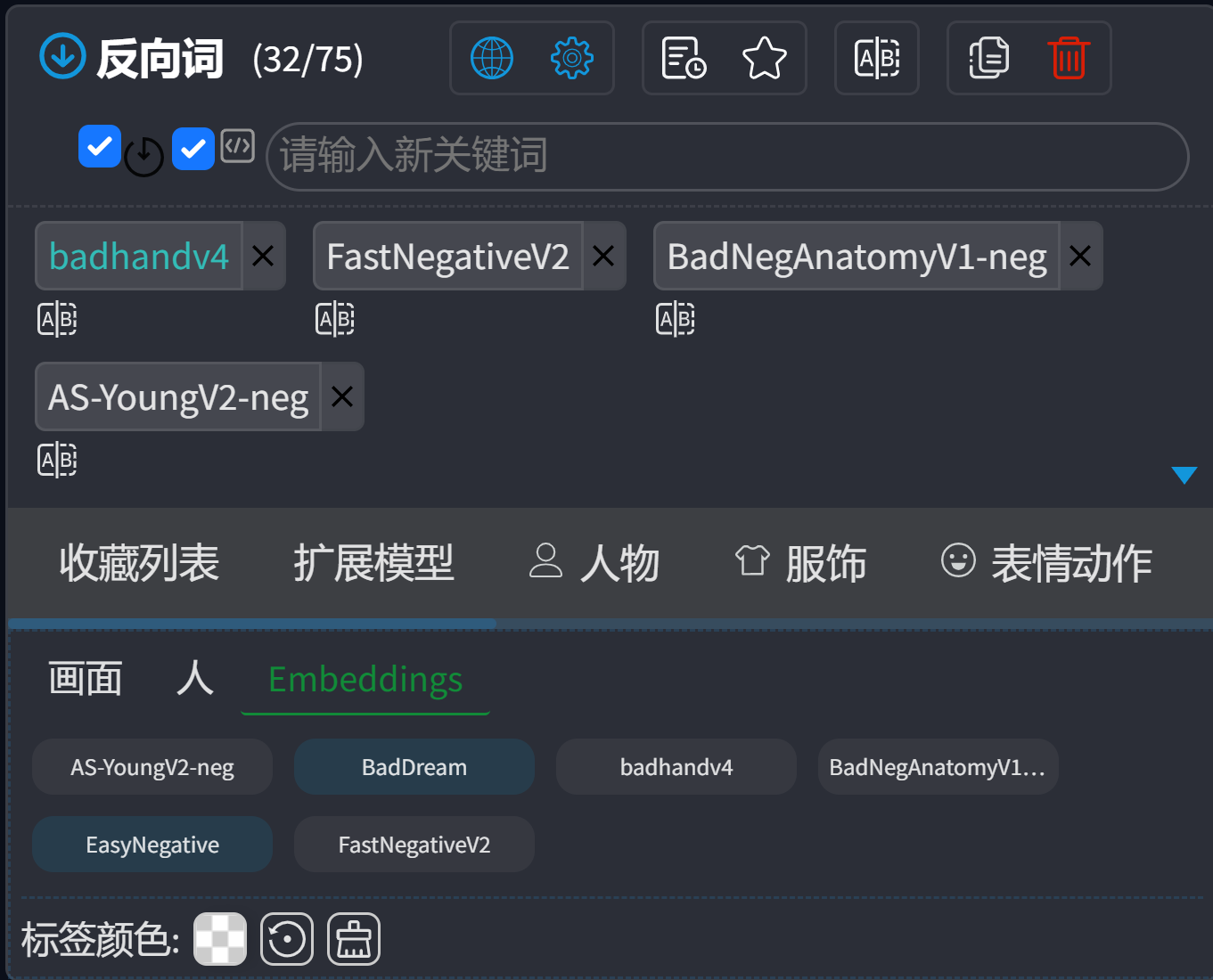
2.6 生成参考
纯扩散模型的随机性实在太高!生成质量也参差不齐,往往需要生成很多张才能挑选到一张满意的作品。使用ControlNet可以在一定程度上缓解这个问题,这部分内容我们之后再详细讨论。下面来看个实际例子:
参数设置:
- SD模型:夜羊社v1.2
- VAE模型:animevae.pt
- CLIP层数:2
- 正向提示词:(1girl),serafuku,smile,kawaii,in autumn,(badhandv4:0.6)
- 反向提示词:badhandv4,FastNegativeV2,BadNegAnatomyV1-neg,AS-YoungV2-neg
- 图像尺寸:707x1000
生成结果展示:



3. 采样方法
位于界面的这个位置:
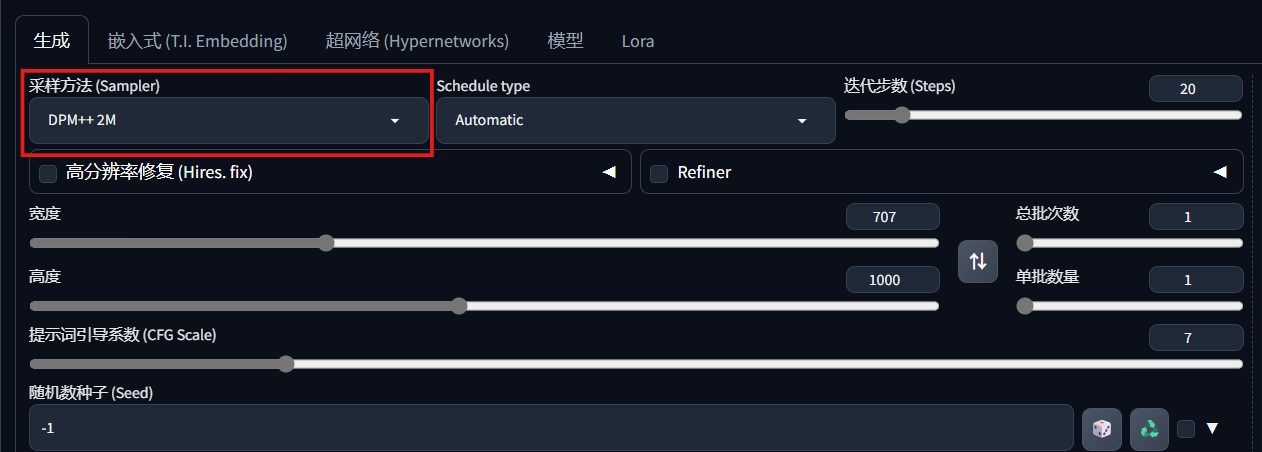
提供以下选项:
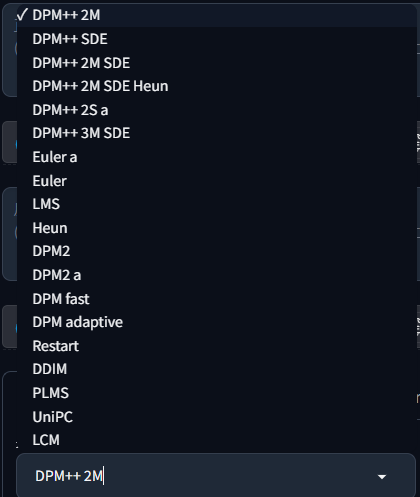
采样方法控制图像生成的迭代优化逻辑,决定了模型如何逐步优化图像:从随机噪声开始,每一步"采样"修正细节,直到形成最终画面。不同方法的主要差异在于优化策略(例如"大步快速修正"还是"精细逐步调整"),进而影响最终的出图效果,尤其是在细节表现和生成速度方面。
选择合适的采样器,理论上可以按照以下需求来选择:
- 追求速度:LCM(速度最快)> UniPC(适合5-10步快速生成)> Euler(适合20-30步)
- 追求细节:DPM++ 2M SDE Heun(极致细节表现)> DPM++ 2M SDE(高细节)> DPM++ 2M(平衡型)
- 追求创意:Euler a(艺术感强)> DPM2 a(创意+细节兼顾)
- 日常通用:DPM++ 2M(新手首选,适应绝大多数场景)
我使用的是性能一般的GTX 2050显卡,显存仅4GB,下面是使用前面提到的提示词进行的对比测试:
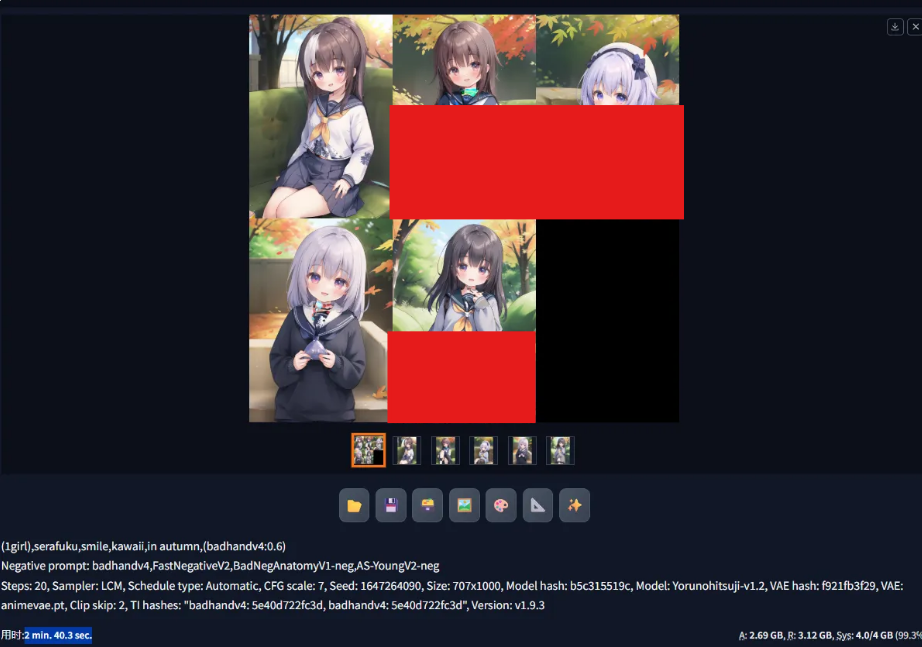
LCM示例:
生成5张图耗时2分40.3秒。不过这个方法r率意外地高…怎么全是男性角色
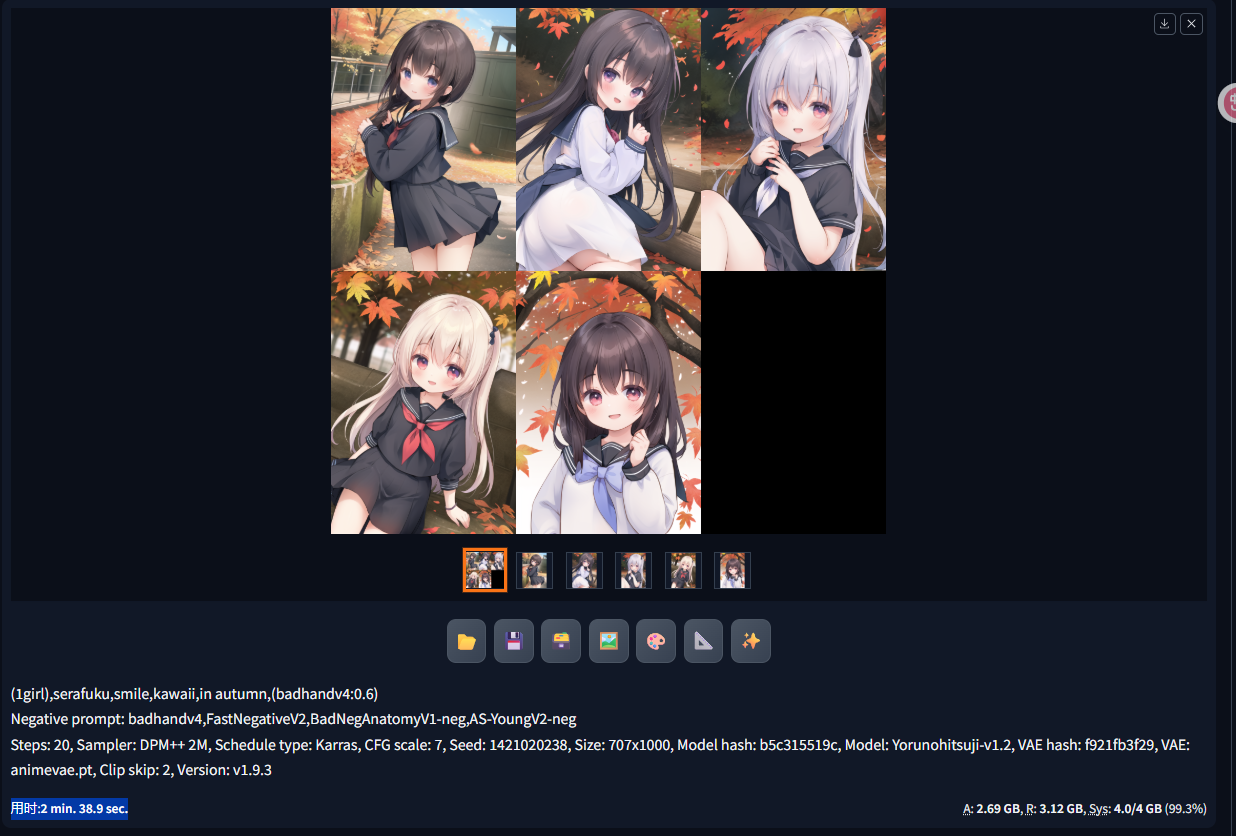
DPM++ 2M示例:
生成5张图耗时2分38.9秒。
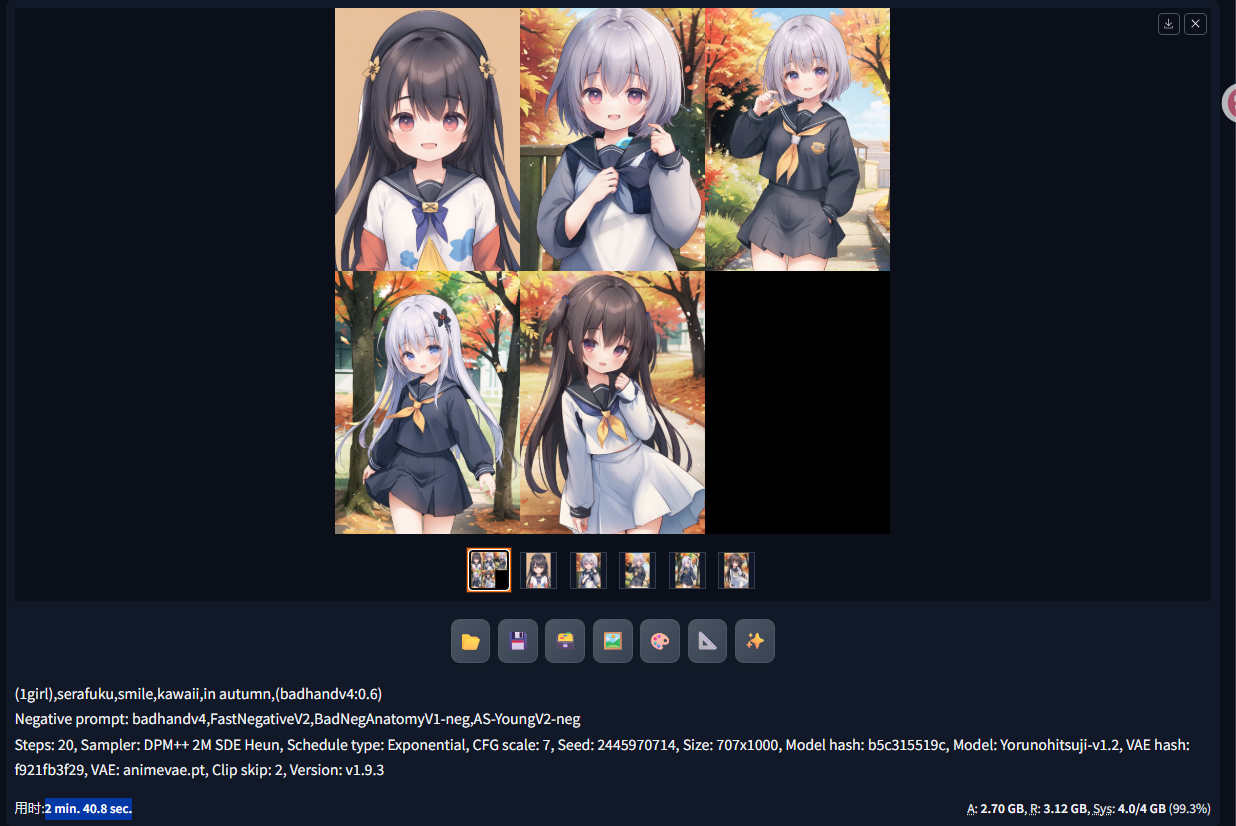
DPM++ 2M SDE Heun示例:
生成5张图耗时2分40.8秒。
总体评价:不同采样方法的结果和速度差异不是很明显。后来我才发现,这是因为我的步数设置太低了,只有20步,导致那些复杂算法的额外计算量还没有充分体现出来,所以时间相差不大。
4. 噪声调度器
位于界面的这个位置:
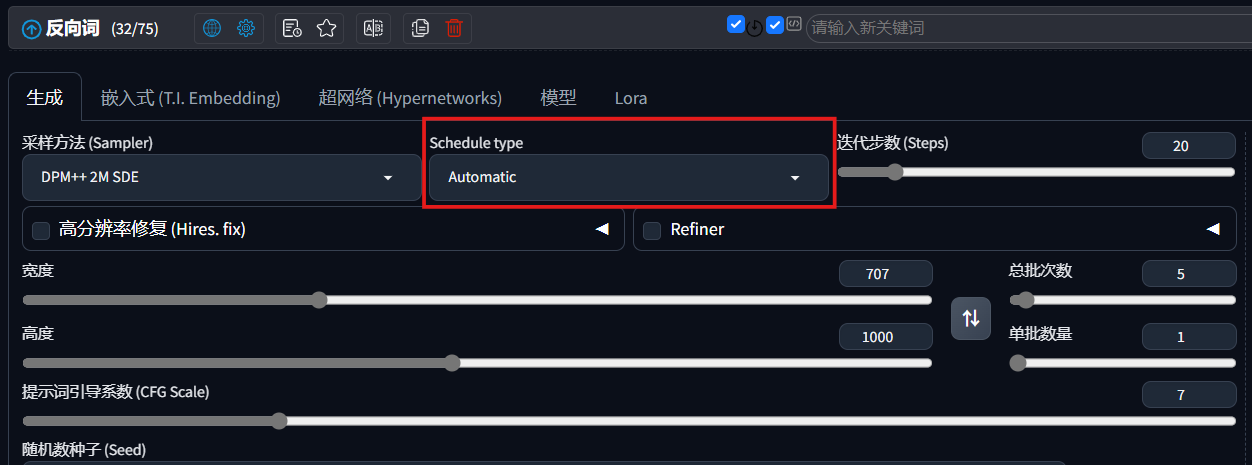
提供以下选项:
在生成图像的过程中,模型需要从充满噪声的图像逐步去噪以得到清晰画面。噪声调度器决定了每一步去噪时噪声强度如何降低,直接影响画面的细节、风格和收敛速度。
- 快节奏调度器(如Uniform):噪声降低速度快,画面收敛快但细节较少;
- 慢节奏调度器(如Karras):噪声降低速度慢,画面细节丰富但生成时间较长。
推荐选择以下几种调度器:
- Karras:
最常用的调度器!由Stable Diffusion团队专门优化,平衡了细节表现和收敛速度,适合绝大多数场景(尤其是写实和二次元风格)。
特点:去噪节奏合理,画面细节丰富且稳定,新手可以无脑选择。 - Automatic:
自动适配型调度器,会根据所选采样方法和步数"智能选择最佳节奏",效果接近Karras,特别适合不想纠结参数设置的用户。 - Uniform:
噪声强度"匀速降低",去噪节奏最快,画面收敛极快但细节相对较少,适合生成抽象或低精度图像(如快速测试提示词效果)。 - Exponential:
噪声强度"指数级降低",前期去噪缓慢(保留更多噪声→产生更多创意),后期快速收敛,适合生成艺术感强、风格独特的图像(如印象派风格或梦幻场景)。
噪声调度器与采样方法相互影响,例如:
- Karras(调度器)+ DPM++ 2M(采样)→ 日常出图的最佳组合;
- Exponential(调度器)+ Euler a(采样)→ 艺术创意效果拉满,特别适合抽象风格作品。
5. 迭代步数
位于界面的这个位置:
在生成图像的过程中,模型从完全噪声的图像开始,每一步"迭代"都会去除部分噪声并优化细节,最终形成清晰画面。迭代步数就是这个过程需要经历的次数,直接影响画面的细节丰富度、质量和生成时间。
1. 低步数(约10-20步)
- 效果:画面细节较少、可能模糊(噪声未完全去除),但生成速度快。
- 适用场景:快速测试提示词效果(了解大致构图是否可行)、生成草图或草稿。
2. 中步数(约20-40步)
- 效果:画面细节逐渐丰富(轮廓清晰、基本元素完整),速度和质量较为平衡。
- 适用场景:日常创作(二次元、插画等)、对细节要求不是特别极致的场合。
3. 高步数(约40-100步)
- 效果:画面细节极其丰富(发丝、纹理、光影过渡自然),但生成时间较长。
- 适用场景:写实肖像、商业级插画、高精度场景(如建筑、风景等)。
需要注意的是,步数并非越高越好。步数过高会遇到"边际效应":超过50-60步后,细节提升效果越来越不明显,但时间消耗却大幅增加。同时,步数需要与采样方法、模型类型和图像分辨率配合考虑。创意型采样方法(如Euler a)和某些特殊模型可能需要稍高的步数才能充分展现艺术细节,而图像分辨率越高,也需要相应提高步数以避免细节丢失。
6. 提示词引导系数 CFG Scale
位于界面的这个位置:
提示词引导系数控制提示词对生成图像的影响强度。值越小,生成的图像可能与提示词的关联度较低,但艺术创意性更强(适合抽象、超现实风格);值越大,AI越"严格听话",生成的图像更贴近提示词描述,但可能失去一些随机性和创意性(适合写实、精准需求)。日常创作通常选择7作为平衡点。
乍看之下,这个参数似乎与CLIP层数效果类似,但它们控制的维度不同:CLIP层数主要影响的是提示词的语义挖掘深度,而CFG则影响的是提示词与整个画面的关联程度。以生成"赛博朋克城市"为例,调整CFG Scale可以控制画面与赛博朋克风格的贴合度,调整CLIP终止层数则控制对"赛博朋克城市"这一概念语义细节的挖掘深度,两者共同作用于最终画面效果。在实际创作中,调整其中一个参数后,可能需要相应调整另一个以达到最佳效果。例如,提高CLIP终止层数(让模型更关注细节)时,如果发现画面过于僵硬,可适当降低CFG Scale来平衡;降低CLIP终止层数追求创意时,若画面偏离主题太远,则可提高CFG Scale拉回与提示词的关联。
实用参考:
- 日常创作建议选择7-9(效果平衡且稳定)。
- 创意风格建议选择3-5(让AI有更多创作自由)。
- 写实/精准需求建议选择10-12(但注意不要太高,容易导致画面崩坏)。
- 数值超过15时,必须同时提高迭代步数(建议50步以上),否则画面很可能崩坏。
- 迭代步数较低时,CFG不宜设置过高(避免画面崩坏);
- 提示词较复杂时,可适当提高CFG(帮助AI更好把握核心细节);
- 使用LCM等快速采样时,CFG应当调低(建议1-2,否则会产生冲突)。
示例:以简单的"a cat"作为提示词,迭代步数设为20,对比不同CFG值的效果:
cfg=30(过高,画面开始崩坏):

cfg=15(较高,还算可接受):

cfg=7(平衡值,效果最自然):

cfg=1(过低,几乎忽略提示词)