【Linux】基础文件IO

🌟🌟作者主页:ephemerals__
🌟🌟所属专栏:Linux
前言
无论是日常使用还是系统管理,文件是Linux系统中最核心的概念之一。对于初学者来说,理解文件是如何被创建、读取、写入以及存储的,是掌握Linux的必经之路。本文将深入探讨Linux文件IO的基础知识,从最基本的文件操作命令到系统调用,带你一步步揭开文件IO的神秘面纱。
一、C语言文件接口回顾
在学习Linux系统级文件操作之前,我们可以先回顾一下C语言文件接口:
【c语言】玩转文件操作-CSDN博客
二、系统级文件IO接口
相比语言层面的文件操作函数,系统级文件IO接口更加接近底层。实际上,语言层的文件接口对系统级接口进行了封装,屏蔽了底层操作系统的复杂性。 并且,不同的操作系统,提供的系统级文件接口也不同,语言层针对不同操作系统进行不同的封装,可以使用户无需在意操作系统差异,提高了跨平台性。接下来给大家介绍几个常用的Linux下系统文件接口。
文件的打开和关闭
open
open是一个系统调用,用于打开或创建一个磁盘级文件。它的函数原型如下:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
参数pathname:要打开的文件路径(用字符串表示)
参数flags:表示打开文件的方式。可传入的参数有如下几种宏:
O_RDONLY:只读模式打开文件。O_WRONLY:只写模式打开文件。O_RDWR:读写模式打开文件。O_CREAT:如果文件不存在,则创建文件(此时需要传第三个参数)。O_TRUNC:如果文件已存在,清空其内容。O_APPEND:写入时追加到文件末尾。
不难发现,上述的某些设定是可以同时存在(例如只写打开时,如果文件不存在可以设定创建文件,如果已经存在则清空),因此这些参数可以自行选择同时传入(例如O_WRONLY | O_CREAT | O_TRUNC)。为什么可以用按位或的方式传入多个参数呢?其实是由位掩码实现的:
假如宏
O_WRONLY被替换为0000 0001(二进制),而宏O_CREAT被替换为0000 0010(二进制),宏O_TRUNC被替换为0000 0100(二进制),三者按位或的结果就是0000 0111(二进制),就相当于将其二进制的对应位“点亮”为1,函数体内部通过按位与操作判断每一位是否为1,就可以执行相应的操作。
Linux的很多系统调用都通过这种使用按位与的方式支持传入多个选项,既高效又简洁。
参数mode:表示文件的打开权限(第二个参数设定了O_CREAT时才需要),用八进制表示。如果不传入,会发生未定义行为。
注意:该参数只是设定了默认权限,并不是文件的实际权限,实际权限受到umask权限掩码影响。
返回值:成功时返回一个非负整数(文件描述符,稍后讲解),失败时返回-1。
修改当前进程创建文件时的权限掩码:
#include <sys/types.h>
#include <sys/stat.h>mode_t umask(mode_t mask); // 参数是八进制形式的新权限,返回旧权限
close
系统调用close的作用是关闭文件。其函数原型如下:
#include <unistd.h>int close(int fd);
参数:文件描述符,表示要关闭哪一个文件。
返回值:成功返回0,失败返回-1。
从这里我们也不难看出,文件描述符代表了文件,对文件的各种操作需要配合文件描述符进行。
文件打开与关闭使用示例:
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main()
{//以写的方式创建一个不存在的文件int fd = open("test.txt", O_WRONLY | O_CREAT | O_TRUNC);if(fd < 0) // 说明文件打开失败{std::cerr << "文件打开失败" << std::endl;return 1;}//关闭文件close(fd);return 0;
}
运行结果:

可以看到,当前路径下出现了一个叫做“test.txt”的文件。
文件的读写操作
write
write也是一个系统调用,它的功能是向文件写入内容。函数原型如下:
#include <unistd.h>ssize_t write(int fd, const void *buf, size_t count);
参数fd:要写入文件的文件描述符
参数buf:要写入的数据的起始地址
参数count:要写入的数据的字节数
返回值:成功时返回成功写入的字节数;失败时返回-1。
注:向文件写入字符串时,末尾不要带’\0’。因为字符串末尾有’\0’是C/C++等语言层面的概念,并非系统级要求,在文件当中没有意义。其次,我们学习C语言文件写入接口时,分为文本写入和二进制写入,但其实在系统层面,并没有文本文件和二进制文件的区分,本质上都是字节流的形式。
使用示例:
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <cstring>int main()
{//以写的方式创建一个不存在的文件int fd = open("test.txt", O_WRONLY | O_CREAT | O_TRUNC);if(fd < 0) // 说明文件打开失败{std::cerr << "文件打开失败" << std::endl;return 1;}const char* s = "hello world";write(fd, s, strlen(s)); // 写入//关闭文件close(fd);return 0;
}
运行结果:

read
read的作用是从文件读取内容。函数原型如下:
#include <unistd.h>ssize_t read(int fd, void *buf, size_t count);
参数fd:要读的文件的文件描述符
参数buf:输出型参数,接收读入的数据(一般是字符数组或结构化数据的地址)
参数count:要读取的字节数(一般是字符数组或结构化数据的大小)
返回值:返回成功读入的字节数,0表示读到文件末尾,-1表示读取错误。
使用示例:

#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <cstring>int main()
{//以读的方式打开文件test.txtint fd = open("test.txt", O_RDONLY);if(fd < 0){std::cerr << "文件打开失败" << std::endl;return 1;}char buffer[128]; // 创建一个结构化数据,用于将文件读到内存中int n = read(fd, buffer, sizeof(buffer) - 1); // 给'\0'留一个位置if(n > 0){//由于读入的是字符串,所以读取之后在末尾加上'\0'buffer[n] = '\0';//输出读到的数据std::cout << buffer << std::endl;}//关闭文件close(fd);return 0;
}
运行结果:

三、文件描述符
刚才学习系统文件操作接口时,我们已经初步接触到了“文件描述符”。文件描述符其实就是一个整数,用来唯一标识已经打开的文件,系统调用接口只通过文件描述符来区分文件。
C语言的FILE结构体内部就封装了文件描述符,对应成员叫做_fileno。
默认打开的三个流
之前学习C语言文件接口时,我们知道一个程序启动时会默认打开三个流,分别是标准输入流、标准输出流和标准错误流,这三个流分别对应文件描述符0、1、2。你可能会问:三个流难道是文件吗?实际上是如此。在Linux下,在进程层面我们认为“一切皆文件”,那么显示器和键盘也可以看作文件。我们能从键盘输入数据,实际上是从“键盘文件”读取数据;能在显示器上看到数据,实际上是向“显示器文件”写入数据。
由于程序启动时默认就打开了这三个流,所以我们在进行键盘输入/显示器输出时,无需打开文件。这三个流当中,标准输入流对应键盘,而标准输出流和标准错误流对应显示器。
注:“默认打开输入输出流”的特性并不是某种语言所特有的,而是操作系统支持的。
接下来我们尝试对描述符为0、1、2的文件进行简单操作,验证刚才的说法:
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <cstring>int main()
{//从标准输入流读取数据std::cout << "请输入:" << std::flush;char buff[20];int n = read(0, buff, sizeof(buff) - 1);//向标准输出流写入数据std::cout << "标准输出流:" << std::flush;write(1, buff, n);//向标准错误流写入数据std::cout << "标准错误流:" << std::flush;write(2, buff, n);return 0;
}
运行结果:

注:这里我们虽然没有显式输出换行符,但是它们还是自动分成了三行,原因是read是以字节流的方式读入的,我们从键盘输入数据时,按下Enter时将换行符也读进了buff,因此输出时也带上了换行符。
文件描述符的本质与文件的打开过程
很明显,一个进程可以打开多个文件。而操作系统中存在着大量进程,也就意味着操作系统中存在者大量已打开的文件。
就像管理进程一样,操作系统必然要对这些文件进行管理。因此,就一定有描述文件的结构体,还有数据结构将这些结构体组织起来。在Linux下,该结构体叫做struct file,代表被打开的文件。
那么,既然是进程打开了文件,那么进程和文件的对应关系是如何形成的呢?
实际上task_struct中有一个files_struct*类型的指针,叫做files,它指向一个struct files_struct结构体,该结构体叫做“文件描述符表”。文件描述符表就表示了当前进程打开的所有文件。

文件描述符表结构当中,有一个指针数组叫做fd_array,它的指针类型是file*,刚好指向struct file结构体,这样进程和文件就彻底连接起来了。
到这里,我们就不难得出结论:文件描述符就是fd_array的数组下标。我们传入文件描述符,系统内部就将其当作下标来访问fd_array,进而访问对应的文件(struct file结构体)。
因此,当一个文件被打开时,要先将该文件从磁盘加载到内存中(数据拷贝),形成对应struct file结构体,然后在fd_array中分配一个指针,指向file结构体。后续就可以使用该指针对应的下标(也就是文件描述符),对文件进行操作了。

那么,如果关闭文件,该文件所对应的struct file结构体就相应释放了吗?其实不一定。因为可能还有其他进程打开了这个文件。没错,如果这个文件已经被加载到内存,形成了struct file结构体,那么其他进程打开该文件时,就没必要重新创建struct file结构体,只需让其fd_array中的指针指向已经存在的struct file即可。此时如果要关闭该文件,直接释放struct file肯定是不可行的,因为其他进程还在使用该文件。所以我们能想到:struct file当中应该有类似智能指针shared_ptr的引用计数,记录有多少个进程打开了该文件。只有引用计数为0时,才会释放掉struct file。
补充:
struct file结构体描述的是已经打开的文件(也就是内存级文件),并不代表磁盘级文件。磁盘级文件和内存文件的关系就像是程序和进程的关系,程序加载到内存,运行起来后才叫做进程。磁盘级文件描述的是文件的属性和内容,而内存级文件描述了文件的打开模式、引用计数和操作集等等。操作系统为每一个硬件设备都创建一个
struct file,其中包含对设备进行读写操作的函数指针(也就是操作集)。尽管各个设备的读写接口不同,但它们的参数,返回值都相同,这样通过struct file内部的函数指针,就可通过回调的方式,用“相同的函数名”,调用不同的读写接口,在软件层屏蔽了不同设备的底层差异(C语言实现多态)。因此在进程层面,一切皆文件。
文件描述符的分配原则
文件创建时,文件描述符(也就是说fd_array的指针)并不是随机分配给新创建的文件的,而是有一定的规则。我们写一段代码进行验证:
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <cstring>int main()
{int fd1 = open("test1.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);std::cout << "fd1 : " << fd1 << std::endl;int fd2 = open("test2.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);std::cout << "fd2 : " << fd2 << std::endl;//关闭标准输入流close(0);int fd3 = open("test3.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);std::cout << "fd3 : " << fd3 << std::endl;int fd4 = open("test4.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);std::cout << "fd4 : " << fd4 << std::endl;int fd5 = open("test5.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);std::cout << "fd5 : " << fd5 << std::endl;close(fd1);close(fd2);close(fd3);close(fd4);close(fd5);return 0;
}

可以看到,fd1和fd2以及fd3、fd4和fd5是逐渐递增的。而我们关闭了0(标准输入流)后,创建的fd3占据了原本标准输入流的文件描述符。从此可以得出结论:在fd_array的数组下标中,选择没有被使用的,且是最小的那个,作为新创建文件的文件描述符。
重定向
了解了文件描述符的分配规则以后,我们就可以利用它进行“重定向”操作了。先看一段代码:
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <cstring>int main()
{close(1); // 关闭标准输出流int fd = open("test.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if(fd < 0){std::cerr << "open error" << std::endl;return 1;}std::cout << "hello world" << std::endl;close(fd);return 0;
}
上述代码中,我们首先关闭了标准输出流,然后创建了一个新文件。按照分配规则,则新文件会占据原本标准输出流的文件描述符“1”,此时我们再使用cout向标准输出流打印。结果如下:

可以看到,出现了一个文件,其内容包含了我们要打印的字符串。其实这种操作就叫做“输出重定向”。由于标准输出只针对与文件描述符为1的文件,所以重定向操作是将fd_array数组下标为1的指针指向修改到其他文件,导致标准输出不再作用于显示器。

当然,同样的原理也可实现“输入重定向”“追加重定向(不清空重定向的文件进行追加写入)”等操作。
Linux下,有帮助我们进行重定向的系统调用:
#include <unistd.h>int dup2(int oldfd, int newfd);
该函数会让文件描述符newfd所对应的指针指向oldfd所对应的文件。如果成功,返回newfd;否则返回-1。注意:oldfd必须是一个有效的文件描述符。
使用示例:
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <cstring>int main()
{int fd = open("test.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if(fd < 0){std::cerr << "open error" << std::endl;return 1;}dup2(fd, 1); // 让标准输出指向创建的新文件std::cout << "hello world" << std::endl;close(fd);return 0;
}
四、缓冲区
之前我们学习C语言时,就已经接触过“缓冲区”的概念,今天我们就结合对内存级文件的了解,深入学习一下缓冲区。
缓冲区的本质就是一块内存区域。在操作系统中,实际上有两种不同的缓冲区:语言级缓冲区和文件内核缓冲区。
以C语言举例,创建文件时要调用fopen函数,它返回一个FILE*指针。此时,操作系统当中就会出现一个FILE结构对象,用来在语言层管理文件(例如之前提到的_fileno封装)。而C语言语言层的缓冲区就存在于FILE结构体中。当出现以下三种情况之一,缓冲区内的数据就会被刷新,写入到系统级的文件内核缓冲区中:
- 强制刷新(如调用fflush)
- 满足以下刷新条件之一
- 处于写透模式 – 没有缓冲机制,立即刷新
- 缓冲区满了
- 行缓冲(换行时缓冲,一般针对显示器)
- 进程退出
而文件内核缓冲区的刷新策略十分复杂,我们可以理解为只要从语言层缓冲区刷新到文件缓冲区,就相当于将数据交给了硬件。
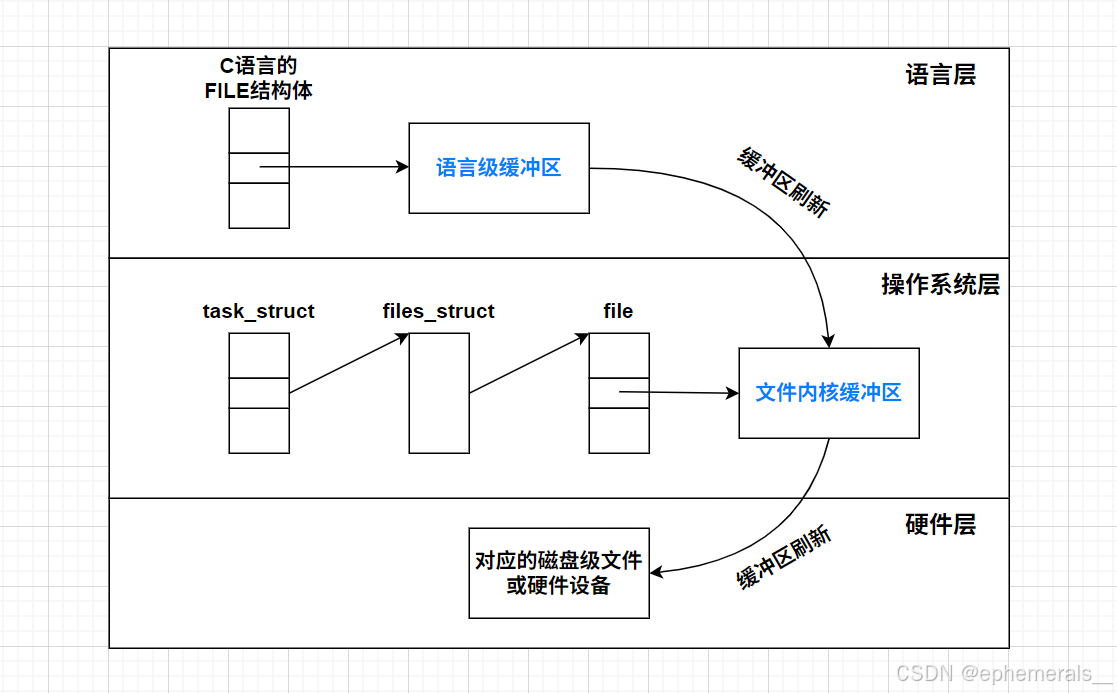
其实不需要缓冲区,就可以实现语言层到硬件层的数据交互。那么为什么会存在缓冲区呢?
- 语言层缓冲区存在的意义:将数据写入文件必须通过系统调用,频繁使用系统调用的时间成本过高,使用语言层缓冲区将多次写入的数据收集起来,再统一写入,显著减少了使用系统调用的次数,提高效率。
- 文件内核缓冲区存在的意义:提高系统调用的运行效率。
注:如果进行了重定向,那么对应文件的缓冲区刷新策略也会修改,因为文件被换走了,不同的文件,缓冲区刷新策略可能不同。
Linux的系统调用fsync可以将文件缓冲区的数据刷新到外设当中:
#include <unistd.h>int fsync(int fd); // 传入对应的文件描述符
小练习
判断以下代码的运行结果:
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <cstring>int main()
{int fd = open("test.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if(fd < 0){std::cerr << "open error" << std::endl;return 1;}dup2(fd, 1); // 输出重定向printf("printf\n");fprintf(stdout, "fprintf\n");const char* s = "write\n";size_t len = strlen(s);write(1, s, len);fork(); // 创建子进程return 0;
}
运行结果:
![[Pasted image 20250601223628.png]]
解释:我们首先将标准输出重定向到test.txt文件中,然后进行三种写入操作。原本它们是要向显示器打印的,但由于重定向操作,改为向文件写入数据。因此,即便字符串末尾有“\n”,也没有刷新语言层缓冲区内的字符串,因此文件中先写入了“write”(因为这里直接通过系统调用写入,没有语言层缓冲区)。然后我们用fork创建了一个子进程,子进程和父进程共用一份代码和数据,由于语言层缓冲区位于FILE结构体中(也就是栈区中),因此父子进程共用一个语言层缓冲区。然后父子进程各退出一次,也就将语言层缓冲区刷新了两次,因此文件中就出现了两次“printf”和"fprintf"。
总结
本篇文章,我们深入学习了Linux的文件IO接口,并且对内存级文件的存储结构、缓冲区等概念有了深刻的认知。在内存级文件的基础上,博主接下来会和大家一起进入“磁盘级文件”的学习,深入理解文件系统相关知识。如果你觉得博主讲的还不错,就请留下一个小小的赞在走哦,感谢大家的支持❤❤❤