Spark-TTS: AI语音合成的“变声大师“
嘿,各位AI爱好者!还记得那些机器人般毫无感情的合成语音吗?或者那些只能完全模仿但无法创造的语音克隆?今天我要介绍的Spark-TTS模型,可能会让这些问题成为历史。想象一下,你可以让AI不仅说出任何文字,还能控制它是用男声还是女声,高音还是低音,快速还是缓慢…听起来很酷,对吧?那就跟我一起来看看这个语音合成界的"变声大师"吧!
为什么我们需要一个新的TTS模型?
在深入了解Spark-TTS之前,让我们先聊聊目前TTS(文本转语音)技术面临的几个"小烦恼":
- 架构太复杂:现有的TTS系统经常需要多个模型协同工作,就像一个需要五六个厨师才能做出一道菜的餐厅
- 缺乏控制灵活性:大多数系统只能模仿现有声音,但无法精确调整声音特性,就像只能照搬食谱而不能调味
- 缺少统一的评估标准:没有一个公认的"评分卡"来衡量不同TTS系统的好坏
Spark-TTS就是为了解决这些问题而生的。它不仅简化了架构,还提供了前所未有的语音控制能力,同时还带来了一个开放的数据集作为行业"评分卡"。
Spark-TTS的秘密武器:BiCodec
Spark-TTS最大的创新在于一个叫做BiCodec的组件。这是什么神奇的东西?简单来说,BiCodec就像是一个超级高效的语音编码器,它把语音分解成两种互补的"代币"(Token):
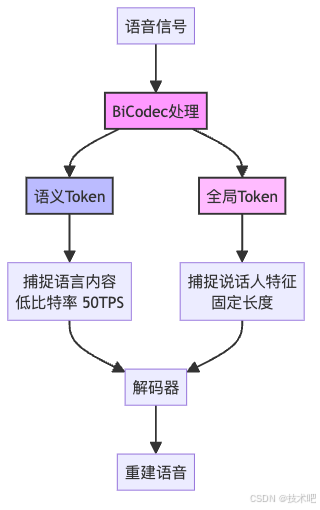
这两种Token各司其职:
- 语义Token:记录"说了什么",每秒50个Token,非常节省空间
- 全局Token:记录"谁在说",包含说话人的音色、性别等固定特征
这种设计太聪明了!就像把一段语音拆成了"内容"和"声音特征"两部分,这样我们就可以单独控制每个部分。想要同样的话用不同的声音说出来?只需要换一下全局Token就行。想要不同的话用同样的声音说出来?只需要换一下语义Token就行。
Spark-TTS的统一架构:简约而不简单
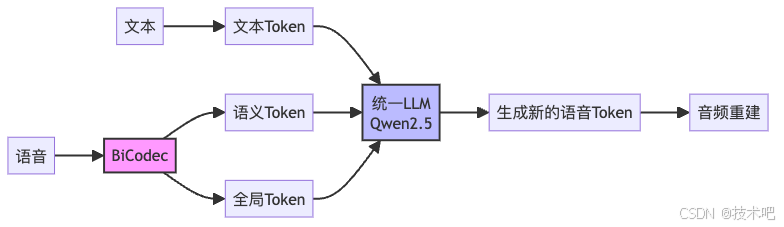
Spark-TTS的另一个亮点是它的统一架构。它把BiCodec产生的语音Token和普通的文本Token一起输入到同一个LLM中(具体使用了Qwen2.5-0.5B模型)。这就像把"做饭"和"调酒"这两项看似不同的技能交给同一个大厨处理,大大简化了整个流程。
这种设计让Spark-TTS可以像普通的文本生成模型一样工作,只不过它生成的不是文字,而是可以转换成语音的Token。想象一下,之前需要一个复杂的厨房才能完成的工作,现在只需要一个多才多艺的厨师就够了!
想要什么声音,就有什么声音
Spark-TTS最让人兴奋的能力是它强大的语音控制能力。它支持两种控制方式:
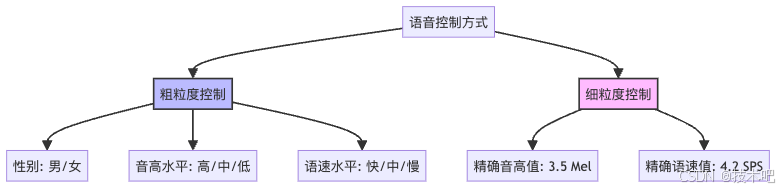
- 粗粒度控制:就像是告诉模型"我要一个高音快语速的女声"
- 细粒度控制:就像是告诉模型"我要音高是3.5 Mel,语速是4.2 SPS的声音"
这就像是从"我要一杯甜饮料"到"我要一杯加了3.5勺糖、4.2毫升柠檬汁的饮料"的精确跨越!更厉害的是,即使你只提供粗粒度控制,Spark-TTS也会通过"思维链"(Chain-of-Thought)机制自动推断出合适的细粒度参数。
实验结果显示,Spark-TTS在性别控制上的准确率高达99.77%。这意味着,如果你要求它用女声说话,几乎可以100%确定它会用女声说话,而不会突然冒出一个大叔的声音!
VoxBox数据集:TTS界的"ImageNet"
为了推动整个TTS领域的发展,Spark-TTS的研究团队还发布了一个名为VoxBox的开源数据集。这个数据集包含了超过10万小时的中英文语音数据,每条数据都有详细的属性标注,包括性别、音高和语速,有些甚至还标注了年龄和情感。
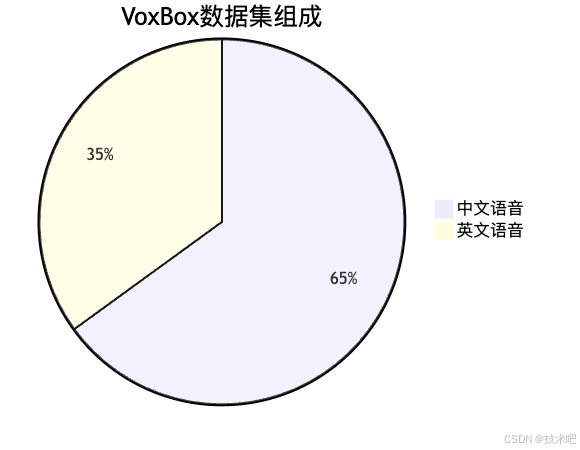
这就像是给TTS研究者们提供了一个"标准训练场",让大家可以在同一个"赛道"上比较不同模型的性能。在这个数据集的帮助下,TTS技术的发展可能会像计算机视觉在ImageNet数据集发布后那样迅速加速!
Spark-TTS的性能:以小博大的效率冠军
在性能方面,Spark-TTS也表现不俗:
- 低比特率,高质量:在低比特率(<1 kbps)下,BiCodec的语音重建质量达到了业界最高水平
- 高可懂度:在零样本TTS测试中,Spark-TTS生成的语音在可懂度方面表现优异,中文错误率仅次于闭源模型Seed-TTS
- 轻量高效:使用仅0.5B参数和10万小时训练数据,Spark-TTS性能超过了参数量是它16倍(8B)、训练数据是它2.5倍(25万小时)的Llasa模型
这就像是一个体重只有对手一半的拳击手,却能打败更高级别的对手!Spark-TTS证明了,有时候聪明的设计比简单地堆砌更多资源更重要。
还有改进空间
当然,Spark-TTS也不是完美的。研究者指出,在零样本TTS场景下,Spark-TTS在说话人相似度方面还有提升空间。简单说,就是当它模仿某个人的声音时,听起来可能还不够像。这可能是因为自回归语言模型在生成过程中引入了一些随机性,以及全局Token对音色的控制还不够精确。
不过,研究团队已经计划在未来的版本中解决这个问题,主要方向是增强全局Token对音色的控制能力。
总结:语音合成的新时代
Spark-TTS通过创新的BiCodec技术和统一的LLM架构,为语音合成领域带来了三大突破:
- 架构简化:单一模型替代复杂的多阶段系统
- 精确控制:前所未有的语音属性精确控制能力
- 标准基准:VoxBox数据集为整个行业提供了标准评估基准
这些进步让我们离"任意文本,任意声音,任意风格"的理想TTS系统又近了一步。想象一下,未来你可能会有一个AI助手,它不仅能用你喜欢的声音说话,还能根据场景自动调整语速和语调,激动时会提高音调,严肃时会放慢语速…这一切,都可能因为Spark-TTS这样的技术突破而变为现实。
对于AI爱好者和开发者来说,Spark-TTS展示了如何通过巧妙的架构设计和数据表示方式,让AI系统变得更加灵活和可控。即使你不直接从事TTS开发,这种思路也值得借鉴:有时候,改变数据的表示方式,比简单地增加模型大小更能带来突破性的进展。
你期待这样的AI语音技术用在哪些场景呢?是个性化的有声读物,还是能模仿你声音的数字助手?欢迎在评论区分享你的想法!