【论文笔记】High-Resolution Representations for Labeling Pixels and Regions
【题目】:High-Resolution Representations for Labeling Pixels and Regions
【引用格式】:Sun K, Zhao Y, Jiang B, et al. High-resolution representations for labeling pixels and regions[J]. arXiv preprint arXiv:1904.04514, 2019.
【网址】:https://arxiv.org/pdf/1904.04514
【开源代码】:https://github.com/HRNet
目录
一、瓶颈问题
二、本文贡献
三、解决方案
1. 模型架构
2. 文中修改内容
3. 具体实施
四、实验结果
1. 数据集
1.1 Cityscapes
1.2 PASCAL context
1.3 LIP
1.4 MS-COCO2017
1.5 WFLW
1.6 AFLW
1.7 COFW
1.8 300W
2. 语义分割
3. COCO物体检测
4. 面部关键点检测
5. 实证分析
一、瓶颈问题
- 高分辨率表示的重要性:在语义分割、目标检测等任务中,高分辨率表示对细节(如小物体、像素级标注)至关重要。传统方法(如 FCN、U-Net)通过下采样 - 上采样路径处理分辨率,但可能丢失低分辨率分支的信息。
- 原始 HRNetV1 的局限:仅利用高分辨率卷积的输出特征,丢弃了低分辨率卷积的通道子集,未充分发挥多分辨率卷积的容量。
二、本文贡献
- 提出HRNetv2:通过双线性上采样将低分辨率特征缩放到高分辨率,与高分辨率特征拼接,生成融合所有分辨率的特征表示。避免了分辨率分支的通道信息浪费,提升模型的表征能力。
- 提出HRNetV2p:将高分辨率特征通过平均池化下采样至多个层级,构建类似FPN的多尺度表示,适配目标检测中不同大小物体的识别需求。
- 提出 “跨分辨率全连接 + 双向信息流动” 的卷积模块设计
三、解决方案
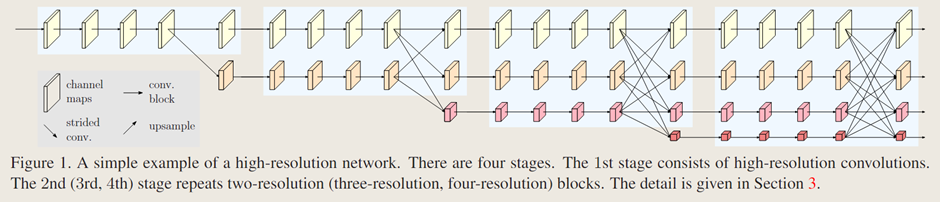
1. 模型架构
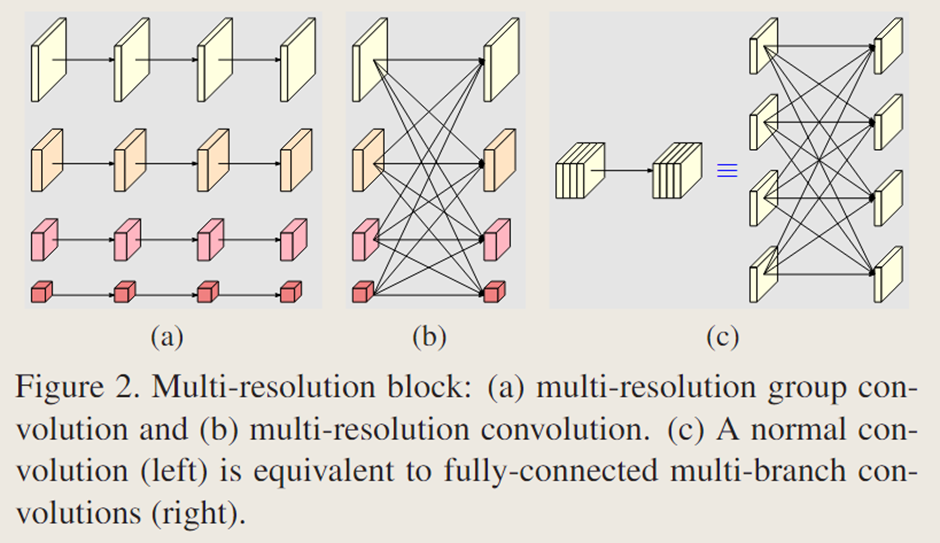
网络模型包含四部分(如图1所示),其中第二、第三和第四阶段由重复的模块化多分辨率块组成。一个多分辨率块包含一个多分辨率组卷积和一个多分辨率卷积,分别如图 2(a)和(b)所示。多分辨率组卷积是组卷积的简单扩展,它将输入通道划分为若干通道子集,并在不同空间分辨率下对每个子集分别进行常规卷积操作。多分辨率卷积如图2(b)所示,它类似于常规卷积的多分支全连接方式,如图 2(c)所示。
模型中分辨率的降低通过若干个步长为2的3×3卷积实现的,分辨率提升则是使用双线性(或最近邻)上采样完成。
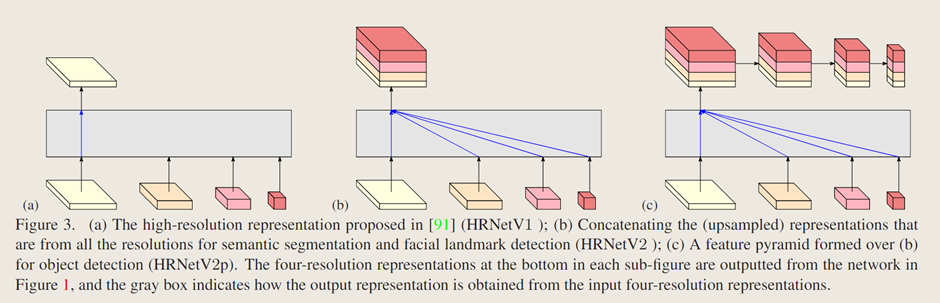
2. 文中修改内容
原始HRNetV1:仅输出高分辨率卷积的表示特征图,如图3(a)所示,低分辨率部分被舍弃。
文中方案:通过双线性上采样将低分辨率表示缩放到高分辨率,并将各表示子集进行拼接,如图3(b)所示。对于目标检测的应用中,文中通过平均池化将高分辨率表示下采样到多个层级,构建多层表示,如图3(c)所示。
3. 具体实施
网络从一个主干模块开始,该模块由两个步长为 3×3 的卷积组成,将分辨率降低至 1/4。第一阶段包含 4 个残差单元,每个单元由一个宽度为 64 的瓶颈结构构成,随后接一个 3×3 卷积,将特征图的宽度降至 c。第二、第三、第四阶段分别包含 1、4、3 个多分辨率块。四种分辨率的卷积宽度(通道数)分别为 c、2C、4C 和 8C。多分辨率组卷积中的每个分支包含 4 个残差单元,且每个单元在每种分辨率下均包含两个 3×3 卷积。
在语义分割和面部关键点检测的应用中,文中通过 1×1 卷积融合来自所有四个分辨率的输出表示(图 3(b)),生成 15C 维的表示。然后,将每个位置的融合表示输入到带有 softmax/MSE 损失的线性分类器 / 回归器中,以预测分割图 / 面部关键点热图。对于语义分割任务,训练和测试时均通过双线性上采样将分割图上采样 4 倍至输入尺寸。在目标检测应用中,文中通过 1×1 卷积将高分辨率表示的维度降至 256(类似于 FPN ),然后再构建图 3(c)中的特征金字塔。
四、实验结果
1. 数据集
1.1 Cityscapes
Cityscapes 数据集包含 5000 张高质量像素级精细标注的场景图像。其中精细标注的图像被划分为 2975 张训练图像、500 张验证图像和 1525 张测试图像。该数据集包含 30 个类别,其中 19 个类别用于评估。除了类别平均交并比(mIoU)外,文中在测试集上还报告了其他三项指标:类别交并比(cat.)、实例类别交并比(cla.)和实例类别交并比(cat.)。
数据增强方式包括随机裁剪(从 1024×2048 裁剪至 512×1024)、在 [0.5, 2] 范围内的随机缩放,以及随机水平翻转。优化器使用 SGD,基础学习率为 0.01,动量为 0.9,权重衰减为 0.0005。学习率衰减采用幂次为 0.9 的多项式策略。所有模型均在 4 块 GPU 上使用同步 BN(syncBN)进行训练,批量大小为 12,迭代 120K 次。
1.2 PASCAL context
PASCAL context 数据集包含 4998 张用于训练的场景图像和 5105 张用于测试的图像,拥有 59 个语义标签和 1 个背景标签。
数据增强和学习率策略与 Cityscapes 相同。遵循广泛使用的训练策略,文中将图像调整为 480×480 大小,设置初始学习率为 0.004,权重衰减为 0.0001。批量大小为 16,迭代次数为 6 万次。
1.3 LIP
LIP数据集包含50,462张经过精心标注的人体图像,其中分为30,462张训练图像和10,000张验证图像。该方法在20个类别上进行评估(19个人体部位标签和1个背景标签)。遵循标准的训练和测试设置,图像被调整为473×473大小,并且性能评估基于原始图像和翻转图像分割图的平均值。
数据增强和学习率策略与 Cityscapes 相同。文中将初始学习率设置为 0.007,动量设置为 0.9,权重衰减设置为 0.0005。批量大小为 40,迭代次数为 11 万次。
1.4 MS-COCO2017
文中在 MS-COCO 2017 检测数据集上进行评估,该数据集包含约 11.8 万张训练图像、5 千张验证图像(val)和约 2 万张未提供标注的测试图像(test-dev)。评估采用标准的 COCO 格式评价方式。
1.5 WFLW
WFLW 数据集是基于 WIDER Face 构建的最新数据集。该数据集包含 7500 张训练图像和 2500 张测试图像,每张图像均标注有 98 个人工关键点。文中在测试集及其多个子集上报告结果,这些子集包括:大姿态(326 张图像)、表情(314 张图像)、光照(698 张图像)、妆容(206 张图像)、遮挡(736 张图像)和模糊(773 张图像)。
1.6 AFLW
AFLW 数据集是一个广泛使用的基准数据集,每张图像包含 19 个面部关键点。文中使用 20,000 张训练图像训练模型,并在 AFLW 全集(4,386 张测试图像)和 AFLW 正面集(从 4,386 张测试图像中选出的 1,314 张测试图像)上报告结果。
1.7 COFW
COFW 数据集包含 1345 张带遮挡的训练人脸图像和 507 张测试人脸图像,每张图像标注有 29 个面部关键点。
1.8 300W
300W 数据集由 HELEN、LFPW、AFW、XM2VTS 和 IBUG 数据集组合而成,每张人脸包含 68 个关键点。文中使用 3148 张训练图像,其中包括 HELEN 和 LFPW 的训练子集以及 AFW 的完整数据集。文中采用两种协议评估性能:完整集和测试集。完整集包含 689 张图像,进一步分为来自 HELEN 和 LFPW 的公共子集(554 张图像)和来自 IBUG 的挑战性子集(135 张图像)。用于竞赛的官方测试集包含 600 张图像(300 张室内图像和 300 张室外图像)。
2. 语义分割
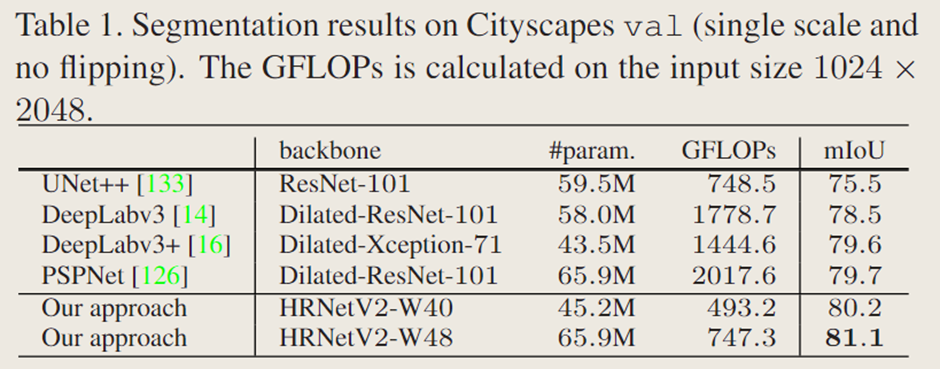
表 1 提供了在参数和计算复杂度以及 mIoU 等级方面与Cityscapes验证集上几种代表性方法的比较。(i) HRNetV2-W40(40 表示高分辨率卷积的宽度)的模型大小与 DeepLabv3+ 相似,计算复杂度更低,但性能更好:比 UNet++ 提升 4.7 分,比 DeepLabv3 提升 1.7 分,比 PSPNet、DeepLabv3+ 提升约 0.5 分。(ii) HRNetV2-W48 的模型大小与 PSPNet 相似,计算复杂度却低得多,因此性能显著提高:比 UNet++ 提高 5.6 个百分点,比 DeepLabv3 提高 2.6 个百分点,比 PSPNet、DeepLabv3+ 提高约 1.4 个百分点。在下面的比较中,文中采用 HRNetV2-W48,它在 ImageNet 3 上经过预训练,模型大小与大多数基于 DilatedResNet-101 的方法相似。
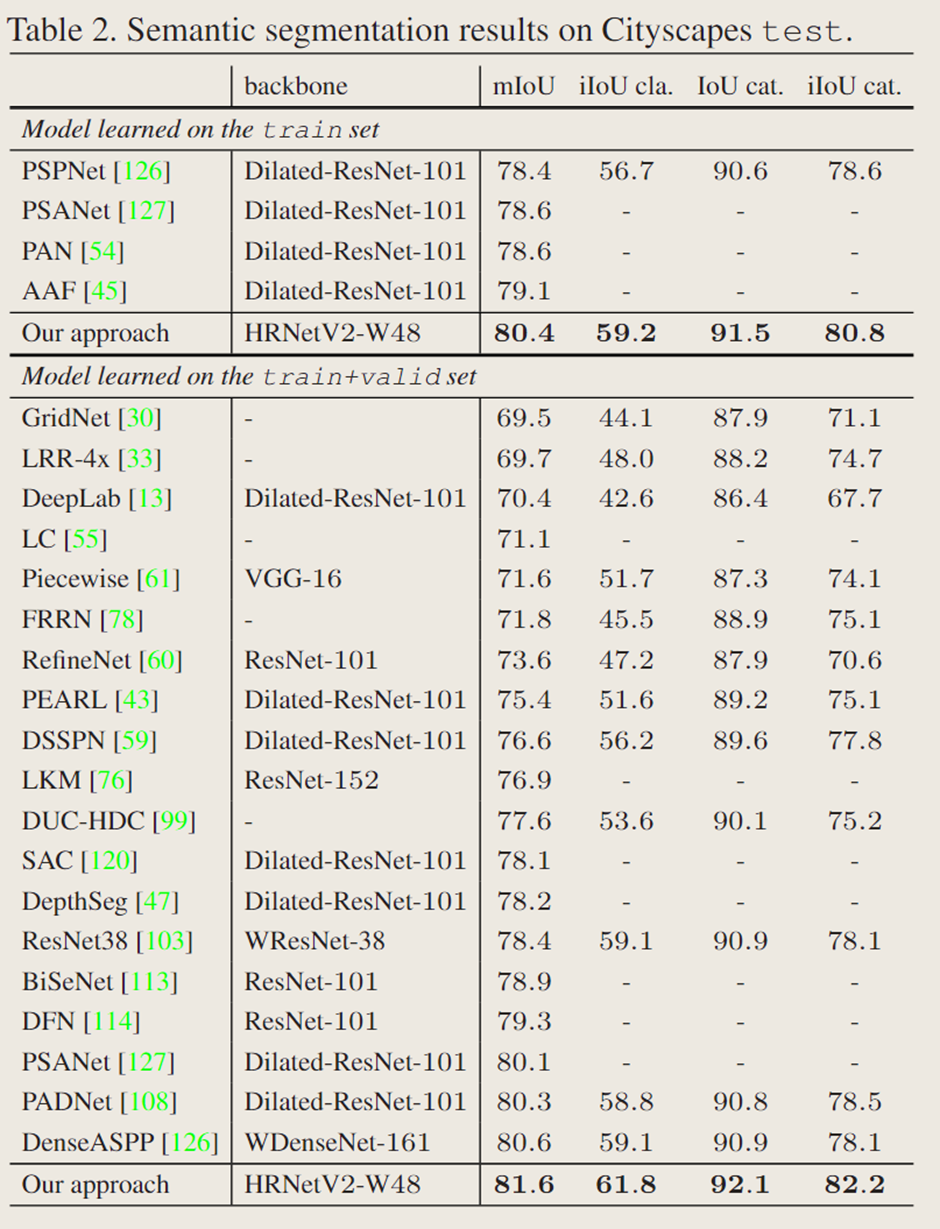
表 2 提供了文中的方法与最先进方法在城市景观测试集上的比较。所有结果均使用了六种比例和翻转。表 2 评估了两种不使用粗略数据的情况:一种是在训练集上学习的模型,另一种是在训练+验证集上学习的模型。在这两种情况下,HRNetV2-W48 都取得了最好的成绩,比之前的先进水平高出 1 分。
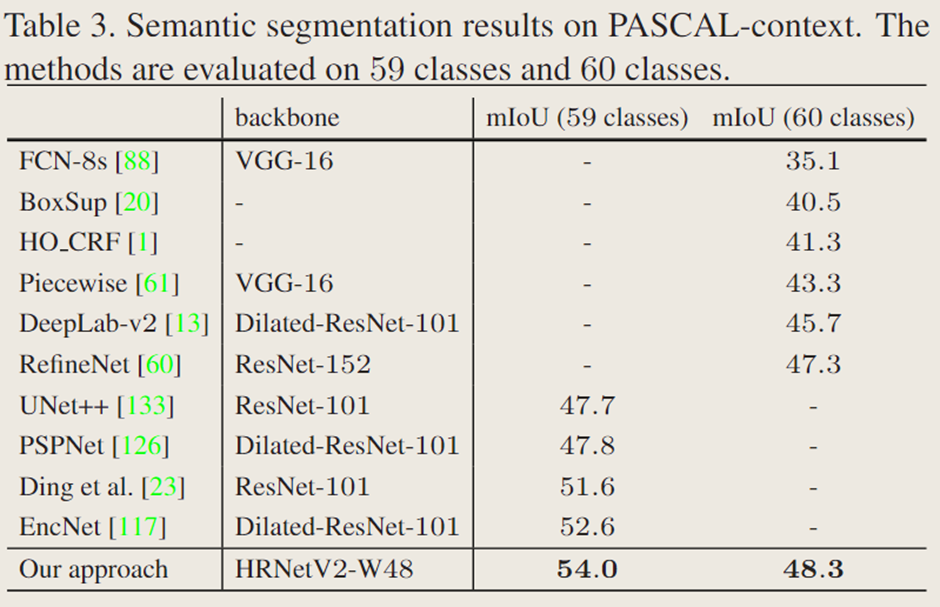
表 3 给出了文中的方法与最先进方法的比较。有两种评估方案:59 个类别的 mIoU 和 60 个类别的 mIoU(59 个类别 + 背景)。在这两种情况下,HRNetV2-W48 的表现都优于以前的最先进方法。
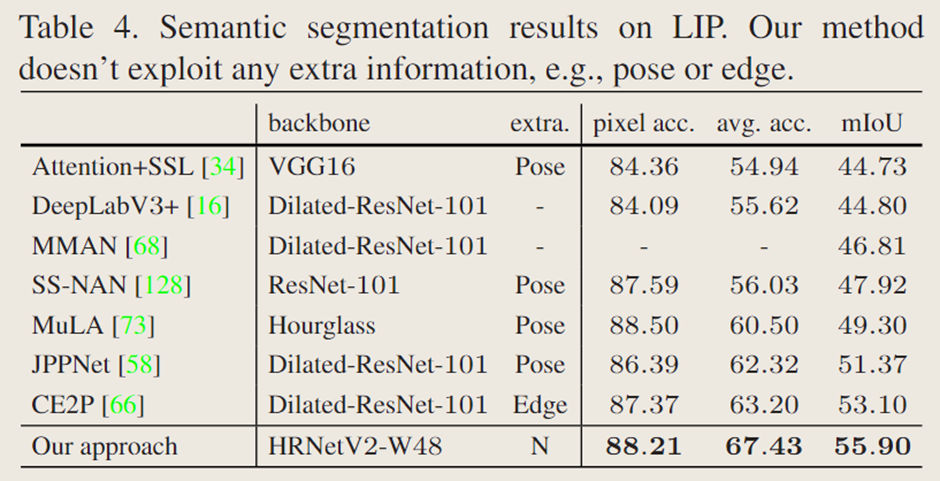
表 4 展示了文中的方法与最先进方法的对比。HRNetV2-W48 的整体性能表现最佳,且参数更少、计算成本更低。此外需要说明的是,文中的网络未使用姿态或边缘等额外信息。
3. COCO物体检测
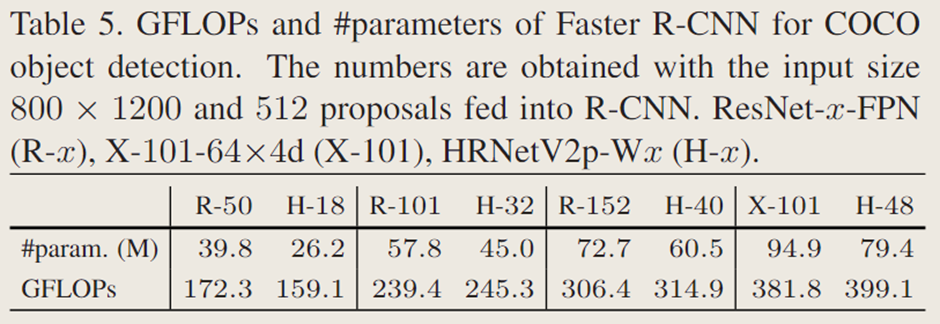
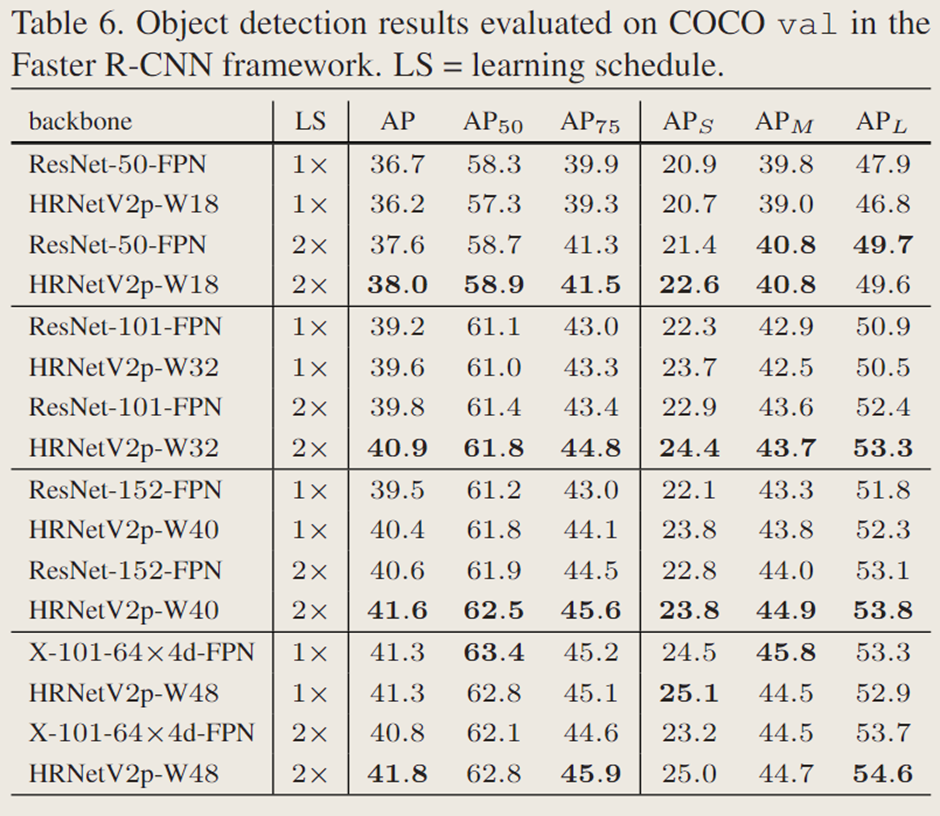
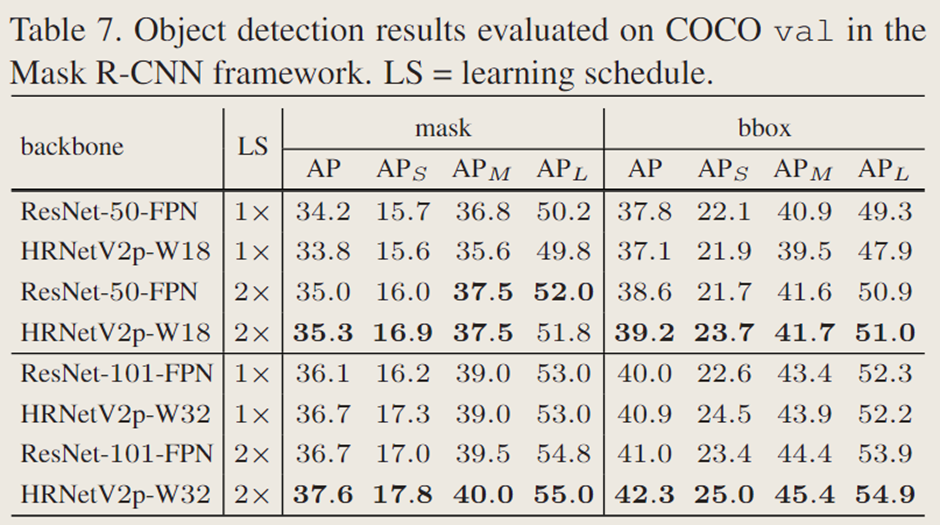
表 5 总结了参数量和计算量(GFLOPs)。表 6 和表 7 报告了在 COCO 验证集上的检测结果。通过分析可得出以下几点结论:(i)HRNetV2p-W18(HRNetV2p-W32)的模型规模和计算复杂度均小于 ResNet-50-FPN(ResNet-101-FPN)。(ii)在 1× 训练配置下,HRNetV2p-W32 的性能优于 ResNet101-FPN,而 HRNetV2p-W18 略逊于 ResNet50-FPN,这可能是由于优化迭代次数不足所致。(iii)在 2× 训练配置下,HRNetV2p-W18 和 HRNetV2p-W32 的性能分别超越了 ResNet-50-FPN 和 ResNet-101-FPN。
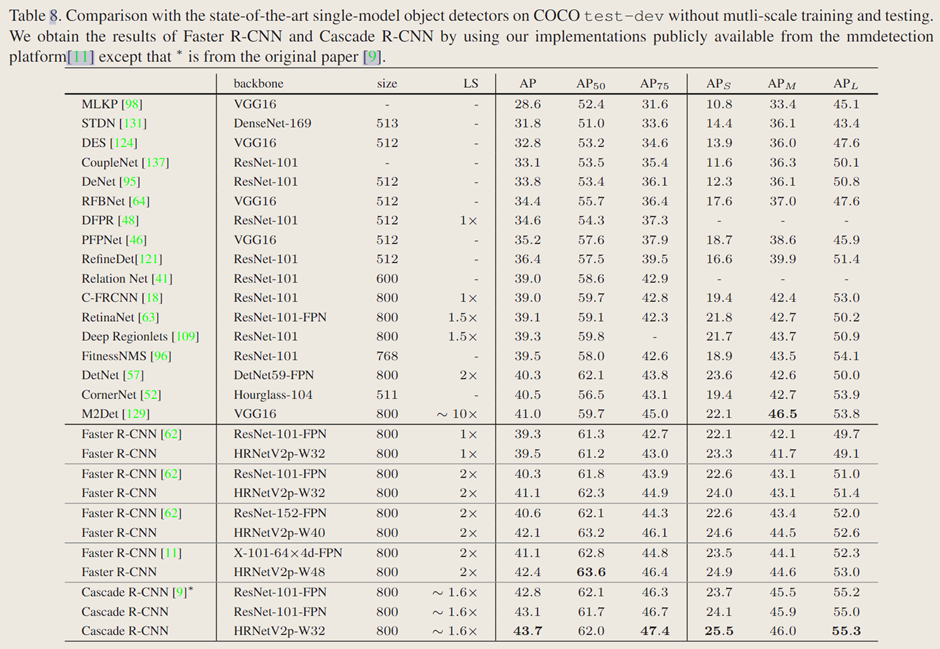
表 8 报告了文中的网络与最先进的单模型目标检测器在 COCO test-dev 上的比较,未使用 [65,79,56,90,89,75] 中所做的多尺度训练和多尺度测试。在 Faster R-CNN 框架中,文中的网络在参数和计算复杂度相近的情况下表现优于 ResNet 系列:HRNetV2p-W32 对比 ResNet-101-FPN,HRNetV2p-W40 对比 ResNet-152-FPN,HRNetV2p-W48 对比 X-101-64×4d-FPN。在 Cascade R-CNN 框架中,文中的 HRNetV2p-W32 表现更优。
4. 面部关键点检测
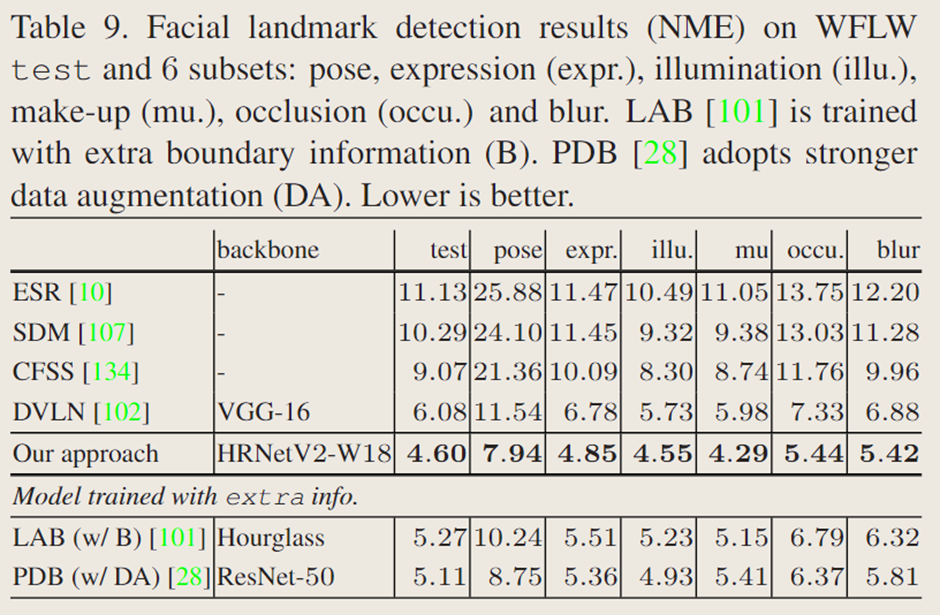
表 9 展示了文中的方法与最先进方法的对比。在测试集及所有子集上,文中的方法显著优于其他方法,包括利用额外边界信息的 LAB和使用更强数据增强的 PDB 。
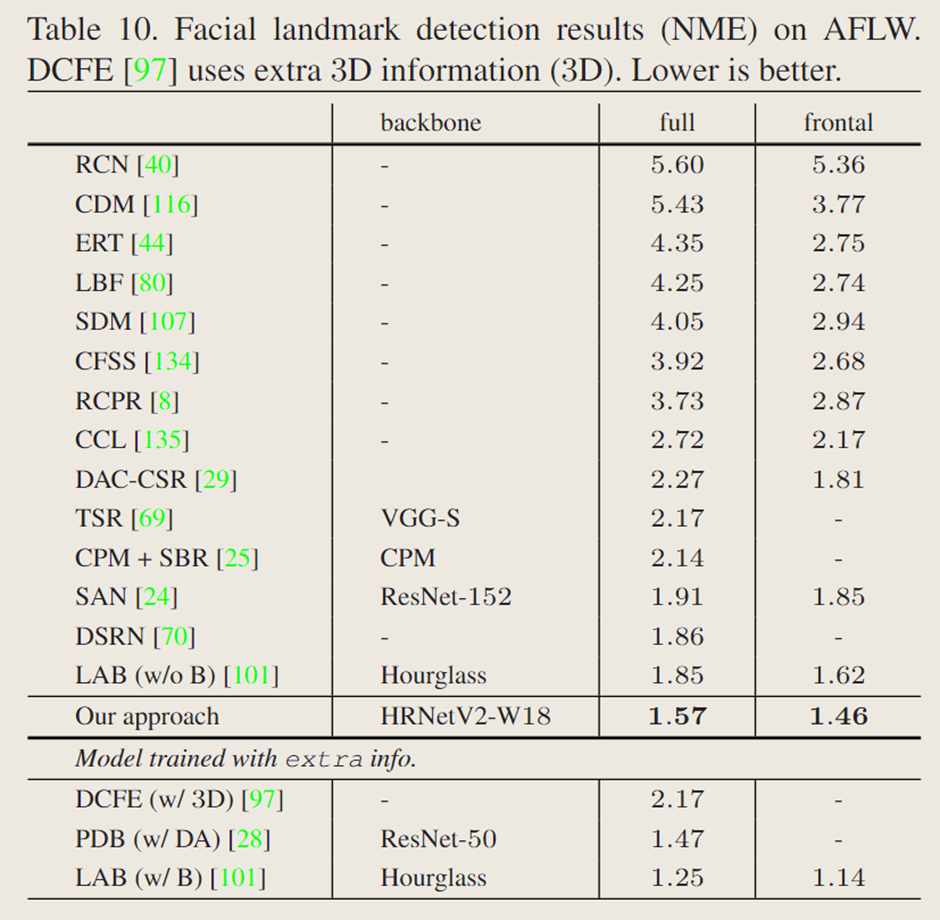
表 10 展示了文中的方法与最先进方法的对比。在未使用额外信息和更强数据增强的方法中,文中的方法取得了最佳性能,甚至优于利用额外 3D 信息的 DCFE。不过,文中的方法性能略逊于使用额外边界信息的 LAB 和采用更强数据增强的 PDB。
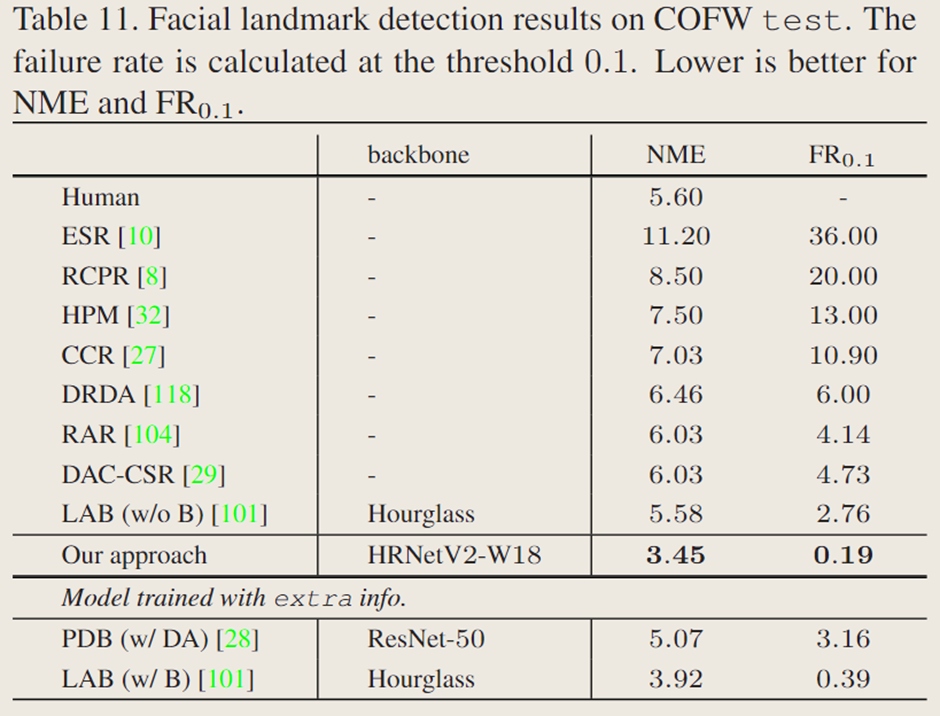
表 11 展示了文中的方法与最先进方法的对比。HRNetV2 大幅优于其他方法。特别是,它比利用额外边界信息的 LAB 和采用更强数据增强的 PDB 表现更优。
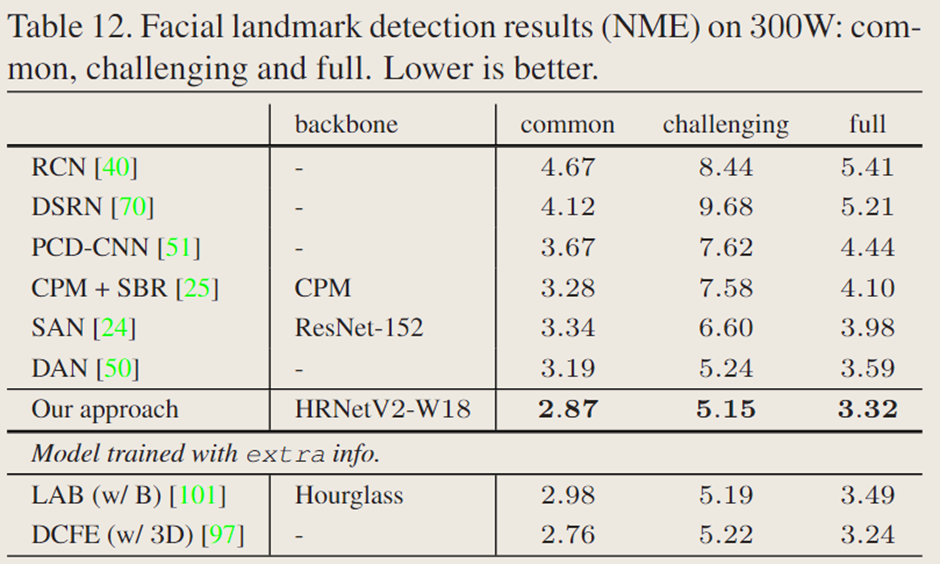
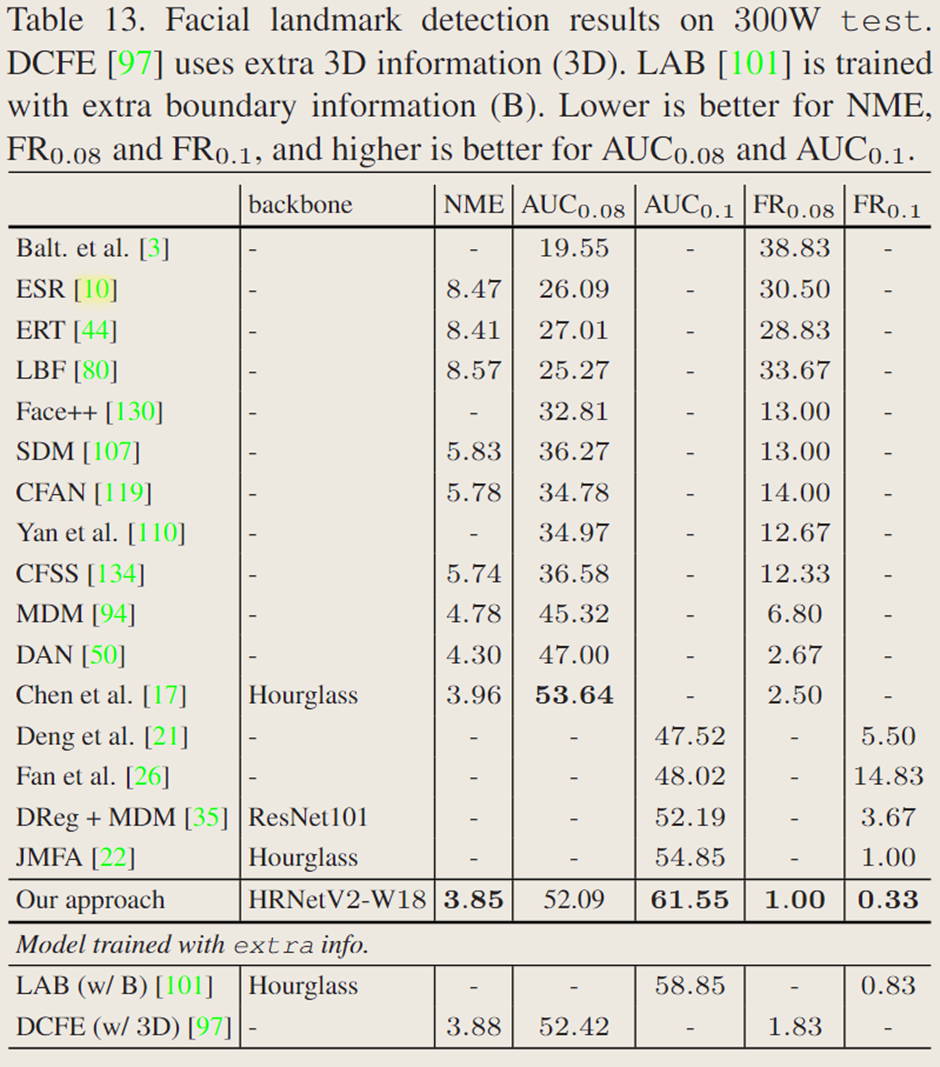
表 12 给出了完整集及其两个子集(普通子集和挑战性子集)的结果。表 13 给出了测试集的结果。与使用参数和计算复杂度较大的 Hourglass 作为主干网络的 Chen 等人的方法相比,除了 AUC 0.08 分数外,文中的分数更优。在没有使用额外信息和更强数据增强的方法中,文中的 HRNetV2 获得了整体最佳性能,甚至优于使用额外边界信息的 LAB 和利用额外 3D 信息的 DCFE 。
5. 实证分析
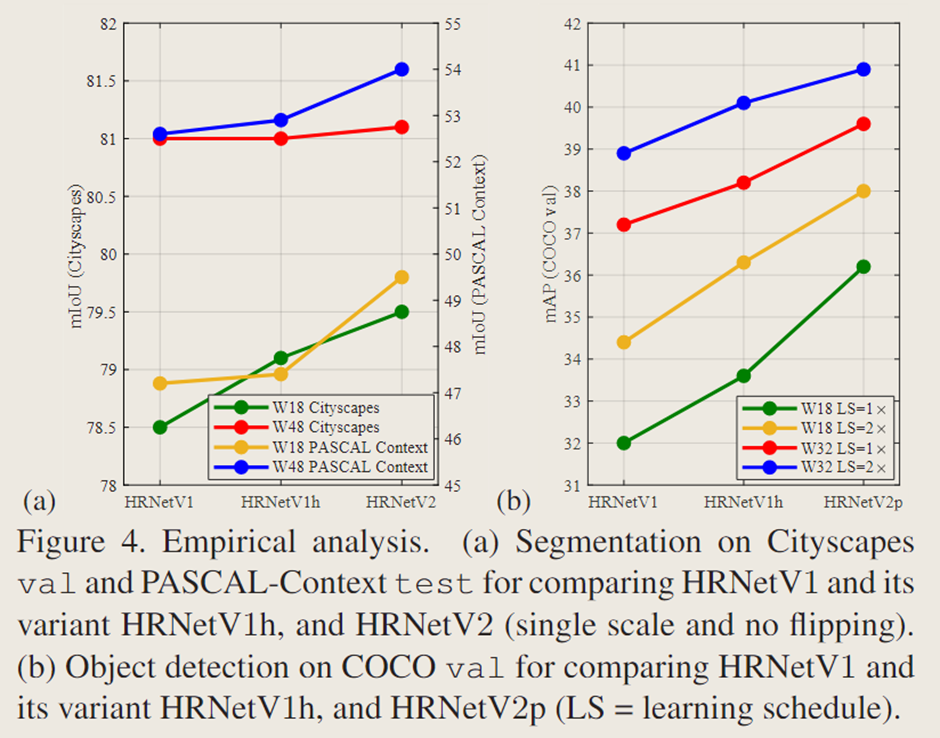
文中在语义分割和 COCO 目标检测任务上,将改进后的网络 HRNetV2 和 HRNetV2p 与原始网络(简称 HRNetV1)进行了对比。如图 4(a)和图 4(b)所示的分割与目标检测结果表明,HRNetV2 显著优于 HRNetV1,仅在 Cityscapes 分割任务的大模型场景中增益较小。文中还测试了一个变体(标记为 HRNetV1h),该变体通过添加 1×1 卷积来增加输出高分辨率表示的维度。图 4(a)和图 4(b)的结果显示,该变体相比 HRNetV1 仅有轻微提升,这表明在 HRNetV2 中聚合低分辨率并行卷积的表示对于提升模型能力至关重要。