主流 AI IDE 之一的 Windsurf 使用入门
一、Windsurf 的常见入门界面
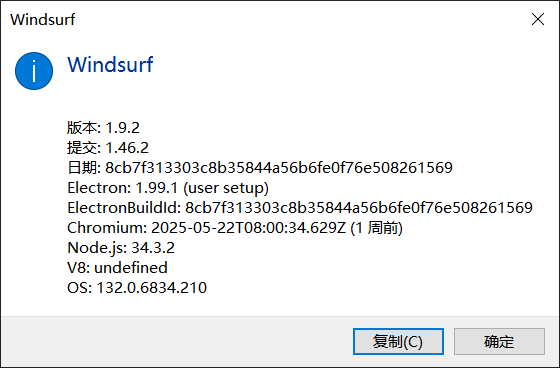
以上是本次展示Windsurf版本信息。
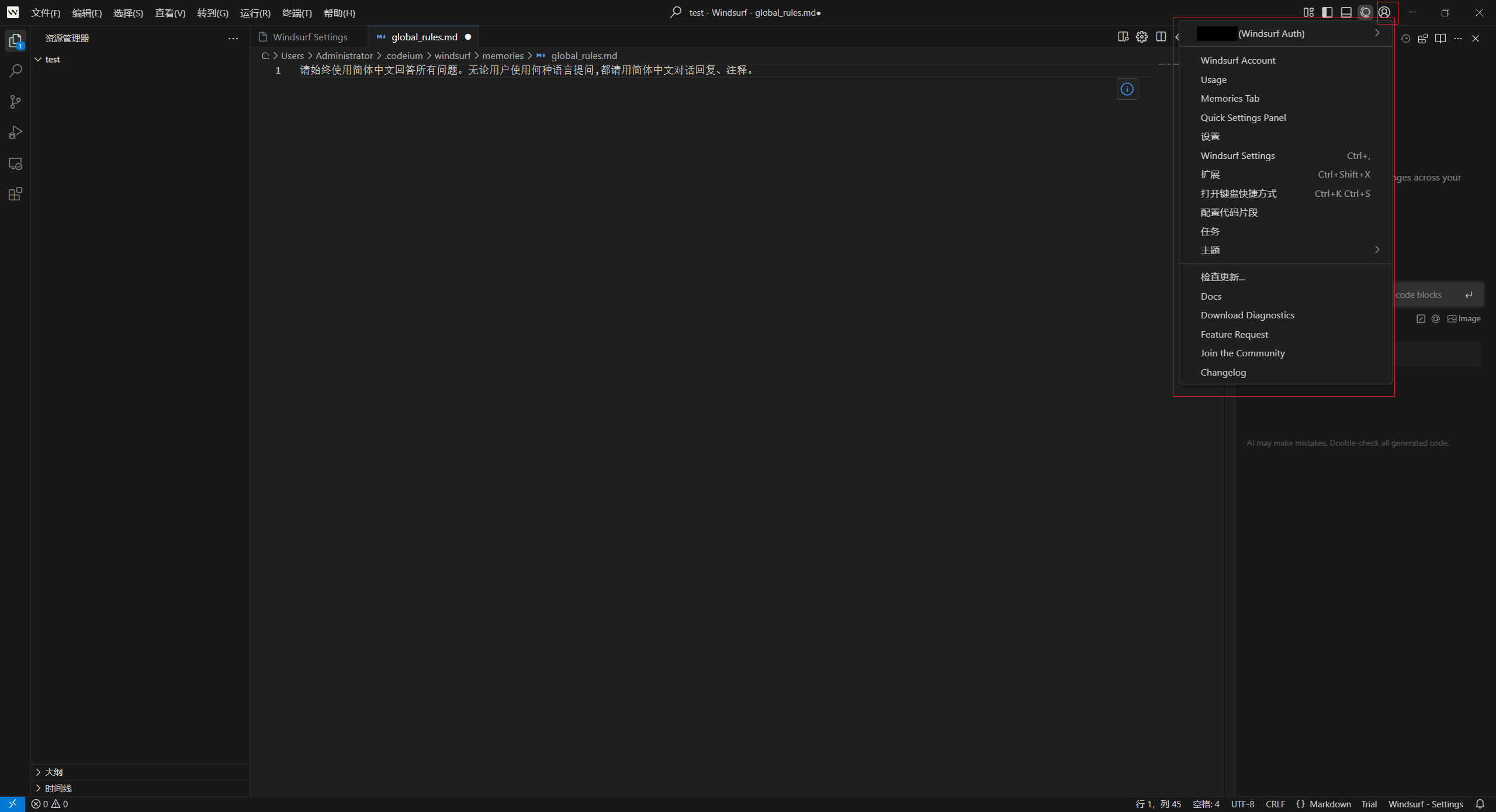
1.1 个人配置中心
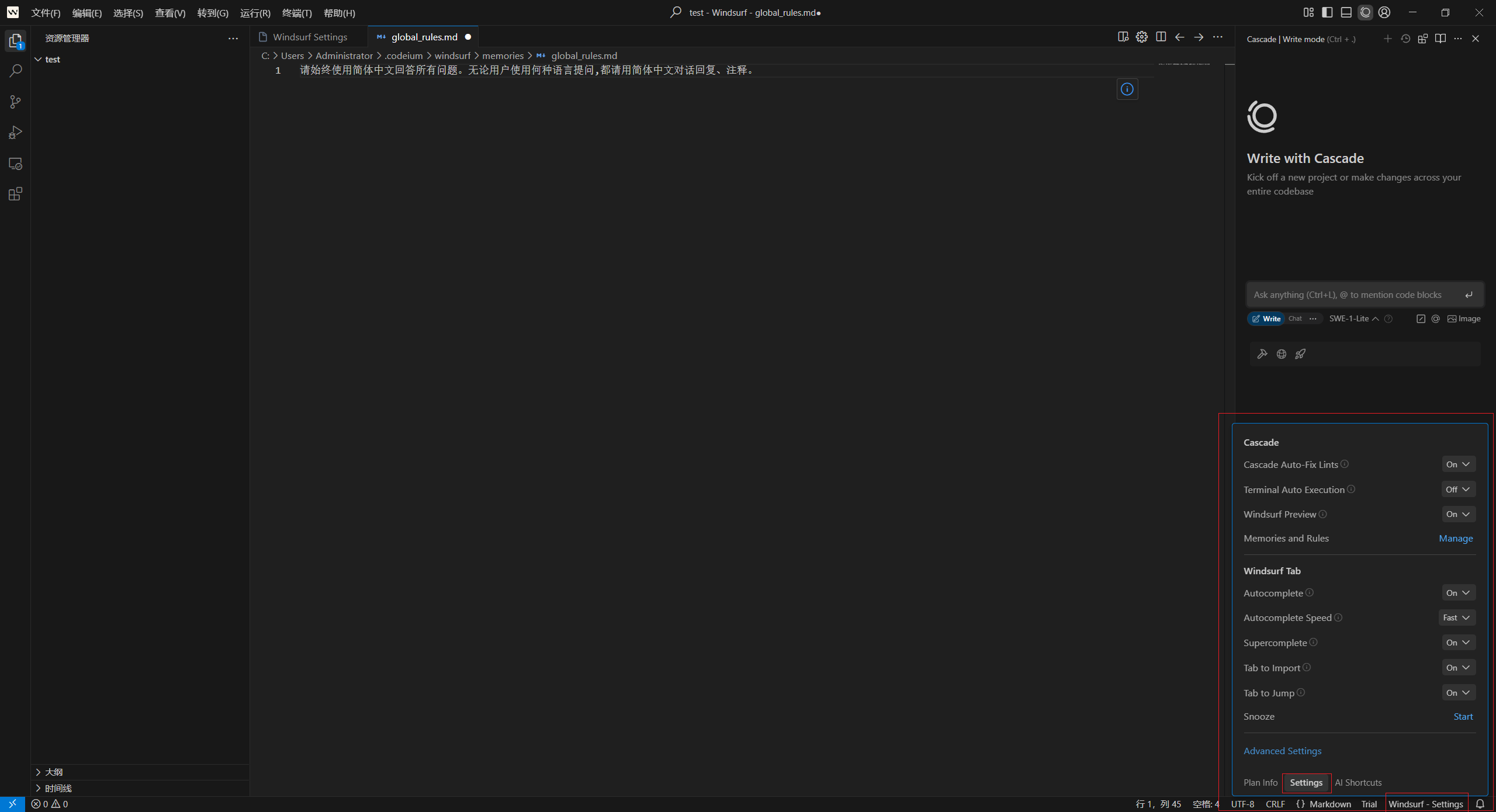
1.2 AI 助手快捷设置
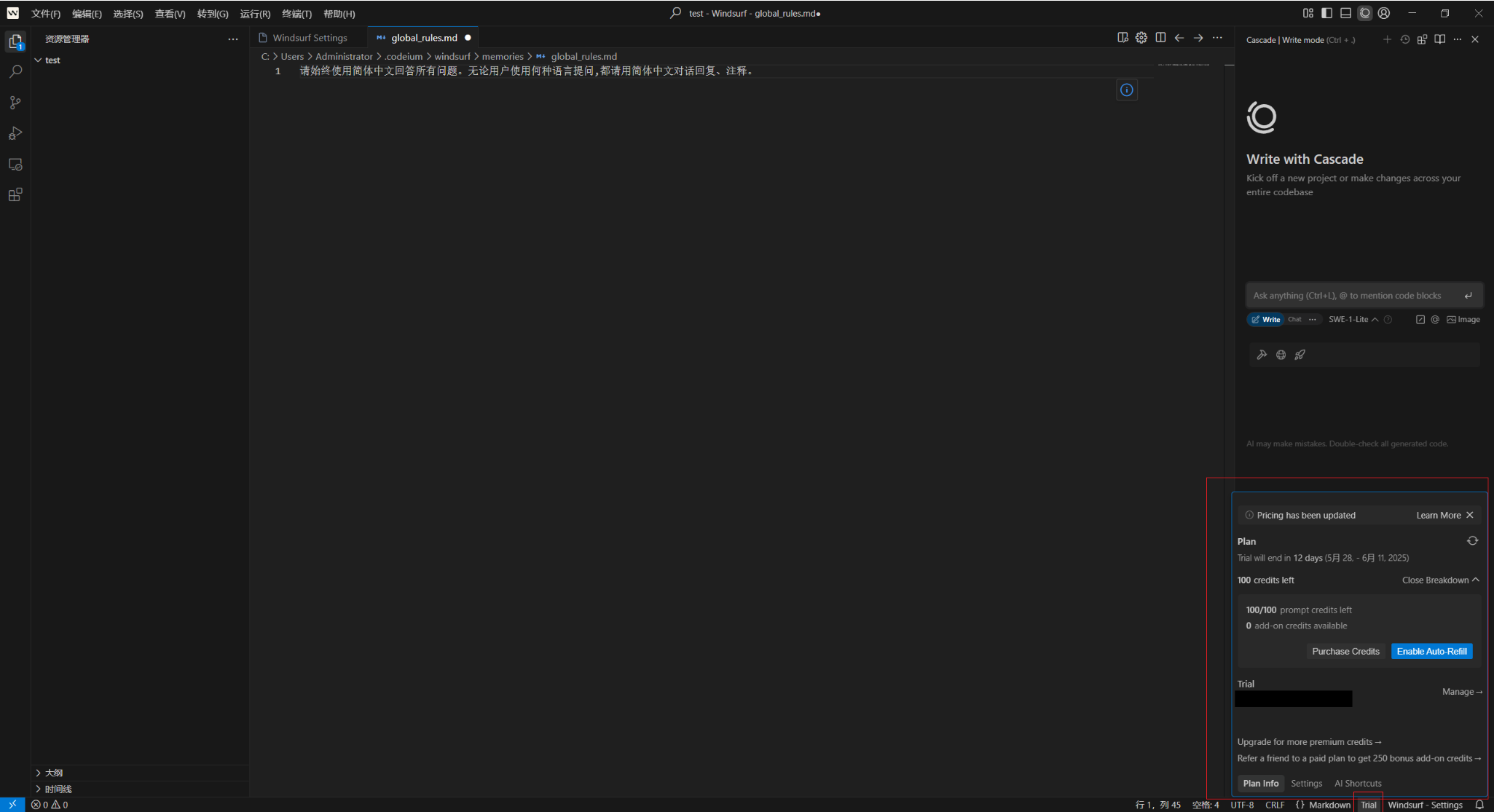
1.3 使用额度查看页面
1.4 智能助手
Windsurf 编辑器中 AI 助手名称 :Cascade 。打开 Cascade 窗口,开始聊天就可以了。方框里有写和聊两种状态锁定模式。
写就是,AI 自动帮你写程序,自动创建文件,自动 Debug,全程你点同意或者拒绝就可以了。
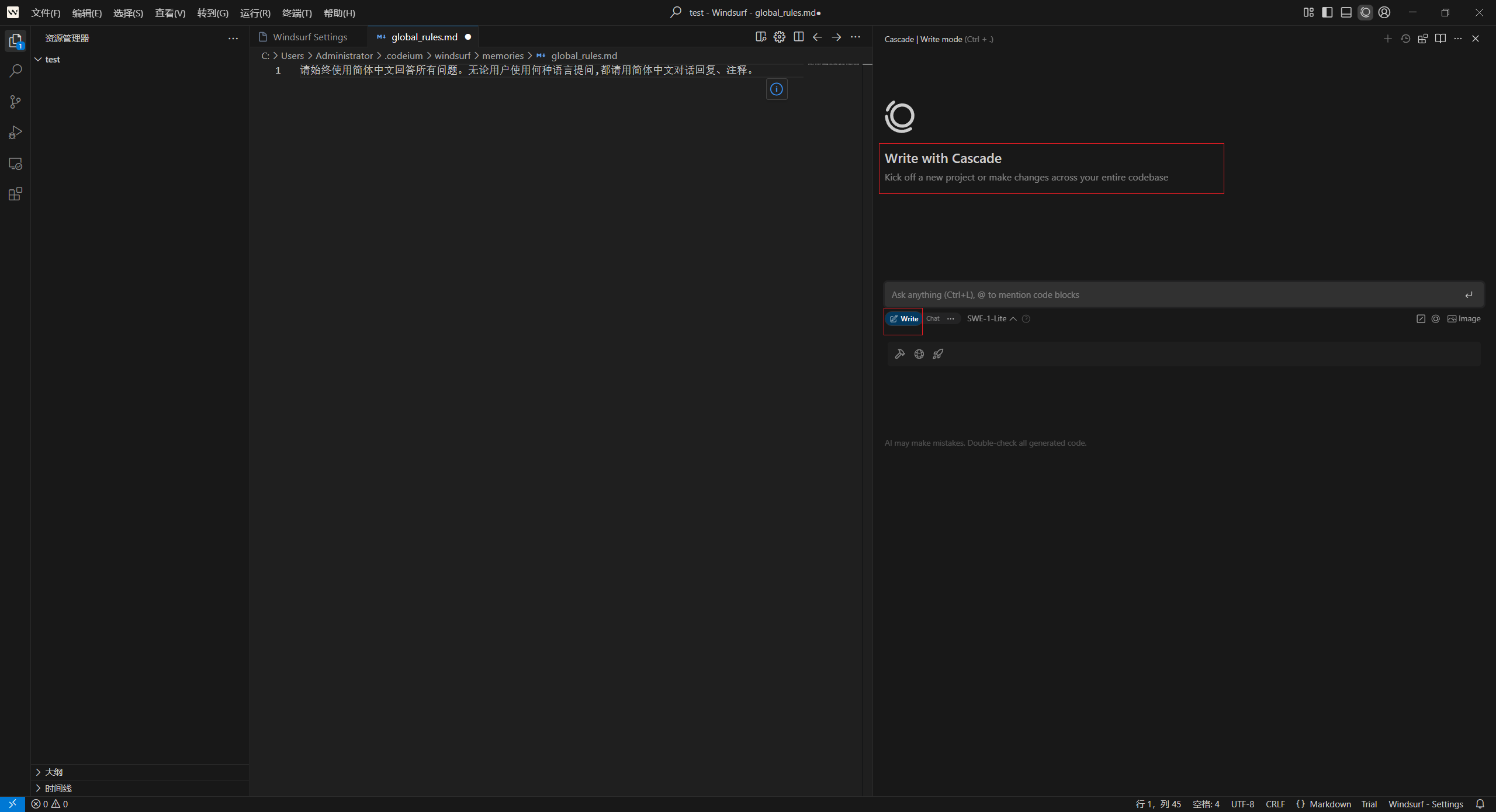
聊就是沟通交流,像 AI 助理一样,可以讨论代码,可以当 Claude 使用。如果输出中中断,取消输出,在对话框打两个字“继续”,让它继续输出就可以了。
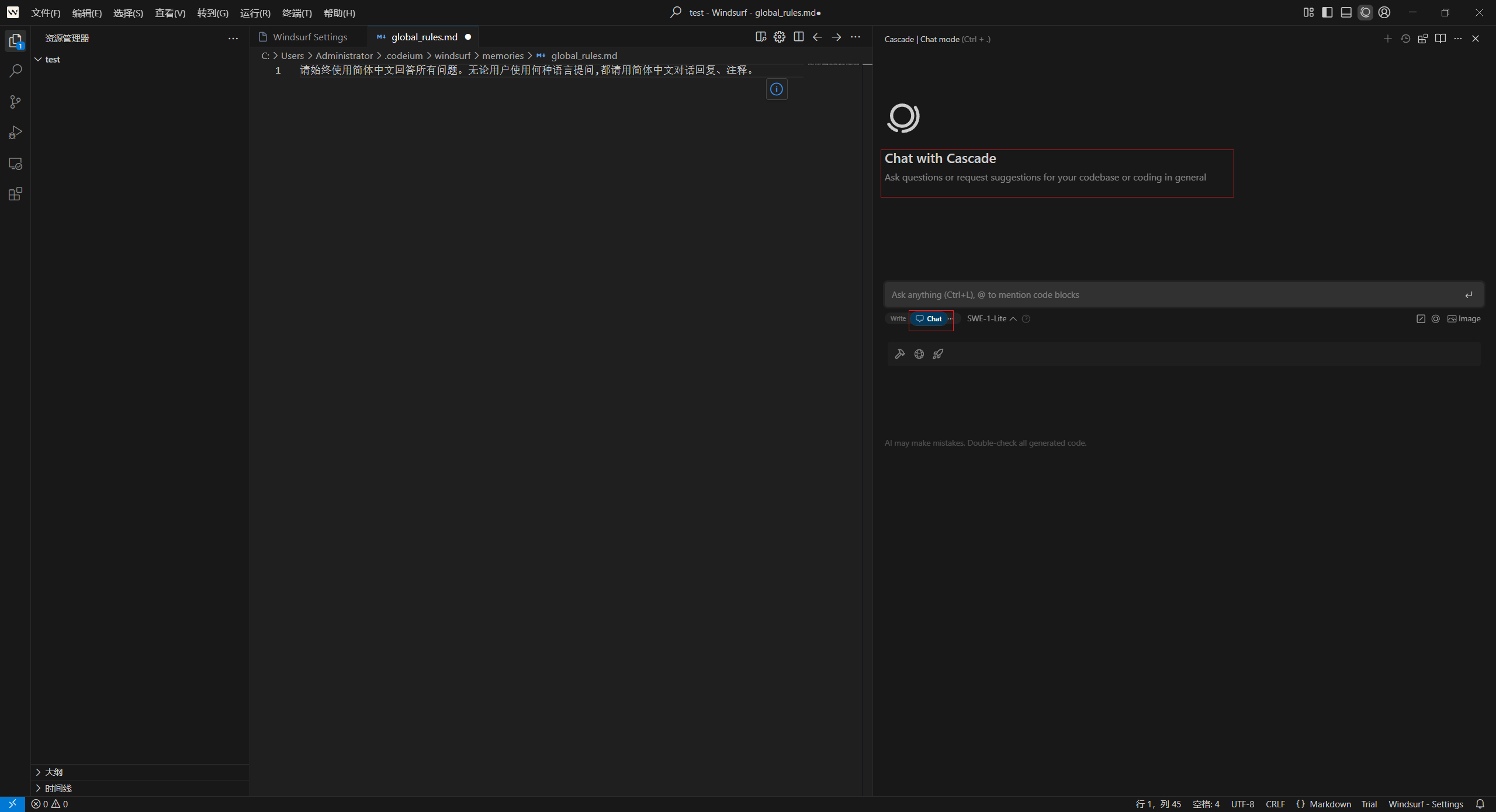
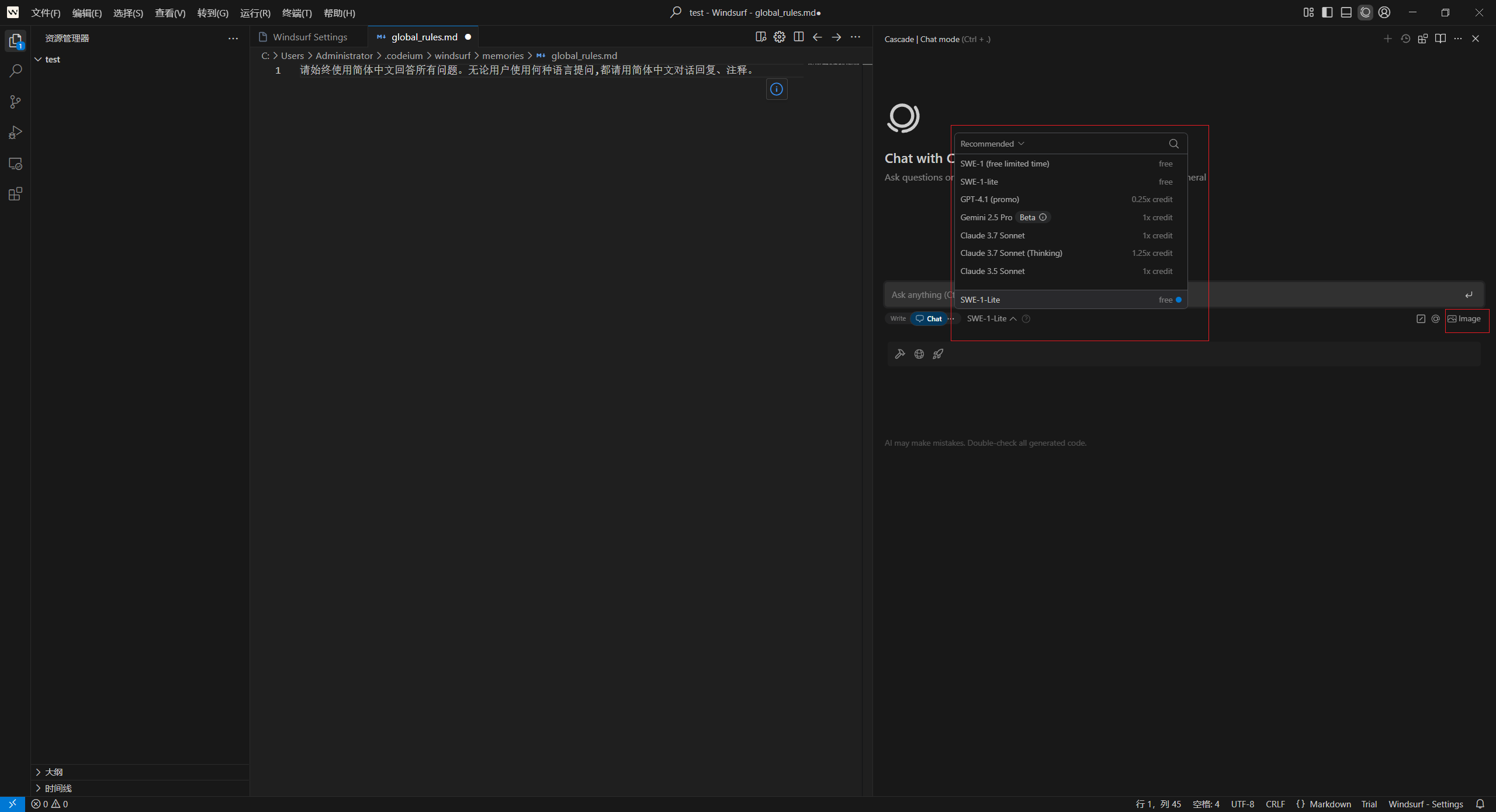
这个版本还有一个Windsurf 的“Legacy Mode”(传统模式),我其实更喜欢称之为:节能模式。仅在需要基础问答、且不依赖实时数据/多轮对话的场景下启用此模式。

1.5 图片上传(Image Upload)
将图片添加到提示中,以便在Cascade的建议中引用。例如,Figma 设计的截图、线框图等等都可以!这种模式目前适用于 Claude 3.5 Sonnet 等型号的多模态大模型。只需拖动或粘贴图像,单击输入文本框下方的“添加图像”按钮即可将其包含在对话的消息上下文中。
二、Windsurf 的常见入门操作
2.1 互联网与文档搜索
Cascade 现在可以直观地解析和分块网页和文档,为模型提供实时上下文。理解此功能的关键在于,Cascade 会像人类一样浏览互联网。
最快捷的入门方法是在编辑器右下角的“Windsurf 设置”中激活网页搜索功能。也可以通过以下几种不同的方式激活此功能:
(1)提出一个可能需要互联网的问题(例如“React 最新版本有什么新功能?”)。
(2)用于@web强制进行文档搜索。
(3)用于@docs查询我们确信可以高质量阅读的文档列表。
(4)将 URL 粘贴到您的消息中。

2.2 记忆 (Memories)与规则(Rules)配置
在 Windsurf 中,同样有两种机制用于跨对话共享和持久化上下文:
1、记忆 (Memories),由 Cascade 自动生成;
2、规则 (Rules),由用户在工作区和全局级别手动定义;
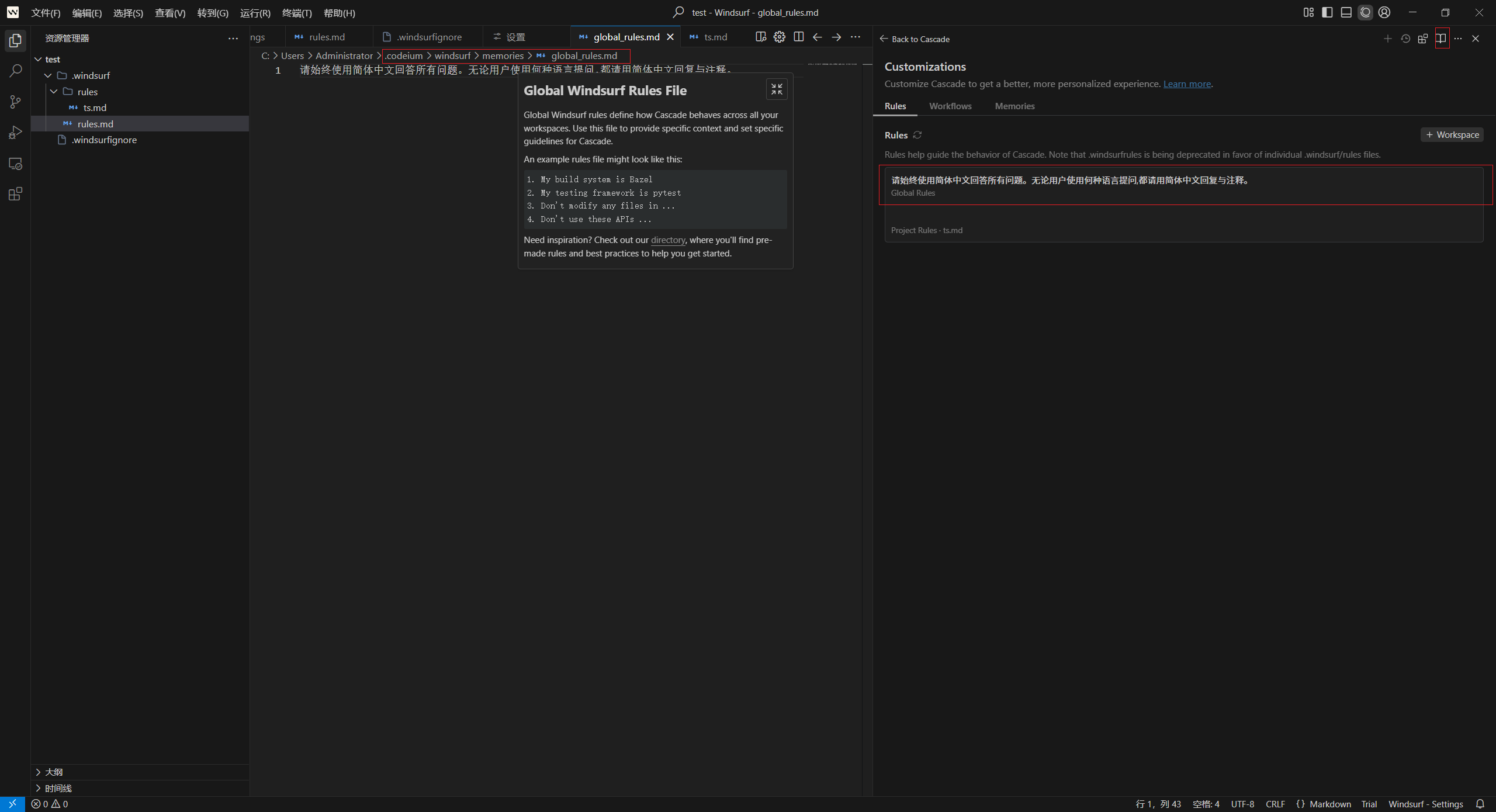
全局级别:~/.codeium/windsurf/memories/global_rules.md;
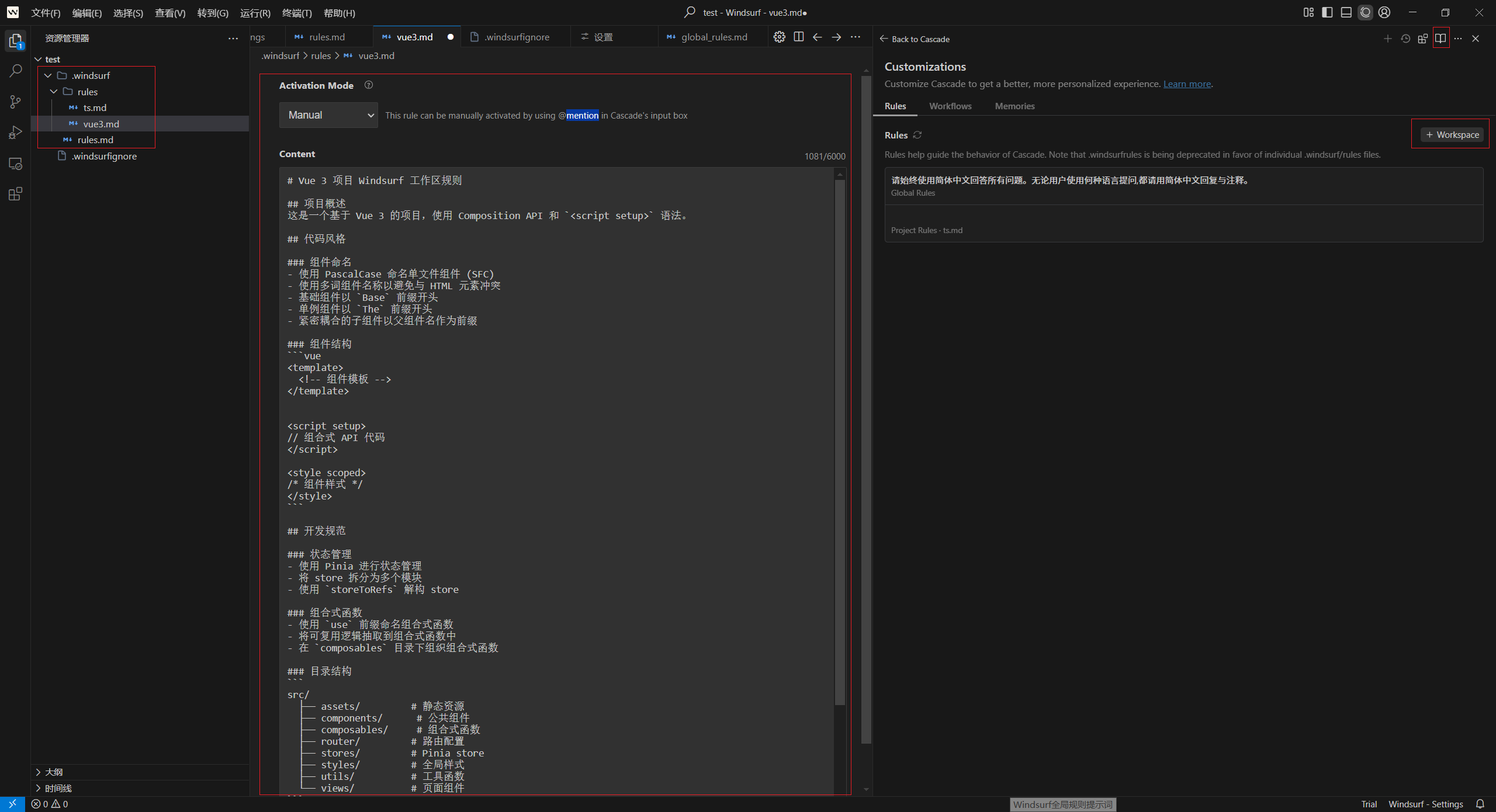
工作区级别:以 Markdown 文件的形式保存在 .windsurf/rules/ 目录中,终于从 .windsurfrules 单文件形式进化到“多文件+可视化”配置了。
规则文件内容有长度限制,单个规则文件不超过 6000 字符,多个规则文件总共不超过 12,000 个字符。
激活模式:
1、Manual:手动,特定领域规则,在对话提示词中通过 @rules 选择规则;
2、Always On:始终开启,工作区全局类规则;
3、Model Decision:模型决策,基于用户定义的自然语言描述,由模型决定是否应用此规则,在 Cursor 中叫“Agent Requested”;
4、Glob:基于用户定义的 glob 模式匹配规则,例如 .tsx,src/**/.ts,按语言类型、特定目录和文件匹配;在 Cursor 中叫 Auto Attached。
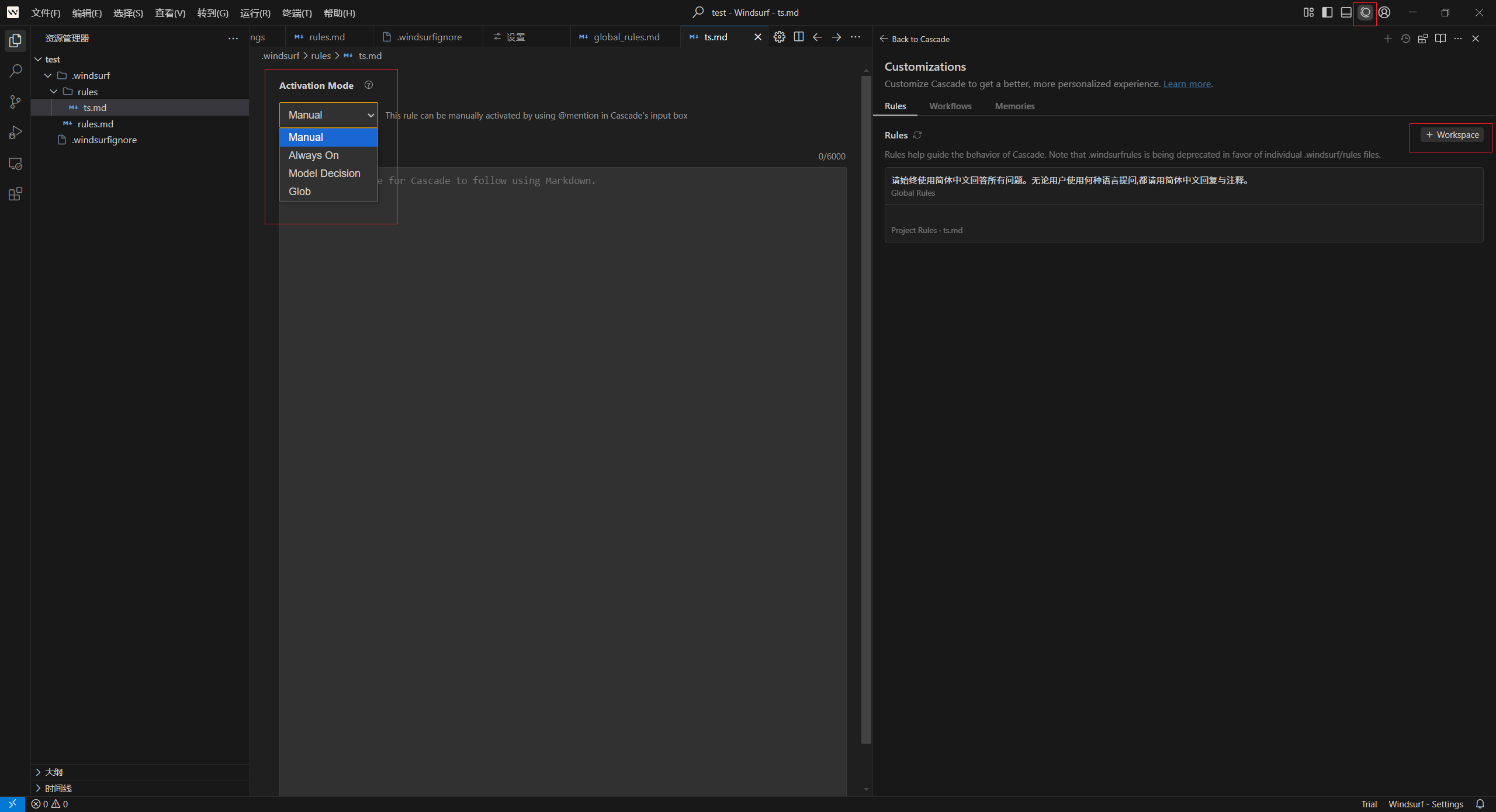
配置全局级别规则示例:
配置当前项目工作区局部级别规则示例:
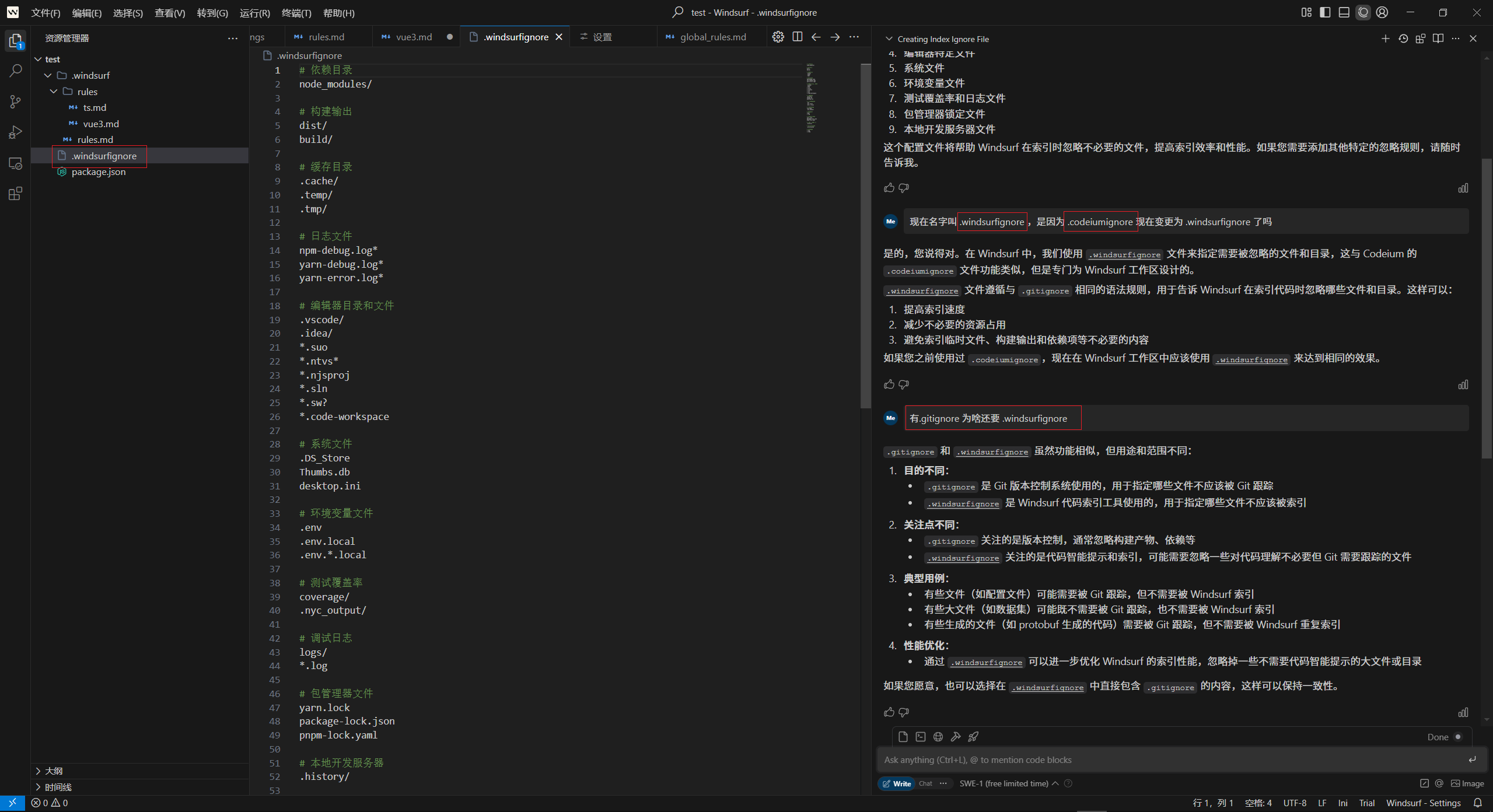
2.3 本地索引 (Local Indexing)
为了代码感知对话、自动补全,Windsurf 会索引工作区。
索引消耗一部分 CPU 资源。
索引需要 RAM (对于包含 5000 个文件的工作区,大约需要 300MB)。
对于拥有约 10GB RAM 的用户,Windsurf 建议将“Max Workspace Size (File Count)”设置不超过 10,000 个文件。
支持在工作区根目录通过 .windsurfignore 或 .codeiumignore 声明忽略索引文件,与 .gitignore 语法相同,默认忽略 .gitignore 中声明的文件夹和文件。
2.4 工作流程(Workflows)
工作流允许我们定义一系列步骤,指导 Cascade AI 助手执行重复性任务,如服务部署、代码评审;工作流以 Markdown 文件的形式保存在 .windsurf/workflows/ 目录中,通过 /[name-of-workflow] 触发。保存后,可以通过斜线命令在 Cascade 中调用工作流:
/address-pr-comments
这是我们团队内部用来处理 PR 评论的工作流程。/git-workflows
使用预定义格式提交并使用适当的 CLI 命令创建具有标准化标题和描述的拉取请求。 /dependency-management
根据配置文件(例如 requirements.txt、package.json)自动安装或更新项目依赖项。 /code-formatting
在文件保存时或提交之前自动运行代码格式化程序(如 Prettier、Black)和 linters(如 ESLint、Flake8),以维护代码风格并尽早发现错误。 /run-tests-and-fix
运行或添加单元或端到端测试并自动修复错误,以确保提交、合并或部署之前的代码质量。 /deployment
自动执行将应用程序部署到各种环境(开发、暂存、生产)的步骤,包括任何必要的部署前检查或部署后验证。 /security-scan
作为 CI/CD 管道的一部分或按需集成并触发代码库上的安全漏洞扫描。工作原理:
规则通常通过在提示级别提供持久、可重复使用的上下文来为大型语言模型提供指导。
工作流通过在轨迹级别提供结构化的步骤或提示序列来扩展这一概念,引导模型完成一系列相互关联的任务或操作。
要执行工作流,用户只需使用/[workflow-name]命令在 Cascade 中调用它。
可以在工作流中调用其他工作流!
例如,/workflow-1 可以包含“调用 /workflow-2”和“调用 /workflow-3”之类的指令。
调用时,Cascade 会按顺序处理工作流中定义的每个步骤,按照指定的方式执行操作或生成响应。
创建工作流程示例:
要开始使用工作流,请点击CustomizationsCascade 右上角滑块菜单中的图标,然后导航到Workflows面板。在这里,您可以点击+ Workflow按钮来创建新的工作流。 工作流以 markdown 文件的形式保存在存储库根目录中.windsurf/workflows/,包含标题、描述和一系列步骤,以及 Cascade 要遵循的具体说明。

2.5 模型上下文协议(MCP)
MCP(模型上下文协议)是一种允许 LLM 访问自定义工具和服务的协议。MCP 客户端可以向 MCP 服务器发出请求,以访问其提供的工具。Cascade 现在已与 MCP 原生集成,允许您选择自己的 MCP 服务器供 Cascade 使用。
Windsurf 中叫“Plugins”,在 ~/.codeium/windsurf/mcp_config.json 文件中全局配置,JSON 文件遵循与 Claude Desktop 配置文件相同的模式,建议可视化配置,因为有提供“禁/启用服务、输入认证/资源路径,查看/禁/启用工具”等操作视图;Cascade 侧边面板顶部 Plugins 工具栏。
Cascade 作为 MCP Client 选择和请求 MCP Servers,使 LLMs 能够访问自定义工具和服务。
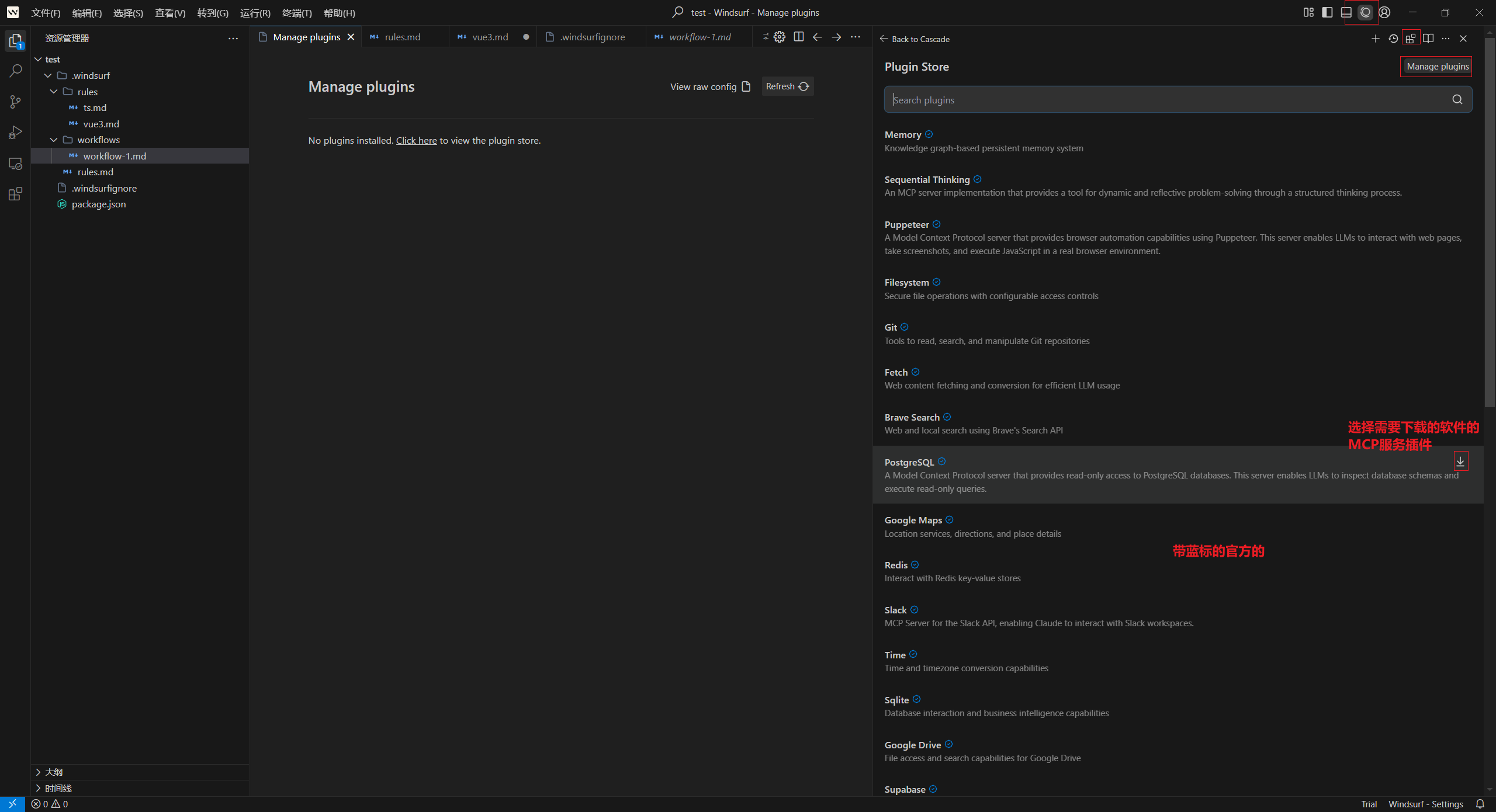
添加新的 MCP 插件后,请确保按下刷新按钮。官方 MCP 插件将显示蓝色复选标记,表明它们是由母服务公司制作的。
备注:要是安装工具插件或修改配置,导致Windsurf 异常不能启动,比如: “Windsurf failed to start” 等异常不能启动,尝试清除聊天记录然后重启来解决:Windows: C:\Users\<YOUR_USERNAME>\.codeium\windsurf\cascade;Linux/Mac: ~/.codeium/windsurf/cascade。--------------------------------------
没有自由的秩序和没有秩序的自由,同样具有破坏性。

————————————————