Linux之文件进程间通信信号
Linux之文件&进程间通信&信号
- 文件
- 文件描述符
- 文件操作
- 重定向
- 缓冲区
- 一切皆文件的理解
- 文件系统
- 磁盘物理结构&块
- 文件系统结构
- 软硬链接
- 进程间通信
- 匿名管道
- 命名管道
- system V共享内存
- 信号
文件
首先,Linux下一切皆文件。对于大量的文件,自然要先描述再组织把它们管理起来。
文件描述符
fd,file descriptor,即文件描述符是操作系统用来标识一个打开的文件,方便对其做管理的一种描述方式。每一个进程打开的一个文件/IO资源,系统内核都会分配一个fd来标识它(取一个最小的未使用的fd),如此在os和进程看来没有底层差异,全是文件,全通过文件描述符来标识并操作。文件被描述好了,接下来只需用数组组织起来即可。
文件操作
文件操作的系统调用有open,close,read,write。
| 函数 | 参数 | 返回值 | ||
| open | const char* pathname | int flags | /*mode_t mode*/ | int |
| 绝对/相对文件路径 | O_RDONLY/O_WRONLY/O_RDWR+O_CREAT/O_TRUNC/O_APPEND… | 文件属性,如果新建 | 文件描述符 | |
| close | int fd | int | ||
| 文件描述符 | 0成功,-1失败 | |||
| read | int fd | void*buf | size_t count | ssize_t |
| 文件描述符 | 用户自定义的输入缓冲区 | 读入的最大字节数 | 读到的字节数 | |
| write | int fd | void*buf | size_t count | ssize_t |
| 文件描述符 | 用户定义的输出缓冲区 | 写出的最大字节数 | 写出的字节数 | |
重定向
重定向符的其他用法,n>a.txt 将n号fd重定向到a.txt;&>a.txt 将1、2号fd重定向到a.txt;n>&m 将n号fd重定向到m号fd对应文件。追加同理。
原理,文件描述符分配规则是取最小可用编号开始分配,而os会在进程启动时自动打开0、1、2分别对应标准输入、标准输出和标准错误。至此,原理已出。比如输出重定向,通过close(1)关闭标准输出,再打开一个新文件,os会分配给它1号fd,于是往1号fd里输入的内容就进入了新文件里。
c语言头文件<stdio.h>里定义的stdin、stdout 和 stderr都是FILE类型结构体,里面既封装了fd,也维护了下面要说的语言层缓冲区。比如stdin里面必然有一个变量保存fd也就是1,这样调用fprintf之类库函数时才能在调用write时传入fd参数(IO库函数都封装了上面提到的4个系统调用)。也正因如此,printf使用stdout作为输出流,重定向后,printf往1号fd文件写入时就往新文件里而非标准输出写了。
dup2系统调用
| 函数 | 参数 | 返回值 | ||
| dup2 | int oldfd | int newfd | int | |
| 文件的源fd | 文件的目的fd | 成功返回新fd,-1错误 | ||
int dup(int oldfd);将oldfd对应文件映射到最小未使用的fd的位置,功能没有dup2强大。int dup3(int oldfd, int newfd, int flags);多了flags参数,此处用不到,自行了解吧。
缓冲区
分为操作系统层,语言层和用户层。现实生活中,缓冲区的存在多是为了减少等待时间或运输时间,从而提高效率。
- 操作系统级别的缓冲,分为页面缓存(Page Cache)和套接字缓存(Socket Buffer)。前者是在内核当程序读取文件时,操作系统会将文件内容的一部分或全部加载到内核空间的内存中的页面缓存;当程序写入文件时,数据首先被写入页面缓存,采取一定策略,比如写满了,再刷新到磁盘。后者在网络通信再讲。
可见,高速的CPU读取龟速的磁盘文件时通过页面缓存一次读一批数据,减少了IO次数从而提效。 - 语言层缓冲区,位于用户空间,由语言运行时环境管理。没错,c语言的FILE结构体里就为每一个打开的文件维护了一个缓冲区,并采取一定策略进行刷新。缓冲区类型有三种,全缓冲(Fully Buffered),适用于输出到普通文件,直到缓冲区满或显式调用 fflush() 或关闭文件时才写入磁盘。行缓冲(Line Buffered),适用于标准输入输出,遇到换行符时,缓冲区刷新。无缓冲(Unbuffered),无缓存,立即写入或读取。
刷新方式有三种:1强制刷新,比如fflush,2刷新条件满足,就是上面说的,3进程正常退出时,对于库函数比如exit,会刷新,系统调用如_exit不会;对于信号杀死,取决于信号处理器调用的退出函数。无论哪种,os只会关fd,不管语言层缓冲区,很合理吧。
可见,全缓冲通过一次刷新一大批数据,减少了系统调用的开销和与磁盘等的IO。行缓冲既减少系统调用,又符合人的使用习惯。无缓冲不经过语言层缓冲区直接写入目标文件,少了一次拷贝,对于少次数、大容量的数据效率高。 - 用户级别缓冲区,是用户自定义的、位于内存的缓冲区。自行了解吧。
一切皆文件的理解
接下来,阐述我对Linux下,一切皆文件的重点关于设备成为文件的理解。注意,以下部分结构体名并非真实对应于Linux内核源码中,请自行鉴别。
- 首先,Linux,把一切可以IO的东西,包括普通文件,目录,IO设备等,分别用对应结构体去描述,比如struct txt,struct dir,strcut device等以及对应操作方法struct file_operations。struct device里面包含了type、status、设备属性信息等,struct file_operations包含该设备的特定开关读写方法,以函数指针形式存放。
- 当打开该设备文件时,先创建一个struct file对象,让其成员struct file_operations *f_op指向设备定义好的操作方法结构体,其他成员填充即可。值得注意的是,成员struct list_head fu_list让所有struct file组织起来了。(struct address_space *f_mapping成员与os的内核缓冲区有关)
- os为打开的该设备文件分配fd,实质是将上面的strcut file*放进对应进程的struct files_struct的struct file * fd_array[ ]里,而它在该数组里的下标就是fd。
综上所述,Linux通过抽象描述非普通文件为file结构体,从而在上层提供了统一的看待方式和操作方法,忽略底层差异,便于统一管理,提高效率。
另一方面,也应了那句话,所有软件的问题,都可以通过加一层软件层来解决。
文件系统
文件系统是os对所有文件的描述方式。下面以ext2文件系统为核。
磁盘物理结构&块
可以自己去网上搜磁盘图片。一个磁盘,由许多盘面组成,盘面上有许多条磁道,不同扇面的同径磁道组成柱面,盘面按圆心角度可分成许多扇区,扇区就是磁盘存储基本单位,这里假设容量512字节,即0.5KB。磁盘是围绕主轴转动的,边上有传动臂,上面的磁头可以在每个盘面的同一扇区同时读写。
CHS定址可确定唯一位置,cylinder柱面,head磁头,sector扇区。
LBA定址,原理是将柱面切开并拼接成一维,以扇区为基本单位组成线性结构,对扇区编号。如此,只要知道每个柱面的扇区个数、每个磁道的扇区个数和扇区号,即可唯一确定位置。
os访问磁盘,以块为单位,常见4KB,因为效率高。
文件系统结构
对于一个磁盘Disk,有多个分区Partition,每个分区有多个块组Block Group。
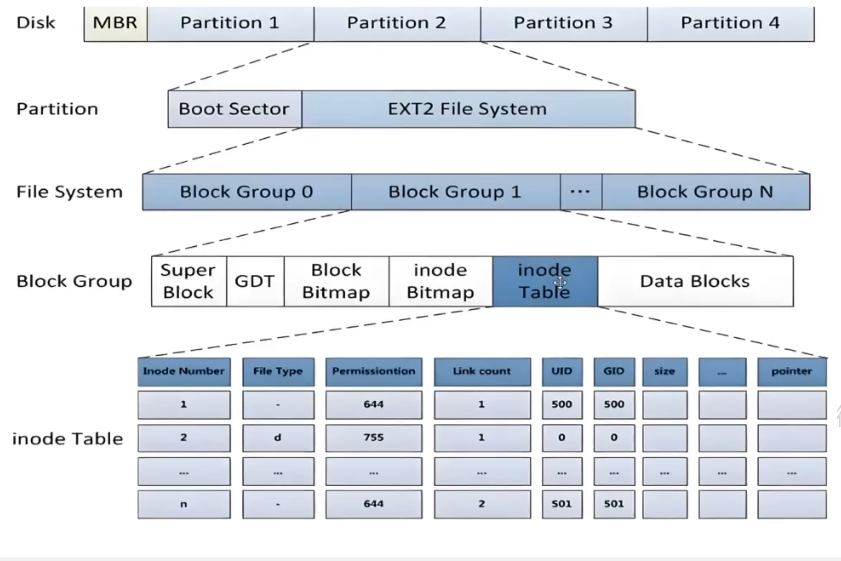
块组内,Data Blocks存储文件的内容。inode Table存文件的属性,类似struct inode描述文件属性,诸如大小、类型,通常一个占128字节。每个文件都有一个inode编号,ls -i查看。
inode Bitmap和Block Bitmap均为位图,用于记录inode和Data是否被占用。
GDT,Group Descriptor Table,块组描述符表,用于记录块组属性信息,比如组内inode Table的位置,空闲inode个数。
Super Block,超级块,存储文件系统的分区结构信息,比如分区内block和inode总量和单位大小及其他重要信息。鸡蛋不要放到同一个篮子里,超级块会在部分快组开头出现,用于备份恢复。
格式化,创建或重新组织文件系统结构,即重写Super Block这种重要块区。
文件系统的载体是分区,所以inode在文件系统中,即分区内唯一。
目录也是文件,它的内容存储它包含文件的inode和文件名映射关系。第一次访问文件时,进程已经拿到文件路径,从根目录层层递进,直到拿到文件inode,这之中,os会创建dentry结构体(在file结构体中)保存每一个文件的inode,并用双向链表串起来,宏观上这些dentry呈树形结构。第二次访问它时,os会先去这个树中搜索它的inode,效率更高。
另外,文件分区在拿到文件路径时就已经确定了,因为分区都会挂载到一个目录上,即建立连接,访问该目录等于访问该分区。
软硬链接
软链接是存储目标文件的路径的文件,有独立inode,类似快捷方式,ln -s file newfile。硬链接与目标文件共享inode,本质是一组新的文件名和同一个inode的映射关系,ln file newfile。ll后第三列数字为硬链接数,类比引用计数,故可用作备份,删除所有指向该inode的文件才会删除磁盘上该文件。
用户无法给目录建立硬链接,但可以建立软链接。前者因为会形成路径环问题,查找等操作会死循环bug,而Linux的.和…作为天然内置的目录硬链接因为符号特殊性和确定性可以避开前面的问题,比如加个if判断;后者因为软链接的类型是l,目录类型是d,可以直接区分。
进程间通信
匿名管道
原理是父进程创建子进程,子与父共享同一个files_struct(内部的引用计数会增加),利用这点,父先创建管道文件再fork,父子就同时打开了这个内存级的“文件”(其实就是os在内存开了一片缓冲区)。具体来说,函数int pipe(int pipefd[2]);传入一个数组,pipe会创建管道文件,并将读端和写端文件描述符放入传入数组中。
利用管道+fork可实现进程池。父进程创建一个管道就fork,父往管道写,子读到就去执行相应任务,而且可以重复上述过程,每一个子进程都有各自与父相连的管道,形成简易进程池。
值得一提的是,管道通信有4种通信情况(1)写慢读快,读端就会阻塞等待(2)写快读慢,写满时写端也阻塞等待(3)所有写关,os检测到没有活跃的写入端存在(即达到EOF条件),则下一次read()调用就会返回0(4)读关,写继续,os会发送13号SIGPIPE信号杀死该进程。可见,管道是有一定同步机制的。且是半双工的,即同一时间双方只能一方发另一方收,而全双工可以双方同时收发。
管道是面向字节流的,它指的是数据被视为一个连续的、无结构的字节序列进行处理或传输。这种模式下,数据没有被分割成固定大小的消息或者包,而是作为一个整体流来进行操作。以后tcp和udp会细说。
命名管道
用于非父子关系的进程间通信的,真实存在的特殊有名文件,它并不存储数据于磁盘,而是遵循FIFO,让数据直接从写进程流向读进程。
既可以在bash用mkfifo+路径创建命名管道,也可以用函数int mkfifo(const char *pathname, mode_t mode);第一个参数是命名管道的相对/绝对路径,第二个是管道的权限模式比如给0666搭配umask。可以用rm也可unlink删除之。
system V共享内存
通过将同一块共享内存段附加或者说映射到自己的进程地址空间的共享区内,实现不同进程看到同一份资源,从而通信。
创建/获取共享内存:int shmget(key_t key, size_t size, int shmflg);key是用户层的用来唯一标识一个共享内存段,让多个进程可以通过它找到并连接到同一个共享内存段。通常由key_t ftok(const char *pathname, int proj_id);传入一个路径名和项目id来产生。size是请求的共享内存大小(字节)。shmflg有IPC_CREAT,该key对应的共享内存段不存在就创建返回,存在就返回;IPC_CREAT|IPC_EXCL,存在就失败返回-1,不存在创建返回;前面二选一再|上权限比如0666。返回值是os为该共享内存段分配的即系统层的唯一标识符,用于后续具体的内存管理操作。
附加/挂接共享内存:void *shmat(int shmid, const void *_Nullable shmaddr, int shmflg);shmid就是os分配的标识符,shmaddr指定共享内存段在进程地址空间中的起始地址。通常设置为 NULL,让系统自动选择合适的地址进行映射。shmflg: 附加标志位(如 SHM_RDONLY 表示只读访问,不设则默认读写附加),通常给0即可。成功返回指向进程地址空间中共享内存段起始地址的指针,失败返回 (void *) -1。
分离共享内存:int shmdt(const void *shmaddr);用于将共享内存段从调用进程的地址空间分离。shmaddr就是shmat返回值。
删除共享内存:int shmctl(int shmid, int op, struct shmid_ds *buf);op是操作命令,通常给IPC_RMID用于删除。buf可以提取出描述共享内存的内核结构体,搭配IPC_STAT选项。下图可见,我们用户层设置的key被记录在了该结构体里面。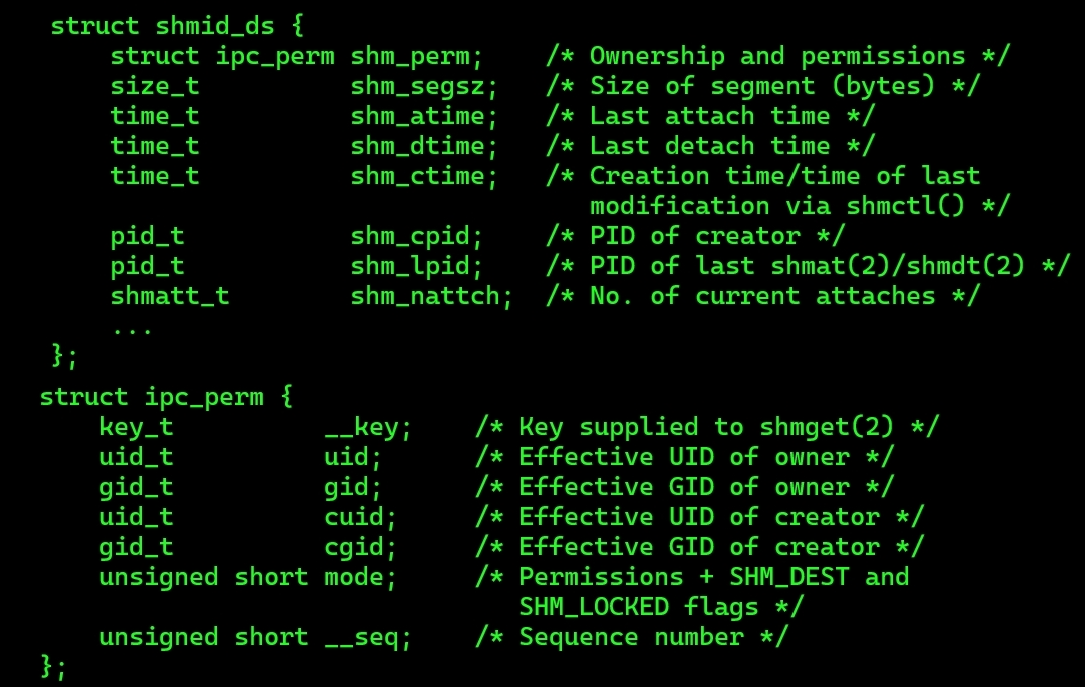
常用的共享内存相关命令:ipcs -m查看所有共享内存段,ipcrm -m+id删除指定id的共享内存段。
鉴于共享内存没有同步机制,只要内存里有数据,就能立刻读上来,目前可以采取写方写完后向命名管道发送数据当作信号,读方收到再开始读取。以后则可以搭配信号量实现同步机制。
标题中system V是一种IPC,inter process communicate标准/机制,除共享内存外,还有system V消息队列和信号量。
system V消息队列是一个内核维护的缓冲区,用于存储由多个进程发送的消息。类比共享内存的概念和接口,每个消息队列都有一个唯一的键值(key)和一个标识符(msqid)。可以用int msgget(key_t key, int msgflg);创建/获取一个消息队列,并用返回的标识符传入int msgsnd(int msqid, const void* msgp, size_t msgsz, int msgflg);向它发送一个消息,其中 msgp指向用户定义的消息struct msgbuf {long mtype;/* message type, must be > 0 * /char mtext[1];/* message data * /};msgsz是正文大小即mtext的大小。用ssize_t msgrcv(int msqid, void* msgp, size_t msgsz, long msgtyp, int msgflg);接收消息。int msgctl(int msqid, int cmd, struct msqid_ds *buf);则类比shmaddr。
消息队列生命周期也是随内核的。ipcs -q可查看该资源,ipcrm -q+id删除。
system V信号量semaphore,是IPC机制,与后面的多线程处的信号量应区分开。信号量本质是一个计数器,用于表示可用资源的数量,所有主体访问临界资源前,都要先申请信号量。此处,将被保护起来的共享资源称为临界资源,多个主体(此处即进程)争夺式申请有限共享资源称为互斥。信号量的P操作指等待/申请信号量,V操作指释放信号量。当然了,信号量也是临界资源,它的安全性由PV操作的原子性保证。信号量创建/获取int semget(key_t key, int nsems, int semflg);nsems是信号量个数。初始化信号量值int semctl(int semid, int semnum, int cmd, … /* union semun arg * /);semnum是信号量集中信号量编号如0,cmd给SETVAL,…传union semun,里面设置val。PV操作int semop(int semid, struct sembuf * sops, size_t nsops);struct sembuf包含unsigned short sem_num; /* semaphore number * /short sem_op; /* semaphore operation * /short sem_flg; /* operation flags * /sem_op给-1+1分别表示PV。
值得一提的是,system V共享内存、消息队列和信号量的结构体都包含key,且key在这三者中唯一。也就是说,os把三者当成同一种资源。怎么做到的?先用统一的struct A(struct ipc_ids)描述所有ipc资源,里面包含一个指针指向struct B(struct ipc_id_ary),B里有一个柔性数组存放开辟的ipc资源结构体头部struct C(struct kern_ipc_perm)指针,前文诸如shmget成功后os分配的id就是它在柔性数组里的下标。柔性数组存放的指针p指向同一种类型struct C,再存放ipc资源结构体类型假设struct shmds,由于每个ipc资源结构体内必须第一个包含struct C作为公共头结构,所以强转后(struct shmds*)p->即可访问对应ipc资源结构体内部所有成员。类比多态。
信号
Linux系统中,信号被分为标准信号前31个和实时信号后31个。我们只关注前面的标准信号。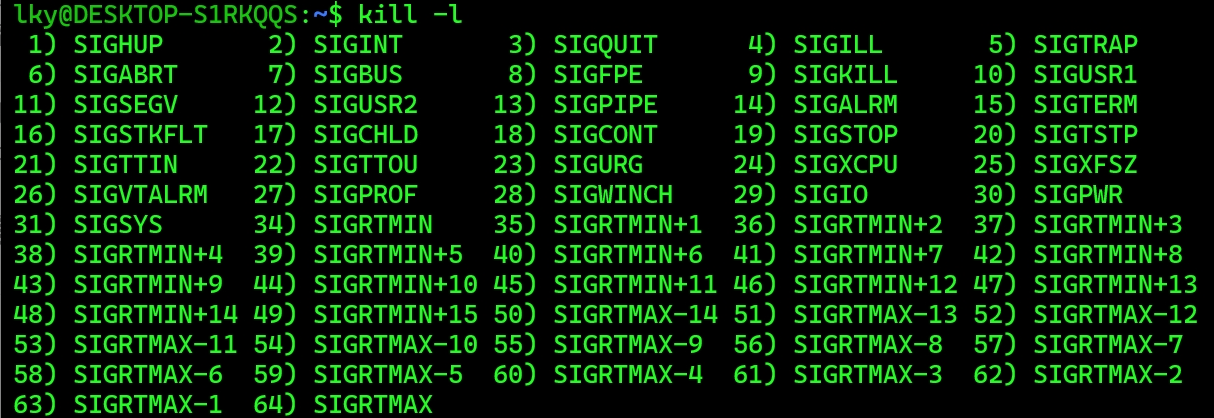
信号的产生方式,通常有键盘组合键,Ctrl+C发送 SIGINT中断进程,Ctrl+Z发送SIGTSTP停止/暂停进程,但可以继续运行,Ctrl+\发送 SIGQUIT请求进程退出,并进行核心转储;系统调用,unsigned int alarm(unsigned int seconds);seconds秒后向该进程发送14号SIGALRM信号,void abort(void);用来终止程序,且忽略下文的信号处理器,int kill(pid_t pid, int sig);向指定进程发送信号,int raise(int sig);向自己发送信号;硬件异常,常见的除0错误和野指针导致的崩溃,硬件检测到异常后通过中断等机制通知CPU,然后操作系统再根据异常类型做出反应,并可能向相关进程发送信号,比如除0发送SIGFPE,float point error,野指针发送SIGSEGV,segmentation fault;内核条件,比如当子进程终止或状态发生变化时,父进程会收到 SIGCHLD 信号,以及写端写入读端关闭,写端收到SIGPIPE。
键盘产生的信号,只能发给前台进程,像./exe运行起来的,占用标准输入的进程。而后台进程,像./exe &运行起来的,虽然能占用标准输出,但不占用标准输入,即键盘。这也是孤儿进程在被领养后成为后台进程,ctrl+c对其无效。
jobs命令查看所有后台任务,fg+任务号可将对应进程转为前台。Ctrl+Z可将进程切换为后台,bg+任务号可让后台任务恢复运行。
信号的处理方式,有默认处理,即os预设的,Core:终止进程并生成核心转储,Term:终止进程但不生成核心转储,Ign:忽略该信号,Stop:停止进程,Cont:继续已停止的进程,信号的预定义默认动作由man 7 signal查看;捕捉/自定义信号处理,通过typedef void (*sighandler_t)(int);sighandler_t signal(int signum, sighandler_t handler);由用户自定义,handler就是自定义处理方法,也可以传SIG_IGN忽略、SIG_DFL默认;忽略处理,除了9号SIGKILL和19号SIGSTOP,其余都可以被捕捉或忽略,而这二者是保证系统安全稳定的一道防线。
alarm函数可以实现定时功能的任务。alarm的原理是,os把系统中许多进程定都闹钟用结构体描述、最小堆组织起来,当时间戳到达堆顶元素定时时间后,执行对应结构体中存储的方法,发送SIGALRM。
core dump是核心转储,操作系统在程序发生崩溃或异常终止时,将该进程在内存中的核心数据从内存拷贝到磁盘,形成一个“核心文件”或“core dump”,通常文件名为core。core dump的一大功能是支持debug,我们运行崩溃后,gdb myexe,core-file core即可查到崩溃行,这就是事后调试。使用ulimit -a查看是否开启核心转储功能,ulimit -c 0禁用它,ulimit -c+非零值,表示最大core大小、单位为字节、比如4096开启它。想永久修改则修改.bashrc文件。但是,大型应用程序的核心转储文件可能会占用大量磁盘空间加上生成核心转储文件的过程可能会消耗一定的时间和资源,通常选择关闭。而之前进程篇提到的wait的status在子进程异常退出时,低8位的最高位为1表示生成core dump。
信号的保存:在信号被进程收到后,信号处递达状态;产生但未递达,处未决状态pending,并在该进程的pending信号位图对应位置置1;如果进程选择对信号阻塞/屏蔽Block,该进程的blocked信号位图对应置1。pending位图、blocked位图和handler位图均存储在task_struct中信号那一部分,前二者用unsigned int的32位存储信号的对应状态,handler存储对应信号处理方法,SIG_DFL就是(sighandler_t)0,SIG_IGN(sighandler_t)1,自定义的话存对应signal传入的handler函数指针。
下面介绍常用关于信号集(sigset_t是信号集,但内部使用位图,此处认为二者等价)操作的函数:信号阻塞,int sigprocmask(int how, const sigset_t *set, sigset_t *oldset);how有SIG_BLOCK,或操作保证set里置1的信号位原位图里一定置1,SIG_UNBLOCK,与操作保证解除屏蔽即对应一定置0,SIG_SETMASK即用set完全覆盖原位图。set是你新建传入的想要修改的位图,oldset是输出给你的原信号位图,便于恢复;int sigpending(sigset_t *set);set输出型参数,传入set,带出pending信号集;int sigemptyset(sigset_t *set);初始化传入的信号集;int sigismember(const sigset_t *set, int signum); 返回1/0表示信号是否在信号集set置1;int sigaddset(sigset_t *set, int signum);添加信号到set中。
解除屏蔽后,可能出现发送多个信号同时到达的情况,但是这些信号中,标准信号只会递达一次,实时信号不做讨论。
int sigaction(int signum,const struct sigaction *_Nullable restrict act,struct sigaction *_Nullable restrict oldact);比signal功能更强大,struct sigaction {void(*sa_handler)(int);void (*sa_sigaction)(int, siginfo_t *, void *);sigset_t sa_mask;int sa_flags; void(*sa_restorer)(void);};中sa_handler是处理方法,当设置了sa_flags设置SA_SIGINFO 标志时,会调用sa_sigaction,能获取更多信号相关信息(如发送者 PID)。sa_mask在处理该信号时,额外要阻塞的信号集合(防止并发冲突)。sa_flags控制标志位。另外,在进入信号处理函数期间,当前信号会被自动阻塞(屏蔽),比signal安全。
进程处理信号的时机发生在进程由用户态返回内核态之时,通常是硬件或软件产生了中断(如定时器、I/O 完成、键盘输入等)或者系统调用,触发进入内核,内核处理完中断或执行完系统调用后,在准备返回用户态前,会统一检查是否有未处理的信号。这是为了防止破环程序状态,比如如寄存器、堆栈不一致等,而只能在“安全点”检查并处理信号。
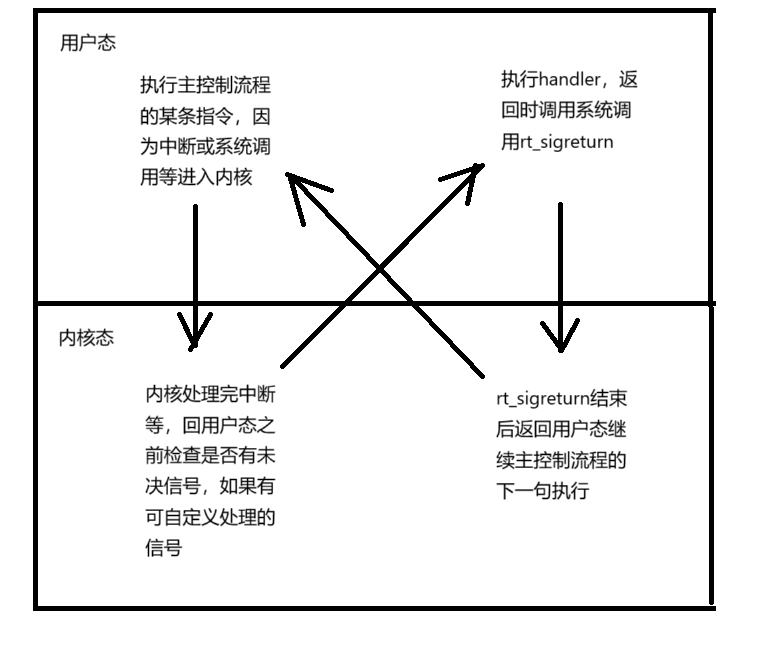
信号处理流程:
- 进程在用户态User Mode执行主控制流程的某条指令即main函数的某行代码时因为中断、异常或系统调用进入内核态Kernel Mode。
- 内核处理完中断等,在回用户态之前会先处理当前进程pending位图里置1的信号(没有就返回用户态),如果在blocked位图里也被置1了,那也不做处理,认为是返回用户态,否则清除 pending 位图中对应的 bit(置 0),根据信号类型选择处理方式:默认动作就执行终止进程等操作;忽略就返回用户态;捕捉,进入用户态执行自定义处理方法handler。
- 在内核态返回用户态时,CPU 就会开始执行handler,它返回时调用系统调用rt_sigreturn()。
- 再次进入内核态,这个系统调用中,内核从栈中恢复寄存器状态,并让进程返回用户态恢复主控制流程执行流。
问1:怎么确保内核态返回用户态时执行handler?
答1:内核在用户栈伪造一个特殊的调用栈帧(stack frame)修改用户态寄存器RIP(指向下一条要执行的指令的地址)指向你注册的 handler 函数地址,模拟一次函数调用的过程,这样在进入用户态后会先调用这个函数。
问2:怎么确保用户态执行完handler返回内核态?
答2:在上面的栈帧中,handler的返回地址会被设置成rt_sigreturn地址,通过修改寄存器rsp实现。同时,在这个栈帧中,还保存了当前程序计数器(PC)、寄存器状态等信息,以便 handler 执行完毕后能正确返回恢复上下文。而后rt_sigreturn取出之前保存的寄存器状态并恢复,让进程回到原本被打断的用户代码继续执行。
外设中断机制:外设发起中断,由中断控制器分配中断号并通知CPU,CPU接收中断号后暂停当前任务,保存现场即寄存器状态,去IDT(Interrupt Descriptor Table,中断描述符表,存放了struct gate_struct,用来找到中断处理函数)中执行中断处理方法,完成后恢复原状态并继续任务。
集成到CPU内部的时钟源持续触发时钟中断,驱动操作系统的调度器进行进程切换。在Linux早期版本的O(1)调度器中,task_struct里有一个字段int count表示当前剩余的时间片数量,每来一个时钟中断,CPU去IDT中执行对应中断服务例程,count–,到0就会调用schedule()进行调度。当然了,现代Linux采用CFS调度器,使用虚拟运行时间以及红黑树管理,自行了解。
CPU内部也可以通过软件主动中断来触发系统调用,比如int 0x80,x86下的一个软件中断指令,和syscall,x86_64下触发中断,进入内核态,从而发起系统调用的指令,这称为软中断。而os内有一张系统调用表,即存放系统调用的函数指针数组,下标称为系统调用号。int 0x80触发软中断后,CPU也去IDT执行对应中断处理方法,后者会获取系统调用号再去系统调用表调用之。软中断,又称陷阱,而除零/野指针/缺页这类CPU 执行指令时检测到错误,切到内核态,查找IDT表项,判断异常是否可修复,比如缺页中断/异常只需开空间、映射页表即可修复,不可则发送信号给当前进程。
值得一提的是,我们所用的系统调用诸如read和write都经过glibc在真正的系统调用上封装一层。当调用read之类时,函数内部会调glibc做的syscall函数,里面才真正调用syscall指令。
用户态:权限最低,基本只能访问自己的代码段数据段。
内核态:权限最高,能够访问所有的系统资源,包括但不限于CPU的所有指令集、所有物理内存、I/O设备、中断控制器等,因为它要管理所有软硬件资源。
os区分二态是通过cs(Code Segment Register,代码段寄存器)寄存器中的特定字段——当前特权级(Current Privilege Level, CPL)标识当前上下文CPU处于哪个特权级别,为0内核态,为3用户态。
进程地址空间中的内核区里面包含系统调用表和方法、PCB以及os代码等,也会通过页表映射物理内存,但是系统层面只映射一次,全进程共享。
到此,总结一个完整的信号产生发送接收处理流程:你按下了 Ctrl+C,产生了一个中断;CPU 进入内核态,调用中断处理函数;内核根据IDT中中断服务例程要发送SIGINT信号,找到当前前台进程,在pending位图把这个信号标记为1。如果目标进程处于可中断状态(例如正在睡眠),则调正其状态。否则,等内核处理完中断等,在返回用户态之前,检查pending及blocked位图,如果发现SIGINT未决且未阻塞,pending中置0,如果默认动作则执行终止进程,忽略则返回用户态,有捕捉处理方法则进入用户态调用handler方法,结束返回内核态恢复原程序执行流上下文,进入用户态继续执行下一个指令。
下面介绍一些优雅的回收子进程资源,防止出现僵尸进程的方法:
- 在SIGCHLD的捕捉方法里用while+waitpid(-1,nullptr,WNOHANG)非阻塞式轮询等待,判断返回值为0表示没有任何子进程已退出,此时break即可。
- 设置SIGCHLD的处理方法为忽略。注意是SIG_IGN,这实际上改变了内核对待子进程结束通知的方式,使得它可以自动清理子进程,而默认动作里的Ign不会触发这种自动清理机制。但是该方法可移植性差。
- 双重 fork 技术:首先由父进程创建一个子进程,然后这个子进程再创建一个孙子进程去执行实际任务,而该子进程则立即退出。这样做的目的是让孙子进程成为孤儿进程,被init 进程(PID=1)的子进程领养,由它来负责回收资源。非常推荐。
目前,这篇博客就结束了,历时数月,毕竟去年就起笔作文了,开个头草草结束,转头去准备期末和应付蓝桥杯(省二)了。如今又耗时数天,终于完成了三集一体的庞然大物,文件系统+ipc+信号。(长出一口气😉
这些就此为止了,接下来是线程部分了。何妨吟啸且徐行