【MySQL】索引(B+树详解)



MySQL(五)索引
一、索引的减I/O设计
1.读取量
2.搜索树
2.1方向
2.2有序
3.分多叉
3.1B树
弊端:
3.2B+树
3.2.1非叶子-搜索字段
3.2.1.1海量分叉
3.2.1.1.1最大式
3.2.1.1.2最快式
3.2.1.2缓存内存
3.2.1.2.1字段总量小
3.2.1.2.2时间复杂度
3.2.1.3区间搜索向下保留
3.2.1.3.1过程
3.2.1.3.2模式
3.2.1.3.3效果
3.2.2叶子-对应记录
3.2.2.1全集键值对
3.2.2.2链表物理连续
3.2.2.3开键稳定查询
二、索引的操作
1.查看
2.创建
2.1创建时机
2.2大表索引的创建
2.2.1直接创建过程
2.2.2危险性
2.2.3正确创建做法
3.删除
索引 是以字段为键、记录为值的 B+搜索树
一、索引的减I/O设计
从硬盘搜索读取 查询记录时,由于 一次硬盘读取数据到内存的时间 是内存里操作数据时间的 10万倍,MySQL通过 索引 数据结构的设计 减少了查询记录的硬盘I/O的次数
1.读取量
保持着硬盘 单次最大读取量-页 最大量地进行读取 以减少读取I/O次数,每个B+搜索树节点的存储空间 是一个页,即对应每次读取完 一个B+搜索树节点的 总页存储空间的内容量
2.搜索树
2.1方向
在搜索树中,查询时 会避免遍历地 每次往 正确范围、正向增长搜索到概率 的方向进行搜索 直到最后搜索到 也会精确匹配
2.2有序
搜索树结构 维护了 记录值 以字段键的有序性,支持 以字段的范围查询记录与 以字段的排序记录
对比哈希表:
哈希表虽然能实现 一次硬盘读取 就可O(1)地查询到记录,但只能精确匹配,内部是 以哈希函数维护的 无序数组,无法范围查询,也无法进行排序
3.分多叉
在一次读取的一个节点中 放多个排布搜索对象 分多叉 能一次更多对象的排布完、一次更多对象的搜索完、一次搜索接往到 更加细致确定的 范围区间里来
3.1B树
键值对 单位存储
键值对 合空间 如果很小,节点可以直接 大量存储键值对,每个节点 排布海量N个键值对 N+1次方地 向下分支排布搜索数据 来完成 海量键值对数据的 入树的排布
弊端:
- 存储少-> 排布少-分支少-树高-I/O高
但在数据库中,一个值记录的空间很大,一个键字段的空间很小,键值对的合空间很大:
一个节点一个页的存储量 放不了多几个键值对 排布分叉的,每个节点能存储下来的排布数据少 向下分支少 向下搜索的区间广 ,需要往下分支很多次 才可分布排完数据,树的高度会很高, 处在叶子节点的大部分键值对 要硬盘从顶层 多次读取搜索到底层 才可搜索到,硬盘I/O总体会很高
-
记录在全节点-> 不稳定
作为查询搜索的结果的 键值对里的值记录,与键一块 直接存储在 出现的树节点中,少部分的 在非叶子节点的键值对 可以少量I/O地 往下读取搜索到,大部分的在叶子节点的键值对 需要大量I/O地读取到底层,查询的时间开销不稳定
3.2B+树
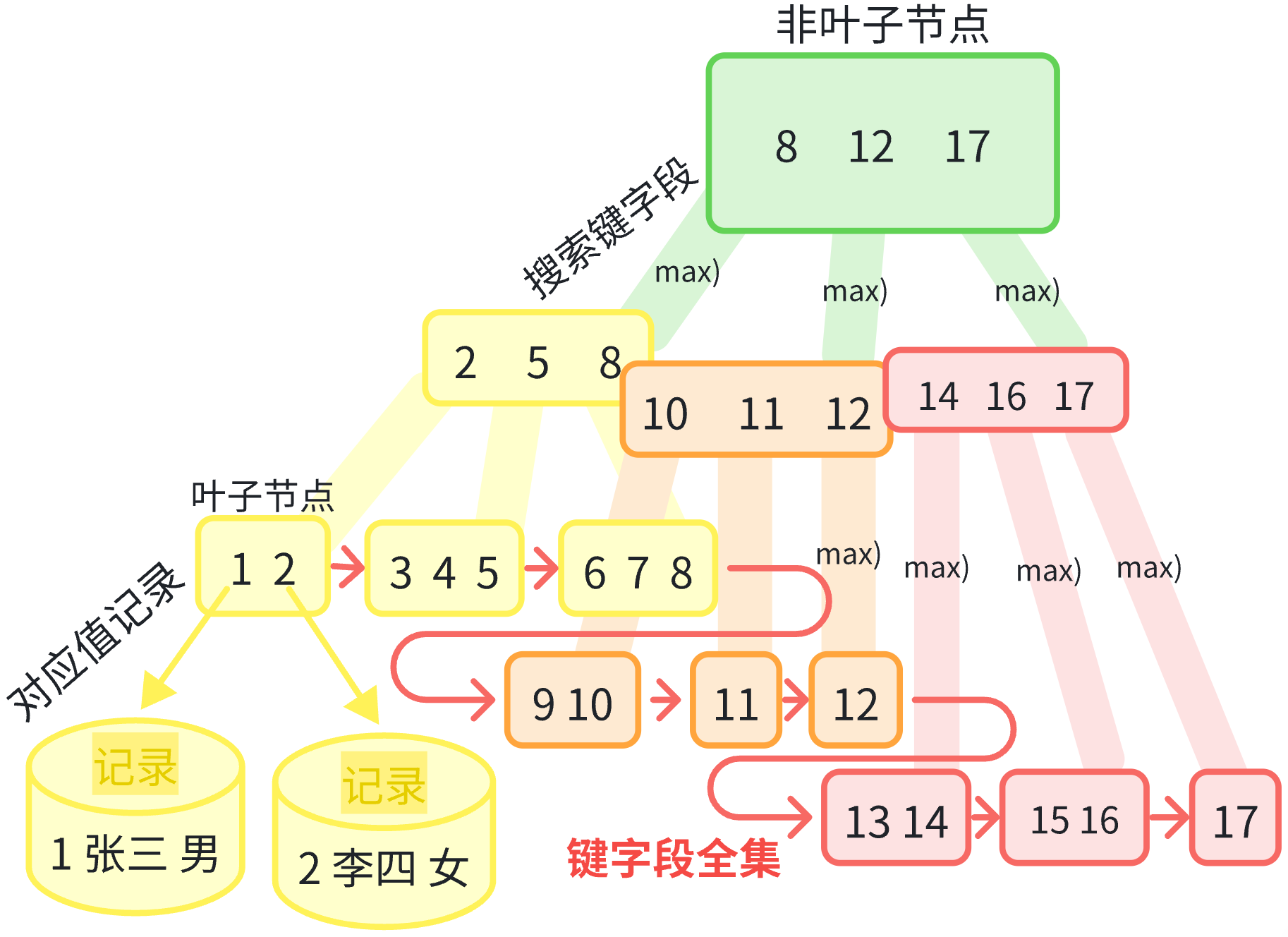
键与值 分开存储
B+树 针对数据库里 值记录空间很大,一个搜索树节点 无法存下过多个键值对 去海量分叉排布,将键与值分开存储,键在非叶子节点搜索,值在叶子节点对应
3.2.1非叶子-搜索字段
3.2.1.1海量分叉
3.2.1.1.1最大式
非叶子搜索阶段 每个非叶子节点 只放无记录值对应的 海量键字段,一个节点一个页 就可最多放 多达1600个键字段地 大量排布搜索数据 细致划出排往范围 地搜索
3.2.1.1.2最快式
内存中 操作数据的速度虽然快,但一次从硬盘读取到内存的数据 如果处理的单位个数过多,一时间内 内存里也无法快速比较完 个数过多的数据,所以每个节点 放1000个键字段 以1000的次方 向下分支排布 存储搜索的数据,3层 对应3次硬盘读取 就可排查地搜索完 分支排布到亿级的 字段量
3.2.1.2缓存内存
3.2.1.2.1字段总量小
非叶子节点内的 亿级总记录个数的 字段量,由于字段的空间很小,能确保 所有全记录对应的 字段总空间 是很小的,况且缓存只对非叶子节点 并未对分支到最后一层的叶子节点 的记录里的 字段量进行缓存,所以非叶子节点里 也不会有 所有记录个数对应的 总字段量 那么多,非叶子节点字段总空间很小 可以缓存到内存中的
3.2.1.2.2时间复杂度
首次查询:
非叶子节点字段量 在首次查询时 B+搜索树高度次硬盘读取 从硬盘 把此搜索树的所有非叶子节点 全部读取加载到缓存中存放
后续查询:
在后续查询时,非叶子节点的字段数据 都已加载在缓存内存中有 不用再硬盘读取 直接继续在缓存中 对字段进行搜索 常数时间,然后搜索出指定叶子节点后 再对存储在硬盘的叶子节点键值对 硬盘读取一次 固定一次硬盘I/O的常数时间,时间复杂度也就成了O(1)
3.2.1.3区间搜索向下保留
3.2.1.3.1过程
非叶子节点的所有键字段 都开区间地隐藏 搜索不到,每次对它们搜索完 都作为查询的 可能的结果键 以子区间最大值的形式 往搜索子区间的N叉区域 分别向下传递
3.2.1.3.2模式
形成了非叶子节点的 只往区间搜索键、键字段数据向下保留传递的 搜索模式
3.2.1.3.3效果
到叶子节点时 整棵树所有出现过的 父节点区间键 与整棵树在叶子节点 最后剩余出的区间键 会构成整棵树的 从左往右有序的 键字段全集
3.2.2叶子-对应记录
3.2.2.1全集键值对
叶子节点层,键字段全集的叶子节点 对应存上值记录 成全集的键值对
3.2.2.2链表物理连续
叶子节点之间 再左右相连地 连接成链表 使搜索树逻辑上的有序 再套上了 物理相邻存储的有序,大大优化了磁盘I/O
3.2.2.3开键稳定查询
B+搜索树都是在叶子节点闭键,键在叶子节点时 才可以去搜索查询到的,查询 会在且只能在 叶子节点搜索查询到,固定了查询的时间开销
二、索引的操作
1.查看
show index from tb_name;查看表中所有的索引
2.创建
create index idx_name on tb_name(col);为表的指定列字段创建索引 ,primary key、unique、foreign key字段 在创建表时 就会自动创建出索引维护
2.1创建时机
在表创建数据空时 或在表的数据量较小时 就要将 要创建的索引创建好
2.2大表索引的创建
2.2.1直接创建过程
为一个记录量很大的表 创建指定字段的索引
第一层:
从创建的 第1个顶层根节点出发,每个节点里面 都有存储1000个字段
第二层:
第二层 为第一层根节点里面存储的1000个排布键 分出的1000个字段区域 往下为每个区域 分叉都创建一个 对分到的区域再次存储有1000个排布键的 排布划分的节点,因此第二层就共创建了1000个节点
第三层:
第三层 为第二层的1000个节点 每个节点 都会分叉1000个区域 每个区域 对应去创建存储有1000个排布值的 1个节点,第三层就会总共去创建1000*1000个节点
第四层:
再往下层就会去创建1000*1000*1000个节点
第N层:
以1000的次方量 往下创建节点,直到叶子所有节点 总共存储的字段 覆盖字段全集时,该字段的B+搜索树 才创建好
2.2.2危险性
工作量巨大,会使服务器 一时间全盘去创建索引的B+搜索树 而呈挂机状态
2.2.3正确创建做法
如果就要为一个海量数据的表 创建索引,正确的做法是:
- 在另一个mysql服务器上 创建相同结构的空表 创建索引
- 再将数据 控制量地 可正常维护索引地 导入建树,B+搜索树创建好索引创建好后
- 最后对服务器更换转到使用 此索引创建好的 mysql服务器
3.删除
drop index idx_name on tb_name;删除表中的指定索引