K-匿名模型
K-匿名模型是隐私保护领域的一项基础技术,防止通过链接攻击从公开数据中重新识别特定个体。其核心思想是让每个个体在发布的数据中“隐匿于人群”,确保任意一条记录至少与其他K-1条记录在准标识符(Quasi-Identifiers, QIDs)上不可区分。
一、K-匿名模型解决的问题
-
防御重新识别攻击
-
例如:发布医疗数据(如疾病诊断记录),删除姓名、身份证号等直接标识符。
-
风险:攻击者结合外部数据(如邮编、性别、年龄),通过QIDs(准标识符)匹配锁定特定个体,泄露疾病等敏感信息。
-
K-匿名的作用:确保每个QIDs组合组内至少有K条记录,使攻击者无法缩小目标个体范围至小于K人。
-
-
支持安全的数据发布
-
适用于:人口普查数据、医疗研究数据、地理位置数据等需公开但含敏感信息的场景。
-
二、实现原理:如何达到“K-匿名”?
通过数据泛化(Generalization)和抑制(Suppression) 操作,降低QIDs(准标识符)的精度,扩大组内记录数。
关键步骤
-
识别准标识符(QIDs)
-
QIDs:非敏感但可链接外部数据的属性(如邮编、性别、年龄、职业)。
-
敏感属性:需保护的隐私信息(如疾病、收入、住址、身份证号)。
-
-
数据泛化
-
降低属性精度,使更多记录共享相同QIDs值:

-
-
数据抑制
-
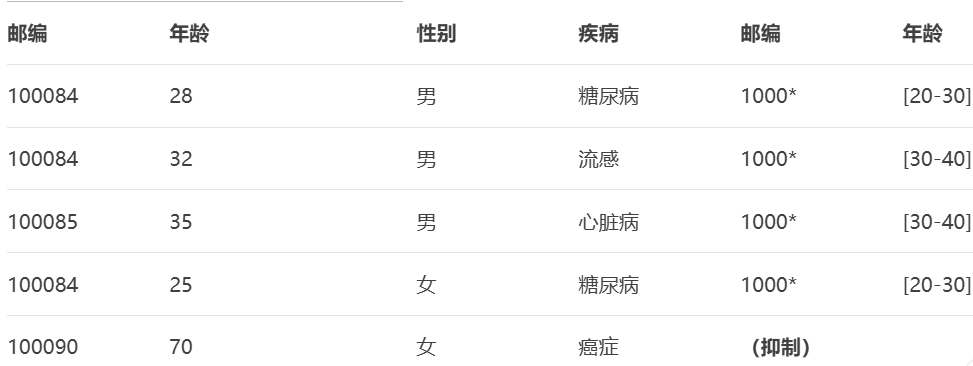
删除无法满足K-匿名的罕见QIDs组合(如仅1人的记录)。医疗数据K-匿名化(K=3)
-
 |
-
解释如下:
-
邮编泛化为前4位(
1000*),年龄分组为[20-30]/[30-40],性别部分泛化为*(代表任意性别)。 -
70岁女性邮编
100090的组仅1人(不满足K=3),整条记录被抑制(不发布)。
-
-
效果:
-
攻击者即使知道某人住在邮编
100084、年龄25-30岁,也无法确定其性别和具体疾病(组内2条糖尿病记录+1条其他记录)。
-
三、与隐私保护的核心联系
1. 直接目标:抵御链接攻击
-
隐私保障:K-匿名确保攻击者通过QIDs最多定位到K个候选个体,无法确定目标是谁。
-
公式:

2. 局限性
| 攻击类型 | 原理 | 案例 |
|---|---|---|
| 同质性攻击 | 组内敏感属性完全相同 | K=3组内3人全是“艾滋病”→ 锁定任意组员患病 |
| 背景知识攻击 | 利用外部信息排除组内部分人 | 已知目标不住100084区 → 排除该区记录 |
| 补充数据攻击 | 联合多个K-匿名数据集交叉分析 | 合并医疗与收入数据,缩小定位范围 |
3. 后续改进模型
为弥补漏洞,K-匿名扩展出更健壮的模型:
-
L-多样性(L-Diversity):
-
要求每个QIDs组内敏感属性至少有L个不同值。
-
例:疾病字段在组内有“糖尿病/流感/心脏病”3种值(L=3),防御同质性攻击。
-
-
T-接近性(T-Closeness):
-
要求组内敏感属性分布接近整体分布(如患病率差异≤阈值T)。
-
避免通过组内分布偏差推测个体(如某组癌症比例80% --- 总体5%)。
-
四、K-匿名的实际意义与挑战
-
优势:
-
直观易实现:泛化与抑制操作简单,兼容传统数据库。
-
平衡效用与隐私:保留数据统计价值(如分析年龄与疾病关联)。
-
-
挑战:
-
效用损失:过度泛化(如年龄全泛化为
[0-100])导致分析价值下降。 -
动态数据失效:新外部数据出现可能破坏原有K-匿名(如新增选民名册)。
-
无法防御强背景知识攻击:如攻击者知道目标近期住院,可直接关联疾病字段。
-