Attention Is All You Need (Transformer) 以及Transformer pytorch实现
参考https://zhuanlan.zhihu.com/p/569527564
Attention Is All You Need (Transformer) 是当今深度学习初学者必读的一篇论文。
一. Attention Is All You Need (Transformer) 论文精读
1. 知识准备
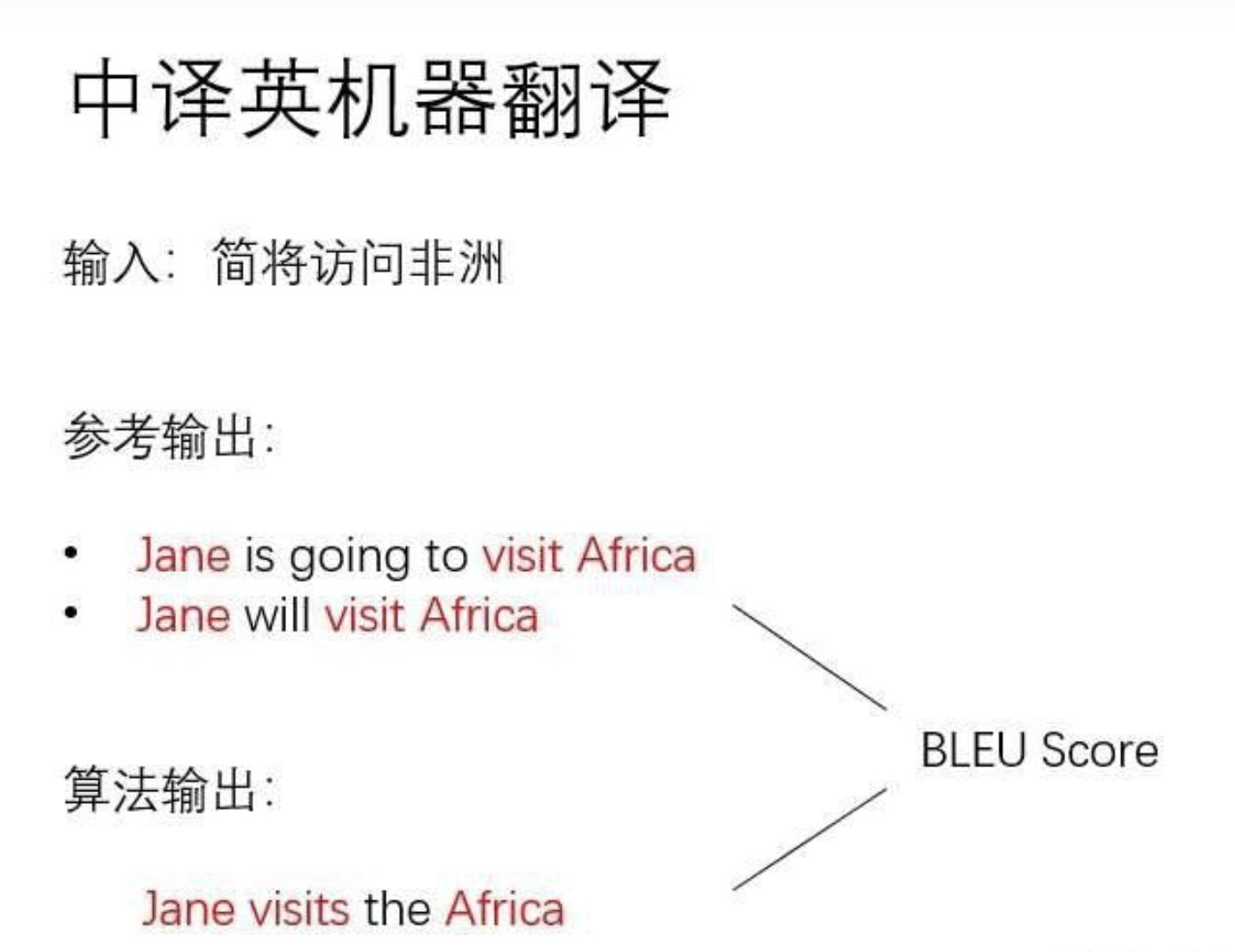
机器翻译,就是将某种语言的一段文字翻译成另一段文字。
由于翻译没有唯一的正确答案,用准确率来衡量一个机器翻译算法并不合适,因此,机器翻译的数据集通常会为每一条输入准备若干个参考输出。统计算法输出和参考输出之间的重复程度,就能评价算法输出的好坏了。这种评价指标叫做BLEU Score。这一指标越高越好。
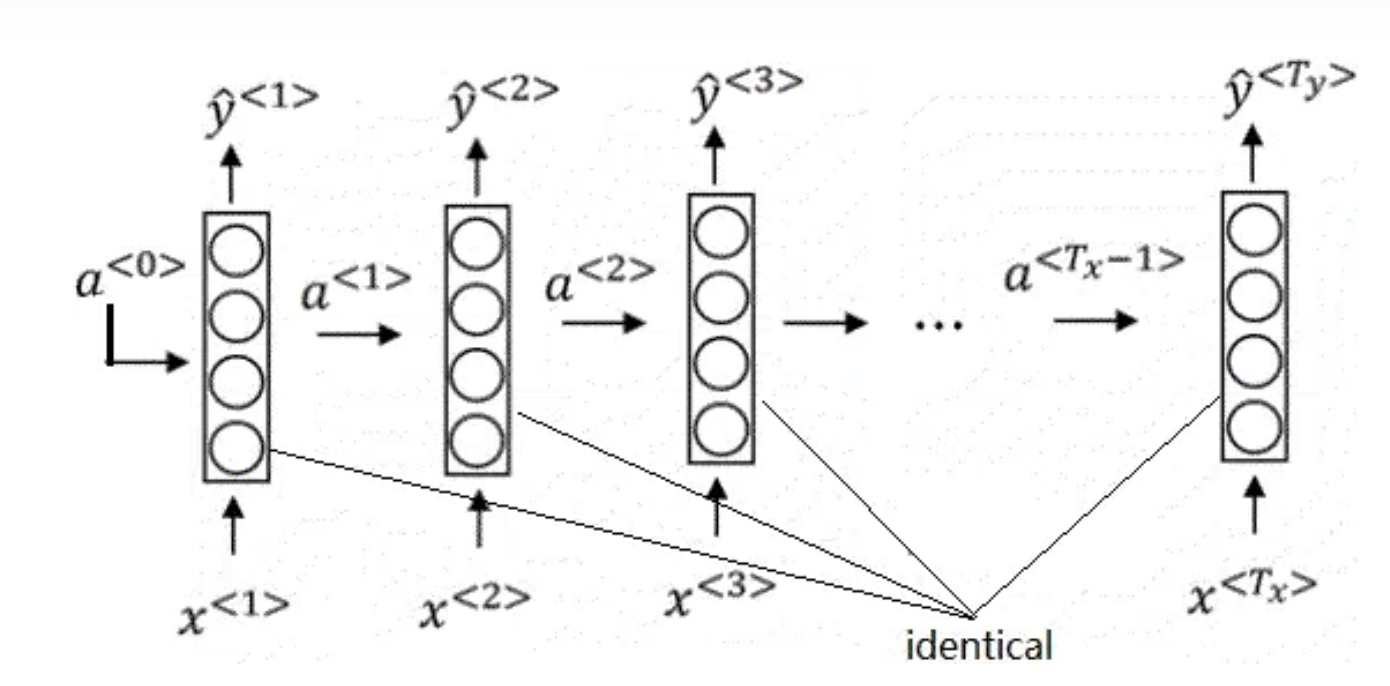
在深度学习时代早期,人们使用RNN(循环神经网络) 来处理机器翻译任务。一段输入先是会被预处理成一个token序列。RNN会对每个token逐一做计算,并维护一个表示整段文字整体信息的状态。根据当前时刻的状态,RNN可以输出当前时刻的一个token。
所谓token,既可以是一个单词、一个汉字,也可能是一个表示空白字符、未知字符、句首字符的特殊字符。
具体来说,在第t轮计算中,输入时上一轮的状态 以及这一轮的输入token
,输出这一轮的状态
以及这一轮的输出token
。
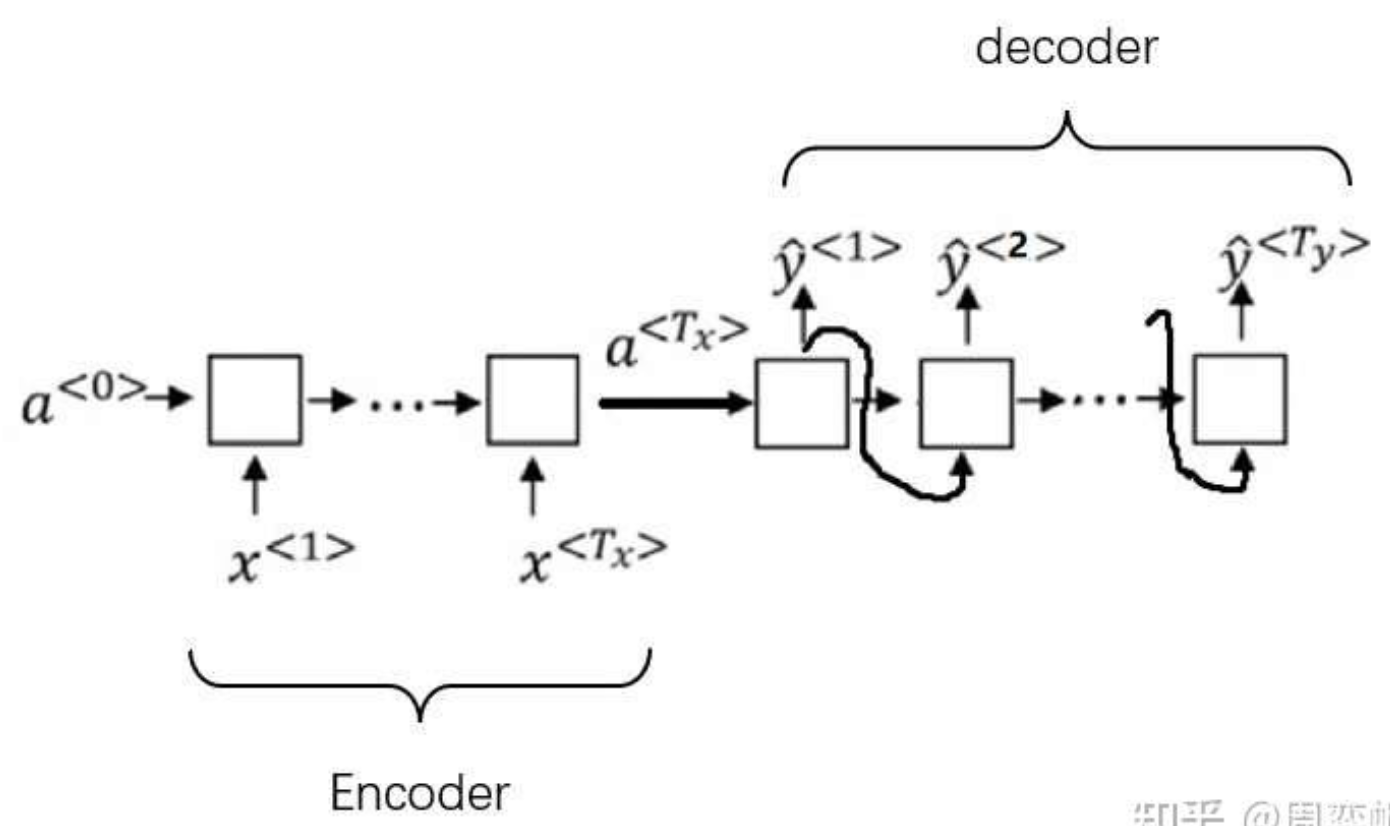
这种简单的RNN架构仅适用于输入和输出等长的任务。然而,大多数情况下,机器翻译的输出和输入都不是等长的。因此,人们使用了一种新的架构。前半部分的RNN只有输入,后半部分的RNN只有输出(上一轮的输出会当作下一轮输入以补充信息)。两个部分通过一个状态 来传递信息。把该状态看成输入信息的一种编码的话,前半部分可以叫做“编码器”,后半部分可以叫做“解码器”。这种架构因而被称为“编码器-解码器”架构。
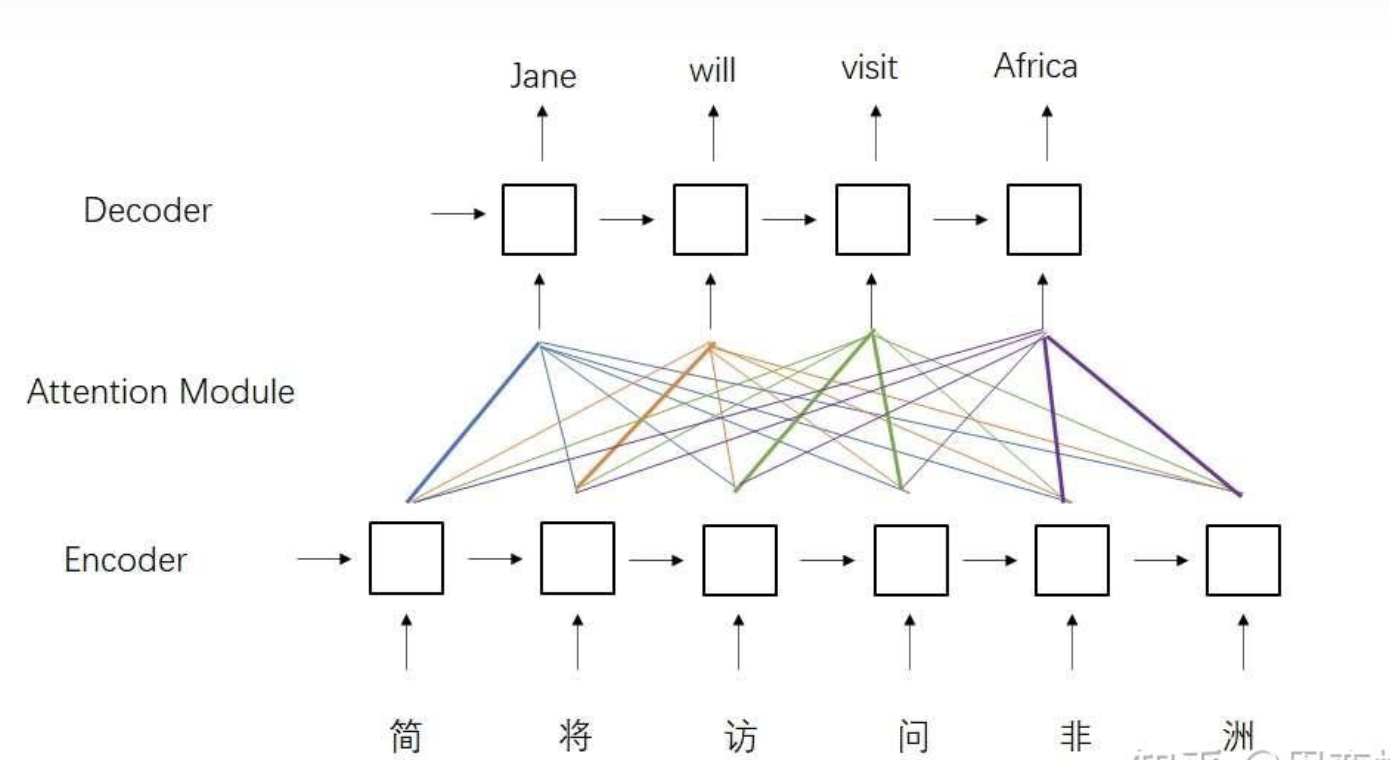
这种架构存在着不足:编码器和解码器之间只通过一个隐状态来传递信息。在处理较长文章时,这种架构的表现不够理想。为此,有人提出了基于注意力的架构。这种架构依然使用了编码器和解码器,只不过解码器的输入时编码器的状态的加权和,而不再是一个简单的中间状态。每一个输出对每一个输入的权重叫做注意力,注意力的大小取决于输出和输入的相关关系。这种架构优化了编码器和解码器之间的信息交流方式,在处理长文章更加有效。
尽管注意力模型的表现已经足够优秀,但所有基于RNN的模型都面临同样的问题:RNN本轮的状态的输入状态取决于上一轮的输出状态,这使RNN的计算必须串行执行。因此,RNN的训练通常比较缓慢。
在这背景下,抛弃RNN, 只使用注意力机制的Transformer横空出世了。
2.摘要与引言
摘要传递的信息非常简练:
- 当前最好的架构师基于注意力的“encoder- decoder”架构。这些架构都使用了CNN和RNN。这篇文章提出的transformer架构仅使用了注意力机制,而无需使用CNN和RNN
- 两项机器翻译的实验表明,这种架构不仅精度高,而且训练时间大幅度缩短。
引言读一段回顾了RNN架构。以LSTM和GRU为代表的RNN在多项序列任务中取得顶尖的成果。许多研究仍在拓宽循环语言模型和“encoder- decoder”架构的能力边界。
第二段就开始讲RNN的不足了。RNN要维护一个隐状态,该隐状态取决于上一时刻的隐状态。这中内在串行计算特质阻碍了训练时的并行计算(特别是训练序列较长时,每一个句子占用的存储更多,batch size变小,并行度降低)。有许多研究都在尝试解决这一问题。但是串行计算的本质是无法改变的。
上一段暗示了Transformer 的第一个设计动机:提升训练的并行度。第三段讲了“Transformer”的另一个设计动机:注意力机制。注意力机制是当时最顶尖的模型中不可或缺的组件。这一机制可以让每对输入输出关联起来,而不用像那么早使用一个隐状态传递信息的“encoder- decoder”模型一样,收到序列距离的限制。然而,几乎所有的注意力机制都用在RNN上的。
既然注意力机制能够无视序列的先后顺序,捕捉序列间的关系,为什么不只用这种机制来构造一个适用一个适用于并行计算的模型呢?因此,在这篇文章中作者提出了Transformer架构。这一架构规避了RNN的使用,完全使用注意力机制来捕捉输入输出序列之间的依赖关系。这种架构不仅训练得更快了,表现还更强了。
通过摘要和引言,我们基本理解了Transformer架构的设计动机。作者想克服RNN不能并行的缺点,又想充分利用没有串行限制的注意力机制,于是就提出了一个只有注意力机制的模型。模型训练出来了,结果出乎预料地好,不仅训练速度大幅加快,模型的表现也吵够了当时所有的其他模型。
3.注意力机制
文章在介绍Transformer的架构时,时自顶向下介绍的。但是,一开始我们并不了解Transformer的各个模块,理解整体框架时会有不少的阻碍。因此,我们可以自底向上地来学习Transformer架构。
4.注意力计算的一个例子
其实,“注意力”这个名字取的非常不易于理解。这个机制应该叫做“全局信息查询”。这一次“注意力”计算,其实就跟去数据库做了一次查询一样。假设,我们现在有这样一个以人名为Key(键),以年龄为Value(值)的数据库:
{张三: 18,张三: 20,李四: 22,张伟: 19 }
现在有一个query(查询),问所有叫张三的人的年龄平均值是多少。让我们写程序的话,我们会把字符串“张三”和所有Key做比较,找出所有张三的value,把这些年龄值相加,取一个平均数。这个平均数是(18+20)/2 =19。
但是,很多时候,我们的查询并不是那么明确。比如,我们可能想查询一下所有姓张的人的年龄平均值。这次,我们不是去比较key=张三,而是比较key[0] ==张。这个平均数应该是(18+20+19)/3=19。
或许,我们查询会更模糊一点,模糊到无法用简单的判断语句来完成,因此,最通用的方法是,把query和key各建模成一个向量。之后,对query和key之间算一个相似度(比如向量内积),以这个相似度为权重,算value的加权和。这样,不管多么抽象的查询,我们都可以把query和key建模成向量,用向量相似度代替查询的判断语句,用加权和代替直接取值再求平均值。“注意力”,其实指的就是这里的权重。
把这种新方法套入刚才那个例子里,我们先把所有key建模成向量,可能可以得到这样的一个新数据库:
{[1, 2, 0]: 18, # 张三[1, 2, 0]: 20, # 张三 [0, 0, 2]: 22, # 李四[1, 4, 0]: 19 # 张伟 }
假设key[0]==1表示姓张。我们的查询“所有姓张的人的年龄平均值”就可以表示成向量【1,0,0】。用这个query和所有key算出的权重是:
dot([1, 0, 0], [1, 2, 0]) = 1
dot([1, 0, 0], [1, 2, 0]) = 1
dot([1, 0, 0], [0, 0, 2]) = 0
dot([1, 0, 0], [1, 4, 0]) = 1之后,我们该用这些权重算平均值了。注意,算平均值时,权重的和应该是1,因此,我们可以用soft Max把这些权重归一化一下,再算value的加权和。
softmax([1, 1, 0, 1]) = [1/3, 1/3, 0, 1/3]
dot([1/3, 1/3, 0, 1/3], [18, 20, 22, 19]) = 19这样,我们就用向量运算代替了判断语句,完成了数据库的全局信息查询。那三个1/3就是query对每个key的注意力。
5. Scaled Dot-Product Attention
我们刚刚完成的计算差不多就是Transformer里的注意力,这种计算在论文里叫放缩点乘注意力(Scaled Dot-Product Attention)。它的公式是:
我们先来看看Q,K,V在刚刚那个例子里究竟是什么,K比较好理解,K就是key向量的数组,也就是
K = [[1, 2, 0], [1, 2, 0], [0, 0, 2], [1, 4, 0]]同样,V就是value向量的数组。而在我们刚刚那个例子里,value都是实数。实数其实也就是可以看成长度为1的向量。因此,那个例子的V应该是:
V = [[18], [20], [22], [19]]
在我们刚刚的例子里,我们只多了一次查询。因此,准确来说,我们的操作应该写成:
其中,query q就是【1,0,0】
实际上,我们可以一次做多组query。把所有q打包成矩阵Q,就得到了公式:
就是query和key向量的长度。由于query和key要做点乘,这两种向量的长度必须一致。value向量的长度倒是可以不一致,论文里把value向量的长度叫做
。在我们这个例子里,
=1,
=3
为什么要用一个和成比例的项来缩放
呢?softmax 在绝对值较大的区域梯度较小,梯度下降的速度比较慢,因此,我们要让softmax的点乘数值尽可能小。而一般在
较大时,也就是向量较长时,点乘数值会比较大。除以一个和
相关的量能够防止点乘的值过大。
刚才也提到,其实是在算query和key相似度,而算相似度并不只有求点乘这一种方式。另一种常用的注意力函数叫做加性注意力,它用一个单层神经网络来计算两个向量的相似度。相比之下,点乘注意力算起来快一些。出于性能上的考量,论文使用了点乘注意力。
6.自注意力
自注意力是3.2.3节里提及的内容。我认为,学完注意力的原理后,立刻去学自注意力能够更快地理解注意力机制。当然,论文里并没有对自注意力进行过多的引入,初学者学起来会非常困难。因此,这里我参考《深度学习专项》里的介绍方式,用一个更具体的例子介绍了自注意力。
大致明白了注意力机制其实就是“全局信息查询”,并掌握了注意力的公式后,我们来以Transformer的自注意力为例,进一步理解注意力的意义。
自注意力模块目的是为了每一个输入token生成一个向量表示,该表示不仅能反应token本身的性质,还能反应token在局子里特有的性质。比如翻译“简访问非洲”这句话时,第三个字“问”在中文里很多个意思,比如询问、慰问等。我们想为它生成一个表示,知道它在句子中的具体意思。而在例句中,“问”字组词组成了“访问”,所以它应该取“询问”这个意思,而不是“慰问”。“询问”就是“问”字在这句话里的表示。
让我们看看自注意力模块具体时怎么生成这种表示的。自注意力的输入是3个矩阵Q,K,V。准确来说,这些矩阵是向量的数组,也就是每一个token的query,key, value向量构成的数组。自注意力模块会为每一个token输出一个向量表示A。是第t个token在这句话里向量表示。
让我们还是以刚刚那个句子“简访问非洲”为例,看一下自注意力怎么计算的。现在,我们想计算。
表示的是“问”字在句子里的确切含义。为了获取
,我们可以问这样一个可以用数学表达的问题:“和‘问’字组词的字的词嵌入式什么?”。这个问题就是第三个token的query向量
。
和“问”字组词的字,很肯能是一个动词。恰好,每一个token的key 就表示这个token的词性;每一个token的value
,就是这个token的嵌入。

这样,我们就可以根据每个字的词性(key),尽量去找动词(和query比较相似的key),求出权重(query和key做点乘再做softmax),对所有value求一个加权平均,就差不多能回答问题了。
经计算,,
可能会比较相关,即这两个向量的内积比较大。因此,最终算出来的
约等于
,即问题“哪个字和‘问‘ 字组词了?的答案是第二个访字。
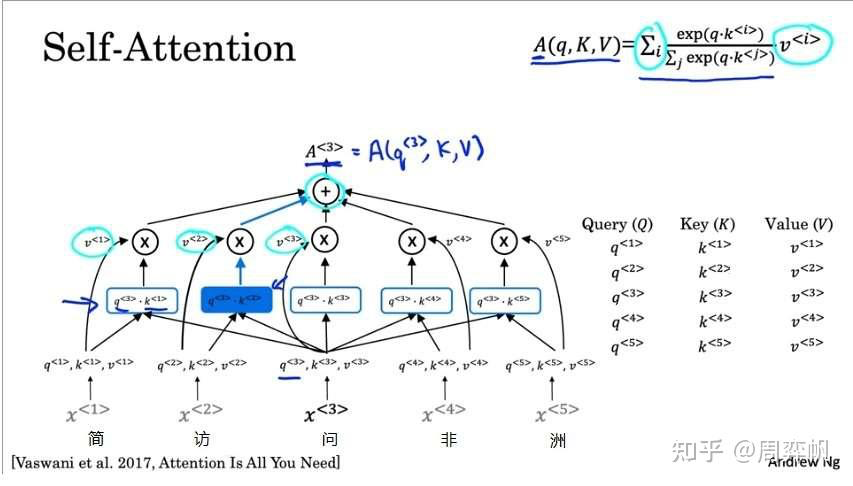
这是 的计算过程。准确来说,
.类似地,
到
都是用这个公式来计算。把所有A的计算合起来,把q合起来,得到的公式就是注意力的公式。
从上一节中,我们知道了注意力其实就是全局信息查询,而在这一节,我们知道了注意力的一种应用:通过让一句话中每个单词去向其他单词查询信息,我们能为每一个单词生成一个更有意义的向量表示。
可是,我们还留了一个问题没解决:每个单词的query,key, value 是怎么得来的?这就要看transformer里的另一种机制---多头注意力。
7. 多头注意力
在自注意力中,每一个单词的query,key, value应该只和该单词本身有关。因此,这三个向量都应该由单词的词嵌入得到。另外,每个单词的query,key, value不应该是人工指定的,而应该是可学习的。因此,我们可以用可学习的参数来描述从词嵌入到 query,key, value的变换过程。综上,自注意力的输入Q,K,V因该用下面的公式计算:
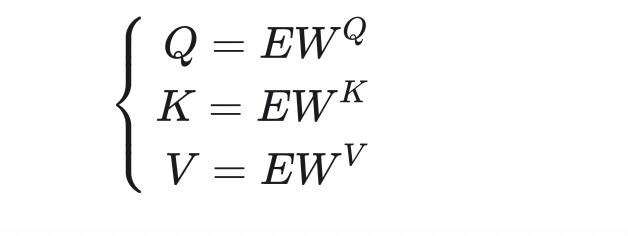
其中,E是词嵌入矩阵,也就是每个单词的词嵌入的数组;是可学习的参数矩阵。在Transformer中,大部分中间向量的长度都用
表示,词嵌入的长度也是
。因此,设输入的句子长度为n, 则E的形状是
,
的形状是
,
的形状是
。
就像卷积层能够用多个卷积核生成多个通道的特征一样,我们也用多组生成多组自注意力结果。这样,每个单词的自注意力表示会更丰富一点,这种机制就叫做多头注意力。把多头注意力用在自注意力上的公式为:
Transformer似乎默认所有向量都是行向量,参数矩阵都写成了右乘而不是常见的左乘。
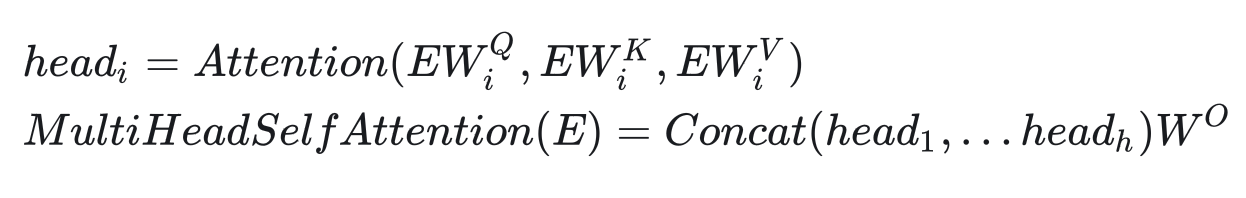
其中,h是多头自注意力的“头”数, 是另一个参数矩阵。多头注意力模块的输入输出向量的长度都是
。因此,
的形状是
(自注意力的输出长度是
,有h个输出)。在论文中,Transformer的默认参数配置如下:

实际上,多头注意力机制不仅仅可以用在计算自注意力上。推广一下,如果把多头自注意力的输入E 拆成三个矩阵Q,K,V,则多头注意力的公式为:
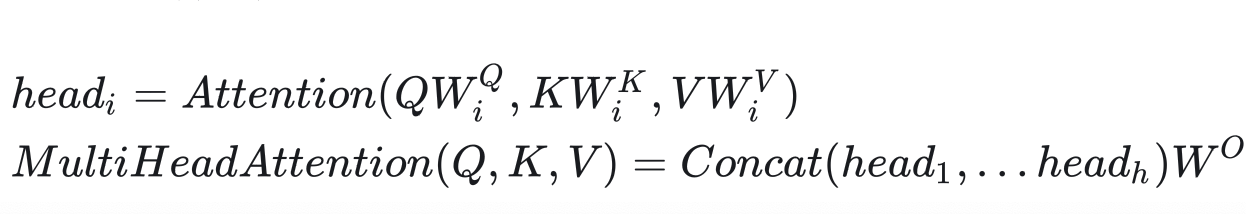
8. Transformer模型架构
看懂了注意力机制,可以回过头阅读3.1节学习Transformer的整体架构了。
论文里的图1是transformer 的架构图:
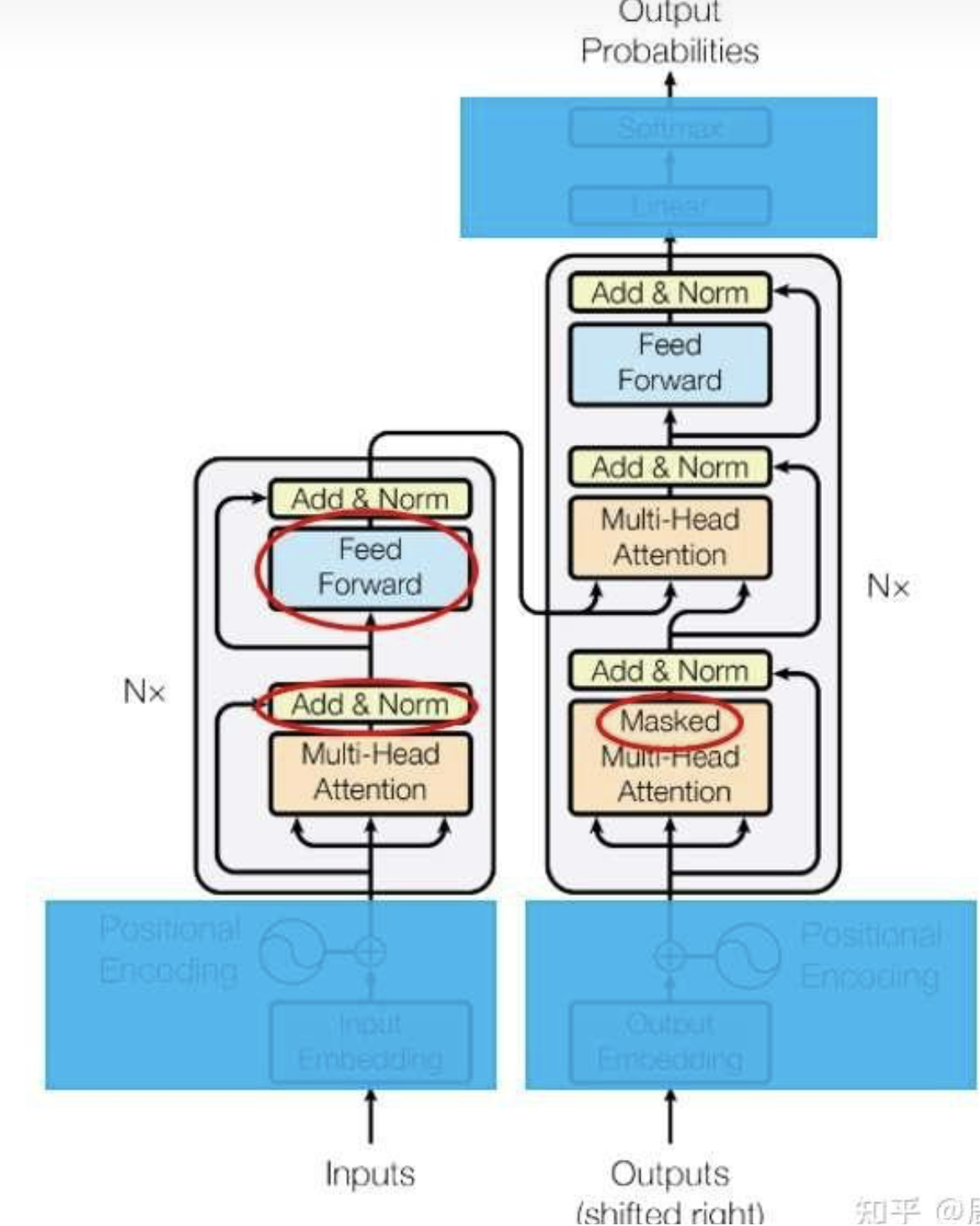
三个疑问:
1. Add & Norm
2. Feed Forward
3. 为什么一个多头注意力前面加了Masked
我们来一次看懂这三个模块。
9. 残差连接
Transformer使用了和ResNet 类似的残差连接,即设模块本身的映射F(x),则模块输出为Normalization(F(x)+x)。和ResNet不同,Transformer使用的归一化方法是LayerNorm。
另外要注意的是,残差连接有一个要求:输入x和输出F(x)+x的维度必须等长,在Transformer中,包含所有词嵌入在内的向量长度都是
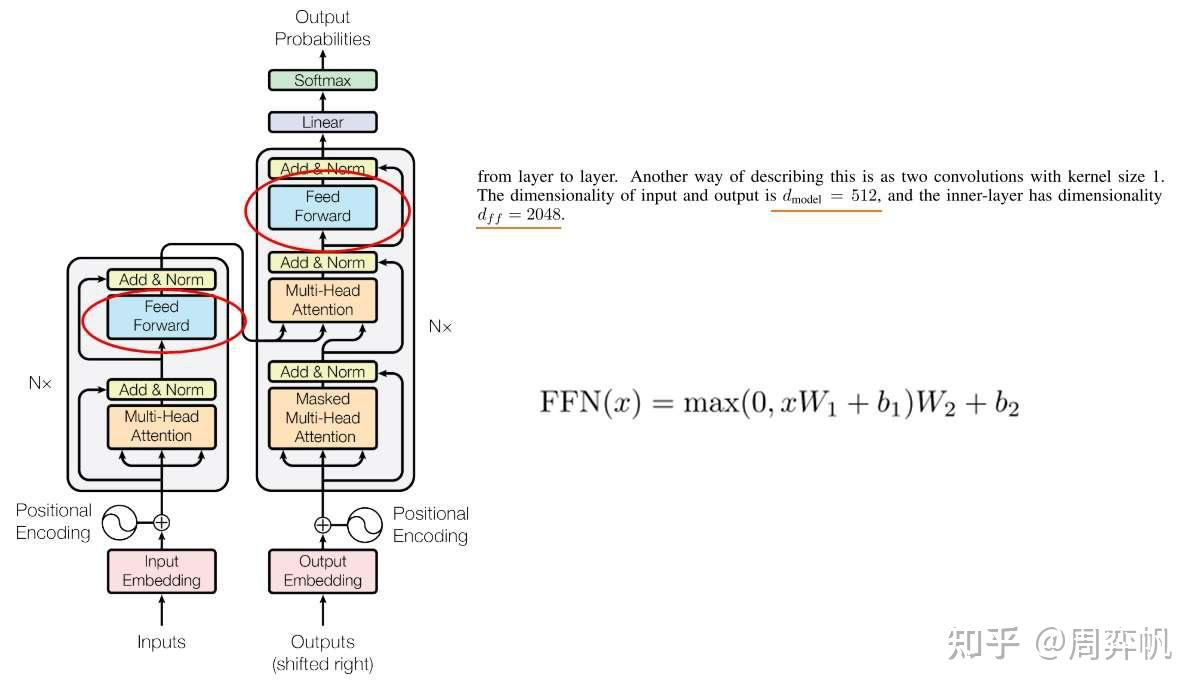
10.前馈网络
架构图中的前馈网络(Feed Forward)其实就是一个全连接网络。具体来说,这个子网络由两个线性层组成,中间用ReLU作为激活函数。
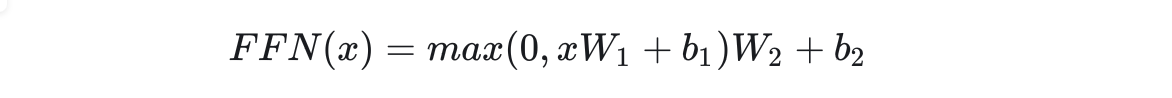
中间的隐藏层维度数记做 。
=2048
11. 整体架构与掩码多头注意力
现在,我们基本能看懂模型的整体架构了。只有读懂了整个模型的运行原理,我们才能搞懂多头注意力前面的masked哪来的。
论文第3章开头介绍了模型的运行原理。和多数强力的序列转换模型一样,Transformer使用了encoder-decoder的架构。早期基于RNN的序列转换模型在生成序列时一般会输入前i个单词,输出 i+1个单词。

而Transformer 不同。对于输入序列,它会被编码器编码成中间表示
.给定z的前提下,解码器输入
,输出
预测。
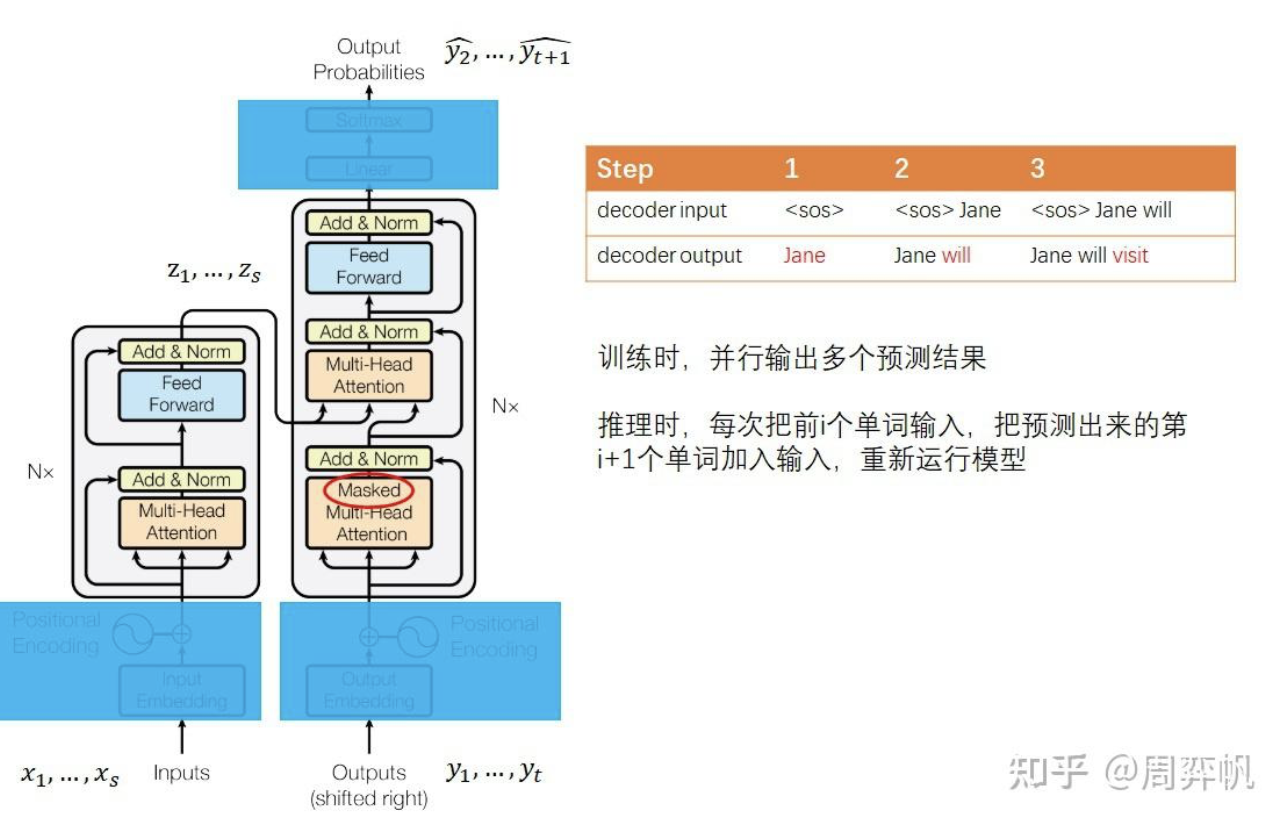
Transformer 默认会并行地输出结果。而在推理时,序列必须得串行生成。直接调用Transformer的并行输出逻辑会产生非常多的冗余运算量。推理的代码实现可以进行优化。
具体来说,输入序列x会经过N=6个结构相同的层。每层有多个子层组成。第一个子层是多头注意力层,准确来说,是多头自注意力。这一层可以为每一个输入单词体恤更有意义的表示。之后数据会经过前馈网络子层。最终,输出编码结果z。
得到z后,要用解码器输出结果了。解码器的输入时当前已经生成的序列,该序列会经过掩码(masked)多头自注意力子层。我们先不管这个掩码是什么意思,暂且把它当成普通的多头自注意力层。它的作用和编码器中的一样,用于提取出更有意义的表示。
接下来,数据还会经过一个多头注意力层。这个层比较特别,它的K,V来自z,Q来自上一层的输出。为什么会有这样的设计呢?这种设计来自于早期的注意力模型。如下图所示,在早期的注意力模型中,每一个输出单词都会与每一个输入单词求一个注意力,以找到每一个输出单词最相关的某几个输入单词。用注意力公式来表达的话,Q就是输出单词,K, V就是输入单词。
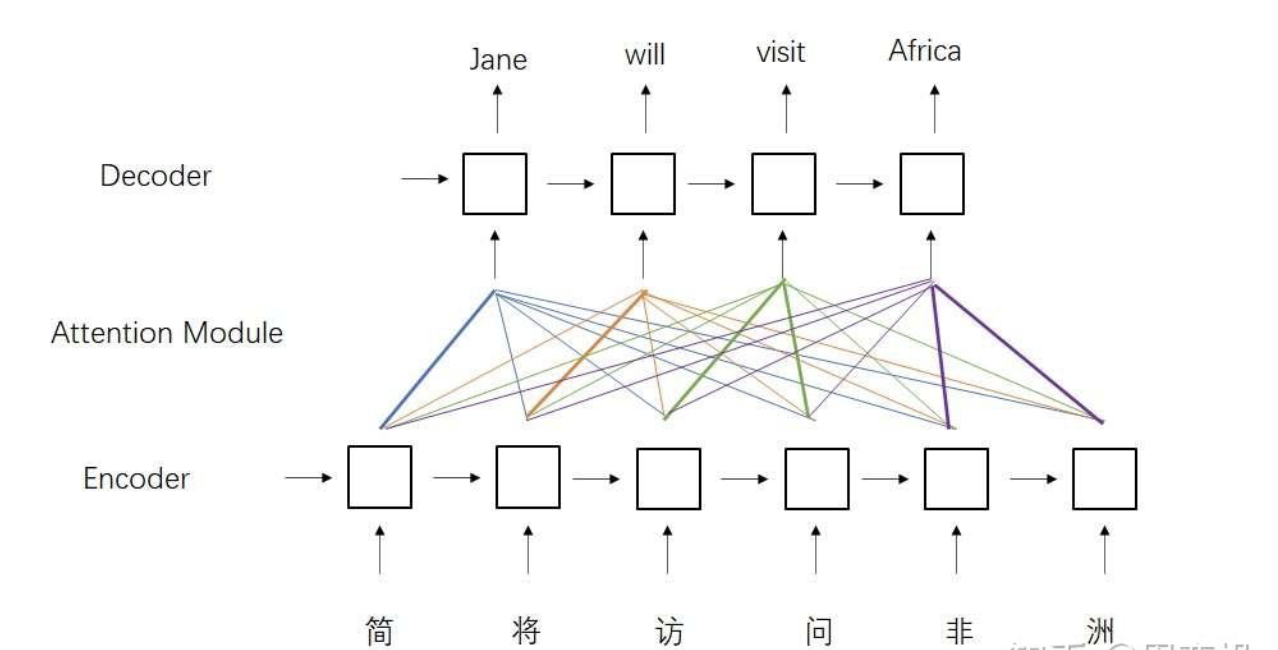
经过第二个多头注意力层后,和编码器一样,数据会经过一个前馈网络。最终,网络并行输出各个时刻的下一个单词。
这种并行计算有一个要注意的地方。在输出第t+1个单词时,模型不应该提前知道t+1时刻之后的信息。因此,应该只保留t时刻之前的信息,遮住后面的输入。这可以通过添加掩码实现。添加掩码一个不严谨示例如下表:

这就是为什么编码器的多头自注意力层前面有一个masked。在论文中,mask是通过令注意力公式 的softmax的输入为实现的(softmax的输入为
,注意力权重就几乎为0,被遮住的输出也几乎全部为0)。每个mask都是一个上三角矩阵。
12. 嵌入层
看完了Transformer主干结构,再来看看输入输出做了哪些前后处理。
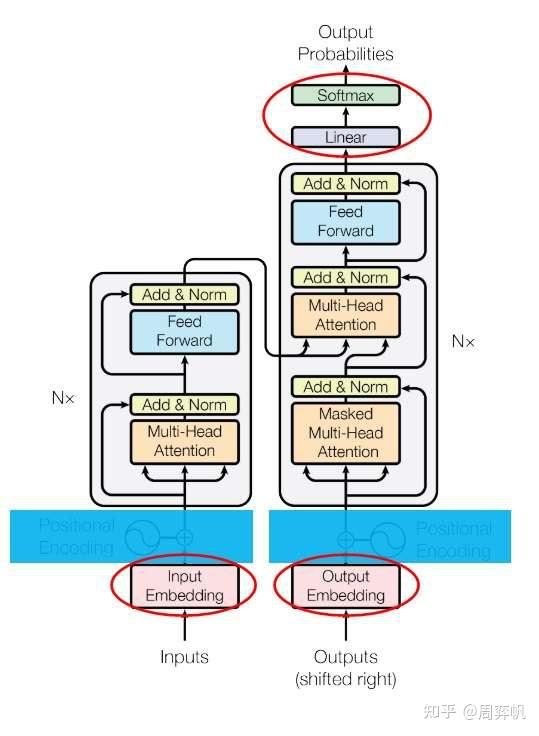
和其他大多数序列转换任务一样,Transformer主干结构的输入输出都是词嵌入序列。词嵌入,其实就是一个把one-hot向量转换成有意义的向量的转换矩阵。在transformer中,解码器的嵌入层和输出层是共享权重的---输出线性层表示的线性变换是嵌入层的逆变换,其目的是把网络输出的嵌入再转换回one-hot向量。如果某任务的输入和输出是同一种语言,那么编码器的嵌入层和编码层的嵌入层也可以共享权重。
论文中写道:“输入输出的嵌入层和softmax前的线性层共享权重”。这个描述不够清楚。如果输入和输出的不是同一种语言,比如输入中文输出英文,那么共享一个词嵌入是没有意义的。
嵌入矩阵的权重乘了。
由于模型要预测一个单词,输出的线性层后面还有一个常规的softmax操作。
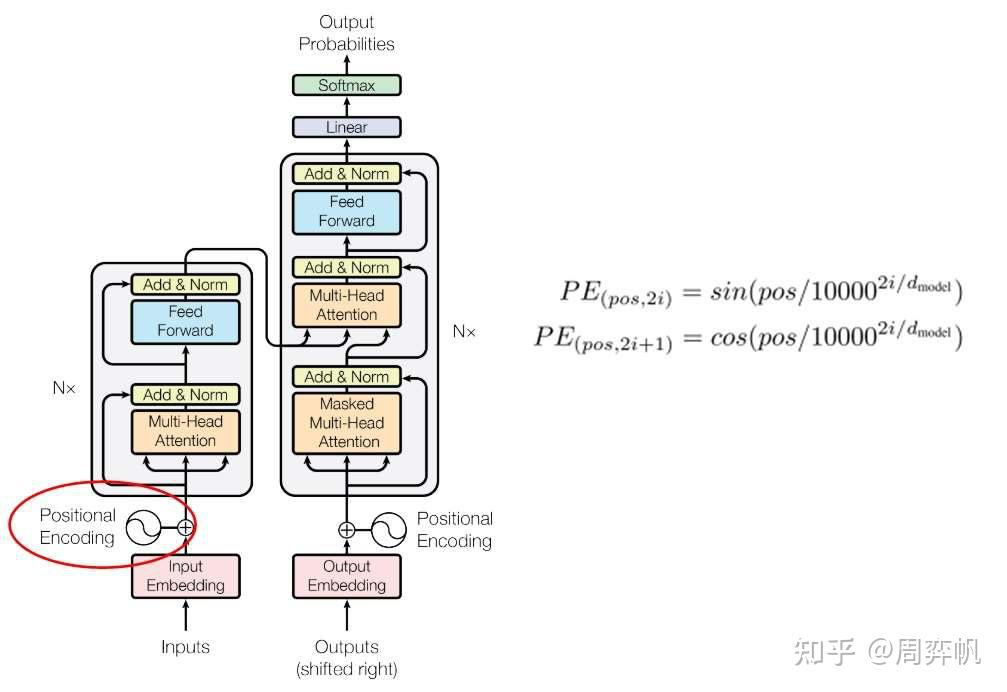
13. 位置编码
现在,Transformer的结构图还剩一个模块没有读---位置编码。无论是RNN还是CNN,都能自然地利用到序列的先后顺序这一信息。然而,Transformer的主干网络并不能利用到序列顺序信息。因此,Transformer使用了一种叫做位置编码的机制,对编码器和解码器的嵌入输入做了一些修改,以向模型提供序列顺序信息。
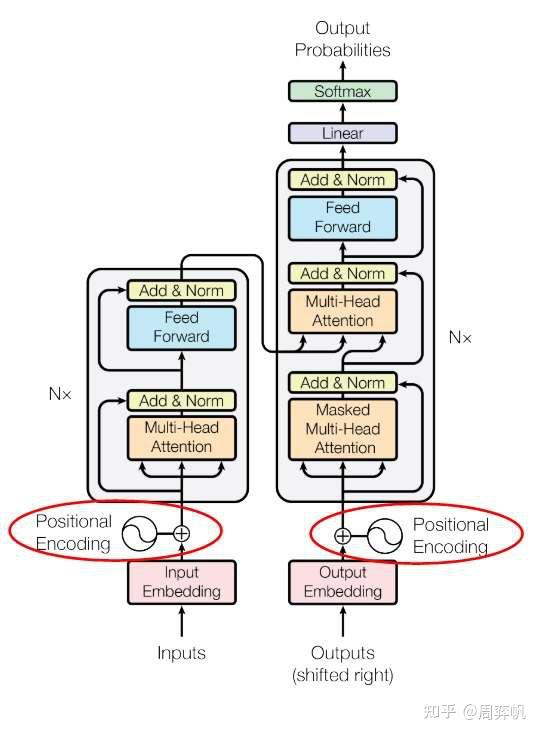
嵌入层的输出是一个向量数组,即词嵌入向量的序列。设数组的位置叫pos,向量的某一维叫i。
维度向量索引(i) 的理解:
首先位置编码的结构:
位置编码向量是一个长度为 d_model(例如 512)的向量,其中:
-
偶数索引位置(0,2,4,...)使用正弦函数计算:
PE(pos, 2i) = sin(...) -
奇数索引位置(1,3,5,...)使用余弦函数计算:
PE(pos, 2i+1) = cos(...) -
这里的i就是维度索引,它表示的是位置编码向量中“逻辑维度组”。
为什么需要维度索引i?
位置编码的关键思想是:不同维度对应不同“频率”的位置信息:
- 较小的i值->较低的频率->捕捉长距离位置关系
- 较大的i值->较高的频率->捕捉短距离位置关系
想象位置编码矩阵(序列长度 x 模型维度):
位置0: [sin(i=0), cos(i=0), sin(i=1), cos(i=1), ...]
位置1: [sin(i=0), cos(i=0), sin(i=1), cos(i=1), ...]
...
- 每一列对应一个特定的i值
- 同一i的sin/cos对编码相似的位置关系特性
- 不同i提供不同“分辨率”的位置信息
加上位置pos
位置序列: [0, 1, 2]位置编码矩阵: 位置0: [PE(0,0), PE(0,1), PE(0,2), PE(0,3)] 位置1: [PE(1,0), PE(1,1), PE(1,2), PE(1,3)] 位置2: [PE(2,0), PE(2,1), PE(2,2), PE(2,3)]
关键特性
-
绝对位置表示:每个整数位置对应唯一编码
-
顺序保持:位置1的编码介于位置0和位置2之间
-
相对距离:位置差越大,编码差异越大
-
可扩展性:理论上可处理任意长度序列(受限于数值精度)
我们为每一个向量里的每一个数添加一个实数编码, 这种编码方式要满足以下性质:
1. 对于同一个pos不同的i, 即对于一个词嵌入向量的不同元素,它们的编码要各不相同。
2. 对于向量的同一个维度处,不同pos的编码不同。且pos间要满足相对关系,即
。
要满足这两种性质的话,我们可以轻松地设计一种编码函数:
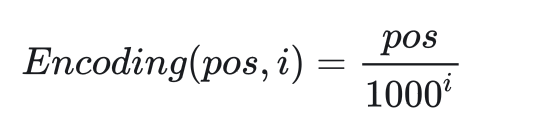
即对于每一个位置i,用小数点后的3个十进制数位来表示不同的pos,pos之间也满足相对关系。
但是,这种编码不利于网络学习。我们更希望所有编码都差不多大小,且都位于0~1之间。为此,Transformer使用了三角函数作为编码函数。这种位置编码(Positional Encoding, PE)的公式如下。
![]()
i不同,则三角函数的周期不同。同pos不同周期的三角函数值不重复。这满足上面的性质1。另外,根据三角函数的和角公式:
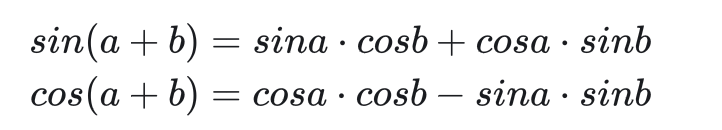
f(pos + k )是 f(pos) 的一个线性函数,即不同的pos之间有相对关系。这满足性质2。
本文作者也尝试了用可学习的函数作为位置编码函数。实验表明,二者的表现相当。作者还是使用了三角函数作为最终的编码函数,这是因为三角函数能够外推到任意长度的输入序列,而可学习的位置编码只能适应训练时的序列长度。
14. 为什么用自注意力
在论文的第四章,作者用自注意力层对比了循环层和卷积层,探讨了自注意力的一些优点。
自注意力层是一种和循环层和卷积层等效的计算单元。它们的目的都是把一个向量序列映射成另一个向量序列,比如说编码器把x映射成中间表示。论文比较了三个指标:每一层的计算复杂度、串行操作的复杂度、最大路径长度。

前两个指标很容易懂,第三个指标最大路径长度需要解释一下。最大路径长度表示数据从某个位置传递到另一个位置的最大长度。比如对边长为n的图像做普通卷积操作,卷积核大小为3*3, 要做n/3次卷积才能把信息丛左上角的像素传播到右下角的像素。设卷积核变长为k,则最大路径长度。如果是空洞卷积的话,像素第一次卷积的感受也是3*3,第二次是5*5,第三次是9*9,以此类推,感受也会指数级增长,这种卷积最大路径长度为
我们可以从这三个指标分别探讨自注意力的好处。首先看序列操作的复杂度。如引言所写,循环层最大的问题是不能并行训练,序列计算复杂度是。而自注意力层和卷积一样可以完全并行。
再看每一层的复杂度。设n是序列长度,d是词嵌入向量长度。其他架构的复杂度有,而自注意力是d。一般模型的d会大于n,自注意力的计算复杂度也会低一些。
最后是最大路径长度。注意力本来就是全局查询操作,可以在O(1的时间里完成所有元素间信息的传递。它的信息传递速度远胜卷积层和循环层。
为了降低每层的计算复杂度,可以改进自注意力层的查询方式,让每个元素查询最近的个元素。本文仅提出了这一想法,并没有做相关实验。
15. 实验与结果
本工作测试了“英语-德语”和“英语-法语”两项翻译任务。使用论文的默认模型配置,在8张P100上只需12小时就能把模型训练完。本工作使用了Adam优化器,并对学习率调度有一定的优化。模型有两种正则化方式:1)每个子层后面有Dropout,丢弃概率0.1;2)标签平滑(Label Smoothing)。Transformer在翻译任务上胜过了所有其他模型,且训练时间大幅缩短。
论文同样展示了不同配置下Transformer的消融实验结果。
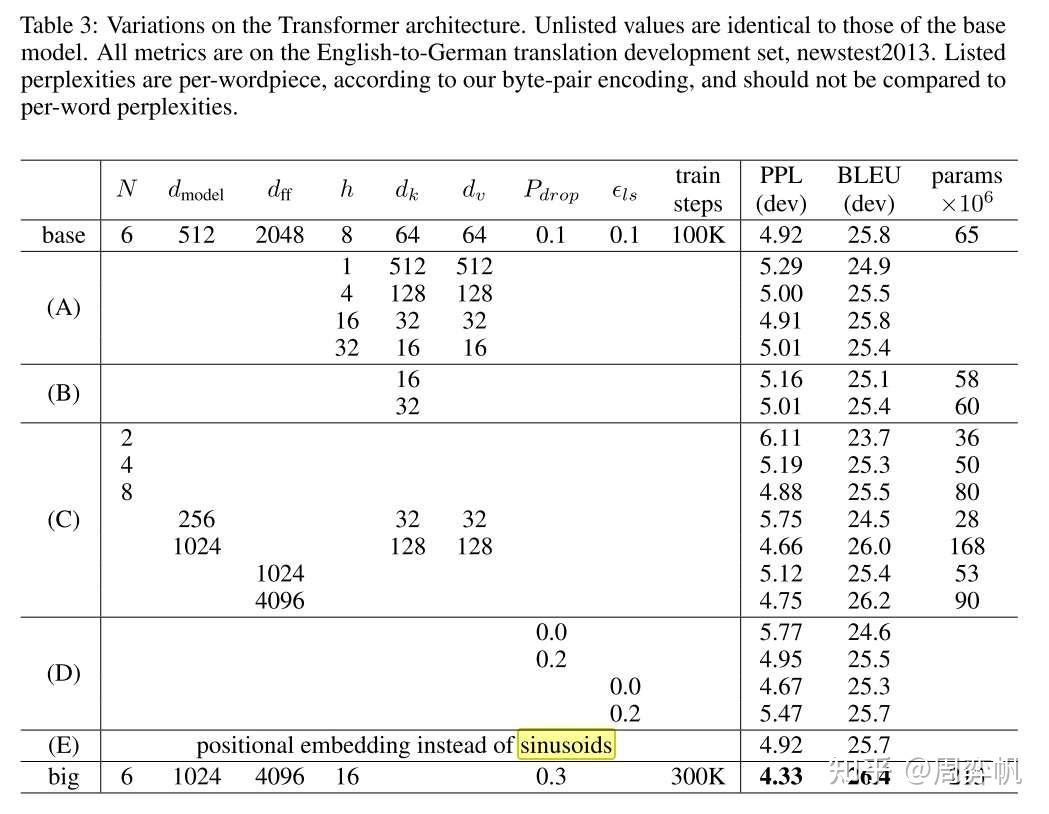
实验A表明,计算量不变的前提下,需要谨慎地调节h和的比例,太大太小都不好。这些实验也说明,多头注意力比单头是要好的。
实验B表明,增加可以提升模型性能。作者认为,这说明计算key, value相关性是比较困难的,如果用更精巧的计算方式来代替点乘,可能可以提升性能。
实验C, D表明,大模型是更优的,且dropout是必要的。
如正文所写,实验E探究了可学习的位置编码。可学习的位置编码的效果和三角函数几乎一致。
16. 总结
为了改进RNN不可并行的问题,这篇工作提出了Transformer这一仅由注意力机制构成的模型。Transformer的效果非常出色,不仅训练速度快了,还在两项翻译任务上胜过其他模型。
作者也很期待Transformer在其他任务上的应用。对于序列长度比较大的任务,如图像、音频、视频,可能要使用文中提到的只关注局部的注意力机制。由于序列输出时仍然避免不了串行,作者也在探究如何减少序列输出的串行度。
现在来看,Transformer是近年来最有影响力的深度学习模型之一。它先是在NLP中发扬光大,再逐渐扩散到了CV等领域。文中的一些预测也成为了现实,现在很多论文都在讨论如何在图像中使用注意力,以及如何使用带限制的注意力以降低长序列导致的计算性能问题。
我认为,对于深度学习的初学者,不管是研究什么领域,都应该仔细学习Transformer。在学Transformer之前,最好先了解一下RNN和经典的encoder-decoder架构,再学习注意力模型。有了这些基础,读Transformer论文就会顺利很多。读论文时,最重要的是看懂注意力公式的原理,再看懂自注意力和多头注意力,最后看一看位置编码。其他一些和机器翻译任务相关的设计可以不用那么关注
二. PyTorch Transformer 英中翻译超详细教程
1. 数据集准备
https://github.com/P3n9W31/transformer-pytorch 项目中找到了一个较小的中英翻译数据集。数据集只有几KB大小,中英词表只有10000左右,比较适合做Demo。如果要实现更加强大实用的模型,则需要换更大的数据集。但相应地,你要多花费更多的时间来训练。
该数据集由cn.txt, en.txt, cn.txt.vocab.tsv, en.txt.vocab.tsv这四个文件组成。前两个文件包含相互对应的中英文句子,其中中文已做好分词,英文全为小写且标点已被分割好。后两个文件是预处理好的词表。语料来自2000年左右的中国新闻,其第一条的中文及其翻译如下:
目前 粮食 出现 阶段性 过剩 , 恰好 可以 以 粮食 换 森林 、 换 草地 , 再造 西部 秀美 山川 。
the present food surplus can specifically serve the purpose of helping western china restore its woodlands , grasslands , and the beauty of its landscapes .
词表则统计了各个单词的出现频率。通过使用词表,我们能实现单词和序号的相互转换(比如中文里的5号对应“的”字,英文里的5号对应"the")。词表的前四个单词是特殊字符,分别为填充字符、频率太少没有被加入词典的词语、句子开始字符、句子结束字符。
<PAD> 1000000000
<UNK> 1000000000
<S> 1000000000
</S> 1000000000
的 8461
是 2047
和 1836
在 1784
<PAD> 1000000000
<UNK> 1000000000
<S> 1000000000
</S> 1000000000
the 13680
and 6845
of 6259
to 4292
i_seq = torch.linspace(0, max_seq_len - 1, max_seq_len)
j_seq = torch.linspace(0, d_model - 2, d_model // 2)
pos, two_i = torch.meshgrid(i_seq, j_seq)
2. Transformer 模型
准备好数据后,接下来就要进行这个项目最重要的部分--- Transformer 模型实现了。 我将按照代码的执行顺序,从前往后,自底向上介绍Transformer的各个模块,Positional Encoding, MultiHead Attention,Encoder&Decoder,最后介绍如何把各个模块拼到一起。
2.1 Positional Encoding
模型一开始是Embedding 层加一个Positional Encoding。Embedding在PyTorch里已经有实现了。
求Positional Encoding,其实就是求一个二院函数的许多函数值构成的矩阵。对于二元函数PE(po s, i),我们要求出时所有的函数值,其中,seqlen是该序列的长度,
是每一个词向量的长度。
理论上来说,每个句子的序列长度seqlen是不固定的。但是,我们可以提前预处理一个seqlen很大的Positional Encoding矩阵。每次有句子输入进来,根据这个句子和序列长度,去预处理好的矩阵里取一小块出来即可。
为了并行地求pe,我们要初始化一个二维网络,表示自变量pos, i。生成网络可以用下面的代码实现。
i_seq = torch.linspace(0, max_seq_len - 1, max_seq_len)
j_seq = torch.linspace(0, d_model - 2, d_model // 2)
pos, two_i = torch.meshgrid(i_seq, j_seq)
这段代码的理解:
i_seq:位置序列(pos)
torch.linspace(0, max_seq_len - 1, max_seq_len) - 生成从0 到 max_seq_len -1 的等间隔序列
- 长度= max_seq_len(序列总长度)
- 示例:若max_seq_len = 3 -> [0.0, 1.0, 2.0]
- 物理意义:每个token在序列中的位置索引
j_seq:维度索引序列(i)
torch.linspace(0, d_model - 2, d_model // 2)- 生成从0到d_model-2的等间隔序列
- 长度 = d_model // 2 (位置编码维度的一半)
- 示例: 若d_model = 4 -> [0.0, 2.0] (因为 4// 2 =2个点)
- 物理意义:位置编码向量索引(对应公式中的i)
网络生成 torch.meshgrid
pos, two_i = torch.meshgrid(i_seq, j_seq)- 功能: 创建两个网络矩阵,将两个ID序列扩展为2D网络
- 输出:
-
pos:形状为(max_seq_len, d_model//2)的矩阵# 示例:max_seq_len=3, d_model=4 → j_seq=[0.0,2.0] [[0., 0.], # 第一行全部填充i_seq[0][1., 1.], # 第二行全部填充i_seq[1][2., 2.]] # 第三行全部填充i_seq[2]
-
two_i:形状为(max_seq_len, d_model//2)的矩阵[[0., 2.], # 第一列填充j_seq[0][0., 2.], # 第二列填充j_seq[1][0., 2.]] # 第三列填充j_seq[1](复制行)
利用这个函数的返回结果,我们可以把pos, two_i套入论文的公式,并行地分别算出奇偶位置的 PE 值。
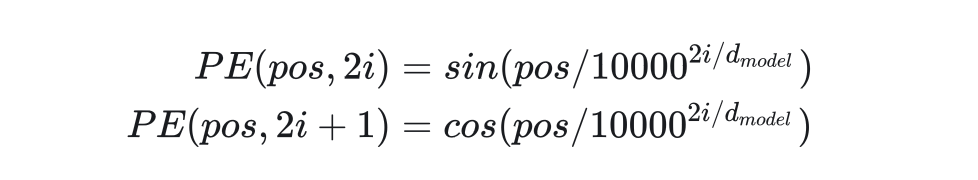
pe_2i = torch.sin(pos / 10000**(two_i / d_model))
pe_2i_1 = torch.cos(pos / 10000**(two_i / d_model))
有了奇偶处的值,现在的问题是怎么把它们优雅地拼到同一个维度上。我这里先把它们堆成了形状为seq_len, d_model/2, 2的一个张量,再把最后一维展平,就得到了最后的pe矩阵。这一操作等于新建一个seq_len, d_model形状的张量,再把奇偶位置处的值分别填入。
pe = torch.stack((pe_2i, pe_2i_1), 2).reshape(1, max_seq_len, d_model)最后,要注意一点。只用 self.pe = pe 记录这个量是不够好的。我们最好用 self.register_buffer('pe', pe, False) 把这个量登记成 torch.nn.Module 的一个存储区(这一步会自动完成self.pe = pe)。这里涉及到 PyTorch 的一些知识了。
PyTorch 的 Module 会记录两类参数,一类是 parameter 可学习参数,另一类是 buffer不可学习的参数。把变量登记成 buffer 的最大好处是,在使用 model.to(device) 把一个模型搬到另一个设备上时,所有 parameter 和 buffer 都会自动被搬过去。另外,buffer和 parameter 一样,也可以被记录到 state_dict 中,并保存到文件里。register_buffer 的第三个参数决定了是否将变量加入 state_dict。由于 pe 可以直接计算,不需要记录,可以把这个参数设成 False。
预处理好pe后,用起来就很方便了。每次读取输入的序列长度,从中取一段出来即可。
另外,Transformer给嵌入层乘了个系数。为了方便起见,我把这个系数放到了Positional Encoding类里面。
class PositionalEncoding(nn.Module):def __init__(self, d_model: int, max_seq_len: int):super().__init__()# Assume d_model is an even number for convenienceassert d_model % 2 == 0i_seq = torch.linspace(0, max_seq_len - 1, max_seq_len)j_seq = torch.linspace(0, d_model - 2, d_model // 2)pos, two_i = torch.meshgrid(i_seq, j_seq)pe_2i = torch.sin(pos / 10000**(two_i / d_model))pe_2i_1 = torch.cos(pos / 10000**(two_i / d_model))pe = torch.stack((pe_2i, pe_2i_1), 2).reshape(1, max_seq_len, d_model)self.register_buffer('pe', pe, False)def forward(self, x: torch.Tensor):n, seq_len, d_model = x.shapepe: torch.Tensor = self.peassert seq_len <= pe.shape[1]assert d_model == pe.shape[2]rescaled_x = x * d_model**0.5return rescaled_x + pe[:, 0:seq_len, :]2.2 Scaled Dot-Product Attention
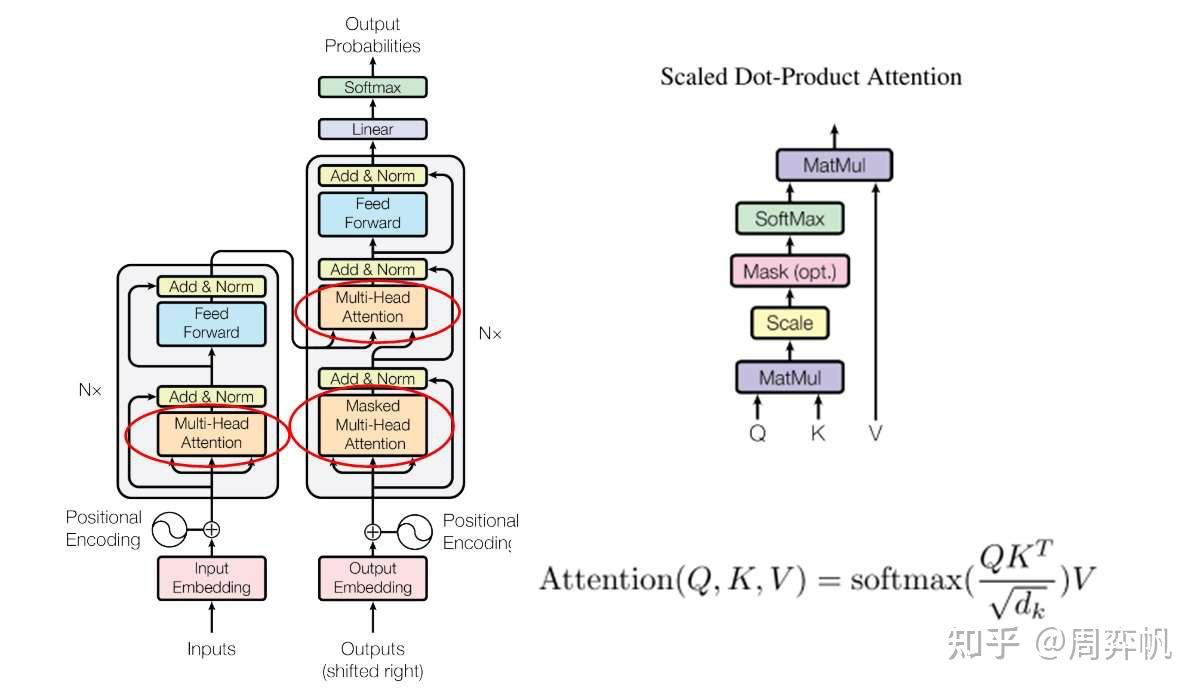
下一步是多头注意力层,为了实现多头注意力,我们先要实现Transformer里经典的注意力计算。而在讲注意力计算之前,我们还要补充一下Transformer中有关mask的一些知识。
Transformer里的mask
Transformer 最大的特点就是能够并行训练。给定翻译好的第1~n个词语,它默认会并行地预测第2~(n+1)个下一个词语。为了模拟串行输出的情况,第个词语不应该看到第个词语之后的信息。
| 输入信息 | 输出 |
|---|---|
| (y1, --, --, --) | y2 |
| (y1, y2, --, --) | y3 |
| (y1, y2, y3, --) | y4 |
| (y1, y2, y3, y4) | y5 |
为了实现这一功能,Transformer在decoder里使用了掩码。掩码取1表示这个地方的数是有效的,取0表示这个地方的数是无效的。Decoder里的这种掩码应该是一个上三角全1矩阵。
掩码是在注意力计算中生效的。对于掩码取0的区域,其softmax前的值取负无穷。这是因为,对于softmax
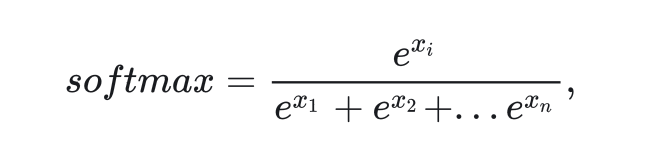
令 可以让它在softmax分母里不产生任何贡献。
以上是论文里提到的mask,它用来模拟Decoder的串行推理。而在代码实现中,还有其他地方会产生mask。在生成一个batch的数据时,要给句子填充<pad>。这个特殊字符也没有实际意义,不应该对计算产生任何贡献。因此,有<pad>的地方mask也应该为0。
注意力计算
由于注意力计算没有任何的状态,因此它应该写成一个函数,而不是一个类。我们可以轻松地用PyTorch代码翻译注意力计算的公式,我们可以轻松地用 PyTorch 代码翻译注意力计算的公式。(注意,我这里的 mask 表示哪些地方要填负无穷,而不是像之前讲的表示哪些地方有效)
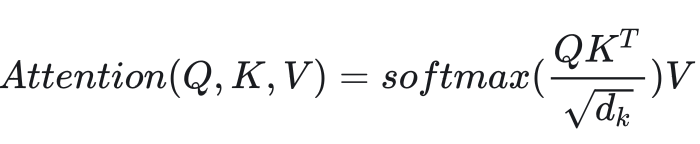
def attention(q: torch.Tensor,k: torch.Tensor,v: torch.Tensor,mask: Optional[torch.Tensor] = None):'''Note: The dtype of mask must be bool'''# q shape: [n, heads, q_len, d_k]# k shape: [n, heads, k_len, d_k]# v shape: [n, heads, k_len, d_v]assert q.shape[-1] == k.shape[-1]d_k = k.shape[-1]# tmp shape: [n, heads, q_len, k_len]tmp = torch.matmul(q, k.transpose(-2, -1)) / d_k**0.5if mask is not None:tmp.masked_fill_(mask, -MY_INF)tmp = F.softmax(tmp, -1)# tmp shape: [n, heads, q_len, d_v]tmp = torch.matmul(tmp, v)return tmp这里有一个很坑的地方。引入了 <pad> 带来的 mask 后,会产生一个新的问题:可能一整行数据都是失效的,softmax 用到的所有 可能都是负无穷 .
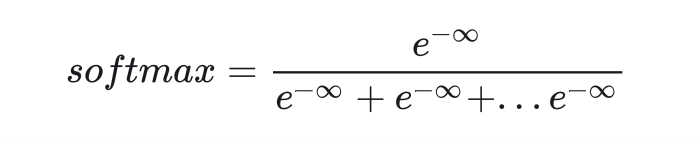
这个数是没有意义的。如果用torch.inf来表示无穷大,就会令exp(torch.inf)=0,最后 softmax 结果会出现 NaN,代码大概率是跑不通的。
但是,大多数 PyTorch Transformer 教程压根就没提这一点,而他们的代码又还是能够跑通。拿放大镜仔细对比了代码后,我发现,他们的无穷大用的不是 torch.inf,而是自己随手设的一个极大值。这样,exp(-MY_INF)得到的不再是0,而是一个极小值。softmax 的结果就会等于分母的项数,而不是 NaN,不会有数值计算上的错误。
Muti-Head Attention
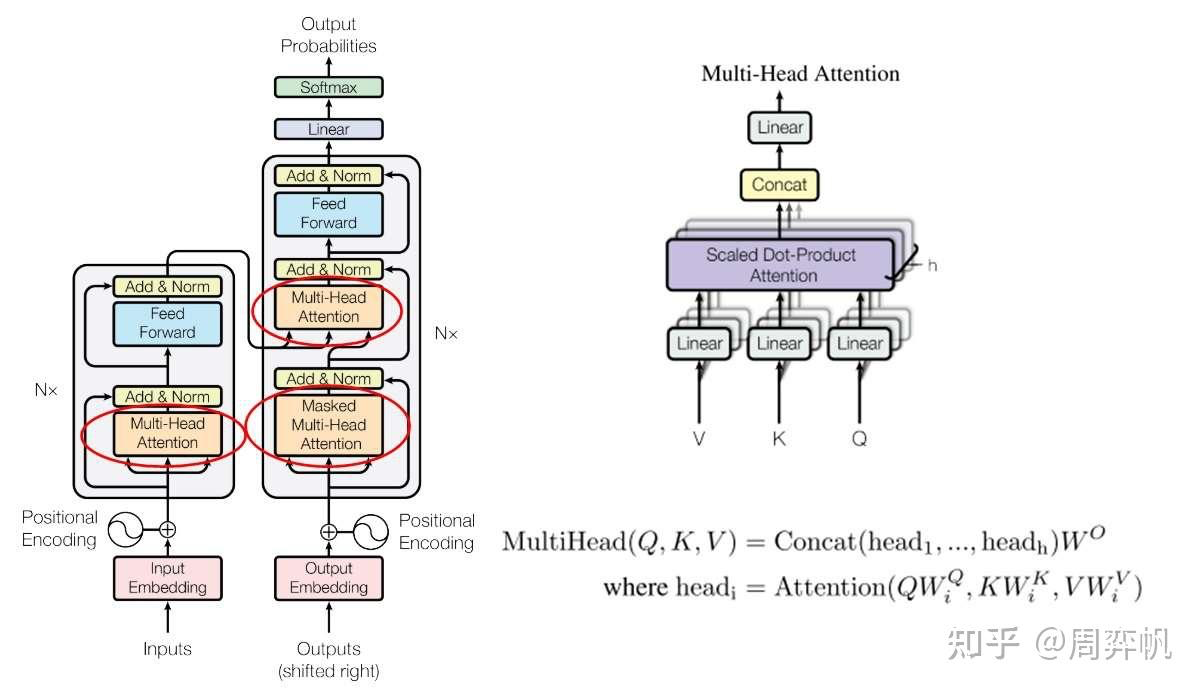
有了注意力计算,就可以实现多头注意力层了。多头注意力层时有学习参数的,它应该写成一个类。
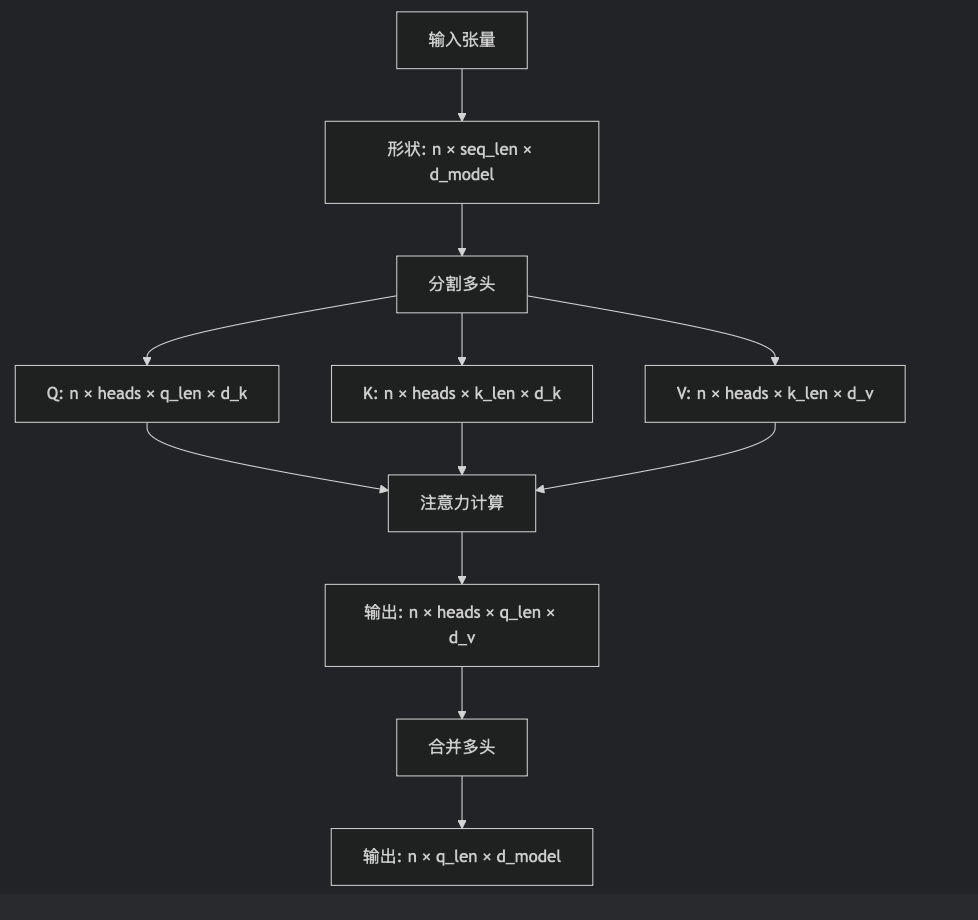
class MultiHeadAttention(nn.Module):def __init__(self, heads: int, d_model: int, dropout: float = 0.1):super().__init__()assert d_model % heads == 0# dk == dvself.d_k = d_model // headsself.heads = headsself.d_model = d_modelself.q = nn.Linear(d_model, d_model)self.k = nn.Linear(d_model, d_model)self.v = nn.Linear(d_model, d_model)self.out = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)def forward(self,q: torch.Tensor,k: torch.Tensor,v: torch.Tensor,mask: Optional[torch.Tensor] = None):# batch should be sameassert q.shape[0] == k.shape[0]assert q.shape[0] == v.shape[0]# the sequence length of k and v should be alignedassert k.shape[1] == v.shape[1]n, q_len = q.shape[0:2]n, k_len = k.shape[0:2]q_ = self.q(q).reshape(n, q_len, self.heads, self.d_k).transpose(1, 2)k_ = self.k(k).reshape(n, k_len, self.heads, self.d_k).transpose(1, 2)v_ = self.v(v).reshape(n, k_len, self.heads, self.d_k).transpose(1, 2)attention_res = attention(q_, k_, v_, mask)concat_res = attention_res.transpose(1, 2).reshape(n, q_len, self.d_model)concat_res = self.dropout(concat_res)output = self.out(concat_res)return output这段代码一处很灵性的地方。在 Transformer 的论文中,多头注意力是先把每个词的表示拆成个h头,再对每份做投影、注意力,最后拼接起来,再投影一次。其实,拆开与拼接操作是多余的。我们可以通过一些形状上的操作,等价地实现拆开与拼接,以提高运行效率。
具体来说,我们可以一开始就让所有头的数据经过同一个线性层,之后在做注意力之前把头和序列数这两维转置一下。这两步操作和拆开来做投影和注意力时等价的。做完了注意力操作之后,再把两个维度转置回来,这和拼接操作时等价的。
前馈网络
class FeedForward(nn.Module):def __init__(self, d_model: int, d_ff: int, dropout: float = 0.1):super().__init__()self.layer1 = nn.Linear(d_model, d_ff)self.dropout = nn.Dropout(dropout)self.layer2 = nn.Linear(d_ff, d_model)def forward(self, x):x = self.layer1(x)x = self.dropout(F.relu(x))x = self.layer2(x)return xEncoder & Decoder
准备好一切组件后,就可以把模型一层一层搭起来了。先搭好每个 Encoder 层和 Decoder 层,再拼成 Encoder 和 Decoder。
Encoder 层和 Decoder 层的结构与论文中的描述一致,且每个子层后面都有一个 dropout,和上一层之间使用了残差连接。归一化的方法是 LayerNorm。顺带一提,不仅是这些层,前面很多子层的计算中都加入了 dropout。
class EncoderLayer(nn.Module):def __init__(self,heads: int,d_model: int,d_ff: int,dropout: float = 0.1):super().__init__()self.self_attention = MultiHeadAttention(heads, d_model, dropout)self.ffn = FeedForward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)def forward(self, x, src_mask: Optional[torch.Tensor] = None):tmp = self.self_attention(x, x, x, src_mask)tmp = self.dropout1(tmp)x = self.norm1(x + tmp)tmp = self.ffn(x)tmp = self.dropout2(tmp)x = self.norm2(x + tmp)return x
class DecoderLayer(nn.Module):def __init__(self,heads: int,d_model: int,d_ff: int,dropout: float = 0.1):super().__init__()self.self_attention = MultiHeadAttention(heads, d_model, dropout)self.attention = MultiHeadAttention(heads, d_model, dropout)self.ffn = FeedForward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.dropout3 = nn.Dropout(dropout)def forward(self,x,encoder_kv: torch.Tensor,dst_mask: Optional[torch.Tensor] = None,src_dst_mask: Optional[torch.Tensor] = None):tmp = self.self_attention(x, x, x, dst_mask)tmp = self.dropout1(tmp)x = self.norm1(x + tmp)tmp = self.attention(x, encoder_kv, encoder_kv, src_dst_mask)tmp = self.dropout2(tmp)x = self.norm2(x + tmp)tmp = self.ffn(x)tmp = self.dropout3(tmp)x = self.norm3(x + tmp)return xEncoder和Decoder就在所有子层前面加了一个嵌入层、一个位置编码,再把多个子层堆起来而已,其他输入输出照搬即可。注意,我们可以给嵌入层输入pad_idx参数,让<pad>的计算不对梯度产生贡献。
class Encoder(nn.Module):def __init__(self,vocab_size: int,pad_idx: int,d_model: int,d_ff: int,n_layers: int,heads: int,dropout: float = 0.1,max_seq_len: int = 120):super().__init__()self.embedding = nn.Embedding(vocab_size, d_model, pad_idx)self.pe = PositionalEncoding(d_model, max_seq_len)self.layers = []for i in range(n_layers):self.layers.append(EncoderLayer(heads, d_model, d_ff, dropout))self.layers = nn.ModuleList(self.layers)self.dropout = nn.Dropout(dropout)def forward(self, x, src_mask: Optional[torch.Tensor] = None):x = self.embedding(x)x = self.pe(x)x = self.dropout(x)for layer in self.layers:x = layer(x, src_mask)return xclass Decoder(nn.Module):def __init__(self,vocab_size: int,pad_idx: int,d_model: int,d_ff: int,n_layers: int,heads: int,dropout: float = 0.1,max_seq_len: int = 120):super().__init__()self.embedding = nn.Embedding(vocab_size, d_model, pad_idx)self.pe = PositionalEncoding(d_model, max_seq_len)self.layers = []for i in range(n_layers):self.layers.append(DecoderLayer(heads, d_model, d_ff, dropout))self.layers = nn.Sequential(*self.layers)self.dropout = nn.Dropout(dropout)def forward(self,x,encoder_kv,dst_mask: Optional[torch.Tensor] = None,src_dst_mask: Optional[torch.Tensor] = None):x = self.embedding(x)x = self.pe(x)x = self.dropout(x)for layer in self.layers:x = layer(x, encoder_kv, dst_mask, src_dst_mask)return xTransformer类
我们一点一点来看。先看初始化函数。初始化函数的输入其实就是 Transformer 模型的超参数。总结一下,Transformer 应该有这些超参数:
d_model模型中大多数词向量表示的维度大小d_ff前馈网络隐藏层维度大小n_layers堆叠的 Encoder & Decoder 层数head多头注意力的头数dropoutDropout 的几率
另外,为了构建嵌入层,要知道源语言、目标语言的词典大小,并且提供pad_idx。为了预处理位置编码,需要提前知道一个最大序列长度。
照着子模块的初始化参数表,把参数归纳到__init__的参数表里即可。
class Transformer(nn.Module):def __init__(self,src_vocab_size: int,dst_vocab_size: int,pad_idx: int,d_model: int,d_ff: int,n_layers: int,heads: int,dropout: float = 0.1,max_seq_len: int = 200):super().__init__()self.encoder = Encoder(src_vocab_size, pad_idx, d_model, d_ff,n_layers, heads, dropout, max_seq_len)self.decoder = Decoder(dst_vocab_size, pad_idx, d_model, d_ff,n_layers, heads, dropout, max_seq_len)self.pad_idx = pad_idxself.output_layer = nn.Linear(d_model, dst_vocab_size)def generate_mask(self,q_pad: torch.Tensor,k_pad: torch.Tensor,with_left_mask: bool = False):# q_pad shape: [n, q_len]# k_pad shape: [n, k_len]# q_pad k_pad dtype: boolassert q_pad.device == k_pad.devicen, q_len = q_pad.shapen, k_len = k_pad.shapemask_shape = (n, 1, q_len, k_len)if with_left_mask:mask = 1 - torch.tril(torch.ones(mask_shape))else:mask = torch.zeros(mask_shape)mask = mask.to(q_pad.device)for i in range(n):mask[i, :, q_pad[i], :] = 1mask[i, :, :, k_pad[i]] = 1mask = mask.to(torch.bool)return maskdef forward(self, x, y):src_pad_mask = x == self.pad_idxdst_pad_mask = y == self.pad_idxsrc_mask = self.generate_mask(src_pad_mask, src_pad_mask, False)dst_mask = self.generate_mask(dst_pad_mask, dst_pad_mask, True)src_dst_mask = self.generate_mask(dst_pad_mask, src_pad_mask, False)encoder_kv = self.encoder(x, src_mask)res = self.decoder(y, encoder_kv, dst_mask, src_dst_mask)res = self.output_layer(res)return res再看一下 forward 函数。forward先预处理好了所有的 mask,再逐步执行 Transformer 的计算:先是通过 Encoder 获得源语言的中间表示encoder_kv,再把它和目标语言y的输入一起传入 Decoder,最后经过线性层输出结果res。由于 PyTorch 的交叉熵损失函数自带了 softmax 操作,这里不需要多此一举。
generate_mask 的输入有 query 句子和 key 句子的 pad mask q_pad, k_pad,它们的形状为[n, seq_len]。若某处为 True,则表示这个地方的字符是<pad>。对于自注意力,query 和 key 都是一样的;而在 Decoder 的第二个多头注意力层中,query 来自目标语言,key 来自源语言。with_left_mask 表示是不是要加入 Decoder 里面的模拟串行推理的 mask,它会在掩码自注意力里用到。
一开始,先取好维度信息,定好张量的形状。在注意力操作中,softmax 前的那个量的形状是 [n, heads, q_len, k_len],表示每一批每一个头的每一个query对每个key之间的相似度。每一个头的mask是一样的。因此,除heads维可以广播外,mask 的形状应和它一样。
mask_shape=(n,1,q_len,k_len)
再新建一个表示最终 mask 的张量。如果不用 Decoder 的那种 mask,就生成一个全零的张量;否则,生成一个上三角为0,其余地方为1的张量。注意,在我的代码中,mask 为 True 或1就表示这个地方需要填负无穷。
下面的代码利用了PyTorch的取下标机制,直接并行地完成了mask赋值。
for i in range(n):mask[i, :, q_pad[i], :] = 1mask[i, :, :, k_pad[i]] = 1
完整代码如下:
def generate_mask(self,q_pad: torch.Tensor,k_pad: torch.Tensor,with_left_mask: bool = False):# q_pad shape: [n, q_len]# k_pad shape: [n, k_len]# q_pad k_pad dtype: boolassert q_pad.device == k_pad.devicen, q_len = q_pad.shapen, k_len = k_pad.shapemask_shape = (n, 1, q_len, k_len)if with_left_mask:mask = 1 - torch.tril(torch.ones(mask_shape))else:mask = torch.zeros(mask_shape)mask = mask.to(q_pad.device)for i in range(n):mask[i, :, q_pad[i], :] = 1mask[i, :, :, k_pad[i]] = 1mask = mask.to(torch.bool)return mask看完了mask的生成方法后,我们回到前一步,看看mask会在哪些地方被调用。
在 Transformer 中,有三类多头注意力层,它们的 mask 也不同。Encoder 的多头注意力层的 query 和 key 都来自源语言;Decoder 的第一个多头注意力层的 query 和 key 都来自目标语言;Decoder 的第二个多头注意力层的 query 来自目标语言, key 来自源语言。另外,Decoder 的第一个多头注意力层要加串行推理的那个 mask。按照上述描述生成mask即可。
def forward(self, x, y):src_pad_mask = x == self.pad_idxdst_pad_mask = y == self.pad_idxsrc_mask = self.generate_mask(src_pad_mask, src_pad_mask, False)dst_mask = self.generate_mask(dst_pad_mask, dst_pad_mask, True)src_dst_mask = self.generate_mask(dst_pad_mask, src_pad_mask, False)encoder_kv = self.encoder(x, src_mask)res = self.decoder(y, encoder_kv, dst_mask, src_dst_mask)res = self.output_layer(res)return res
训练
准备好了模型、数据集后,剩下的工作非常惬意,只要随便调用一下就行了。训练的代码如下:
import torch
import torch.nn as nn
import timefrom dldemos.Transformer.data_load import (get_batch_indices, load_cn_vocab,load_en_vocab, load_train_data,maxlen)
from dldemos.Transformer.model import Transformer# Config
batch_size = 64
lr = 0.0001
d_model = 512
d_ff = 2048
n_layers = 6
heads = 8
dropout_rate = 0.2
n_epochs = 60
PAD_ID = 0def main():device = 'cuda'cn2idx, idx2cn = load_cn_vocab()en2idx, idx2en = load_en_vocab()# X: en# Y: cnY, X = load_train_data()print_interval = 100model = Transformer(len(en2idx), len(cn2idx), PAD_ID, d_model, d_ff,n_layers, heads, dropout_rate, maxlen)model.to(device)optimizer = torch.optim.Adam(model.parameters(), lr)citerion = nn.CrossEntropyLoss(ignore_index=PAD_ID)tic = time.time()cnter = 0for epoch in range(n_epochs):for index, _ in get_batch_indices(len(X), batch_size):x_batch = torch.LongTensor(X[index]).to(device)y_batch = torch.LongTensor(Y[index]).to(device)y_input = y_batch[:, :-1]y_label = y_batch[:, 1:]y_hat = model(x_batch, y_input)y_label_mask = y_label != PAD_IDpreds = torch.argmax(y_hat, -1)correct = preds == y_labelacc = torch.sum(y_label_mask * correct) / torch.sum(y_label_mask)n, seq_len = y_label.shapey_hat = torch.reshape(y_hat, (n * seq_len, -1))y_label = torch.reshape(y_label, (n * seq_len, ))loss = citerion(y_hat, y_label)optimizer.zero_grad()loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), 1)optimizer.step()if cnter % print_interval == 0:toc = time.time()interval = toc - ticminutes = int(interval // 60)seconds = int(interval % 60)print(f'{cnter:08d} {minutes:02d}:{seconds:02d}'f' loss: {loss.item()} acc: {acc.item()}')cnter += 1model_path = 'dldemos/Transformer/model.pth'torch.save(model.state_dict(), model_path)print(f'Model saved to {model_path}')if __name__ == '__main__':main()
所有的超参数都写在代码开头。在模型结构上,我使用了和原论文一样的超参数。
# Config
batch_size = 64
lr = 0.0001
d_model = 512
d_ff = 2048
n_layers = 6
heads = 8
dropout_rate = 0.2
n_epochs = 60
PAD_ID = 0
之后,进入主函数。一开始,我们调用load_data.py提供的API,获取中英文序号到单词的转换词典,并获取已经打包好的训练数据。
def main():device = 'cuda'cn2idx, idx2cn = load_cn_vocab()en2idx, idx2en = load_en_vocab()# X: en# Y: cnY, X = load_train_data()
接着,我们用参数初始化好要用到的对象,比如模型、优化器、损失函数。
print_interval = 100model = Transformer(len(en2idx), len(cn2idx), PAD_ID, d_model, d_ff,n_layers, heads, dropout_rate, maxlen)
model.to(device)optimizer = torch.optim.Adam(model.parameters(), lr)citerion = nn.CrossEntropyLoss(ignore_index=PAD_ID)
tic = time.time()
cnter = 0
再然后,进入训练循环。我们从X, Y里取出源语言和目标语言的序号数组,输入进模型里。别忘了,Transformer可以并行训练。我们给模型输入目标语言前n-1个单词,用第2到第n个单词作为监督标签。
for epoch in range(n_epochs):for index, _ in get_batch_indices(len(X), batch_size):x_batch = torch.LongTensor(X[index]).to(device)y_batch = torch.LongTensor(Y[index]).to(device)y_input = y_batch[:, :-1]y_label = y_batch[:, 1:]y_hat = model(x_batch, y_input)
得到模型的预测y_hat后,我们可以把输出概率分布中概率最大的那个单词作为模型给出的预测单词,算一个单词预测准确率。当然,我们要排除掉<pad>的影响。
y_label_mask = y_label != PAD_ID
preds = torch.argmax(y_hat, -1)
correct = preds == y_label
acc = torch.sum(y_label_mask * correct) / torch.sum(y_label_mask)
我们最后算一下loss,并执行梯度下降,训练代码就写完了。为了让训练更稳定,不出现梯度过大的情况,我们可以用torch.nn.utils.clip_grad_norm_(model.parameters(), 1)裁剪梯度。
n, seq_len = y_label.shape
y_hat = torch.reshape(y_hat, (n * seq_len, -1))
y_label = torch.reshape(y_label, (n * seq_len, ))
loss = citerion(y_hat, y_label)optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1)
optimizer.step()训练结果
