大模型备案中语料安全详细说明
《AIGC安全要求》针对语料安全,在语料来源授权合法、安全评估核验、不良语料类型三个方面提出了重点要求,具体要求包括:
1、授权合法
语料的来源需要有合法的、明确的授权,确保其符合“授权、同意、告知”的合法性原则。根据语料的来源属性分类,具体的要求梳理如下:
| 语料来源 | 含义 | 合规要求 |
| 开源语料 | 是训练数据的主要来源,指开放的,任何人得以获取的语料 | 应具有该语料来源的开源许可协议或相关授权文件,建议重点关注: |
| 自采语料 | 是指自行生产或直接从互联网采集的语料 | 应具有采集记录,不应采集他人已明确不可采集的语料 |
| 商业语料 | 是自采语料的对应概念,指通过与第三方语料提供方进行交易获得的语料 | 应有具备法律效力的交易合同、合作协议等,且当交易方或合作方不能提供语料来源、质量、安全等方面的承诺以及相关证明材料时,不应使用该语料,这就要求相关方对交易方或合作方所提供的语料、承诺、材料进行审核 |
| 使用者输入语料 | 是指将使用者输入的信息作为语料 | 应具有使用者授权记录 |
2、安全评估与核验
对于采集的语料,需要严格控制违法不良信息的比率。语料采集前,需要进行针对违法不良信息进行安全评估,采集后输入语料库之后需要进行再次核验。
具体而言,如采集前评估得出违法不良信息超过5%,则该来源不得被采集;如若采集后核验违法不良信息超过5%,则该来源不得被使用。虽然两步走的设置看似天衣无缝,但从部分企业的尽调结果来看,相应管控和筛查的工作目前仍未到位。语料安全作为生产资料的重要组成部分,评估不当很可能导致紧随其后的产品研发环节就出现问题。
除此以外,还需要遵循在内容过滤、知识产权、个人信息、标注安全等方面的合规要求:

语料来源合规要求
因此,企业需要在首次安全评估之后保持对语料来源的持续敏感度。并在之后的操作处理中进行持续性的内容过滤,采取关键词、分类模型、人工抽检等方式过滤违法不良信息。
对于涉及知识产权和个人信息的语料,还应当设置专门的负责人和管理策略,在使用之前注意该语料是否存在侵犯他人权利的情况,并与相关方提前协商,告知有关风险或取得其授权同意,并取得正式性的记录文件;要求语料提供方提供语料来源、质量安全等承诺以及相关证明材料并进行审核。
3、不良语料类型
对于具体需要规避的语料类型,《AIGC安全要求》附录A列举了涉及语料及生成内容安全的类型,共分为5类31种,制定了特别的安全需求:
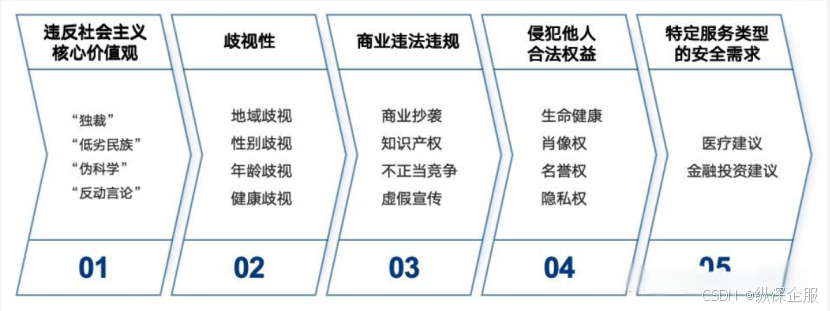 不良语料类型
不良语料类型
需要特别关注的是,本次不良语料类型特别提出了针对“特定服务类型”的安全需求。
例如,针对医疗建议类的算法和问答建议,当前不少医疗健康产品和服务当中,开发了智能健康管家等功能,涉及根据用户的健康分析报告,提出对应的诊疗分析、用药建议等,对于这一类功能,需要特别谨慎对待其是否可能出现非专业性、误导性的用药和诊断结论,否则可能导致“无病呻吟”或“病急乱投医”的情况。
例如,针对金融投资建议类的算法和分析建议,需要遵循银行、保险、金融等方面对于投资者、投保人的合法权益保护,避免违反相关的监管规定,为了业务竞争而向投资者、投保人等通过AI作出涉及不正当竞争、违反金融风险管控的分析或违规引导。