【AI学习从零至壹】基于深度学习的⽂本分类任务
基于深度学习的⽂本分类任务
- 文本分类任务的实现思路
- ⽂本预处理
- 文本分词
- Jieba分词
- 文本分词器SentencePiece
- 训练步骤
- ⽂本结构化转换
- 语料转换为训练样本
文本分类任务的实现思路
⽂本分类就是⼀个将⽂本分配到预定义类别的⼀个过程
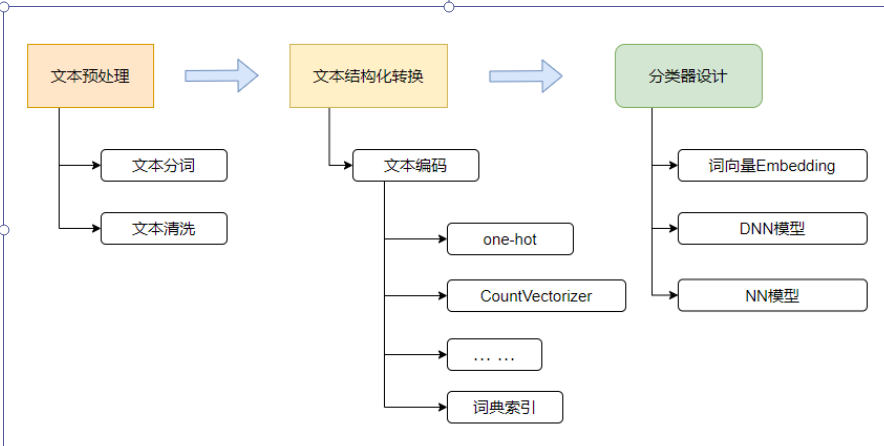
整体流程包括:
- ⽂本语料的获取和预处理
- ⽂本语料的结构化编码
- 分类模型设计及实现
其中的⽂本语料结构化编码是重点,具体实现包括
⽂本语料 → 通过语料创建词典 → 语料转换为训练样本 → 词向量Embedding
⽂本预处理
模型训练的样本,通常会以句(sentence)或段落(paragraph⽅式呈现。所以通常会先进⾏⽂本分词,在⾃然语⾔处理过程中,称为标记(tokenize)。
文本分词
英⽂语料进⾏分词,相对⽐较简单。可以直接通过字符串的 split() 函数来直接拆分使⽤空格分隔开的单词。当然,这种直接的⽅式也存在着⼀些问题。例如:⽂本中的标点符号抽取,连字符的拼接等,也需要注意。
Jieba分词
jieba是⼀款强⼤的Python中⽂分词组件,采⽤MIT授权协议,兼容Python 2/3。它⽀持精确、全、搜索引擎、paddle四种分词模式,还能处理繁体中⽂,⽀持⾃定义词典,应⽤⼴泛。
核心功能
| jieba.cut | 接受字符串,返回可迭代⽣成器 |
|---|---|
| jieba.cut_for_search | ⽤于搜索引擎分词 |
| jieba.lcut() | 直接生成的就是一个list |
import jieba
strs = ["中国人民大学","你好我是谁","甜美"]
for str in strs:seg_list = jieba.cut(str,use_paddle = True)print("paddle Mode: " + '/'.join(list(seg_list)))
seg_list = jieba.cut("我来到北京大学",cut_all = True)
seg_list = jieba.cut("我来到中国人民大学",cut_all = False)
print(",".join(seg_list))
文本分词器SentencePiece
SentencePiece 是⼀种⽆监督的⽂本分词器和去分词器,主要⽤于基于神经⽹络的⽂本⽣成系统,其中词汇量在神经模型训练之前预先确定。 SentencePiece 实现了⼦词单元 subword units(例如,字节对编码 byte-pair-encoding(BPE))和 ⼀元语⾔模型 unigram language model),并扩展了从原始句⼦的直接训练⽅式。 SentencePiece 允许我们制作⼀个纯粹的端到端系统,不依赖于特定于语⾔的预处理/后处理。
需要预定义token的数量
通常情况下,基于神经⽹络的机器翻译模型使⽤的都是固定词汇表。不像绝⼤多数假设⽆限词汇量的⽆监督分词算法SentencePiece训练分词模型是要确保最终词汇量是固定的,例如 8k、16k 或 32k。请注意,SentencePiece 指定了训练的最终词汇量⼤⼩,这与使⽤合并操作次数的 subword-nmt 不同。合并操作的次数是 BPE 特定的参数,不适⽤于其他分割算法,包括 unigram、word 和 character。
通过原始语料训练
以前的分词实现需要输⼊的语句进⾏预标记处理。这种要求是训练确保模型有效性所必需的。但这会使预处理变得复杂,因为我们必须提前运⾏语⾔相关的分词器。 SentencePiece 就是⼀个可以满⾜快速从原始句⼦进⾏训练的模型。这对于训练中⽂和⽇⽂的分词器和分词解码器都很有⽤,因为单词之间不存在明确的空格。
空格被视为基本符号
⾃然语⾔处理的第⼀步是⽂本标记化。例如,标准的英语分词器会分割⽂本“Hello world.ˮ。分为以下三个token。[Hello][World][.]
SentencePiece 将输⼊⽂本视为 Unicode 字符序列。空格也作为普通符号处理。
为了显式地将空格作为基本标记处理,SentencePiece ⾸先使⽤元符号“▁ˮ(U+2581)对空格进⾏转义,如下所⽰。由于空格保留在分段⽂本中,因此我们可以对⽂本进⾏解码,⽽不会产⽣任何歧义。
此功能可以在不依赖特定语⾔资源的情况下执⾏去标记化。 请注意,在使⽤标准分词器拆分句⼦时,我们⽆法应⽤相同的⽆损转换,因为它们将空格视为特殊符号。标记化序列不保留恢复原始句⼦所需的信息。
detokenized = ''.join(pieces).replace('_',' ')
byte-pair-encoding(BPE)
BPE⾸先把⼀个完整的句⼦分割为单个的字符,频率最⾼的相
连字符对合并以后加⼊到词表中,直到达到⽬标词表⼤⼩。对
测试句⼦采⽤相同的subword分割⽅式。BPE分割的优势是它
可以较好的平衡词表⼤⼩和需要⽤于句⼦编码的token数量
训练步骤
分词
模型训练
import sentencepiece as spm
#引入外部文本资料训练分词模型
spm.SentencePieceTrainer.Train(intput = 'hlm_c.txt',model_prefix = 'hlm_mod',vocab_size = 10000)
#加载模型进行分词
sp = spm.SentencePieceProcessor(model_file = 'hlm_mod.model')
print(sp.EncodeAsPieces('我爱北京天安门'))
- 方法参数
- input : 每⾏⼀句的原始语料库⽂件。⽆需预处理。默认情况下,SentencePiece 使⽤ Unicode NFKC 规范化输⼊。还可以传递逗号分隔的⽂件列表
- model_prefix : 输出的模型名前缀。算法最后会⽣成<model_name>.model和<model_name>.vocab两个⽂件。
- vocab_size :词表⼤⼩,类似于8000,16000,32000等值
- character_coverage :模型覆盖的字符数量,良好的默认值:对于具有丰富字符集的语⾔(如⽇语或中⽂)使⽤0.9995;对于其它⼩字符集的语⾔使⽤1.0
- model_type :模型算法类型。从 unigram(默认)、bpe、char 、word 中进⾏选择。使⽤word类型时,输⼊句⼦必须预先标记。
模型训练后还⽣成了⼀个 <model_name>.vocab 的⽂件,⾥⾯包含了指定⼤⼩的词典。
⽂字处理基本单元(token) 字符或词汇不重复字符构建字典
当模型推理过程中,遇到字典中没有包含token时,出现key index错误。Out Of Value(OOV问题)解决思路:通过特殊token ,统⼀替代未知token,通过字典映射,⽂本转换token index
转换值转变模型导⼊数据
数据还需要从⽂本到数值转换,使⽤Dataset封装上⾯处理逻辑
模型结构搭建
token_index →→ embedding →→ rnn →→ linear →→ logits
embedding shape:[batch, token_len, features] 符合 RNN输⼊要求
⽂本结构化转换
分词之后通常会选择下⼀步做的就是构建词典(词汇表 vocabulary)。它包含语料中所有不重复的词汇的集合。
词典(vocabulary)本质上就是⼀个 token ↔ index 的⼀个dict。
class Vocabulary:def __init__(self,vocab):self.vocab = vocabdef from_documents(cls,documents):#字典构建no_repeat_tokens = set()for cmt in documents:no_repeat_tokens.update(list(cmt))tokens = ['PAD','UNK'] + list(no_repeat_tokens)vocab = { tk:i for i,tk in enumerate(tokens)}return cls(vocab)
关于Token
在NLP的语料处理分词环节,因语⾔不同,往往也会产⽣出不同的结果。以东亚语⾔为例(中、⽇、韩):我们既可以把⽂章拆分为“词ˮ,⼜可以把⽂章拆分为“字ˮ。这种结果导致我们在描述分词时往往会让⼈产⽣歧义:到底是“词ˮ还是“字ˮ?
token可以解决这个概念(或者说描述)问题,不论我们拆分的是什么,每个被拆分出的内容,统⼀以token指代。
词汇表中保存的是不重复的token,token_index也就是给每个
token分配的唯⼀索引值。
代码中的 PAD 和 UNK 是在词表中添加的特殊符号。这⾥要解释⼀下NLP中的OOV概念。
关于OOV(Out Of Value )
OOV是指模型在测试或预测中遇到的新词。这些新词在模型已构建的词汇表中并不存在。因此,会导致模型⽅法⽆法识别并处理这些OOV新词。
例如我们的词表是基于标准的汉语词典词汇。当遇到类似“爷⻘
回ˮ,“⼝嗨ˮ,“布吉岛ˮ等新词时,词表⾥⾯没有这样的词,也就
⽆法把新词映射为对应的索引。
语料转换为训练样本
得到了词汇表,我们就把⽂本语料集中的每个样本,统⼀转换为token_index的集合。