机器学习基础(四) 决策树
决策树简介
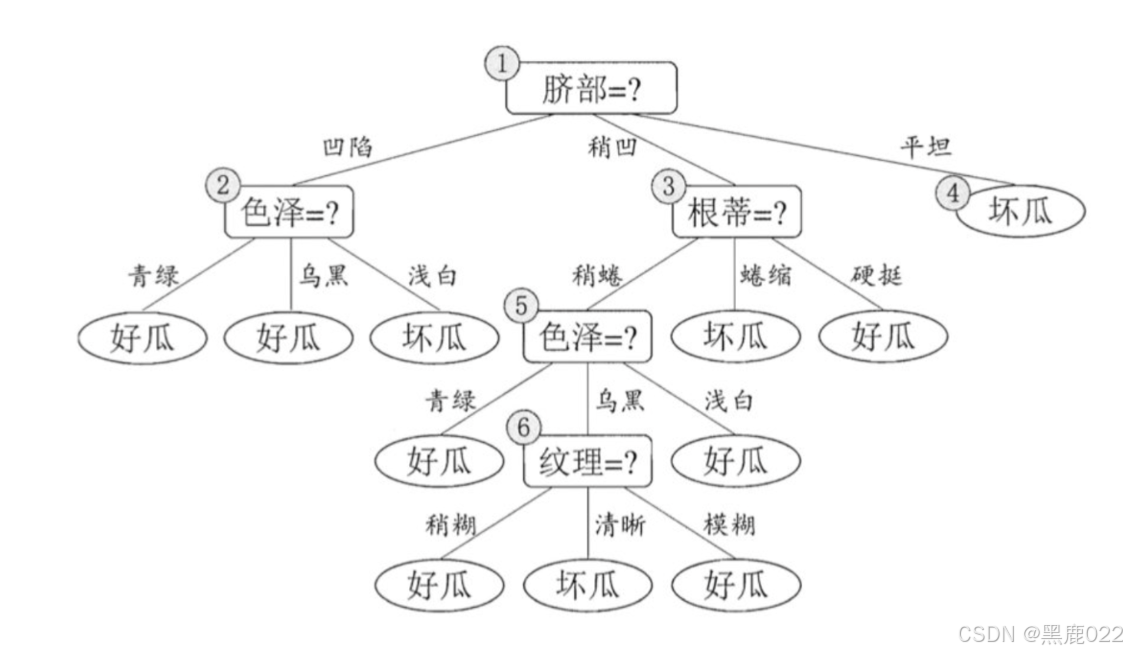
决策树结构:
决策树是一种树形结构,树中每个内部节点表示一个特征上的判断,每个分支代表一个判断结果的输出,每个叶子节点代表一种分类结果
决策树构建过程(三要素):
- 特征选择
选择较强分类能力的特征 - 决策树的生成
根据选择的特征生成决策树 - 决策树的剪枝
决策树也容易过拟合,采用剪枝的方法缓解过拟合
信息熵
信息熵
“信息熵”:是信息论中的一个核心概念,它本质上是对不确定性或信息量的度量。
随机变量不确定度的度量
信息熵越大,信息的不确定性越大,信息的确定性越小,信息的纯度越低,分类的效果越差
公式:
H ( D ) = − Σ ( p k ∗ l o g 2 p k ) H(D)=-\Sigma(p_k*log_2p_k) H(D)=−Σ(pk∗log2pk)
D:当前的数据集(样本集合)。
pk:数据集 D 中第 k 类样本所占的比例。pk = |Ck| / |D|,其中 |Ck| 是第 k 类样本的数量,|D| 是总样本数。
信息增益和ID3决策树
ID3决策树是使用信息增益进行特征划分的。
信息增益基于信息论中的熵概念,用来评估通过某个特征对数据集进行分割后所带来的纯度提升或不确定性减少的程度。简单来说,信息增益越大,表示使用该特征进行划分能更有效地降低数据集的混乱程度。
g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)
g(D,a):表示数据集D上使用属性a进行划分的信息增益
H(D):表示数据集D的熵,衡量了数据集的不确定性或混乱程度
H(D|A): 表示在已知属性A的条件下,数据集D的条件熵,即在给定属性A的情况下数据集的剩余不确定性。
决策树的生成
1.计算每个特征的信息增益
2.使用信息增益最大的特征将数据集拆分为子集
3.使用该特征(信息增益最大的特征)作为决策树的一个节点
4.若该节点已成功分类(节点中只有一个类的样本)或该节点达到停止生长条件,则停止生长,否则使用剩余特征对子集重复上述(1,2,3)过程
不足:基于信息增益计算的方式,会偏向于选择种类多的特征作为分裂依据
C4.5决策树
核心目的:解决ID3算法中信息增益(Information Gain)对多值特征的偏好问题,避免了过拟合问题。
C4.5是使用信息增益率进行特征选择的。本质是给信息增益添加了一个和特征数量相关的惩罚系数。
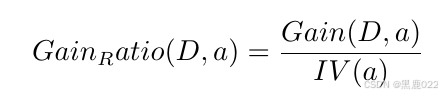
其中:
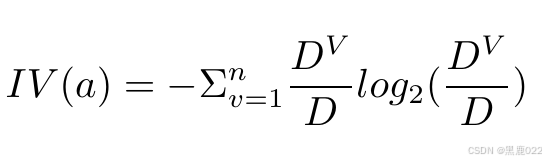
决策树的生成
类似ID3,只是调整为基于信息增益率进行特征选择。
CART (Classification and Regression Tree) 决策树
CART树结构是一种决策树模型,二叉树结构,既可以用于分类任务又可以用于回归任务。
CART是使用基尼系数(Gini)来进行特选择的。
基尼系数
Gini值本质:从数据集D中随机抽取两个样本,其类别标记不一致的概率。 故,Gini(D)值越小,数据集D的纯度越高。
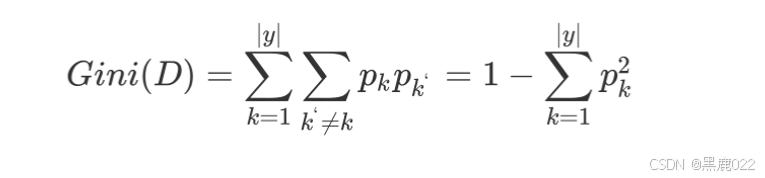
基尼指数:选择使划分后基尼系数最小的属性作为最优化分属性。
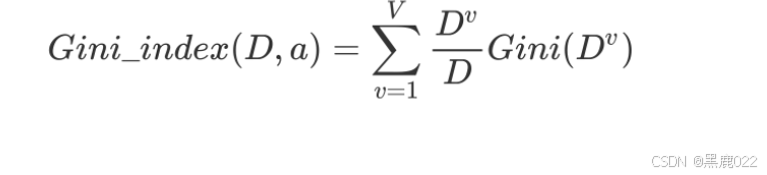
基尼指数值越小,则说明优先选择该特征。
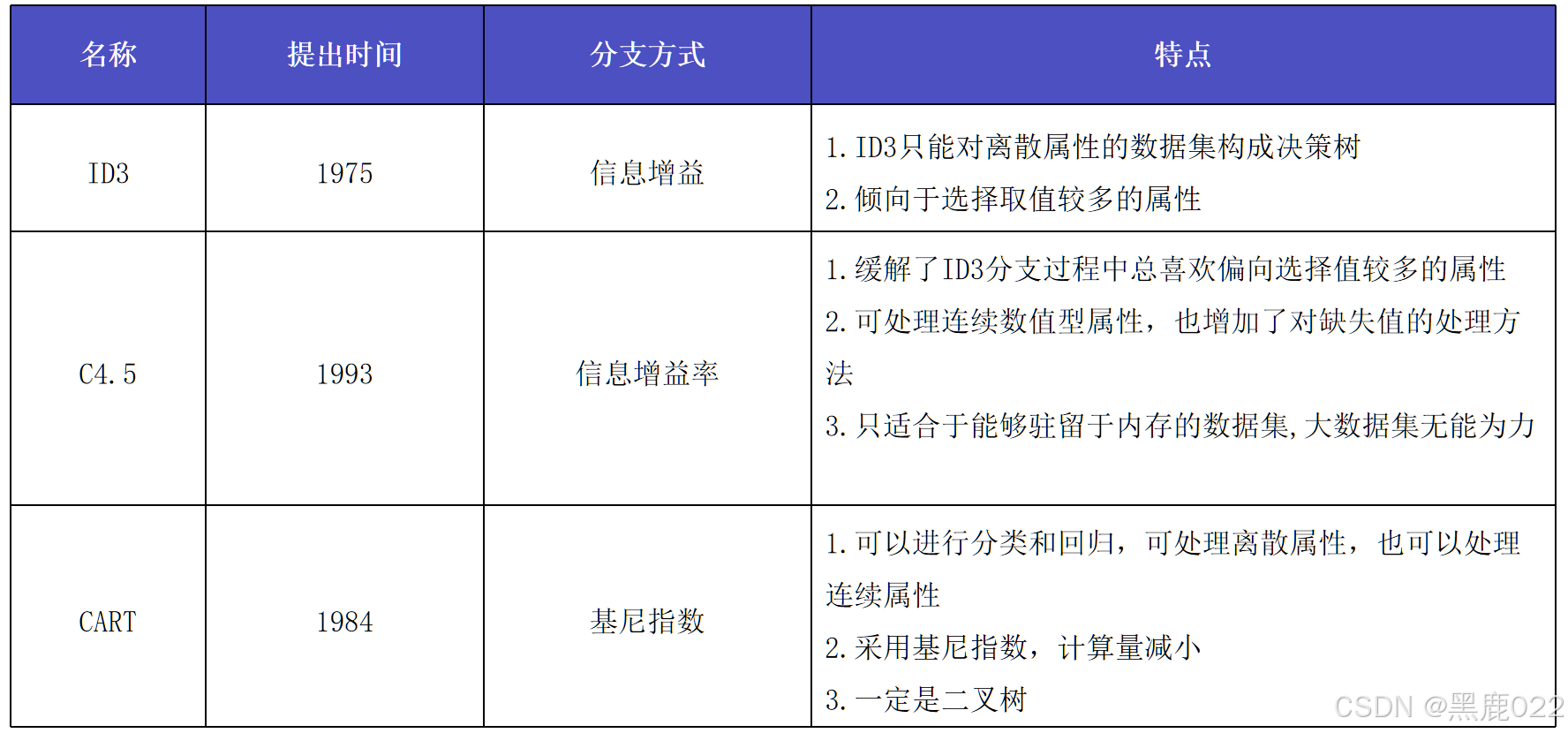
三种决策树的区别
实践
数据下载地址:
https://tianchi.aliyun.com/dataset/192460
我们只使用其中的titanic_train.csv.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,classification_report,roc_auc_score# 1.加载并了解数据
train=pd.read_csv("titanic_train.csv")# 显示数据集的前几行,以便快速查看数据结构
print(train.head())print("------------------------------------------"*3)
print("训练数据的详细描述:")
# 提供数据集的详细描述,包括每列的非空值数量和数据类型
train.info()
print("我们发现Age,Embarked两列都有缺失值。")
print("------------------------------------------"*3)# 选择特征变量和目标变量
x = train[['Pclass', 'Sex', 'Age', 'Embarked','Ticket']]
y = train['Survived']# 填充缺失值:使用平均值填充Age列的缺失值,使用前向填充法填充Embarked列的缺失值
x.loc[:,'Age']=x.loc[:,'Age'].fillna(x.loc[:,'Age'].mean())
x.loc[:,'Embarked']=x.loc[:,'Embarked'].ffill()
print("填充缺失值后:")
# 独热编码:将分类变量转换为独热编码表示,避免模型对数字类型的分类变量进行错误的数学运算
x=pd.get_dummies(x,drop_first=True)
x.info()
print(x.head())
print("------------------------------------------"*3)# 划分训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=666)# 数据标准化
ss=StandardScaler()
x_train=ss.fit_transform(x_train)
x_test=ss.transform(x_test)# 创建并训练决策树模型
dtc=DecisionTreeClassifier(max_depth=5)
dtc.fit(x_train,y_train)
y_predict=dtc.predict(x_test)# 模型评估
print(f"准确率:{dtc.score(x_test, y_test)}")
print(f"精确率:{precision_score(y_test, y_predict)}")
print(f"召回率:{recall_score(y_test, y_predict)}")
print(f"F1:{f1_score(y_test, y_predict)}")
print(f"ROC_AUC:{roc_auc_score(y_test, y_predict)}")
print(f"分类报告{classification_report(y_test, y_predict, target_names=['Died', 'Survivor'])}")"""PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S[5 rows x 12 columns]
------------------------------------------------------------------------------------------------------------------------------
训练数据的详细描述:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 PassengerId 891 non-null int64 1 Survived 891 non-null int64 2 Pclass 891 non-null int64 3 Name 891 non-null object 4 Sex 891 non-null object 5 Age 714 non-null float646 SibSp 891 non-null int64 7 Parch 891 non-null int64 8 Ticket 891 non-null object 9 Fare 891 non-null float6410 Cabin 204 non-null object 11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
我们发现Age,Embarked两列都有缺失值。
------------------------------------------------------------------------------------------------------------------------------
填充缺失值后:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Columns: 685 entries, Pclass to Ticket_WE/P 5735
dtypes: bool(683), float64(1), int64(1)
memory usage: 608.3 KBPclass Age ... Ticket_W/C 14208 Ticket_WE/P 5735
0 3 22.0 ... False False
1 1 38.0 ... False False
2 3 26.0 ... False False
3 1 35.0 ... False False
4 3 35.0 ... False False[5 rows x 685 columns]
------------------------------------------------------------------------------------------------------------------------------
准确率:0.8044692737430168
精确率:0.8571428571428571
召回率:0.6
F1:0.7058823529411765
ROC_AUC:0.7678899082568807
分类报告 precision recall f1-score supportDied 0.78 0.94 0.85 109Survivor 0.86 0.60 0.71 70accuracy 0.80 179macro avg 0.82 0.77 0.78 179
weighted avg 0.81 0.80 0.80 179"""