【项目】在线OJ(负载均衡式)
目录
一、项目目标
二、开发环境
1.技术栈
2.开发环境
三、项目树
目录结构
功能逻辑
编写思路
四、编码
1.complie_server
服务功能
代码蓝图
开发编译功能
日志功能
编辑
测试编译模块
开发运行功能
设置运行限制
jsoncpp
编写CR
如何生成唯一文件名
读写文件
测试全部编译服务
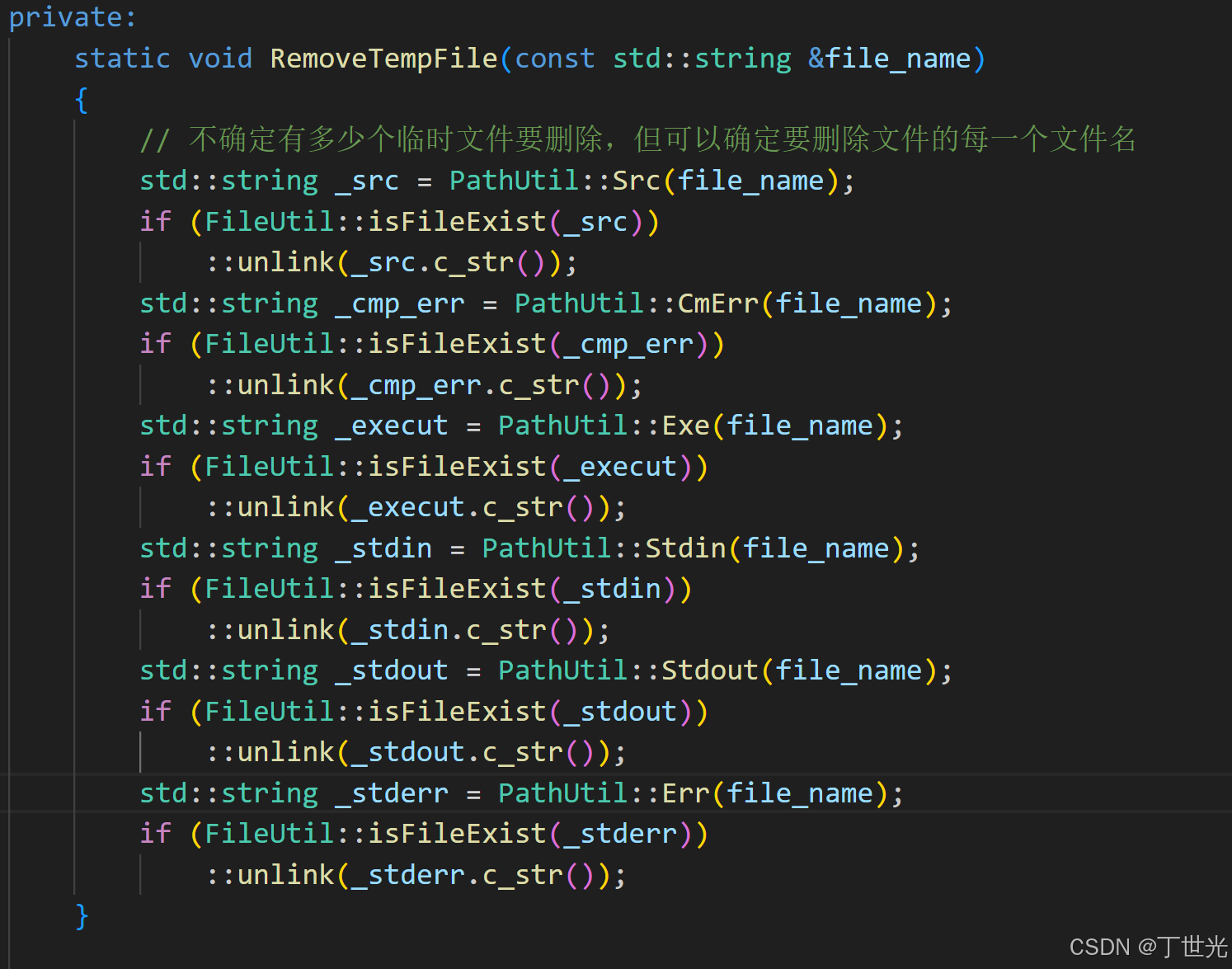
自动删除所有临时文件
将本地的编译服务打包成网络服务
改一下端口号
2.基于MVC结构的oj_server
服务框架
实现服务路由
文件版题库设计
ojmodel.hpp
安装ctemplate库
ojcontrol.hpp
负载均衡设计
补全Control::Judge
Postman接口测试
一、项目目标
- 实现LeetCode的一个子功能——在线OJ,即做题判题功能。
项目内容主要是加载题目列表、编译服务要负载均衡,当然,这两句话很笼统,具体每一步实现,都已按步给出。
本文介绍了一个基于C++的在线判题系统(Online Judge)开发项目。系统分为编译服务(compile_server)和OJ服务(oj_server)两部分,采用MVC架构设计。编译服务负责代码编译运行,采用负载均衡策略;OJ服务提供题目展示和判题功能。技术栈包括C++ STL、Boost、cpp-httplib、ctemplate、jsoncpp等库。系统实现了题目管理、代码提交、编译运行、结果返回等核心功能,支持多主机负载均衡和异常处理。开发环境为Ubuntu 22.04,使用VSCode进行开发,通过详细的设计文档和测试案例验证了系统可靠性。
二、开发环境
1.技术栈
重要程度按星⭐给出
- C++ STL标准库 ⭐⭐⭐⭐⭐
- Boost标准库(用于字符串切割)⭐⭐⭐⭐
- cpp-httplib(第三方开源网络库,用于C++项目中网络的封装)⭐⭐⭐⭐
- ctemplate(第三方开源前端网页渲染库)⭐⭐⭐
- jsoncpp(第三方开源序列化、反序列化库)⭐⭐⭐⭐⭐
- 负载均衡设计 ⭐⭐⭐⭐⭐
- 多进程、多线程 ⭐⭐⭐⭐⭐
- MySQL - C connect ⭐⭐⭐⭐
- Ace前端在线编辑器 ⭐
- html/css/js/jquery/ajax ⭐
2.开发环境
- 内核版本
ljy@Aliutocoo:~$ uname -a
Linux Aliutocoo 5.15.0-130-generic #140-Ubuntu SMP Wed Dec 18 17:59:53 UTC 2024 x86_64 x86_64 x86_64 GNU/Linux
- 发行版本
ljy@Aliutocoo:~$ lsb_release -a
LSB Version: core-11.1.0ubuntu4-noarch:security-11.1.0ubuntu4-noarch
Distributor ID: Ubuntu
Description: Ubuntu 22.04.5 LTS
Release: 22.04
Codename: jammy
- 代码编辑器
VSCode
三、项目树
目录结构
- 创建一个项目目录
mkdir OnlineJudge
- 创建comm文件夹,用于保存项目中的公共方法,比如

- 创建oj_server文件夹,用于保存实现OJ的代码
- 创建complie_server文件夹,用户保存编译的代码
功能逻辑
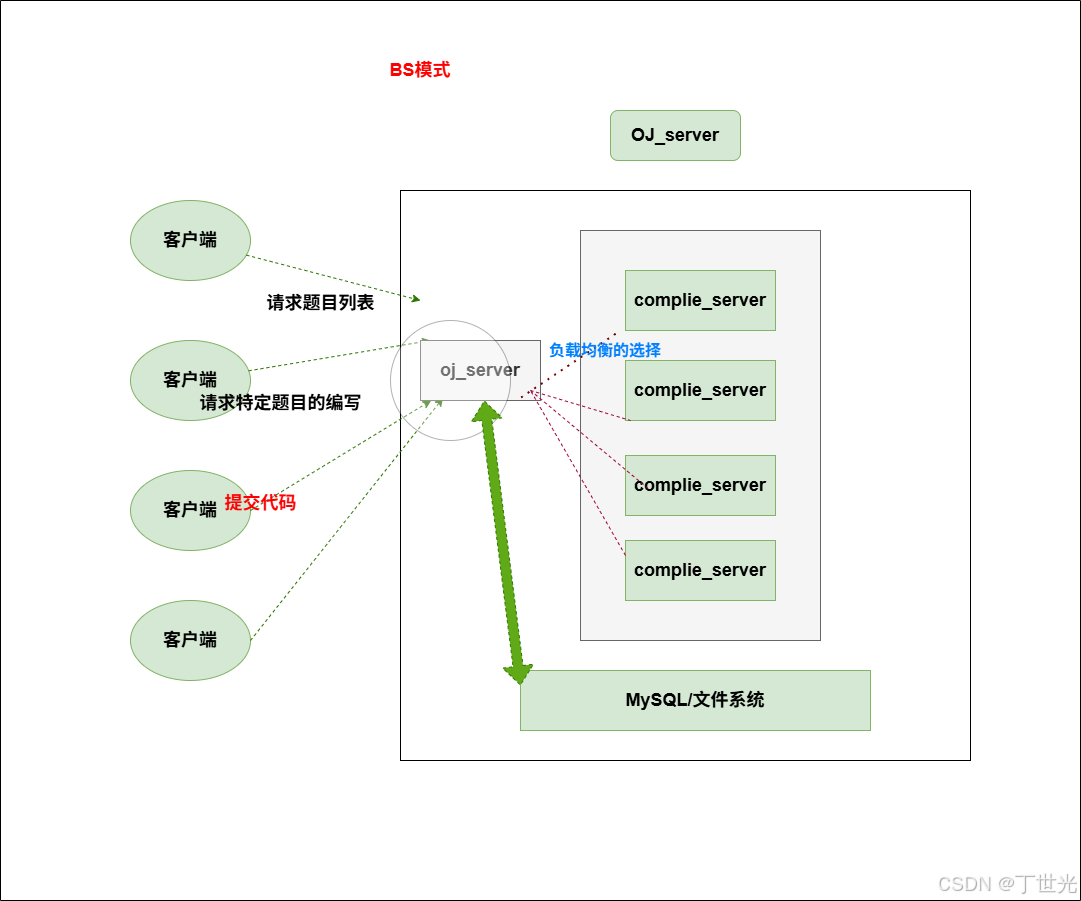
- 客户端可以请求题目列表
- 客户端可以请求编写特定题目的代码
- 客户端可以提交代码
- 服务器将代码负载均衡的发送给编译器
- 服务器从数据库或者文件中返回题目列表
编写思路
1.先编写complie_server
2.编写oj_server,只模拟LeetCode的刷题界面
3.在线OJ_version1,基于文件
4.引入前端网页渲染
5.在线OJ_version2,基于MySQL
四、编码
1.complie_server
服务功能
编译并运行代码,得到格式化的结果。
代码蓝图
- complie.hpp:编译逻辑
- run.hpp:运行逻辑
- complie_run.hpp:将编译和运行整合到一起的逻辑
- server_complie.cc:提供网络服务,将编译功能网络化
- Makefile
开发编译功能
- 暂时完成Makefile
server_complie:server_complie.ccg++ -o $@ $^ -std=c++11.PHONY:clean
clean:rm -f server_complie
- complie.hpp
编译服务要编译的代码由远端提交,但是编译这个过程的前提下,要形成临时文件可供编译。
编译服务对临时文件做操作,只关注编译结果,1.编译通过,2.编译报错,将保存信息保存到临时文件中。
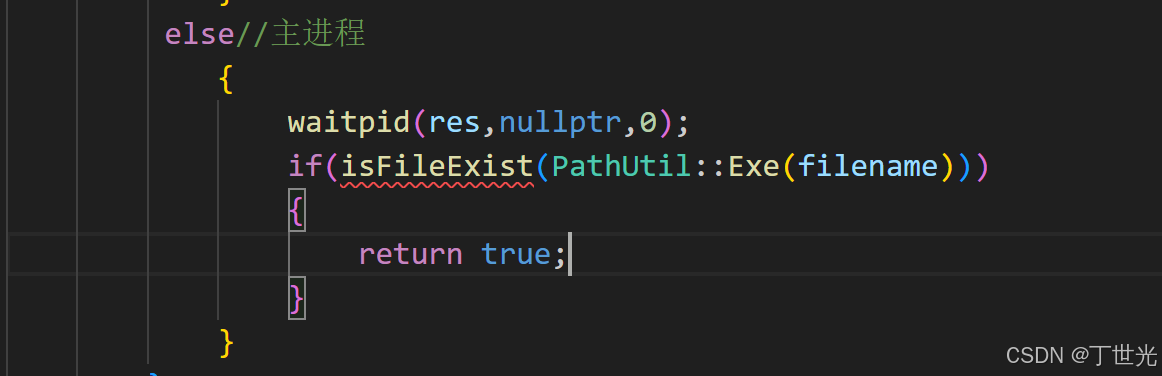
当前进程并不真正执行编译操作,如果用当前进程做编译操作等于当前进程要替换成g++服务,因此当前进程要fork一个子进程。
编译操作:
#pragma once
//本文件只实现编译功能
#include <iostream>
#include <unistd.h>namespace ns_complier
{class Complier{public:Complier(){}~Complier(){}//只关注编译结果:编译通过返回true,编译失败返回false//要编译的文件被保存在临时文件目录下//静态成员函数:没有this指针static bool Complie(const std::string& filename){//创建子进程pid_t res = fork();//assert(res >= 0);if(res < 0){return false;}//副进程if(res == 0){//g++ -o target src -std=c++11execlp("g++","g++","-o");}else//主进程{}}};
}
源文件最终统一放到./temp目录下
在这个地方需要构建三个信息
1.待编译的源文件:aaa.cpp
2.目标可执行程序:aaa.exe
3.当前文件的标准错误信息:aaa.stderr
这三个信息,不仅适用于一道题目,而是适用于所有题目,所以在comm目录下实现一个工具Util


#pragma once
#include <iostream>
#include <string>namespace ns_util
{class PathUtil{//根据文件名获取完整的文件格式:"aaa" -> "./temp/aaa.cpp"static std::string Src(std::string filename){}//根据文件名获取最终目标的文件名:"aaa"->"./temp/aaa.exe"static std::string Exe(std::string filename){}//根据文件名获取错误信息的文件名:"aaa"->"./temp/aaa.stderr"static std::string Err(std::string filename){}};
}
接下来为comlie.hpp引入这个功能。
#pragma once
//本文件只实现编译功能
#include <iostream>
#include <unistd.h>#include "../comm/Util.hpp"
namespace ns_complier
{//引入using namespace ns_util;class Complier{public:Complier(){}~Complier(){}//只关注编译结果:编译通过返回true,编译失败返回false//要编译的文件被保存在临时文件目录下//静态成员函数:没有this指针static bool Complie(const std::string& filename){//创建子进程pid_t res = fork();//assert(res >= 0);if(res < 0){return false;}//副进程if(res == 0){//g++ -o target src -std=c++11execlp("g++","g++","-o",PathUtil::Exe(filename).c_str(),PathUtil::Src(filename).c_str(),"-std=c++11",nullptr);}else//主进程{}}};
}
实现三个构建文件名的函数。

#pragma once
#include <iostream>
#include <string>namespace ns_util
{const static std::string dir = "./temp/";class PathUtil{static std::string AddSuffix(std::string& filename,std::string suffix){std::string pathname = "";pathname+=dir;pathname+=filename;pathname+=suffix;}public://根据文件名获取完整的文件格式:"aaa" -> "./temp/aaa.cpp"static std::string Src(std::string filename){return AddSuffix(filename,".cpp");}//根据文件名获取最终目标的文件名:"aaa"->"./temp/aaa.exe"static std::string Exe(std::string filename){return AddSuffix(filename,".exe");}//根据文件名获取错误信息的文件名:"aaa"->"./temp/aaa.stderr"static std::string Err(std::string filename){return AddSuffix(filename,".stderr");}};
}
设计程序时,让子进程做程序替换,执行"g++",而父进程则一定要去等子进程。
此外,如果编译失败,父进程要记录错误信息。
可以通过是否生成可执行程序来判断编译是否成功。

同样的把这个功能实现在Util中

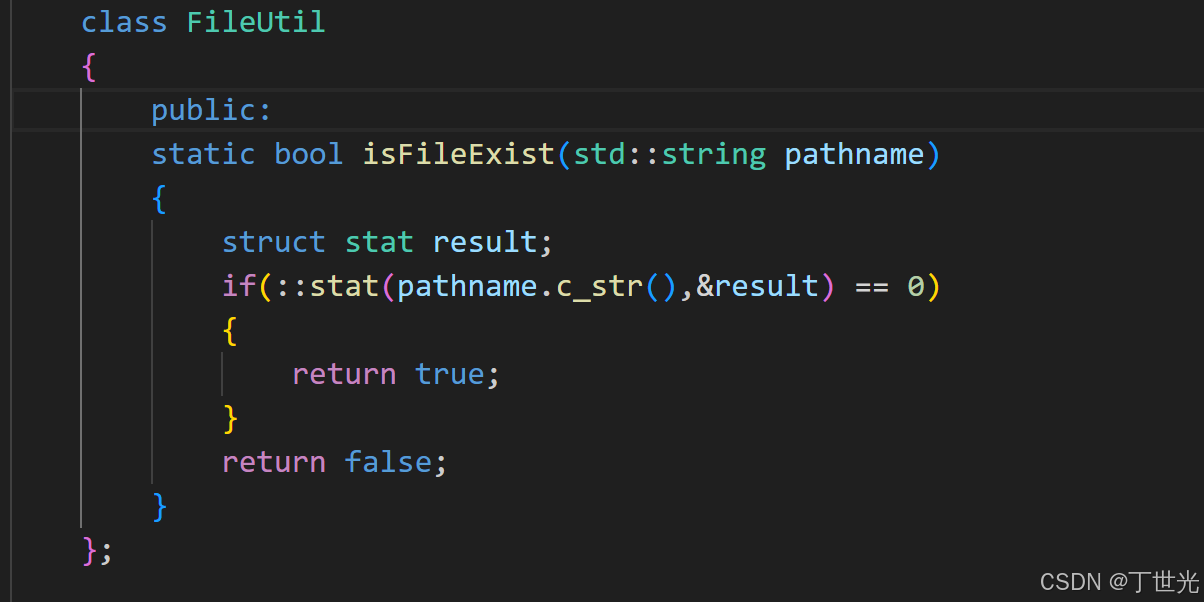
这里使用到了一个系统调用接口,可以判断一个文件是否存在
man 2 stat
下一个加的功能是,要求g++编译错误时的信息,写入到临时文件目录下。
这是过程必然要将标准错误流重定向到自己的文件中,还记得Linux下的文件操作吗

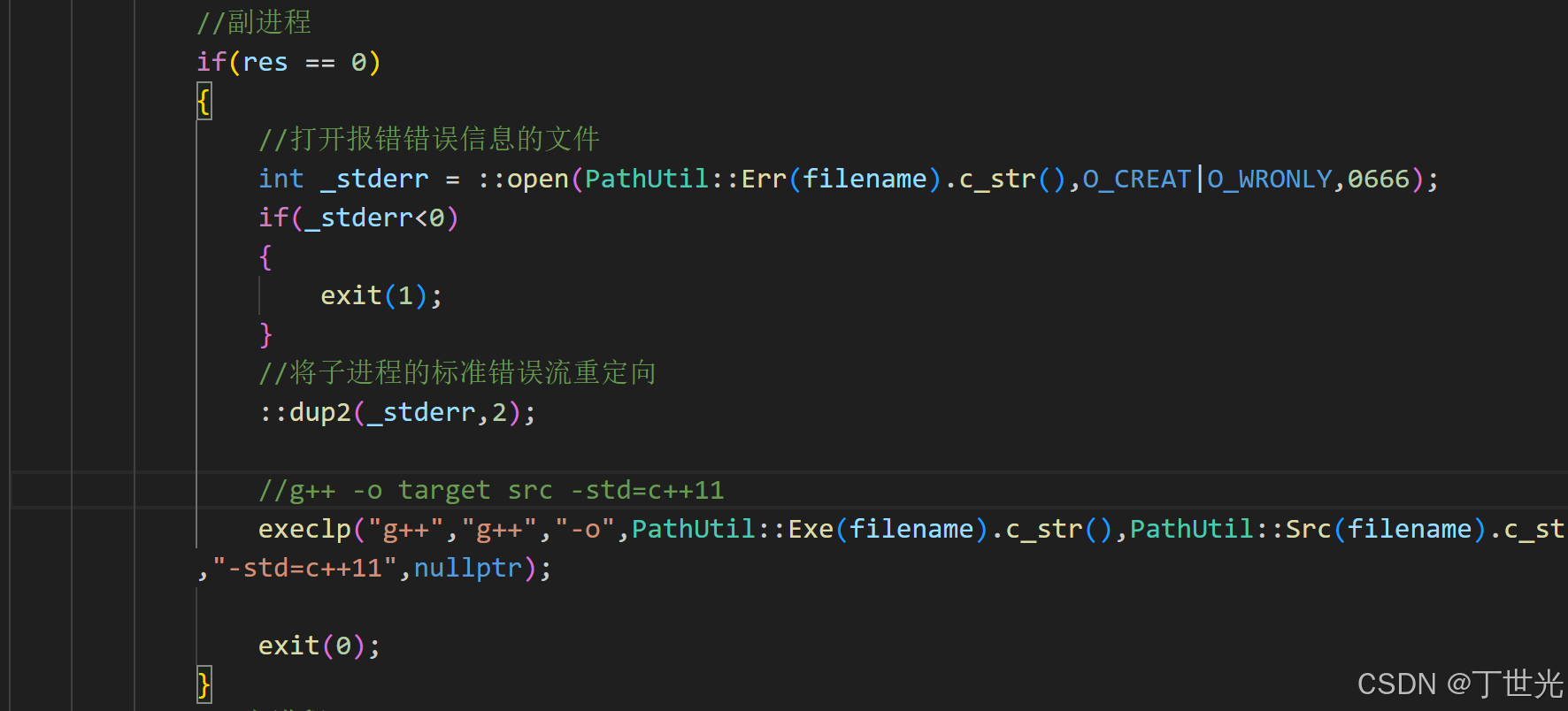
日志功能

#pragma once
#include <iostream>
#include <string>
#include "Util.hpp"namespace ns_log
{ using namespace ns_util;enum{INFO,DEBUG,WARNING,ERROR,FATAL};//LOG() << "message:";inline std::ostream& Log(std::string level,std::string file,int line){//日志信息输出到cout 的缓冲区std::string message;//添加日志等级message +="[";message += level;message +="]";//添加日期message += "[";message += TimeUtil::GetTimeStamp();message += "]";//添加文件名message += "[";message += file;message += "]";//添加行号message += ":";message += std::to_string(line);//注意,这一行是把msg刷新到了cout 的缓冲区,但是没有endl,打印不会立刻执行。std::cout << message;return std::cout;}//再封装一层宏调用#define LOG(level) Log(#level,__FILE__,__LINE__)}
获取时间这个功能可以写到工具类中
//获取时间class TimeUtil{public://获取时间戳,以字符串的形式获取static std::string GetTimeStamp(){struct timeval outtime;::gettimeofday(&outtime,nullptr);return std::to_string(outtime.tv_sec);}};
获取时间戳用到了一个系统调用
man 2 gettimeofday
将日志模块添加到编译服务中。
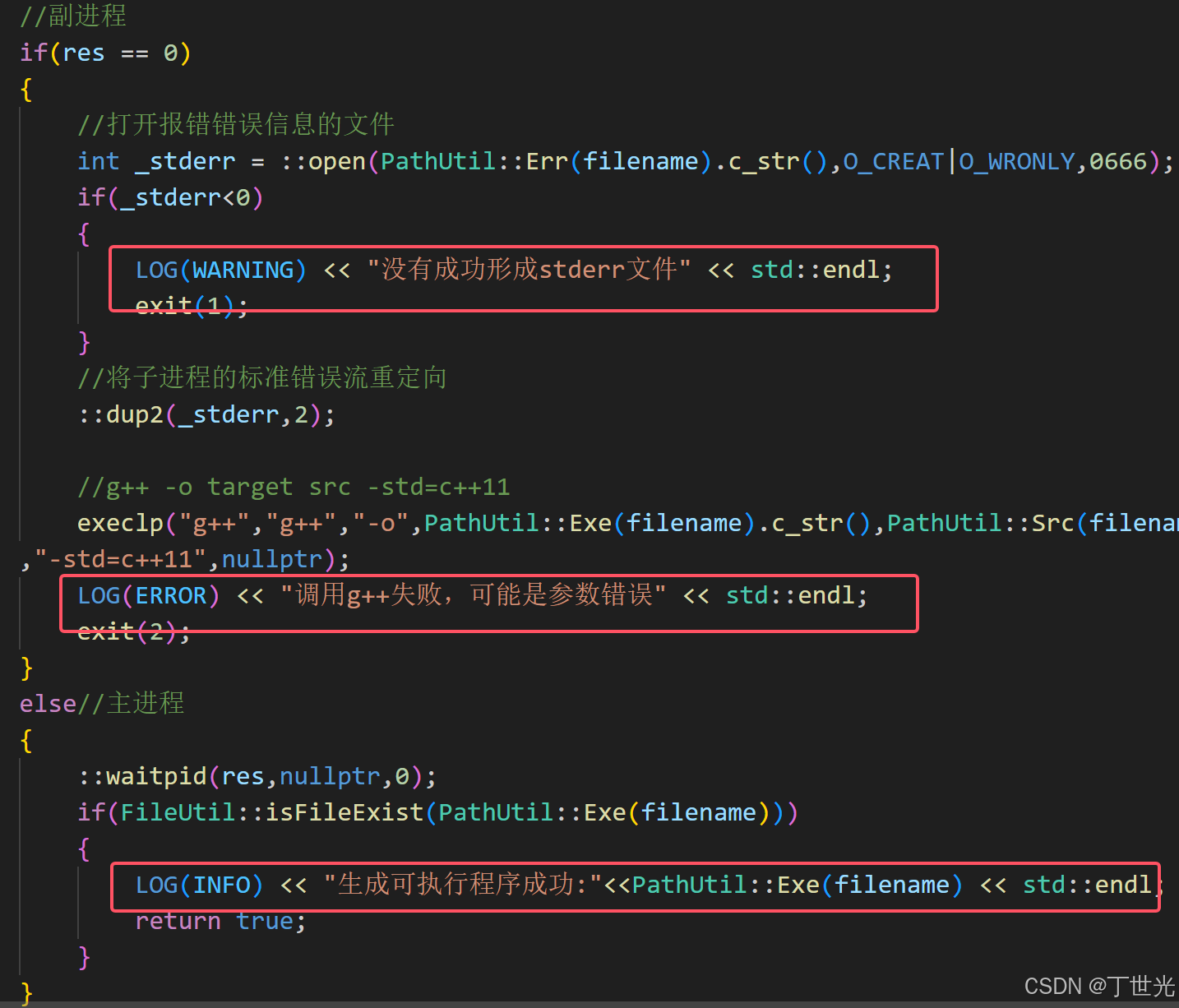
测试编译模块
写一段测试的代码。
![]()
#include "complie.hpp"using namespace ns_complier;int main()
{std::string test = "5.19";Complier::Complie(test);return 0;
}
由于没有在线OJ提交来的源文件,我们可以自己写一个测试的源文件。
#include <iostream>int main()
{std::cout << "this is test\n";
}

开发运行功能

#pragma once
//本文件实现运行功能 namespace ns_runner
{class Runner{public:Runner(){}~Runner(){}static bool Run(const std::string& filename){/*************************************** 程序运行* 1.代码跑完,结果正确* 2.代码跑完,结果不正确* 3.代码出异常* Run不考虑代码执行结果是否正确* 代码结果是否正确,由我们编写的测试用例来量度* 这个过程由oj版块决定* * 运行函数,必须知道要运行的程序在哪里* 对于这个程序:* 1.标准输入,默认是键盘,但是在Oj系统中,它被存储在一个文件中,我们设计时不考虑* 2.标准输出,默认输出到屏幕,需要重定向到一个文件* 3.标准错误,需要重定向,保存运行时的错误信息* **************************************/}};
}
对于错误信息,有编译时的报错,这种一般都是语法检查,还有运行时的报错,在当前这个项目中,为了区分编译错误和运行错误,我们将这两种错误写到两个文件中。

static std::string CmErr(std::string filename)
{return AddSuffix(filename,".complier_err");
}接下来,我们要打开三个文件,stdin,stdout,stderr,并把他们重定向。
先完善工具类

//文件路径工具class PathUtil{static std::string AddSuffix(std::string &filename, std::string suffix){std::string pathname = "";pathname += dir;pathname += filename;pathname += suffix;return pathname;}public:/***********编译时用到的临时文件*************/// 根据文件名获取完整的文件格式:"aaa" -> "./temp/aaa.cpp"static std::string Src(std::string filename){return AddSuffix(filename, ".cpp");}// 根据文件名获取最终目标的文件名:"aaa"->"./temp/aaa.exe"static std::string Exe(std::string filename){return AddSuffix(filename, ".exe");}static std::string CmErr(std::string filename){return AddSuffix(filename,".complier_err");}/**********运行时用到的临时文件 **************/ // 根据文件名获取错误信息的文件名:"aaa"->"./temp/aaa.stderr"static std::string Err(std::string filename){return AddSuffix(filename, ".stderr");}static std::string _Stdin(std::string filename){return AddSuffix(filename,".stdin");}static std::string _Stdout(std::string filename){return AddSuffix(filename,".stdout");}};}

#pragma once
//本文件实现运行功能
#include "../comm/Util.hpp"
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/wait.h>
namespace ns_runner
{using namespace ns_util;class Runner{public:Runner(){}~Runner(){}static bool Run(const std::string& filename){/*************************************** 程序运行* 1.代码跑完,结果正确* 2.代码跑完,结果不正确* 3.代码出异常* Run不考虑代码执行结果是否正确* 代码结果是否正确,由我们编写的测试用例来量度* 这个过程由oj版块决定* * 运行函数,必须知道要运行的程序在哪里* 对于这个程序:* 1.标准输入,默认是键盘,但是在Oj系统中,它被存储在一个文件中,我们设计时不考虑* 2.标准输出,默认输出到屏幕,需要重定向到一个文件* 3.标准错误,需要重定向,保存运行时的错误信息* **************************************///要执行的可执行程序:"1234"->"./temp/1234.exe"std::string execute = PathUtil::Exe(filename);std::string _stdin = PathUtil::Stdin(filename);std::string _stdout = PathUtil::Stdout(filename);std::string _stderr = PathUtil::Err(filename);//现在知道了这三个临时文件的名字,就要打开它们umask(0);int in_fd = ::open(_stdin.c_str(),O_CREAT|O_RDONLY,0664);int out_fd = ::open(_stdin.c_str(),O_CREAT|O_WRONLY,0664);int err_fd = ::open(_stdin.c_str(),O_CREAT|O_WRONLY,0664);if(in_fd < 0 || out_fd < 0 || err_fd < 0){return -1;}//现在打开了三个文件,子进程会继承父进程的文件描述符表//子进程需要重定向pid_t pid = fork();if(pid < 0){::close(in_fd);::close(out_fd);::close(err_fd);return -2;}else if (pid == 0){::dup2(in_fd,0);::dup2(out_fd,1);::dup2(err_fd,2);//子进程做程序替换,执行可执行程序::execlp(execute.c_str(),execute.c_str(),nullptr);//退出码为什么是1,因为如果执行到这行,一定是程序替换失败了exit(1);}else{::close(in_fd);::close(out_fd);::close(err_fd);//父进程等待子进程int status;::waitpid(pid,&status,0);//为什么是按位与,低16位中,高8位是退出码,低7位是异常编号,return status& 0x7F;//返回异常编号}}};
}对编译运行做一个测试。并且加上日志。

#include "complie.hpp"
#include "run.hpp"
using namespace ns_complier;
using namespace ns_runner;
int main()
{std::string test = "5.19";Complier::Complie(test);Runner::Run(test);return 0;
}
测试运行成功时,发现运行的打印结果输出到了out文件中
![]()
#include <iostream>int main()
{std::cout << "这是运行成功的测试" << std::endl;
}
![]()
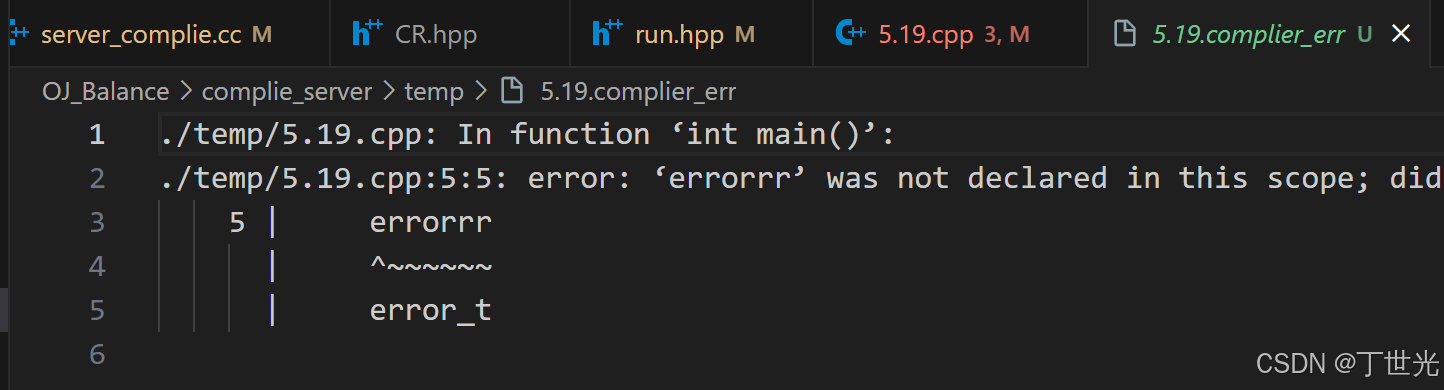
测试能否将编译错误的信息输出到文件中
设置运行限制
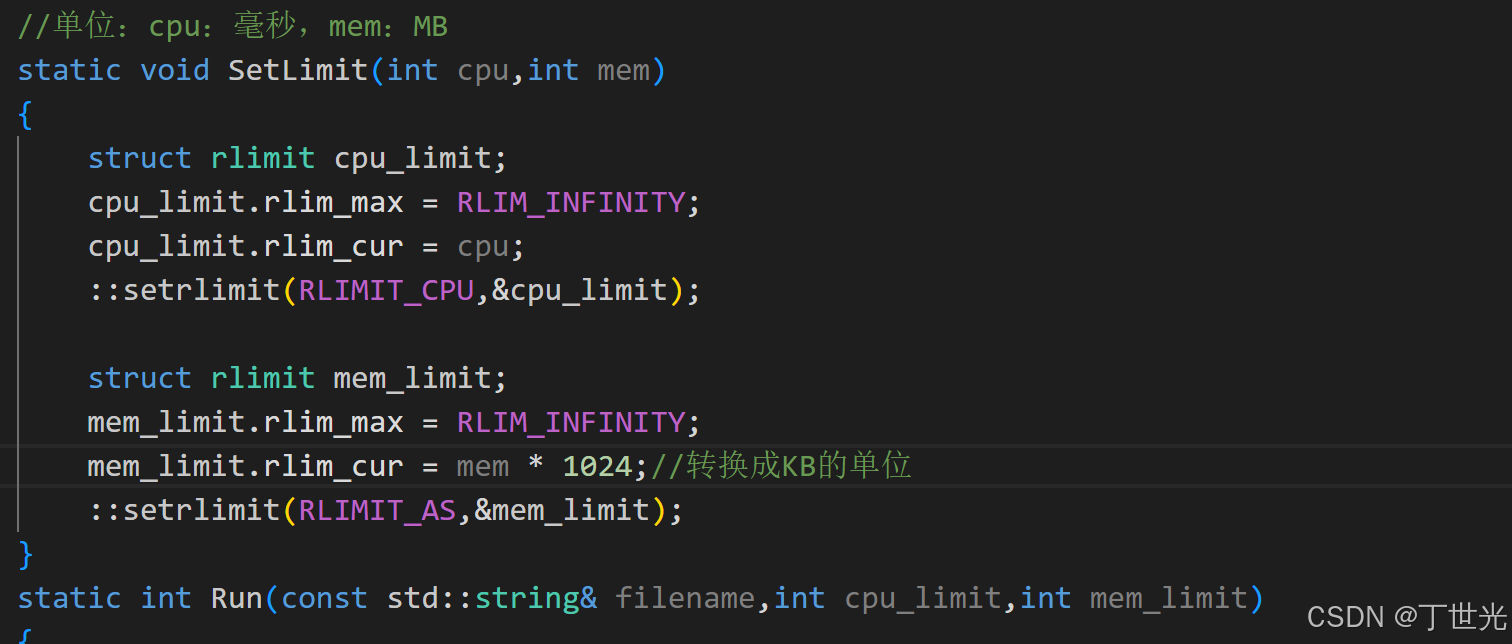
在网页写OJ题时,往往报错提示我们的代码超时了,或者说内存占用过高了,这一类提示是由于OJ题设计者对运行做了限制。
Linux操作系统下有以下接口可供调用
man 2 setrlimit值得说明的是,cpu占用超出限制是发送24号信号来终止,内存占用超出限制是发送6号信号来终止

jsoncpp
JsonCpp 是一个在 C++ 里处理 JSON 数据的开源库,它能够实现 JSON 数据的解析、序列化以及操作等功能。该库在 C++ 项目中被广泛运用,像网络应用、配置文件解析等场景都会用到它
Ubuntu安装jsoncpp
sudo apt install libjsoncpp-dev -y
验证安装
ls /usr/include/jsoncpp
编写CR
#pragma once
// 本文件将编译和运行整合到一起
#include "complie.hpp"
#include "run.hpp"namespace ns_CR
{using namespace ns_complier;using namespace ns_runner;class ComplieAndRun{//对于一个整合好的函数,它处理一个从下层传上来的网络字节流,输出的也应该是一个字符串static bool Start(){}};
}
这个过程涉及将字符串中的一个个值解析出来,即将字符串转换为结构化数据,这个过程称为反序列化,C++要想做这个工作,需要使用jsoncpp库

#pragma once
// 本文件将编译和运行整合到一起
#include "complie.hpp"
#include "run.hpp"#include <jsoncpp/json/json.h>namespace ns_CR
{using namespace ns_complier;using namespace ns_runner;/**************************************** 输入:* code: 用户提交的代码* input: 用户给自己提交的代码对应的输入,不做处理* cpu_limit: 时间要求* mem_limit: 空间要求** 输出:* 必填* status: 状态码* reason: 请求结果* 选填:* stdout: 我的程序运行完的结果* stderr: 我的程序运行完的错误结果** 参数:* in_json: {"code": "#include...", "input": "","cpu_limit":1, "mem_limit":10240}* out_json: {"status":"0", "reason":"","stdout":"","stderr":"",}* ************************************/class ComplieAndRun{// 对于一个整合好的函数,它处理一个从下层传上来的网络字节流,输出的也应该是一个字符串static void Start(const std::string& in_json, std::string out_json){// 把网络字节流反序列化Json::Value in_string;// 要用到Json中的反序列中间类Json::Reader reader;reader.parse(in_json, in_string);//{"code":"#include .....",}std::string code = in_string["code"].asString();std::string input = in_string["input"].asString();int cpu_limit = in_string["cpu_limit"].asInt();int mem_limit = in_string["mem_limit"].asInt();//做一个小判断if(code.size() == 0)return;//对于解析出来代码的处理,形成一个SRC文件,但是有可能多个用户在做同一道题,所以要保证形成的SRC//文件是唯一的std::string filename = FileUtil::UniqueFileName();//这里拿到了文件名,就可以生成SRC文件了,方法在comm中有//有了文件名,有了代码,就要报代码写入文件FileUtil::WriteFile(PathUtil::Src(filename),code);}};
}
加入错误信息处理
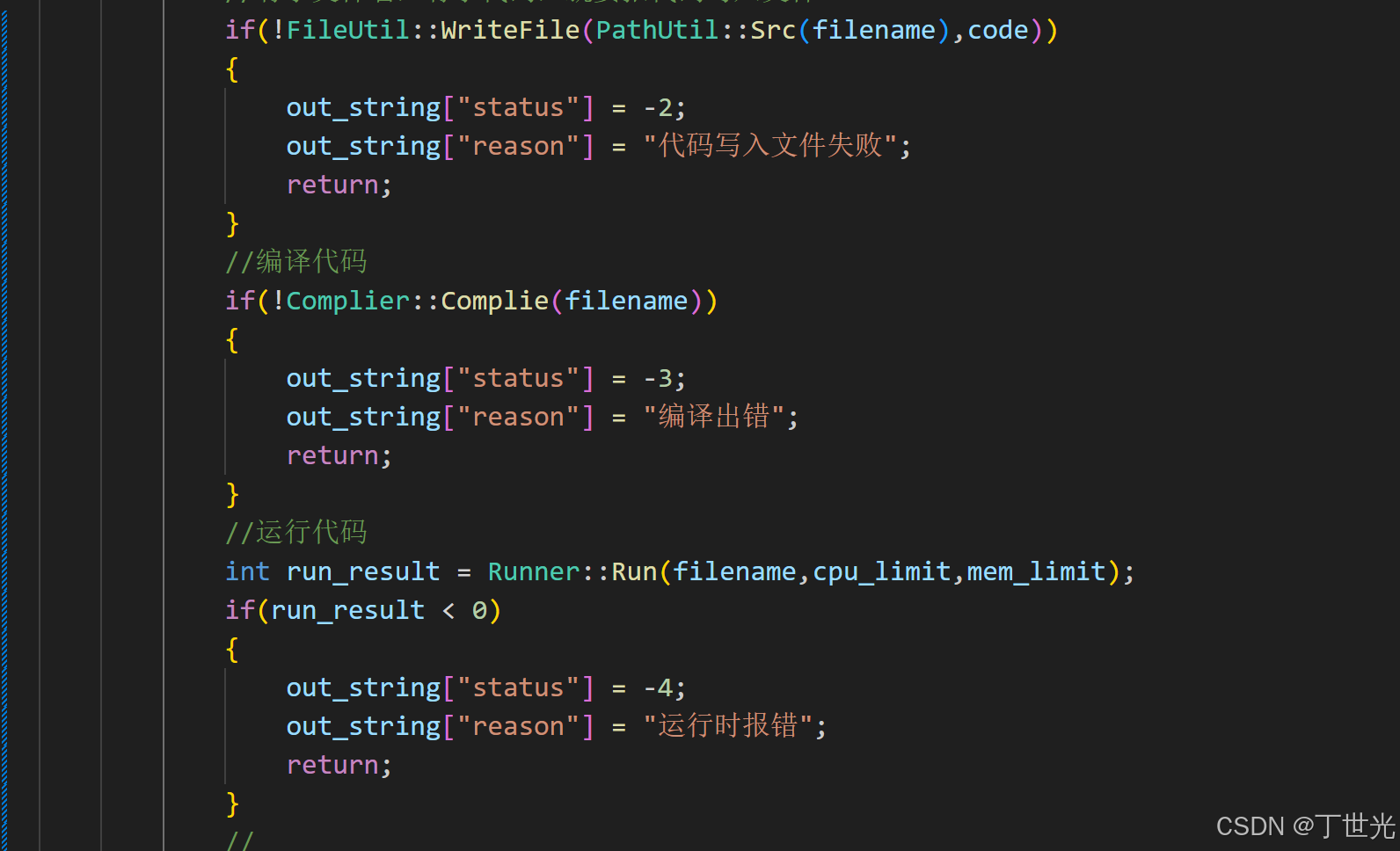
这样写有代码冗余,可以借助go to语句来改善,尽管go to语句几乎不怎么用。
打算在代码尾部写上一段标签,用于go to 语句的跳转,go to 语句和标签之间不要定义变量,因此,在go to语句之前定义接下来用到的全部变量。

END标签怎么写
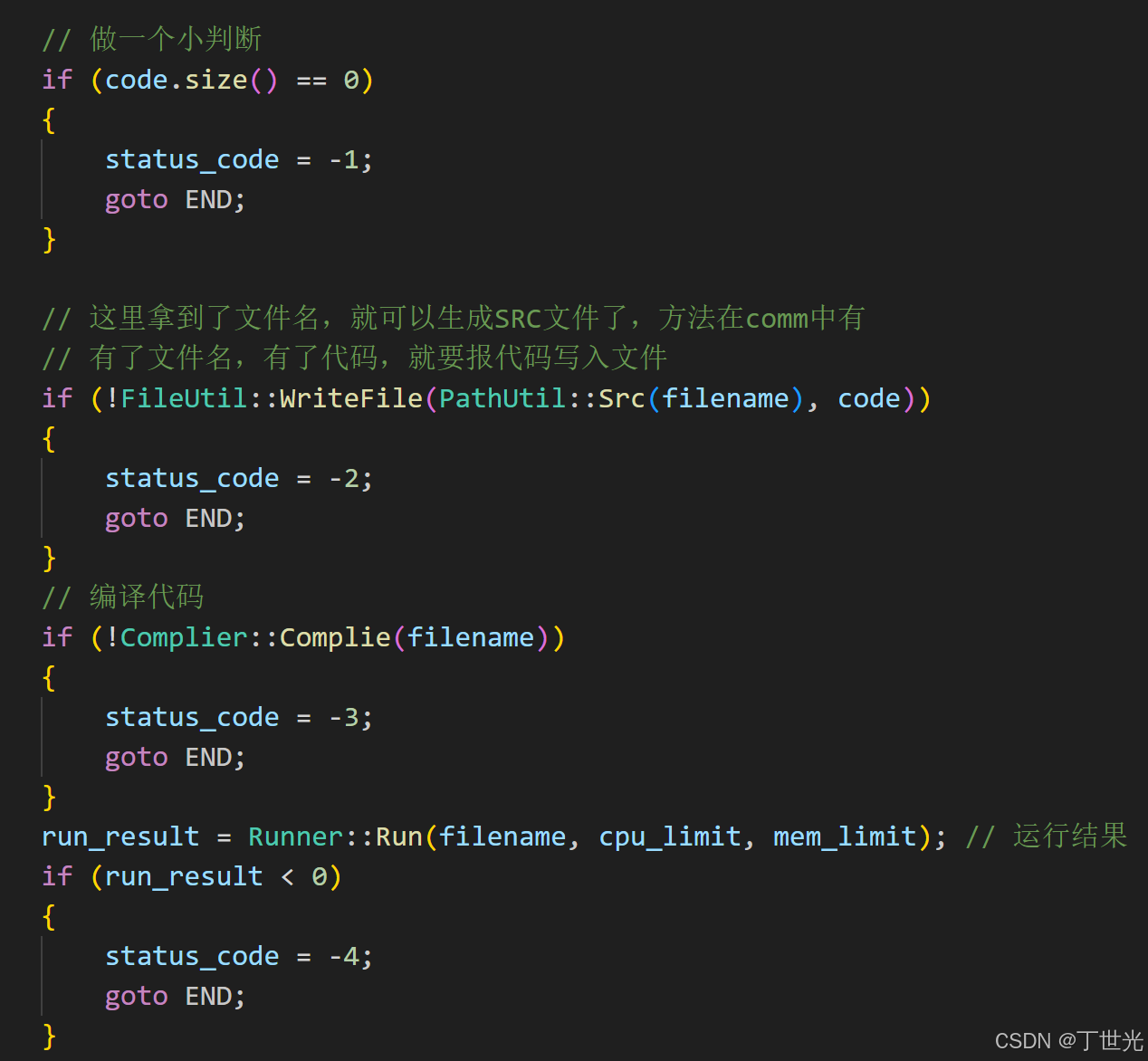


把文件名带进来是为了输出一个编译时的错误,这个错误保存在文件中。
static std::string CodeToString(int code,std::string& _filename){/*** code* < 0 :非运行出错* > 0 :运行时出异常* ==0 成功运行* */std::string desc;switch (code){case 0:desc = "代码编译运行成功";break;case -1:desc = "提交的代码为空";break;case -2:desc = "未知错误,可能是写入文件失败";break;case -3:desc = FileUtil::ReadFile(PathUtil::CmErr(_filename));break;case -4:desc = "运行出错";break;case SIGABRT:desc = "内存超出使用范围";break;case SIGXCPU:desc = "内存超出使用范围";break;default:desc = "未知错误,status_code等于" + std::to_string(code);break;}return desc;}

#pragma once
// 本文件将编译和运行整合到一起
#include "complie.hpp"
#include "run.hpp"#include <jsoncpp/json/json.h>namespace ns_CR
{using namespace ns_complier;using namespace ns_runner;/**************************************** 输入:* code: 用户提交的代码* input: 用户给自己提交的代码对应的输入,不做处理* cpu_limit: 时间要求* mem_limit: 空间要求** 输出:* 必填* status: 状态码* reason: 请求结果* 选填:* stdout: 我的程序运行完的结果* stderr: 我的程序运行完的错误结果** 参数:* in_json: {"code": "#include...", "input": "","cpu_limit":1, "mem_limit":10240}* out_json: {"status":"0", "reason":"","stdout":"","stderr":"",}* ************************************/class ComplieAndRun{static std::string CodeToString(int code,std::string& _filename){/*** code* < 0 :非运行出错* > 0 :运行时出异常* ==0 成功运行* */std::string desc;switch (code){case 0:desc = "代码编译运行成功";break;case -1:desc = "提交的代码为空";break;case -2:desc = "未知错误,可能是写入文件失败";break;case -3:desc = FileUtil::ReadFile(PathUtil::CmErr(_filename));break;case -4:desc = "运行出错";break;case SIGABRT:desc = "内存超出使用范围";break;case SIGXCPU:desc = "内存超出使用范围";break;default:desc = "未知错误,status_code等于" + std::to_string(code);break;}return desc;}// 对于一个整合好的函数,它处理一个从下层传上来的网络字节流,输出的也应该是一个字符串static void Start(const std::string &in_json, std::string out_json){// 把网络字节流反序列化Json::Value in_string;// 要用到Json中的反序列中间类Json::Reader reader;reader.parse(in_json, in_string);//{"code":"#include .....",}std::string code = in_string["code"].asString();std::string input = in_string["input"].asString();int cpu_limit = in_string["cpu_limit"].asInt();int mem_limit = in_string["mem_limit"].asInt();// 准备out_json,这个过程是序列化Json::Value out_string;// 定义可能的全部变量int status_code = 0; // 用于保存执行结果// 对于解析出来代码的处理,形成一个SRC文件,但是有可能多个用户在做同一道题,所以要保证形成的SRC// 文件是唯一的std::string filename = FileUtil::UniqueFileName();int run_result = 0;// 做一个小判断if (code.size() == 0){status_code = -1;goto END;}// 这里拿到了文件名,就可以生成SRC文件了,方法在comm中有// 有了文件名,有了代码,就要报代码写入文件if (!FileUtil::WriteFile(PathUtil::Src(filename), code)){status_code = -2;goto END;}// 编译代码if (!Complier::Complie(filename)){status_code = -3;goto END;}run_result = Runner::Run(filename, cpu_limit, mem_limit); // 运行结果if (run_result < 0){status_code = -4;goto END;}// 出异常if (run_result > 0){status_code = run_result;goto END;}END:out_string["status"] = status_code;out_string["reason"] = CodeToString(status_code,filename);if (status_code == 0){// 整个过程全部成功std::string _stdout;FileUtil::ReadFile(PathUtil::Stdout(filename));out_string["stdout"] = _stdout;std::string _stderr;FileUtil::ReadFile(PathUtil::Err(filename));out_string["stderr"] = _stderr;}}};
}
不难看出一点,status_code大于0时,一定是运行时出现异常,那么这个异常在CodeToString处理了,为什么整个过程全部运行成功后,还是把stderr文件带出去了。
其实不影响,因为运行成功时,这个文件为空。
如何生成唯一文件名
//形成唯一的文件名static std::string UniqueFileName(){static std::atomic_uint id(0);++id;//生成唯一文件名:毫秒级时间戳+递增器std::string a = TimeUtil::GetTimeStampMs();std::string b = std::to_string(id);return a + "_" + b;}
读写文件
static bool WriteFile(const std::string& filename,std::string& code){std::ofstream out(filename);if(!out.is_open()){return false;}out.write(code.c_str(),code.size());out.close();return true;}static bool ReadFile(const std::string& filename,std::string* content,bool keep=false){(*content).clear();std::ifstream in(filename);if(!in.is_open()){return false;}std::string line;while(std::getline(in,line)){//按行读(*content) += line;(*content) += (keep ? "\n" :"");}return true;}
测试全部编译服务
先测试正确运行的情况下,各个文件的生成,是否正确
编译sever_complie.cc

#include "CR.hpp"
using namespace ns_CR;
int main()
{//先形成一个json字符串Json::Value in_value;std::string in_json;//待处理的字符串//手动处理in_value["code"] = R"(
#include <iostream>
int main()
{std::cout << "我是客户端发送来的源代码" << std::endl;return 0;
}
)";in_value["input"] = "";in_value["cpu_limit"] = 1;in_value["mem_limit"] = 1024 * 30;//如果内存限制为30MB,这个地方的单位是KB,需要转化//代码走到这一步,可以得到结构化字符串Json::FastWriter writer;in_json = writer.write(in_value);//in_json是结构化字符串std::string out_json;ComplieAndRun::Start(in_json,&out_json);std::cout << out_json << std::endl;return 0;
}
生成了一个文件名唯一的源文件
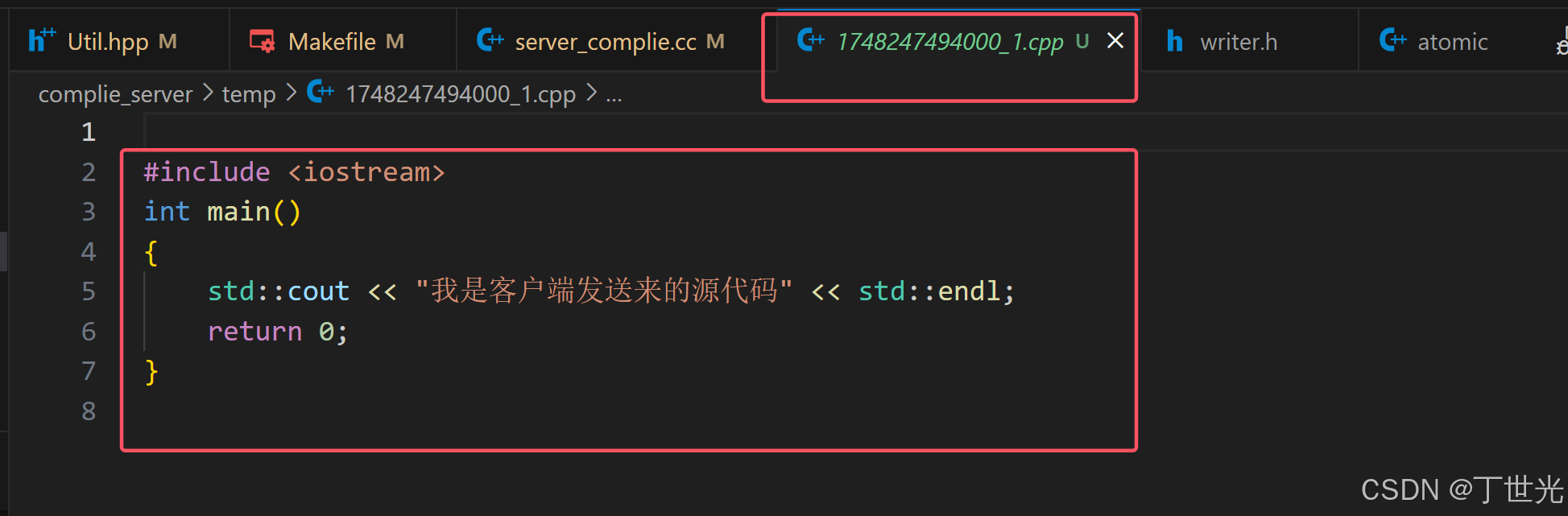
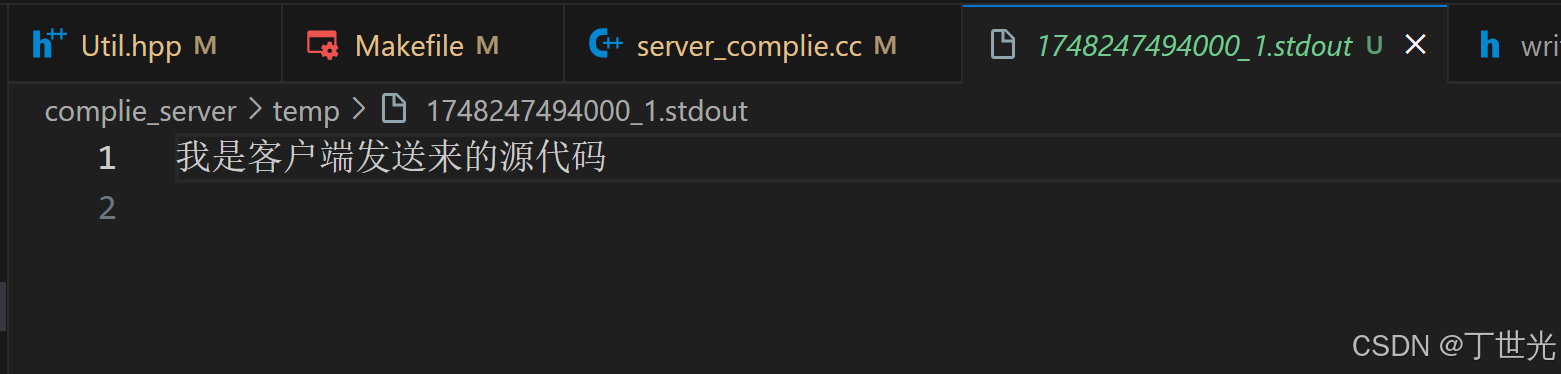
程序的打印结果也正常保存在了stdout文件中
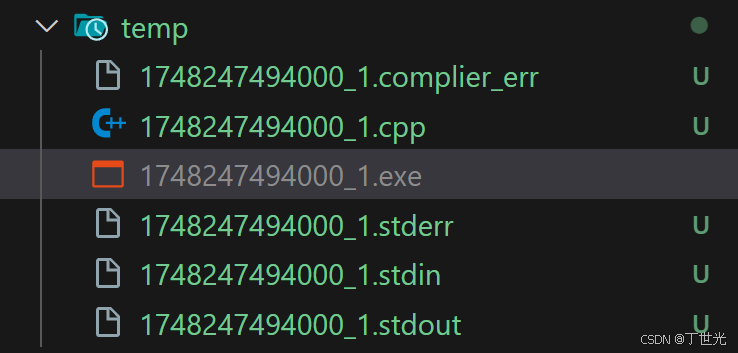
所有文件正常被生成
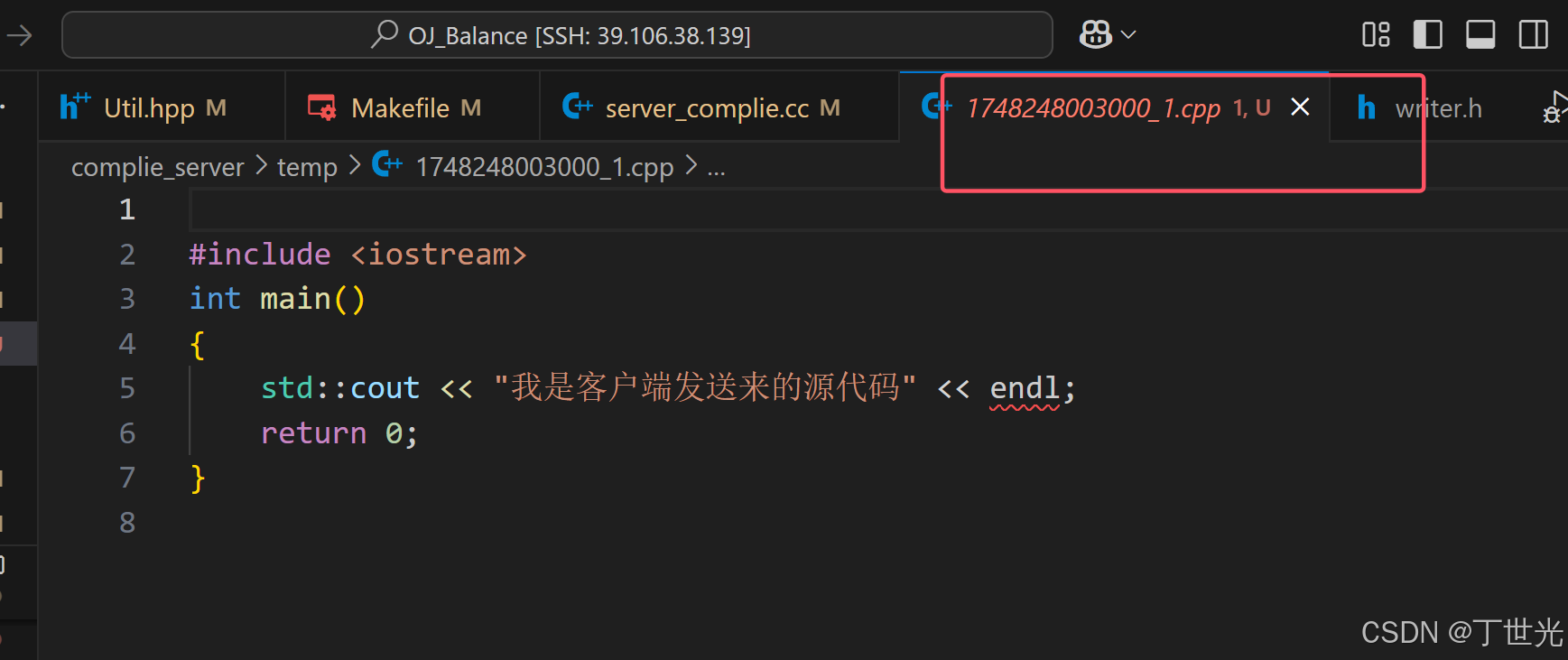
如果是一个错误的代码呢,我们把源代码中少写一个std的域名,看看编译错误能不能被保存在文件中

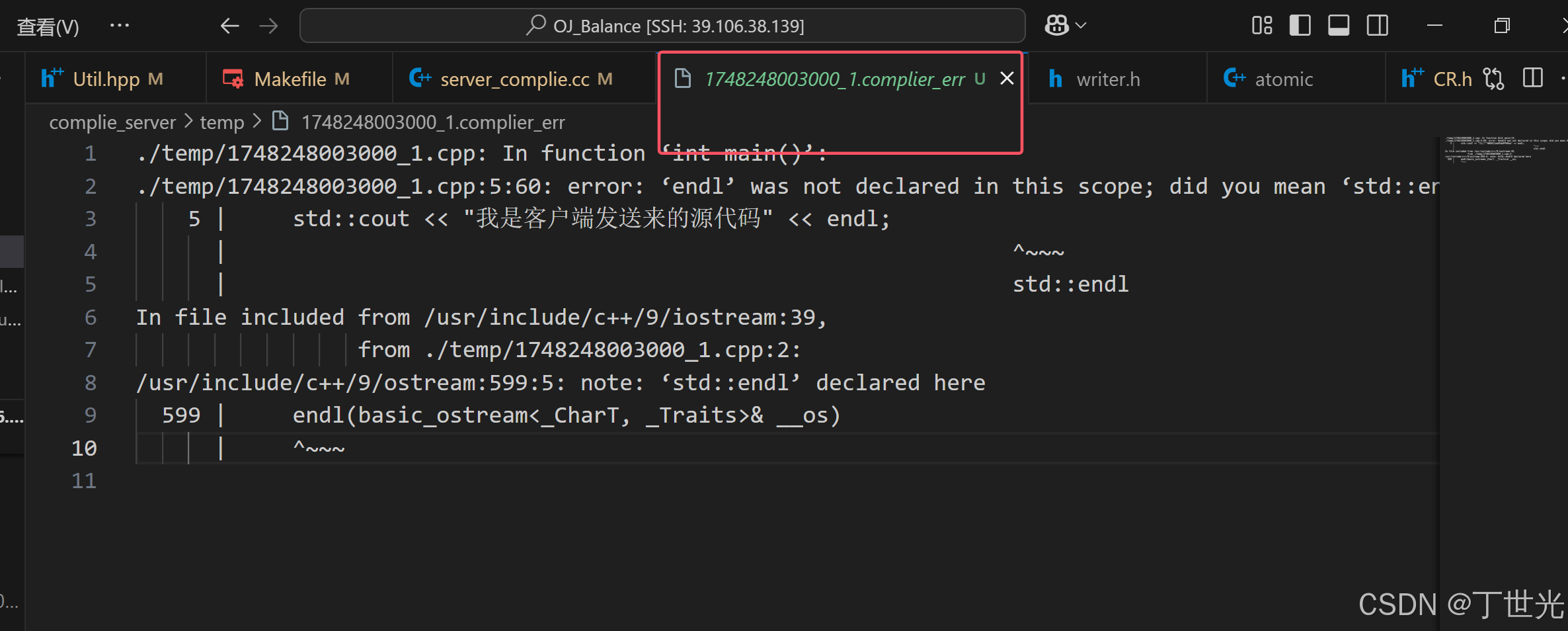
可以再测试一下运行超时的情况
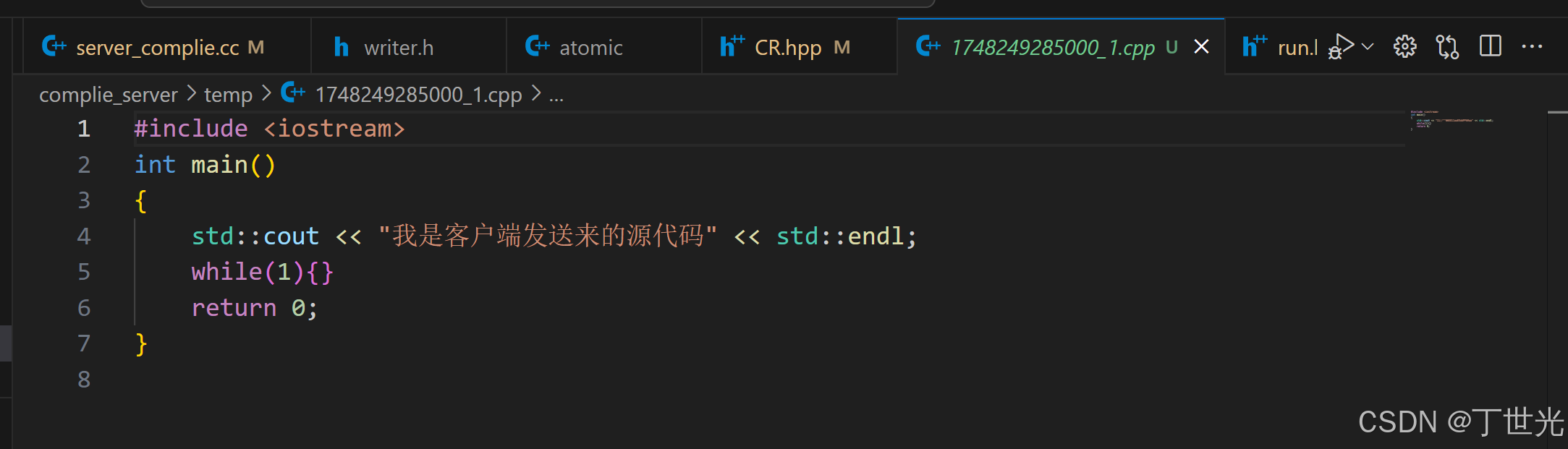
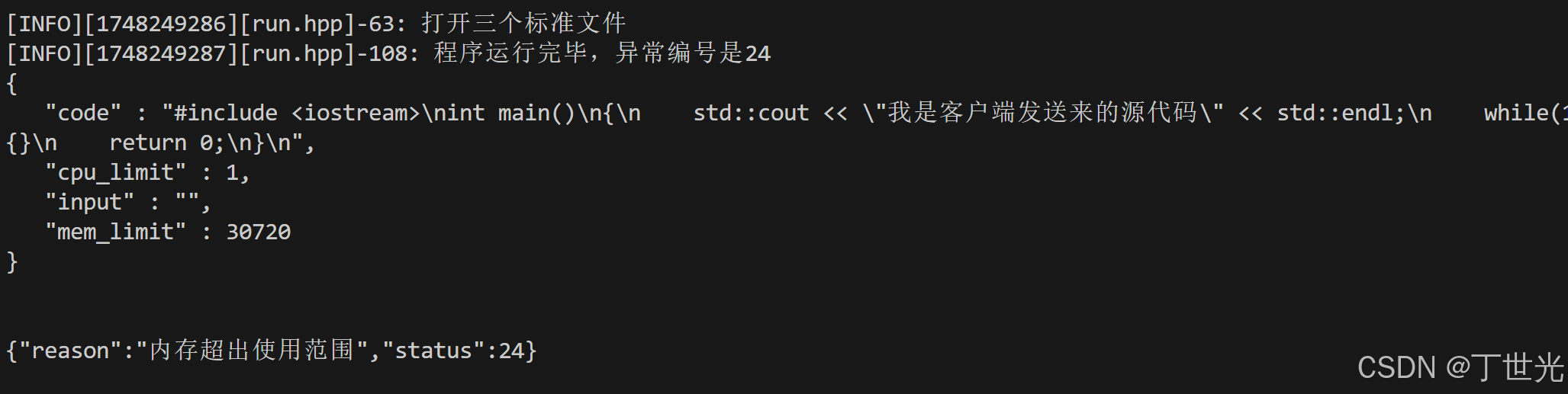
自动删除所有临时文件
将本地的编译服务打包成网络服务
cpp-httplib是一个轻量级的 C++ HTTP 库,用于快速开发 HTTP 客户端和服务器。它的设计目标是简单易用,仅需一个头文件(httplib.h),无需额外的依赖,非常适合嵌入式系统、小型服务或快速原型开发
怎么使用呢
1.在Gitee上搜索cpp-httplib开源项目,比如这个
https://gitee.com/welldonexing/cpp-httplib
2.点击标签,选择要下载的一个版本,我这里下载的是0.18.0
3.使用cpp-httplib要注意
*g++编译器要尽可能的新,我这里使用的是
4.由于我在云服务器上开发,需要将在windows上下载的头文件传到云服务器上。
sudo apt update sudo apt upgrade sudo apt install lrzsz -yrz

这个文件比较大,我下载的这个足足有一万多行
先简单引用一下这个头文件,看看编译是否报错
在Makefile中链接多线程库
简单写一个根目录处理,用到了lamada表达式
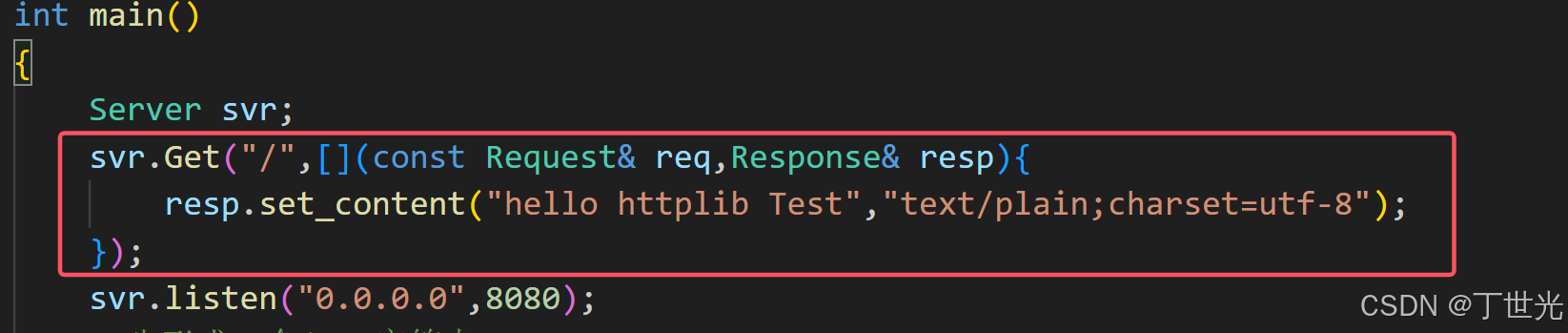
再简单写一个编译并运行
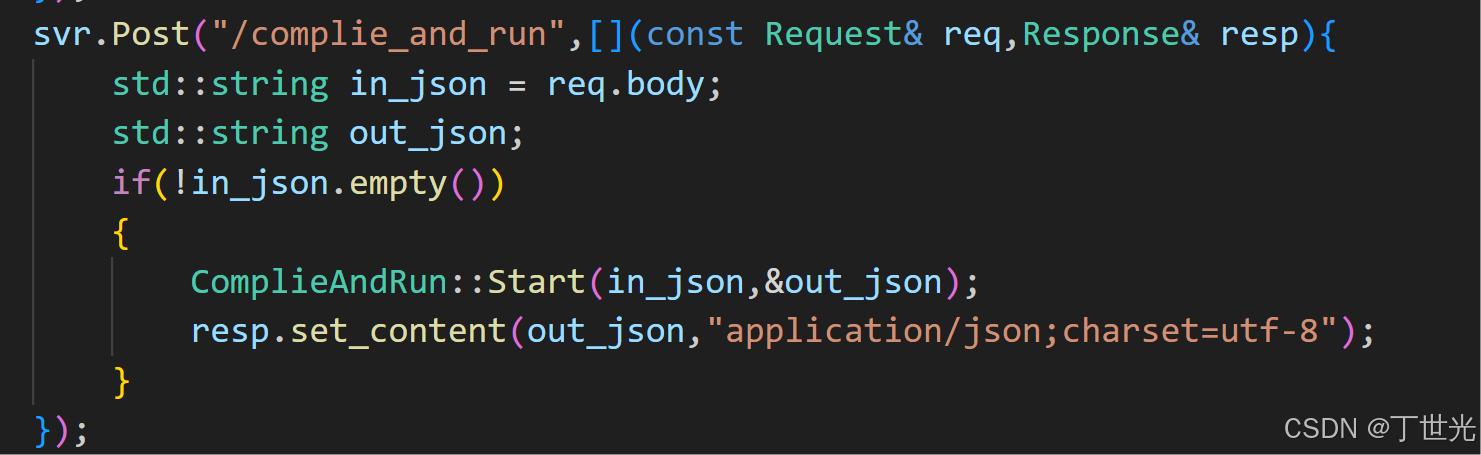
如果用浏览器去访问是得不到结果的,因为浏览器默认是用GET方法请求,这里借助postman工具测试
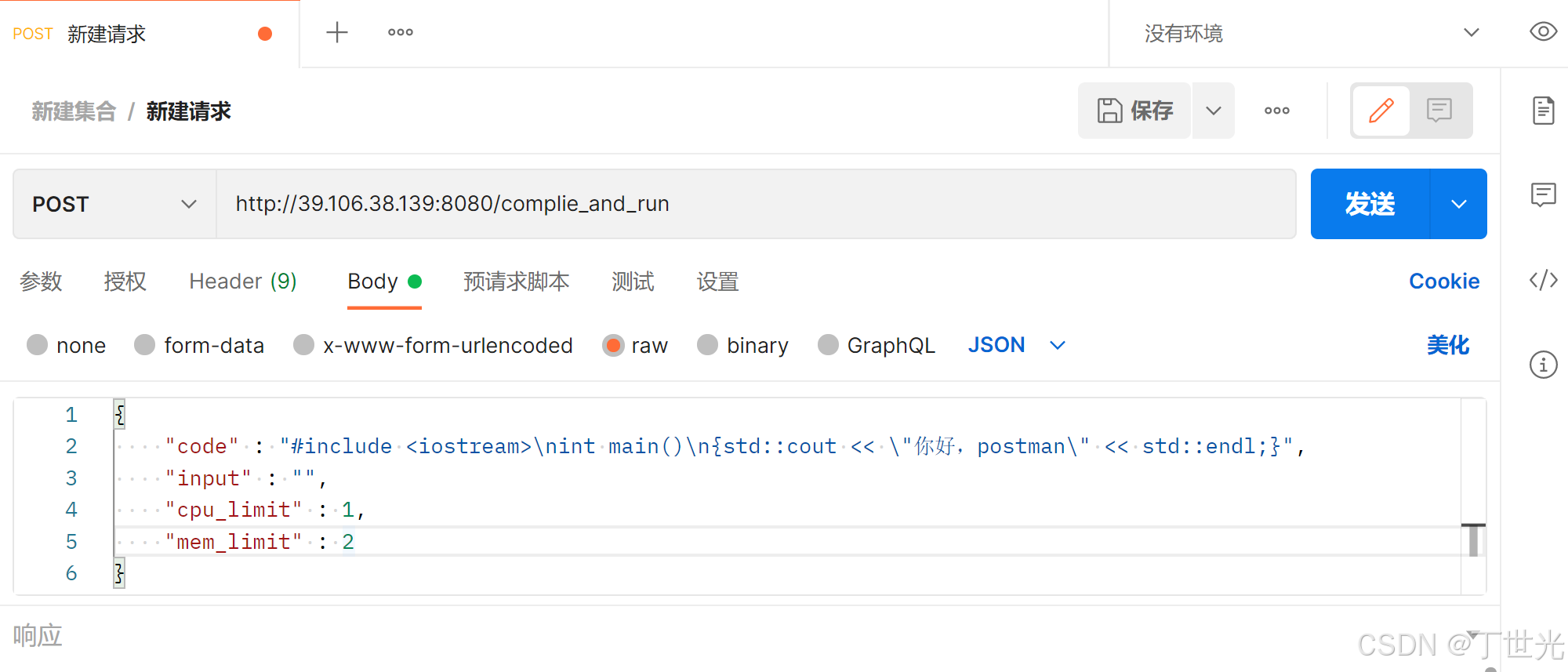
改一下端口号

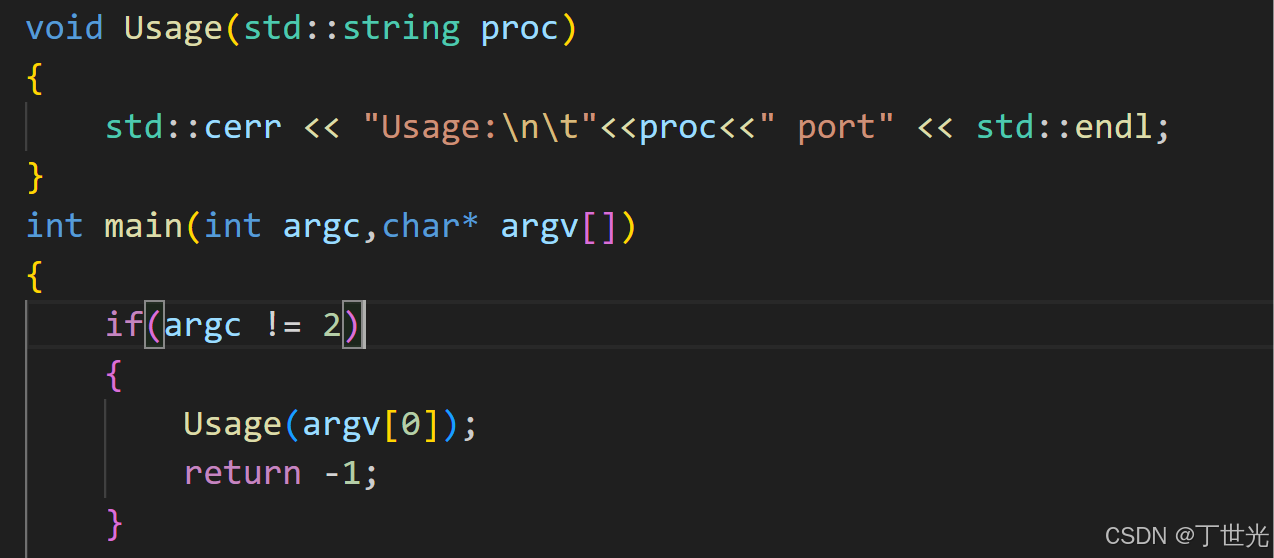

2.基于MVC结构的oj_server
- oj_server和complie_server什么关系
oj_server才是这个项目中的核心模块,oj_server最终是负载均衡式的去调用complie_server程序
服务框架
1.一个oj服务,要有首页,这里用题目列表代替即可,因为这不是这个项目的重点
2.要有题目的编辑页面
3.oj_server能获取提交上来的代码,编译并运行,返回结果。
所谓的基于MVC结构。
MVC(Model-View-Controller)是一种软件设计模式,通过将程序分为三个核心部分:模型(Model)、视图(View)和控制器(Controller),实现代码的分离和复用,提升开发效率与可维护性。
| 组件 | 职责 | 典型实现 | 与其他组件的交互 |
|---|---|---|---|
| 模型(Model) | - 处理业务逻辑与数据存储 - 负责数据的增删改查 - 与数据库直接交互 | - 数据库实体类(如 Java 的 POJO) - 业务逻辑类(Service 层) | - 被控制器调用以获取 / 修改数据 - 状态变化时通知视图 |
| 视图(View) | - 负责用户界面展示 - 渲染数据并与用户交互 - 不包含任何业务逻辑 | - Web 页面(HTML/JSP/Vue 组件) - 移动端界面(XML/Storyboard) | - 通过控制器获取模型数据 - 将用户输入传递给控制器 |
| 控制器(Controller) | - 作为模型与视图的中间层 - 接收用户请求,调用模型处理业务 - 决定返回哪个视图及传递的数据 | - Spring MVC 中的 @Controller 类 - Servlet 控制器 | - 从视图获取用户输入 - 调用模型方法处理逻辑 - 将结果传递给视图渲染 |
其中Controller是oj_server要实现的重点。
实现服务路由
#include <iostream>
#include "../comm/httplib.h"using namespace httplib;
int main()
{//网络服务Server svr;//用户获取所有题目列表svr.Get("/all_questions",[](const Request& req,Response& resp){resp.set_content("展示OJ的全部题目","text/plain;charset=utf-8");});//用户选定了一道题,展示题目编辑页面,(正则表达式和Raw String)svr.Get(R"(/question/(\d+))",[](const Request& req,Response& resp){std::string number = req.matches[1];//Request的matches用来匹配正则表达式resp.set_content("当前题目详情是题号"+number,"text/plain;charset=utf-8");});//用户提交代码,使用我们的判题功能svr.Get(R"(/judge/(\d+))",[](const Request& req,Response& resp){std::string number = req.matches[1];//Request的matches用来匹配正则表达式resp.set_content("当前判题"+number,"text/plain;charset=utf-8");});svr.set_base_dir("./wwwroot");svr.listen("0.0.0.0",8088);return 0;
}文件版题库设计
既然基于文件存储,就要有一个文件来保存所有的题目唯一标识。
![]()
对于每一道题,单独存储在一个目录,所有题目的粗略信息保存在题目列表里
格式:题号 标题 难度 cpu限制 内存限制
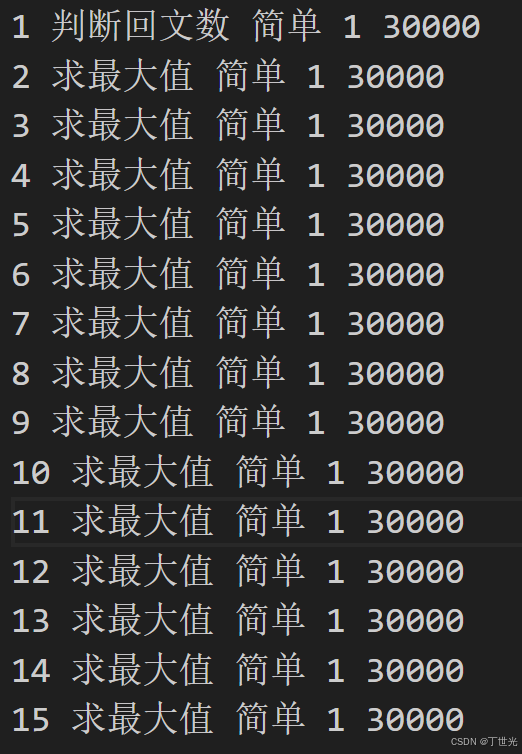
而对于每一道题,有三个文件与之相关。
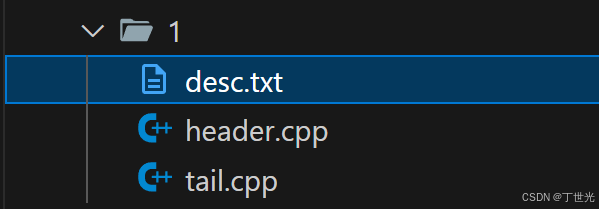
desc.txt存储详细信息,header.cpp是展现给用户看到的代码,tail.cpp最后拼接header.cpp返回给后端的编译服务,编译运行。
判断一个整数是否是回文数。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。示例 1:输入: 121
输出: true
示例 2:输入: -121
输出: false
解释: 从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不是一个回文数。
示例 3:输入: 10
输出: false
解释: 从右向左读, 为 01 。因此它不是一个回文数。
进阶:你能不将整数转为字符串来解决这个问题吗?
#include <iostream>
#include <string>
#include <vector>
#include <map>
#include <algorithm>using namespace std;class Solution{public:bool isPalindrome(int x){//将你的代码写在下面return true;}
};
#ifndef COMPILER_ONLINE
#include "header.cpp"
#endifvoid Test1()
{// 通过定义临时对象,来完成方法的调用bool ret = Solution().isPalindrome(121);if(ret){std::cout << "通过用例1, 测试121通过 ... OK!" << std::endl;}else{std::cout << "没有通过用例1, 测试的值是: 121" << std::endl;}
}void Test2()
{// 通过定义临时对象,来完成方法的调用bool ret = Solution().isPalindrome(-10);if(!ret){std::cout << "通过用例2, 测试-10通过 ... OK!" << std::endl;}else{std::cout << "没有通过用例2, 测试的值是: -10" << std::endl;}
}int main()
{Test1();Test2();return 0;
}
ojmodel.hpp
model模块, 属性是一个KV结构,可以根据题号映射题目全部内容
对外提供的接口:
GetAllQuestions,这个接口对外输出一个vector,存储了全部题目
GetOneQuestion,这个接口输出具体的一道题的详细信息
#pragma once
// Model模块的作用:
// 根据题目list文件,加载所有的题目信息到内存中
// model: 主要用来和数据进行交互,对外提供访问数据的接口
#include <iostream>
#include <string>
#include <unordered_map>
#include <vector>
#include <fstream>
#include <cassert>
#include "../comm/Util.hpp"
#include "../comm/Log.hpp"namespace ns_model
{using namespace ns_util;using namespace ns_log;typedef struct Question{std::string number; // 题目编号,唯一std::string title; // 题目的标题std::string star; // 难度: 简单 中等 困难int cpu_limit; // 题目的时间要求(S)int mem_limit; // 题目的空间要求(KB)std::string desc; // 题目的描述std::string header; // 题目预设给用户在线编辑器的代码std::string tail; // 题目的测试用例,需要和header拼接,形成完整代码}Question;std::string g_questionslist = "./questions/Questions.list";std::string g_questionspath = "./questions/";class Model{private:// 根据题号拿到题目的详细内容std::unordered_map<std::string, Question> ql;public:Model(){assert(LoadQuestionsList(g_questionslist));}//从文件中把题目列表加载到内存中bool LoadQuestionsList(const std::string& questionlist)//文件名{std::ifstream in(questionlist);if(!in.is_open()){LOG(FATAL) << " 加载题库失败,请检查是否存在题目文件\n";return false;}std::string line;while(getline(in,line)){//字符串分割std::vector<std::string> tokens;StringUtil::Split(line,&tokens," ");if(tokens.size() != 5){//忽略这一行LOG(WARNING) << "某一行加载失败,请检查文件格式是否出错\n";continue;}//切割成功了,就把对应的K,V值插入Question q;q.number = tokens[0];q.title = tokens[1];q.star = tokens[2];q.cpu_limit = atoi(tokens[3].c_str());q.mem_limit = atoi(tokens[4].c_str());std::string path = g_questionspath;path += q.number;path += "/";FileUtil::ReadFile(path+="desc.txt",&(q.desc),true);FileUtil::ReadFile(path+="header.cpp",&(q.header),true);FileUtil::ReadFile(path+="tail.cpp",&(q.tail),true);ql.insert({q.number,q});}LOG(INFO) << "加载题库成功\n";in.close();return true;}//这个函数把所有题目从unordered_map中拷贝到vector中bool GetAllQuestions(std::vector<Question> *out){if(ql.size() == 0){LOG(ERROR) << "用户获取题库失败\n";return false;}for(auto& e:ql){out->push_back(e.second);}return true;} //获取某一道题的详细信息bool GetOneQuestion(std::string& number,Question* out){const auto& iter = ql.find(number);if(iter == ql.end()){LOG(ERROR) << "获取题目详细内容失败,题目编号;"<<number<<std::endl;return false;}*out = iter->second;return true;}~Model(){}};
}
值得一提的是,用到了分割字符串的boost库
sudo apt updatesudo apt install libboost-all-dev验证安装
dpkg -s libboost-dev | grep Version
//字符串工具class StringUtil{public:/*** str:输入型参数,待分割的字符串* content:输出型参数,是一个vector,里面保存分割完的字符串* sep:分割符*/static bool Split(const std::string& str,std::vector<std::string>* content,const std::string& sep){boost::split((*content),str,boost::is_any_of(sep),boost::algorithm::token_compress_on);}};安装ctemplate库
CTemplate 是一个用于生成文本输出(如 HTML、配置文件)的 C++ 模板库,由 Google 开发,特点是语法简单、安全且高效。它通过
{{VARIABLE}}风格的标记将模板文件与数据分离,广泛用于 Web 应用和代码生成工具。sudo apt updatesudo apt install libctemplate-dev
验证安装
ls -l /usr/include/ctemplateojcontrol.hpp
图片渲染的工作由V来完成,借助ctemplate库,至于view的接口设计,需要看control要如何调用,所以先来设计control.hpp
#pragma once#include <iostream>
#include <string>
#include <vector>
#include "../comm/Util.hpp"
#include "../comm/Log.hpp"
#include "ojmodel.hpp"
#include "ojview.hpp"namespace ns_control
{using namespace ns_util;using namespace ns_log;using namespace ns_model;using namespace ns_view;class Control{private:Model _model;View _view;public://control用这个接口,输出一个html网页bool AllQuestions(std::string* html){std::vector<Question> q;if(_model.GetAllQuestions(&q)){//调用view的接口去渲染_view.AllToHtml();}else{return false;}}bool OneQuestions(std::string& number,std::string* html){Question q;if(_model.GetOneQuestion(number,&q)){//调用view的接口去渲染_view.OneToHtml();}else{return false;}}};
}
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include "ojmodel.hpp"
#include <ctemplate/template.h>namespace ns_view
{using namespace ns_model;const std::string template_path = "./ctemplate/";class View{public://产出一个htmlbool AllToHtml(const std::vector<Question>& qs,std::string* html){// 题目的编号 题目的标题 题目的难度// 推荐使用表格显示// 1. 形成路径std::string src_html = template_path + "all_questions.html";// 2. 形成数字典ctemplate::TemplateDictionary root("all_questions");for (const auto& q : qs){ctemplate::TemplateDictionary *sub = root.AddSectionDictionary("question_list");sub->SetValue("number", q.number);sub->SetValue("title", q.title);sub->SetValue("star", q.star);}//3. 对于ctemplate,获取被渲染的htmlctemplate::Template *tpl = ctemplate::Template::GetTemplate(src_html, ctemplate::DO_NOT_STRIP);//4. 对于ctemplate,要把src_html渲染到哪里tpl->Expand(html, &root);return true;}bool OneToHtml(std::string* html){return true;}};
}
ctemplate是渲染网页,因此要有已经写好的待渲染的网页,放在ctemplate目录下
源码就不展示了,只需要知道这两个网页即可,ojserver.cc中是这样写的
Web根目录是这样写的

编写获取一道题的函数
bool OneToHtml(const Question& q,std::string* html){//1.获取路径std::string src_html = template_path + "one_question.html";//2.形成字典ctemplate::TemplateDictionary root("one_question");root.SetValue("number",q.number);root.SetValue("title",q.title);root.SetValue("star",q.star);root.SetValue("desc",q.desc);root.SetValue("pre_code",q.header);//3.对于ctemplate,要知道src_html在哪里ctemplate::Template* tpl = ctemplate::Template::GetTemplate(src_html,ctemplate::DO_NOT_STRIP);//4.对于ctemplate,要把src_html渲染tpl->Expand(html,&root);return true;}

负载均衡设计
提供编译服务的主机配置文件。
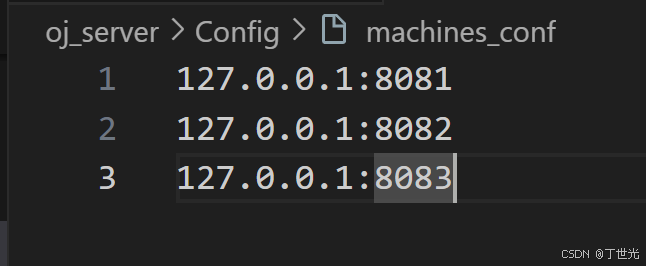
// 提供编译服务的主机class Machine{public:std::string ip; // 提供编译服务的主机ipuint16_t port; // 端口uint64_t load; // 该主机的负载,用请求的熟练来衡量负载std::mutex *mtx; // C++提供的锁,禁止拷贝,所以必须定义为指针public:Machine() : ip(""), port(0), load(0), mtx(nullptr) {}~Machine() {}//主机负载+1bool LoadIncrease(){if(mtx) mtx->lock();++load;if(mtx) mtx->unlock();return true;}//主机负载-1bool LoadDecrease(){if(mtx) mtx->lock();--load;if(mtx) mtx->unlock();return true;}uint64_t Load(){uint64_t _load = 0;if (mtx) mtx->lock();_load = load;if (mtx) mtx->unlock();return _load;}};
// 负载均衡模块class LoadBalance{private:// 对于一个负载均衡模块,要知道都有哪些主机可以调配// 在vector里,每一个主机的下标就是主机的idstd::vector<Machine> machines;// 有哪些主机在线,用machines的下标标识std::vector<int> online;// 有哪些主机离线:idstd::vector<int> offline;std::mutex mtx;public:LoadBalance(){assert(LoadConf(machines_path));}~LoadBalance() {}public:// 加载配置文件bool LoadConf(const std::string &conf_path){std::ifstream in(conf_path);if (!in.is_open()){LOG(ERROR) << "加载配置文件失败,请检查文件名\n";return false;}std::string line;while (std::getline(in, line)){std::vector<std::string> tokens;StringUtil::Split(line, &tokens, ":");if (tokens.size() != 2){LOG(WARNING) << " 切分 " << line << " 失败"<< "\n";continue;}Machine m;m.ip = tokens[0];m.port = atoi(tokens[1].c_str());m.load = 0;m.mtx = new std::mutex();// machines为0时,则把id为0的主机插入在线online.push_back(machines.size());machines.push_back(m);}in.close();return true;}// id: 输出型参数// m : 输出型参数//这里为什么是二级指针,就要思考,外部是什么类型的值,由于管理机器是由vector管理,在外面就//不能再定义一个machine的变量,否则意味着一台新的主机bool SmartChoice(int *id, Machine **m){// 1. 使用选择好的主机(更新该主机的负载)// 2. 我们需要可能离线该主机mtx.lock();// 负载均衡的算法// 1. 随机数+hash// 2. 轮询+hashint online_num = online.size();if (online_num == 0){mtx.unlock();LOG(FATAL) << " 所有的后端编译主机已经离线, 请运维的同事尽快查看"<< "\n";return false;}// 通过遍历的方式,找到所有主机中负载最小的机器*id = online[0];*m = &machines[online[0]];uint64_t min_load = machines[online[0]].Load();//假设id_0的主机负载是最小的for (int i = 1; i < online_num; i++){uint64_t curr_load = machines[online[i]].Load();if (min_load > curr_load){min_load = curr_load;*id = online[i];*m = &machines[online[i]];}}mtx.unlock();return true;}//离线一台主机bool OfflineMachine(const int& which){mtx.lock();for(auto iter = online.begin(); iter != online.end(); iter++){if(*iter == which){//要离线的主机已经找到啦online.erase(iter);offline.push_back(which);break; //因为break的存在,所有我们暂时不考虑迭代器失效的问题}}mtx.unlock();}//打印所有的主机信息void ShowMachines(){mtx.lock();std::cout << "当前在线主机列表: ";for(auto &id : online){std::cout << id << " ";}std::cout << std::endl;std::cout << "当前离线主机列表: ";for(auto &id : offline){std::cout << id << " ";}std::cout << std::endl;mtx.unlock();}};
补全Control::Judge
//control提供判题功能bool Judge(const std::string& number,const std::string in_json,std::string* out_json){// LOG(DEBUG) << in_json << " \nnumber:" << number << "\n";// 0. 根据题目编号,直接拿到对应的题目细节struct Question q;_model.GetOneQuestion(number, &q);// 1. in_json进行反序列化,得到题目的id,得到用户提交源代码(header.cpp),inputJson::Reader reader;Json::Value in_value;reader.parse(in_json, in_value);std::string code = in_value["code"].asString();// 2. 重新拼接用户代码+测试用例代码,形成新的代码Json::Value all_value;all_value["input"] = in_value["input"].asString();all_value["code"] = code + "\n" + q.tail;all_value["cpu_limit"] = q.cpu_limit;all_value["mem_limit"] = q.mem_limit;//序列化Json::FastWriter writer;std::string all_string = writer.write(all_value);// 3. 选择负载最低的主机(差错处理)// 规则: 一直选择,直到主机可用,否则,就是全部挂掉while(true){int id = 0;Machine *m = nullptr;if(!_loadbalc.SmartChoice(&id, &m)){break;}// 4. 然后发起http请求,得到结果httplib::Client cli(m->ip, m->port);m->LoadIncrease();LOG(INFO) << " 选择主机成功, 主机id: " << id << " 详情: " << m->ip << ":" << m->port << " 当前主机的负载是: " << m->Load() << "\n";if(auto res = cli.Post("/compile_and_run", all_string, "application/json;charset=utf-8")){// 5. 将结果赋值给out_jsonif(res->status == 200){*out_json = res->body;m->LoadDecrease();LOG(INFO) << "请求编译和运行服务成功..." << "\n";break;}m->LoadDecrease();}else{//请求失败LOG(ERROR) << " 当前请求的主机id: " << id << " 详情: " << m->ip << ":" << m->port << " 可能已经离线"<< "\n";_loadbalc.OfflineMachine(id);_loadbalc.ShowMachines(); //仅仅是为了用来调试}}}
在运行后,报编译错误,原因是找不到header.cpp,原因是提交序列化字符串的时候是用户提交的+后端现成的tail.cpp,和header.cpp没有关联,所有在g++编译时,要指定条件编译选项,header.cpp的内容要展示给用户,不能再修改。

Postman接口测试
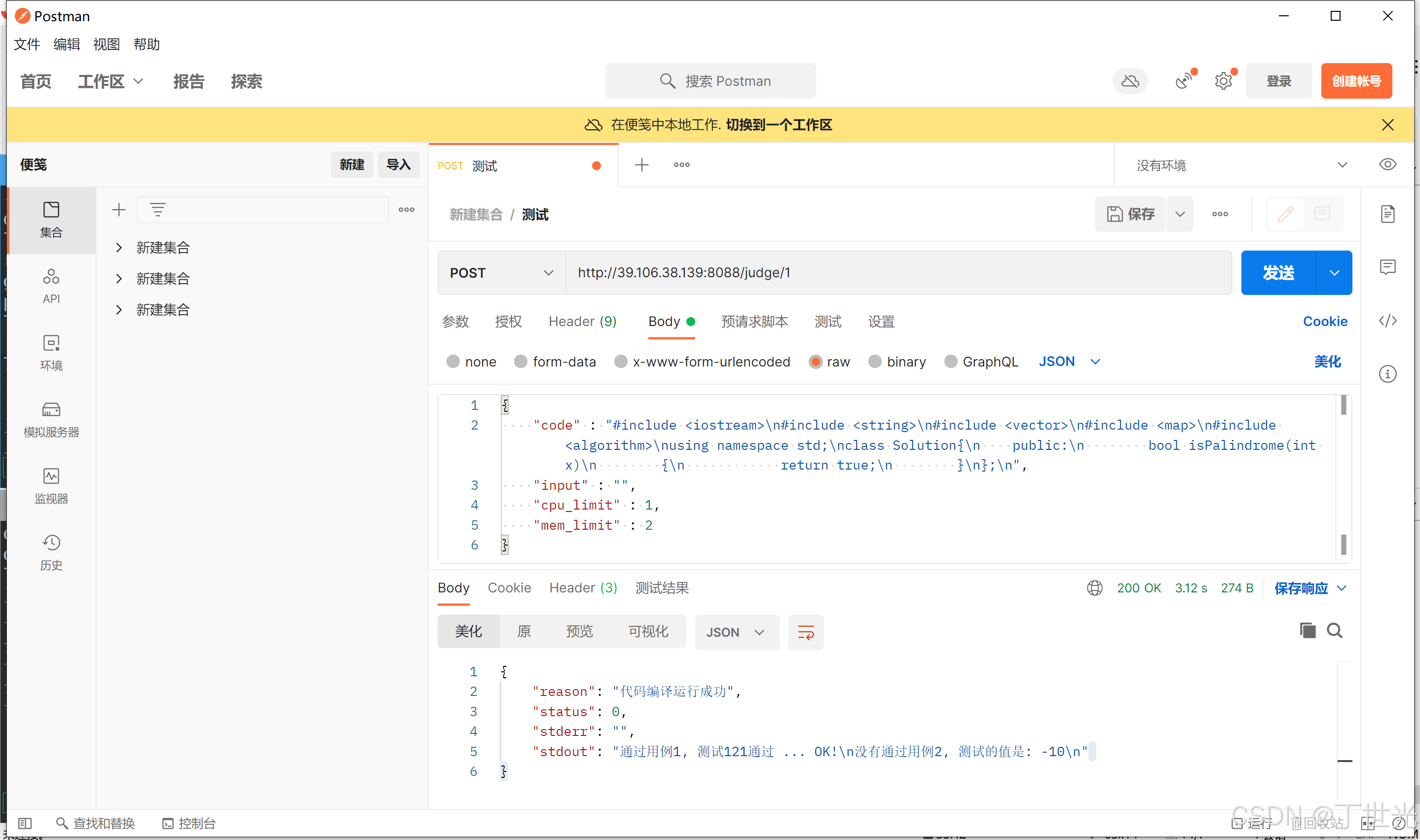
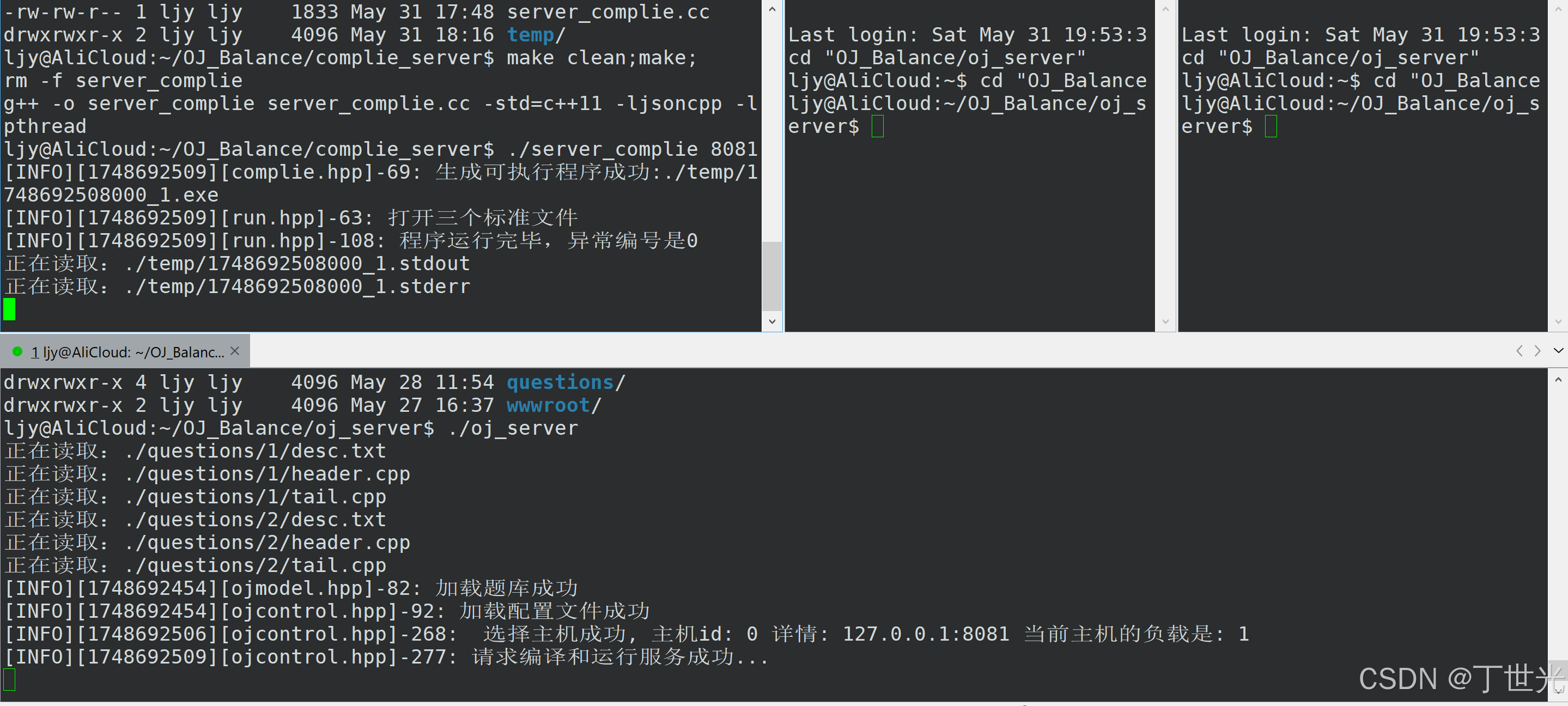
我们假设三台提供编译服务的主机都已经启动,并测试关掉一台主机,再请求,看看能否让其他在线主机提供编译服务。
主机0挂掉,主机1、2在线
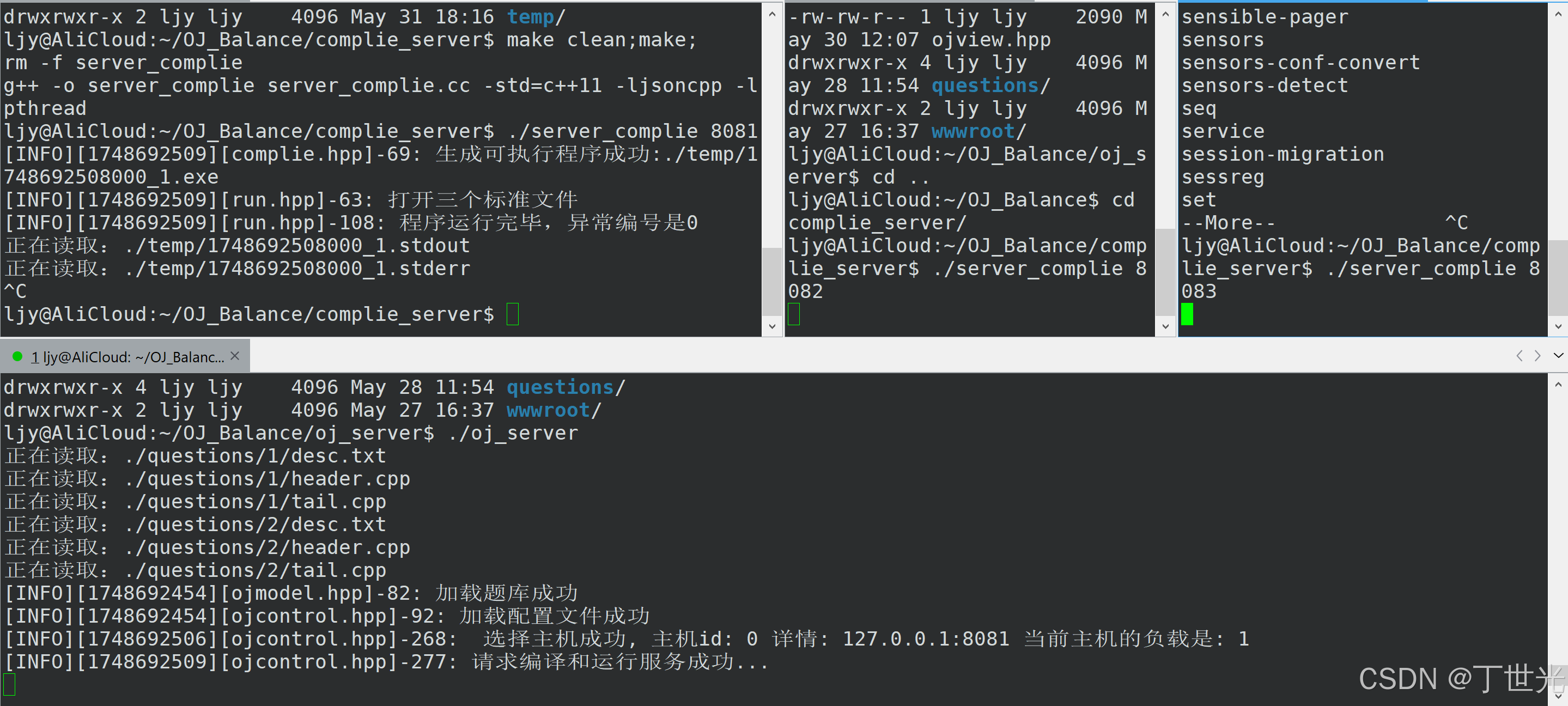
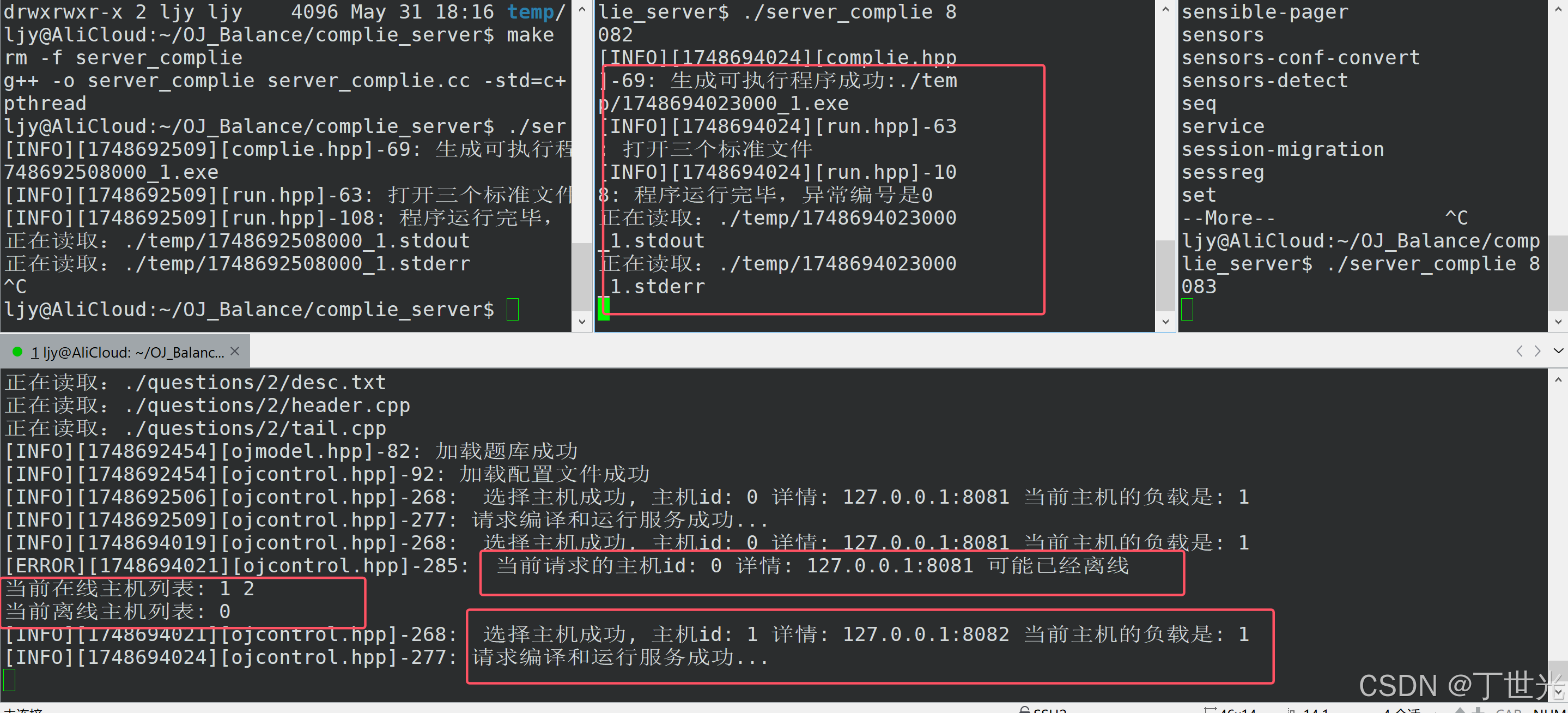
同样用这种方法测试主机2
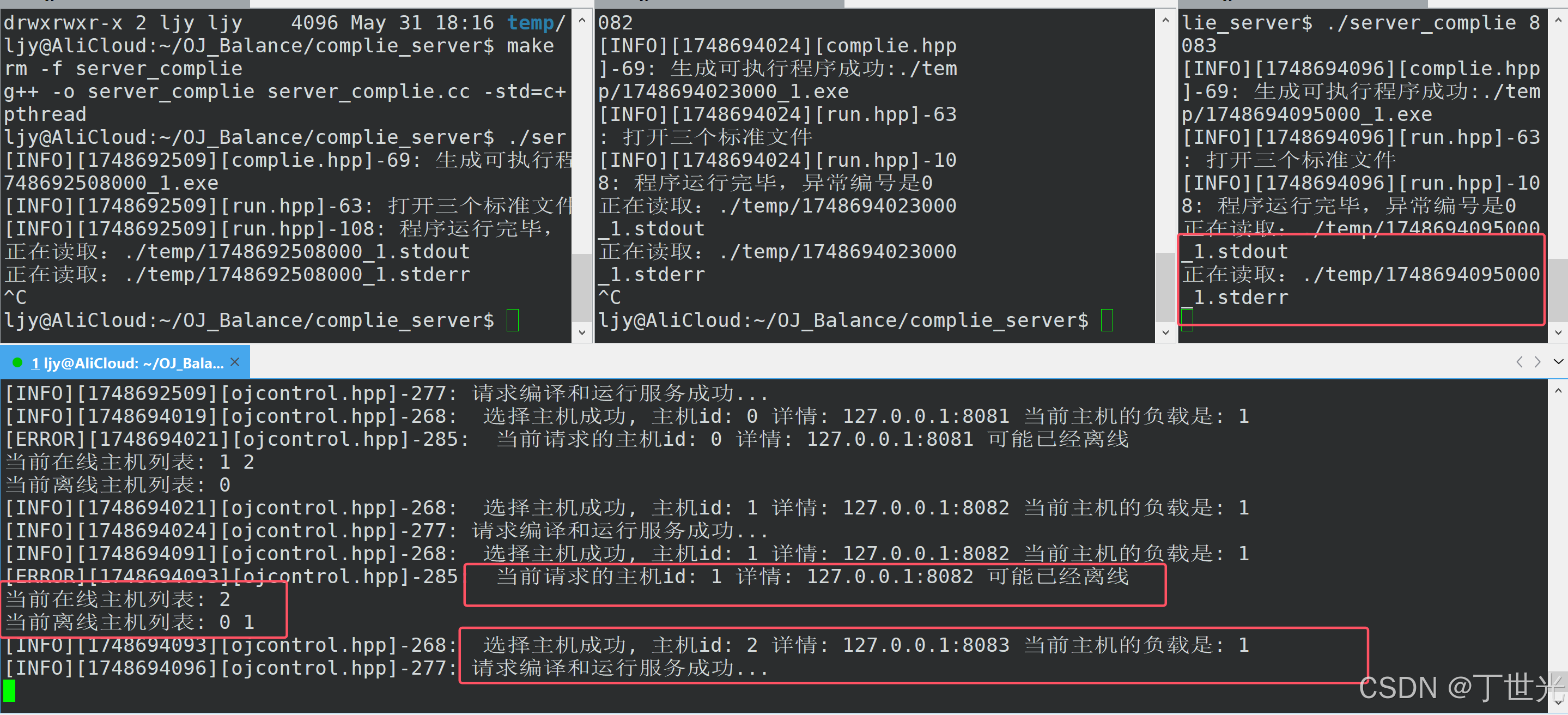
那如果三台机器全部挂断
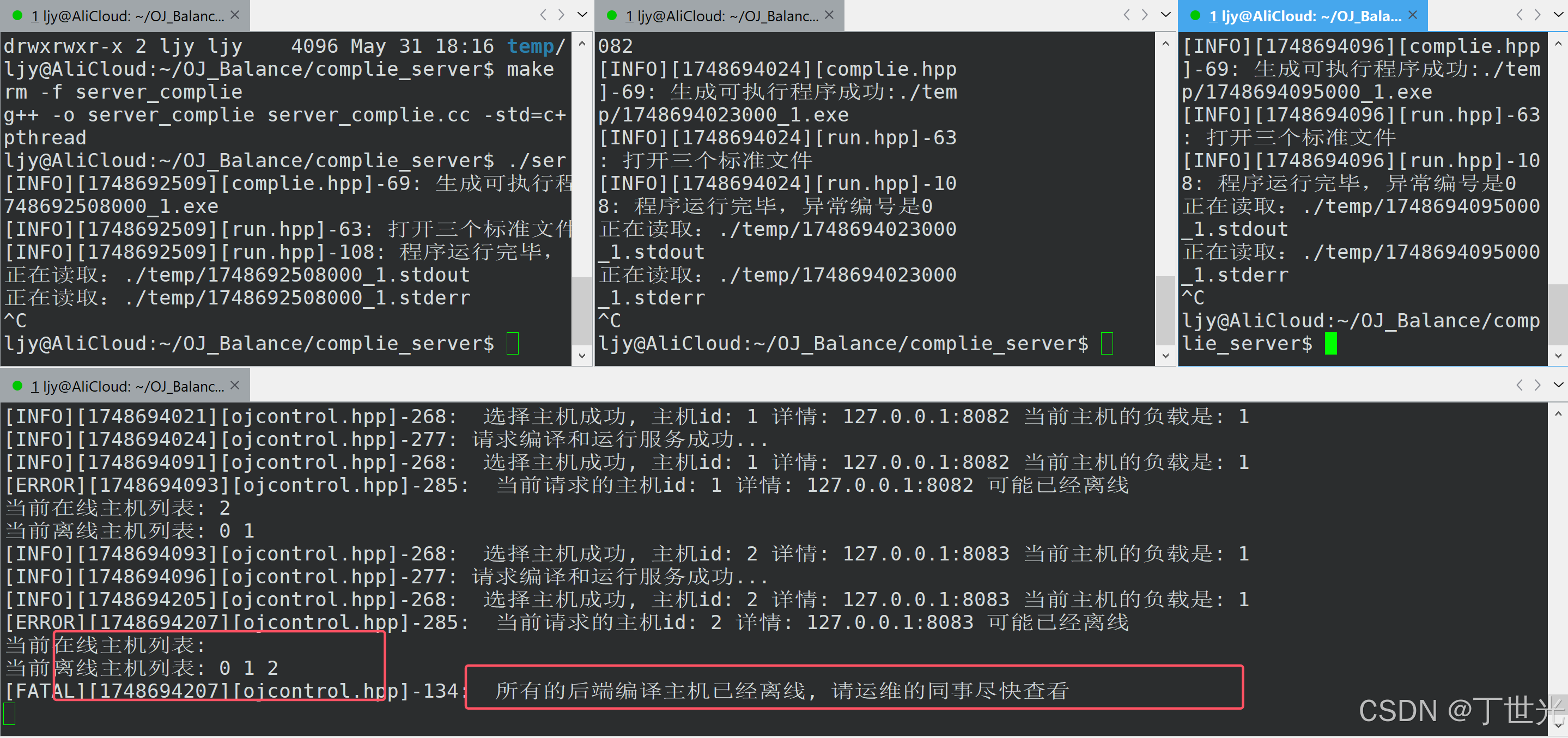
符合预期,测试完毕