【数据集】中国江北气候区100m逐日近地表气温数据
目录
- 数据概述
- 一、数据输入来源与处理流程
- 1. 再分析气温数据(主输入)
- 2. 辅助数据(辅助输入)
- 3. 对比数据集
- 二、数据预处理与标准化
- 三、模型结构与参数设置
- 1. 模型结构 —— ConvLSTM 网络
- 四、训练与推理流程
- 1. 训练阶段
- 2. 推理阶段
- 五、输出效果与评估结果
- 1. 精度评估指标
- 2. 辅助变量重要性评估(Importance Score)
- 3. 与其他数据集对比
- 六、最终数据成果
- 数据下载
- 基于FileZilla下载数据
- Python实现代码下载
- 参考
根据论文《Convolutional Long Short-Term Memory network for generating 100 m daily near-surface air temperature》,本文旨在利用ConvLSTM(卷积长短期记忆网络)模型,生成中国江北气候区在2019–2023年夏季(6–8月)的100米空间分辨率的逐日近地表气温数据(最高温 Tmax、最低温 Tmin、平均温 Tmean)。以下是该数据集的详细生产过程,涵盖输入数据来源、处理方法、模型结构及最终输出效果。

数据概述
一、数据输入来源与处理流程
研究采用的数据总结如下:

1. 再分析气温数据(主输入)
ERA5 与 ERA5-Land陆地再分析产品:
-
提供小时级的温度数据。
-
ERA5(0.25°)用于填补 ERA5-Land(0.1°,约等于10 km)在陆水交界处的空缺。
ERA5-land以0.1的较高空间分辨率提供每小时温度,但仅针对陆地地区,导致陆地-水界面出现缺口。为了解决这个问题,我们使用0.25分辨率的无缝ERA5数据来填补ERA5-Land中的空白。 -
所有时间数据从 UTC 转换为北京时间(UTC+8)。
由于研究区域位于中国境内,ERA5-hour(UTC) 和 ERA5-land-hour(UTC) 数据被转换为中国时区 (UTC+8)。 -
使用双线性插值将 ERA5 resample 至 0.1°。
-
融合后计算每日 Tmax、Tmin、Tmean。
2. 辅助数据(辅助输入)
温度与海拔高度密切相关,因为海拔越高,温度越低。数字高程模型提供了重要的地形信息,直接影响温度模式。
不同的土地利用类型也会影响温度变化。人类活动的增加放大了不透水表面对温度的影响。然而,LULC数据在土地覆盖均匀的地区可能不太有效,如山区,那里类似的像素编码可能无法捕捉温度变化。尽管所选的 LULC 数据满足研究的时间和空间分辨率要求,但有限的类别数量(如表1所示)导致了类似的挑战。
此外,在城市地区,高度的土地利用异质性和100米的目标分辨率仍然会带来精度损失的风险,尤其是在分散的城市绿地中。
考虑到以上两个原因,我们计划采用NDVI(归一化植被指数)和FVC(植被覆盖度)数据来补充LULC信息。
| 数据类型 | 数据来源 | 分辨率 | 描述 |
|---|---|---|---|
| DEM (数字高程模型) | NASA SRTM | 90m | 反映地形对气温的影响 |
| LULC (土地利用/覆盖) | CLCD | 30m | 9类地表类型(如耕地、城市、森林等) |
| FVC (植被覆盖度) | Sentinel-2 NDVI计算 | 10m | 基于 NDVI 的经验估算公式计算得出 |
| 气候分区矢量 | 中国气候区划数据 | / | 用于定义研究区域 |
| 地面气象站观测数据 | 中国气象局 V3.0 | 日尺度 | 用作模型训练与验证标签,共276个站点 |
CLCD 土地利用类型含9个分类,如下:

3. 对比数据集
为了评估ConvLSTM降尺度数据集(表示为CMData)的性能,选择了另外两个数据集进行比较:
(1) 2019年至2022年6月至8月的每日温度数据(WData)
J2024-Reconstruction of all-sky daily air temperature datasets with high accuracy in China from 2003 to 2022
(2) 2019年至2023年6月至8月的每月温度数据(TData)
J2019-1 km monthly temperature and precipitation dataset for China from 1901 to 2017
为了确保时间尺度的一致性,CMData和台站温度数据都汇总到一个月尺度,以便与TData进行比较。
二、数据预处理与标准化
空间重采样:所有数据统一至0.001°(约100米)空间分辨率。
标准化处理:
- Tmax、Tmin、Tmean、DEM 使用 Z-score 标准化。
- FVC、LULC 保持原始形式输入。
窗口提取:以站点为中心提取 5×5 像素窗口,构建六维数组输入模型。
三、模型结构与参数设置
1. 模型结构 —— ConvLSTM 网络
ConvLSTM:在 LSTM 的基础上引入卷积操作,融合时间与空间特征。

因此,本研究中使用的网络由三个ConvLSTM层组成,分别具有128、64和64个隐藏单元。最后应用一个卷积层来产生Tmax、Tmin和Tmean的输出。卷积核大小设置为5×5。通过优化和测试,我们实现了模型准确性和过度拟合风险之间的平衡。在其他参数中,批量大小被设置为32,训练时期的数量被设置为50。
网络层数:
- 三层 ConvLSTM:隐藏单元数分别为 128、64、64。
- 最后一层为卷积层,输出单个预测值(Tmax、Tmin、Tmean)。
卷积核大小:5×5。
损失函数:加权 MSE(均方误差):Tmax 和 Tmin 权重为 0.4,Tmean 权重为 0.2。
训练参数:
- 批处理大小(Batch size):32
- 训练轮次(Epochs):50
四、训练与推理流程
本研究基于两个假设:
(1) 周围环境影响中心位置的温度。据此,我们选取了气象站位置及其周围5×5图像窗口对应的像元作为数据批次。
(2) 温度和环境因素之间的关系在几年内保持相对稳定。虽然全球变暖是一个严重的长期现象1,但短期波动是存在的,线性趋势在短短几年内并不明显。这个假设保证了在研究期(五年)内共享同一个模型的可行性。
此外,通过将时间框架集中在夏季,大规模的温度波动有所缓解。
在这项研究中,我们首先使用双线性插值法处理从ERA5和ERA5-land、DEM、LULC和FVC数据计算的每日温度数据,以实现0.001(约100米)的空间分辨率。
使用处理后的数据作为ConvLSTM模型输入,我们以100米的空间分辨率生成每日Tmax、Tmin和Tmean数据。
然后,我们进行了时间和空间的准确性评估,计算微波辐射、RMSE和R2指标,并与其他数据集进行比较。
此外,我们分析了所选因子作为输入数据的通道重要性,并讨论了降尺度数据集的应用价值。
1. 训练阶段
在对原始多数据集进行双线性插值后,我们对Tmax、Tmin、Tmean和DEM应用Z得分标准化,而FVC、NDVI和LULC则以其原始形式使用。
由于NDVI和FVC有很强的相关性,我们测试了三种情况——使用NDVI、FVC或两者都使用——发现只使用FVC会导致较小的培训损失。因此,FVC被选为与DEM和LULC作为最终的辅助投入。
在标准化的图像中,我们提取与气象站相对应的图像窗口,并将其堆叠成六维数组:ID、年份、时间步长、通道Channel、高度、宽度。
这里,ID代表不同的站,Year代表研究年份(2019–2023),Time_Step代表天数(6月到8月,92天),Channel 代表输入变量(Tmax,Tmin,Tmean,DEM,FVC,LULC),Height 和Width 代表窗口维数(均为5)。
在随机选择训练和测试站后,我们将ID和Year维度合并到Batch维度中,得到一个五维输入数组:Batch_Size、Time_Step、Channel、Height、Width。
输入维度:[Batch_Size, Time_Step (92天), Channel (6), Height (5), Width (5)]
模型的损失函数是均方误差(MSE)。
标签为站点观测数据(Tmax、Tmin、Tmean)
说明:最初,损失被定义为Tmax、Tmin和Tmean的平均MSE。经过测试,我们发现Tmax和Tmin的MSE高于Tmean。因此,我们将损失函数调整为MSEs的加权和,Tmax和Tmin的权重为0.4,Tmean的权重为0.2。
2. 推理阶段
使用基于台站的数据进行初始模型训练和验证。对于像素级温度推断,我们采用了滑动窗口方法。
首先,使用与训练数据相同的平均值和标准偏差对输入数据进行标准化:
对于Tmax,30.950和3.285;对于Tmin,24.081和2.709;对于Tmean,27.303和2.723;DEM为 69.769 和138.189 。
然后提取围绕每个目标像素的 5×5窗口 作为推理的输入,并应用该模型获得Tmax、Tmin和Tmean。
使用滑动窗口法对整个区域像素进行推理:
- 每个像素提取其周围 5×5 窗口作为输入。
- 使用训练好的模型预测该像素的 Tmax、Tmin、Tmean。
五、输出效果与评估结果
考虑的评价指标有三个,如下:

1. 精度评估指标
月尺度评价指标如下:
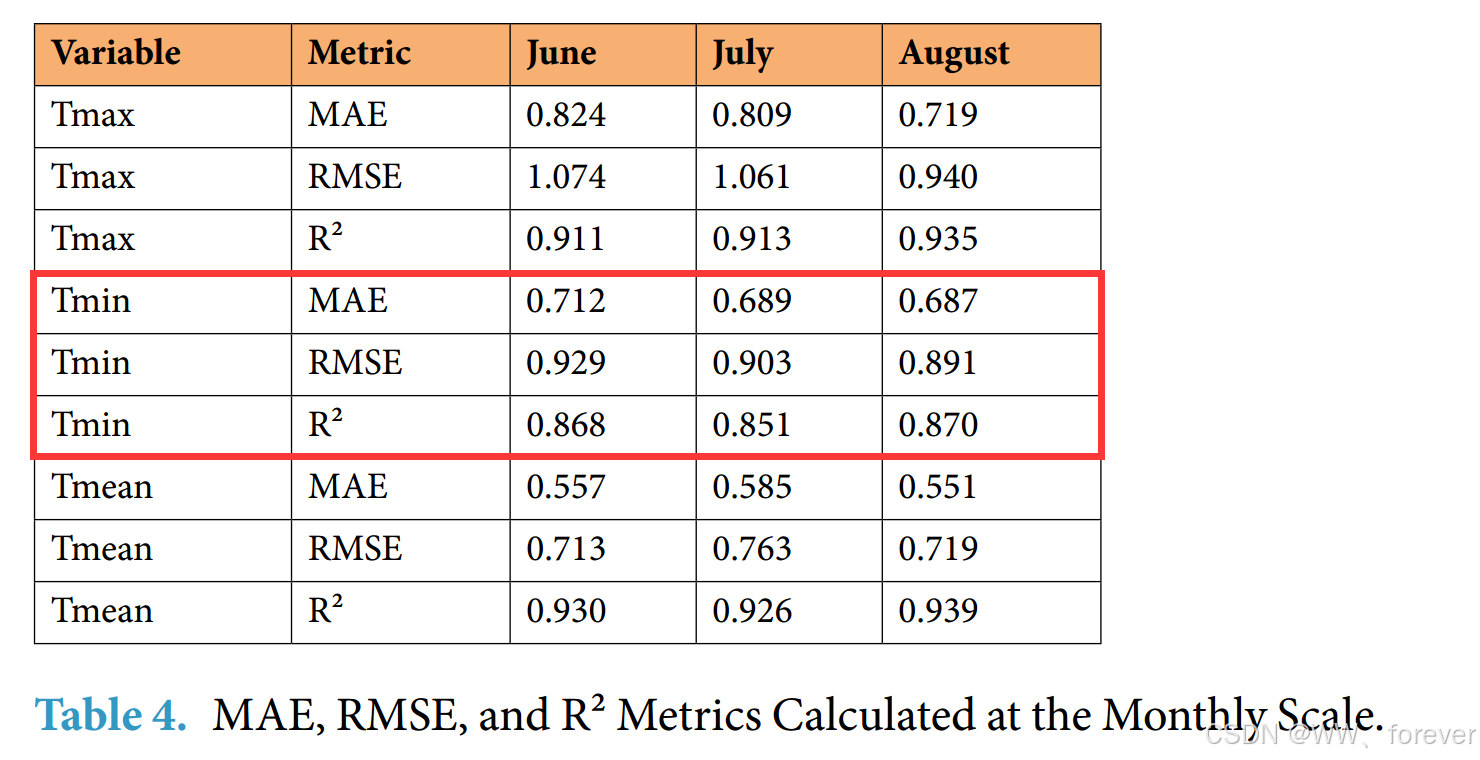
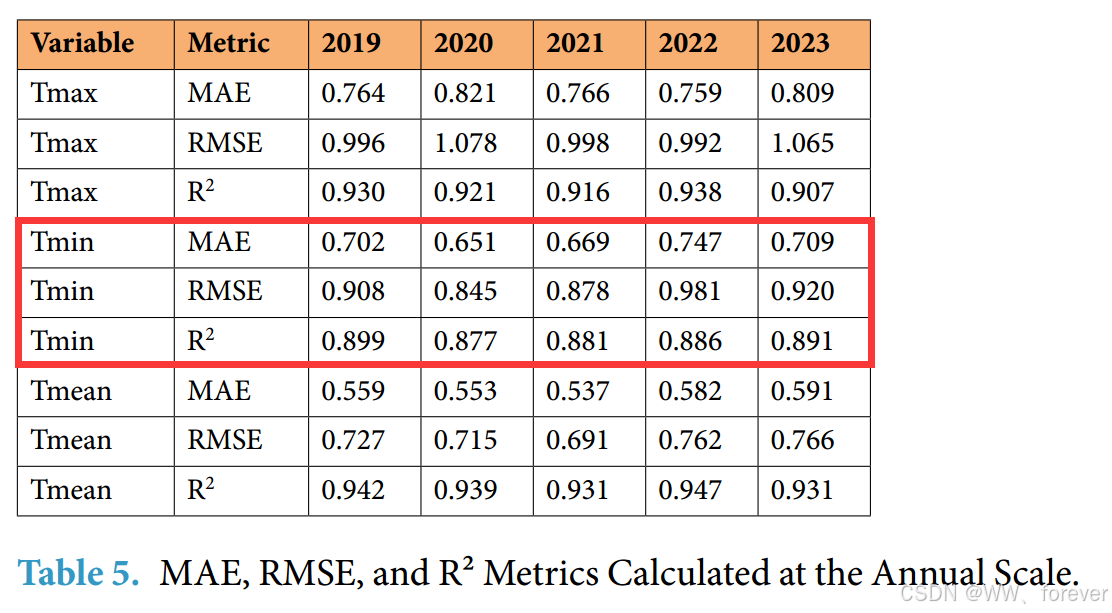
年尺度评价指标如下:
| 变量 | MAE (℃) | RMSE (℃) | R² |
|---|---|---|---|
| Tmax | 0.784 | 1.027 | 0.929 |
| Tmin | 0.696 | 0.908 | 0.892 |
| Tmean | 0.564 | 0.733 | 0.943 |
Tmean 的预测精度最高。
散点密度图显示了Tmax (a)、Tmin (b)和Tmean ©的观测值和预测值之间的一致性,MAE、RMSE和R2的结果位于左上角。

箱线图显示真实观测值和预测值之间的月(a)和年(b)绝对差异

空间评估显示:大多数站点 MAE < 1°C,R² > 0.9,但部分高海拔森林地区精度较低(如安徽岳西站)。

2. 辅助变量重要性评估(Importance Score)
每个 辅助变量的重要性分数评估如下:
| 输入因子 | 重要性评分 |
|---|---|
| ERA5-Tmean | 49.33% |
| ERA5-Tmin | 20.74% |
| ERA5-Tmax | 16.88% |
| DEM | 8.55% |
| LULC | 4.15% |
| FVC | 0.89% |
对应于所有站点的LULC、DEM和FVC属性的MAE值。

主要依赖 ERA5 气温数据。
DEM 在辅助数据中最重要,FVC 贡献最小。
3. 与其他数据集对比
相比 WData(1km/日)与 TData(1km/月):
- CMData(本研究)空间分辨率更高(100m);
- 精度略低于 WData,但远优于 TData;
- 更适合城市内部温度细节研究。


六、最终数据成果
输出内容:逐日 Tmax、Tmin、Tmean(单位:℃)
时间范围:2019–2023年6月–8月
空间范围:中国江北气候区(110.22°E–121.91°E,27.20°N–34.10°N)
空间分辨率:100米
数据下载
国家青藏高原科学数据中心-Summer Daily Scale 100m Maximum, Minimum, and Average Temperature

基于FileZilla下载数据
下载信息如下:

打开FileZilla,并填写上述信息:

可根据需要,右键下载。
Python实现代码下载
GitHub-ConvLSTM-for-Temperature-Downscaling

各文件功能总结如下:
main_run.py: main function to run scripts
convlstm_final.py: convLSTM model
contribution_factors.py: customized function to calculate channel importance
criterion_weighted.py: weighted criterion function train_validate.py: train and validate functions
parameters_std.xlsx: standardized parameters for required training channels
checkpoint_model_19-23.pth: final model to conduct downscaling