C++内联函数(inline)的作用
C++内联函数的作用
数据结构之栈(Stack)
下图来自:函数调用/调用栈(call stack)

先进来的后出去,后进去的先出来,后进先出(LIFO)

函数调用栈
每个函数最终都必须将控制权返回给调用它的函数。系统必须以某种方式跟踪每个函数为了将控制权返回给调用它的函数所需的返回地址。
函数调用栈是处理此信息的理想数据结构。每次一个函数调用另一个函数时,一个条目就会被压入栈中。这个条目 —— 称为栈帧或活动记录 —— 包含被调用函数返回给调用函数所需的返回地址。
下图来自:栈的基础知识-函数调用栈的过程图解

调用栈的美妙之处在于,每个被调用函数总能在调用栈顶找到它返回给调用者所需的信息。如果一个函数调用另一个函数,新函数调用的栈帧就简单地被压入调用栈。因此,新被调用函数返回给调用者所需的返回地址现在就在栈顶。
后进先出这种行为正好是一个函数返回给调用它的函数
返回类型 func3(参数){...
}
返回类型 func2(参数){...func3(b);
}
返回类型 func1(参数){..func2(a);
}
调用顺序:func1、func2、func3
进栈顺序:func1、func2、func3
函数执行:func3结果给func2,func2结果给func3
出栈顺序:func3、func2、func1

下图来自:函数调用栈

下图来自:栈的基础知识-函数调用栈的过程图解
过程
函数调用栈是指程序运行时内存一段连续的区域,用来保存函数运行时的状态信息,包括函数参数与局部变量等。
称之为“栈”是因为发生函数调用时,调用函数(caller)的状态被保存在栈内,被调用函数(callee)的状态被压入调用栈的栈顶
在函数调用结束时,栈顶的函数(callee)状态被弹出,栈顶恢复到调用函数(caller)的状态。
函数调用栈在内存中从高地址向低地址生长,所以栈顶对应的内存地址在压栈时变小,退栈时变大。—引用:栈的基础知识-函数调用栈的过程图解
被调函数返回给调用函数后,被调函数的非静态局部变量(non-static)都会被销毁,静态变量(static)不会

函数调用例子

步骤一:操作系统调用main函数

栈帧告知main函数如何返回到操作系统(也就是说,转移到返回地址R1),并且栈帧中包含了main函数的局部变量a的空间,a被初始化为10,还包含了局部变量result的空间,result尚未被初始化。
步骤二:main函数调用square函数

这个栈帧包含了函数square返回至main函数时所需的返回地址(即R2),以及函数square的局部变量x所占用的内存空间。
步骤三:square返回其结果给main函数
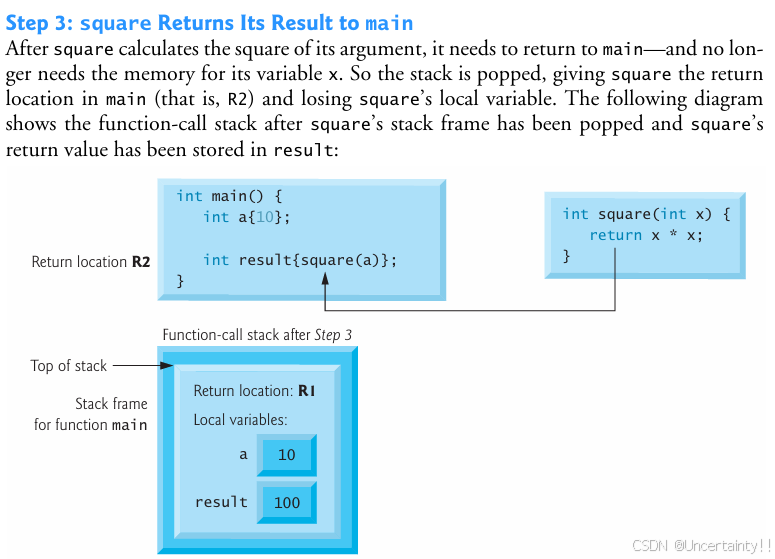
当执行到main函数的右花括号(表示函数结束)时,main函数的栈帧会从栈中弹出。这就为main函数提供了它返回操作系统所需的地址(即前面图中的R1)。在这一时刻,main函数的局部变量a和result就不再可用了。
内联函数(inline)的作用
C++ 提供内联函数以帮助减少函数调用开销
为了消除函数调用的时空开销,C++ 提供一种提高效率的方法,即在编译时将函数调用处用函数体替换,类似于C语言中的宏展开。这种在函数调用处直接嵌入函数体的函数称为内联函数(Inline Function)。但也存在缺点,就是每一调用处均会展开,增加了重复的代码量。–引用 【C++】C++中内联函数详解(搞清内联的本质及用法)
在函数定义中,将 “inline” 置于函数返回类型之前,这是在建议编译器在每次调用该函数的地方(在合适的情况下)生成该函数主体代码的副本,以此避免函数调用,不过这样可能会使程序体积变大,并且编译器也可能忽略 “inline” 限定符。
可复用的内联函数通常放在头文件中,以便其定义能在每个使用它们的源文件中进行内联。
《C++ 核心准则》建议将 “短小且对时间要求严格” 的函数声明为内联函数。
// inline function that calculates the volume of a cube.
#include <iostream>
using namespace std;
// Definition of inline function cube. Definition of function appears
// before function is called, so a function prototype is not required.
// First line of function definition also acts as the prototype.
inline double cube(double side) { return side * side * side; // calculate cube
} int main() {double sideValue; // stores value entered by user cout << "Enter the side length of your cube: ";cin >> sideValue; // read value from user// calculate cube of sideValue and display resultcout << "Volume of cube with side " << sideValue << " is " << cube(sideValue) << '\n';
内联函数在哪定义和声明?
推荐文章:【C++】C++中内联函数详解(搞清内联的本质及用法)
内联函数是定义在头文件还是源文件?
内联展开是在编译时进行的,只有链接的时候源文件之间才有关系。内联要想跨源文件必须把实现写在头文件里。----引用 【C++】C++中内联函数详解(搞清内联的本质及用法)
内联函数的定义不一定要跟声明放在一个头文件里面
定义可以放在一个单独的头文件中,里面需要给函数定义前加上inline 关键字----引用 【C++】C++中内联函数详解(搞清内联的本质及用法)
一个头文件中定义
内联函数通常定义在头文件中,原因如下:
- 编译时展开需求:内联函数是在编译时进行代码展开的,这意味着在调用内联函数的地方,编译器会直接将函数体的代码插入到调用处。为了让编译器能够在多个源文件中都能找到内联函数的定义进行展开,就需要将内联函数的定义放在头文件中。这样,当不同的源文件包含该头文件时,编译器在编译每个源文件时都能获取到内联函数的定义,从而进行内联展开。如果内联函数定义在源文件中,其他源文件在编译时无法看到其定义,就无法进行内联展开。
- 跨源文件使用:在C++项目中,通常会有多个源文件相互协作。如果内联函数要在多个源文件中被调用,就必须保证每个源文件都能访问到其定义。由于头文件会被包含到各个源文件中,将内联函数定义在头文件中可以满足跨源文件使用的需求。
// 文件名:my_header.h
#ifndef MY_HEADER_H
#define MY_HEADER_H// 内联函数定义在头文件中
inline int add(int a, int b) {return a + b;
}#endif// 文件名:main.cpp
#include <iostream>
#include "my_header.h"int main() {int result = add(3, 5);std::cout << "The result of addition is: " << result << std::endl;return 0;
}
在这个例子中,add 函数是一个内联函数,它的定义直接写在了 my_header.h 头文件中。main.cpp 包含了这个头文件后,就可以调用 add 函数,编译器在编译 main.cpp 时会看到 add 函数的定义并进行内联展开。
一个头文件声明,另一个头文件定义
不过,虽然内联函数通常定义在头文件中,但也有一些特殊情况或不同的做法:
- 分离声明和定义:内联函数的定义不一定要跟声明放在同一个头文件里面,定义可以放在一个单独的头文件中,里面需要给函数定义前加上
inline关键字。这样可以将内联函数的声明和定义分开,使代码结构更加清晰,特别是对于一些比较复杂的内联函数,可能会将其定义放在一个专门的内联函数定义头文件中,而在其他头文件中只进行声明。 - 模板内联函数:对于模板内联函数,其定义通常也放在头文件中。因为模板函数在实例化时需要知道函数的具体定义,所以将模板内联函数的定义放在头文件中,方便编译器在不同源文件中实例化模板时找到函数定义进行内联展开。
也有将内联函数定义在源文件中的情况,但这样做会限制内联函数的使用范围,使其只能在当前源文件中被内联展开,其他源文件无法使用该内联函数,违背了内联函数提高效率和代码复用的初衷。因此,在实际开发中,为了充分发挥内联函数的优势,一般会将内联函数的定义放在头文件中。
// 文件名:my_inline_functions.h
#ifndef MY_INLINE_FUNCTIONS_H
#define MY_INLINE_FUNCTIONS_H// 内联函数声明
inline int multiply(int a, int b);#endif// 文件名:my_inline_functions_definition.h
#ifndef MY_INLINE_FUNCTIONS_DEFINITION_H
#define MY_INLINE_FUNCTIONS_DEFINITION_H#include "my_inline_functions.h"// 内联函数定义,注意前面的 inline 关键字
inline int multiply(int a, int b) {return a * b;
}#endif// 文件名:main.cpp
#include <iostream>
#include "my_inline_functions_definition.h"int main() {int result = multiply(4, 6);std::cout << "The result of multiplication is: " << result << std::endl;return 0;
}