Java函数式编程(中)
三、Stream API
(1)创建操作
| 构建 | |
| Arrays.stream(数组) | 根据数组构建 |
| Collection.stream() | 根据集合构建 |
| Stream.of(对象1, 对象2, ...) | 根据对象构建 |
| 生成 | |
| IntStream.range(a, b) | 根据范围生成(含a 不含b) |
| IntStream.rangeClosed(a, b) | 根据范围生成(含a 也含b) |
| IntStream.iterate(s, p -> c) | s初始值,p前值,c当前值 |
| IntStream.generate(() -> c) | c当期值 |
| 合并 | |
| Stream.concat(流1, 流2) | 合并两个流 |
(2)中间操作
| 截取 | |
| stream.skip(n) | 舍弃n个,保留剩余 |
| stream.limit(n) | 从当前保留n个 |
| stream.dropWhile(x -> boolean) | 舍弃,直到不满足条件,保留剩余 |
| stream.takewhile(x -> boolean) | 保留,直到不满足条件,舍弃剩余 |
| 过滤 | |
| stream.filter(x -> boolean) | 满足条件的保留 |
| 转换 | |
| stream.map(x -> y) | 将x转换为y |
| stream.flatMap(x -> substream) | 将x转换为substream |
| stream.mapMulti((x, consumer) -> void) | consumer消费的x会进入结果 |
| stream.mapToInt(x -> int) | 将x转换为int |
| stream.mapToLong(x -> long) | 将x转换为long |
| stream.mapToDouble(x -> double) | 将x转换为double |
| 排序与去重 | |
| stream.distinct() | 去重 |
| stream.sort((a, b) -> int) | a与b比较,返回负 a小,返回零相等,返回正 b小 |
(3)终结操作
| 查找 | |
| stream.findFirst() | 找到第一个,返回Optional |
| stream.findAny() | 随便找一个,返回Optional |
| 判断 | |
| stream.anyMatch(x -> boolean) | 随便一个满足条件,返回true |
| stream.allMatch(x -> boolean) | 所有都满足条件,才返回true |
| stream.noneMatch(x -> boolean) | 所有都不满足条件,才返回true |
| 消费 | |
| stream.forEach(x -> void) | 消费 |
| stream.forEachOrdered(x -> void) | 按序消费 |
| 化简 | |
| stream.reduce(init, (p, x) -> r) | init初始值,用上次结果p和当前元素x生成本次结果r |
| stream.reduce(init, (p, x) -> r, (r1, r2) -> r) | 最后是表示结果之间进行合并 |
| stream.reduce((p, x) -> r) | 用第一个值作为初始值,返回Optional |
| stream.min((a, b) -> int) | 求最小值 |
| stream.max((a, b) -> int) | 求最大值 |
| stream.count() | 求个数 |
| 收集 | |
| stream.toArray() | 收集为数组 |
| stream.toArray(size -> new A[size]) | 收集为数组 |
| stream.collect(() -> c, (c, x) -> void, (c1, c2) -> c) | 收集到容器:首先创建容器c,其次将x放入c,最后合并所有容器 |
(4)调试
| 调试 | |
| stream.peek(x -> void) | 调试 |
(5)收集器
| 收集器 | |
| joinint(delimiter) | 拼接字符串,delimiter分隔符 |
| toList() | 用ArrayList收集 |
| toSet() | 用HashSet收集 |
| toMap(x -> k, x -> v) | 从x提取出k, v |
| toUnmodifiableList() | 用不可变List收集 |
| toUnmodifiableSet() | 用不可变Set收集 |
| toUnmodifiableMap(x -> k, x -> v) | 用不可变Map收集 |
| partitioningBy(x -> boolean, dc) | 按条件分区,用下游收集器dc收集 |
| groupingBy(x -> k, dc) | 从x提取出k,用下游收集器dc收集 |
| mapping(x -> y, dc) | 将x转换为y,用下游收集器dc收集 |
| flatMapping(x -> substream, dc) | 将x转换为substream,用下游收集器dc收集 |
| filtering(x -> boolean, dc) | 过滤后,用下游收集器dc收集 |
| counting() | 求个数 |
| minBy((a, b) -> int) | 求最小 |
| maxBy((a, b) -> int) | 求最大 |
| summingInt(x -> int) | 转int后求和 |
| averagingInt(x -> int) | 转int后求平均 |
| reducing(init, (p, x) -> r) | init初始值,用上次结果p和当前元素x生成本次结果r |
(6)int流
| int流 | |
| intstream.mapToObj(int -> obj) | 转换为obj流 |
| intstream.boxed() | 转换为Integer流 |
| instream.sum() | 求和 |
| intstream.min() | 求最小值,返回Optional |
| intstream.max() | 求最大值,返回Optional |
| intstream.average() | 求平均值,返回Optional |
| intstream.summaryStatistics() | 综合count sum min max average |
1. 过滤 - filter
需求:找到所有的浆果
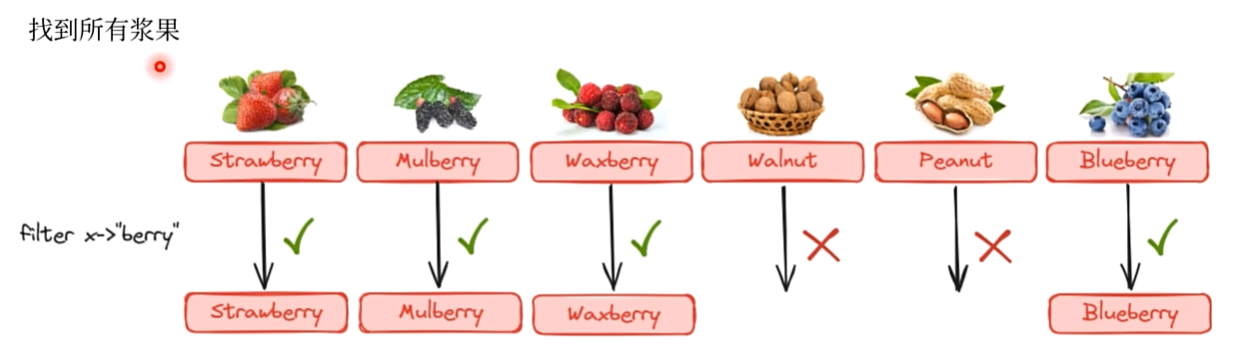
关键:Predicate
实现代码:
package com.itheima.day3.stream;import java.util.stream.Stream;public class C01FilterTest {public static void main(String[] args) {Stream.of(new Fruit("草莓", "Strawberry", "浆果", "红色"),new Fruit("桑葚", "Mulberry", "浆果", "紫色"),new Fruit("杨梅", "Waxberry", "浆果", "红色"),new Fruit("核桃", "Walnut", "坚果", "棕色"),new Fruit("花生", "Peanut", "坚果", "棕色"),new Fruit("蓝莓", "Blueberry", "浆果", "蓝色"))
// .filter(f->f.category().equals("浆果") && f.color().equals("蓝色")).filter(f->f.category().equals("浆果")).filter(f->f.color().equals("蓝色")).forEach(System.out::println);}record Fruit(String cname, String name, String category, String color) {}
}
2. 映射 - map
需求:把所有果实打成酱
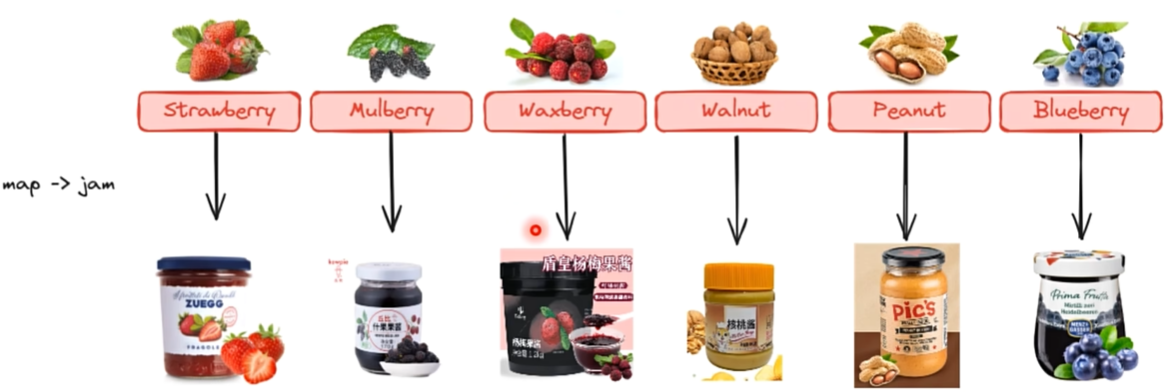
实现:Function
实现代码:
package com.itheima.day3.stream;import java.util.stream.Stream;public class C02MapTest {public static void main(String[] args) {Stream.of(new Fruit("草莓", "Strawberry", "浆果", "红色"),new Fruit("桑葚", "Mulberry", "浆果", "紫色"),new Fruit("杨梅", "Waxberry", "浆果", "红色"),new Fruit("核桃", "Walnut", "坚果", "棕色"),new Fruit("草莓", "Peanut", "坚果", "棕色"),new Fruit("蓝莓", "Blueberry", "浆果", "蓝色")).map(f->f.cname()+"酱").forEach(System.out::println);}record Fruit(String cname, String name, String category, String color) {}
}
3. 降维(扁平化)- flatMap
需求:二维数据 变成 一维数据
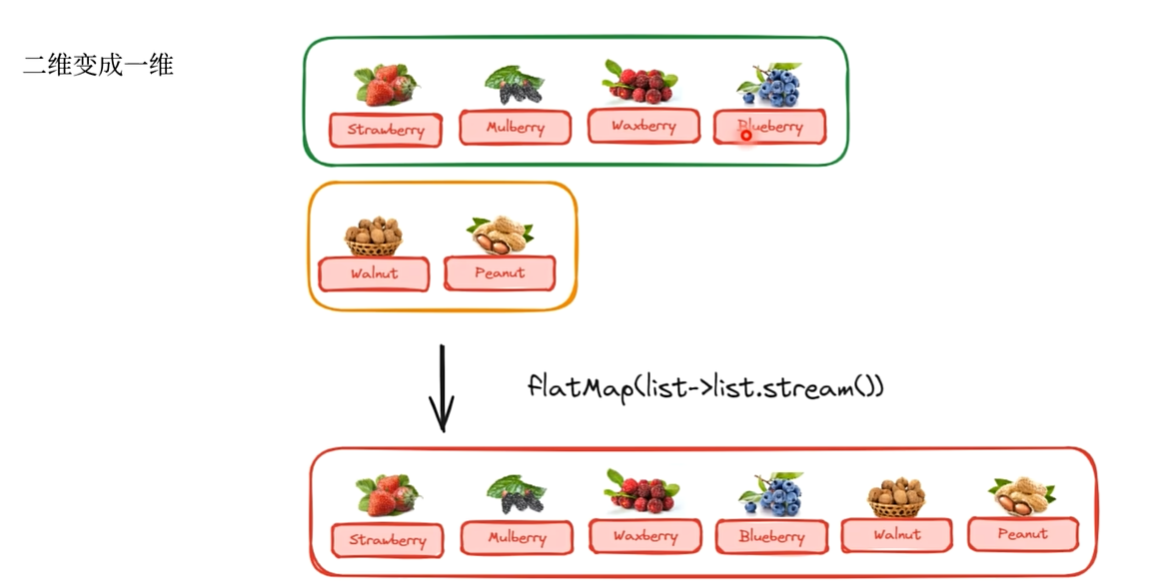
关键:Function
实现代码:
package com.itheima.day3.stream;import java.util.Arrays;
import java.util.Collection;
import java.util.List;
import java.util.stream.Stream;public class C03FlatMapTest {public static void main(String[] args) {Stream.of(List.of(new Fruit("草莓", "Strawberry", "浆果", "红色"),new Fruit("桑葚", "Mulberry", "浆果", "紫色"),new Fruit("杨梅", "Waxberry", "浆果", "红色"),new Fruit("蓝莓", "Blueberry", "浆果", "蓝色")),List.of(new Fruit("核桃", "Walnut", "坚果", "棕色"),new Fruit("草莓", "Peanut", "坚果", "棕色")))
// .flatMap(list -> list.stream()).flatMap(Collection::stream).forEach(System.out::println);Integer[][] array2D = {{1, 2, 3},{4, 5, 6},{7, 8, 9},};Arrays.stream(array2D)
// .flatMap(array -> Arrays.stream(array)).flatMap(Arrays::stream).forEach(System.out::println);}record Fruit(String cname, String name, String category, String color) {}}
- 降维前:

- 降维后:

4. 构建
用 已有数据 构建出 Stream流

示例代码:
package com.itheima.day3.stream;import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.stream.Stream;public class C04BuildTest {public static void main(String[] args) {// 1. 从集合构建Set.of(1, 2, 3).stream().forEach(System.out::println);List.of(1, 2, 3).stream().forEach(System.out::println);Map.of("a", 1, "b", 2).entrySet().stream().forEach(System.out::println);// 2. 从数组构建int[] array = {1, 2, 3};Arrays.stream(array).forEach(System.out::println);// 3. 从对象构建Stream.of(1, 2, 3, 4, 5).forEach(System.out::println);}
}
5. 拼接 - concat
将两个流合并成一个
Stream.concat(流1, 流2)
示例代码:
package com.itheima.day3.stream;import java.util.stream.Stream;public class C05ConcatSplitTest {public static void main(String[] args) {// 1. 合并Stream<Integer> s1 = Stream.of(1, 2, 3);Stream<Integer> s2 = Stream.of(4, 5, 1, 2);Stream<Integer> concat = Stream.concat(s1, s2);concat.forEach(System.out::println);}
}
6. 截取 - skip、limit、takeWhile、dropWhile
- 截取 - 直接给出截取位置
- skip(long n) 跳过 n 个数据,保留剩下的
- limit(long n) 保留 n 个数据,剩下的不要
- 截取 - 根据条件确定截取位置
- takeWhile(Predicate p) 条件成立保留, 一旦条件不成立,剩下的不要
- dropWhile(Predicate p) 条件成立舍弃, 一旦条件不成立,剩下的保留
示例代码:
package com.itheima.day3.stream;import java.util.stream.Stream;public class C05ConcatSplitTest {public static void main(String[] args) {// 1. 合并Stream<Integer> s1 = Stream.of(1, 2, 3);Stream<Integer> s2 = Stream.of(4, 5, 1, 2);Stream<Integer> concat = Stream.concat(s1, s2); // 1 2 3 4 5 1 2/*2. 截取 - 直接给出截取位置skip(long n) 跳过 n 个数据,保留剩下的limit(long n) 保留 n 个数据,剩下的不要*/concat.skip(2).forEach(System.out::print); // 3 4 5 1 2concat.limit(2).forEach(System.out::print); // 1 2concat.skip(2).limit(2).forEach(System.out::print); // 3 4/*3. 截取 - 根据条件确定截取位置takeWhile(Predicate p) 条件成立保留, 一旦条件不成立,剩下的不要dropWhile(Predicate p) 条件成立舍弃, 一旦条件不成立,剩下的保留*/concat.takeWhile(x -> x < 3).forEach(System.out::print); // 1 2concat.dropWhile(x -> x < 3).forEach(System.out::print); // 3 4 5 1 2}
}
7. 生成 - range、iterate、generate
不用现有数据 生成 Stream 对象

示例代码:
package com.itheima.day3.stream;import java.util.concurrent.ThreadLocalRandom;
import java.util.stream.IntStream;public class C06GenerateTest {public static void main(String[] args) {// 1. IntStream.rangeIntStream.range(1, 10).forEach(System.out::println); // 含头不含尾 [)IntStream.rangeClosed(1, 9).forEach(System.out::println); // 含头也含尾 []// 2. IntStream.iterate 生成 1 3 5 7 9 ... 奇数序列 可以根据上一个元素值来生成当前元素IntStream.iterate(1, x -> x + 2).limit(10).forEach(System.out::println); // 前10个奇数IntStream.iterate(1, x -> x <= 9, x -> x + 2).forEach(System.out::println); // 10以内的奇数// 3. IntStream.generate 生成5个0~100内的随机整数(包含0,不包含100 -> [0, 100) )IntStream.generate(()-> ThreadLocalRandom.current().nextInt(100)).limit(5).forEach(System.out::println);ThreadLocalRandom.current().ints(5, 0, 100).forEach(System.out::println);}
}
8. 查找与判断 - findAny、findFirst、anyMatch、allMatch、noneMatch
查找
- filter(Predict p).findAny()
- filter(Predict p).findFirst()
判断
- anyMatch(Predict p)
- allMatch(Predict p)
- noneMatch(Predict p)
示例1:查找
package com.itheima.day3.stream;import java.util.stream.IntStream;public class C07FindTest {public static void main(String[] args) {// 1. findFirst 找到第一个元素IntStream stream = IntStream.of(1, 2, 3, 4, 5, 6);// 查找第一个偶数(找不到则返回-1)System.out.println(stream.filter(x -> (x & 1) == 0).findFirst().orElse(-1)); // OptionalInt[2]// 查找第一个偶数,找到才打印,找不到不打印stream.filter(x -> (x & 1) == 0).findFirst().ifPresent(System.out::println); // 2// 2. findAny 找到任意一个偶数元素stream.filter(x -> (x & 1) == 0).findAny().ifPresent(System.out::println); // 串行流: 2(与findFirst一致); 并行流: 2 或 4 或 6}
}
示例2:判断
package com.itheima.day3.stream;import java.util.stream.IntStream;public class C08MatchTest {public static void main(String[] args) {IntStream stream = IntStream.of(1, 2, 3, 4, 5, 6);// 检查是否有偶数System.out.println(stream.anyMatch(x -> (x & 1) == 0)); // true// 检查是否所有元素都是偶数System.out.println(stream.allMatch(x -> (x & 1) == 0)); // false// 检查是否所有元素都不是偶数System.out.println(stream.noneMatch(x -> (x & 1) == 0)); // false}
}
9. 排序与去重 - distinct、sorted
示例代码:
package com.itheima.day3.stream;import java.util.Comparator;
import java.util.stream.IntStream;
import java.util.stream.Stream;public class C09SortTest {public static void main(String[] args) {// 去重IntStream.of(1, 2, 3, 1, 2, 3, 3, 4, 5).distinct().forEach(System.out::println); // 1, 2, 3, 4, 5// 排序Stream.of(new Hero("令狐冲", 90),new Hero("风清扬", 98),new Hero("独孤求败", 100),new Hero("方证", 92),new Hero("东方不败", 98),new Hero("冲虚", 90),new Hero("向问天", 88),new Hero("任我行", 92),new Hero("不戒", 88))
// .sorted((a, b) -> a.strength() < b.strength() ? -1 : a.strength() == b.strength() ? 0 : 1) // 按武力值升序排序
// .sorted((a, b) -> Integer.compare(a.strength(), b.strength()))
// .sorted(Comparator.comparingInt(h -> h.strength()))
// .sorted(Comparator.comparingInt(Hero::strength).reversed()) // 按武力降序.sorted(Comparator.comparingInt(Hero::strength).reversed().thenComparingInt(h -> h.name().length())) // 按武力降序,武力相等的按名字长度升序.forEach(System.out::println);}record Hero(String name, int strength) {}
}
10. 化简 - reduce
适用场景:求最大值、最小值、平均值、和、个数
示例代码:
package com.itheima.day3.stream;import java.util.Comparator;
import java.util.Optional;
import java.util.stream.Stream;/*化简:两两合并,只剩一个适合:最大值、最小值、求和、求个数....reduce((p, x) -> r) p 上次的合并结果, x 当前元素, r 本次合并结果.reduce(init, (p, x) -> r).reduce(init, (p, x) -> r, (r1, r2) -> r)*/
public class C10ReduceTest {record Hero(String name, int strength) {}public static void main(String[] args) {Stream<Hero> stream = Stream.of(new Hero("令狐冲", 90),new Hero("风清扬", 98),new Hero("独孤求败", 100),new Hero("方证", 92),new Hero("东方不败", 98),new Hero("冲虚", 90),new Hero("向问天", 88),new Hero("任我行", 92),new Hero("不戒", 88));// 1) 求武力最高的 heroOptional<Hero> result = stream.reduce((h1, h2) -> h1.strength() > h2.strength() ? h1 : h2);Hero result2 = stream.reduce(new Hero("-", -1), (h1, h2) -> h1.strength() > h2.strength() ? h1 : h2);System.out.println(result2);// 2) 求高手总数System.out.println(stream.map(h -> 1).reduce(0, Integer::sum));System.out.println(stream.count());// 3) 求武力值最高的heroSystem.out.println(stream.max(Comparator.comparingInt(Hero::strength)));// 4) 求武力值最低的heroSystem.out.println(stream.min(Comparator.comparingInt(Hero::strength)));// 5) 求所有hero的武力值的和System.out.println(stream.mapToInt(Hero::strength).sum());// 6) 求hero的武力值的平均值System.out.println(stream.mapToInt(Hero::strength).average());}
}
11. 收集 - collect
作用:将元素收集入容器
示例代码:
package com.itheima.day3.stream;import java.util.*;
import java.util.stream.Stream;public class C11CollectTest {record Hero(String name, int strength) {}/*收集:将元素收集入容器.collect(() -> c, (c, x) -> void, ?)() -> c 创建容器 c(c, x) -> void 将元素 x 加入 容器 c*/public static void main(String[] args) {Stream<String> stream = Stream.of("令狐冲", "风清扬", "独孤求败", "方证","东方不败", "冲虚", "向问天", "任我行", "不戒", "不戒", "不戒", "不戒");// ------------------收集到集合容器---------------// 1) 收集到 ListList<String> result = stream.collect(() -> new ArrayList<>(), (list, x) -> list.add(x), (a, b) -> {});// ArrayList::new () -> new ArrayList()// ArrayList::add (list, x) -> list.add(x)List<String> result2 = stream.collect(ArrayList::new, ArrayList::add, (a, b) -> {});// 2) 收集到 SetSet<String> result3 = stream.collect(LinkedHashSet::new, Set::add, (a, b) -> {});// 3)收集到 Map (key、value)Map<String, Integer> result4 = stream.collect(HashMap::new, (map, x) -> map.put(x, 1), (a, b) -> {});for (Map.Entry<String, Integer> entry : result4.entrySet()) {System.out.println(entry);}// ---------------收集到字符串容器-----------------// 4) 收集到StringBuilderStringBuilder sb = stream.collect(StringBuilder::new, StringBuilder::append, (a, b) -> {});System.out.println(sb);// 5) 收集到StringJoiner 添加分隔符StringJoiner sj = stream.collect(() -> new StringJoiner(","), StringJoiner::add, (a, b) -> {});System.out.println(sj);}
}
12. 收集器 - Collectors
示例代码:
package com.itheima.day3.stream;import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.Stream;// Collector 收集器
public class C12CollectorTest {record Hero(String name, int strength) {}public static void main(String[] args) {Stream<String> stream = Stream.of("令狐冲", "风清扬", "独孤求败", "方证","东方不败", "冲虚", "向问天", "任我行", "不戒");// 1) 收集到 ListList<String> result = stream.collect(() -> new ArrayList<>(), (list, x) -> list.add(x), (a, b) -> {});List<String> result2 = stream.collect(ArrayList::new, ArrayList::add, (a, b) -> {});List<String> result3 = stream.collect(Collectors.toList());List<String> result4 = stream.toList();// 2) 收集到 SetSet<String> result5 = stream.collect(LinkedHashSet::new, Set::add, (a, b) -> {});Set<String> result6 = stream.collect(Collectors.toSet());// 3)收集到 StringBuilderStringBuilder sb = stream.collect(StringBuilder::new, StringBuilder::append, (a, b) -> {});String result7 = stream.collect(Collectors.joining());// 4) 收集到 StringJoinerStringJoiner sj = stream.collect(() -> new StringJoiner(","), StringJoiner::add, (a, b) -> {});String result8 = stream.collect(Collectors.joining(","));// 5) 收集到 Map (key、value)Map<String, Integer> result9 = stream.collect(HashMap::new, (map, x) -> map.put(x, 1), (a, b) -> {});Map<String, Integer> map = stream.collect(Collectors.toMap(x -> x, x -> 1));/*Map2: new ArrayList(["方证","冲虚","不戒"])3: new ArrayList(["令狐冲","风清扬","向问天","任我行"])4: new ArrayList(["独孤求败","东方不败"])下游收集器*/// 按元素长度分组收集Map<Integer, List<String>> result10 = stream.collect(Collectors.groupingBy(String::length, Collectors.toList()));// 按元素长度分组收集,并将元素使用逗号分隔Map<Integer, String> result11 = stream.collect(Collectors.groupingBy(String::length, Collectors.joining(",")));for (Map.Entry<Integer, String> e : result11.entrySet()) {System.out.println(e);}}
}
13. 下游收集器
与groupingBy()配合使用的下游收集器:
| 收集器 | 含义 |
| mapping(x -> y, dc) | 将 x 转换为 y,用下游收集器 dc 收集 |
| flatMapping(x -> substream, dc) | 将 x 转换为 substream,用下游收集器dc收集 |
| filtering(x -> boolean, dc) | 过滤后,用下游收集器 dc 收集 |
| counting() | 求个数 |
| minBy((a, b) -> int) | 求最小 |
| maxBy((a, b) -> int) | 求最大 |
| summingInt(x -> int) | 转 int 后求和 |
| averagingInt(x -> int) | 转 int 后求平均 |
| reducing(init, (p, x) -> r) | init 初始值,用上次结果 p 和当前元素 x 生成本次结果r |
示例代码:
package com.itheima.day3.stream;import java.util.*;
import java.util.stream.Collector;
import java.util.stream.Collectors;
import java.util.stream.Stream;// 静态导入
import static java.util.stream.Collectors.*;public class C13GroupingByTest {record Hero(String name, int strength) {}public static void main(String[] args) {Stream<Hero> stream = Stream.of(new Hero("令狐冲", 90),new Hero("风清扬", 98),new Hero("独孤求败", 100),new Hero("方证", 92),new Hero("东方不败", 98),new Hero("冲虚", 90),new Hero("向问天", 88),new Hero("任我行", 92),new Hero("不戒", 88));// 1. mapping(x -> y, dc) 需求:根据名字长度分组,分组后组内只保留他们的武力值// new Hero("令狐冲", 90) -> 90// dc 下游收集器 down collectorMap<Integer, List<Integer>> collect1 = stream.collect(groupingBy(h -> h.name().length(), mapping(Hero::strength, toList())));// 2. filtering(x -> boolean, dc) 需求:根据名字长度分组,分组后组内过滤掉武力小于 90 的// 在分组收集的过程中,执行过滤Map<Integer, List<Hero>> collect2 = stream.collect(groupingBy(h -> h.name().length(), filtering(h -> h.strength() >= 90, toList())));// 或 先过滤,再来分组收集Map<Integer, List<Hero>> collect3 = stream.filter(h -> h.strength() >= 90).collect(groupingBy(h -> h.name().length(), toList()));// 3. flatMapping(x -> substream, dc) 需求:根据名字长度分组,分组后组内保留人名,并且人名切分成单个字符// "令狐冲".chars().mapToObj(Character::toString).forEach(System.out::println);Map<Integer, List<String>> collect4 = stream.collect(groupingBy(h -> h.name().length(),flatMapping(h -> h.name().chars().mapToObj(Character::toString), toList())));// 4. counting() 需求:根据名字长度分组,分组后求每组个数stream.collect(groupingBy(h -> h.name().length(), counting()));//5. minBy((a, b) -> int) 需求:根据名字长度分组,分组后求每组武功最低的人// 6. maxBy((a, b) -> int) 需求:根据名字长度分组,分组后求每组武功最高的人Map<Integer, Optional<Hero>> collect5 = stream.collect(groupingBy(h -> h.name().length(), minBy(Comparator.comparingInt(Hero::strength))));Map<Integer, Optional<Hero>> collect6 = stream.collect(groupingBy(h -> h.name().length(), maxBy(Comparator.comparingInt(Hero::strength))));// 7. summingInt(x -> int) 需求:根据名字长度分组,分组后求每组武力和// 8. averagingDouble(x -> double) 需求:根据名字长度分组,分组后求每组武力平均值Map<Integer, Integer> collect7 = stream.collect(groupingBy(h -> h.name().length(), summingInt(h -> h.strength)));Map<Integer, Double> collect8 = stream.collect(groupingBy(h -> h.name().length(), averagingDouble(Hero::strength)));// 9. reducing(init, (p, x) -> r)// 求和Map<Integer, Integer> collect9 = stream.collect(groupingBy(h -> h.name().length(), mapping(Hero::strength, reducing(0, Integer::sum))));// 求个数Map<Integer, Integer> collect10 = stream.collect(groupingBy(h -> h.name().length(), mapping(h -> 1, reducing(0, Integer::sum))));// 求平均,缺少 finisherMap<Integer, double[]> collect = stream.collect(groupingBy(h -> h.name().length(),mapping(h -> new double[]{h.strength(), 1},reducing(new double[]{0, 0}, (p, x) -> new double[]{p[0] + x[0], p[1] + x[1]}))));for (Map.Entry<Integer, double[]> e : collect.entrySet()) {System.out.println(e.getKey() + ":" + Arrays.toString(e.getValue()));}}
}
14. 基本流
基本类型是指 IntStream、LongStream 和 DoubleStream,它们在做数值计算时有更好的性能。
| int 流 | 含义 |
| intStream.mapToObj(int -> obj) | 转换为obj流 (对象流) |
| intStream.boxed() | 转换为Integer流(对象流) |
| intStream.sum() | 求和 |
| intStream.min() | 求最小值,返回Optional |
| intStream.max() | 求最大值,返回Optional |
| intStream.average() | 求平均值,返回Optional |
| intStream.summaryStatistics() | 综合count sum min max average |
示例代码:
package com.itheima.day3.stream;import java.util.IntSummaryStatistics;
import java.util.stream.DoubleStream;
import java.util.stream.IntStream;
import java.util.stream.LongStream;
import java.util.stream.Stream;public class C14Effective {record Hero(String name, int strength) {}/*三种基本流*/public static void main(String[] args) {IntStream a = IntStream.of(97, 98, 99);LongStream b = LongStream.of(1L, 2L, 3L);DoubleStream c = DoubleStream.of(1.0, 2.0, 3.0);Stream<Integer> d = Stream.of(1, 2, 3);// 转换为字符串a.mapToObj(Character::toString).forEach(System.out::println); // a b c// count sum min max averageIntSummaryStatistics stat = a.summaryStatistics();System.out.println(stat.getSum()); // 294System.out.println(stat.getCount()); // 3System.out.println(stat.getMax()); // 99System.out.println(stat.getMin()); // 97System.out.println(stat.getAverage()); // 98.0}
}
转换成基本流:
| 转换 | 含义 |
| stream.map(x -> y) | 将流中的每个元素x通过mapper函数转换为另一种类型y,形成新的stream |
| stream.flatMap(x -> substream) | 将每个元素x映射为一个子流substream,然后将所有子流扁平化合并为一个新的stream |
| stream.mapMulti(x, consumer) -> void) | 类似flatMap,但通过Consumer动态决定输出多个或零个元素到结果流 |
| stream.mapToInt(x -> int) | 将流元素x转换为int,返回一个IntStream(原始类型流,避免装箱开销) |
| stream.mapToLong(x -> long) | 将流元素x转为long,返回LongStream |
| stream.mapToDouble(x -> double) | 将流元素x转换为double,返回DoubleStream |
示例代码:
package com.itheima.day3.stream;import java.util.stream.Stream;public class C14Effective {record Hero(String name, int strength) {}/*三种基本流*/public static void main(String[] args) {Stream<Hero> stream = Stream.of(new Hero("令狐冲", 90),new Hero("风清扬", 98));stream.mapToInt(Hero::strength).forEach(System.out::println); // 90 98}
}
15. 特性
(1)不可变性
- 描述:Stream操作(如filter、map)不会修改原始数据源,而是生成一个新的Stream
- 优势:避免副作用,适合并发编程。
(2)惰性求值(Lazy Evaluation)
- 描述:中间操作(如filter、map)不会立即执行,只有在终端操作(如collect、forEach)触发时才会实际计算。
- 优势:优化性能(如短路操作limit()、findFirst()。
- 示例:
List<Integer> numbers = List.of(1, 2, 3, 4, 5);
numbers.stream().filter(n -> {System.out.println("Filtering: " + n); // 只有终端操作触发时才会执行return n % 2 == 0;}).map(n -> {System.out.println("Mapping: " + n);return n * 2;}).findFirst(); // 触发计算,可能只处理前几个元素(3)一次性消费(Single Use)
- 描述:Stream只能被消费一次,终端操作调用后流即关闭,再次使用会抛出IllegalStateException
- 示例:
Stream<Integer> stream = Stream.of(1, 2, 3);
stream.forEach(System.out::println); // 正常
stream.forEach(System.out::println); // 抛出异常(4)并行处理(Parallel Processing)
- 描述:通过parallel() 方法将流转换为并行流,自动利用多核CPU加速处理。
- 注意:需确保操作是线程安全的,无共享可变状态。
- 示例:
List<Integer> numbers = List.of(1, 2, 3, 4, 5);
int sum = numbers.parallelStream() // 并行流.mapToInt(n -> n * 2).sum();示例代码:
package com.itheima.day3.stream;import java.util.stream.Stream;public class C15Summary {public static void main(String[] args) {/*掌握 Stream 流的特性1. 一次使用2. 两类操作(中间操作 lazy 懒惰, 终结操作 eager 迫切)*/Stream<Integer> s1 = Stream.of(1, 3, 5); // 水滴// 一次特性// s1.forEach(System.out::println); // 1, 3, 5// s1.forEach(System.out::println); // java.lang.IllegalStateException: stream has already been operated upon or closed// ----------------------------------- ------------------------- 阀门// 在终结操作被调用时才执行前面的中间操作s1.map(x -> x + 1) // 水管 2 4 6.filter(x -> x <= 5) // 水管 2 4.forEach(System.out::println); // 水管 总阀门 2 4}
}
16. 并行
示例代码:
package com.itheima.day3.stream;import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Vector;
import java.util.stream.Collector;
import java.util.stream.Stream;// 并行流
public class C16Parallel {public static void main(String[] args) {// 单线程List<Integer> collect = Stream.of(1, 2, 3, 4).collect(Collector.of(// 如何创建容器() -> {System.out.printf("%-12s %s%n",simple(),"create");return new ArrayList<Integer>();},// 如何向容器添加数据(list, x) -> {List<Integer> old = new ArrayList<>(list);list.add(x);System.out.printf("%-12s %s.add(%d)=>%s%n",simple(), old, x, list);},// 如何合并两个容器的数据(list1, list2) -> {List<Integer> old = new ArrayList<>(list1);list1.addAll(list2);System.out.printf("%-12s %s.add(%s)=>%s%n", simple(),old, list2, list1);return list1;},// 收尾list -> null,// 特性:并发、收尾、顺序Collector.Characteristics.IDENTITY_FINISH));/*1) 数据量问题: 数据量大时才建议用并行流2) 线程会无限增加吗: 跟 cpu 能处理的线程数相关3) 收尾的意义: 转不可变集合、StringBuilder 转 String ...4) 是否线程安全: 不会有线程安全问题(访问的不是同一个ArrayList,互不干扰)5) 特性:是否需要收尾(默认收尾)是否需要保证顺序(默认保证)容器是否支持并发(默认不需要支持)到达选择哪一种?A. Characteristics.CONCURRENT + Characteristics.UNORDERED + 线程安全容器 -> 并发量大性能可能会受影响B. 默认 + 线程不安全容器 -> 占用内存多,合并多也会影响性能*/List<Integer> collect2 = Stream.of(1, 2, 3, 4).parallel().collect(Collector.of(// 如何创建容器() -> {System.out.printf("%-12s %s%n", simple(), "create");return new Vector<Integer>(); // 支持并发的容器,线程安全},// 如何向容器添加数据(list, x) -> {List<Integer> old = new ArrayList<>(list);list.add(x);System.out.printf("%-12s %s.add(%d)=>%s%n", simple(), old, x, list);},// 如何合并两个容器的数据(list1, list2) -> {List<Integer> old = new ArrayList<>(list1);list1.addAll(list2);System.out.printf("%-12s %s.add(%s)=>%s%n", simple(), old, list2, list1);return list1;},// 收尾list -> {System.out.printf("%-12s finish: %s=>%s%n", simple(), list, list);return Collections.unmodifiableList(list); // 转不可变List}// 特性:并发、是否需要收尾,是否要保证收集顺序, Collector.Characteristics.IDENTITY_FINISH // 不需要收尾, Collector.Characteristics.UNORDERED // 不需要保证收集顺序, Collector.Characteristics.CONCURRENT // 支持并发));System.out.println(collect2);// java.lang.UnsupportedOperationException(如果没添加: Collector.Characteristics.IDENTITY_FINISH )collect2.add(100);System.out.println(collect2);}private static String simple() {String name = Thread.currentThread().getName();int idx = name.indexOf("worker");if (idx > 0) {return name.substring(idx);}return name;}
}

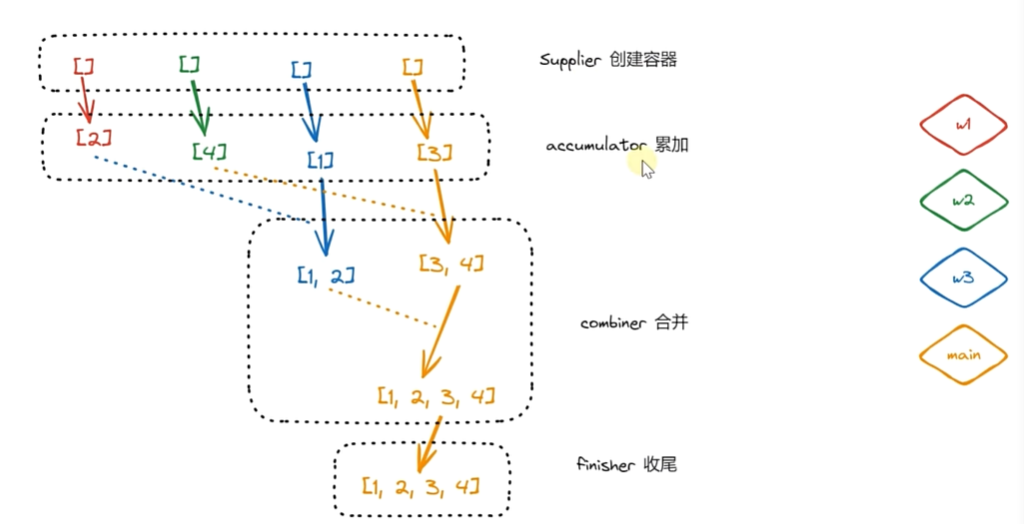
17. 效率
示例1:求和
package com.itheima.day3.performance;import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.stream.IntStream;// 性能:求和
public class T01Sum {@State(Scope.Benchmark)public static class MyState {public static final int COUNT = 10000;public int[] numbers = new int[COUNT];public List<Integer> numberList = new ArrayList<>(COUNT);public MyState() {for (int i = 0; i < COUNT; i++) {int x = i + 1;numbers[i] = x;numberList.add(i, x);}}}// 基本类型 -> 用loop循环对int求和@Benchmark@BenchmarkMode(Mode.AverageTime)@OutputTimeUnit(TimeUnit.NANOSECONDS)public int primitive(MyState state) {int sum = 0;for (int number : state.numbers) {sum += number;}return sum;}// 包装类型 - 用loop循环对Integer求和@Benchmark@BenchmarkMode(Mode.AverageTime)@OutputTimeUnit(TimeUnit.NANOSECONDS)public int boxed(MyState state) {int sum = 0;for (Integer i : state.numberList) {sum += i;}return sum;}// 普通Stream流 -> 用Stream对Integer求和@Benchmark@BenchmarkMode(Mode.AverageTime)@OutputTimeUnit(TimeUnit.NANOSECONDS)public int stream(MyState state) {return state.numberList.stream().reduce(0, (a, b) -> a + b);}// 基本流 -> 用IntStream对int求和@Benchmark@BenchmarkMode(Mode.AverageTime)@OutputTimeUnit(TimeUnit.NANOSECONDS)public int intStream(MyState state) {return IntStream.of(state.numbers).sum();}public static void main(String[] args) throws RunnerException {Options opt = new OptionsBuilder().include(T01Sum.class.getSimpleName()) // 指定要运行的测试类.forks(1) // 使用一个独立JVM进程.build();new Runner(opt).run();// MyState state = new MyState();
// T01Sum test = new T01Sum();
// System.out.println(test.primitive(state));
// System.out.println(test.boxed(state));
// System.out.println(test.stream(state));
// System.out.println(test.intStream(state));}
}
测试结果对比:Score的单位为ms
- 元素个数为100时:
| Benchmark | Mode | Cnt | Score (ns/op) | Error (ns/op) | Units |
|---|---|---|---|---|---|
| T01Sum.primitive | avgt | 5 | 25.424 | ± 0.782 | ns/op |
| T01Sum.intStream | avgt | 5 | 47.482 | ± 1.145 | ns/op |
| T01Sum.boxed | avgt | 5 | 72.457 | ± 4.136 | ns/op |
| T01Sum.stream | avgt | 5 | 465.141 | ± 4.891 | ns/op |
- 元素个数为1000时:
| Benchmark | Mode | Cnt | Score (ns/op) | Error (ns/op) | Units |
|---|---|---|---|---|---|
| T01Sum.primitive | avgt | 5 | 270.556 | ± 1.277 | ns/op |
| T01Sum.intStream | avgt | 5 | 292.467 | ± 10.987 | ns/op |
| T01Sum.boxed | avgt | 5 | 583.929 | ± 57.338 | ns/op |
| T01Sum.stream | avgt | 5 | 5948.294 | ± 2209.211 | ns/op |
- 元素个数为10000时:
| Benchmark | Mode | Cnt | Score (ns/op) | Error (ns/op) | Units |
|---|---|---|---|---|---|
| T01Sum.primitive | avgt | 5 | 2681.651 | ± 12.614 | ns/op |
| T01Sum.intStream | avgt | 5 | 2718.408 | ± 52.418 | ns/op |
| T01Sum.boxed | avgt | 5 | 6391.285 | ± 358.154 | ns/op |
| T01Sum.stream | avgt | 5 | 44414.884 | ± 3213.055 | ns/op |
结论:
- 做数值计算,优先挑选基本流(IntStream等),在数据量较大时,它的性能已经非常接近普通for循环;
- 做数值计算,应当避免普通流(Stream),性能与其它几种相比,慢一个数量级。
示例2:求最大值
package com.itheima.day3.performance;import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;import java.util.ArrayList;
import java.util.concurrent.*;
import java.util.stream.IntStream;// 性能:求最大值
public class T02Parallel {static final int n = 1000000;@State(Scope.Benchmark)public static class MyState {int[] numbers = new int[n];{for (int i = 0; i < n; i++) {numbers[i] = ThreadLocalRandom.current().nextInt(10000000);}}}/*** loop循环求最大值* @param state* @return*/@Benchmark@BenchmarkMode(Mode.AverageTime)@OutputTimeUnit(TimeUnit.NANOSECONDS)public int primitive(MyState state) {int max = 0;for (int number : state.numbers) {if (number > max) {max = number;}}return max;}/*** 串行流求最大值* @param state* @return*/@Benchmark@BenchmarkMode(Mode.AverageTime)@OutputTimeUnit(TimeUnit.NANOSECONDS)public int sequence(MyState state) {return IntStream.of(state.numbers).max().orElse(0);}/*** 并行流求最大值* @param state* @return*/@Benchmark@BenchmarkMode(Mode.AverageTime)@OutputTimeUnit(TimeUnit.NANOSECONDS)public int parallel(MyState state) {return IntStream.of(state.numbers).parallel().max().orElse(0);}/*** 分而治之 - 自定义多线程并行求最大值* - 将数据分成10份,从每份里找到最大的,最后从每份的最大值中再挑选出整体的最大值* @param state* @return* @throws ExecutionException* @throws InterruptedException*/@Benchmark@BenchmarkMode(Mode.AverageTime)@OutputTimeUnit(TimeUnit.NANOSECONDS)public int custom(MyState state) throws ExecutionException, InterruptedException {int[] numbers = state.numbers;// 将数据分成10份int step = n / 10;ArrayList<Future<Integer>> result = new ArrayList<>();try (ExecutorService service = Executors.newVirtualThreadPerTaskExecutor()) {// 从每份里找打最大值添加到resultfor (int j = 0; j < n; j += step) {int k = j;result.add(service.submit(() -> {int max = 0;for (int i = k; i < k + step; i++) {if (numbers[i] > max) {max = numbers[i];}}return max;}));}}System.out.println(result.size());int max = 0;// 从result里找到最大的,即为整体数据中最大值for (Future<Integer> future : result) {if (future.get() > max) {max = future.get();}}return max;}public static void main(String[] args) throws RunnerException, ExecutionException, InterruptedException {Options opt = new OptionsBuilder().include(T02Parallel.class.getSimpleName()).forks(1).build();new Runner(opt).run();
// MyState state = new MyState();
// T02Parallel test = new T02Parallel();
// System.out.println(test.primitive(state));
// System.out.println(test.sequence(state));
// System.out.println(test.parallel(state));
// System.out.println(test.custom(state));}
}
测试结果对比:
- 元素个数为100时:
| Benchmark | Mode | Cnt | Score (ns/op) | Error (ns/op) | Units |
|---|---|---|---|---|---|
| T02Parallel.custom | avgt | 5 | 39619.796 | ± 1263.036 | ns/op |
| T02Parallel.parallel | avgt | 5 | 6754.239 | ± 79.894 | ns/op |
| T02Parallel.primitive | avgt | 5 | 29.538 | ± 3.056 | ns/op |
| T02Parallel.sequence | avgt | 5 | 80.170 | ± 1.940 | ns/op |
- 元素个数为10000时:
| Benchmark | Mode | Cnt | Score (ns/op) | Error (ns/op) | Units |
|---|---|---|---|---|---|
| T02Parallel.custom | avgt | 5 | 41656.093 | ± 1537.237 | ns/op |
| T02Parallel.parallel | avgt | 5 | 11218.573 | ± 1994.863 | ns/op |
| T02Parallel.primitive | avgt | 5 | 2217.562 | ± 80.981 | ns/op |
| T02Parallel.sequence | avgt | 5 | 5682.482 | ± 264.645 | ns/op |
- 元素个数为1000000时:
| Benchmark | Mode | Cnt | Score (ns/op) | Error (ns/op) | Units |
|---|---|---|---|---|---|
| T02Parallel.custom | avgt | 5 | 194984.564 | ± 25794.484 | ns/op |
| T02Parallel.parallel | avgt | 5 | 298940.794 | ± 31944.959 | ns/op |
| T02Parallel.primitive | avgt | 5 | 325178.873 | ± 81314.981 | ns/op |
| T02Parallel.sequence | avgt | 5 | 618274.062 | ± 5867.812 | ns/op |
结论:
- 并行流相对自定义多线程实现分而治之代码更为简洁;
- 并行流只有在数据量非常大时,才能充分发力;数据量少时,还不如用串行流
示例3:并行(发)收集
package com.itheima.day3.performance;import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ThreadLocalRandom;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.function.Function;import static java.util.stream.Collectors.*;// 性能:并行(发)收集
// ConcurrentHashMap
// HashMap
public class T03Concurrent {static final int n = 1000000;@State(Scope.Benchmark)public static class MyState {int[] numbers = new int[n];{for (int i = 0; i < n; i++) {numbers[i] = ThreadLocalRandom.current().nextInt(n / 10);}}}/*** 不可变 - 新的计数值* @param state* @return*/@Benchmark@BenchmarkMode(Mode.AverageTime)@OutputTimeUnit(TimeUnit.NANOSECONDS)public Map<Integer, Integer> loop1(MyState state) {Map<Integer, Integer> map = new HashMap<>();for (int number : state.numbers) {map.merge(number, 1, Integer::sum);}return map;}/*** AtomicInteger对象* @param state* @return*/@Benchmark@BenchmarkMode(Mode.AverageTime)@OutputTimeUnit(TimeUnit.NANOSECONDS)public Map<Integer, AtomicInteger> loop2(MyState state) {Map<Integer, AtomicInteger> map = new HashMap<>();for (int number : state.numbers) {map.computeIfAbsent(number, k -> new AtomicInteger()).getAndIncrement();}return map;}/*** 单线程* @param state* @return*/@Benchmark@BenchmarkMode(Mode.AverageTime)@OutputTimeUnit(TimeUnit.NANOSECONDS)public Map<Integer, Long> sequence(MyState state) {return Arrays.stream(state.numbers).boxed().collect(groupingBy(Function.identity(), counting())); // 数字相同的分到一组,值为出现次数}/*** 并行流 - 用hashMap收集* @param state* @return*/@Benchmark@BenchmarkMode(Mode.AverageTime)@OutputTimeUnit(TimeUnit.NANOSECONDS)public Map<Integer, Long> parallelNoConcurrent(MyState state) {return Arrays.stream(state.numbers).boxed().parallel().collect(groupingBy(Function.identity(), counting()));}/*** 并行流 - 内部用支持并发的容器concurrentHashMap(容器数量为1)* @param state* @return*/@Benchmark@BenchmarkMode(Mode.AverageTime)@OutputTimeUnit(TimeUnit.NANOSECONDS)public ConcurrentMap<Integer, Long> parallelConcurrent(MyState state) {return Arrays.stream(state.numbers).boxed().parallel().collect(groupingByConcurrent(Function.identity(), counting()));}public static void main(String[] args) throws RunnerException, ExecutionException, InterruptedException {Options opt = new OptionsBuilder().include(T03Concurrent.class.getSimpleName()).forks(1).build();new Runner(opt).run();
// MyState state = new MyState();
// T03Concurrent test = new T03Concurrent();
// System.out.println(test.loop1(state));
// System.out.println(test.loop2(state));
// System.out.println(test.sequence(state));
// System.out.println(test.parallelNoConcurrent(state));
// System.out.println(test.parallelConcurrent(state));}
}
测试结果对比:
- 元素个数为100时:
| Benchmark | Mode | Cnt | Score (ns/op) | Error (ns/op) | Units |
|---|---|---|---|---|---|
| loop1 | avgt | 5 | 1312.389 | ± 90.683 | ns/op |
| loop2 | avgt | 5 | 1776.391 | ± 255.271 | ns/op |
| sequence | avgt | 5 | 1727.739 | ± 28.821 | ns/op |
| parallelNoConcurrent | avgt | 5 | 27654.004 | ± 496.970 | ns/op |
| parallelConcurrent | avgt | 5 | 16320.113 | ± 344.766 | ns/op |
- 元素个数为10000时:
| Benchmark | Mode | Cnt | Score (ns/op) | Error (ns/op) | Units |
|---|---|---|---|---|---|
| loop1 | avgt | 5 | 211526.546 | ± 13549.703 | ns/op |
| loop2 | avgt | 5 | 203794.146 | ± 3525.972 | ns/op |
| sequence | avgt | 5 | 237688.651 | ± 7593.483 | ns/op |
| parallelNoConcurrent | avgt | 5 | 527203.976 | ± 3496.107 | ns/op |
| parallelConcurrent | avgt | 5 | 369630.728 | ± 20549.731 | ns/op |
- 元素个数为1000000时:
| Benchmark | Mode | Cnt | Score (ms/op) | Error (ms/op) | Units |
|---|---|---|---|---|---|
| loop1 | avgt | 5 | 69.154 | ± 3.456 | ms/op |
| loop2 | avgt | 5 | 83.815 | ± 2.307 | ms/op |
| sequence | avgt | 5 | 103.585 | ± 0.834 | ns/op |
| parallelNoConcurrent | avgt | 5 | 167.032 | ± 15.406 | ms/op |
| parallelConcurrent | avgt | 5 | 52.326 | ± 1.501 | ms/op |
结论:
- sequence是一个容器单线程收集,数据量少时性能占优;
- parallelNoConcurrent是多个容器多线程并行收集,时间应该花费在合并容器上,性能最差;
- parallelConcurrent是一个容器多线程并发收集,在数据量大时性能较优。
示例4:MethodHandle性能
package jmh;import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;import java.lang.invoke.MethodHandle;
import java.lang.invoke.MethodHandles;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.util.function.BinaryOperator;public class Sample2 {/*** 普通方法调用* @return*/@Benchmarkpublic int origin() {return add(1, 2);}static int add(int a, int b) {return a + b;}// ----------------------------static Method method;static MethodHandle methodHandle;static {try {method = Sample2.class.getDeclaredMethod("add", int.class, int.class);methodHandle = MethodHandles.lookup().unreflect(method);} catch (NoSuchMethodException | IllegalAccessException e) {throw new RuntimeException(e);}}/*** 反射* @return* @throws InvocationTargetException* @throws IllegalAccessException*/@Benchmarkpublic Object reflection() throws InvocationTargetException, IllegalAccessException {// 动态调用add方法return method.invoke(null, 1, 2);}/*** MethodHandle* @return* @throws Throwable*/@Benchmarkpublic Object method() throws Throwable {// 使用MethodHandle调用add方法,比反射更轻量级,更接近JVM底层调用机制return methodHandle.invoke(1, 2);}// ----------------------------------/*** Lambda* @return*/@Benchmarkpublic int lambda() {return test(Integer::sum, 1, 2);}@FunctionalInterfaceinterface Add {int add(int a, int b);}static int test(Add add, int a, int b) {return add.add(a, b);}public static void main(String[] args) throws RunnerException {Options opt = new OptionsBuilder().include(Sample2.class.getSimpleName()).forks(1).build();new Runner(opt).run();}
}测试结果对比:
| Benchmark | Mode | Cnt | Score | Error | Units |
|---|---|---|---|---|---|
| Sample2.lambda | thrpt | 5 | 389307532.881 | ± 332213073.039 | ops/s |
| Sample2.method | thrpt | 5 | 157556577.611 | ± 4048306.620 | ops/s |
| Sample2.origin | thrpt | 5 | 413287866.949 | ± 65182730.966 | ops/s |
| Sample2.reflection | thrpt | 5 | 91640751.456 | ± 37969233.369 | ops/s |
结论:
- 普通方法调用最快,Lambda性能接近普通方法,MethodHandle性能约为普通方法的38%,反射Reflection最慢,仅为普通方法的22%。
- 尽量使用普通方法或Lambda,避免使用反射