操作系统:文件系统笔记
文件系统
参考资料:
- 12.10 虚拟文件系统_哔哩哔哩_bilibili
- 7.1 文件系统全家桶 | 小林coding
基本组成
文件系统是操作系统中负责管理持久数据的子系统,说简单点,就是负责把用户的文件存到磁盘硬件中,因为即使计算机断电了,磁盘里的数据并不会丢失,所以可以持久化的保存文件。
Linux 最经典的一句话是:「一切皆文件」,不仅普通的文件和目录,就连块设备、管道、socket 等,也都是统一交给文件系统管理的。
每个文件由两个核心数据结构描述:inode(元信息)和dentry(目录层级关系)。
索引节点(inode):身份证,找到对应数据块
-
功能:记录文件的元信息,是文件的唯一标识。
-
存储位置:存放在磁盘中,占用磁盘空间。
-
核心字段
- inode 编号(唯一标识)
- 文件大小、访问权限(读 / 写 / 执行)
- 时间戳(创建时间、修改时间、访问时间)
- 数据块在磁盘中的位置(指针数组)
- 文件类型(普通文件、目录、设备文件等)
-
一一对应:每个文件对应唯一的 inode,即使文件名不同(如硬链接)。
-
不记录文件名:仅存储文件属性和数据位置,文件名由 dentry 管理。
目录项(dentry):从文件名(字符串),找索引节点
元数据定址: 通过文件名→目录项→找到 inode 编号→读取 inode。
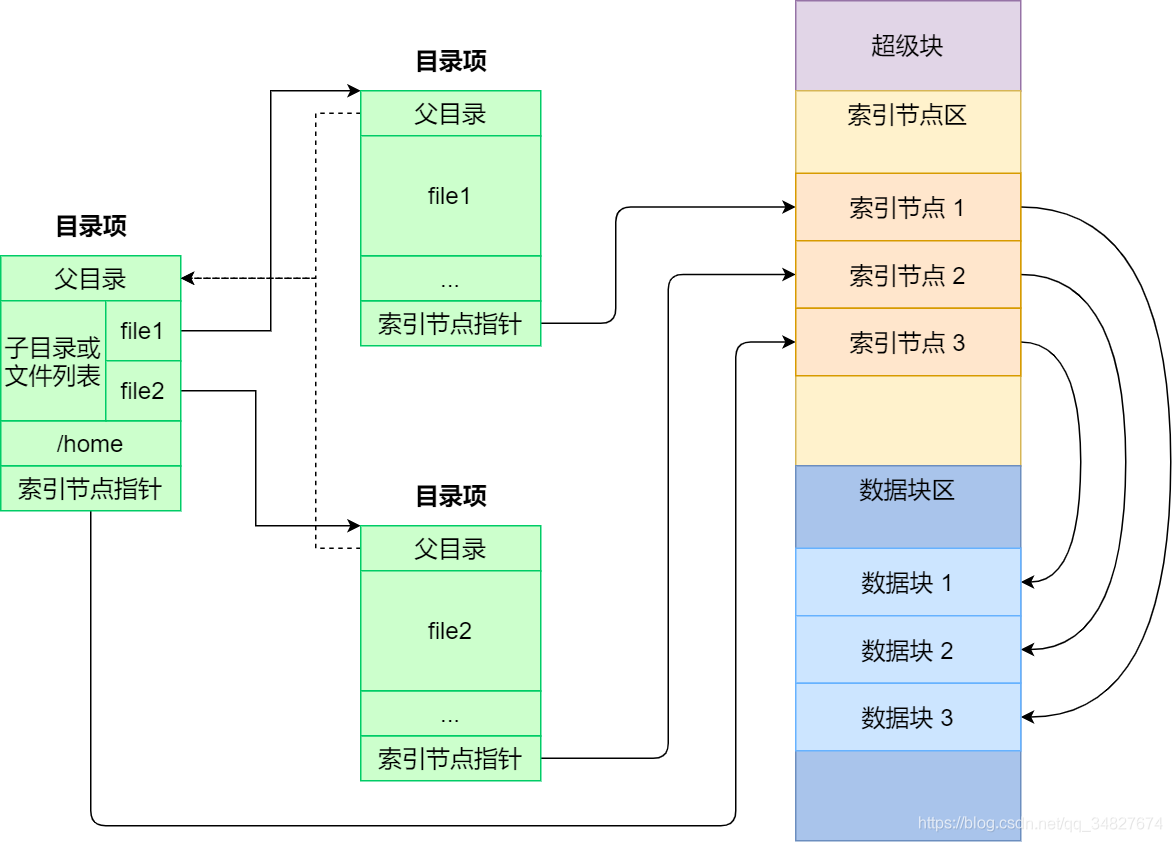
目录项,就是目录文件中的数据。
目录在磁盘上的“内容”就是其包含的文件和子目录的目录项列表((文件名, inode编号)),这些列表存储在分配给该目录的数据块中。
再把目录项缓存到内存中,dcache
- 内存加速:内核缓存最近访问的
(父目录dentry, 文件名) → 子dentry映射 - 避免磁盘 I/O:若缓存命中,直接返回 inode,无需扫描目录数据块
目录文件里面有什么
目录文件本质上是一个特殊的“映射表”文件,其数据块中存储的是「目录项列表」(Directory Entry List),通过这个列表实现文件名到 inode 编号的直接映射
目录文件的数据块中存储的是 ext2_dir_entry_2 结构体数组(以 Ext2 为例),每个结构体代表一个目录项,包含:
struct ext2_dir_entry_2 {__le32 inode; // 文件/子目录的 inode 编号(4字节)__le16 rec_len; // 当前目录项的总长度(含填充,2字节)__u8 name_len; // 文件名实际长度(1字节)__u8 file_type; // 文件类型(普通/目录/符号链接等,1字节)char name[]; // 文件名(变长数组,1-255字节)
};
- 每个目录至少包含两个特殊项:
.(当前目录)和..(父目录) rec_len确保目录项按 4 字节对齐(提升访问效率)file_type直接记录类型,避免为判断类型而读 inode
示例目录 /home 的数据块内容(二进制简化视图):
+-----------------------------------------------------------------------------------------+
| inode=2 | rec_len=12 | name_len=1 | file_type=DIR | "." | ← 当前目录 (链接到 inode 2) |
|---------|------------|------------|---------------|------|-------------------------------|
| inode=2 | rec_len=12 | name_len=2 | file_type=DIR | ".." | ← 父目录 (链接到根目录 inode 2) |
|---------|------------|------------|---------------|------|-------------------------------|
| inode=12| rec_len=16 | name_len=4 | file_type=DIR | "user" | ← 子目录 user |
|---------|------------|------------|---------------|--------|-----------------------------|
| inode=45| rec_len=20 | name_len=8 | file_type=REG | "file.txt" | ← 普通文件 file.txt |
|---------|------------|------------|---------------|------------|-------------------------|
| ... (剩余空间用 0 填充) |
+-----------------------------------------------------------------------------------------+
如何通过文件名找到 inode 节点?
查找流程(以查找 /home/user/file.txt 为例):
步骤 1:解析路径,逐级进入目录
- 从根目录开始(根目录 inode 固定为 2)
- 读取根目录的 数据块 → 在目录项列表中查找
home- 找到条目:
name="home", inode=12, file_type=DIR
- 找到条目:
- 进入
home目录(加载 inode 12)
步骤 2:在目录数据块中线性扫描
-
读取
home目录的数据块(根据 inode 12 的指针定位) -
遍历目录项列表,查找
username="user", inode=30, file_type=DIR
步骤 3:重复直至找到目标文件
- 进入
user目录(加载 inode 30) - 扫描其数据块,查找
file.txt- 找到条目:
name="file.txt", inode=45, file_type=REG
- 找到条目:
- 最终获得目标文件的 inode 编号:45
步骤 4:加载文件 inode
- 根据 inode 编号 45 计算所在块组:
块组号 = (45 - 1) / inodes_per_group - 从该块组的 inode 表 中读取 inode 45 的元数据
- 通过 inode 中的 数据块指针 访问文件内容

现代的改进:
目录项缓存(dcache):就是内存中的目录项
- 内存加速:内核缓存最近访问的
(父目录dentry, 文件名) → 子dentry映射 - 避免磁盘 I/O:若缓存命中,直接返回 inode,无需扫描目录数据块
Ext2 使用线性扫描(效率低),现代文件系统引入优化:
| 文件系统 | 优化方式 | 效果 |
|---|---|---|
| Ext3 | 线性扫描 + 目录索引块 | 中等规模目录效率提升 |
| Ext4 | HTree (B树变种) + 哈希索引 | 支持百万级文件目录的快速查找 |
| XFS | B+树组织目录项 | 极速查找 + 高效插入/删除 |
🔍Ext4 的 HTree 示例:
- 对文件名计算哈希值(如
MurmurHash3)- 在目录数据块中建立 B树结构,按哈希值排序
- 查找时:计算
file.txt的哈希值 → 在 B树中快速定位
目录文件就是一张“文件名-inode对照表”,查找文件就是逐级查表的过程。
那文件数据是如何存储在磁盘的呢?
扇区、数据块的大小
磁盘读写的最小单位是扇区,扇区的大小只有 512B 大小,很明显,如果每次读写都以这么小为单位,那这读写的效率会非常低。
所以,文件系统把多个扇区组成了一个逻辑块,每次读写的最小单位就是逻辑块(数据块),Linux 中的逻辑块大小为 4KB,也就是一次性读写 8 个扇区,这将大大提高了磁盘的读写的效率。
下图的目录项,可能是内存中的缓存,或者目录文件的
另外,磁盘进行格式化的时候,会被分成三个存储区域,分别是超级块、索引节点区和数据块区。
- 超级块,用来存储文件系统的详细信息,比如块个数、块大小、空闲块等等。
- 索引节点区,用来存储索引节点;
- 数据块区,用来存储文件或目录数据;
我们不可能把超级块和索引节点区全部加载到内存,这样内存肯定撑不住,所以只有当需要使用的时候,才将其加载进内存,它们加载进内存的时机是不同的:
- 超级块:当文件系统挂载时进入内存;
- 索引节点区:当文件被访问时进入内存;
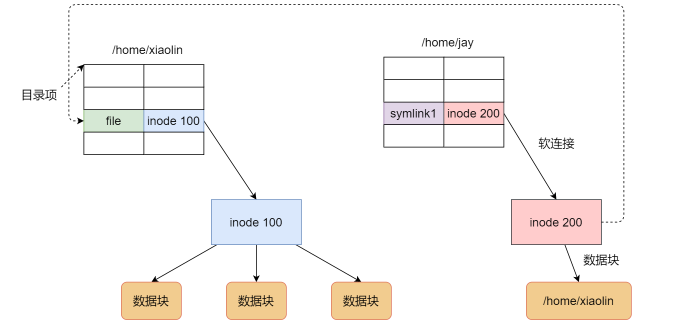
软连接和硬链接
硬链接:
硬链接是多个目录项中的「索引节点」指向一个文件,也就是指向同一个 inode,但是 inode 是不可能跨越文件系统的,每个文件系统都有各自的 inode 数据结构和列表,所以硬链接是不可用于跨文件系统的。
由于多个目录项都是指向一个 inode,那么只有删除文件的所有硬链接以及源文件时,系统才会彻底删除该文件。
- inode 共享
- 所有硬链接共享相同的 inode 编号 和 数据块。
- 修改任一链接,其他链接同步更新(本质是修改同一文件)。
- 链接计数:像是智能指针的引用计数
- inode 中维护
链接计数(Link Count),记录指向它的目录项数量。 - 新建硬链接 → 链接计数
+1;删除链接 → 链接计数-1。 - 只有当链接计数归 0 时,文件数据才会被真正删除。
- inode 中维护
- 限制
- ❌ 不能跨文件系统(不同文件系统 inode 独立管理)。
- ❌ 不能对目录创建硬链接(防止目录环导致死循环)。
ln 源文件 硬链接名 # 创建硬链接

软链接
像是win里面的快捷方式,拥有自己的 inode 和 数据块(数据块存储目标文件的路径字符串)。
- 灵活性
- ✅ 可跨文件系统(仅存储路径字符串)。
- ✅ 可链接目录(常用场景:
ln -s /mnt/data ~/data)。
- 脆弱性
- 若目标文件被删除或移动,软链接成为 悬空链接(Dangling Link),访问时报错
No such file or directory。
- 若目标文件被删除或移动,软链接成为 悬空链接(Dangling Link),访问时报错
ln -s 目标路径 软链接名 # 创建软链接

虚拟文件系统
简单来说,对各种文件系统的封装,提供统一的API,给开发者使用
文件系统的种类众多,而操作系统希望对用户提供一个统一的接口,于是在用户层与文件系统层引入了中间层,这个中间层就称为虚拟文件系统(Virtual File System,VFS)。
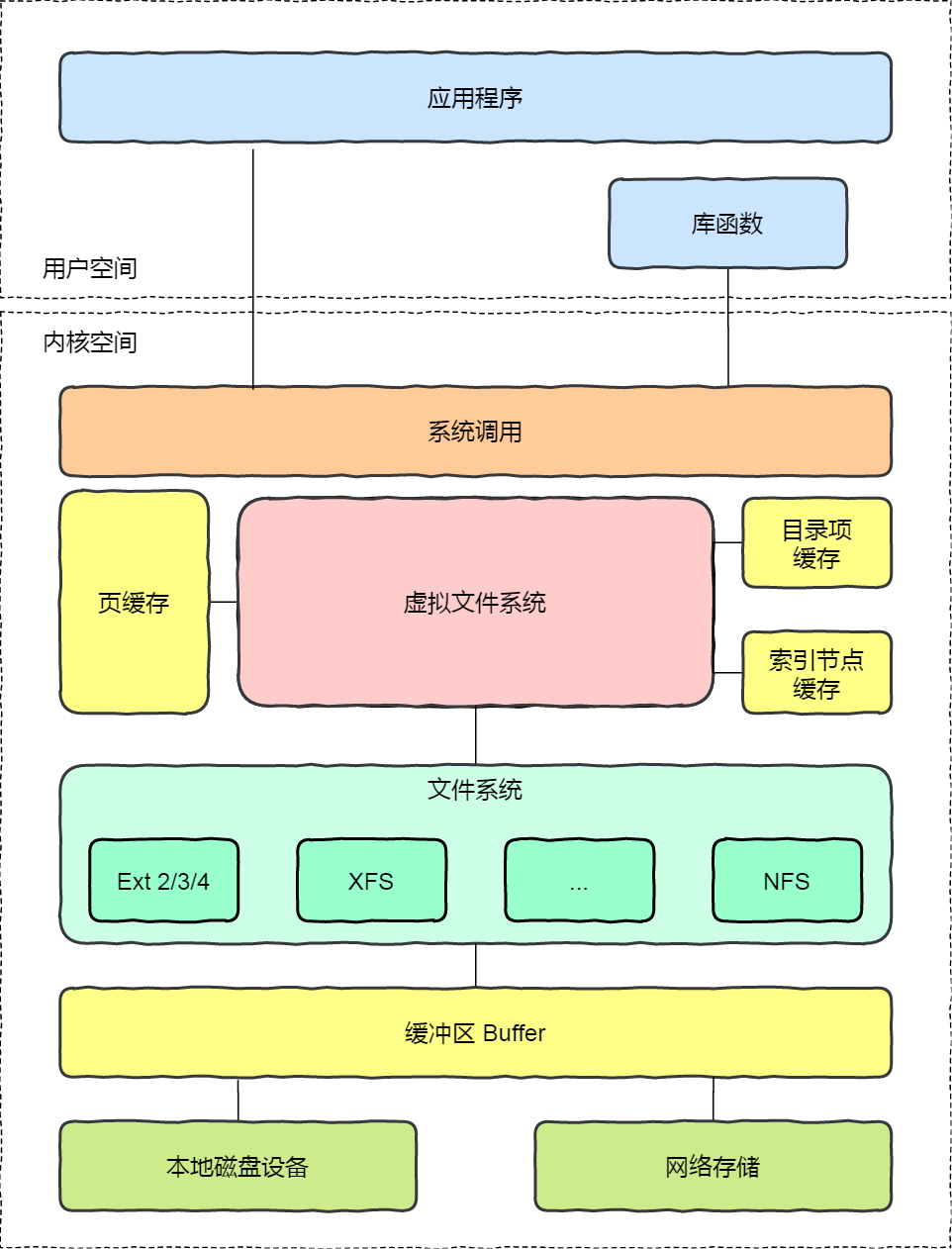
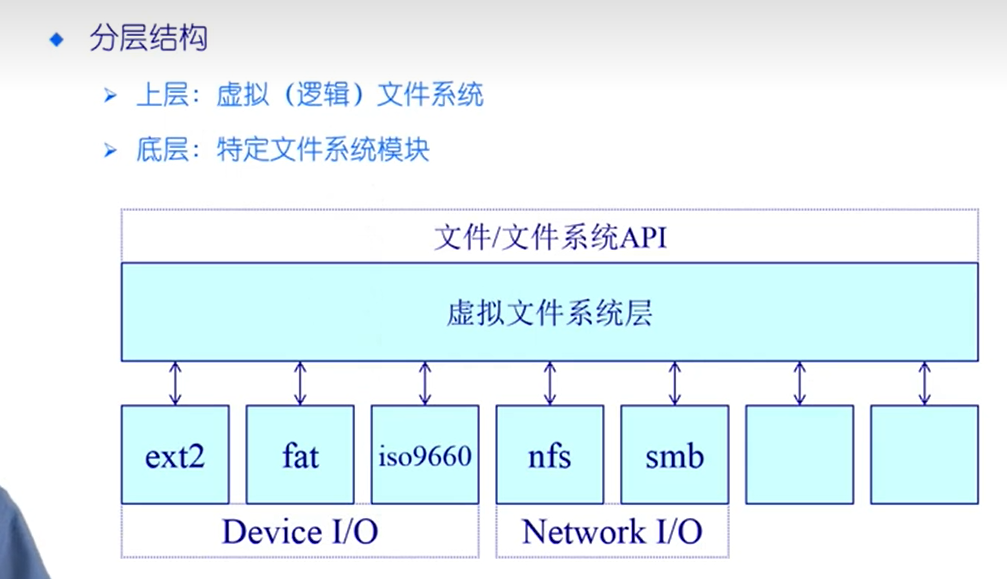


虚拟文件系统不存在在硬盘里面,是内存中的概念,当操作系统创建好之后,操作系统会将虚拟文件系统这个子系统创建好。
文件系统的数据结构:都在磁盘中
- 卷控制块:超级块
- 文件控制块:
inode - 目录节点:
dentry

数据都在磁盘中的数据块中,这些内容都在磁盘中,什么时候能加载到内存中来
- 卷控制块:卷控制模块 : 当文件系统挂载时进入内存
- 文件控制块: 当文件被访问时进入每次
- 目录节点: 在遍历一个文件路径时进入内存

目录节点是什么?
是目录文件里面的目录项吗?不知道
接下来介绍文件系统的类型
Linux 支持的文件系统也不少,根据存储位置的不同,可以把文件系统分为三类:
- 磁盘的文件系统,它是直接把数据存储在磁盘中,比如 Ext 2/3/4、XFS 等都是这类文件系统。
- 内存的文件系统,这类文件系统的数据不是存储在硬盘的,而是占用内存空间,我们经常用到的
/proc和/sys文件系统都属于这一类,读写这类文件,实际上是读写内核中相关的数据数据。 - 网络的文件系统,用来访问其他计算机主机数据的文件系统,比如 NFS、SMB 等等。
文件系统首先要先挂载到某个目录才可以正常使用,比如 Linux 系统在启动时,会把文件系统挂载到根目录。
数据块缓存
知识点结构:

硬盘比较大,但是比内存慢:所以需要缓存技术,把数据从硬盘读到内存中来,接下来的访问都在内存中进行,提高速度
这就是所谓的buff,数据缓存技术,data buff技术
data buff技术读入内存有几种方式:
- 按需读入,需要了再读进内存
- 预读取:提前读入内存
写磁盘也是一样:可能多次写入,就在内存中操作,延迟写入磁盘
缓存的数据的单位也不同:两种数据块的缓存方式
- 普通的缓冲区缓存
- 页缓存:结合分页机制

希望能和分页结合:实现基于分页的缓存机制:使得数据更好与应用程序交互
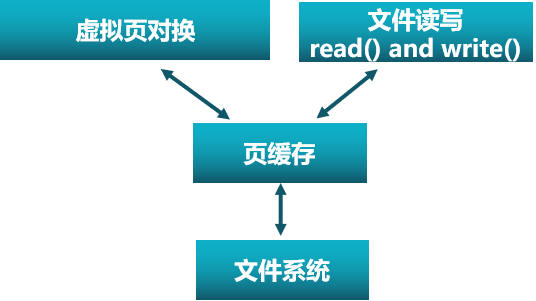
这里介绍不多:涉及到缓冲区的大小和页置换算法,缓冲区到底放哪些页
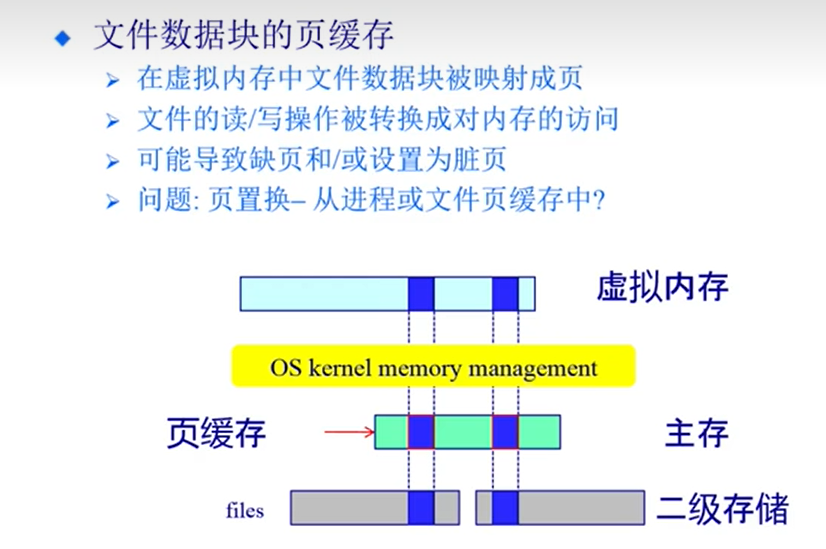
打开文件的数据结构

这里就是文件描述符,通过进程打开文件表、系统级的打开文件表,找到索引节点
打开文件:返回文件描述符的过程
- 首先找文件在硬盘上什么地方。
- 所谓打开,把硬盘中存的那个关于文件的文件控制块的内容读到内存中。
- 把相关的文件信息,放在打开文件表中,成为其中的一个项。
- 再把这个项的索引index返回给我们,就是文件描述符。
这中间还有一层系统打开文件表:可能不同进程访问同一个文件,系统打开文件表只要一个项即可
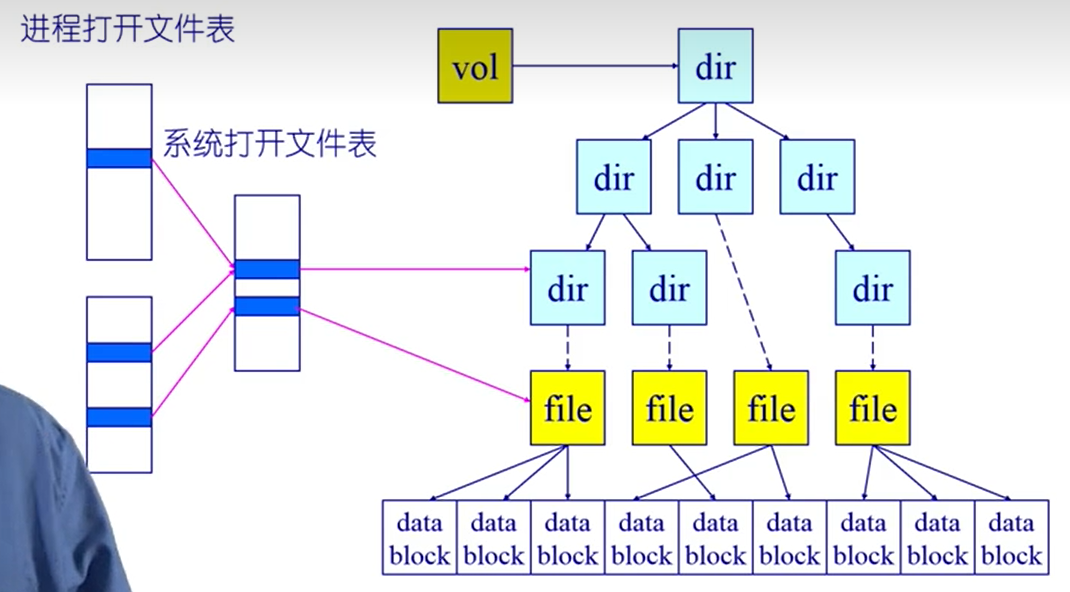
返回的文件描述符,会找到系统打开文件表的对应的项,从而找到文件的inode信息,从而确定在磁盘中的位置,进而再把磁盘的对应的数据块读入内存,进行操作。
每个文件都有inode,存放了这个文件的信息,像是身份证,身份证号唯一。
索引节点,也就是 inode,用来记录文件的元信息,比如 inode 编号、文件大小、访问权限、创建时间、修改时间、数据在磁盘的位置等等。索引节点是文件的唯一标识,它们之间一一对应,也同样都会被存储在硬盘中,所以索引节点同样占用磁盘空间。
一些文件系统提供文件锁,用于协调多进程的文件访问
- 强制 – 根据锁保持情况和访问需求确定是否拒绝访问
- 劝告 – 进程可以查找锁的状态来决定怎么做
在图解系统中对应的是文件的使用:
操作文件会返回一个文件描述符,每一个进程一个进程打开文件表,文件描述符是int,对应的打开文件表的一项,操作系统在打开文件表中维护着打开文件的状态和信息:
- 文件指针
- 文件打开计数器
- 文件磁盘位置
- 访问权限
我们从用户角度来看文件的话,就是我们要怎么使用文件?首先,我们得通过系统调用来打开一个文件。
fd = open(name, flag); # 打开文件 ... write(fd,...); # 写数据 ... close(fd); # 关闭文件上面简单的代码是读取一个文件的过程: - 首先用
open系统调用打开文件,open的参数中包含文件的路径名和文件名。 - 使用write写数据,其中write使用open所返回的文件描述符,并不使用文件名作为参数。 - 使用完文件后,要用close系统调用关闭文件,避免资源的泄露。我们打开了一个文件后,操作系统会跟踪进程打开的所有文件,所谓的跟踪呢,就是操作系统为每个进程维护一个打开文件表,文件表里的每一项代表「文件描述符」,所以说文件描述符是打开文件的标识。
操作系统在打开文件表中维护着打开文件的状态和信息:
- 文件指针:系统跟踪上次读写位置作为当前文件位置指针,这种指针对打开文件的某个进程来说是唯一的;
- 文件打开计数器:文件关闭时,操作系统必须重用其打开文件表条目,否则表内空间不够用。因为多个进程可能打开同一个文件,所以系统在删除打开文件条目之前,必须等待最后一个进程关闭文件,该计数器跟踪打开和关闭的数量,当该计数为 0 时,系统关闭文件,删除该条目;
- 文件磁盘位置:绝大多数文件操作都要求系统修改文件数据,该信息保存在内存中,以免每个操作都从磁盘中读取;
- 访问权限:每个进程打开文件都需要有一个访问模式(创建、只读、读写、添加等),该信息保存在进程的打开文件表中,以便操作系统能允许或拒绝之后的 I/O 请求;
用户操作文件都是修改字节,但是而操作系统则是以数据块来读写文件,那屏蔽掉这种差异的工作就是文件系统了。
我们来分别看一下,读文件和写文件的过程:
- 当用户进程从文件读取 1 个字节大小的数据时,文件系统则需要获取字节所在的数据块,再返回数据块对应的用户进程所需的数据部分。
- 当用户进程把 1 个字节大小的数据写进文件时,文件系统则找到需要写入数据的数据块的位置,然后修改数据块中对应的部分,最后再把数据块写回磁盘。
所以说,文件系统的基本操作单位是数据块。

文件的分配、存储
问题:文件有大小,如何为文件分配数据块
分配方式:
- 连续分配
- 链式分配
- 索引分配
好坏的指标:
- 高效:存储利用:外部碎片问题
- 访问速度
连续分配
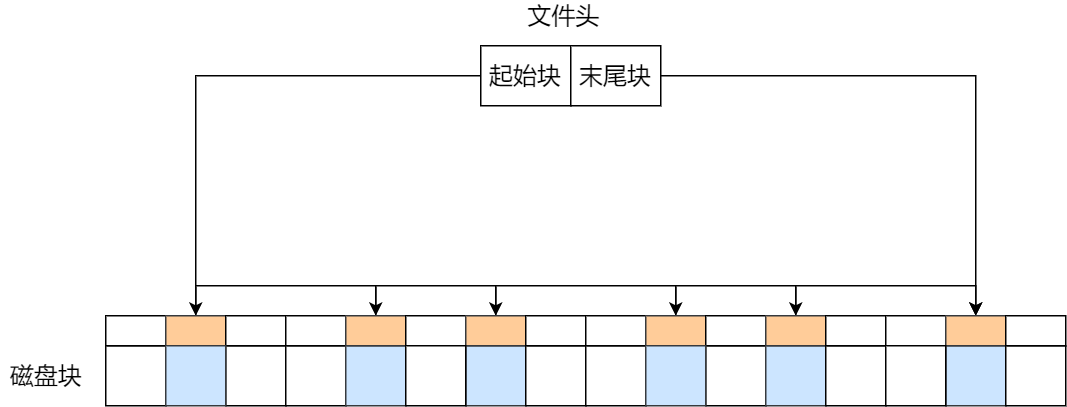
文件存放在磁盘「连续的」物理空间中。这种模式下,文件的数据都是紧密相连,读写效率很高,因为一次磁盘寻道就可以读出整个文件。
使用连续存放的方式有一个前提,必须先知道一个文件的大小,这样文件系统才会根据文件的大小在磁盘上找到一块连续的空间分配给文件。
所以,文件头里需要指定「起始块的位置」和「长度」,有了这两个信息就可以很好的表示文件存放方式是一块连续的磁盘空间。
优势:
- 读写很方便:一次磁盘寻道就可以读出整个文件。
- 高效的顺序和随机读取

缺点:
- 「磁盘空间碎片」
- 「文件长度不易扩展」。
例子:文件删除和扩展,空间变换,造成预分配的空间不够,产生内存碎片
链式分配
使用链表,链表的方式存放是离散的,不用连续的
链表的方式解决了连续分配的磁盘碎片和文件动态扩展的问题
优点:
- 消除磁盘碎片
- 文件的长度可以动态扩展
根据实现方式不同又分成
- 隐式链表
- 显式链接
首先介绍隐式链表分配:
实现的方式是文件头要包含「第一块」和「最后一块」的位置,并且每个数据块里面留出一个指针空间,用来存放下一个数据块的位置。正常的链表的思路。一个数据块指向下一个数据块。
隐式链表分配缺点也很明显:
- 缺点在于无法直接访问数据块,只能通过指针顺序访问文件
- 数据块指针占有一定的存储空间。
- 稳定性差,系统在运行过程中由于软件或者硬件错误导致链表中的指针丢失或损坏,会导致文件数据的丢失。
接下来,显式链表分配:
实现的方式是:把用于链接文件各数据块的指针,显式地存放在内存的一张链接表中,该表在整个磁盘仅设置一张,每个表项中存放链接指针,指向下一个数据块号。
内存中的这样一个表格称为文件分配表(*File Allocation Table,[FAT]*)
对于显式链接的工作方式,我们举个例子,文件 A 依次使用了磁盘块 4、7、2、10 和 12 ,文件 B 依次使用了磁盘块 6、3、11 和 14 。利用下图中的表,可以从第 4 块开始,顺着链走到最后,找到文件 A 的全部磁盘块。同样,从第 6 块开始,顺着链走到最后,也能够找出文件 B 的全部磁盘块。最后,这两个链都以一个不属于有效磁盘编号的特殊标记(如 -1 )结束。
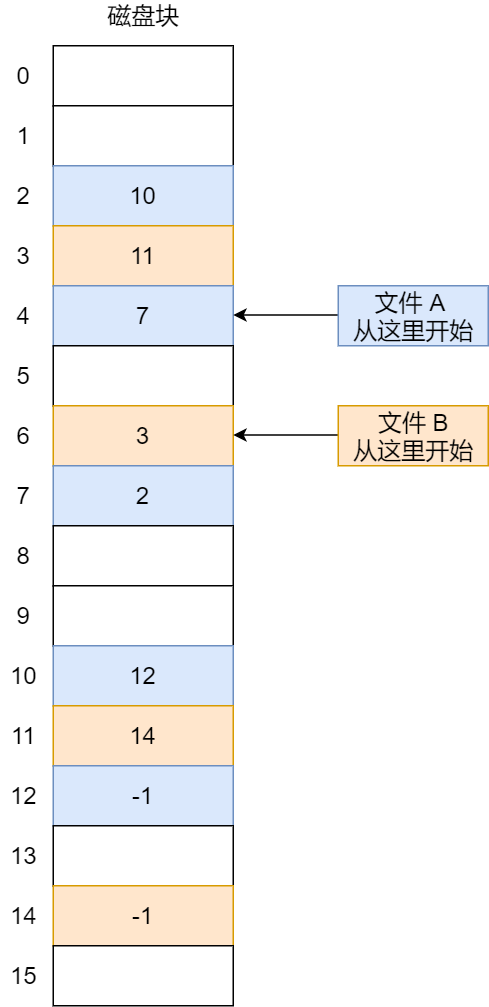
优点:
- 文件分配表在内存中:提高了检索速度、大大减少了访问磁盘的次数:隐式的需要不断访问数据块的指针才能找到下一个数据块
- 指针都存在一个文件分配表中,不同担心链表断开。
缺点:
-
但也正是整个表都存放在内存中的关系,它的主要的缺点是不适用于大磁盘。原因如下:
比如,对于 200GB 的磁盘和 1KB 大小的块,这张表需要有 2 亿项,每一项对应于这 2 亿个磁盘块中的一个块,每项如果需要 4 个字节,那这张表要占用 800MB 内存,很显然 FAT (文件分配表)方案对于大磁盘而言不太合适。
索引分配
链表的方式解决了连续分配的磁盘碎片和文件动态扩展的问题,但是不能有效支持直接访问(FAT除外),索引的方式可以解决这个问题。
索引的实现是为每个文件创建一个「索引数据块」在磁盘中,里面存放的是指向文件数据块的指针列表,说白了就像书的目录一样,要找哪个章节的内容,看目录查就可以。
文件头包含一个指向「索引数据块」的指针,索引数据块指向文件数据块的指针列表,是一个目录。
优点:
- 文件的创建、增大、缩小很方便:也是通过指针指向数据块
- 不会有碎片的问题:目录中存放的是指针
- 支持顺序读写和随机读写:有目录
创建文件时,索引块的所有指针都设为空。当首次写入第 i 块时,先从空闲空间中取得一个块,再将其地址写到索引块的第 i 个条目。
就是写入目录当中。
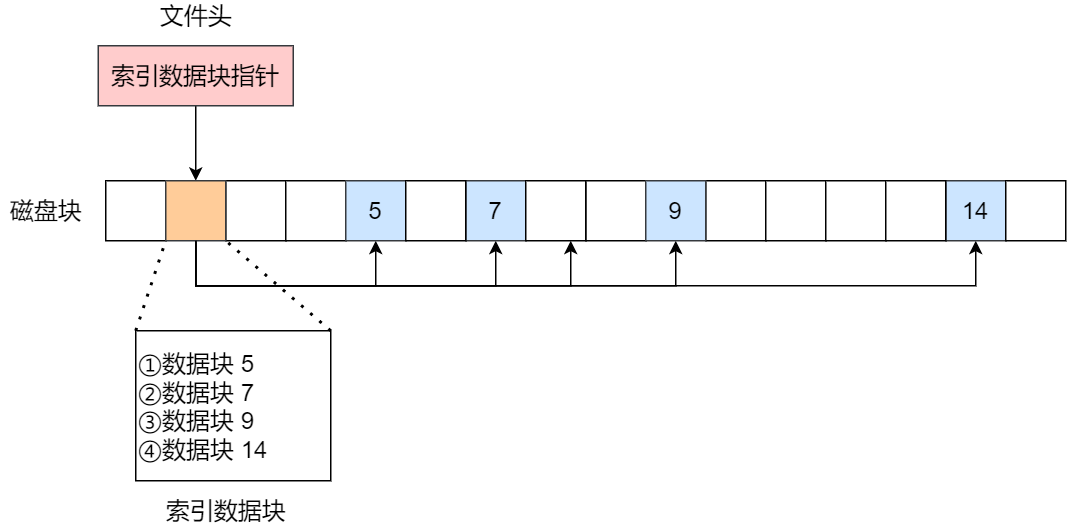
缺点:
- 如果文件很小,明明只需一块就可以存放的下,但还是需要额外分配一块来存放索引数据,所以缺陷之一就是存储索引带来的开销。:文件很小就一页,不需要目录,还需要单独开一页放目录。
如果文件很大,大到一个索引数据块放不下索引信息,这时又要如何处理大文件的存放呢?这里又回到磁盘的分配问题:还应该有链表、索引方式这里:
-
链表 + 索引:这种组合称为「链式索引块」
实现方式是在索引数据块留出一个存放下一个索引数据块的指针,于是当一个索引数据块的索引信息用完了,就可以通过指针的方式,找到下一个索引数据块的信息。那这种方式也会出现前面提到的链表方式的问题,万一某个指针损坏了,后面的数据也就会无法读取了。
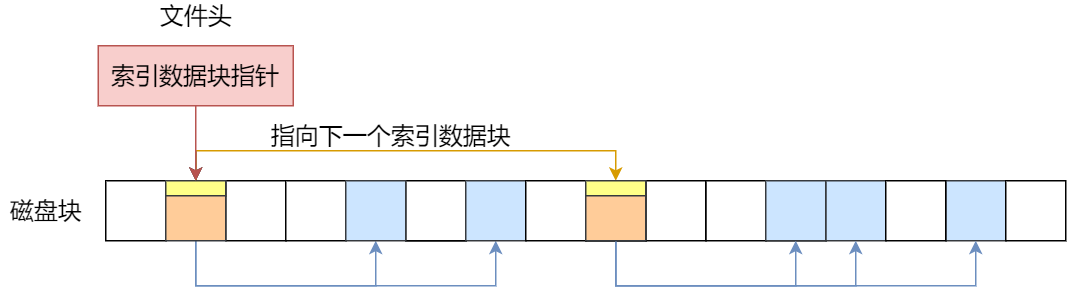
-
索引 + 索引,这种组合称为「多级索引块」
实现方式是通过一个索引块来存放多个索引数据块,一层套一层索引。
有点像多级页表。
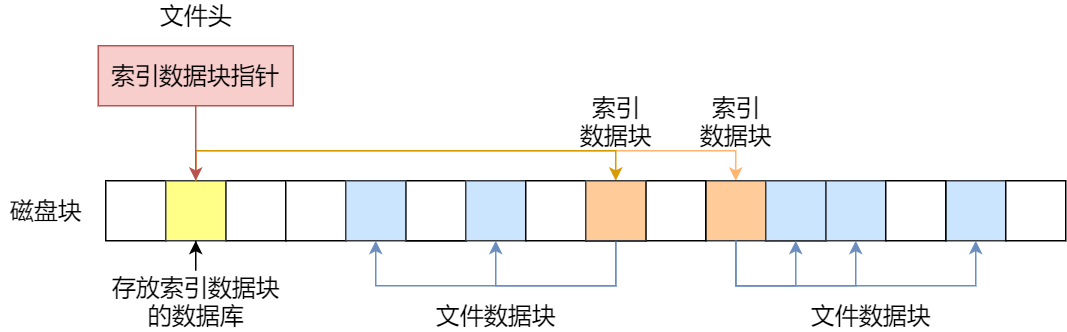

这里链表分配应该是指隐式链表。
那早期 Unix 文件系统是组合了前面的文件存放方式的优点,它是根据文件的大小,存放的方式会有所变化:
- 如果存放文件所需的数据块小于 10 块,则采用直接查找的方式;
- 如果存放文件所需的数据块超过 10 块,则采用一级间接索引方式;
- 如果前面两种方式都不够存放大文件,则采用二级间接索引方式;
- 如果二级间接索引也不够存放大文件,这采用三级间接索引方式;
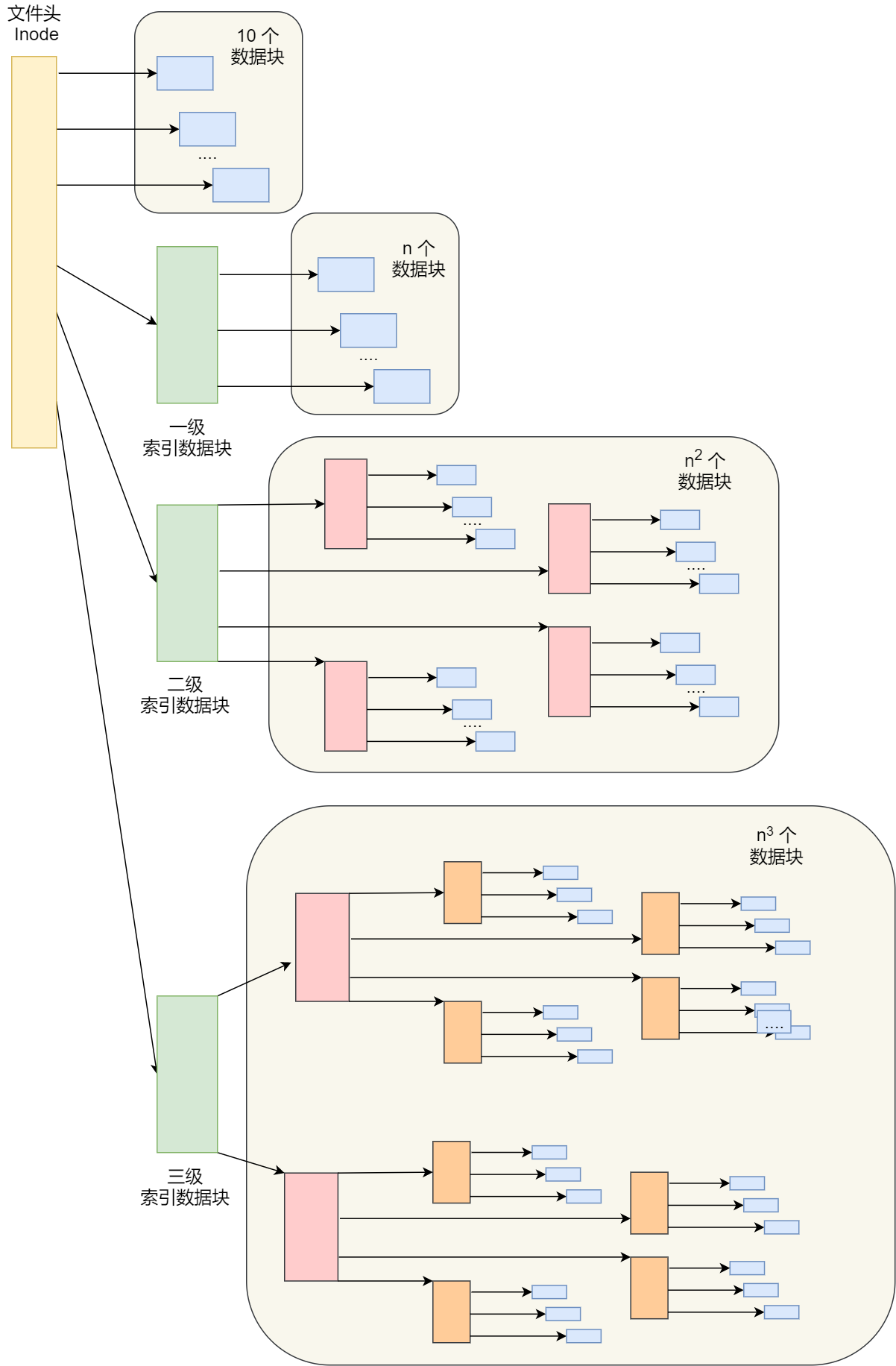
那么,文件头(Inode)就需要包含 13 个指针:
- 10 个指向数据块的指针;
- 第 11 个指向索引块的指针;
- 第 12 个指向二级索引块的指针;
- 第 13 个指向三级索引块的指针;
优点:
- 这种方式能很灵活地支持小文件和大文件的存放:
这个方案就用在了 Linux Ext 2/3 文件系统里,
缺点:
- 对于大文件则以多级索引的方式来支持,所以大文件在访问数据块时需要大量查询;
为了解决这个问题,Ext 4 做了一定的改变,具体怎么解决的
空闲空间管理
前面说到的文件的存储是针对已经被占用的数据块组织和管理,接下来的问题是,如果我要保存一个数据块,我应该放在硬盘上的哪个位置呢?
所以针对磁盘的空闲空间也是要引入管理的机制
- 空闲表法
- 空闲链表法
- 位图法
空闲表法
空闲表法就是为所有空闲空间建立一张表,表内容包括空闲区的第一个块号和该空闲区的块个数,注意,这个方式是连续分配的。如下图:
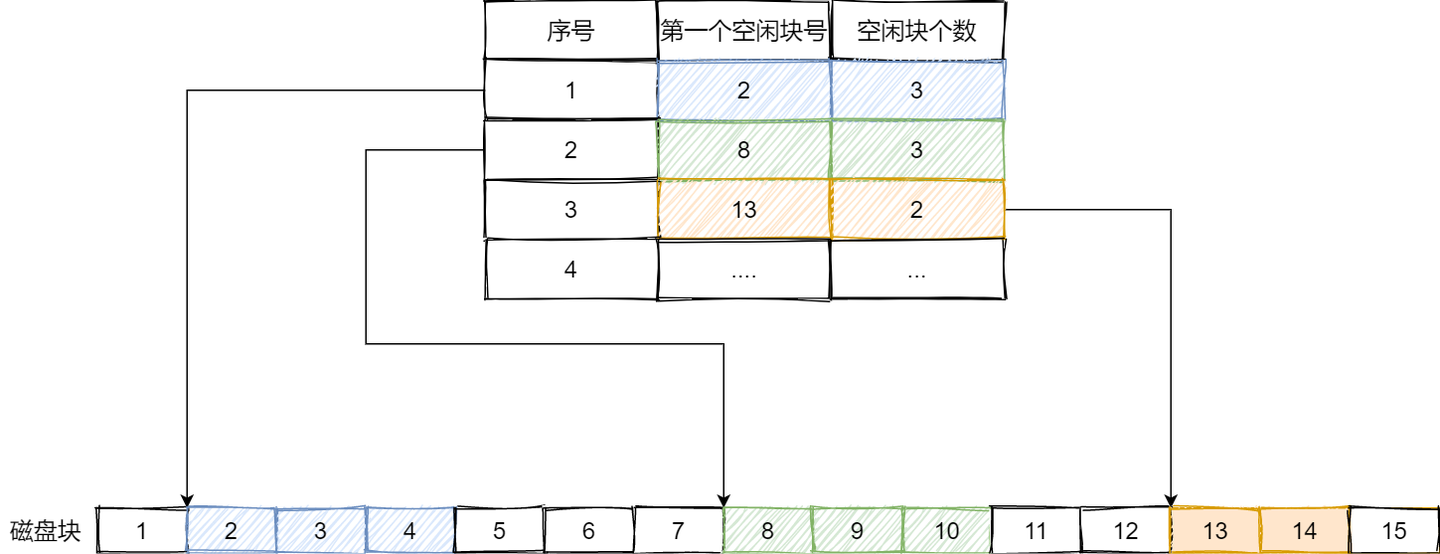
当请求分配磁盘空间时,系统依次扫描空闲表里的内容,直到找到一个合适的空闲区域为止。当用户撤销一个文件时,系统回收文件空间。这时,也需顺序扫描空闲表,寻找一个空闲表条目并将释放空间的第一个物理块号及它占用的块数填到这个条目中。
适用:
- 这种方法仅当有少量的空闲区时才有较好的效果。
缺点:
- 如果存储空间中有着大量的小的空闲区,则空闲表变得很大,这样查询效率会很低。
- 另外,这种分配技术适用于建立连续文件。
空闲链表法
我们也可以使用「链表」的方式来管理空闲空间,每一个空闲块里有一个指针指向下一个空闲块,这样也能很方便的找到空闲块并管理起来。如下图:
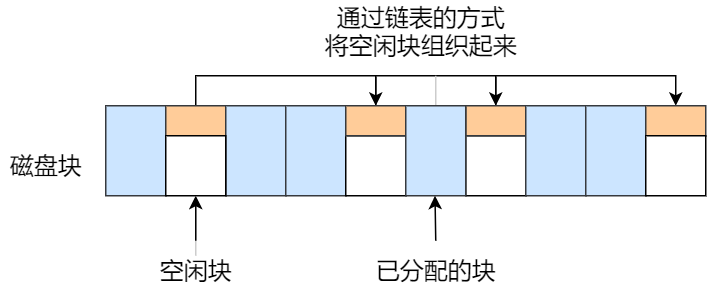
当创建文件需要一块或几块时,就从链头上依次取下一块或几块。反之,当回收空间时,把这些空闲块依次接到链头上。
这种技术只要在主存中保存一个指针,令它指向第一个空闲块。其特点是简单,但不能随机访问,工作效率低,因为每当在链上增加或移动空闲块时需要做很多 I/O 操作,同时数据块的指针消耗了一定的存储空间。
空闲表法和空闲链表法都不适合用于大型文件系统,因为这会使空闲表或空闲链表太大。
位图法:linux使用
位图是利用二进制的一位来表示磁盘中一个盘块的使用情况,磁盘上所有的盘块都有一个二进制位与之对应。
当值为 0 时,表示对应的盘块空闲,值为 1 时,表示对应的盘块已分配。它形式如下:
1111110011111110001110110111111100111 ...
在 Linux 文件系统就采用了位图的方式来管理空闲空间,不仅用于数据空闲块的管理,还用于 inode 空闲块的管理,因为 inode 也是存储在磁盘的,自然也要有对其管理。

对于160G的硬盘,40M数据块,需要5M的位图,可以接受
题目中 “40M 的 block” 应为 “4K 的 block”,此时:
- 块数量 = (160{GB} / 4{KB} = 40,960,000) 块
- 位图大小 = (40,960,000{位} / 8 = 5,120,000{字节} = 5{MB})
总结:位图大小与块大小成反比,实际文件系统中数据块大小通常为 4KB(如 ext4、NTFS),此时 160GB 硬盘的位图约为 5MB。题目可能因单位混淆(MB 误写为 KB)导致数据矛盾,修正后逻辑成立。
那文件数据是如何存储在磁盘的呢?
磁盘读写的最小单位是扇区,扇区的大小只有 512B 大小,很明显,如果每次读写都以这么小为单位,那这读写的效率会非常低。
所以,文件系统把多个扇区组成了一个逻辑块,每次读写的最小单位就是逻辑块(数据块),Linux 中的逻辑块大小为 4KB,也就是一次性读写 8 个扇区,这将大大提高了磁盘的读写的效率。
一开始需要把位图,从硬盘导入带内存中去,要考虑一致性,万一断电,内存中修改没有写入硬盘中就会出现不一致?怎么解决?
首先修改磁盘的位图对应的位置,然后再使用磁盘,最后再修改内存中的位图对应的位。

文件系统的结构
下面是图解系统的内容
https://xiaolincoding.com/os/6_file_system/file_system.html
数据块的位图是放在磁盘块里的,假设是放在一个块里,一个块 4K,每位表示一个数据块,共可以表示 4 * 1024 * 8 = 2^15 个空闲块,由于 1 个数据块是 4K 大小,那么最大可以表示的空间为 2^15 * 4 * 1024 = 2^27 个 byte,也就是 128M。
也就是说按照上面的结构,如果采用「一个块的位图 + 一系列的块」,外加「一个块的 inode 的位图 + 一系列的 inode 的结构」能表示的最大空间也就 128M,这太少了,现在很多文件都比这个大。
在 Linux 文件系统,把这个结构称为一个块组,那么有 N 多的块组,就能够表示 N 大的文件。
下图给出了 Linux Ext2 整个文件系统的结构和块组的内容,文件系统都由大量块组组成,在硬盘上相继排布:
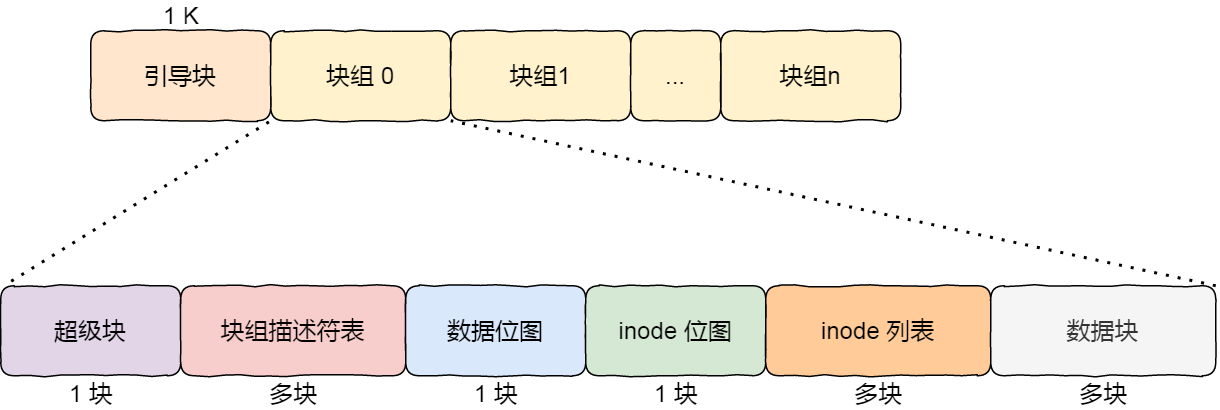
最前面的第一个块是引导块,在系统启动时用于启用引导,接着后面就是一个一个连续的块组了,块组的内容如下:
- 超级块,包含的是文件系统的重要信息,比如 inode 总个数、块总个数、每个块组的 inode 个数、每个块组的块个数等等。
- 块组描述符,包含文件系统中各个块组的状态,比如块组中空闲块和 inode 的数目等,每个块组都包含了文件系统中「所有块组的组描述符信息」。
- 数据位图和 inode 位图, 用于表示对应的数据块或 inode 是空闲的,还是被使用中。
- inode 列表,包含了块组中所有的 inode,inode 用于保存文件系统中与各个文件和目录相关的所有元数据。
- 数据块,包含文件的有用数据。
你可以会发现每个块组里有很多重复的信息,比如超级块和块组描述符表,这两个都是全局信息,而且非常的重要,这么做是有两个原因:
- 如果系统崩溃破坏了超级块或块组描述符,有关文件系统结构和内容的所有信息都会丢失。如果有冗余的副本,该信息是可能恢复的。
- 通过使文件和管理数据尽可能接近,减少了磁头寻道和旋转,这可以提高文件系统的性能。
不过,Ext2 的后续版本采用了稀疏技术。该做法是,超级块和块组描述符表不再存储到文件系统的每个块组中,而是只写入到块组 0、块组 1 和其他 ID 可以表示为 3、 5、7 的幂的块组中。
Lab9: file system
实验手册:Lab1: Xv6 and Unix utilities · 6.S081 All-In-One
优秀笔记:MIT 6.S081 Operating System - 知乎
在本实验室中,您将向xv6文件系统添加大型文件和符号链接。
git的相关操作
获取实验室的xv6源代码并切换到fs分支:
git fetch #获取远程更新,保持同步git checkout fsmake clean #删除临时文件
xv6实验git分支建议
建议是每个实验创建一个测试分支,例如对于***util***来说
git checkout fs # 切换到util分支
git checkout -b fs_test # 建立并切换到util的测试分支
当你在**util_test*分支中每测试通过一个作业,请提交(git commit)你的代码,并将所做的修改合并(git merge)到util***中,然后提交(git push)到gitee
git add .
git commit -m "完成了第一个作业"
git checkout fs
git merge fs_test
git push gitee fs:fs
Large files(moderate)
在本作业中,您将增加xv6文件的最大大小。目前,xv6文件限制为268个块或268*BSIZE字节(在xv6中BSIZE为1024)。此限制来自以下事实:一个xv6 inode包含12个“直接”块号和一个“间接”块号,“一级间接”块指一个最多可容纳256个块号的块,总共12+256=268个块。
bigfile命令可以创建最长的文件,并报告其大小:
$ bigfile
..
wrote 268 blocks
bigfile: file is too small
$测试失败,因为bigfile希望能够创建一个包含65803个块的文件,但未修改的xv6将文件限制为268个块。
您将更改xv6文件系统代码,以支持每个inode中可包含256个一级间接块地址的“二级间接”块,每个一级间接块最多可以包含256个数据块地址。结果将是一个文件将能够包含多达65803个块,或256*256+256+11个块(11而不是12,因为我们将为二级间接块牺牲一个直接块号)。
预备知识
mkfs程序创建xv6文件系统磁盘映像,并确定文件系统的总块数;此大小由***kernel/param.h***中的FSSIZE控制。您将看到,该实验室存储库中的FSSIZE设置为200000个块。您应该在make输出中看到来自mkfs/mkfs的以下输出:
nmeta 70 (boot, super, log blocks 30 inode blocks 13, bitmap blocks 25) blocks 199930 total 200000
这一行描述了mkfs/mkfs构建的文件系统:它有70个元数据块(用于描述文件系统的块)和199930个数据块,总计200000个块。
如果在实验期间的任何时候,您发现自己必须从头开始重建文件系统,您可以运行make clean,强制make重建fs.img
看什么
磁盘索引节点的格式由fs.h中的struct dinode定义。您应当尤其对NDIRECT、NINDIRECT、MAXFILE和struct dinode的addrs[]元素感兴趣。查看《XV6手册》中的图8.3,了解标准xv6索引结点的示意图。
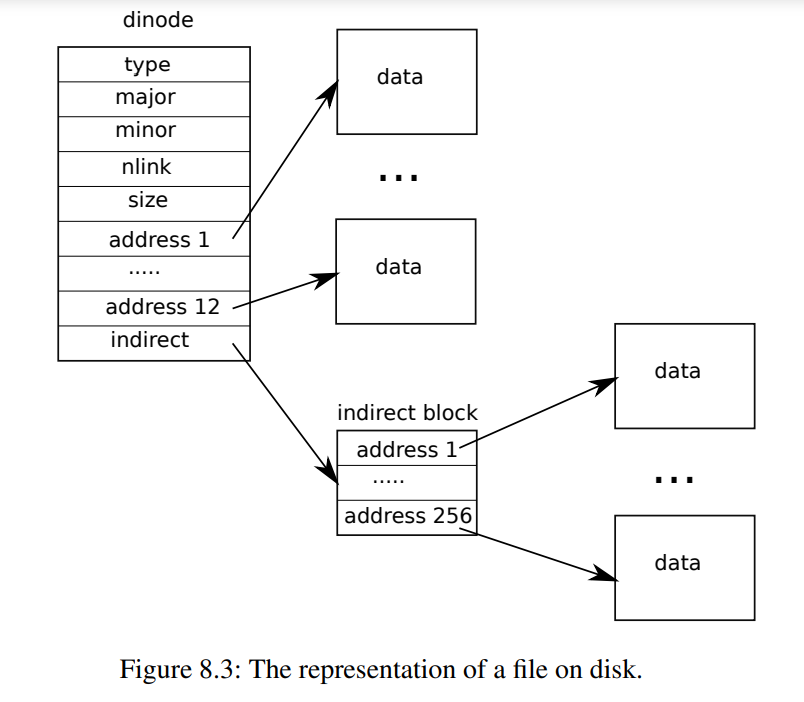
在磁盘上查找文件数据的代码位于***fs.c***的bmap()中。看看它,确保你明白它在做什么。在读取和写入文件时都会调用bmap()。写入时,bmap()会根据需要分配新块以保存文件内容,如果需要,还会分配间接块以保存块地址。
bmap()处理两种类型的块编号。bn参数是一个“逻辑块号”——文件中相对于文件开头的块号。ip->addrs[]中的块号和bread()的参数都是磁盘块号。您可以将bmap()视为将文件的逻辑块号映射到磁盘块号。
你的工作
修改bmap(),以便除了直接块和一级间接块之外,它还实现二级间接块。你只需要有11个直接块,而不是12个,为你的新的二级间接块腾出空间;不允许更改磁盘inode的大小。ip->addrs[]的前11个元素应该是直接块;第12个应该是一个一级间接块(与当前的一样);13号应该是你的新二级间接块。当bigfile写入65803个块并成功运行usertests时,此练习完成:
$ bigfile
..................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
wrote 65803 blocks
done; ok
$ usertests
...
ALL TESTS PASSED
$
运行bigfile至少需要一分钟半的时间。
提示:
- 确保您理解
bmap()。写出ip->addrs[]、间接块、二级间接块和它所指向的一级间接块以及数据块之间的关系图。确保您理解为什么添加二级间接块会将最大文件大小增加256*256个块(实际上要-1,因为您必须将直接块的数量减少一个)。 - 考虑如何使用逻辑块号索引二级间接块及其指向的间接块。
- 如果更改
NDIRECT的定义,则可能必须更改***file.h***文件中struct inode中addrs[]的声明。确保struct inode和struct dinode在其addrs[]数组中具有相同数量的元素。 - 如果更改
NDIRECT的定义,请确保创建一个新的*fs.img*,因为mkfs使用NDIRECT构建文件系统。 - 如果您的文件系统进入坏状态,可能是由于崩溃,请删除*fs.img*(从Unix而不是xv6执行此操作)。
make将为您构建一个新的干净文件系统映像。 - 别忘了把你
bread()的每一个块都brelse()。 - 您应该仅根据需要分配间接块和二级间接块,就像原始的
bmap()。 - 确保
itrunc释放文件的所有块,包括二级间接块。
上面是实验手册、以下是笔记
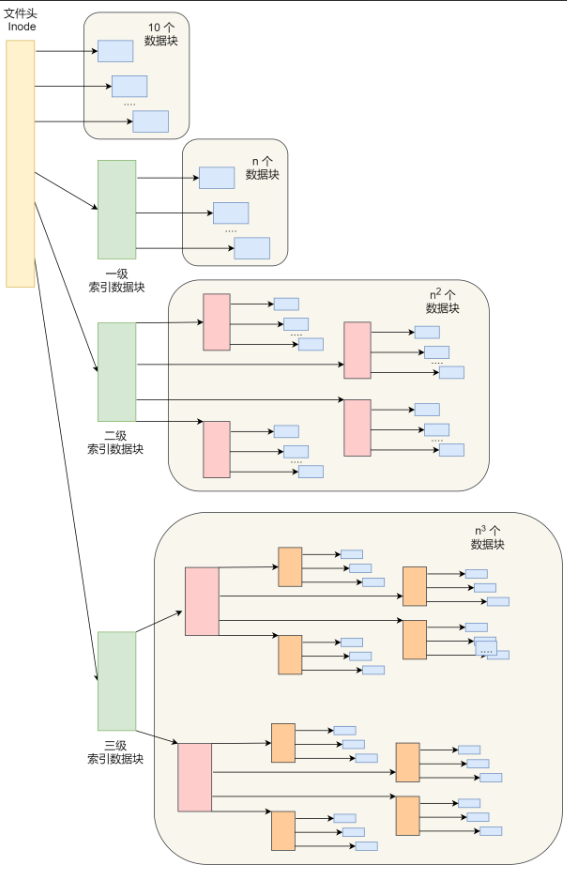
原来一个xv6 inode包含12个“直接”块号和一个“间接”块号,“一级间接”块指一个最多可容纳256个块号的块
改成二级索引:
- 修改inode数据结构
- 修改bmap()函数增加二级索引的逻辑
先看bmap()函数的原来的样子
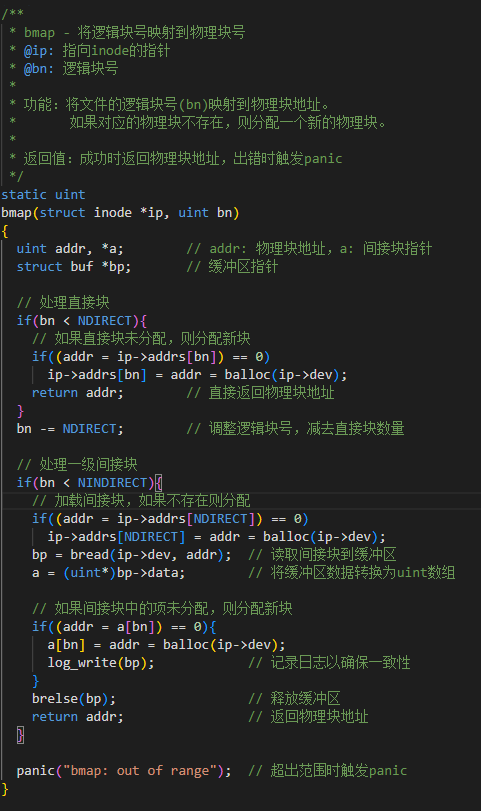
/*** bmap - 将逻辑块号映射到物理块号* @ip: 指向inode的指针* @bn: 逻辑块号* * 功能:将文件的逻辑块号(bn)映射到物理块地址。* 如果对应的物理块不存在,则分配一个新的物理块。* * 返回值:成功时返回物理块地址,出错时触发panic*/
static uint
bmap(struct inode *ip, uint bn)
{uint addr, *a; // addr: 物理块地址,a: 间接块指针struct buf *bp; // 缓冲区指针// 处理直接块if(bn < NDIRECT){// 如果直接块未分配,则分配新块if((addr = ip->addrs[bn]) == 0)ip->addrs[bn] = addr = balloc(ip->dev);return addr; // 直接返回物理块地址}bn -= NDIRECT; // 调整逻辑块号,减去直接块数量// 处理一级间接块if(bn < NINDIRECT){// 加载间接块,如果不存在则分配if((addr = ip->addrs[NDIRECT]) == 0)ip->addrs[NDIRECT] = addr = balloc(ip->dev);bp = bread(ip->dev, addr); // 读取间接块到缓冲区a = (uint*)bp->data; // 将缓冲区数据转换为uint数组// 如果间接块中的项未分配,则分配新块if((addr = a[bn]) == 0){a[bn] = addr = balloc(ip->dev);log_write(bp); // 记录日志以确保一致性}brelse(bp); // 释放缓冲区return addr; // 返回物理块地址}panic("bmap: out of range"); // 超出范围时触发panic
}
增加二级索引
首先修改宏
fs.h
#define NDIRECT 11 // inode 中直接地址项的数量 从12改成11
#define NINDIRECT (BSIZE / sizeof(uint)) // 每个间接块中的地址数量
#define NININDIRECT (NINDIRECT * NINDIRECT) // 二级间接块可容纳的地址数量
#define MAXFILE (NDIRECT + NINDIRECT + NININDIRECT )// 把直接地址项改小,然后增加二阶索引
// 这个 dinode 结构代表的是磁盘上的 inode 格式,也就是 inode 在磁盘上的存储形式。
struct dinode {short type; // 文件类型 - 例如 T_FILE、T_DIR、T_DEVshort major; // 主设备号 - 仅适用于设备文件short minor; // 次设备号 - 仅适用于设备文件short nlink; // 硬链接数 - 记录指向该inode的文件名数量uint size; // 文件大小 - 单位为字节uint addrs[NDIRECT+2]; // 数据块地址 - 包含直接块和间接块地址};
// inode 结构也要修改
struct inode {uint dev; // 设备编号 - 表明该inode位于哪个设备上uint inum; // inode编号 - 用于在设备上唯一标识一个inodeint ref; // 引用计数 - 记录当前有多少个地方引用了这个inodestruct sleeplock lock; // 睡眠锁 - 用于保护inode的下面这些字段int valid; // 有效性标志 - 标记inode是否已从磁盘读取// 以下字段是磁盘inode的内存副本short type; // 文件类型 - 可以是文件、目录、设备等short major; // 主设备号 - 用于字符设备或块设备short minor; // 次设备号 - 用于字符设备或块设备short nlink; // 硬链接数 - 记录指向该inode的文件名数量uint size; // 文件大小 - 单位为字节uint addrs[NDIRECT+2]; // 数据块地址 - 包含直接块和间接块地址};
否则在mkfs.c中有断言
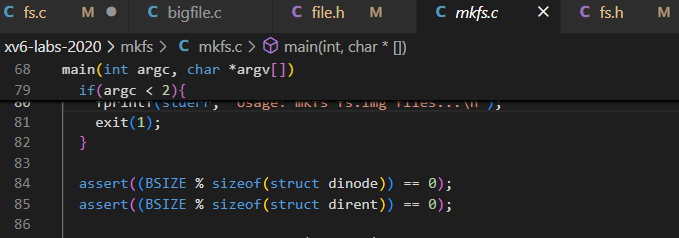
这两行代码是文件系统实现中的关键断言,用于确保块大小(BSIZE)与数据结构大小的对齐关系。它们的作用是:
assert((BSIZE % sizeof(struct dinode)) == 0);
确保块大小是磁盘 inode(struct dinode)大小的整数倍。这保证了每个块可以恰好容纳整数个 inode,不会有空间浪费或数据跨块存储的情况。assert((BSIZE % sizeof(struct dirent)) == 0);
确保块大小是目录项(struct dirent)大小的整数倍。这保证了每个块可以恰好容纳整数个目录项,使目录项的定位和管理更加高效。
/*** 处理二级间接块映射* 二级间接块包含指向间接块的指针,每个间接块再包含指向数据块的指针* 寻址公式:二级块索引 = bn / NINDIRECT,一级块索引 = bn % NINDIRECT*/bn -= NINDIRECT; // 调整逻辑块号,减去直接块数量if(bn < NININDIRECT){// 加载二级间接块(如果不存在则分配)if((addr = ip->addrs[NDIRECT+1]) == 0)ip->addrs[NDIRECT+1] = addr = balloc(ip->dev);bp = bread(ip->dev, addr); // 读取二级间接块a = (uint*)bp->data; // 转换为指针数组uint indirect_bn = bn / NINDIRECT; // 计算一级间接块在二级块中的索引if((addr = a[indirect_bn]) == 0){a[indirect_bn] = addr = balloc(ip->dev); // 分配新的一级间接块log_write(bp); // 记录日志以确保元数据持久化}brelse(bp); // 释放二级间接块缓冲区// 加载一级间接块bp = bread(ip->dev, addr); // 读取一级间接块a = (uint*)bp->data; // 转换为指针数组uint data_bn = bn % NINDIRECT; // 计算数据块在一级块中的索引if((addr = a[data_bn]) == 0) {a[data_bn] = addr = balloc(ip->dev); // 分配新数据块log_write(bp); // 记录日志以确保元数据持久化}brelse(bp); // 释放一级间接块缓冲区return addr; // 返回最终数据块地址}
确保itrunc释放文件的所有块,包括二级间接块。
主要是依次遍历数据块
/*** itrunc - 递归释放inode关联的所有数据块* @ip: 指向inode的指针(调用者必须持有ip->lock)* * 功能:释放文件占用的所有数据块,包括直接块、一级间接块和二级间接块,* 并将inode的大小重置为0。* * 注意:* 1. 调用者必须持有inode锁(ip->lock)确保操作原子性* 2. 函数会释放所有层级的块,确保无内存泄漏*/
void
itrunc(struct inode *ip)
{int i, j;struct buf *bp, *bp1; // 缓冲区指针:bp用于间接块,bp1用于数据块uint *a, *a1; // 指向块数据的指针// 1. 释放直接块(0级索引)for(i = 0; i < NDIRECT; i++){if(ip->addrs[i]){ // 检查直接块是否存在bfree(ip->dev, ip->addrs[i]); // 释放数据块ip->addrs[i] = 0; // 清空inode中的地址项}}// 2. 释放一级间接块(1级索引)if(ip->addrs[NDIRECT]){ // 检查一级间接块是否存在bp = bread(ip->dev, ip->addrs[NDIRECT]); // 读取间接块内容a = (uint*)bp->data; // 将内容转换为地址数组// 遍历一级间接块中的所有数据块地址for(j = 0; j < NINDIRECT; j++){if(a[j]) // 检查数据块是否存在bfree(ip->dev, a[j]); // 释放数据块}brelse(bp); // 释放间接块缓冲区bfree(ip->dev, ip->addrs[NDIRECT]); // 释放一级间接块本身ip->addrs[NDIRECT] = 0; // 清空inode中的间接块地址}// 3. 释放二级间接块(2级索引)if(ip->addrs[NDIRECT + 1]) { // 检查二级间接块是否存在bp = bread(ip->dev, ip->addrs[NDIRECT + 1]); // 读取二级间接块a = (uint*)bp->data; // 将内容转换为地址数组// 遍历二级间接块中的每个一级间接块地址for(i = 0; i < NINDIRECT; i++) {if(a[i]) { // 检查一级间接块是否存在bp1 = bread(ip->dev, a[i]); // 读取一级间接块a1 = (uint*)bp1->data; // 将内容转换为地址数组// 遍历一级间接块中的所有数据块地址for(j = 0; j < NINDIRECT; j++) {if(a1[j]) // 检查数据块是否存在bfree(ip->dev, a1[j]); // 释放数据块}brelse(bp1); // 释放一级间接块缓冲区bfree(ip->dev, a[i]); // 释放一级间接块本身}}brelse(bp); // 释放二级间接块缓冲区bfree(ip->dev, ip->addrs[NDIRECT + 1]); // 释放二级间接块本身ip->addrs[NDIRECT + 1] = 0; // 清空inode中的二级间接块地址}// 4. 更新inode元数据ip->size = 0; // 将文件大小置为0(单位:字节)iupdate(ip); // 将inode变更写回磁盘
}
Symbolic links(moderate)
在本练习中,您将向xv6添加符号链接。符号链接(或软链接)是指按路径名链接的文件;当一个符号链接打开时,内核跟随该链接指向引用的文件。符号链接类似于硬链接,但硬链接仅限于指向同一磁盘上的文件,而符号链接可以跨磁盘设备。尽管xv6不支持多个设备,但实现此系统调用是了解路径名查找工作原理的一个很好的练习。
你的工作
您将实现symlink(char *target, char *path)系统调用,该调用在引用由target命名的文件的路径处创建一个新的符号链接。有关更多信息,请参阅symlink手册页(注:执行man symlink)。要进行测试,请将symlinktest添加到***Makefile***并运行它。当测试产生以下输出(包括usertests运行成功)时,您就完成本作业了。
$ symlinktest
Start: test symlinks
test symlinks: ok
Start: test concurrent symlinks
test concurrent symlinks: ok
$ usertests
...
ALL TESTS PASSED
$
提示:
- 首先,为
symlink创建一个新的系统调用号,在*user/usys.pl*、**user/user.h*中添加一个条目,并在kernel/sysfile.c***中实现一个空的sys_symlink。 - 向***kernel/stat.h***添加新的文件类型(
T_SYMLINK)以表示符号链接。 - 在kernel/fcntl.h*中添加一个新标志(
O_NOFOLLOW),该标志可用于open系统调用。请注意,传递给open的标志使用按位或运算符组合,因此新标志不应与任何现有标志重叠。一旦将user/symlinktest.c*添加到Makefile***中,您就可以编译它。 - 实现
symlink(target, path)系统调用,以在path处创建一个新的指向target的符号链接。请注意,系统调用的成功不需要target已经存在。您需要选择存储符号链接目标路径的位置,例如在inode的数据块中。symlink应返回一个表示成功(0)或失败(-1)的整数,类似于link和unlink。 - 修改
open系统调用以处理路径指向符号链接的情况。如果文件不存在,则打开必须失败。当进程向open传递O_NOFOLLOW标志时,open应打开符号链接(而不是跟随符号链接)。 - 如果链接文件也是符号链接,则必须递归地跟随它,直到到达非链接文件为止。如果链接形成循环,则必须返回错误代码。你可以通过以下方式估算存在循环:通过在链接深度达到某个阈值(例如10)时返回错误代码。
- 其他系统调用(如
link和unlink)不得跟随符号链接;这些系统调用对符号链接本身进行操作。 - 您不必处理指向此实验的目录的符号链接。
上面是实验指导,下面是个人笔记
软链接
像是win里面的快捷方式,拥有自己的 inode 和 数据块(数据块存储目标文件的路径字符串)。
- 灵活性
- ✅ 可跨文件系统(仅存储路径字符串)。
- ✅ 可链接目录(常用场景:
ln -s /mnt/data ~/data)。
- 脆弱性
- 若目标文件被删除或移动,软链接成为悬空链接(Dangling Link),访问时报错
No such file or directory。
- 若目标文件被删除或移动,软链接成为悬空链接(Dangling Link),访问时报错
ln -s 目标路径 软链接名 # 创建软链接
在 Unix/Linux 系统中,创建软连接(符号链接)和硬链接分别通过不同的系统调用实现。以下是这两种链接的核心系统调用函数及其区别:
硬链接:link() 系统调用
#include <unistd.h>int link(const char *oldpath, const char *newpath);
// 创建文件 "test.txt" 的硬链接 "test_hardlink"
if (link("test.txt", "test_hardlink") == -1) {perror("link failed");exit(EXIT_FAILURE);
}
软连接(符号链接):symlink() 系统调用
#include <unistd.h>int symlink(const char *oldpath, const char *newpath);
// 创建指向 "test.txt" 的软链接 "test_symlink"
if (symlink("test.txt", "test_symlink") == -1) {perror("symlink failed");exit(EXIT_FAILURE);
}
读取软链接内容:readlink() 系统调用
#include <unistd.h>ssize_t readlink(const char *path, char *buf, size_t bufsiz);
char buf[1024];
ssize_t len = readlink("test_symlink", buf, sizeof(buf) - 1);
if (len != -1) {buf[len] = '\0'; // 手动添加字符串终止符printf("Symbolic link target: %s\n", buf);
}
- 读取软链接文件本身的内容(即被指向文件的路径),而非被指向文件的内容。
- 返回值为读取的字节数,不包含字符串终止符
'\0'。
主要是添加系统调用:首先我们按常规操作, 把一个新的系统调用sys_symlink的代号, 跳转函数等等设立好. 然后我们直接开始看sys_symlink的实现: 我们把其对应的inode的type设为T_SYMLINK, 然后在其data block的[0, MAXPATH]的范围里写上所要链接的target path的路径.
实验操作:
添加系统调用的常规操作,如在user/usys.pl、user/user.h中添加一个条目,在kernel/syscall.c、kernel/syscall.h中添加相关内容
在系统调用里面
syscall.h
#define SYS_symlink 22syscall.c
// 这是 C 语言中定义函数指针数组的语法
static uint64 (*syscalls[])(void) = {
[SYS_fork] sys_fork,
[SYS_exit] sys_exit,
[SYS_wait] sys_wait,
[SYS_pipe] sys_pipe,
[SYS_read] sys_read,
[SYS_kill] sys_kill,
[SYS_exec] sys_exec,
[SYS_fstat] sys_fstat,
[SYS_chdir] sys_chdir,
[SYS_dup] sys_dup,
[SYS_getpid] sys_getpid,
[SYS_sbrk] sys_sbrk,
[SYS_sleep] sys_sleep,
[SYS_uptime] sys_uptime,
[SYS_open] sys_open,
[SYS_write] sys_write,
[SYS_mknod] sys_mknod,
[SYS_unlink] sys_unlink,
[SYS_link] sys_link,
[SYS_mkdir] sys_mkdir,
[SYS_close] sys_close,
[SYS_symlink] sys_symlink,
};
/*
用户程序通过汇编指令(如 ecall)触发系统调用
处理器切换到内核模式,跳转到内核的陷阱处理代码
陷阱处理代码保存寄存器状态到 trapframe
调用 syscall() 函数
syscall() 根据 a7 寄存器的值查找并执行对应的系统调用处理函数
处理函数返回结果到 a0 寄存器
陷阱处理代码恢复寄存器状态,返回用户模式
*/
void
syscall(void)
{int num;struct proc *p = myproc();// 根据 a7 寄存器的值查找并执行对应的系统调用处理函数num = p->trapframe->a7;if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {//处理函数返回结果到 a0 寄存器p->trapframe->a0 = syscalls[num]();} else {printf("%d %s: unknown sys call %d\n",p->pid, p->name, num);p->trapframe->a0 = -1;}
}增加文件类型
stat.h增加 T_SYMLINK
/*** @enum 文件类型定义* 描述文件系统中不同类型的文件*/
#define T_DIR 1 // 目录文件:存储文件名与inode的映射关系
#define T_FILE 2 // 普通文件:存储用户数据(如文本、二进制数据)
#define T_DEVICE 3 // 设备文件:表示硬件设备(如字符设备、块设备)
#define T_SYMLINK 4 // 符号链接(软链接):存储指向其他文件的路径名
/*** @brief 文件元数据结构,用于描述文件的状态信息* 包含文件类型、权限、大小、时间戳等核心属性*/
struct stat {int dev; // 设备号:文件所在的设备标识uint ino; // inode号:文件在设备中的唯一标识short type; // 文件类型:使用上述T_*宏定义(如T_FILE、T_SYMLINK)short nlink; // 硬链接数:指向该inode的文件名数量uint64 size; // 文件大小:以字节为单位(对目录和设备文件无意义)};
增加辅助标志
fcntl.h
#define O_RDONLY 0x000 // 只读模式(主模式标志)
#define O_WRONLY 0x001 // 只写模式(主模式标志)
#define O_RDWR 0x002 // 读写模式(主模式标志)
#define O_CREATE 0x200 // 创建文件(如果不存在)
#define O_TRUNC 0x400 // 截断文件(如果已存在)// 位数不重叠
#define O_NOFOLLOW 0x800 // 不跟随符号链接(直接操作链接文件本身)
在makefile中添加symlinktest
ifeq ($(LAB),fs)
UPROGS += \$U/_bigfile$U/_symlinktest
endif
首先给出软连接的系统调用
// int symlink(const char *oldpath, const char *newpath);系统调用
uint64
sys_symlink(void){char koldpath[MAXPATH] = {0};/*等价于char kpath[MAXPATH], ktarget[MAXPATH];memset(kpath, 0, MAXPATH);memset(ktarget, 0, MAXPATH);*/char knewpath[MAXPATH] = {0};struct inode* ip_path;int ret = -1;// 从用户空间获取参数,第一个参数if(argstr(0,koldpath,MAXPATH)<0)return -1;if(argstr(1,knewpath,MAXPATH)<0)return -1;// 配合end_op()保证原子操作begin_op();// 在指定路径knewpath分配一个新的inode,并将其类型标记为符号链接(T_SYMLINK)// 目录文件,目录项对应inode节点ip_path = create(knewpath, T_SYMLINK, 0, 0);if(ip_path == 0){// 创建失败处理ret = -1;goto out;}// 向inode数据块中写入koldpath路径if(writei(ip_path , 0 , (uint64)koldpath , 0 , MAXPATH) < MAXPATH){ret = -1;iunlockput(ip_path); // 释放inode并减少引用计数goto out;}iunlockput(ip_path); // 释放inode并减少引用计数ret = 0;
out:end_op();return ret;
}
改open系统调用以处理路径指向符号链接的情况。如果文件不存在,则打开必须失败。当进程向open传递O_NOFOLLOW标志时,open应打开符号链接(而不是跟随符号链接)。
这里先通过trapframe 结构体获取系统调用参数
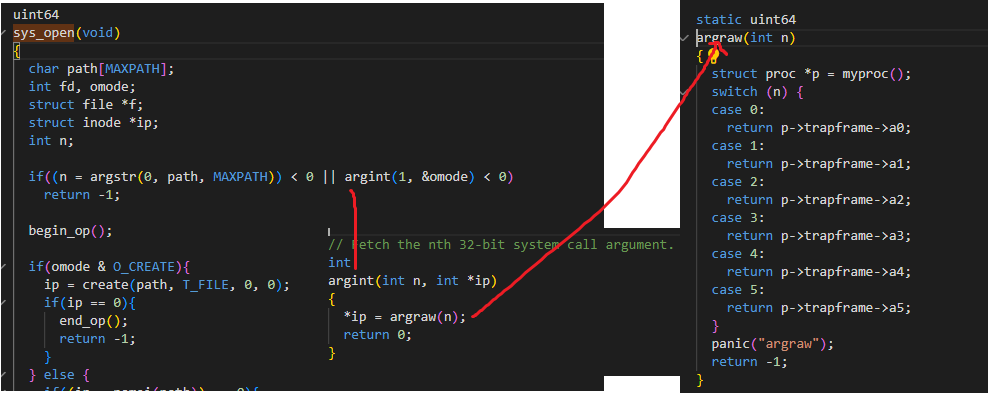
RISC-V 系统调用寄存器使用详解
在 RISC-V 架构(从代码中的 trapframe->a0 等寄存器名可看出)中,用户态程序通过寄存器传递系统调用参数:
- a0 寄存器:存储系统调用号
- a1~a6 寄存器:依次存储系统调用的第 1~6 个参数
当发生系统调用时(如通过 ecall 指令),CPU 会跳转到内核态,此时参数值被保存在进程的 trapframe 结构体中。
| 寄存器 | 用途 | 系统调用中的作用 |
|---|---|---|
| a0 | 参数1 / 返回值 | 传递参数 + 返回结果 |
| a1 | 参数2 | 传递参数 |
| a2 | 参数3 | 传递参数 |
| a3 | 参数4 | 传递参数 |
| a4 | 参数5 | 传递参数 |
| a5 | 参数6 | 传递参数 |
| a6 | 临时寄存器 | ❌ 系统调用中未使用 |
| a7 | 系统调用号 | 标识具体系统调用 |
这里是sys_open的新增部分,
-
不断通过
readi()从 inode 读取数据的核心函数,其主要功能是将文件内容从磁盘读取到指定的缓冲区(用户空间或内核空间) -
得到存放的路径字符串
-
再通过
namei:根据给定的文件路径字符串(path),递归解析路径中的各层目录,返回最终目标文件的 inode 结构体指针。 -
不断循环这一过程
int depth = 0;// 当前 inode 是符号链接 (T_SYMLINK)// 未设置 O_NOFOLLOW 标志(允许跟随链接)while (ip->type == T_SYMLINK && !(omode & O_NOFOLLOW)) {char ktarget[MAXPATH] ={0};// memset(ktarget, 0, MAXPATH);// 从软链接的inode的[0, MAXPATH]读出它所对应的target pathif ((readi(ip, 0, (uint64)ktarget, 0, MAXPATH)) <= 0) {iunlockput(ip);end_op();return -1;}iunlockput(ip); // 解锁ip,且减少计数if((ip = namei(ktarget)) == 0){ // 根据路径字符串找inode,给ipend_op();return -1;}ilock(ip); // 新路径的inode上锁depth++;if (depth > 10) {iunlockput(ip);end_op();return -1;}}