Go语言中的rune和byte类型详解
1. rune类型
1.1. 基本概念
1. rune是Go语言的内建类型,它是int32的别名,即32位有符号整数;
2. 用于表示一个Unicode码点,全拼Unicode code point;
3. 可以表示任何UTF-8编码的字符;
1.2. 特点
1. 每个rune对应一个Unicode字符;
2. 可以表示超过ASCII范围的字符,如中文、日文、表情等;
3. 在内存中占用4个字节,即32位;
1.3. 使用示例
func main() {s := "你好,世界"for _, r := range s {fmt.Printf("%c => %U\n", r, r)}
}2. byte类型
2.1. 基本概念
1. byte是Go语言的内建类型,它是uint8的别名,即8位无符号整数;
2. 用于表示一个ASCII字符或UTF-8编码的一个字节;
2.2. 特点
1. 每个byte对应一个字节,其中每个字创8位;
2. 只能表示ASCII字符或UTF-8编码的单个字节;
3. 在内存中占用1个字节;
2.3. 使用示例
func main() {s := "Hello"for i := 0; i < len(s); i++ {fmt.Printf("%c => %d\n", s[i], s[i])}
}3. rune和byte的主要区别
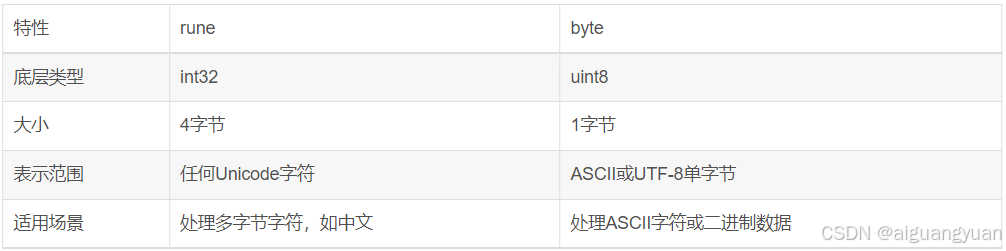
4. 字符串遍历时的差异
4.1. 使用byte遍历,可能出错
s := "你好"
for i := 0; i < len(s); i++ {fmt.Printf("%x ", s[i]) // 打印UTF-8编码的每个字节
}
// 输出: e4 bd a0 e5 a5 bd (6个字节)4.2. 使用rune遍历,正确方式
s := "你好"
for _, r := range s {fmt.Printf("%c ", r) // 打印每个Unicode字符
}
// 输出: 你 好5. 类型转换
5.1. 字符串转[]rune
s := "你好"
runes := []rune(s) // 转换为rune切片5.2. []rune转字符串
runes := []rune{'你', '好'}
s := string(runes)5.3. 字符串转[]byte
s := "你好"
bytes := []byte(s) // 转换为byte切片5.4. []byte转字符串
bytes := []byte{0xe4, 0xbd, 0xa0} // "你"的UTF-8编码
s := string(bytes)6. 实际应用场景
6.1. rune的典型使用场景
1. 处理包含非ASCII字符的字符串;
2. 需要按字符而非字节操作字符串时;
3. 计算字符串的实际字符数而非字节数;
func countChars(s string) int {return len([]rune(s))
}6.2. byte的典型使用场景
1. 处理二进制数据;
2. 处理纯ASCII字符串;
3. 需要与底层字节交互时;
func processBinary(data []byte) {// 处理字节数据
}7. 注意事项
1. 使用len()函数直接获取字符串长度时,返回的是字节数而非字符数;
2. 对非ASCII字符串按索引访问时,得到的是UTF-8编码的单个字节而非完整字符;
3. 在range循环中迭代字符串时,会自动按rune处理;
正确获取字符串字符数的方法:
s := "你好,世界"
charCount := utf8.RuneCountInString(s) // 或者 len([]rune(s))