机器学习:逻辑回归与混淆矩阵
本文目录:
- 一、逻辑回归Logistic Regression
- 二、混淆矩阵
- (一)精确率precision
- (二)召回率recall
- (三)F1-score:了解评估方向的综合预测能力
- (四)Roc曲线
- (五)Auc面积
一、逻辑回归Logistic Regression
基本思想:逻辑回归的假设函数: h(w) = sigmoid(wx + b ),线性回归的输出,作为逻辑回归的输入;逻辑回归特别适用于二分类问题,也可以用于多分类问题的处理。
• 具体流程:
- 利用线性模型 f(x) = wx + b 根据特征的重要性计算出一个值;
- 再使用 sigmoid 函数将 f(x) 的输出值映射为概率值;
- 设置阈值,进行判定。比如针对二分类问题,如果输出概率值大于阈值(eg: 0.5),则将未知样本输出为一类(eg: 1 类);否则输出为另一类(eg: 0 类)。
代码如下:
例:
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScalerdef dm01_LogisticRegression():# 1. 获取数据.data = pd.read_csv('data/breast-cancer-wisconsin.csv')data.info()# 2. 数据预处理.# data = data.replace(to_replace='?', value=np.NAN)data = data.replace('?', np.NaN)data = data.dropna()data.info()# 3. 确定特征值和目标值.x = data.iloc[:, 1:-1]y = data.Classprint(f'x.head(): {x.head()}')print(f'y.head(): {y.head()}')# 3. 分割数据.x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=21)# 4. 特征处理.transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 5. 模型训练.estimator = LogisticRegression()estimator.fit(x_train, y_train)# 6. 模型预测y_predict = estimator.predict(x_test)print(f'预测值: {y_predict}')# 7. 模型评估print(f'准确率: {estimator.score(x_test, y_test)}')print(f'准确率: {accuracy_score(y_test, y_predict)}')if __name__ == '__main__':dm01_LogisticRegression()
二、混淆矩阵
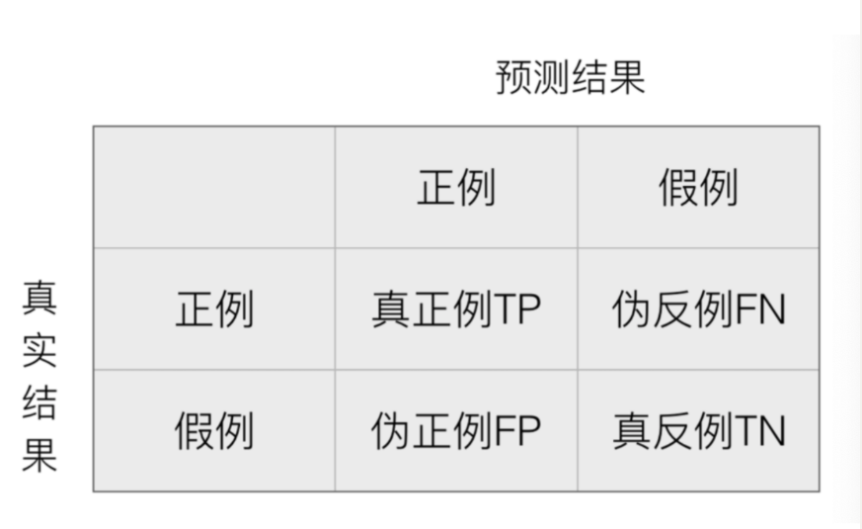
(一)精确率precision
精确率也叫做查准率,指的是对正例样本的预测准确率。
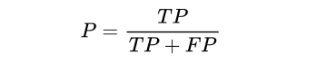
例子:**
样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A: 预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP 为:3
- 伪反例 FN 为:3
- 假正例 FP 为:0
- 真反例 TN:4
- 精准率:3/(3+0) = 100%
模型 B: 预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP 为:6
- 伪反例 FN 为:0
- 假正例 FP 为:3
- 真反例 TN:1
- 精准率:6/(6+3) = 67%
(二)召回率recall
召回率也叫做查全率,指的是预测为真正例样本占所有真实正例样本的比重。
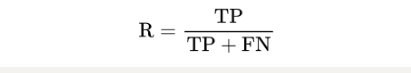
例子:**
样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A: 预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP 为:3
- 伪反例 FN 为:3
- 假正例 FP 为:0
- 真反例 TN:4
- 精准率:3/(3+0) = 100%
- 召回率:3/(3+3)=50%
模型 B: 预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP 为:6
- 伪反例 FN 为:0
- 假正例 FP 为:3
- 真反例 TN:1
- 精准率:6/(6+3) = 67%
- 召回率:6/(6+0)= 100%
(三)F1-score:了解评估方向的综合预测能力
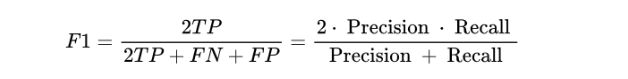
(四)Roc曲线
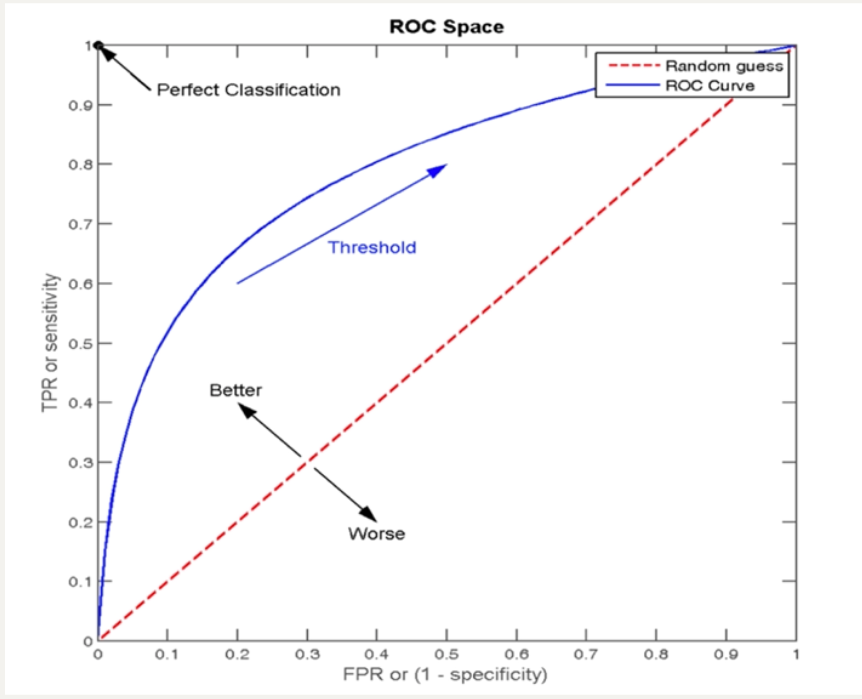
ROC 曲线:
- 正样本中被预测为正样本的概率,即:TPR (True Positive Rate)
- 负样本中被预测为正样本的概率,即:FPR (False Positive Rate)
以FPR为横坐标,TPR为纵坐标,描出不同阈值下的点所形成的曲线就是Roc曲线。
(五)Auc面积
Auc面积:
AUC 是 ROC 曲线下面的面积,该值越大,则模型的辨别能力就越强。AUC 范围在 [0, 1] 之间,主要用来判断模型对正例和负例的辨别能力。
图像越靠近 (0, 1) 点则 ROC 曲线下面的面积就会越大,对正负样本的辨别能力就越强;当 AUC= 1 时,该模型被认为是完美的分类器,但是几乎不存在完美分类器。
例:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, roc_auc_score# 1. 定义函数, 表示: 数据基本处理
def dm01_数据基本处理():# 1. 读取数据, 查看数据的基本信息.churn_pd = pd.read_csv('data/churn.csv')# churn_pd.info()# print(f'churn_pd.describe(): {churn_pd.describe()}')# print(f'churn_pd: {churn_pd}')# 2. 处理类别型的数据, 类别型数据做 one-hot编码(热编码).churn_pd = pd.get_dummies(churn_pd)churn_pd.info()# print(f'churn_pd: {churn_pd}')# 3. 去除列 Churn_No, gender_Malechurn_pd.drop(['Churn_No', 'gender_Male'], axis=1, inplace=True) # 按列删除print(f'churn_pd: {churn_pd}')# 4. 列标签重命名, 打印列名churn_pd.rename(columns={'Churn_Yes': 'flag'}, inplace=True)print(f'列名: {churn_pd.columns}')# 5. 查看标签的分布情况 0.26用户流失value_counts = churn_pd.flag.value_counts()print(value_counts)# 2. 定义函数, 表示: 特征筛选
def dm02_特征筛选():# 1. 读取数据churn_pd = pd.read_csv('data/churn.csv')# 2. 处理类别型的数据, 类别型数据做 one-hot编码(热编码).churn_pd = pd.get_dummies(churn_pd)# 3. 去除列 Churn_No, gender_Malechurn_pd.drop(['Churn_No', 'gender_Male'], axis=1, inplace=True)# 4. 列标签重命名churn_pd.rename(columns={'Churn_Yes': 'flag'}, inplace=True)# 5. 查看标签的分布情况value_counts = churn_pd.flag.value_counts()print(value_counts)# 6. 查看Contract_Month 是否预签约流失情况sns.countplot(data=churn_pd, x='Contract_Month', hue='flag')plt.show()# 3. 定义函数, 表示: 模型训练 和 评测
def dm03_模型训练和评测():# 1. 读取数据churn_pd = pd.read_csv('data/churn.csv')# 2. 数据预处理# 2.1 处理类别型的数据, 类别型数据做 one-hot编码(热编码).churn_pd = pd.get_dummies(churn_pd)# 2.2 去除列 Churn_No, gender_Malechurn_pd.drop(['Churn_No', 'gender_Male'], axis=1, inplace=True)# 2.3 列标签重命名churn_pd.rename(columns={'Churn_Yes': 'flag'}, inplace=True)# 3. 特征处理.# 3.1 提取特征和标签x = churn_pd[['Contract_Month', 'internet_other', 'PaymentElectronic']]y = churn_pd['flag']# 3.2 训练集和测试集的分割x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=21)# 4. 模型训练.estimator = LogisticRegression()estimator.fit(x_train, y_train)# 5. 模型预测y_predict = estimator.predict(x_test)print(f'预测结果: {y_predict}')# 6. 模型评估print(f'准确率: {accuracy_score(y_test, y_predict)}')print(f'准确率: {estimator.score(x_test, y_test)}')# 计算AUC值.print(f'AUC值: {roc_auc_score(y_test, y_predict)}')if __name__ == '__main__':# dm01_数据基本处理()# dm02_特征筛选()dm03_模型训练和评测()今天的分享到此结束。