Elasticsearch 读写流程深度解析
在数据驱动的数字化浪潮中,Elasticsearch 凭借其毫秒级搜索响应与水平扩展能力,已成为现代数据架构的核心引擎。本文将深入剖析其读写流程的设计思想、实现细节与工程权衡,揭示这一分布式系统的精妙架构。
一、 架构基石:分布式设计的精妙平衡
1.1 分片(Shard)机制:数据水平扩展的核心
- 分片本质:每个索引被拆分为多个独立的分片(默认 5 个),每个分片是一个完整的 Lucene 索引实例
- 路由算法:文档通过
shard = hash(_routing) % number_of_primary_shards定位目标分片 - 动态扩容:通过 Split API 可对分片二次拆分,实现存储容量倍增
1.2 副本(Replica)设计:高可用的双重保障
- 数据冗余:每个主分片可配置多个副本(默认 1 个),物理存储在不同节点
- 读写分离:副本分片可处理读请求,提升系统吞吐量(通过
preference参数控制) - 故障转移:主分片异常时,Master 节点自动触发副本晋升(Raft 协议选举)
1.3 节点角色:去中心化的协作网络
| 节点类型 | 核心职责 | 资源隔离建议 |
|---|---|---|
| Master Node | 集群状态管理/分片分配 | 低CPU/中内存 |
| Data Node | 存储数据/执行读写操作 | 高CPU/高内存/高IO |
| Coordinating Node | 请求路由/结果聚合 | 中CPU/高网络带宽 |
| Ingest Node | 数据预处理(Pipeline 执行) | 中CPU/中内存 |
设计权衡:通过角色分离避免单点瓶颈,但增加运维复杂度(需专用 Master 节点防脑裂)
二、 写入流程:可靠性与实时性的精密协作
2.1 数据写入流程图
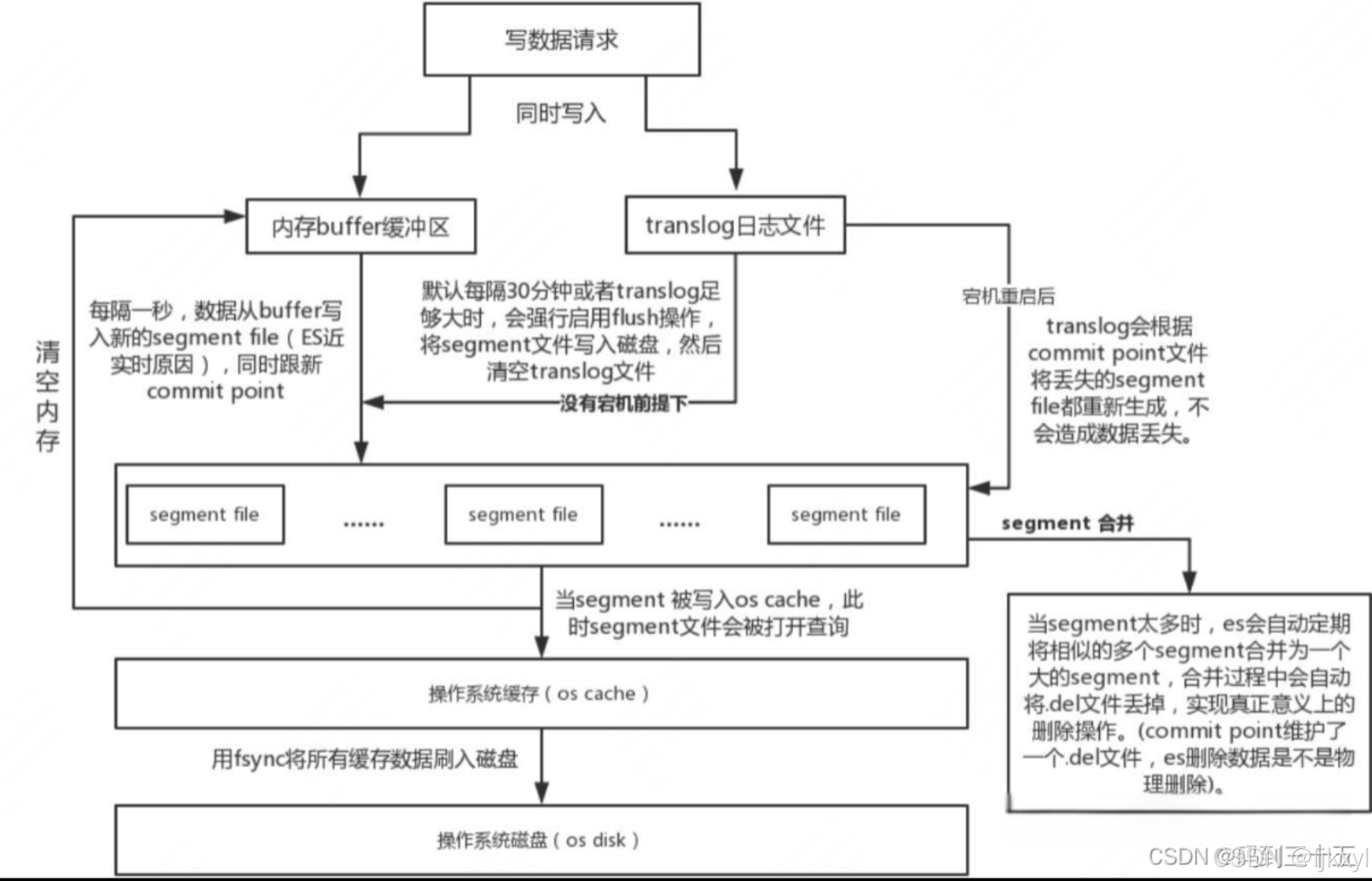
2.2 底层存储引擎运作
-
Translog 的可靠性设计
- 追加写入:所有写操作立即追加到 translog(文件系统缓存)
- 刷盘策略:每 5 秒执行
fsync(可配置index.translog.durability为request强同步) - 分段滚动:translog 超过 512MB 时生成新文件(
index.translog.generation)
-
Refresh:可搜索性的关键
- 内存刷新:默认每 1 秒将 In-memory Buffer 转为 Lucene Segment
- 实时性代价:高频 Refresh 增加 I/O 压力(可通过
index.refresh_interval调整) - Segment 特性:不可修改(删除标记 .del 文件),只追加合并
-
Flush:持久化与清理
- 触发条件:Translog 大小超限(默认 512MB)或 30 分钟超时
- 原子操作:
- 调用
fsync确保所有 Segment 落盘 - 清空 Translog(生成新空文件)
- 清空 Memory Buffer
- 调用
-
段合并(Segment Merge)优化
- 策略选择:TieredMergePolicy 分层合并(小段→中段→大段)
- I/O 控制:
MergeScheduler动态调节并发度(避免磁盘过载) - 优化效果:减少文件句柄数,提升查询性能
三、 读取流程:分布式查询的协同艺术
3.1 查询请求全链路解析
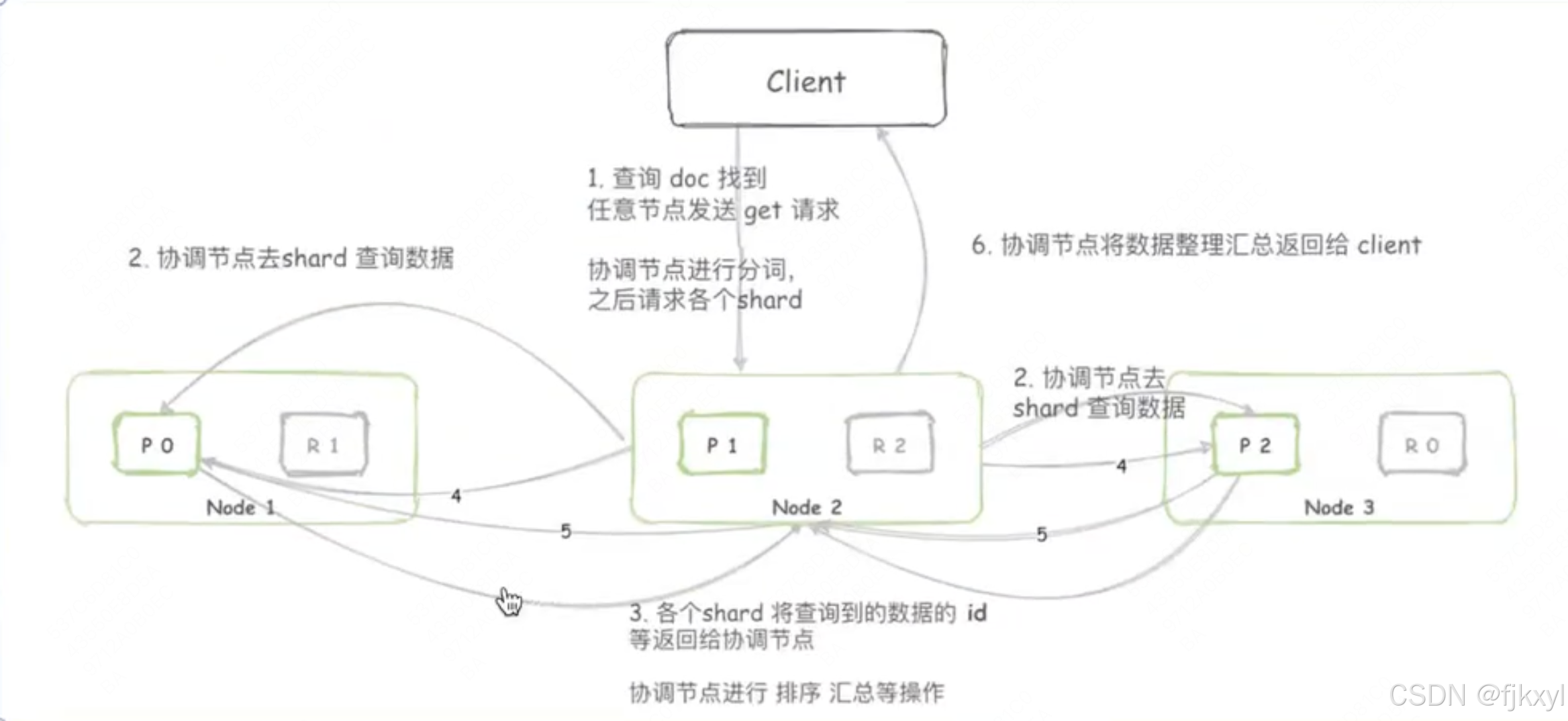
3.2 关键阶段技术细节
-
Query 阶段(Scatter)
- 分片选择:协调节点基于路由信息定位主/副本分片(负载均衡)
- 本地搜索:各分片在 Lucene 倒排索引中检索(使用 SkipList 跳表加速)
- 结果压缩:仅返回 DocID、Score、Sort Values(减少网络传输)
-
Fetch 阶段(Gather)
- 文档拉取:协调节点按排序结果向对应分片获取完整文档
- 高亮处理:在数据节点重新运行查询生成高亮片段
- 分页优化:通过
search_after避免深度翻页性能劣化
3.3 性能加速机制
-
缓存体系
缓存类型 存储内容 失效条件 Query Cache Filter 上下文结果 Segment 变更 Request Cache 聚合结果(hits=0 时) 索引数据更新 Fielddata Cache 文本字段分词结果 内存压力/LRU 淘汰 -
预加载优化
- 文件系统缓存:Lucene 依赖 OS Page Cache 加速磁盘读取
- 预热脚本:通过
index.store.preload预载热点索引文件
四、 容错与一致性:分布式场景下的工程智慧
4.1 写入一致性模型
- 配置策略:通过
wait_for_active_shards控制最小成功副本数all:所有副本确认(强一致,延迟高)quorum:多数副本确认(推荐平衡点)1:仅主分片确认(弱一致,延迟低)
4.2 故障恢复流程
- 分片重分配:Master 检测到节点离线,启动副本提升
- 数据同步:新主分片从 Translog 恢复未刷盘数据
- 分段修复:通过 Checksum 校验 Segment 完整性
工程挑战:脑裂场景下的数据冲突通过版本号(
_version)解决(乐观锁)
五、 深度优化:生产环境的最佳实践
5.1 写入性能调优
- Bulk 批处理:单批次 5-15MB 数据(避免堆内存压力)
- 线程池配置:调整
write队列大小(thread_pool.write.queue_size) - 磁盘隔离:SSD 部署热数据,SATA 存冷数据(Tiered Storage)
5.2 查询效率提升
- 索引设计:
{"settings": {"number_of_routing_shards": 32, // 为未来扩容预留"refresh_interval": "30s" // 降低实时性要求场景},"mappings": {"properties": {"timestamp": { "type": "date", "doc_values": true } // 启用列存加速聚合}} } - 查询重构:
- 用 Filter 替代 Bool Query 的 Must 子句(利用缓存)
- 避免通配符查询(
wildcard),改用 N-gram 分词
结语:分布式系统的设计哲学
Elasticsearch 的卓越性能源于对三大矛盾的巧妙平衡:
- 实时 vs 吞吐:Translog 持久化与 Refresh 机制的协作
- 扩展性 vs 一致性:分片化存储与可调一致性模型
- 灵活性 vs 效率:DSL 的丰富表达能力与倒排索引/列存优化
其核心启示在于:所有分布式系统都是妥协的艺术。Elasticsearch 通过分层设计(Translog/Lucene Segment)、异步协作(副本复制)、智能调度(合并策略/缓存)等机制,在工程复杂度与性能之间找到了黄金平衡点。理解这些设计思想,不仅有助于优化 Elasticsearch 使用,更为构建任何大规模分布式系统提供了宝贵范式。
参考文档:https://cloud.tencent.com/developer/article/2398626