Redis命令使用
Redis是以键值对进行数据存储的,添加数据和查找数据最常用的2个指令就是set和get。
- set:set指令用来添加数据。把key和value存储进去。
- get:get指令用来查找相应的键所对应的值。根据key来取value。
首先,我们先进入到redis客户端。然后使用set和get。
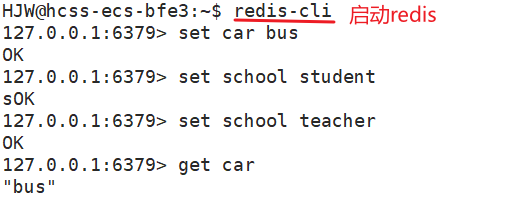
对于这里的key和value,不需要加上引号,就可以表示字符串的类型。如果要是给key和value加上引号也是可以的(单引号或双引号都可以)。redis中的命令不区分大小写。
如果get到一个不存在的key,那么就会显示(nil),这个意思与NULL一样,表示找不到,为空。
Redis全局命令
Redis支持很多种数据结构,整体来说,Redis是键值对结构,key只能是字符串,value实际上有很多种类型,比如说,字符串、哈希表、列表、集合、有序集合等等,操作不同的数据结构就会有不同的命令。
所以,全局命令,就是能够搭配任意一个数据结构来使用的命令。
keys
- keys:返回所有满足样式(pattern)的 key。⽀持如下统配样式。
语法:KEYS pattern
h?llo匹配hello,hallo和hxllo。匹配任意一个字符h*llo匹配 hllo 和 heeeello。匹配0个或多个任意字符h[ae]llo匹配 hello 和 hallo 但不匹配 hillo。即匹配包含a或e的键h[^e]llo匹配 hallo , hbllo , … 但不匹配 hello。即除了包含e的不符合,其它都符合。h[a-b]llo匹配 hallo 和 hbllo。匹配a到b这个范围内的字符,包含两侧边界。
命令有效版本:1.0.0 之后
时间复杂度: O ( N ) O(N) O(N)
返回值:匹配 pattern 的所有 key。
示例:
// 创建key
redis 127.0.0.1:6379> SET runoob1 redis
OK
redis 127.0.0.1:6379> SET runoob2 mysql
OK
redis 127.0.0.1:6379> SET runoob3 mongodb
OK// 查找以 runoob 为开头的 key:
redis 127.0.0.1:6379> KEYS runoob*
6) "runoob3"
7) "runoob1"
8) "runoob2"//获取 redis 中所有的 key 可用使用 *。
redis 127.0.0.1:6379> KEYS *
9) "runoob3"
10) "runoob1"
11) "runoob2"
在生产环境中,一般都会禁止使用keys命令,尤其是keys *:查询redis中所有的key。
EXISTS
这个命令是判断某个值是否存在。
语法:EXISTS key [key ...]
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:key 存在的个数。
示例:
127.0.0.1:6379> set hello 111
OK
127.0.0.1:6379> set hallo 222
OK
127.0.0.1:6379> set haxxllo 333
OK
127.0.0.1:6379> keys *
1) "hello"
2) "hallo"
3) "school"
4) "car"
5) "haxxllo"
6) "test"
127.0.0.1:6379> exists hello car
(integer) 2
127.0.0.1:6379> exists hello
(integer) 1
127.0.0.1:6379> exists car
(integer) 1
用exists判断的时候,一次判断和分开判断时是有区别的。因为redis是一个客户端、服务器结构的程序。客户端和服务器之间通过网络来进行通信。一次判断完的话,只会产生一次请求和响应。而用两次判断的话,会多增加一次请求和响应。分开的写法,会产生更多轮次的网络通信。所以能一次查找最好。
DEL
删除指定的 key。
语法:DEL key [key ...]
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:删除掉的 key 的个数。
示例:
127.0.0.1:6379> keys *
1) "hello"
2) "hallo"
3) "school"
4) "car"
5) "haxxllo"
6) "test"
127.0.0.1:6379> del car
(integer) 1
127.0.0.1:6379> del hallo
(integer) 1
127.0.0.1:6379> keys *
1) "hello"
2) "school"
3) "haxxllo"
4) "test"
EXPIRE
为指定的 key 添加秒级的过期时间(Time To Live TTL)
语法:EXPIRE key seconds
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:1 表示设置成功。0 表示设置失败。
这个的场景会用在验证码或者优惠券在指定时间之前有效等等。
示例:
127.0.0.1:6379> keys *
1) "hello"
2) "school"
3) "haxxllo"
4) "test"
127.0.0.1:6379> expire hello 10
(integer) 1
127.0.0.1:6379> get hello
"111"
127.0.0.1:6379> get hello
"111"
127.0.0.1:6379> get hello
"111"
127.0.0.1:6379> get hello
(nil)
TTL
获取指定 key 的过期时间,秒级。
语法:TTL key
命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:剩余过期时间。-1 表示没有关联过期时间,-2 表示 key 不存在。
示例:
127.0.0.1:6379> keys *
1) "school"
2) "haxxllo"
3) "test"
127.0.0.1:6379> expire school 10
(integer) 1
127.0.0.1:6379> ttl school
(integer) 6
127.0.0.1:6379> ttl school
(integer) 3
127.0.0.1:6379> ttl school
(integer) -2
[!note] 注意
EXPIRE 和 TTL 命令都有对应的支持毫秒为单位的版本:PEXPIRE 和 PTTL,详细⽤法就不再介绍了。
TYPE
返回 key 对应的值的数据类型。
语法:TYPE key
命令有效版本:1.0.0 之后
比特就业课时间复杂度:O(1)
返回值: none , string , list , set , zset , hash 和stream(用于消息队列和日志存储,支持消息的持久化和时间排序) 。
示例:
redis> SET key1 "value"
"OK"
redis> LPUSH key2 "value"
(integer) 1
redis> SADD key3 "value"
(integer) 1
redis> TYPE key1
"string"
redis> TYPE key2
"list"
redis> TYPE key3
"set
FLUSHALL
这个命令用于清除所有的键,相当于MySQL中的drop dataname,这个命令不能随便使用。开玩笑来说这个命令是“删库跑路”。
语法:flushall
127.0.0.1:6379> keys *
1) "key1"
2) "key2"
3) "key3"
127.0.0.1:6379> flushall
OK
127.0.0.1:6379> keys *
(empty array)
数据类型与内部编码
Redis 针对每种数据结构都有⾃⼰的底层内部编码实现,而且是多种实现,这样 Redis 会在合适的场景选择合适的内部编码。
| 数据类型 | 说明 |
|---|---|
| string(字符串) | 基本的数据存储单元,可以存储字符串、整数或者浮点数 |
| hash(哈希) | 一个键值对的集合,可以存储多个字段 |
| list(列表) | 一个简单的列表,可以存储一系列的字符串元素 |
| set(集合) | 一个无序集合,可以存储不重复的字符串元素 |
| zset(有序集合) | 类似于集合,但是每个元素都有一个分数(权重)与之关联 |
| Bitmaps(位图) | 基于字符串类型,可以对每个位进行操作 |
| Stream(流) | 用于消息队列和日志存储,支持消息的持久化和时间排序 |
还有其它的数据类型,不过最常用的就是前5种。其它的数据类型也某些特定的场景下才会用到。
Redis在底层实现上述数据结构的时候,会在源码层面,针对上述实现进行特定的优化,来节省时间/空间的效果,其中特定的优化就是编码方式。
另外Redis承诺,我这个哈希表,你在进行查询、插入、删除操作的时候,保证时间复杂度为O(1),但是这个背后的实现,不一定就是一个标准的哈希表。可能在特定的场景下,使用别的数据结构实现,但是仍然保证时间复杂度符合承诺。
每种数据类型,都可能会有多种实现方式,Redis称其为编码方式,常见编码方式如下表:
| 数据类型 | 内部编码 |
|---|---|
| string | raw int embstr |
| hash | hashtable ziplist |
| list | linkedlist ziplist |
| set | hashtable intset |
| zset | skiplist ziplist |
- string
- int:存储的字符串是一个可以用64位有符号整数表示的数字时,会用int编码。
- raw:存储的字符串长度超过44字节时,会使用raw编码。raw编码需要两次内存分配,分别用于存储Redis对象头和字符串数据。
- embstr:存储的字符串长度小于等于44字节时,会使用embstr编码。embstr编码将redis对象头和字符串数据连续存储在一块内存中,避免了多次内存分配,提高了内存使用效率和操作性能。
- hash
- hashtable:是一种标准的哈希表数据结构,支持快速的查找。插入和删除操作,适合存储大规模的哈希对象。
- ziplist:同时满足2个条件,才会使用ziplist编码。第一,哈希对象保存到键值对数量小于
hash-max-ziplist-entries(默认值是512);第二,哈希对象保存的所有键值对的键和值的字符串长度都小于hash - max - ziplist - value(默认值为 64)。ziplist是一种紧凑的、连续的内存数据结构,适合存储小的哈希对象,可以节省内存。
- list
- linkedlist:是一种双向链表数据结构,支持在列表的两端快速插入和删除元素,但内存开销较大。
- set
- intset:当集合对象同时满足以下两个条件时,Redis 会使用
intset编码。第一,集合对象保存的所有元素都是整数值。第二,集合对象保存的元素数量小于set - max - intset - entries(默认值为 512)。intset是一种紧凑的整数集合数据结构,适合存储整数集合,可以节省内存。 - hashtable:当集合对象不满足
intset编码的条件时,Redis 会使用hashtable编码。hashtable的键用于存储集合元素,值都为NULL,支持快速的查找、插入和删除操作。
- intset:当集合对象同时满足以下两个条件时,Redis 会使用
- zset
- ziplist:
ziplist编码的有序集合将成员和分数依次存储在ziplist中,并且按照分数从小到大排序,适合存储小的有序集合。 - skiplist:
skiplist是一种跳跃表数据结构,它结合了链表和二分查找的思想,支持快速的插入、删除和查找操作,同时还可以按照分数范围进行快速遍历。在 Redis 中,skiplist还会和hashtable结合使用,hashtable用于快速查找成员的分数,skiplist用于维护元素的有序性。
- ziplist:
示例:
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> lpush mylist a b c
(integer) 3
127.0.0.1:6379> object encoding hello
"embstr"
127.0.0.1:6379> object encoding mylist
"quicklist"
可以通过 object encoding 命令查询内部编码:
为什么可以看到每种数据结构都有至少两种以上的内部编码实现?Redis 这样设计有两个好处:
- 可以改进内部编码,而对外的数据结构和命令没有任何影响,这样⼀旦开发出更优秀的内部编码,⽆需改动外部数据结构和命令,例如 Redis 3.2 提供了 quicklist,结合了 ziplist 和 linkedlist 两者的优势,为列表类型提供了⼀种更为优秀的内部编码实现,而对用户来说基本无感知。
- 多种内部编码实现可以在不同场景下发挥各自的优势,例如 ziplist 比较节省内存,但是在列表元素比较多的情况下,性能会下降,这时候 Redis 会根据配置选项将列表类型的内部实现转换为linkedlist,整个过程⽤户同样无感知。