大模型-attention汇总解析之-NSA
NSA(Native Sparse Attention)是一种新型的稀疏注意力机制,于2025年2月16日由DeepSeek发布。旨在解决长上下文建模中的效率问题,同时保持模型能力。通过结合算法创新和硬件适配优化,实现了高效的长上下文建模。
算法核心优化点:
-
动态分层稀疏策略: NSA采用了一种动态分层稀疏策略,结合了粗粒度token压缩和细粒度token选择,以保留全局上下文感知和局部精度。
-
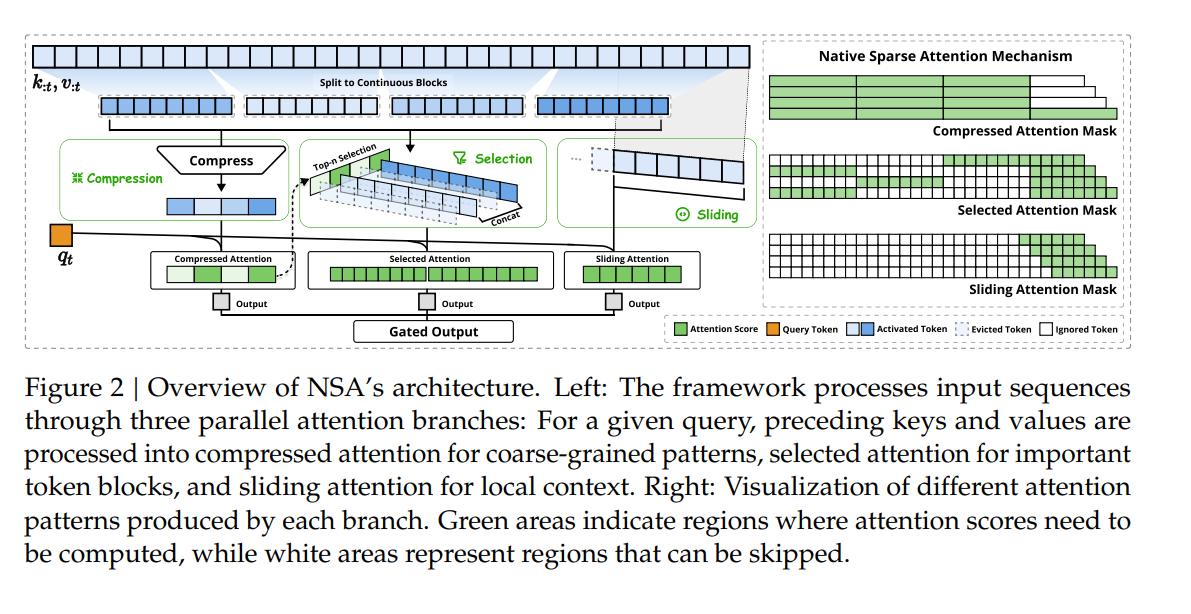
融合三种注意力路径:
-
压缩注意力:通过沿seqlen维度分块减少计算量,同时保留全局上下文信息,降低计算负担。
-
选择注意力:在压缩注意力之后,选择关键块中的k和v和q进行attention计算,保留细粒度的信息。且进一步减少计算量,同时保证局部精度,保留重要性得分最高的 n 个稀疏块中的 token,并参与注意力计算.
-
滑动窗口注意力:处理局部上下文信息,确保模型能够学习局部模式。
-
可训练的架构: NSA采用可训练的算子,能够在训练过程中动态学习最优的稀疏模式,从而在保持模型性能的同时,降低训练成本。
1. 滑动窗口模块
它处理的是输入序列的局部上下文,通过滑动窗口的方式对序列进行处理,捕捉局部上下文信息,防止局部模式干扰其他分支学习,增强模型对长序列的适应性。 通过三个模块分别输出三种attention,获取得到三种k,v,q 之后,按照如下公式计算,进行组合输出。
2.压缩注意力
压缩模块: 将输入的k, v块进行压缩处理,得到压缩后的键值对。压缩的目的是减少计算量,用更紧凑的表示来替代原始的kv对。具体压缩的方法见如下公式:
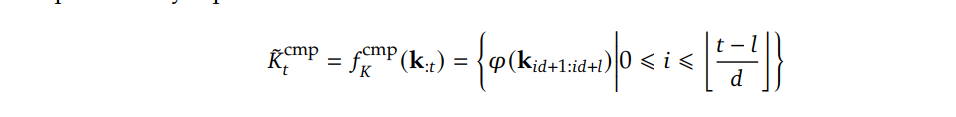
3. 选择模块
在压缩模块的右侧,有“Top-n Selection”,即从键值对块中基于重要性分数选择出前n个重要的块。被选中的块会进行拼接操作。 具体操作如下:先计算每个块的重要性分数,其实就是刚刚聚合过的k向量和q向量进行注意力分数的计算, 然后根据注意力分数选择前n个重要的块。
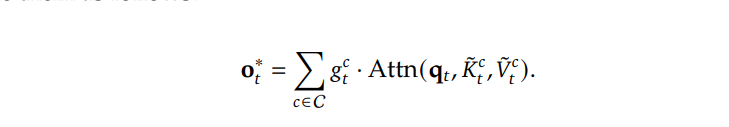
硬件优化:
-
NSA通过Triton实现了硬件优化的稀疏注意力内核,利用了现代GPU架构的特性,例如Tensor Core和连续块访问,以实现高效的计算。
-
参考 FlashAttention v2内外循环硬件加速技术思路,优化块状稀疏注意力以利用Tensor Core并访问内存,确保平衡的算术强度。
-
Triton是由OpenAI开源的高效编译器和编程框架,主要用于加速GPU上的深度学习模型的张量运算。与CUDA不同,Triton旨在让研究者和工程师在不深入了解GPU体系结构的情况下编写高效的GPU代码。
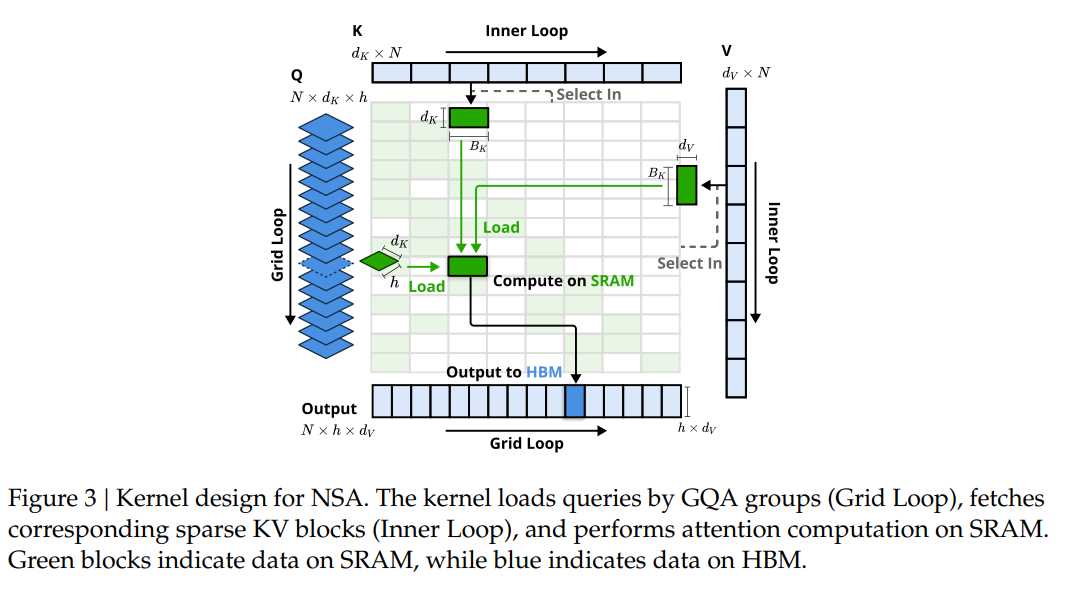
NSA的内核仍然和flash attention一样,将时间上连续的查询块加载到静态随机存取存储器(SRAM),关键就在于使用了一种不同的GQA策略:对于查询序列上的每个位置,将GQA组内的所有查询头(它们共享相同的稀疏kv块)加载到SRAM中,主要有以下三个关键特征:
-
以group为中心的数据加载,对于每个inner loop,加载组内所有的Q以及它们共享的稀疏kv块。
-
共享kv获取,按顺序将连续kv块加载到SRAM中,避免重复的kv获取
-
基于网格的外循环,由于不同查询块的内循环长度(与所选块的数量n成正比)几乎相同,将output和Grid Loop放入Triton的网格调度器中,以简化和优化内核。