Foundation Models for Generalist Geospatial Artificial Intelligence论文阅读
文章目录
- 摘要
- 1. 引言
- 2. 研究背景
- 3. 预训练数据
- 3.1 HLS-2数据
- 3.2 高效数据采样
- 3.3 预处理程序
- 4. 模型结构和预训练
- 4.1 时空数据考虑
- 4.2 预训练
- 4.3 预训练结果
- 5. 下游任务
- 5.1 任务微调数据集
- 5.2 微调模型设置
- 5.3 微调任务结果
- 5.3.1 云插补任务
- 5.3.2 洪水映射任务
- 5.3.3 火灾痕迹检测
- 5.3.4 多光谱作物分割
- 6. 讨论
- 7. 总结
- 8. 个人总结
论文原网址:https://arxiv.org/abs/2310.18660
huggingface:https://huggingface.co/ibm-nasa-geospatial
Github:https://github.com/NASA-IMPACT/hls-foundation-os
摘要
高度可适应和可重复使用的人工智能模型的开发将在地球科学和遥感领域产生重大影响。基础模型在大量未标注数据集上进行自监督预训练,然后通过少量标注数据集进行微调,以适应各种下游任务。科学界越来越关注这种方法是否能成功地应用于自然语言处理以外的领域,从而有效地构建利用多传感器数据的通用AI模型。本文介绍了一种新框架,用于在大规模地理空间数据上高效进行基础模型的预训练和微调。我们利用这一框架创建了 Prithvi,一种基于transformer的地理空间基础模型,预训练使用了来源于Landsat-Sentinel 2(HLS)数据集的超过1TB多光谱卫星影像数据。我们的研究展示了微调 Prithvi 以应对一系列地球观测任务的有效性,这些下游任务包括多时相云孔缺失填补、洪水映射、野火痕迹分割和多时相作物分割等。我们深入分析并评估了 Prithvi 预训练权重对下游任务的影响,也比较了三种不同的学习曲线:1)微调整个模型,2)仅微调解码器以进行下游任务,3)在不利用 Prithvi 预训练权重的情况下训练模型。实验结果表明,使用预训练模型相比随机初始化权重能够加速微调过程。此外,预训练的 Prithvi 在下游任务中表现良好,例如在多时相云填补任务中,结构相似度指数相比条件生成对抗网络(GAN)模型提高了5个百分点(或5.7%)。最后,由于地球观测领域中标注数据的有限性,我们逐步减少可用标注数据量以精细化模型,评估数据效率,并展示在显著减少数据量的情况下,模型的准确性仍能保持不变。预训练的1亿参数模型及其相应的微调工作流已经通过 Hugging Face 向全球地球科学社区公开发布,作为开源贡献。
1. 引言
随着数据可用性和AI模型规模的不断增加,开发和训练模型已经变得愈加昂贵。这对于以观测为驱动的地球科学领域尤其重要。在当今庞大的遥感数据量环境中,探索和处理未标记数据的挑战为研究工作带来了巨大的障碍。因此,机器学习和深度学习技术被越来越多地应用于更高效地分析这些数据集。然而,绝大多数地球科学和遥感领域的AI模型仍然依赖于标记数据进行监督学习,而这些标记数据的生产成本十分高昂。此外,这些任务特定的模型在空间和时间上的泛化能力较差,迫使每个应用都需要构建新的模型。为了解决这些问题,基础模型应运而生,它通过自监督学习在大量未标记的数据集上进行预训练。然后,基础模型可以通过较小的标记数据集进行微调,应用于多种下游任务。这种任务无关的范式在自然语言处理等领域最近解锁了新的性能水平和新兴行为。因此,科学界对如何在地球科学和遥感领域有效利用这一方法,构建能够在多种任务中表现出色的通用模型,产生了越来越浓厚的兴趣。
在本文中,我们提出了一个框架用于创建地理空间基础模型,我们的框架提供了一个分布式且可扩展的基础结构,用于训练、微调和推理,并通过智能数据发现操作符(如采样和预处理)直接连接到地理空间数据源。我们在图1中概述了这一框架。我们使用这个框架训练了Prithvi,这是一个利用NASA的统一陆地卫星Sentinel-2(HLS)多光谱卫星数据的地理空间基础模型。预训练的模型经过微调,适用于多种下游应用,如多时相云填补、洪水制图、火灾痕迹分割和多时相作物分割。我们通过研究一系列关键研究问题(RQ)全面评估了模型的性能,重点考虑了人工智能在地球科学领域的发展、影响和合作:
RQ1:在地球科学中,设计和评估基础模型的关键因素是什么?
RQ2:考虑到遥感数据的海量数据量,其中可能包含不同生态系统和景观中重复的信息,以及数据采集过程中固有的噪声(如云遮挡或传感器故障),我们如何有效地预训练基础模型,确保噪声移除并避免冗余?
RQ3:基础模型能否利用训练数据中的不同特征,并在不同的地球科学领域中进行泛化,同时只需要显著更少的标注数据即可达到基准性能?
在本工作的剩余部分,我们将全面回答关于大规模自监督学习和基础模型时代,人工智能在地球科学领域的关键研究问题。通过分享我们的见解,并提供开源的模型架构、预训练权重以及在HuggingFace上的推理服务,我们支持加速人工智能在地球科学领域的发展。
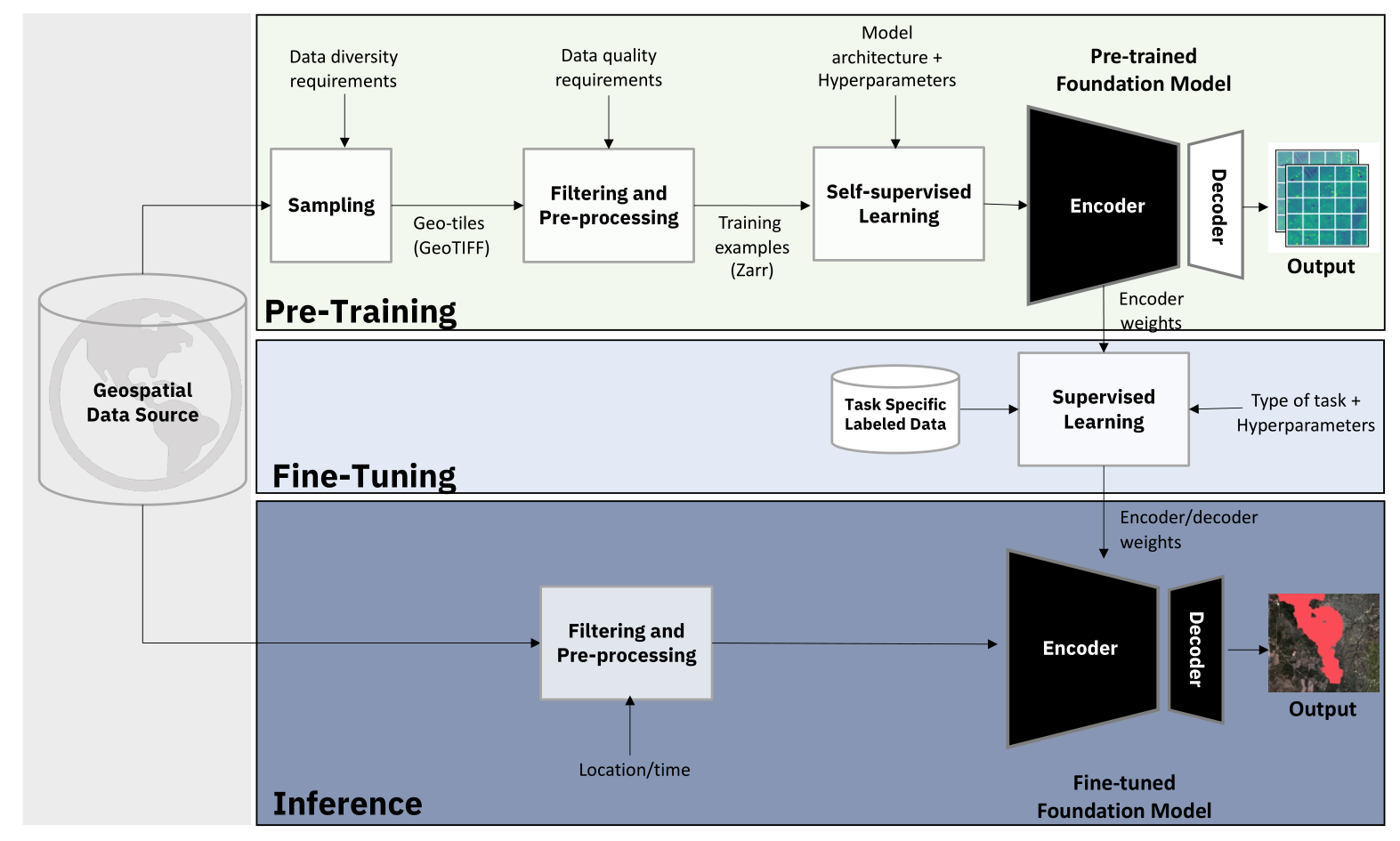
图1:我们提出了一个开创性的框架,用于从原始卫星影像开发地理空间基础模型,并利用该框架生成Prithvi-100M模型。该框架包括:(1)原始地理空间数据的采样、过滤和预处理,以及自监督基础模型的预训练;(2)针对特定下游应用的微调;(3)推理过程。
2. 研究背景
基础模型是通用型AI模型,通过自监督在大规模无标签数据集上进行预训练,然后针对不同的下游任务进行微调。
Masked Autoencoder(MAE)被设计用于从部分观测中重建原始信号,将图像划分为不重叠的块,随机采样一些块并遮掩其他块,以减少冗余。其编码器基于Vision Transformer(ViT)模型,仅处理可见块,从而优化计算效率;解码器使用编码后的可见块和遮掩标记来重建图像,主要用于预训练;重建过程预测遮掩块的像素值,通过均方误差(MSE)来衡量原始图像与重建图像之间的差异。MAE的预训练过程设计高效,避免了专门的操作,其成为图像处理的一种新颖方法。
在地球科学领域,研究表明,最初为计算机视觉开发的自监督学习方案可以适应用于基于多光谱和时间序列卫星影像的模型预训练,近期也有一些针对遥感的基础模型提案。然而,这些模型主要聚焦于来自基准数据集的航空影像,旨在进行目标检测任务,并且仅限于可见光波段(红、绿、蓝)。因此,这些模型忽视了卫星影像的地理空间、多光谱和时间序列特性,使得它们不适合大规模的地球观测任务。首次尝试将这些数据类型纳入自监督预训练的方法是Presto。Presto的开发旨在实现轻量级计算,因此其模型较小,参数不到100万(即大约是Prithvi的100倍小)。Presto模型并不通过对图像进行卷积操作来在空间图块之间应用注意力机制。因此,Presto的作者指出,对于基于图像的预测任务,尤其是那些“高度依赖于图像子区域中物体出现”的任务,预处理空间信息的模型可能更为适合。基于这些原因,我们认为Presto是Prithvi的互补方法,在利用长时间序列卫星影像方面具有很高的效能。
地球科学中的遥感目前依赖于针对个别任务的定制模型,并且可能受到地面真值数据可用性的限制。火灾痕迹检测、洪水检测、作物分割,这些研究中引用的每种方法都依赖于标签数据,取决于标签数据的生成,这限制了模型的规模。这些方法需要地面检查和本地知识,具有区域特定性,并且在没有产生大量标签数据的情况下很难进行大规模应用。
已实施的持续学习机制可以缓解灾难性遗忘,随着新信息的到来对模型进行微调,这预示着多任务预训练模型的发展,我们旨在展示Prithvi在适应这些任务方面的能力,并在需要更少标签数据的情况下取得相当或更优的结果。
3. 预训练数据
3.1 HLS-2数据
本文所用HLS-2(Harmonized Landsat Sentinel-2)数据源于NASA戈达德航天中心的研究,利用NASA/USGS的Landsat 8和9卫星与ESA的Sentinel-2A和Sentinel-2B卫星数据,生成统一的地表反射率数据产品。该数据产品提供约每2到3天一次的观测,旨在支持农业监测和详细的土地覆盖分类,涵盖了可见光和热红外波段。
HLS数据通过将Landsat 8和9的OLI传感器与Sentinel-2的MSI传感器的数据进行统一处理,提供了更频繁的影像产品,极大地提升了土地表面监测的频率。HLS数据包括L30(来自Landsat)和S30(来自Sentinel-2)两种产品,分别在30米和10到20米的分辨率下,具有不同的重复周期(Landsat为16天,Sentinel-2为5天)。
HLS L30数据源自Landsat 8的表面反射率数据,并经过正射校正,数据可通过NASA的“HLS Subsetting, Processing, and Exporting Reformatted”工具进行访问。每个HLS图块的尺寸为3660×3660像素,覆盖约109.8×109.8公里的区域。虽然HLS提供多达15个波段的影像数据,但仅使用其中的6个波段(Sentinel-2的2、3、4、8A、11和12波段)用于模型训练。
HLS数据之所以被选中,是因为它具有庞大的数据存档(3.61 PB,数据起始于2015年)和广泛的用户基础。特别值得一提的是,90%的HLS用户来自非政府部门,其中65%的用户来自教育领域,使用了82%的数据,这凸显了HLS在教育和研究中的重要性。此外,商业和非营利组织的用户也占有一定比例。HLS的全球影响力体现在它被广泛应用于不同的地理区域,特别是美国、中国、印度、巴西等国,成为国际研究的核心资源。
HLS数据被广泛应用于多种下游任务,如德国的国家级草原管理、澳大利亚的洪水监测、美国的生物量估算、美国中部的湿地与草原火灾监控等,体现了它在环境管理、灾害响应等领域的重要作用。
3.2 高效数据采样
在卫星数据的预训练过程中,由于不同地区和年份的数据冗余,直接使用所有可用数据进行预训练往往效率低下,例如,随机抽样可能会导致偏向于常见景观,而忽视那些较少见的景观。为了克服这一问题,我们需要一个具有代表性的样本集,避免对常见景观的偏倚,为了解决这个挑战,我们开发了一种基于地理空间统计的灵活分层抽样方法,旨在为预训练提供一个多样化的数据集。
该方法的核心步骤包括:首先,我们自动计算目标区域内不同地理空间统计数据的低分辨率汇总;其次,根据这些统计数据将低分辨率的图块划分为不同的组;最后,我们从这些组中进行均匀抽样,以确保样本集的代表性。这样可以有效避免偏向某些特定景观,确保数据的多样性。
以美国大陆为例,我们使用了从1980年至2022年的日均气温和降水数据(来源于PRISM数据集),以4公里分辨率计算得到了多个统计指标。然后,我们根据这42年期间的气温和降水99%分位值,将美国大陆划分为20个区域。最后,从这些区域中抽取样本,生成用于预训练的数据集,确保气温和降水统计数据的多样性,这也能够作为不同类型景观的代表。
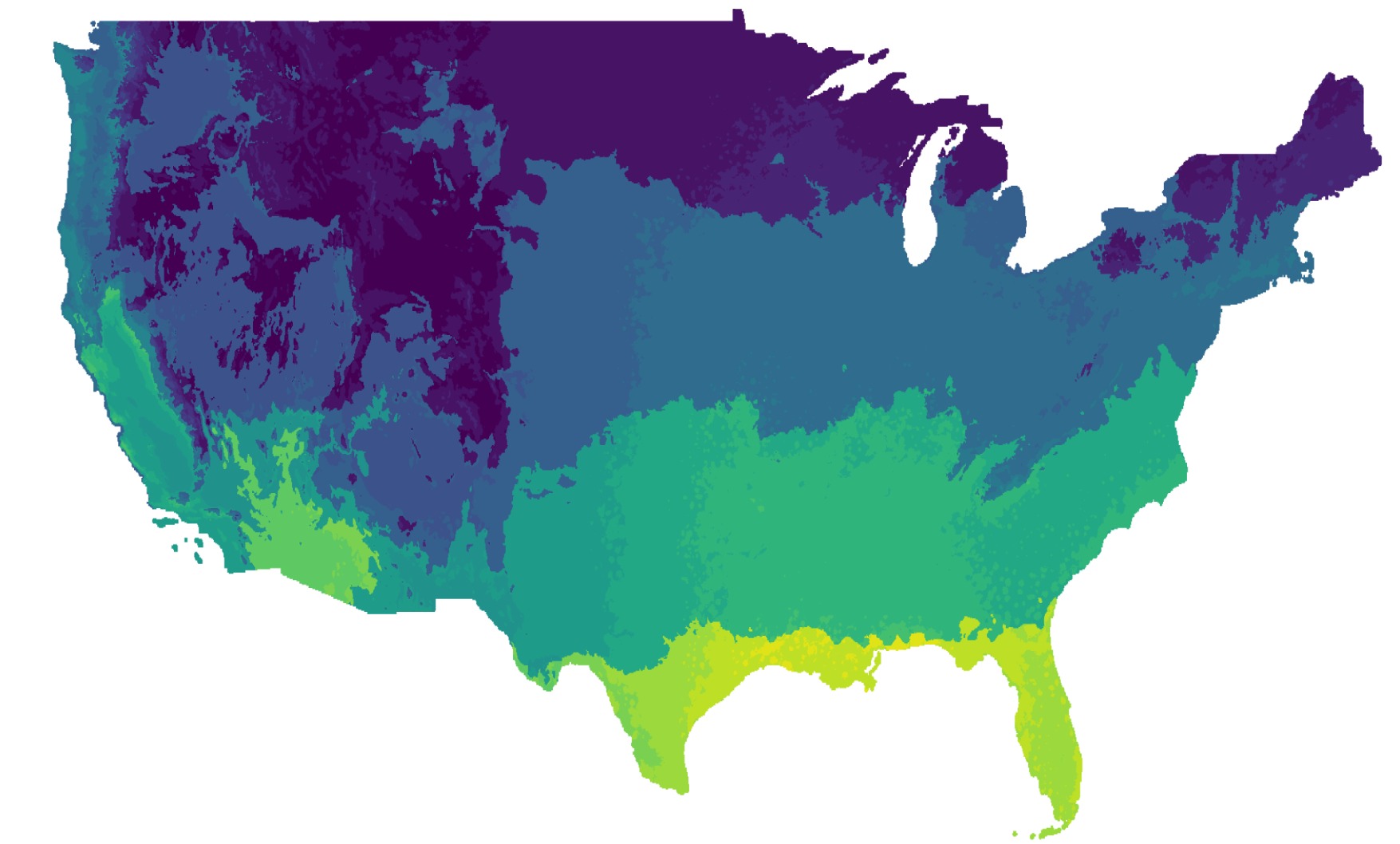
图2:美国大陆的地理区域根据气温和降水数据被划分为20个不同类别。
这一方法通过基于地理空间统计的分层抽样,不仅避免了数据集中常见景观的偏倚,还能够确保数据集在多样性和代表性方面的平衡,为卫星图像预训练提供了一个更为高效和全面的方案。
3.3 预处理程序
在与自然图像或常用遥感基准数据集相比,原始卫星图像的大规模预处理需要额外的工作流程。
HLS数据中可能包含大量云层或无效数据。为了确保高质量的训练数据,我们开发了预处理程序,剔除包含缺失值或云层覆盖的图像。我们使用了与每个HLS图像切片关联的云掩码文件(FMask),它包含每个像素的云层覆盖类别信息(如云、云影、接近云/云影、无数据)。通过云掩码,我们可以确定哪些区域是有效且无云的。
尽管使用云掩码进行图像评估很简单,但由于数据集庞大,这一过程可能变得十分耗时,因此我们无法在训练过程中实时执行该步骤。因此,我们开发了一种离线预处理方法,在训练前完成数据评估和过滤。具体来说,我们将每个HLS切片划分为不重叠的X×Y大小的小区域,然后计算每个小区域中缺失值和云像素的百分比,并定义一个阈值来过滤掉不符合条件的子区域,最后生成一个包含所有有效子图像索引的文件。
为了提高数据预处理效率,我们实现了一个云原生的流水线,可以并行处理多个任务。在数据到达云存储后,我们计算并存储索引文件和训练所需的统计数据(均值和标准差)。
最后一步是将训练数据保存为Zarr格式文件,Zarr格式的优势在于其支持N维数据,并且可以在多个线程或进程中并发地进行读写操作,这使其非常适合用于大规模的预训练任务。我们将这些优质子区域存储在Zarr文件中,并在文件中保存相关信息,如坐标、时间戳等,以便于后续的训练。由于我们的数据集规模庞大,生成Zarr文件的过程可能也会很耗时,因此我们同样开发了一个云原生的方法,能够在多个进程中生成训练数据。通过这种方式,我们能够高效地处理大量卫星图像数据,并为后续的模型训练提供高质量的输入数据。
4. 模型结构和预训练
我们基础模型的预训练基于掩码自编码器(MAE)方法,这是一种成功的自监督学习方法,广泛应用并扩展到不同类型的数据,包括视频和多光谱影像。MAE使用一种不对称的编码器-解码器架构,并结合ViT(视觉变换器)骨干网络来重建掩码图像。在本文中,我们主要关注Prithvi的100M版本,该版本已经在HuggingFace上开源。每个输入图像被划分为大小相同、不重叠的图像块,并随机掩盖其中一部分图像块。编码器仅接收未被掩盖的图像块,生成它们的潜在表示。然后,解码器接收潜在表示和掩码标记,执行图像重建任务。预训练任务是重建掩码标记,损失函数为掩码标记和预测标记在像素空间中的均方误差(MSE),与原始MAE方法一致。
下图中,我们展示了Prithvi中预训练的整体MAE结构。我们对原始MAE进行了修改,以支持具有时间性和多光谱特征的输入。与视频不同,卫星数据可以以不规则且相对较低的频率(按天)获取,并且比RGB图像使用的三个通道有更多的通道。我们对ViT架构的主要修改是3D位置嵌入(3D positional embedding)和3D图块嵌入(3D patch embedding) ,这些是处理时空数据所必需的。我们将在以下部分描述这些修改。
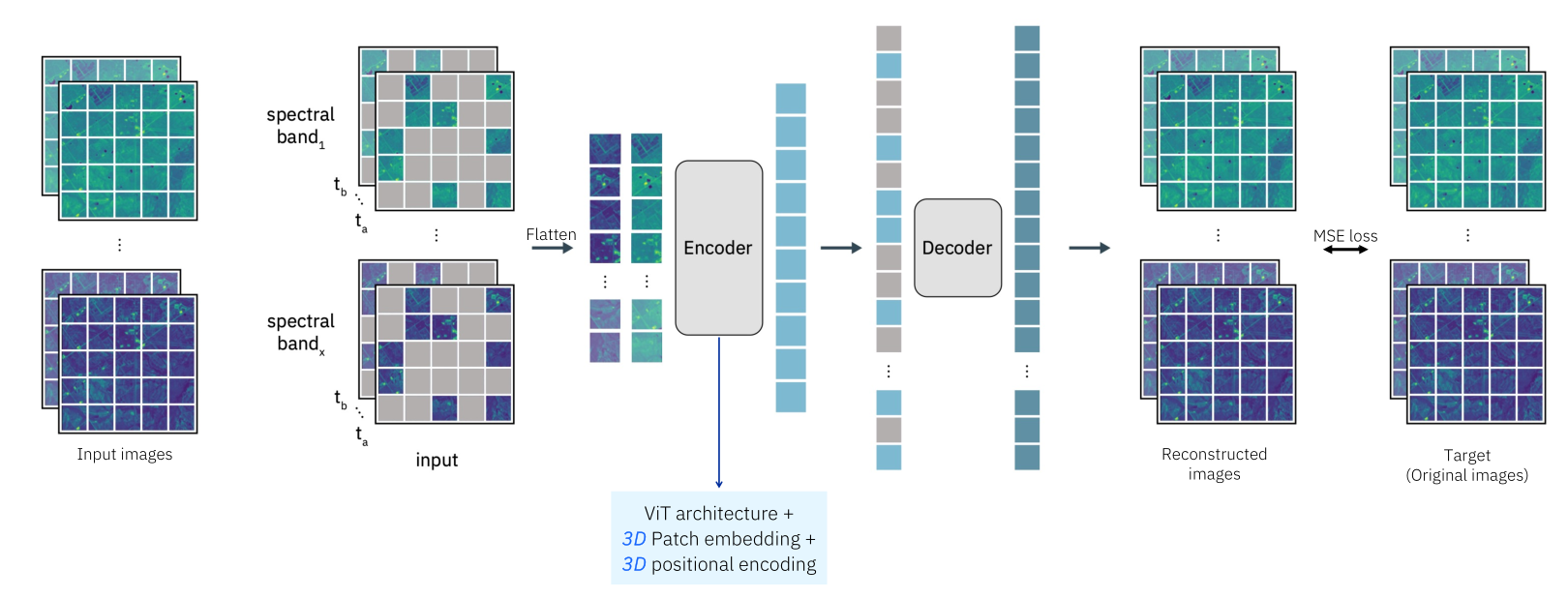
图3::用于在大规模多时态和多光谱卫星图像上进行预训练的掩码自编码器(MAE)结构
4.1 时空数据考虑
在训练地理空间AI模型时,处理3D时空数据是至关重要的。为了有效地应对这一挑战,我们在ViT架构中调整了位置嵌入和图块嵌入。对于3D数据(即二维空间加时间),文献中有几种方法来进行位置编码。例如,某些方法分别为时间和空间维度使用独立的编码,而另一些方法则基于数据的时间戳创建相对时间编码。与这些方法不同,我们提出了一种简单且有效的方法——将原始MAE中的二维正弦余弦位置编码扩展为3D版本。
具体来说,我们首先为高度、宽度和时间分别生成1D的正弦余弦位置编码,然后将这些编码合并成一个3D位置编码。这样可以在时空数据的处理上更加精准。此外,在图块嵌入方面,我们参考了视频处理中的MAE工作(如[54]和[53]),采用了3D图块嵌入的方法。与创建每个时间步长的2D图块并将其按顺序堆叠不同,我们将3D输入数据划分为不重叠、大小相等的数据立方体,并专门利用3D卷积来处理这些数据。为了适应数据的较低频率,我们在实现中将管道大小(即时间维度上的大小)设置为1。
这种方法使得我们能够更好地捕捉时空数据中的空间和时间关系,为地理空间AI模型的训练提供了更加高效和精准的处理方式。
4.2 预训练
在训练大规模时空数据时,数据加载成为了一个显著的瓶颈。为了有效解决这一问题,我们使用了AdamW优化器,参数设置为β1=0.9、β2=0.999,批量大小为1024,采用一周期余弦学习率调度器,最大学习率为5e-4。实验中,我们使用了ViT-base和ViT-large作为模型骨干,并对其进行了1000轮训练。输入图像大小为224×224,补丁大小为1×16×16(时间×x×y),并使用了六个HLSL30波段进行预训练,分别为B02、B03、B04、B05、B06和B07。
所有的预训练都在IBM WatsonX平台上进行,使用了最多64个NVIDIA A100 GPU。重要的是,当处理大规模时空数据时,数据加载往往成为训练过程中的瓶颈,因为每个样本的大小远远大于单词标记,且整体数据量也非常庞大。传统的数据加载方法可能会影响训练效率并限制GPU的使用。
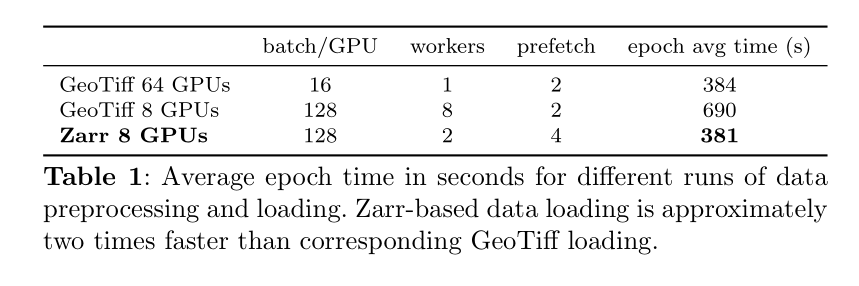
为了优化数据加载,我们采用了Zarr文件格式保存训练数据,并结合PyTorch的DataLoader、xarray和dask进行数据加载。这种方法通过仅存储过滤后的样本,减少了传输到训练环境的数据量,从而提高了数据加载效率。实验结果表明,使用这种方法,我们的Zarr加载方案显著提高了数据加载速度,并且在8个GPU上使用四分之一的工人数量时,训练周期时间减少了超过40%。相比之下,GeoTiff加载方法需要打开多个文件并构建样本,Zarr加载速度更快。我们的数据加载方案为大规模地理空间基础模型的预训练提供了有力支持。
总结来说,采用优化的数据加载方案,不仅提升了训练效率,还为大规模地理空间模型的预训练提供了可行的解决方案,充分发挥了GPU的计算能力。
4.3 预训练结果
在本文中,我们展示了预训练过程中重建损失的变化,具体如图5a所示。总体来看,损失在训练过程中呈现一致的收敛趋势,其中损失峰值可归因于学习率更新。模型最终实现了最低的训练均方误差(MSE)损失为0.0283,并且验证损失为0.0364。在预训练阶段,模型通过学习输入数据中的遮挡像素,掌握了如何重建这些缺失的部分。
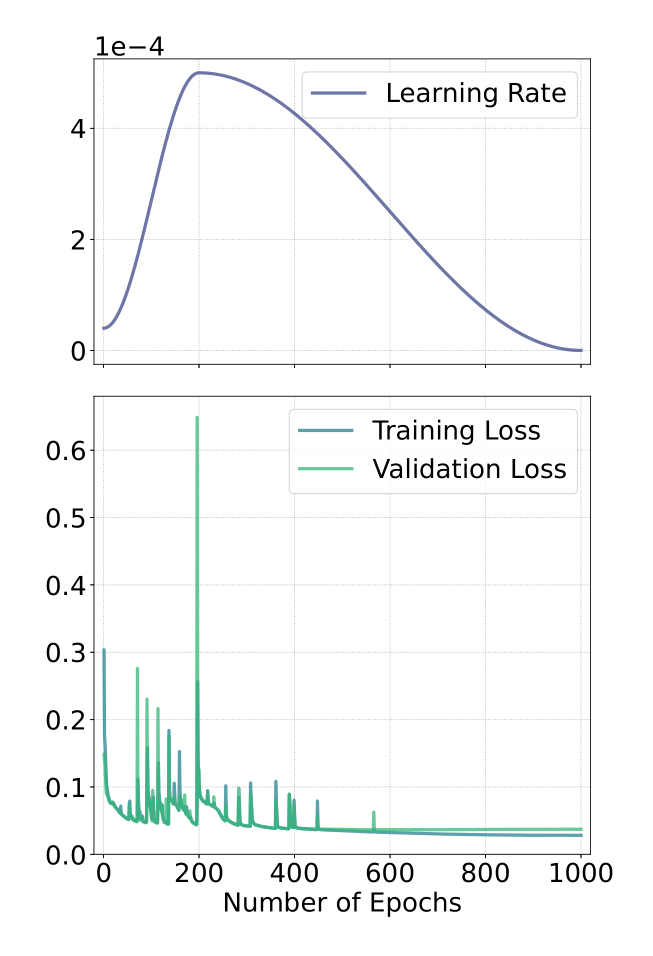
图5a:在预训练过程中,MSE训练和验证损失曲线,同时展示了与学习率调度器相关的值。训练损失降低至0.0283,验证损失最低为0.0364。
为了验证预训练的效果,我们通过图5b和图5c展示了对测试数据(即未见区域)的重建可视化结果。在图5b中,我们特别关注重建过程中的时间维度。通过观察图像中在三个时间步(如右上角的圆形区域)发生变化的部分,我们发现,尽管该圆形区域在三个时间步中大部分被遮挡,模型依然能够成功预测出该区域在t2时刻的颜色变化,从而验证了模型在时间重建方面的能力。

图5b:使用Prithvi模型和ViT-base骨干网络对在训练过程中未见过的图像(不同位置)进行重建结果。在这里,我们将RGB波段(分别为B04、B03和B02)一起展示,以便更好地进行可视化,尽管模型也能预测B05、B06和B07波段。
此外,在图5c中,我们展示了不同遮挡比例对重建结果的影响。当输入图像的一半被随机遮挡时,模型依然能够高精度地重建像素。随着遮挡比例的增加,重建能力有所下降。然而,即便在输入图像有90%被遮挡的情况下,围绕可见像素的重建仍然非常准确,例如在第三列图像的右下角区域。总体而言,模型在RGB波段和红外波段的重建表现出色,并且能够在不同遮挡比例和时间变化的情况下完成任务。

图5c:使用Prithvi模型对在训练过程中未见过的图像(不同位置)进行重建结果,展示了ViT-base骨干网络在不同遮挡比例下对B06和B07波段的重建效果。在这里,我们展示了一个输入图像的单个时间步,该图像在训练过程中未见过。
5. 下游任务
我们利用预训练的基础模型进行多个下游任务的应用。本文主要聚焦于多时相云隙填补、洪水范围分割、野火痕迹分割和多时相作物分割任务。接下来,我们将介绍这些任务及其基础数据,并重点讲解如何将预训练的MAE模型应用于下游任务。
5.1 任务微调数据集
1)多时相云间隙填补:使用来自Harmonized Landsat-Sentinel 2 (HLS) 数据集的影像,覆盖了美国本土的224x224像素区域,具有30米的空间分辨率和六个光谱波段,结合三个时相的数据。每个影像都经过了严格的云覆盖检查,确保每个时相的云覆盖率低于5%。最终的数据集包含了7,852个图像块,适用于基于时间序列的图像填补任务。
2)洪水映射:使用Sen1Floods11数据集,该数据集结合了Sentinel-1和Sentinel-2的影像,并且提供了涵盖世界各地的多个洪水事件的遥感数据。该数据集包括了4,831个512x512像素的图像块,广泛覆盖了120,406平方公里的区域,用于训练和评估全卷积神经网络(FCN)模型,进行洪水水体的分类。
3)野火痕迹映射:利用Monitoring Trends in Burn Severity (MTBS) 历史火灾数据库,从2018年至2021年的火灾数据中选择了相关的HLS影像,用于识别和分析野火的痕迹。数据集中包括了805个符合特定标准的图像块,通过结合火灾形状文件和云层检测,确保影像的有效性和准确性。
4)多时相作物分割:通过Sentinel卫星获取了2022年美国本土的作物分类影像数据,每个影像包括了18个波段,并且采用了来自美国农业部作物数据层(CDL)的作物分类标签。数据集的目标是训练地理空间机器学习模型,进行作物类型的精确分割。
5.2 微调模型设置
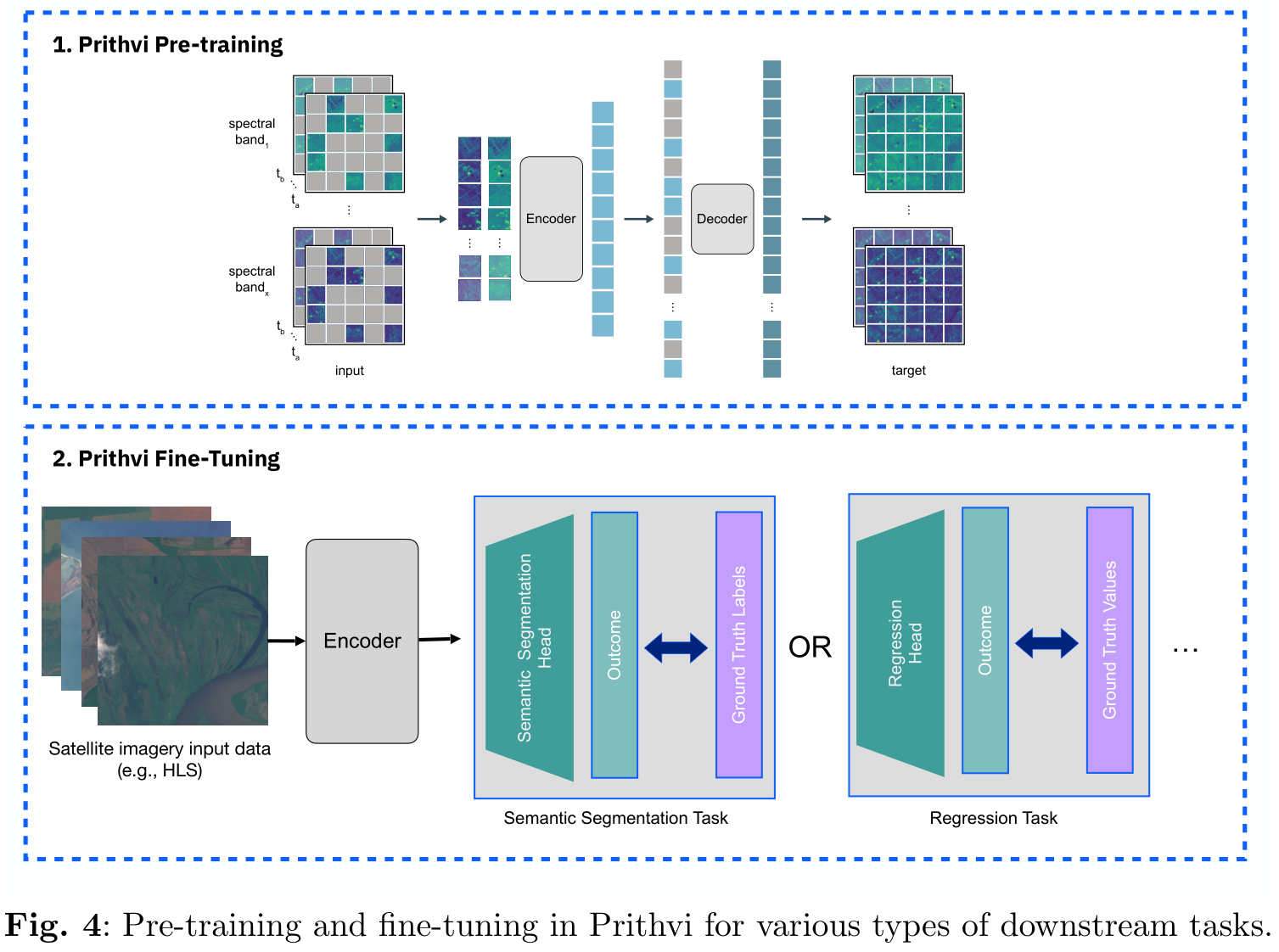
如图4,在遥感图像分析任务中,我们的模型采用了基于掩码自编码器(Masked Autoencoder)的预训练方案,旨在通过编码器特征来重建被掩盖的输入图像。为了适应具体任务,我们在模型的微调模块中,保留了预训练的编码器权重,并针对特定任务学习了解码器权重。该微调模块基于Pytorch框架,且构建在mmsegmentation库之上,后者原生支持语义分割任务。在处理复杂的时空遥感数据时,我们对mmsegmentation进行了扩展,增强了其处理时空数据的功能,并定制了适用于回归和分类等其他任务的操作。本文主要集中在增强版库的语义分割能力上。
在任务特定的解码器设计中,我们提出了一种轻量化的架构便于微调。具体而言,解码器采用由四个ConvTranspose2D层组成的颈部(neck)结构,最终通过一个二维卷积层来输出结果。我们在多个试验的基础上确定了微调的超参数。在最终的实验中,针对不同任务,我们设置了不同的训练批次大小、学习率以及训练周期数。例如,针对洪水映射任务使用的批次大小为4,训练周期为60,学习率为6e-5;而针对野火痕迹任务,则使用批次大小为4,训练周期为50,学习率为1.3e-5;对于多时相作物分割任务,批次大小为8,训练周期为80,学习率为1.5e-5。此外,我们在洪水映射和多时相作物分割任务中使用了加权交叉熵损失以解决类别不平衡问题,而野火痕迹任务则采用了无权重的Dice损失。
对于云插补任务,我们对Prithvi模型的预训练过程进行了适应,利用输入的云掩膜进行推理,并在没有解码器的情况下微调预训练的编码器。在此任务的微调实验中,我们使用了批次大小16、学习率1e-4,并在最多200个周期内进行训练,损失函数选择了均方根误差(RMSE)。我们通过RMSE、**平均绝对误差(MAE)和结构相似性指数(SSIM)**等指标来评估插补性能。
5.3 微调任务结果
5.3.1 云插补任务
在云插补任务中,Prithvi 100M模型的编码器进行了修改,使其能够接受中间时间步的输入掩码,而非随机掩码。这一改进使得模型能够更精确地预测图像中被云层遮挡的部分。
为了对比效果,研究者使用了基于Pix2Pix模型修改过的条件生成对抗网络(CGAN)作为基准模型。该网络通过接受三个时间步的已知像素值,并以此为条件生成缺失的像素。在训练过程中,采用了卷积多尺度补丁鉴别器,其损失函数仅对包含云像素的补丁进行计算。此外,均方误差(MSE)损失只计算掩盖像素的部分,并与鉴别器的铰链损失一起优化生成器。
在实验中,研究者首先将1621个图像块预留作为验证集,确保实验数据的统一性。接下来,分别在多个子集(如6231、3200、1600等图像块)上进行训练,并对结果进行了比较。实验结果表明,Prithvi模型在多个指标上优于CGAN模型,特别是在结构相似性(SSIM)和平均绝对误差(MAE)方面。即使仅使用400个样本进行微调,Prithvi的SSIM也比使用全部样本的CGAN模型高出了1.2%。

图8
在图8a中,经过完整训练数据集微调后的Prithvi模型,承担了填补来自验证集图像中间时间步缺失像素的任务。值得注意的是,Prithvi能够在没有任何关于时间步日期信息的前提下,推断出一个中间季节的像素值。这表明,Prithvi模型具有较强的泛化能力,能够在缺失信息的情况下推测出合理的像素值变化。
相比之下,图8b中的CGAN模型,在相同输入条件下,输出结果却显示出其在约束像素值范围方面的不足。CGAN模型的像素值约束不如Prithvi有效,导致其推测出的像素值偏离合理的范围。通过对比两者的像素值范围和光谱波段关系,可以明显看出Prithvi在精确度和可靠性上优于CGAN模型。
这一结果进一步证明,Prithvi模型在处理云gap插补任务时,无论是对像素值的推测还是对季节性变化的适应性,都具备了更强的表现和更高的精度。这些优势使得Prithvi在实际应用中,比CGAN模型更具实用性和稳定性。
5.3.2 洪水映射任务
在本文中,我们展示了Prithvi模型在不同分辨率的S2数据(10米)上的性能和数据效率实验结果。图9a的实验表明,利用30米分辨率的HLS数据进行预训练,能够显著加速Prithvi在10米分辨率数据上的微调过程,与没有预训练的同一架构相比,预训练的Prithvi在进行洪水映射任务时,微调速度明显更快。在初步实验中,我们发现,预训练的模型在微调25个epoch后超越了ViT-base模型(见表2),而随机初始化权重的相同架构则需要50个epoch才能达到相同的表现。这表明,通过预训练,Prithvi能够在微调时加速性能提升,速度是未预训练模型的两倍以上。整体来说,图9a中的实验结果表明,尽管微调使用的是全球洪水事件数据,但在美国本土数据上进行的预训练显著提升了模型的准确性,这也进一步强调了Prithvi的泛化能力。此外,我们的研究结果还表明,Prithvi模型在处理不同分辨率数据时的适应能力,尤其是在从30米的预训练分辨率过渡到10米的微调分辨率时,依然能够有效地保持性能。
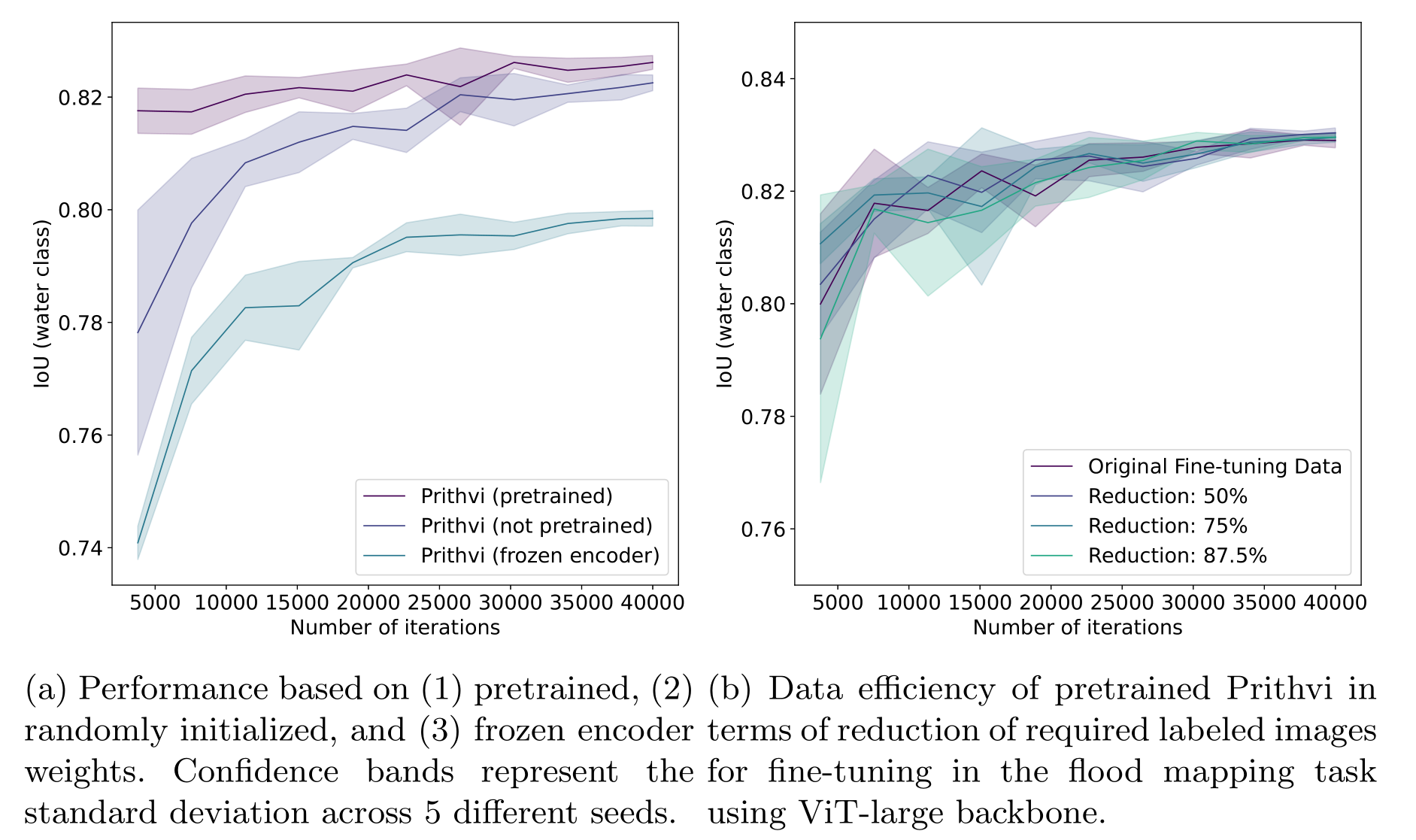
在图9b中,我们展示了Prithvi如何在显著减少标注图像数量的情况下,仍能保持良好的性能。在我们的实验中,我们将微调时使用的标注图像数量从252张减少到126张,结果发现,减少图像数量后,模型的性能与使用全量标注图像时几乎没有差别。具体来说,126张图像覆盖了11个地理区域,每个区域约有11张标注图像。即便我们将标注图像数量进一步减少约90%,模型仍然能够在平均IoU超过80%的情况下收敛。
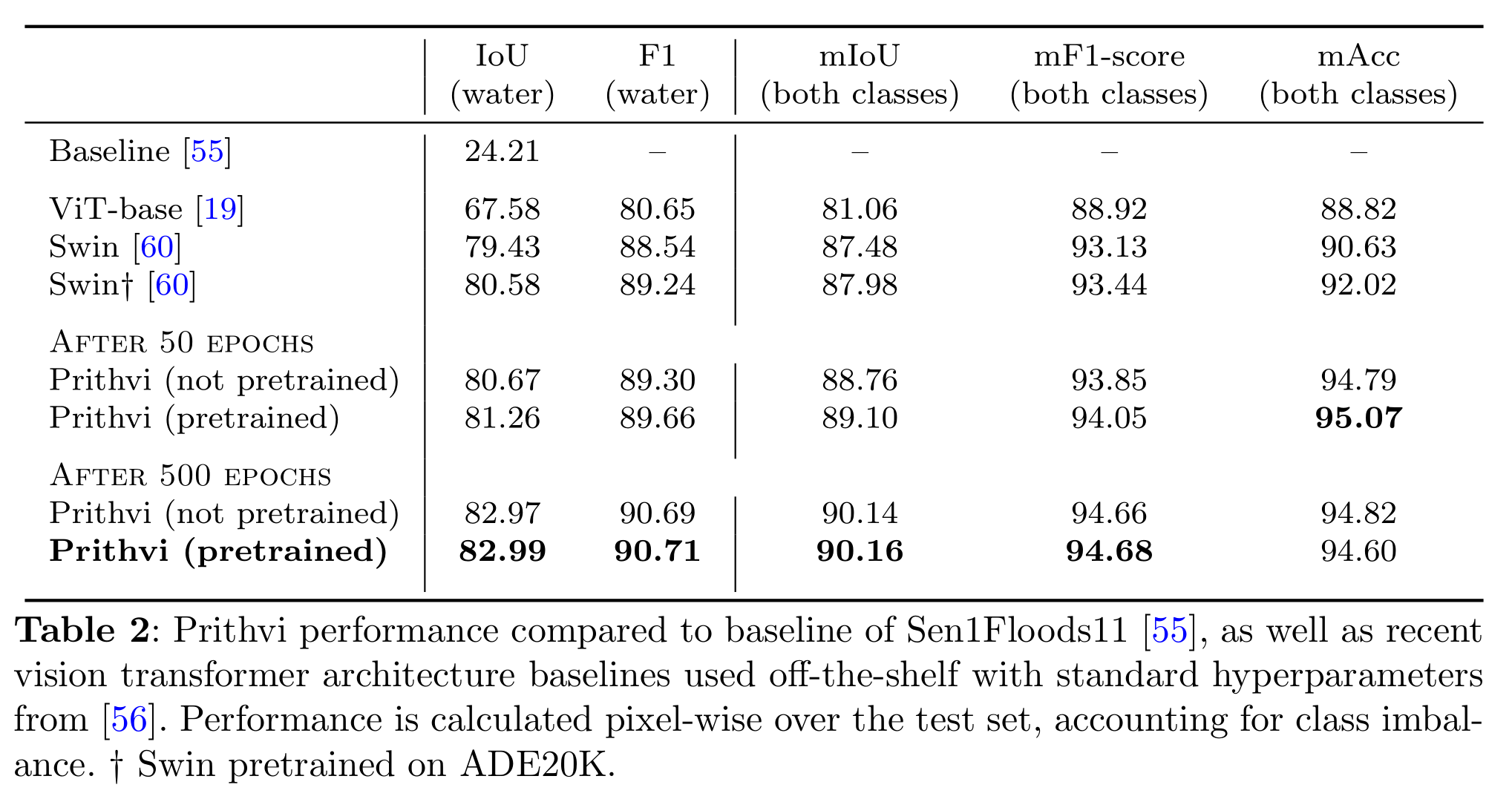
在表2中,我们将Prithvi在洪水映射任务中的表现与[55]中的基准模型以及最新的现成Vision Transformer架构(如ViT和Swin,基于[56]中提出的标准参数)进行了对比。在经过50个epoch的微调后,Prithvi在水体类别上的IoU为81.26,超过了基准模型以及ViT、Swin等现成模型(无论是随机初始化还是预训练的权重)。Prithvi的最佳表现出现在经过500个epoch的微调后,水体类别的IoU达到了82.99。我们还观察到,经过大量epoch的微调后,预训练和非预训练的Prithvi模型表现逐渐趋于一致,这与我们的预期一致。
总体来看,Prithvi模型在数据效率和训练加速方面展现了显著优势,不仅能在较少的标注数据下取得与全量数据相当的效果,而且通过预训练进一步提升了微调过程的速度和最终性能。
5.3.3 火灾痕迹检测
在野火痕迹的分割任务中,实验结果再次表明,预训练模型相较于未经预训练的同一架构表现更佳,如图10a所示。通过实验,我们还验证了在不更新编码器权重时,模型性能明显下降。这与我们的预期一致,因为模型的解码器部分相对较小。最终,所有模型均表现出稳定的收敛性,其中基于预训练权重的模型收敛速度最快。

在图10b中,我们进一步证实了Prithvi模型在标注数据较少的情况下,依然能够保持一致的良好表现。例如,在微调过程中,我们将标注图像的数量减少至原始数据集的四分之一(即,从540张图像减少到252张,再到135张)。实验结果显示,减少标注数据量后,模型的表现与使用全量数据集、三分之二数据集和一半数据集时的表现相当。这一结果凸显了Prithvi模型在数据稀缺环境下的稳定性。
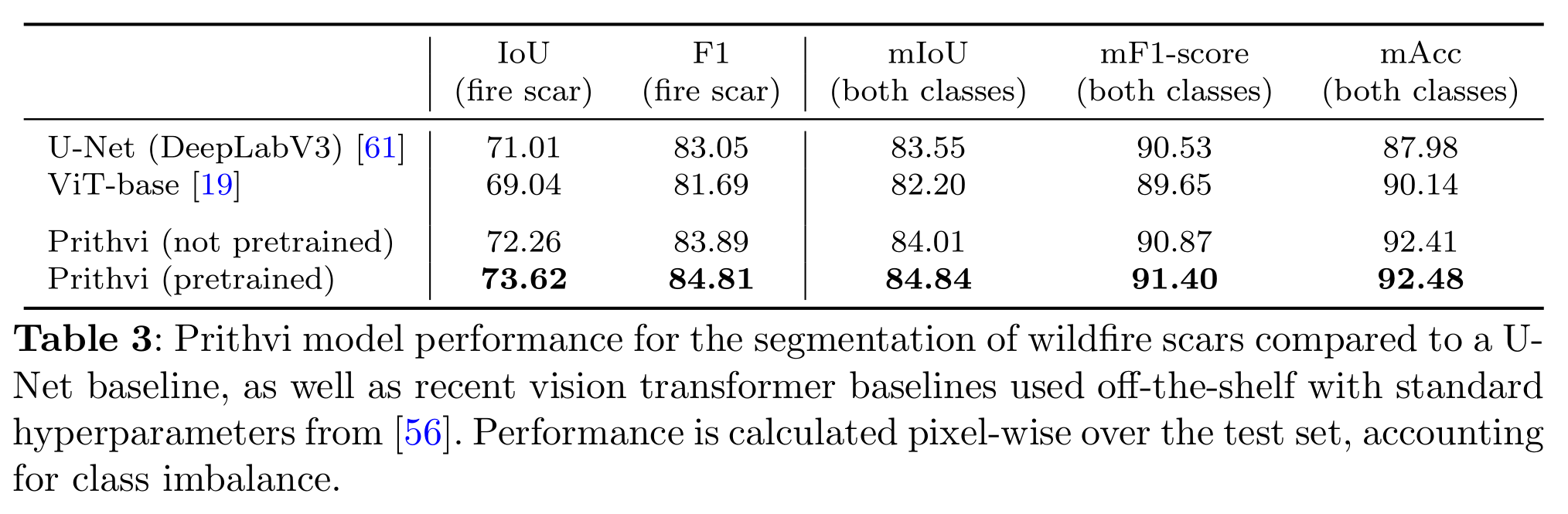
在表3中,我们将Prithvi与基准模型进行了对比。总体来看,经过预训练的Prithvi在性能上超过了随机初始化权重的模型,以及基于U-Net和Transformer的基准模型(使用[56]中提到的标准超参数)。在野火痕迹类别的IoU(交并比)上,Prithvi达到了73.62,超越了基于U-Net的基准模型2.61个百分点,超越基于ViT的基准模型4.58个百分点。虽然整体指标上有所改进,但由于正负类之间存在较高的不平衡(即野火痕迹与土地的类别差异较大),因此整体表现的提升相对较小。Prithvi通过在HLS图块上进行预训练,成功提升了野火痕迹类别的IoU,最高提高了1.36个百分点。
总的来说,Prithvi模型通过预训练和在数据稀缺情况下的表现,展示了其在野火痕迹分割任务中的优势,尤其是在减少标注数据量的同时,依然能够保持稳定的性能表现。
5.3.4 多光谱作物分割
利用高光谱(HLS)数据和作物数据集中的作物标签(CDL)来进行作物和其他土地覆盖类型的分类。模型的输入数据是大小为224x224x18的图像切片,其中224表示图像的高和宽,而18则是通过结合三次时间步的六个光谱波段(包括蓝光、绿光、红光、狭窄近红外(NIR)、短波红外1(SWIR 1)和短波红外2(SWIR 2))得到的。数据集包含13个不同的标签类别。
为了进行对比,我们还使用了原始的U-Net架构,该架构的总下采样率为32倍,并且我们在相同的数据集上对其进行了训练。为了增强训练数据,我们还使用了图像翻转和旋转等数据增强技术。在训练过程中,我们采用了Tversky-focal损失函数,并结合了归一化的类别权重,以提高模型对类别不平衡的处理能力。此外,我们使用了具有动量的随机梯度下降(SGD)优化算法,并结合了Sharpness-Aware Minimization (SAM)框架来进一步优化模型性能,同时应用了多项式学习率衰减策略,以确保学习率逐渐减少,促进模型的更好收敛。
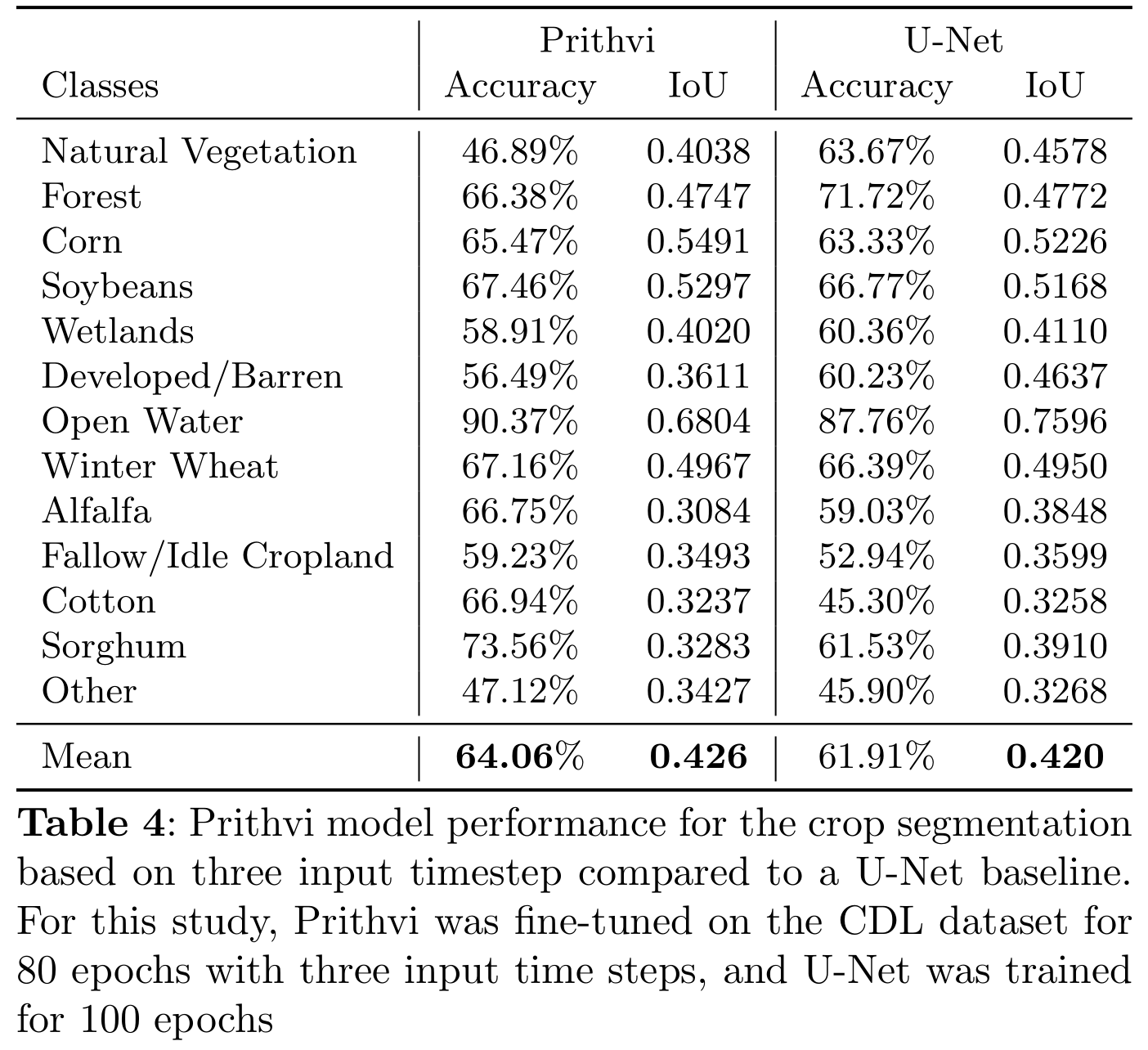
在表4中,我们展示了Prithvi和U-Net在作物分割任务中的性能对比。结果表明,Prithvi在玉米、小麦、苜蓿、休耕/闲置耕地和棉花等类别上表现出了更高的准确率。此外,Prithvi在玉米和大豆类别的交并比(IoU)上也有所提升。总体而言,Prithvi在13个类别的平均准确率为64.06%,而U-Net为61.91%;Prithvi的平均IoU为0.426,U-Net为0.420。尽管两者在IoU分数上差距不大,但Prithvi在一些关键类别的表现上明显优于U-Net,显示了其在作物分割任务中的潜力。
6. 讨论
这篇研究论文展示了在地质科学领域中,尤其是在遥感应用方面,基础模型的潜力和多样性。遥感任务通常需要大量标注数据,但获取这些数据往往面临数据冗余或分布不平衡等问题。近年来,越来越多的研究开始利用自监督学习的概念来解决这一瓶颈。然而,迄今为止,还没有大规模的模型能够处理原始卫星影像,特别是在云层覆盖以及数据采样和加载的效率问题上。为了解决这些挑战,我们设计了一种创新的数据准备管道,专门用于预训练阶段。该管道包括收集HLS数据集用于预训练,并根据统计指标对数据进行分层处理,以促进均匀采样。采样、确保数据平衡以及保持数据质量是成功训练基础模型的关键环节。
此外,在我们的方案中,我们引入了一种自监督学习机制,采用了MAE框架。在这个机制中,我们将75%的数据进行了遮蔽,促使模型尝试恢复这些遮蔽信息。基于这一地理空间基础模型的框架,我们开发了一个紧凑的基础模型,参数量为1亿个,且在多个下游任务上展现出了强劲的性能,特别是在分割和生成任务上,相比现有最先进的模型具有更低的对标注数据数量的敏感性。这证明了基础模型能够在保持高性能的同时,扩展到更多的任务应用,彰显了其在地质科学领域推动机器学习应用发展的巨大潜力。
在预训练阶段,我们对数据采样做出了假设,包括聚焦于美国地区,采用3年的时间步长,且使用一年的数据。尽管与其他模型相比,我们的模型在多个方面表现优秀,但在处理季节性变化时并未显示出显著的提升。Presto是一个自监督的变换器模型,专门用于地理空间任务,特别考虑了时间因素。Presto的目标是实现轻量化计算,因此其参数量较小,少于100万,比Prithvi-100M小了100倍。与Presto不同,Prithvi主要专注于遥感任务,尤其是图像子区域内不同表面的预测,而Presto则更多侧重于利用大范围的像素时间序列,在分类和回归任务上表现出色。
自开源以来,Prithvi已被一些研究者用于他们的研究,特别是在洪水检测方面。通过使用Sen1Floods11数据集,Prithvi在未知地理区域的水类IoU提升了8.6%,展示了基础模型在新任务或未知区域上的优越泛化能力。然而,我们仍然认为在同一分布的数据上,模型性能有进一步提升的空间,未来可能通过多尺度特征的结合来优化这一问题。
通过开源我们的框架和基础模型,我们希望能够加速模型变种的开发,从而解锁更多下游任务,提升模型性能,同时减少所需标注和计算资源。尽管目前的管道主要聚焦于美国地区的数据,以保持计算资源的可控性,但我们已发现,经过微调后,模型具有很强的全球数据泛化能力。未来,我们预计通过使用全球HLS数据进行预训练,模型的性能将进一步提升。尽管我们的模型相对较小,只有1亿个参数,并且仅在美国地区的数据上进行训练,但其在多个下游任务中展现了令人印象深刻的泛化能力。与其他深度学习算法相比,微调和推理所需的数据量明显较少。尽管如此,在一些特定的下游任务中,我们的模型的表现仍未超越最先进的模型,这促使我们探索架构上的改进,并考虑训练一个更大规模的全球模型。目前的模型架构基于3D版本的ViT变换器,我们也期待在未来的工作中探索其他变换器架构,如3D Swin变换器。此外,我们已设计了能够处理未参与预训练的额外波段数据的架构,这一部分仍需要进一步实验。最后,我们对模型在高分辨率卫星影像(即分辨率小于10米)的表现也非常感兴趣。
7. 总结
基础模型可以被视为具有多种功能的工具,既有优点,也有局限性。期望它们在所有应用领域的表现都超过最先进的模型是不明智的。然而,在标注数据有限的领域,它们无疑表现出色。我们的框架促进了大规模地理空间基础模型的开发,例如Prithvi。我们的实验表明,基于对HLS数据的大规模自监督预训练,Prithvi在精度、微调速度和数据效率方面表现优异。值得注意的是,Prithvi能够在微调过程中,通过少量标注数据,对来自全球不同分辨率和地理区域的数据进行良好的泛化。
8. 个人总结
本文提出Prithvi——首个专为地球观测设计的地理空间基础模型(GFM),通过自监督学习在超1TB NASA HLS多光谱卫星影像上预训练,并针对云隙填补、洪水制图、野火痕迹分割、多时相作物分类等任务进行高效微调。其核心创新包括:
1)架构设计:基于掩码自编码器(MAE) 的ViT模型,引入3D位置编码处理时空数据,支持不规则时间序列与多光谱波段83;
2)数据优化:开发分层采样策略解决地理数据冗余问题,利用Zarr格式实现高效云原生预处理,提升训练速度40%6;
3)性能突破:在云隙填补任务中,SSIM指标超越条件GAN 5.7%,重建误差降低15%1;洪水制图任务仅需10%标注数据即可达80% IoU,微调速度提升2倍58;多时相作物分类平均准确率64.06%,关键作物类别(玉米、棉花)IoU显著优于U-Net26;
4)泛化能力:预训练权重使模型在跨区域(如非洲洪水)、跨分辨率(30m→10m) 任务中保持高精度,验证了GFM的强适应性38。
模型已开源至Hugging Face平台,为地球科学社区提供可扩展的AI工具链,推动灾害响应、农业管理等应用的低门槛部署13。
核心价值:Prithvi 证明了基础模型范式能显著缓解地学领域标注数据稀缺、任务泛化性差的瓶颈,为全球可持续发展目标(如SDGs)提供高效技术基座。