【深度学习】14. DL在CV中的应用章:目标检测: R-CNN, Fast R-CNN, Faster R-CNN, MASK R-CNN
深度学习在计算机视觉中的应用介绍
深度卷积神经网络(Deep convolutional neural network, DCNN)是将深度学习引入计算机视觉发展的关键概念。通过模仿生物神经系统,深度神经网络可以提供前所未有的能力来解释复杂的数据模式,从而有效地解决各种计算机视觉任务
在本节中,我们聚焦于深度学习在计算机视觉领域的主要应用场景。从图像分类到目标检测、从图像分割到图像生成,深度学习的能力已渗透到 CV 的各个角落。
我们首先思考以下几个关键问题:
- 视觉数据的挑战:高维、结构化、不变性差异
- 深度学习如何胜任这些复杂任务?
- 不同任务如何设计模型结构和训练方法?
本讲义将围绕以下典型视觉任务展开:
图像分类、目标检测、图像分割、图像生成,以及跨模态视觉理解(如图文匹配、图文检索、文本生成图像等)。
图像分类
图像分类是最经典的计算机视觉任务之一,其目标是将一张图像分为若干已知类别中的一个。
典型的模型结构为卷积神经网络(CNN),代表性模型包括:
- AlexNet(2012):首次大规模使用 GPU 训练 CNN,在 ImageNet 上大幅超越传统方法
- VGG(2014):使用多个 3 × 3 3 \times 3 3×3 卷积层堆叠
- ResNet(2015):引入残差连接,解决深层网络训练难题
- EfficientNet:通过复合缩放(depth、width、resolution)提高性能与效率
现代图像分类模型的核心流程如下:
-
图像预处理(缩放、归一化)
-
特征提取(多层卷积层提取空间特征)
-
分类器(通常为全连接层 + softmax)
-
训练目标为最小化交叉熵损失:
L = − ∑ c = 1 C y c log ( y ^ c ) \mathcal{L} = -\sum_{c=1}^C y_c \log(\hat{y}_c) L=−c=1∑Cyclog(y^c)
其中 y c y_c yc 为真实标签的 one-hot 编码, y ^ c \hat{y}_c y^c 为预测概率。
卷积神经网络结构回顾
典型的 CNN 包含以下几类模块:
- 卷积层(Convolution):提取局部区域特征,具有参数共享与局部连接的特点
- 激活函数(ReLU、Leaky ReLU、Swish 等):增加非线性表达能力
- 池化层(Pooling):下采样,提升不变性(常用 max-pooling, average pooling)
- 批归一化(BatchNorm):稳定训练过程,加速收敛
- 全连接层(FC):用于最终分类或回归任务
卷积层的基本公式为:
Conv ( x ) = ∑ i , j W i , j ⋅ x i , j + b \text{Conv}(x) = \sum_{i,j} W_{i,j} \cdot x_{i,j} + b Conv(x)=i,j∑Wi,j⋅xi,j+b
其中 W W W 为卷积核, x x x 为输入特征图, b b b 为偏置。
数据增强
数据增强在图像分类中扮演重要角色,常用方法包括:
- 几何变换(旋转、平移、缩放、剪裁、翻转)
- 颜色扰动(亮度、对比度、饱和度、色调)
- 随机擦除、MixUp、CutMix 等高级方法
增强的目的:
- 提升模型的泛化能力
- 增强训练数据的多样性
- 减少过拟合风险
例如 CutMix 会将一张图像的一部分替换为另一张图像的一块区域,同时调整标签为加权平均。
训练技巧与优化器选择
图像分类模型的训练通常采用以下优化技巧:
- 使用 Adam 或 SGD with momentum 优化器
- 使用学习率调度器(Cosine Annealing、Step Decay)
- 使用早停(Early Stopping)避免过拟合
- 使用预训练模型进行 fine-tuning,加速训练并提升性能
常见的损失函数为交叉熵损失;多标签分类中使用二元交叉熵(Binary Cross-Entropy)或 Focal Loss。
用回归定位对象 Localize objects with regression
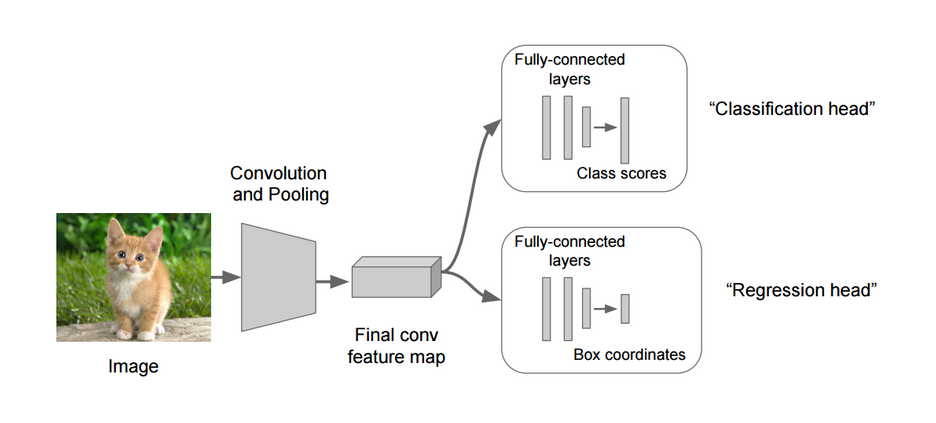
box coordinates有四个坐标,与正确的坐标求L2 distance的loss。
这是个多任务模型,loss是分类头的loss+regression的loss
Coco Dataset的数据格式
"annotations": [{"id": 1,"image_id": 397133,"category_id": 18,"bbox": [258.15, 41.29, 348.26, 243.78],"area": 83634.3,"iscrowd": 0,"segmentation": [[...]]}
]
id:标注 ID
image_id:对应图像的 ID(与 images 中的 ID 对应)
category_id:物体类别 ID(与 categories 中对应)
bbox:边界框,格式为 [x_min, y_min, width, height]
segmentation:实例分割的多边形坐标
area:目标面积
iscrowd:是否为拥挤目标(例如人群、羊群)
iscrowd = 0:表示该目标是一个单独实例(常见)
→ 可以用标准的边界框和多边形分割进行标注。
iscrowd = 1:表示该目标是一组密集难分割的实例集合,例如:
- 一群密集站立的人(如马拉松)
- 一堆拥挤的动物(如羊群)
- 远处的小目标难以区分单个实例时
目标检测(Object Detection)
目标检测任务不仅要判断图像中是否存在某一类物体,还要精确定位该物体在图像中的位置,通常以边界框(bounding box)的形式输出。
目标检测任务输出通常包含:
- 类别标签(classification)
- 边界框坐标(localization): ( x , y , w , h ) (x, y, w, h) (x,y,w,h) 表示中心坐标和宽高
目标检测的挑战
- 单图多目标:可能含有多个物体,且类别不同
- 目标尺度变化大:小目标识别困难
- 遮挡与背景干扰:检测器需具备鲁棒性
- 实时性需求高:尤其在无人驾驶、监控等场景
检测模型分类
目标检测方法主要分为:
-
两阶段方法(Two-stage)
- 如 R-CNN、Fast R-CNN、Faster R-CNN
- 第一阶段提取候选区域(Region Proposals)
- 第二阶段对每个区域进行分类与回归
-
一阶段方法(One-stage)
- 如 YOLO(You Only Look Once)、SSD、RetinaNet
- 直接从图像特征中预测物体类别和边界框
- 更快,但精度略低于 two-stage
Region CNN R-CNN
R-CNN(Regions with Convolutional Neural Networks)是 Ross Girshick 等人于 2014 年提出的经典目标检测算法。该方法首次将卷积神经网络(CNN)应用于区域级目标检测,极大提升了检测准确率,是深度学习检测模型的重要里程碑。

核心思想
R-CNN 的思想是将目标检测任务拆分为两个阶段:
- 使用 Selective Search 提取图像中的候选区域(Region Proposals)
- 对每个候选区域使用 CNN 提取特征,然后使用分类器判断是否包含目标,并通过回归器微调边界框
R-CNN 的整体流程
R-CNN 的检测流程如下:
- 输入一张图像
- 采用 Selective Search 提取约 2000 个候选框
- 将每个候选框裁剪出来,变形成固定尺寸(如 227 × 227 227 \times 227 227×227)
- 将每个区域送入 CNN 提取特征
- 使用 SVM 对特征进行分类(每类一个二分类器)
- 使用 边界框回归器 对检测框进行位置微调
R-CNN 的优点
| 优点 | 描述 |
|---|---|
| 引入 CNN 特征 | 利用深度学习特征表示提升准确率 |
| 检测精度高 | 在 PASCAL VOC 数据集显著优于传统方法 |
| 模块化结构 | 特征提取、分类、回归分离,易于调试与分析 |
R-CNN 的缺点
| 缺点 | 描述 |
|---|---|
| 计算重复 | 每个候选区域单独送入 CNN,极度耗时 |
| 非端到端训练 | CNN、SVM、回归器需分阶段训练 |
| 图像变形 | 所有区域强行 resize,可能损失信息 |
| 推理速度慢 | 每张图像需处理约 2000 个区域 |
背景动机(Motivation)
- Sliding window approach 不适用于 CNN:
- 传统滑动窗口方法在整张图上以不同大小和比例滑动窗口来定位目标,但这对 CNN 来说计算量巨大,效率低下。
- 我们需要一种更快、更有效的方法来识别目标候选区域。
如何生成候选区域(Finding object proposals)
Selective Search 通过图像分割和区域合并策略来生成潜在的目标区域,其核心步骤包括:
1. 贪心层次化超像素分割(Greedy hierarchical superpixel segmentation)
- 图像首先被划分成一组细粒度的超像素区域
- 然后使用贪心算法进行层次化区域合并
2. 多样化的超像素构建与合并策略(Diversification of superpixel construction and merge)
为了增强鲁棒性和覆盖更多候选区域,Selective Search 提供多种策略组合:
- 使用不同的 颜色空间(如 RGB、HSV 等)
- 使用不同的 相似度度量方法(颜色、纹理、大小等)
- 使用不同的 起始区域(starting regions),增加多样性
Bounding Box Regression(边界框回归)
边界框回归(Bounding Box Regression)是 R-CNN 中用于提高候选框定位精度的重要步骤。其核心思想是对初始候选框进行微调,使其更加贴合真实目标位置。该模块以回归的方式学习从候选框到真实框的几何变换。
我们将候选框记为:
P = ( P x , P y , P w , P h ) P = (P_x, P_y, P_w, P_h) P=(Px,Py,Pw,Ph)
其中, P x , P y P_x, P_y Px,Py 是候选框的中心坐标, P w , P h P_w, P_h Pw,Ph 是宽度与高度。
对应的真实框表示为:
G = ( G x , G y , G w , G h ) G = (G_x, G_y, G_w, G_h) G=(Gx,Gy,Gw,Gh)
目标是学习一个变换函数 d ( P ) d(P) d(P),其形式为:
d ( P ) = ( t x , t y , t w , t h ) d(P) = (t_x, t_y, t_w, t_h) d(P)=(tx,ty,tw,th)
表示对候选框中心位置和宽高的平移与缩放。
通过该变换,我们可以得到预测框的坐标:
G ^ x = P w ⋅ d x ( P ) + P x \hat{G}_x = P_w \cdot d_x(P) + P_x G^x=Pw⋅dx(P)+Px
G ^ y = P h ⋅ d y ( P ) + P y \hat{G}_y = P_h \cdot d_y(P) + P_y G^y=Ph⋅dy(P)+Py
G ^ w = P w ⋅ exp ( d w ( P ) ) \hat{G}_w = P_w \cdot \exp(d_w(P)) G^w=Pw⋅exp(dw(P))
G ^ h = P h ⋅ exp ( d h ( P ) ) \hat{G}_h = P_h \cdot \exp(d_h(P)) G^h=Ph⋅exp(dh(P))
其中 d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) d_x(P), d_y(P), d_w(P), d_h(P) dx(P),dy(P),dw(P),dh(P) 是回归网络输出的四个变换值,用于对候选框进行调优。
回归函数本质上是对候选框特征向量进行线性变换。使用的是 CNN 的第五层池化输出( p o o l 5 pool5 pool5 层)作为特征 ϕ 5 ( P ) \phi_5(P) ϕ5(P),并通过线性变换预测回归值:
d i ( P ) = w i ⊤ ϕ 5 ( P ) d_i(P) = \mathbf{w}_i^\top \phi_5(P) di(P)=wi⊤ϕ5(P)
为了学习最优的回归参数 w i \mathbf{w}_i wi,使用如下的最小化损失函数:
w i ∗ = arg min w i ∑ k = 1 N ( t i k − w i ⊤ ϕ 5 ( P k ) ) 2 + λ ∥ w i ∥ 2 \mathbf{w}_i^* = \arg \min_{\mathbf{w}_i} \sum_{k=1}^{N} \left( t_i^k - \mathbf{w}_i^\top \phi_5(P^k) \right)^2 + \lambda \|\mathbf{w}_i\|^2 wi∗=argwimink=1∑N(tik−wi⊤ϕ5(Pk))2+λ∥wi∥2
该损失函数包含两部分:预测误差平方项和正则化项。通过最小化该损失,模型可以学习到将候选框调整为更接近真实框的变换方式。
因为 回归模型并不是直接预测最终的框坐标(如 G ^ x \hat{G}_x G^x),而是预测候选框
P与真实框G之间的 相对变换值t。所以:模型学习的是从 **候选框特征 ϕ§ 到 **几何变换 t i t_i ti 的映射。
Fast R-CNN
Fast R-CNN 是对早期 R-CNN 方法的重大改进,由 Ross Girshick 于 2015 年提出,用于提高目标检测的速度和准确性。它在保持精度的同时,大大减少了训练与测试时间。
Fast R-CNN 的设计动机
R-CNN 存在三个显著问题:
- 多阶段训练:特征提取、SVM分类器训练、边界框回归是分开的。
- 计算重复:每个候选区域单独提取 CNN 特征,导致高昂计算代价。
- 测试慢:每张图像要运行上千次 CNN 前向传播。
为了解决这些问题,Fast R-CNN 做出以下创新:
-
端到端训练
-
将分类和边界框回归整合进同一个神经网络中,采用多任务损失函数,实现 joint training。
以 R-CNN 为例,目标检测被拆成三步:
- 提取候选框(Selective Search) — 不可训练
- 对每个候选框提特征(CNN) — 可训练但单独训练
- 分类器和回归器(SVM + Linear Regressor) — 分别训练
每一部分是分开训练的,不能统一优化,导致效率低、性能受限。
在 Fast R-CNN 中:
-
图像输入后,经过 CNN → RoI Pooling → 全连接 → 分类 + 回归
-
所有模块连成一个网络
-
整个网络通过一个多任务损失函数:
L = L 分类 + λ L 边界框回归 L = L_{\text{分类}} + \lambda L_{\text{边界框回归}} L=L分类+λL边界框回归
-
所有参数一起反向传播、一起优化
-
-
特征共享
-
整张图像只做一次 CNN 前向传播,生成一张共享的 feature map,再从中提取区域特征,极大减少计算量。
在 R-CNN 中:
- 每个 Region Proposal(候选框)都从原图中裁剪出图像块;
- 然后对每个图像块单独送进 CNN 提取特征;
- 图像中有 2000 个 RoI,就跑 2000 次 CNN → 慢得惊人!
在 Fast R-CNN 中:
- 整张图像只跑一次 CNN,得到一个大的 Feature Map(特征图);
- 每个 RoI(候选框)在这个 Feature Map 上找到对应的子区域;
- 使用 RoI Pooling 把这个区域变成固定大小的特征向量;
- 所有 RoI 都复用同一张特征图。
-
-
引入ROI Pooling 层
-
将不同比例的区域(Region of interest, Roi)统一变成固定大小的特征输出
例如将每个区域映射成固定的7x7
ROI Pooling 的核心就是:在特征图上选出每个 ROI 区域 → 划分成固定网格 → 每个网格中取最大值 → 得到固定大小的特征表示。
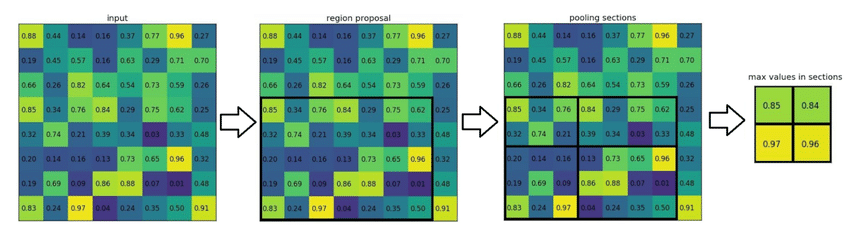
假设你有一个 ROI:
- 位于 CNN 的 feature map 上
- ROI 的大小是 w × h w \times h w×h,单位是特征图坐标
- 你想将这个 ROI 划分成 H out × W out H_{\text{out}} \times W_{\text{out}} Hout×Wout 个池化网格(例如 2×2)
那么每个网格的大小是:
bin width = w W out , bin height = h H out \text{bin width} = \frac{w}{W_{\text{out}}}, \quad \text{bin height} = \frac{h}{H_{\text{out}}} bin width=Woutw,bin height=Houth
-
Faster R-CNN 架构解析
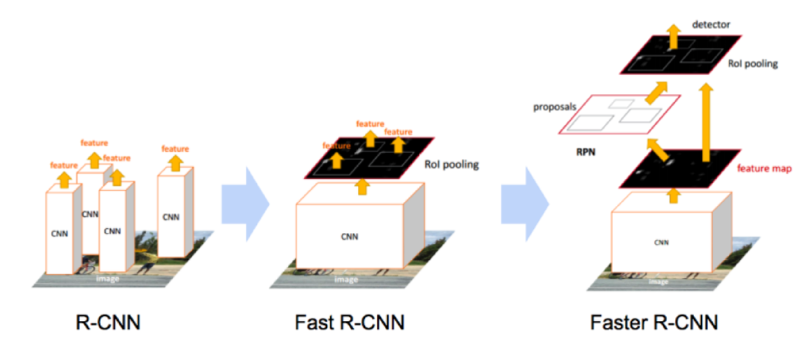
Faster R-CNN 是一个端到端训练的、两阶段的目标检测框架。它是 Fast R-CNN 的增强版本,解决了目标检测中的一个瓶颈问题——候选框生成(Region Proposals)速度慢。
Fast R-CNN 尽管训练端到端、推理快速,但依赖外部的候选框生成器 —— Selective Search,这是一个非神经网络算法,速度慢,不能端到端训练。
Faster R-CNN 用一个小的神经网络 RPN(Region Proposal Network) 来自动学习生成候选框,取代了传统的 Selective Search。
这使得整个模型从图像输入到最终检测结果都可以一体化训练(end-to-end)。
Region Proposal Network(RPN)阶段
- 输入:整张图像
- 输出:一组高质量的候选框(RoIs),通常 300~2000 个
- 特点:
- 使用 CNN 特征图
- 在特征图上滑动 3×3 小窗口,输出:
- 2 个分类(前景 / 背景)
- 4 个边界框回归偏移量
- 每个滑窗生成多个候选框(称为 anchor boxes)
Anchor Boxes
- 每个位置有多个“锚框”,定义不同的尺度和宽高比
- 比如:3 种尺度 × 3 种宽高比 = 9 个 anchor per location
- 每个 anchor 都有:
- 2 个神经元输出类别(前景/背景)
- 4 个神经元预测坐标偏移量
Mask R-CNN:实例分割的深度学习解决方案
一、引言
在图像理解任务中,实例分割(Instance Segmentation)是一项重要但具有挑战性的任务。它要求模型不仅要识别图像中的所有目标(目标检测),还要为每个目标提供像素级的掩码区域(分割)。Mask R-CNN 是由 Facebook AI Research 提出的一种强大架构,它在 Faster R-CNN 的基础上扩展了掩码预测功能,成为当前实例分割的主流方法之一。
二、Mask R-CNN 简介
Mask R-CNN 是一个两阶段的实例分割框架:
- 第一阶段使用 Region Proposal Network(RPN)生成候选区域(Region of Interest, RoI)。
- 第二阶段对每个候选区域进行三项预测:类别分类、边界框回归、像素级掩码生成。
Mask R-CNN 的结构可以表示为:
- Backbone 网络(如 ResNet + FPN):提取整张图像的特征图。
- RPN:生成候选区域。
- RoIAlign:对候选区域从特征图中提取固定大小的区域特征。
- 三个输出分支:
- 分类分支:预测目标的类别。
- 边框分支:预测目标的精确位置。
- 掩码分支:预测每个目标的像素级掩码。
三、RoIAlign:像素级对齐的新方法
RoI Pooling 在 Faster R-CNN 中用于提取固定尺寸的特征图,但它在将浮点坐标量化为整数时会引入空间不对齐的问题。为了解决这个问题,Mask R-CNN 引入了 RoIAlign。
RoIAlign 的特点如下:
- 不进行坐标的量化,保留浮点数精度。
- 使用双线性插值来从原始特征图中采样。
- 输出固定大小(如 14 × 14 14 \times 14 14×14)的特征图,保证空间对齐。
通过精确的对齐方式,RoIAlign 有效提高了掩码预测的质量,特别是在小目标或边缘精度要求高的应用中表现更好。
RoIAlign 原理讲解案例:识别桌子上的一杯水
案例背景
在本案例中,我们以“识别桌子上的一杯水”为例,讲解 RoI Pooling 与 RoIAlign 的区别,以及 RoIAlign 在实例分割中为何更准确。
设有一张输入图像,大小为 600 × 600 600 \times 600 600×600 像素,图中是一张桌子,桌子上放着一杯水。
模型经过前向传播,产生了一个候选框(Region of Interest, RoI),框住了这杯水。该候选框的坐标为:
- 左上角 ( x 1 = 150 , y 1 = 150 ) (x_1 = 150, y_1 = 150) (x1=150,y1=150)
- 右下角 ( x 2 = 450 , y 2 = 450 ) (x_2 = 450, y_2 = 450) (x2=450,y2=450)
所以该框的尺寸为:
- 宽度: w = 450 − 150 = 300 w = 450 - 150 = 300 w=450−150=300
- 高度: h = 450 − 150 = 300 h = 450 - 150 = 300 h=450−150=300
特征图与下采样
这张图片将被送入一个 CNN 主干网络(如 ResNet50),其总的下采样率为 32 32 32,即:
feature map size = 600 32 = 18.75 ≈ 19 × 19 \text{feature map size} = \frac{600}{32} = 18.75 \approx 19 \times 19 feature map size=32600=18.75≈19×19
于是,图像坐标需要映射到特征图坐标系:
x 1 ′ = 150 32 = 4.6875 x 2 ′ = 450 32 = 14.0625 y 1 ′ = 150 32 = 4.6875 y 2 ′ = 450 32 = 14.0625 x_1' = \frac{150}{32} = 4.6875 \\ x_2' = \frac{450}{32} = 14.0625 \\ y_1' = \frac{150}{32} = 4.6875 \\ y_2' = \frac{450}{32} = 14.0625 x1′=32150=4.6875x2′=32450=14.0625y1′=32150=4.6875y2′=32450=14.0625
即该 RoI 在特征图上的浮点坐标范围为 ( 4.6875 , 4.6875 ) (4.6875, 4.6875) (4.6875,4.6875) 到 ( 14.0625 , 14.0625 ) (14.0625, 14.0625) (14.0625,14.0625)。
RoI Pooling 的处理方式
RoI Pooling 会执行如下操作:
-
将浮点坐标进行量化(向下取整):
x 1 ′ ′ = ⌊ 4.6875 ⌋ = 4 , x 2 ′ ′ = ⌊ 14.0625 ⌋ = 14 x_1'' = \lfloor 4.6875 \rfloor = 4, \quad x_2'' = \lfloor 14.0625 \rfloor = 14 x1′′=⌊4.6875⌋=4,x2′′=⌊14.0625⌋=14
-
得到离散的 RoI 区域大小为 10 × 10 10 \times 10 10×10;
-
将其划分成 5 × 5 5 \times 5 5×5 的网格(bin),每个 bin 是 2 × 2 2 \times 2 2×2;
-
每个 bin 中做最大池化(max pooling)。
案例中:
R o I 宽度(特征图上) = 14.0625 − 4.6875 = 9.375 RoI 宽度(特征图上)=14.0625−4.6875=9.375 RoI宽度(特征图上)=14.0625−4.6875=9.375
将宽度 9.375 9.375 9.375 均匀划分为 5 5 5 个 bin:bin width = 9.375 5 = 1.875 \text{bin width} = \frac{9.375}{5} = 1.875 bin width=59.375=1.875
这意味着:
- bin 1 区域: [ 4.6875 , 6.5625 ) [4.6875, 6.5625) [4.6875,6.5625)
- bin 2 区域: [ 6.5625 , 8.4375 ) [6.5625, 8.4375) [6.5625,8.4375)
- bin 3 区域: [ 8.4375 , 10.3125 ) [8.4375, 10.3125) [8.4375,10.3125)
- bin 4 区域: [ 10.3125 , 12.1875 ) [10.3125, 12.1875) [10.3125,12.1875)
- bin 5 区域: [ 12.1875 , 14.0625 ) [12.1875, 14.0625) [12.1875,14.0625)
RoI Pooling 不能处理小数 → 将起始点 & bin 宽度都 取整
- 起始坐标: ⌊ 4.6875 ⌋ = 4 \lfloor 4.6875 \rfloor = 4 ⌊4.6875⌋=4
- bin 宽度: ⌊ 1.875 ⌋ = 1 \lfloor 1.875 \rfloor = 1 ⌊1.875⌋=1
于是:
- bin 1 实际区域:[4, 5)
- bin 2 实际区域:[5, 6)
- bin 3 实际区域:[6, 7)
- …
- 最终只采样了 5 个整数区域,每个宽度为 1,总共宽度仅为 5
实际的 RoI 宽度应该是 9.375,但 RoI Pooling 只用了 5 → 少用了约 47% 区域!
**问题:**由于量化误差,采样位置与原始区域发生偏移,导致特征丢失,特别是对于边缘信息的处理不精确。
RoIAlign 的改进
RoIAlign 不进行量化,而是保留浮点精度:
- RoI 保持 ( 4.6875 , 4.6875 ) (4.6875, 4.6875) (4.6875,4.6875) 到 ( 14.0625 , 14.0625 ) (14.0625, 14.0625) (14.0625,14.0625);
- 仍划分为 5 × 5 5 \times 5 5×5 个 bin;
- 每个 bin 使用 4 4 4 个采样点(中心、边角);
- 在浮点位置使用双线性插值从特征图中提取特征值。
好处:
- 精确还原原始 RoI 区域;
- 没有像素级偏移;
- 更适用于像素级任务,如实例分割中的 mask 预测。
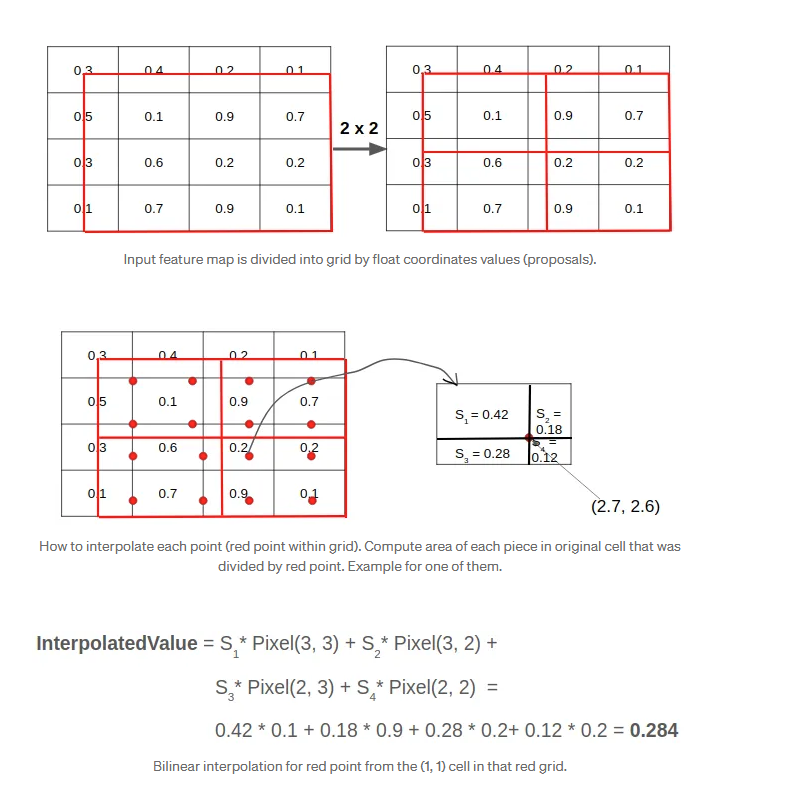
https://firiuza.medium.com/roi-pooling-vs-roi-align-65293ab741db
特征图像素值如下:
[ 0.3 0.4 0.2 0.1 0.5 0.1 0.9 0.7 0.3 0.6 0.2 0.2 0.1 0.7 0.9 0.1 ] \begin{bmatrix} 0.3 & 0.4 & 0.2 & 0.1 \\ 0.5 & 0.1 & 0.9 & 0.7 \\ 0.3 & 0.6 & 0.2 & 0.2 \\ 0.1 & 0.7 & 0.9 & 0.1 \\ \end{bmatrix} 0.30.50.30.10.40.10.60.70.20.90.20.90.10.70.20.1 其中红框表示一个 RoI 区域,划分为 2 × 2 2 \times 2 2×2 网格。图下半部分展示了红色点表示的采样位置。
红框表示 RoI(Region of Interest),其 左上角未对齐 ( x 1 = 0.3 , y 1 = 0.3 ) (x_1 = 0.3, y_1 = 0.3) (x1=0.3,y1=0.3),右下角对齐到 ( x 2 = 4.0 , y 2 = 4.0 ) (x_2 = 4.0, y_2 = 4.0) (x2=4.0,y2=4.0)。因此:
- RoI 宽高: w = h = 4.0 − 0.3 = 3.7 w = h = 4.0 - 0.3 = 3.7 w=h=4.0−0.3=3.7
- 划分为 2 × 2 2 \times 2 2×2 网格,每个 bin 的尺寸为:
bin width = bin height = 3.7 2 = 1.85 \text{bin width} = \text{bin height} = \frac{3.7}{2} = 1.85 bin width=bin height=23.7=1.85
每个 bin 中采样点数量
每个 bin 中采样 2 × 2 = 4 2 \times 2 = 4 2×2=4 个红点,总共有 4 × 4 = 16 4 \times 4 = 16 4×4=16 个采样点。下图展示了采样点的位置。所有红点的坐标均为浮点数,因此都需使用 双线性插值。
我们将以图中给出的右下角 bin 中的 第 4 个红点 ( 2.7 , 2.6 ) (2.7, 2.6) (2.7,2.6) 为例计算插值值。
插值点坐标及其邻近像素值
采样点坐标为 ( x = 2.7 , y = 2.6 ) (x = 2.7, y = 2.6) (x=2.7,y=2.6),其周围 4 个像素格点为:
- ( 2 , 2 ) = 0.2 (2, 2) = 0.2 (2,2)=0.2
- ( 2 , 3 ) = 0.2 (2, 3) = 0.2 (2,3)=0.2
- ( 3 , 2 ) = 0.9 (3, 2) = 0.9 (3,2)=0.9
- ( 3 , 3 ) = 0.1 (3, 3) = 0.1 (3,3)=0.1
计算相对偏移:
d x = x − 2 = 0.7 , d y = y − 2 = 0.6 dx = x - 2 = 0.7, \quad dy = y - 2 = 0.6 dx=x−2=0.7,dy=y−2=0.6
插值权重:
- S 1 = ( 1 − d x ) ( 1 − d y ) = 0.3 ⋅ 0.4 = 0.12 S_1 = (1 - dx)(1 - dy) = 0.3 \cdot 0.4 = 0.12 S1=(1−dx)(1−dy)=0.3⋅0.4=0.12
- S 2 = d x ( 1 − d y ) = 0.7 ⋅ 0.4 = 0.28 S_2 = dx(1 - dy) = 0.7 \cdot 0.4 = 0.28 S2=dx(1−dy)=0.7⋅0.4=0.28
- S 3 = ( 1 − d x ) d y = 0.3 ⋅ 0.6 = 0.18 S_3 = (1 - dx)dy = 0.3 \cdot 0.6 = 0.18 S3=(1−dx)dy=0.3⋅0.6=0.18
- S 4 = d x ⋅ d y = 0.7 ⋅ 0.6 = 0.42 S_4 = dx \cdot dy = 0.7 \cdot 0.6 = 0.42 S4=dx⋅dy=0.7⋅0.6=0.42
带入插值公式:
InterpolatedValue = S 1 ⋅ P 3 , 3 + S 2 ⋅ P 3 , 2 + S 3 ⋅ P 2 , 3 + S 4 ⋅ P 2 , 2 \text{InterpolatedValue} = S_1 \cdot P_{3,3} + S_2 \cdot P_{3,2} + S_3 \cdot P_{2,3} + S_4 \cdot P_{2,2} InterpolatedValue=S1⋅P3,3+S2⋅P3,2+S3⋅P2,3+S4⋅P2,2
= 0.42 ⋅ 0.1 + 0.18 ⋅ 0.9 + 0.28 ⋅ 0.2 + 0.12 ⋅ 0.2 = 0.284 = 0.42 \cdot 0.1 + 0.18 \cdot 0.9 + 0.28 \cdot 0.2 + 0.12 \cdot 0.2 = 0.284 =0.42⋅0.1+0.18⋅0.9+0.28⋅0.2+0.12⋅0.2=0.284
这个值为 (1,1) bin 中的一个红点采样值。
每个 bin 的最大值输出(max pooling)
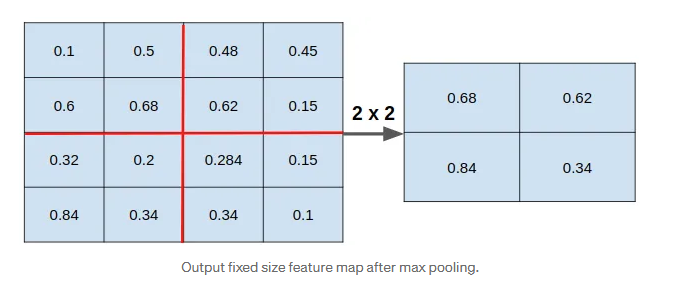
图中下方矩阵显示所有红点采样值:
[ 0.1 0.5 0.48 0.45 0.6 0.68 0.62 0.15 0.32 0.2 0.284 0.15 0.84 0.34 0.34 0.1 ] \begin{bmatrix} 0.1 & 0.5 & 0.48 & 0.45 \\ 0.6 & 0.68 & 0.62 & 0.15 \\ 0.32 & 0.2 & \mathbf{0.284} & 0.15 \\ 0.84 & 0.34 & 0.34 & 0.1 \\ \end{bmatrix} 0.10.60.320.840.50.680.20.340.480.620.2840.340.450.150.150.1
我们将其划分为 2 × 2 2 \times 2 2×2 区域,每个 bin 中取最大值:
- bin(0,0): max ( 0.1 , 0.5 , 0.6 , 0.68 ) = 0.68 \max(0.1, 0.5, 0.6, 0.68) = 0.68 max(0.1,0.5,0.6,0.68)=0.68
- bin(0,1): max ( 0.48 , 0.45 , 0.62 , 0.15 ) = 0.62 \max(0.48, 0.45, 0.62, 0.15) = 0.62 max(0.48,0.45,0.62,0.15)=0.62
- bin(1,0): max ( 0.32 , 0.2 , 0.84 , 0.34 ) = 0.84 \max(0.32, 0.2, 0.84, 0.34) = 0.84 max(0.32,0.2,0.84,0.34)=0.84
- bin(1,1): max ( 0.284 , 0.15 , 0.34 , 0.1 ) = 0.34 \max(0.284, 0.15, 0.34, 0.1) = 0.34 max(0.284,0.15,0.34,0.1)=0.34
最终输出特征图( 2 × 2 2 \times 2 2×2)
[ 0.68 0.62 0.84 0.34 ] \begin{bmatrix} 0.68 & 0.62 \\ 0.84 & 0.34 \\ \end{bmatrix} [0.680.840.620.34]
对比总结
| 步骤 | RoI Pooling | RoIAlign |
|---|---|---|
| 坐标处理 | 舍入浮点为整数 | 保留浮点精度 |
| 特征提取位置 | 固定在整数网格点 | 可在任意浮点位置采样 |
| 池化方法 | max pooling | 双线性插值 + 平均(或 max) |
| 是否存在偏差 | 是,边界错位 | 否,精确对齐 |
| 适合的任务 | 目标检测 | 实例分割、边界敏感任务 |
四、掩码分支设计
掩码分支是 Mask R-CNN 的核心新增部分。它的结构如下:
- 输入:来自 RoIAlign 的固定尺寸特征(如 14 × 14 14 \times 14 14×14)。
- 经过多层卷积处理。
- 输出:每个类别一个掩码,通常大小为 28 × 28 28 \times 28 28×28。
对于一个类别数为 K K K 的任务,掩码分支将输出 K K K 个掩码,最终只保留与分类结果对应的那个掩码作为该目标的分割结果。
五、损失函数设计
Mask R-CNN 是一个多任务学习框架,总损失函数由以下三部分组成:
-
分类损失 L c l s L_{cls} Lcls(交叉熵):
L c l s = − log ( p u ) L_{cls} = -\log(p_u) Lcls=−log(pu)
其中 p u p_u pu 是预测为正确类别 u u u 的概率。 -
边界框回归损失 L b o x L_{box} Lbox(Smooth L1):
L b o x = ∑ i Smooth L 1 ( t i − t i ∗ ) L_{box} = \sum_i \text{Smooth}_{L1}(t_i - t_i^*) Lbox=i∑SmoothL1(ti−ti∗)
其中 t i t_i ti 是预测的偏移, t i ∗ t_i^* ti∗ 是真实偏移。 -
掩码损失 L m a s k L_{mask} Lmask(像素级二分类):
L m a s k = 1 m 2 ∑ i , j [ y i j log ( y ^ i j ) + ( 1 − y i j ) log ( 1 − y ^ i j ) ] L_{mask} = \frac{1}{m^2} \sum_{i,j} [y_{ij} \log(\hat{y}_{ij}) + (1 - y_{ij}) \log(1 - \hat{y}_{ij})] Lmask=m21i,j∑[yijlog(y^ij)+(1−yij)log(1−y^ij)]
其中 m × m m \times m m×m 是掩码尺寸, y i j y_{ij} yij 是像素标签, y ^ i j \hat{y}_{ij} y^ij 是预测概率。
总损失为三者之和:
L = L c l s + L b o x + L m a s k L = L_{cls} + L_{box} + L_{mask} L=Lcls+Lbox+Lmask
六、与 Faster R-CNN 的对比
| 特征 | Faster R-CNN | Mask R-CNN |
|---|---|---|
| 分类 | 有 | 有 |
| 边框回归 | 有 | 有 |
| 像素级掩码输出 | 无 | 有 |
| 区域特征提取方式 | RoI Pooling | RoIAlign(避免量化误差) |
| 多任务学习结构 | 分类 + 回归 | 分类 + 回归 + 掩码 |
七、应用场景
Mask R-CNN 广泛应用于以下任务中:
- 医疗图像分析(如器官分割、病灶检测)
- 自动驾驶中的实例分割(行人、车辆等)
- 视频中的目标追踪与分割
- 智能图像编辑(抠图、背景替换)
- 安防与监控系统中的目标检测与识别
八、小结
Mask R-CNN 是一个基于两阶段检测器的强大实例分割方法。它在 Faster R-CNN 的基础上通过加入精确的 RoIAlign 和掩码分支,实现了高精度的像素级目标理解。其架构清晰,精度高,适用范围广,已成为实例分割任务中的事实标准。
未来可以在以下方向继续优化:
- 更轻量化的结构以提升速度(如使用 MobileNet)
- 更强的掩码分支设计以提高边缘质量
- 与 Transformer 或注意力机制的结合
通过对 Mask R-CNN 的深入理解,可以为处理更复杂的视觉任务打下坚实基础。