论文略读:LIMO: Less is More for Reasoning
202502 arxiv
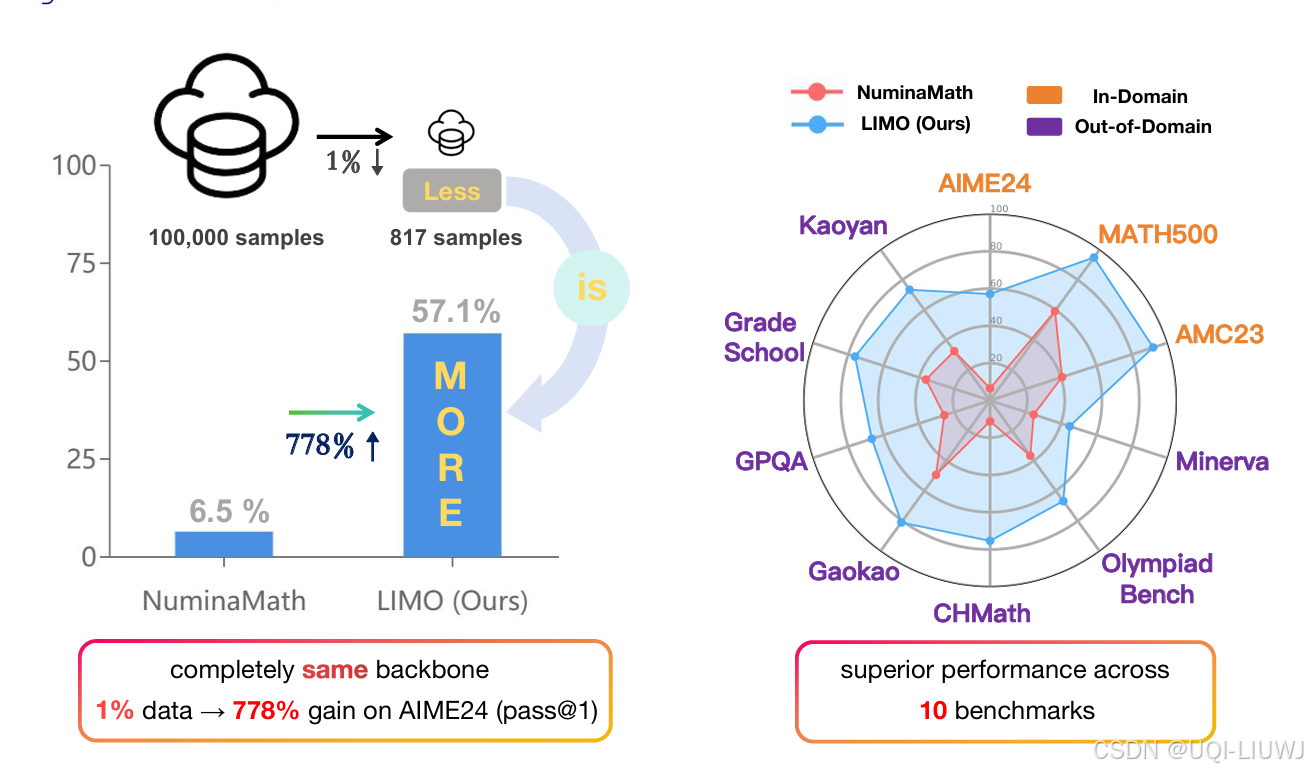
- 在数学推理领域,论文提出的LIMO仅用 817 条精心设计的训练样本,借助简单的监督微调,就全面超越了使用十万量级数据训练的主流模型
- 最近的大模型在预训练阶段已纳入海量数学知识(比如Llama 3 仅在数学推理上的训练数据就高达 3.7 万亿 token)
- 现代 LLM 早已 “知道” 大量数学知识,关键是如何 “唤醒” 它们
- 推理链(chain-of-thought, CoT)的长度,与模型的推理能力密切相关
- 推理链(chain-of-thought, CoT)的长度,与模型的推理能力密切相
- 最近的大模型在预训练阶段已纳入海量数学知识(比如Llama 3 仅在数学推理上的训练数据就高达 3.7 万亿 token)