【动手学机器学习】第三章模式识别与机器学习经典算法——k 近邻算法
前言
本章先来讲解k 近邻算法——最简单的机器学习算法,从中展开机器学习的一些基本概念和思想。或许有的读者会认为机器学习非常困难,需要庞大的模型、复杂的网络,但事实并非如此。
相当多的机器学习算法都非常简单、直观,也不涉及神经网络。本章就将介绍一个最基本的分类和回归算法:k 近邻(k-nearest neighbor, KNN)算法。
KNN 是最简单也是最重要的机器学习算法之一,它的思想可以用一句话来概括:“相似的数据往往拥有相同的类别”,这也对应于中国的一句谚语:“物以类聚,人以群分”。
具体来说,我们在生活中常常可以观察到,同一种类的数据之间特征更为相似,而不同种类的数据之间特征差别更大。例如,在常见的花中,十字花科的植物大多数有 4 片花瓣,而夹竹桃科的植物花瓣大多数是 5 的倍数。虽然存在例外,但如果我们按花瓣数量对植物做分类,那么花瓣数量相同或成倍数关系的植物,相对更可能属于同一种类。
下面,本章将详细讲解并动手实现 KNN 算法,再将其应用到不同的任务中去。
KNN 算法的原理
在分类任务中,我们的目标是判断样本的类别。
KNN 首先会观察与该样本点距离最近的个样本,统计这些样本所属的类别。然后,将当前样本归到出现次数最多的类中。我们用 KNN 算法的一张经典示意图来更清晰地说明其思想。

如图所示,假设共有两个类别的数据点:蓝色圆形和橙色正方形,而中心位置的绿色样本当前尚未被分类。根据统计近邻的思路:
- 当K=3时,绿色样本的个近邻中有两个橙色正方形样本,一个蓝色圆形样本,因此应该将绿色样本点归类为橙色正方形。
- 当K=5时,绿色样本的个近邻中有两个橙色正方形样本,三个蓝色圆形样本,因此应该将绿色样本点归类为蓝色圆形。
从这个例子中可以看出,KNN 的基本思路是让当前样本的分类服从邻居中的多数分类。但是,当的大小变化时,由于邻居的数量变化,其多数类别也可能会变化,从而改变对当前样本的分类判断。因此,决定的大小是 KNN 中最重要的部分之一。直观上来说,当的取值太小时,分类结果很容易受到待分类样本周围的个别噪声数据影响;当的取值太大时,又可能将远处一些不相关的样本包含进来。因此,我们应该根据数据集动态地调整的大小,以得到最理想的结果。
用 KNN 算法完成分类任务
本节将在 MNIST 数据集上应用 KNN 算法,完成分类任务。
MNIST 是手写数字数据集,其中包含了很多手写数字 0~9 的黑白图像,每张图像都由 2828 个像素点组成。读者可以在 MNIST 的官方网站上得到更多数据集的信息。读入后,每个像素点用 1 或 0 表示,1 代表黑色像素,属于图像背景;0 代表白色像素,属于手写数字。我们的任务是用 KNN 对不同的手写数字进行分类。为了更清晰地展示数据集的内容,下面先将前两个数据点转成黑白图像显示出来。此外,把每个数据集都按 8:2 的比例随机划分成训练集(training set)和测试集(test set)。我们先在训练集上应用 KNN 算法,再在测试集上测试算法的表现。
本节中,我们会用到 NumPy 和 Matplotlib 两个 Python 库。NumPy 是科学计算库,包含了大量常用的计算工具,如数组工具、数据统计、线性代数等,我们用 NumPy 中的数组来存储数据,并且会用到其中的许多函数。Matplotlib 是可视化库,包含了各种绘图工具,我们用 Matplotlib 进行数据可视化,以及绘制各种训练结果。本书不会对库中该函数的用法做过多详细说明,感兴趣的读者可以自行查阅官方文档、API 或其他教程,了解相关函数的具体使用方法。
import matplotlib.pyplot as plt
import numpy as np
import os# 读入mnist数据集
m_x = np.loadtxt('mnist_x', delimiter=' ')
m_y = np.loadtxt('mnist_y')# 数据集可视化
data = np.reshape(np.array(m_x[0], dtype=int), [28, 28])
plt.figure()
plt.imshow(data, cmap='gray')# 将数据集分为训练集和测试集
ratio = 0.8
split = int(len(m_x) * ratio)
# 打乱数据
np.random.seed(0)
idx = np.random.permutation(np.arange(len(m_x)))
m_x = m_x[idx]
m_y = m_y[idx]
x_train, x_test = m_x[:split], m_x[split:]
y_train, y_test = m_y[:split], m_y[split:]

下面是 KNN 算法的具体实现。首先,我们定义样本之间的距离。简单起见,我们采用最常用的欧氏距离(Euclidean distance),也就是我们最生活中最常用、最直观的空间距离。
def distance(a, b):return np.sqrt(np.sum(np.square(a - b)))
为了方便,我们将 KNN 算法定义成类,其初始化参数是和类别的数量。每一部分的含义在代码中有详细注释。
class KNN:def __init__(self, k, label_num):self.k = kself.label_num = label_num # 类别的数量def fit(self, x_train, y_train):# 在类中保存训练数据self.x_train = x_trainself.y_train = y_traindef get_knn_indices(self, x):# 获取距离目标样本点最近的K个样本点的标签# 计算已知样本的距离dis = list(map(lambda a: distance(a, x), self.x_train))# 按距离从小到大排序,并得到对应的下标knn_indices = np.argsort(dis)# 取最近的K个knn_indices = knn_indices[:self.k]return knn_indicesdef get_label(self, x):# 对KNN方法的具体实现,观察K个近邻并使用np.argmax获取其中数量最多的类别knn_indices = self.get_knn_indices(x)# 类别计数label_statistic = np.zeros(shape=[self.label_num])for index in knn_indices:label = int(self.y_train[index])label_statistic[label] += 1# 返回数量最多的类别return np.argmax(label_statistic)def predict(self, x_test):# 预测样本 test_x 的类别predicted_test_labels = np.zeros(shape=[len(x_test)], dtype=int)for i, x in enumerate(x_test):predicted_test_labels[i] = self.get_label(x)return predicted_test_labels
最后,我们在测试集上观察算法的效果,并对不同的的取值进行测试。
for k in range(1, 10):knn = KNN(k, label_num=10)knn.fit(x_train, y_train)predicted_labels = knn.predict(x_test)accuracy = np.mean(predicted_labels == y_test)print(f'K的取值为 {k}, 预测准确率为 {accuracy * 100:.1f}%')
K的取值为 1, 预测准确率为 88.5%
K的取值为 2, 预测准确率为 88.0%
K的取值为 3, 预测准确率为 87.5%
K的取值为 4, 预测准确率为 87.5%
K的取值为 5, 预测准确率为 88.5%
K的取值为 6, 预测准确率为 88.5%
K的取值为 7, 预测准确率为 88.0%
K的取值为 8, 预测准确率为 87.0%
K的取值为 9, 预测准确率为 87.0%
使用 scikit-learn 实现 KNN 算法
Python 作为机器学习的常用工具,有许多 Python 库已经封装好了机器学习常用的各种算法。这些库通常经过了很多优化,其运行效率比上面我们自己实现的要高。
所以,能够熟练掌握各种机器学习库的用法,也是机器学习的学习目标之一。其中,scikit-learn(简称 sklearn)是一个常用的机器学习算法库,包含了数据处理工具和许多简单的机器学习算法。
本节以 sklearn 库为例,来讲解如何使用封装好的 KNN 算法,并在高斯数据集 gauss.csv 上观察分类效果。该数据集包含一些平面上的点,分别由两个独立的二维高斯分布随机生成,每一行包含三个数,依次是点的和坐标和类别。首先,我们导入数据集并进行可视化。
from sklearn.neighbors import KNeighborsClassifier # sklearn中的KNN分类器
from matplotlib.colors import ListedColormap# 读入高斯数据集
data = np.loadtxt('gauss.csv', delimiter=',')
x_train = data[:, :2]
y_train = data[:, 2]
print('数据集大小:', len(x_train))# 可视化
plt.figure()
plt.scatter(x_train[y_train == 0, 0], x_train[y_train == 0, 1], c='blue', marker='o')
plt.scatter(x_train[y_train == 1, 0], x_train[y_train == 1, 1], c='red', marker='x')
plt.xlabel('X axis')
plt.ylabel('Y axis')
plt.show()
数据集大小: 200
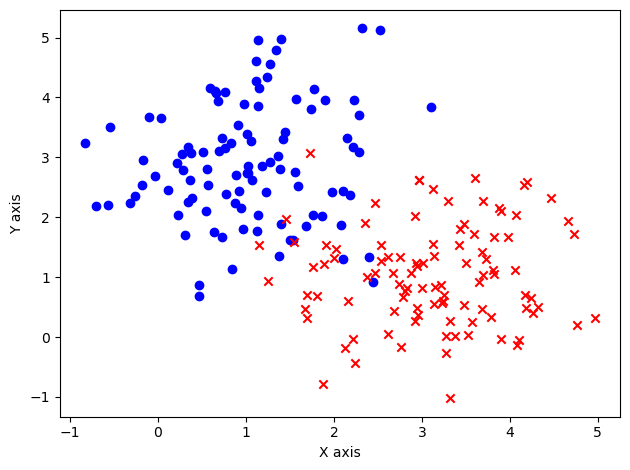
在高斯数据集中,我们将整个数据集作为训练集,将平面上的其他点作为测试集,观察 KNN 在不同的值下的分类效果。因此,我们不对数据集进行划分,而是在平面上以 0.02 为间距构造网格作为测试集。由于平面上的点是连续的,我们无法依次对它们测试,只能像这样从中采样。在没有特殊要求的情况下,我们一般采用最简单的均匀网格采样。这里,我们选用网格间距 0.02 是为了平衡测试点的个数和测试点的代表性,读者也可以调整该数值观察结果的变化。
# 设置步长
step = 0.02
# 设置网格边界
x_min, x_max = np.min(x_train[:, 0]) - 1, np.max(x_train[: