2025年AIR SCI1区TOP,多策略增强蜣螂算法MDBO+实际工程问题,深度解析+性能实测
目录
- 1.摘要
- 2.蜣螂优化算法DBO原理
- 3.改进策略
- 4.结果展示
- 5.参考文献
- 6.代码获取
- 7..算法辅导·应用定制·读者交流

1.摘要
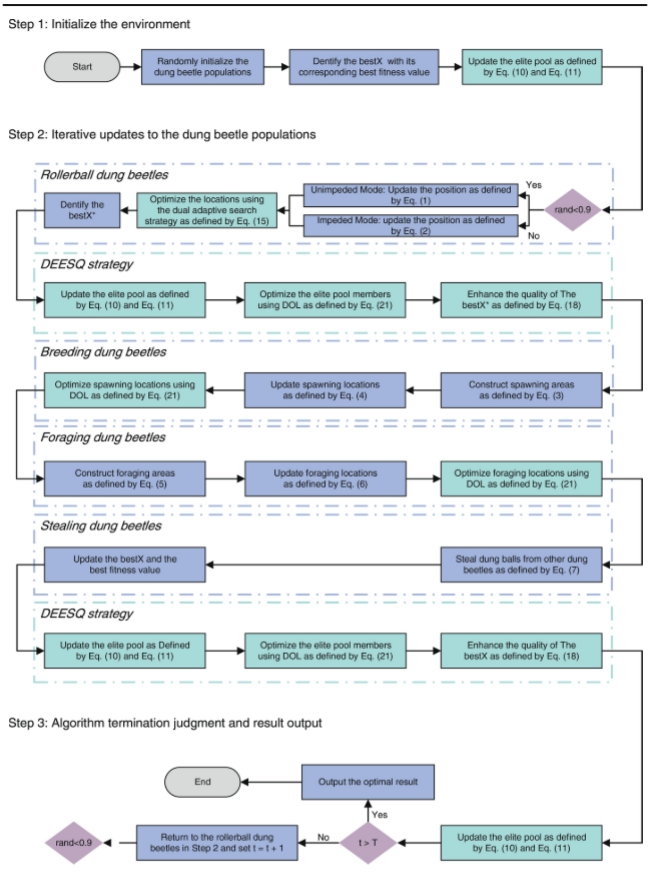
蜣螂优化算法(DBO)作为一种创新元启发式算法,虽具备良好的数值优化能力,但存在收敛速度慢且易陷入局部最优的问题,主要因探索与开发失衡、协同搜索能力不足及群体多样性缺乏所致。为解决这些不足,本文提出了一种基于多策略增强蜣螂优化算法(MDBO),MDBO算法通过自适应调节和精英信息共享,构建搜索-增强-逃逸的协同优化框架,融合双重自适应搜索策略、精英增强解质量机制和动态反向学习,有效提升了群体多样性、协同搜索能力及跳出局部最优的能力,从而实现更高效的全局优化搜索。
2.蜣螂优化算法DBO原理
【智能算法】蜣螂优化算法(DBO)原理及实现
3.改进策略
双重自适应搜索策略
MDBO融入SAO中的双重自适应搜索策略,该策略通过精英个体动态收缩与布朗运动双向交叉扰动强度的自适应调节,有效提升了群体多样性和协同搜索能力,同时实现了探索与利用的动态平衡,显著改善了算法的搜索性能。
MDBO算法中的双重自适应搜索策略通过动态调整领导者质心的收缩幅度和搜索扰动强度,实现对搜索过程的精细控制:
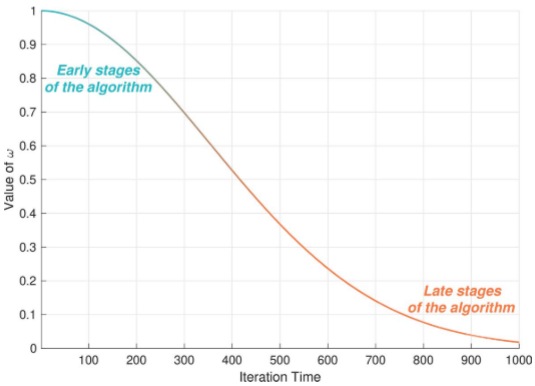
ω = 1 e x p ( ( 2 t T m a x ) 2 ) \omega=\frac{1}{exp((\frac{2t}{T_{max}})^2)} ω=exp((Tmax2t)2)1
领导者质心的自适应收缩机制体现出领导者数量的动态调整特性:在迭代初期,采用高密度领导者分布,形成广域探索的质心,实现全局空间覆盖;在迭代后期,采用领导者数量的非线性衰减策略,使质心逐渐聚焦于全局最优解附近区域,并通过低密度领导者构建局部利用质心,引导精细搜索:
N 1 = N × ω , N 1 ≥ 1 N_1=N\times\omega,\quad N_1\geq1 N1=N×ω,N1≥1
自适应先导质心:
x c = 1 N 1 ∑ i = 1 N 1 x c i x_c=\frac{1}{N_1}\sum_{i=1}^{N_1}x_{ci} xc=N11i=1∑N1xci
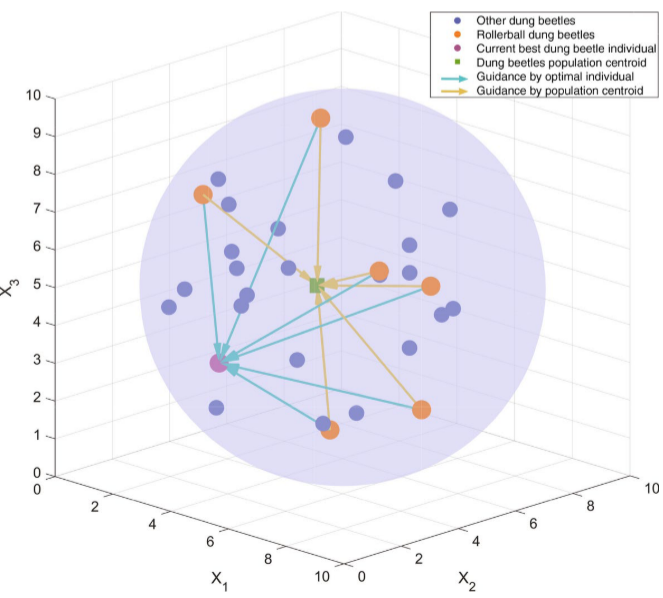
布朗运动双向交叉扰动自适应调节机制,通过非线性加权实现扰动强度的动态平衡:
P T = ω × R B i ⊗ B C T PT=\omega\times RB_i\otimes BCT PT=ω×RBi⊗BCT
其中, P T PT PT为自适应布朗双向交叉摄动机制, R B i RB_i RBi为基于高斯分布表示布朗运动的随机向量, B C T BCT BCT为双向交叉项。
B C T = θ 1 × ( b e s t X − x i ( t ) ) + ( 1 − θ 1 ) × ( x ‾ − x i ( t ) ) BCT=\theta_1\times(bestX-x_i(t))+(1-\theta_1)\times(\overline{x}-x_i(t)) BCT=θ1×(bestX−xi(t))+(1−θ1)×(x−xi(t))
精英增强解质量机制(EESQ)
为提升DBO算法的收敛精度和速度,MDBO引入精英增强解质量机制,EESQ通过引入自适应动态精英池中的高质量个体替代随机生成,解决了传统机制中增强方向随机性过大导致的不稳定问题。EESQ通过计算多名精英个体的均值,为搜索提供更高质量的方向,显著提升了算法的收敛速度和精度,增强了整体优化性能。
x a v g = E r 1 + E r 2 + E r 3 3 , E r 1 , E r 2 , E r 3 ∈ E l i t e P o o l x_{avg}=\frac{E_{r1}+E_{r2}+E_{r3}}{3},\quad E_{r1},E_{r2},E_{r3}\in ElitePool xavg=3Er1+Er2+Er3,Er1,Er2,Er3∈ElitePool
基本候选解生成公式:
x n e w 1 = β ⋅ x a v g + ( 1 − β ) ⋅ x b x_{new1}=\beta\cdot x_{avg}+(1-\beta)\cdot x_b xnew1=β⋅xavg+(1−β)⋅xb
EESQ对其进行两阶段自适应扰动:
x new = { x new 1 + r ⋅ w 1 ⋅ ∣ x new 1 − x avg ∣ + r a n d n , if w 1 < 1 x new 1 + r ⋅ w 1 ⋅ ∣ u ⋅ x new 1 − x avg ∣ + r a n d n , if w 1 ≥ 1 x_{\text{new}} = \begin{cases} x_{\text{new}1} + r \cdot w_1 \cdot \left| x_{\text{new}1} - x_{\text{avg}} \right| + randn, & \text{if } w_1 < 1 \\ x_{\text{new}1} + r \cdot w_1 \cdot \left| u \cdot x_{\text{new}1} - x_{\text{avg}} \right| + randn, & \text{if } w_1 \geq 1 \end{cases} xnew={xnew1+r⋅w1⋅∣xnew1−xavg∣+randn,xnew1+r⋅w1⋅∣u⋅xnew1−xavg∣+randn,if w1<1if w1≥1

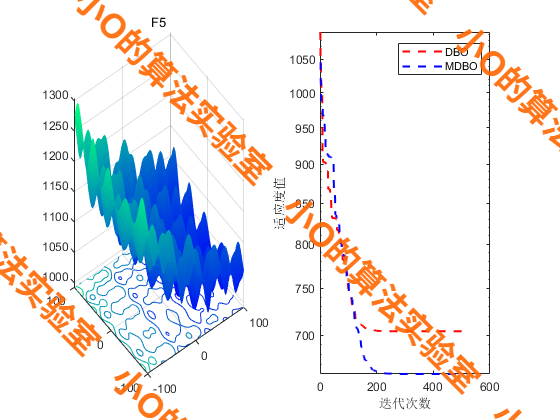
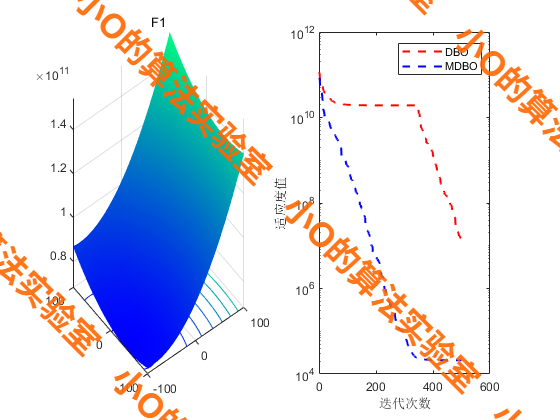
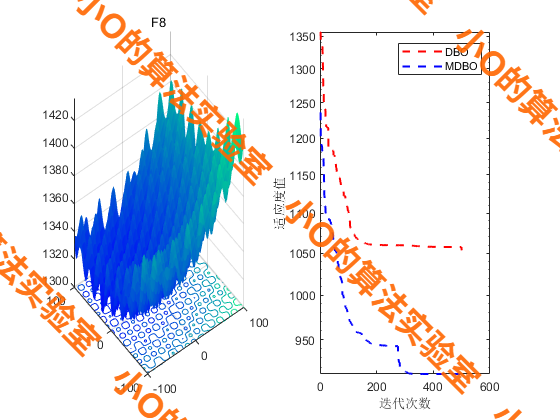
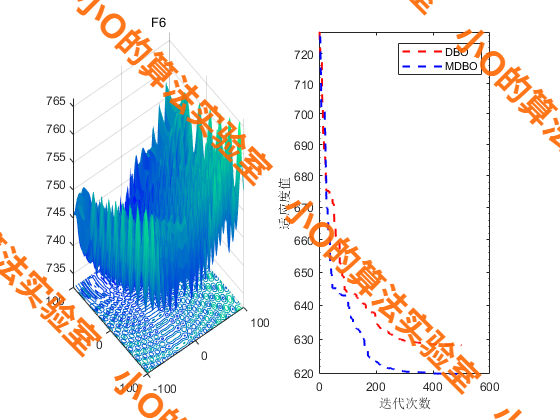
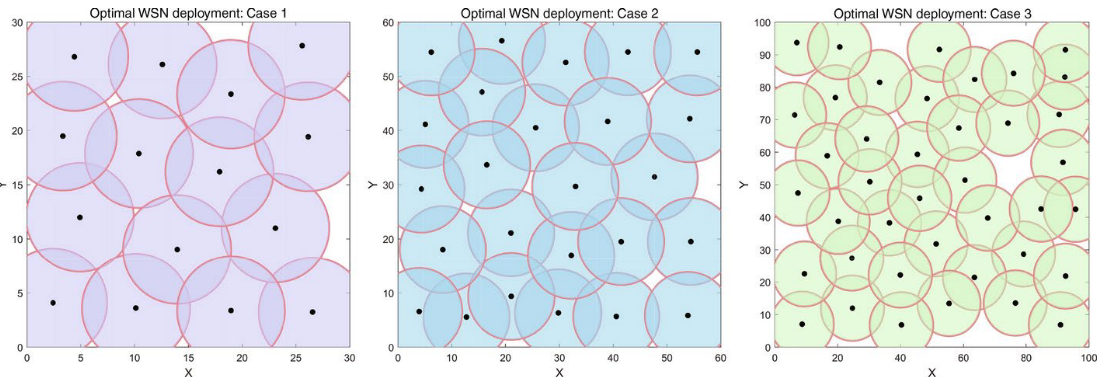
4.结果展示

5.参考文献
[1] Mao Z, Yang Z, Luo D, et al. A multi-strategy enhanced dung beetle algorithm for solving real-world engineering problems[J]. Artificial Intelligence Review, 2025, 58(8): 1-79.