Python基于PCA、PCA-kernel、LDA的鸢尾花数据降维项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档),如需数据+代码+文档可以直接到文章最后关注获取。


1.项目背景
鸢尾花数据集由150个样本组成,涵盖三种鸢尾花的四个特征(萼片长度、宽度及花瓣长度、宽度),是机器学习的经典数据集。本项目旨在利用Python进行PCA、Kernel PCA和LDA降维处理,以简化数据结构并提高分析效率。PCA通过捕捉最大方差方向来压缩数据;Kernel PCA解决非线性问题;LDA则侧重于最大化类别间的分离度,适用于分类任务前的数据预处理。通过这个项目,我们将探索如何有效降低数据维度,并使用文本标签可视化不同鸢尾花类别,提升对降维技术的理解与应用能力。
本项目通过Python基于PCA、PCA-kernel、LDA的鸢尾花数据降维项目实战。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
| 编号 | 变量名称 | 描述 |
| 1 | sepal length (cm) | 萼片长度(单位:厘米) |
| 2 | sepal width (cm) | 萼片宽度(单位:厘米) |
| 3 | petal length (cm) | 花瓣长度(单位:厘米) |
| 4 | petal width (cm) | 花瓣宽度(单位:厘米) |
| 5 | species | 物种类别 0: 山鸢尾(Iris Setosa) 1: 变色鸢尾(Iris Versicolor) 2: 维吉尼亚鸢尾(Iris Virginica) |
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:

3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
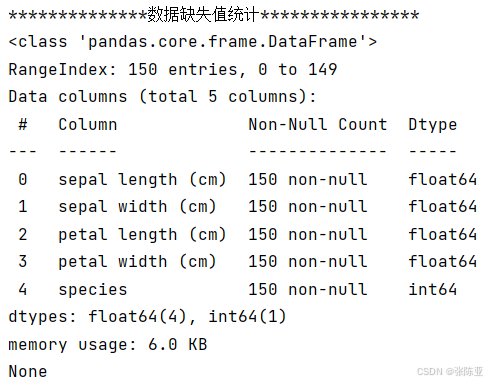
从上图可以看到,总共有5个变量,数据中无缺失值,共150条数据。
关键代码:

3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
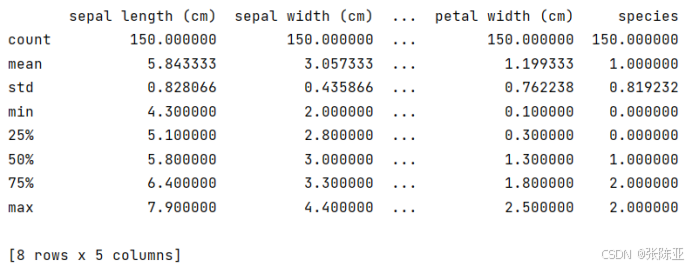
关键代码如下:

4.探索性数据分析
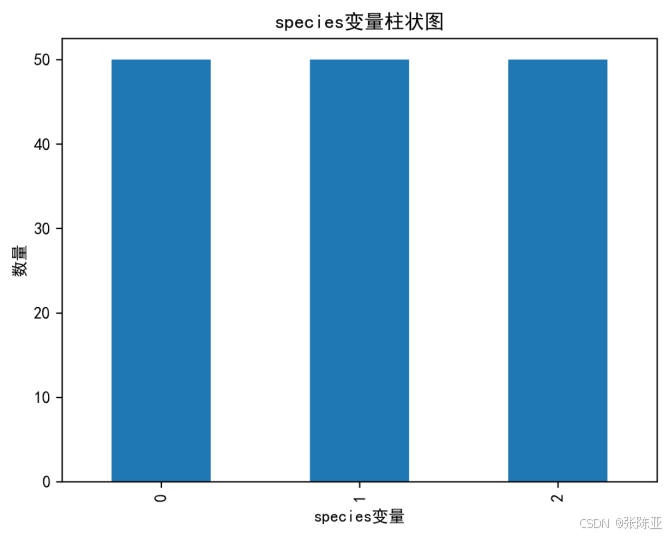
4.1 柱状图
用Matplotlib工具的plot()方法绘制柱状图:
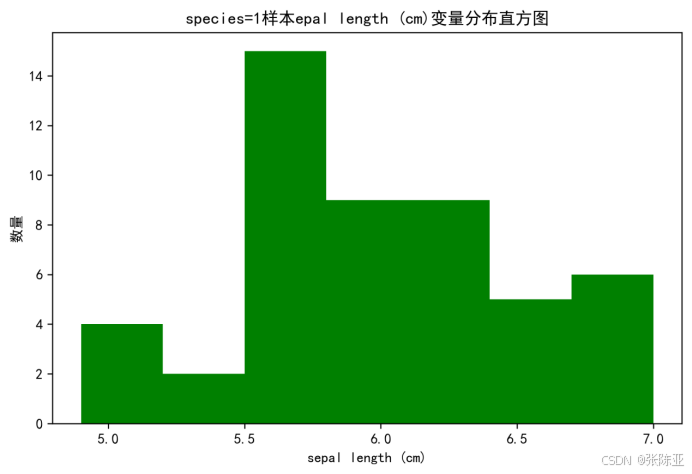
4.2 分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4.3 相关性分析
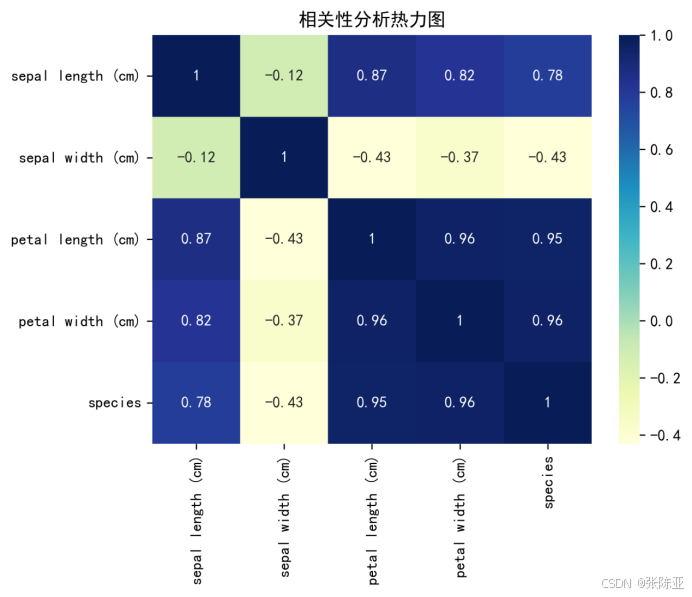
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

6.构建降维模型
主要通过Python基于PCA、PCA-kernel、LDA的鸢尾花数据降维算法,用于目标降维。
6.1 构建模型
| 模型名称 | 模型参数 |
| PCA模型 | n_components=n_components |
| PCA-kernel模型 | n_components=n_components |
| kernel='rbf' | |
| gamma=0.1 | |
| LDA模型 | n_components=n_components |
7.模型评估
7.1降维结果可视化
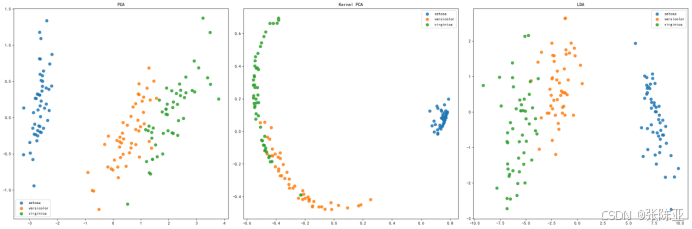
通过对PCA、Kernel PCA和LDA三种降维方法在鸢尾花数据集上的应用与对比,我们观察到不同方法的独特优势。PCA有效地捕捉了数据的最大方差方向,使得山鸢尾明显与其他两类分离,但在处理变色鸢尾和维吉尼亚鸢尾之间的细微差别时表现欠佳。Kernel PCA通过非线性映射提高了类别间的区分度,特别是对于那些线性方法难以分辨的数据点,展示了其处理复杂结构的能力。LDA则专注于最大化类间差异,同时最小化类内差异,实现了三种鸢尾花的最优分类效果。总的来说,LDA在分类任务中表现出色,Kernel PCA适合解决非线性问题,而PCA在保持数据主要信息方面有其独特价值。根据具体应用场景选择合适的降维方法,可以有效提升数据分析和机器学习模型的性能。
8.结论与展望
综上所述,本文采用了通过Python基于PCA、PCA-kernel、LDA的鸢尾花数据降维,最终证明了我们提出的降维模型效果良好。为后续深入分析和实际应用提供了重要参考。