网络爬虫一课一得
网页爬虫(Web Crawler)是一种自动化程序,通过模拟人类浏览行为,从互联网上抓取、解析和存储网页数据。其核心作用是高效获取并结构化网络信息,为后续分析和应用提供数据基础。以下是其详细作用和用途方向:
一、核心作用
-
数据采集
- 自动遍历目标网站,提取文本、图片、视频、链接等公开数据。
- 支持定时抓取,实现数据的动态更新(如新闻、价格、社交媒体内容)。
-
信息结构化
- 将非结构化的网页内容(如HTML)转化为结构化数据(如JSON、CSV),便于数据库存储或分析。
-
效率提升
- 替代人工复制粘贴,处理大规模数据时速度更快、成本更低。
二、主要用途方向
1. 搜索引擎优化(SEO)
- 搜索引擎索引:Google、百度等通过爬虫建立网页索引库,支撑搜索结果。
- 竞品分析:抓取竞品网站的关键词、流量数据,优化自身SEO策略。
2. 商业与市场分析
- 价格监控:电商平台(如亚马逊、淘宝)抓取竞品价格,动态调整定价。
- 舆情分析:爬取社交媒体、论坛评论,分析用户对品牌/产品的评价。
3. 学术与研究
- 文献聚合:自动收集学术论文、专利数据(如PubMed、arXiv)。
- 社会趋势研究:分析新闻、博客内容,追踪公共事件的发展脉络。
4. 金融与投资
- 实时数据获取:抓取股票行情、财报、加密货币价格(如Yahoo Finance)。
- 风险预警:监测企业负面新闻或行业政策变动。
5. 人工智能与大数据
- 训练数据来源:为机器学习模型提供文本(NLP)、图像(CV)数据集。
- 语言模型训练:如ChatGPT的预训练数据部分来源于爬虫抓取的公开网页。
6. 生活服务
- 聚合平台:整合租房信息(如链家)、机票价格(如Skyscanner)。
- 内容推荐:新闻App(如今日头条)爬取多源内容进行个性化推送。
7. 技术运维与安全
- 死链检测:扫描网站内失效的链接或页面错误。
- 安全审计:识别网站漏洞(如敏感信息泄露)。
8. 政府与公共事务
- 政策监控:自动抓取政府网站的政策更新或招标信息。
- 灾害预警:收集气象、地震等实时数据。
三、注意事项
- 合法性:遵守
robots.txt协议,避免抓取敏感或个人隐私数据。 - 反爬机制:需处理验证码、IP封锁、动态加载(如JavaScript渲染)等技术挑战。
- 伦理问题:尊重数据版权,避免过度请求导致服务器负载。
抓取网页数据通常涉及以下几个步骤:发送HTTP请求 → 获取网页内容 → 解析数据 → 存储结果。以下是详细方法和常用工具:
一、基础方法
1. 手动复制粘贴
- 适用场景:少量静态数据(如单页文字、表格)。
- 缺点:效率低,无法自动化。
2. 浏览器开发者工具(DevTools)
- 步骤:
- 右键网页 → 选择“检查”(或按
F12/Ctrl+Shift+I)。 - 在
Elements标签页查看HTML结构,手动复制所需内容。 - 在
Network标签页分析API请求(适用于动态加载数据)。
- 右键网页 → 选择“检查”(或按
- 适用场景:快速查看网页结构或API接口。
二、编程抓取(自动化)
1. 使用 Python 的 requests + BeautifulSoup(静态页面)
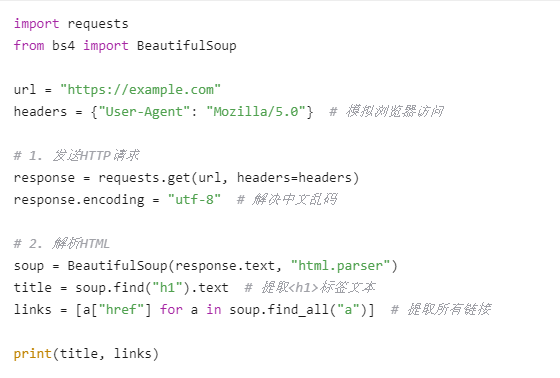
抓取网页数据通常涉及以下几个步骤:发送HTTP请求 → 获取网页内容 → 解析数据 → 存储结果。以下是详细方法和常用工具:
抓取网页数据通常涉及以下几个步骤:发送HTTP请求 → 获取网页内容 → 解析数据 → 存储结果。以下是详细方法和常用工具:
一、基础方法
1. 手动复制粘贴
- 适用场景:少量静态数据(如单页文字、表格)。
- 缺点:效率低,无法自动化。
2. 浏览器开发者工具(DevTools)
- 步骤:
- 右键网页 → 选择“检查”(或按
F12/Ctrl+Shift+I)。 - 在
Elements标签页查看HTML结构,手动复制所需内容。 - 在
Network标签页分析API请求(适用于动态加载数据)。
- 右键网页 → 选择“检查”(或按
- 适用场景:快速查看网页结构或API接口。
二、编程抓取(自动化)
1. 使用 Python 的 requests + BeautifulSoup(静态页面)

2. 动态页面抓取(如JavaScript渲染)
- 工具:
Selenium或Playwright(模拟浏览器操作)。

3. 通过API直接获取数据
- 许多网站(如Twitter、电商平台)通过API返回JSON数据。

三、进阶技巧
-
处理反爬机制:
- 设置请求头(如
User-Agent、Referer)。 - 使用代理IP(如
requests.get(proxies={"http": "ip:port"}))。 - 添加延迟(如
time.sleep(2))。
- 设置请求头(如
-
数据存储:
- 保存为CSV/Excel:
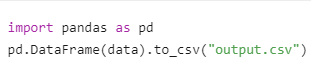
-
- 存入数据库(如MySQL、MongoDB)。
-
框架推荐:
- Scrapy:高性能爬虫框架,适合大规模抓取。
- PyQuery:类似jQuery的HTML解析库。
四、注意事项
-
合法性:
- 检查目标网站的
robots.txt(如https://example.com/robots.txt)。 - 避免高频请求(可能被封IP)。
- 检查目标网站的
-
道德约束:
- 不抓取个人隐私或付费内容。
- 遵守网站的服务条款。
五、完整示例(豆瓣电影Top250)

通过以上方法,你可以灵活应对不同场景的网页抓取需求。如需更复杂的功能(如登录、验证码识别),可结合OCR工具(如Tesseract)或自动化框架进一步扩展。
网络爬虫的应用场景和发展潜力远超基础的数据抓取,随着技术进步和需求演变,其用途不断扩展,未来还可能深度融合新兴技术。以下是更广泛的应用领域和未来趋势分析:
一、扩展应用场景
1. 垂直领域深度挖掘
- 医疗健康
- 抓取医学论文(PubMed)、药品价格、临床试验数据,辅助疾病研究或药物研发。
- 农业与环境
- 监测气象数据、土壤报告、农产品市场价格,优化种植或供应链管理。
2. 物联网(IoT)与智慧城市
- 爬取公共设施数据(如交通摄像头、空气质量传感器),用于实时路况分析或污染预警。
3. 区块链与加密货币
- 追踪链上交易数据(如以太坊浏览器)、交易所动态,分析市场操纵或合规风险。
4. 内容生成与AI训练
- 自动化写作:抓取新闻生成摘要(如AI新闻聚合平台)。
- 多模态数据集:收集图像、视频、音频(如自动驾驶训练需爬取街景图片)。
5. 反欺诈与安全
- 暗网监控:爬取暗网论坛数据,追踪数据泄露或犯罪交易(需合法授权)。
- 虚假广告检测:识别跨平台的诈骗广告模式。
6. 教育与文化保护
- 古籍数字化:自动抓取图书馆电子资源,构建文化遗产数据库。
- 慕课(MOOC)聚合:整合多平台课程资源供学习者检索。
二、未来发展趋势
1. 技术融合与智能化
- AI驱动的爬虫
- 结合NLP理解网页语义,自动识别关键内容(如区分新闻正文与广告)。
- 通过强化学习优化抓取路径,避开反爬陷阱。
- 低代码/无代码爬虫
- 工具如
Octoparse让非技术人员也能快速配置爬取任务。
- 工具如
2. 动态对抗升级
- 反爬技术进化:网站可能采用更复杂的验证(如行为指纹识别)。
- 爬虫的隐蔽性提升:模拟人类操作(鼠标移动、滚动)的“无头浏览器”将成为标配。
3. 伦理与法规完善
- GDPR/《数据安全法》合规:爬虫需明确数据来源授权,隐私保护技术(如差分隐私)可能被强制要求。
- 数据确权:区块链可能用于记录数据抓取链,确保可追溯性。
4. 边缘计算与分布式爬取
- 利用边缘节点(如CDN)分散请求,降低IP封锁风险,同时提升抓取速度。
5. 多模态数据融合
- 从纯文本转向抓取并关联视频、语音、传感器数据,构建更全面的分析模型(如舆情分析结合表情和语调)。
6. Web3.0与去中心化网络
- 爬虫可能适配IPFS(星际文件系统)等去中心化存储,抓取动态分布式内容。
三、潜在挑战与风险
- 法律灰色地带
- 不同国家对数据抓取的合法性界定不一(如美国“HiQ v. LinkedIn”案允许抓取公开数据,但欧盟更严格)。
- 技术成本增加
- 反爬措施(如Cloudflare的5秒盾)可能迫使企业投入更多资源破解。
- 数据质量焦虑
- 虚假信息泛滥(如AI生成内容)可能导致爬取数据可信度下降。
四、总结
网络爬虫的未来将呈现“技术深度化、场景多元化、合规严格化”三大特征。其核心价值在于将无序的网络信息转化为结构化知识,而随着AI、物联网、Web3.0的发展,爬虫可能成为连接物理世界与数字世界的“神经末梢”。但能否持续发展,取决于如何在技术创新、商业需求与伦理法规之间找到平衡点。