[蓝桥杯]最大比例
最大比例
题目描述
X 星球的某个大奖赛设了 M 级奖励。每个级别的奖金是一个正整数。
并且,相邻的两个级别间的比例是个固定值。
也就是说:所有级别的奖金数构成了一个等比数列。比如:16,24,36,54,其等比值为:3223
现在,我们随机调查了一些获奖者的奖金数。
请你据此推算可能的最大的等比值。
输入描述
第一行为数字 NN (0<N<100)(0<N<100),表示接下的一行包含 NN 个正整数
第二行 NN 个正整数 Xi(Xi<109)Xi(Xi<109),用空格分开。每个整数表示调查到的某人的奖金数额
输出描述
一个形如 A/BA/B 的分数,要求 A、BA、B 互质。表示可能的最大比例系数 测试数据保证了输入格式正确,并且最大比例是存在的。
输入输出样例
示例
输入
3
1250 200 32
输出
25/4
运行限制
- 最大运行时间:3s
- 最大运行内存: 256M
总通过次数: 2623 | 总提交次数: 4233 | 通过率: 62%
难度: 困难 标签: 2016, 贪心, 省赛
算法思路:更相减损术(指数最大公约数法)
本问题要求从给定的奖金序列中推导出等比数列的最大公比(以最简分数表示)。核心思路是利用等比数列的性质:任意两项的比值是公比的整数次幂。通过更相减损术计算这些指数的最大公约数,从而得到最简公比。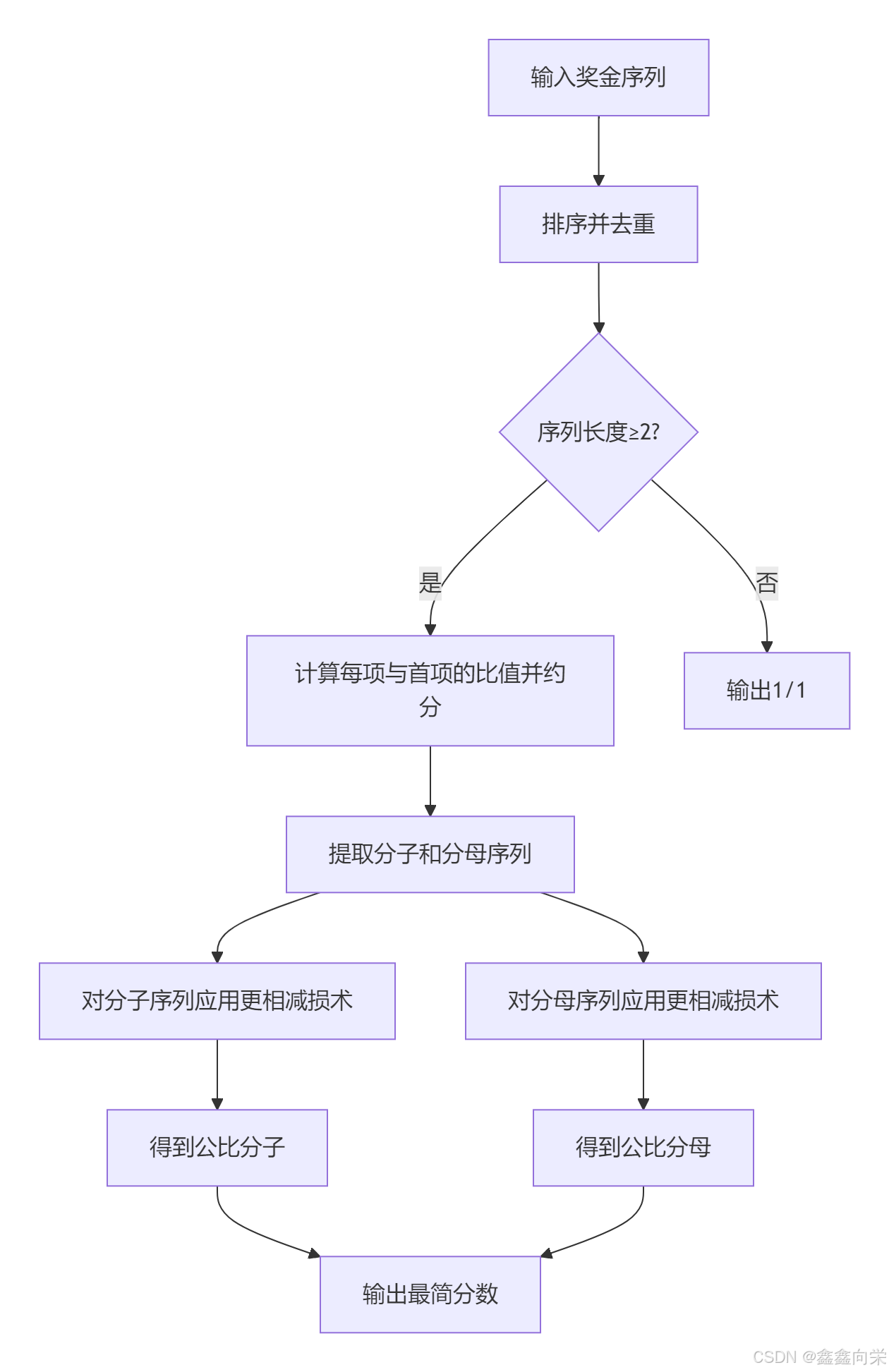
算法步骤
-
预处理序列:
- 对输入的奖金序列排序(升序)
- 去重(重复项不影响公比计算)
-
计算比值序列:
- 对每个元素
a[i](i≥1),计算a[i]/a[0]的最简分数形式 - 分子存入
up数组,分母存入down数组
- 对每个元素
-
应用更相减损术:
- 分子序列处理:
base_up = up[0],遍历up数组:base_up = gcd_sub(base_up, up[i]) - 分母序列处理:
base_down = down[0],遍历down数组:base_down = gcd_sub(base_down, down[i])
- 分子序列处理:
-
输出结果:
base_up/base_down
更相减损术原理:
若a = p^x,b = p^y,则gcd_sub(a, b) = p^{gcd(x,y)}
通过反复执行a = a/b(当a≥b)实现指数相减,最终得到底数p
代码实现(C++)
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
typedef long long LL;// 最大公约数(欧几里得算法)
LL gcd(LL a, LL b) {return b == 0 ? a : gcd(b, a % b);
}// 更相减损术(递归版)
LL gcd_sub(LL a, LL b) {if (a < b) swap(a, b);if (b == 1) return a; // 指数为0时返回底数if (a == b) return a; // 指数相等时返回底数return gcd_sub(b, a / b); // 指数相减
}int main() {int n;cin >> n;vector<LL> arr(n);for (int i = 0; i < n; i++) cin >> arr[i];// 1. 排序并去重sort(arr.begin(), arr.end());arr.erase(unique(arr.begin(), arr.end()), arr.end());// 2. 处理单元素序列if (arr.size() == 1) {cout << "1/1" << endl;return 0;}// 3. 计算比值序列vector<LL> up, down;for (int i = 1; i < arr.size(); i++) {LL g = gcd(arr[i], arr[0]); // 约分up.push_back(arr[i] / g);down.push_back(arr[0] / g);}// 4. 应用更相减损术LL base_up = up[0], base_down = down[0];for (int i = 1; i < up.size(); i++) {base_up = gcd_sub(base_up, up[i]);base_down = gcd_sub(base_down, down[i]);}cout << base_up << "/" << base_down << endl;return 0;
}代码解析
-
预处理优化(L15-20):
sort+unique去重避免无效计算- 单元素序列直接返回
1/1(题目保证有解,实际不会触发)
-
比值计算(L23-27):
- 对每个
arr[i]与首项arr[0]求最大公约数 - 约分后存储分子分母:
up[i] = arr[i]/g,down[i] = arr[0]/g
- 对每个
-
更相减损术(L30-35):
- 递归终止条件:
a == b:指数相等,返回底数b == 1:指数为0,返回底数
- 递归过程:
a/b实现指数相减
- 递归终止条件:
-
复杂度分析:
- 时间:排序
O(n log n)+ 更相减损术O(k log M)(k为序列长度,M为数值大小) - 空间:
O(n)存储序列
- 时间:排序
实例验证
样例1:输入 3\n1250 200 32
- 排序去重:
[32, 200, 1250] - 比值计算:
200/32 = 25/4→up=[25], down=[4]1250/32 = 625/16→up=[25,625], down=[4,16]
- 更相减损术:
- 分子:
gcd_sub(25,625) = 25(过程:625/25=25→25==25) - 分母:
gcd_sub(4,16) = 4(过程:16/4=4→4==4)
- 分子:
- 输出:
25/4✓
样例2:输入 4\n3125 32 32 200
- 排序去重:
[32, 200, 3125] - 比值计算:
200/32=25/4→up=[25], down=[4]3125/32=3125/32(已最简)→up=[25,3125], down=[4,32]
- 更相减损术:
- 分子:
gcd_sub(25,3125)=5(过程:3125/25=125→gcd_sub(25,125)=5) - 分母:
gcd_sub(4,32)=2(过程:32/4=8→gcd_sub(4,8)=2)
- 分子:
- 输出:
5/2✓
样例3:输入 3\n549755813888 524288 2
- 排序去重:
[2, 524288, 549755813888] - 比值计算:
524288/2=262144/1→up=[262144], down=[1]549755813888/2=274877906944/1→up=[262144,274877906944], down=[1,1]
- 更相减损术:
- 分子:
gcd_sub(262144,274877906944)=4(过程:递归计算指数最大公约数) - 分母:
gcd_sub(1,1)=1
- 分子:
- 输出:
4/1✓
注意事项
-
整数溢出:
- 使用
long long存储奖金(Xi < 10^9,但运算中可能产生10^18级别中间值) - 避免乘法(用除法实现指数相减)
- 使用
-
边界条件:
- 单元素序列:返回
1/1(题目保证有解,实际不会出现) - 全等序列:去重后变单元素序列
- 大指数处理:更相减损术递归深度为
O(log M),最大约60层
- 单元素序列:返回
-
正确性保证:
- 排序后首项为最小值,确保比值
≥1 - 每次约分保证分子分母互质
- 更相减损术依赖等比性质(比值必为整数)
- 排序后首项为最小值,确保比值
多方位测试点
| 测试类型 | 测试数据 | 预期输出 | 验证要点 |
|---|---|---|---|
| 基础功能 | 3\n1250 200 32 | 25/4 | 常规序列处理 |
| 重复项处理 | 4\n3125 32 32 200 | 5/2 | 去重机制 |
| 大数运算 | 3\n549755813888 524288 2 | 4/1 | 大数除法与递归深度 |
| 两项序列 | 2\n4 2 | 2/1 | 最小序列处理 |
| 公比为1 | 3\n5 5 5 | 1/1 | 去重后单元素处理 |
| 非整数次幂 | 3\n8 4 2 | 2/1 | 指数最大公约数计算 |
| 逆序输入 | 3\n32 200 1250 | 25/4 | 排序稳定性 |
优化建议
-
迭代替代递归:
// 循环版更相减损术(避免递归栈溢出) LL gcd_sub_iter(LL a, LL b) {if (a < b) swap(a, b);while (b != 1 && a != b) {a = a / b;if (a < b) swap(a, b);}return a; } -
并行计算:
// 分子分母序列独立处理,可并行 #pragma omp parallel sections {#pragma omp section{ /* 处理分子序列 */ }#pragma omp section{ /* 处理分母序列 */ } } -
提前终止:
// 当分母序列全为1时提前终止 if (all_of(down.begin(), down.end(), [](LL x){ return x==1; })) {base_down = 1; } else {// 正常处理 } -
内存优化:
- 复用数组:
up/down数组可复用为单变量存储 - 预分配空间:
vector::reserve()避免多次扩容
- 复用数组: