Python自动化之selenium语句——元素点击、输入、清空和八大元素定位方法
目录
一、元素定位配置
1.导包
2.查找元素
二、元素交互操作
1.点击
2.输入
3.清空
三、元素定位方法
1.ID
2.NAME
3.CLASS_NAME
4.TAG_NAME
5.LINK_TEXT
6.PARTIAL_LINK_TEXT
7.CSS_SELECTOR
8.XPATH
本节讲解元素定位相关知识
一、元素定位配置
1.导包
![]()
2.查找元素
1)查找单个元素,并输出打印
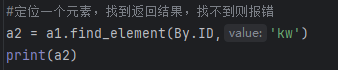
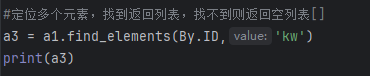
2)查找多个元素,并输出打印
在实际场景中,这条语句可以用来检验使用的定位给方法找到的元素是否是唯一的
3)另一个方法是在浏览器控制台,输入如:document.getElementById('kw'),回车进行查找,即可看见返回数据是几个
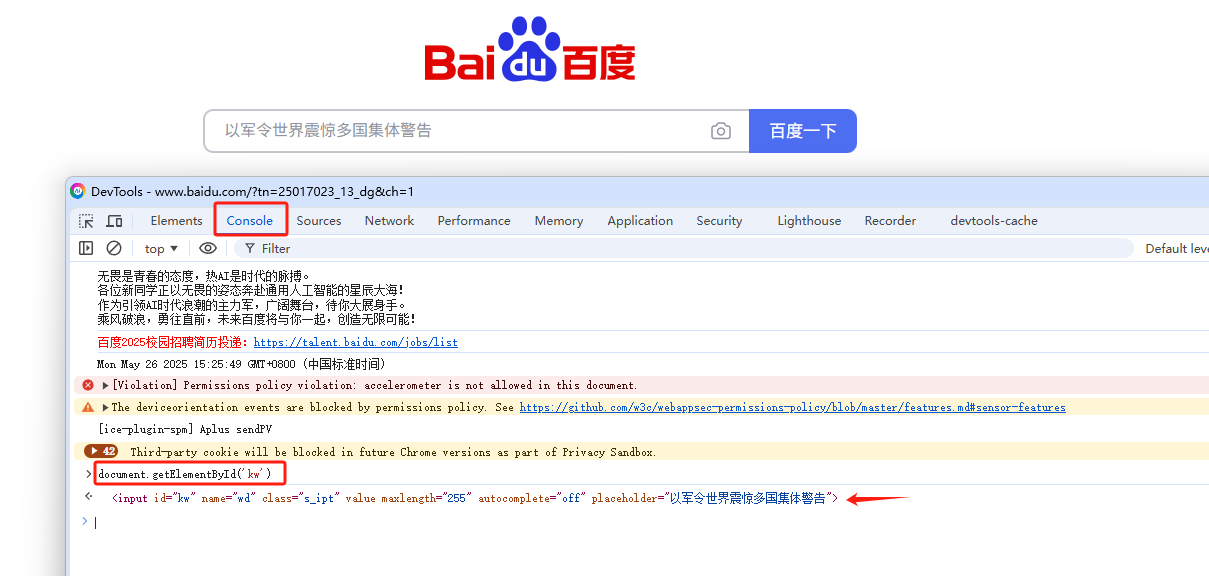
如果复制后出现报错,类似于:Warning: Don’t paste code into the DevTools Console that you don’t understand or haven’t reviewed yourself. This could allow attackers to steal your identity or take control of your computer. Please type ‘allow pasting’ below and hit Enter to allow pasting.
直接在控制台输入allow pasting然后回车,就能复制过来了。
![]()
二、元素交互操作
1.点击
![]()
2.输入
![]()
整体代码:访问百度网址,输入框输入“测试”,点击【百度一下】
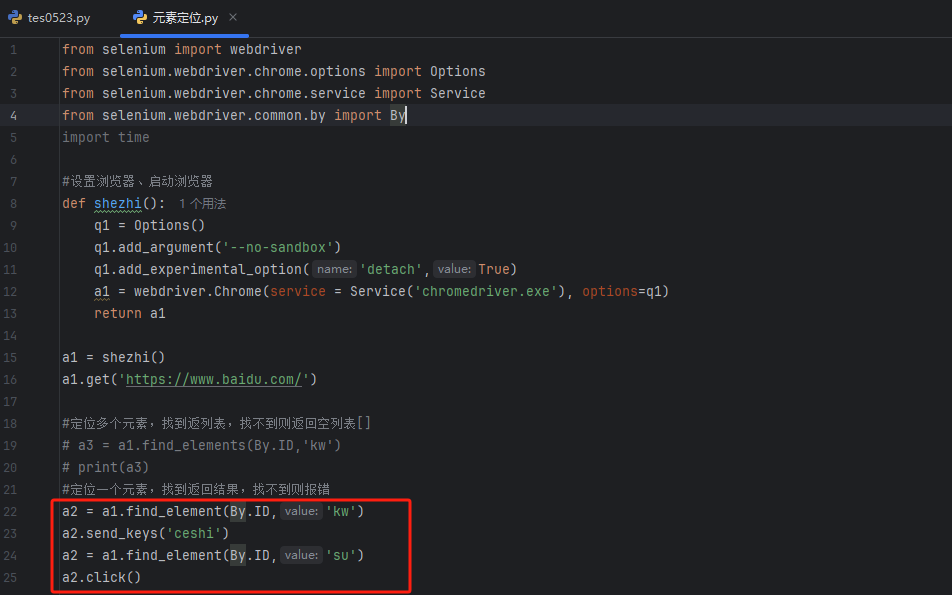
运行结果如下:
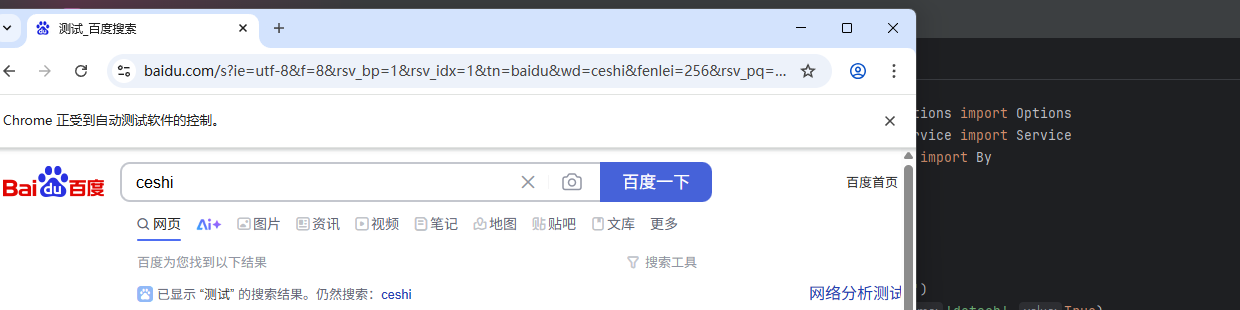
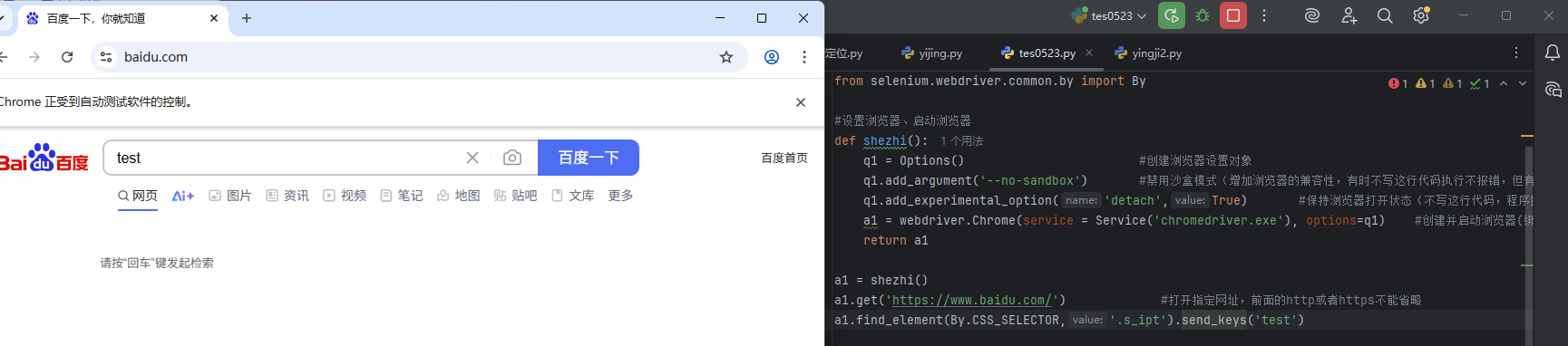
3.清空
![]()
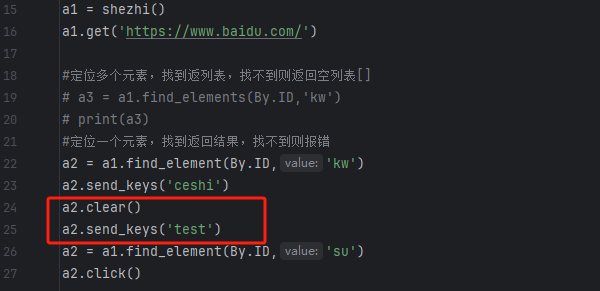
添加两行代码,如下,清空输入框内容后,再写入新的内容"test"
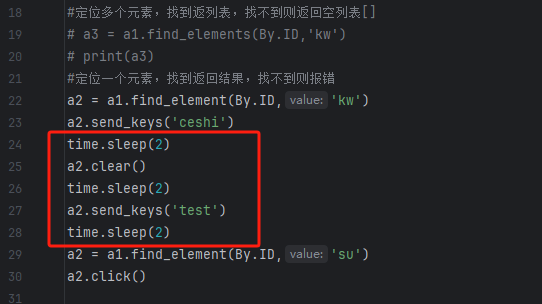
为了清晰的查看变化效果,添加了等待2秒
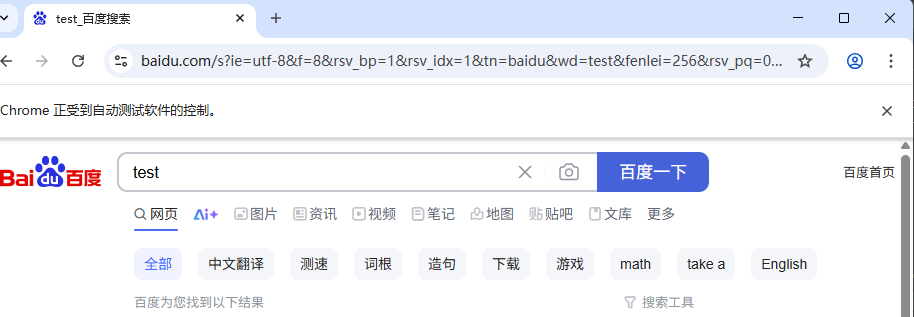
运行结果如下
三、元素定位方法
下面将介绍八大元素定位方法。其中最常用的是xpath定位方法。
1.ID
第二章的元素交互中,使用的就是按照ID查找元素
如:a2 = a1.find_element(By.ID,'kw')
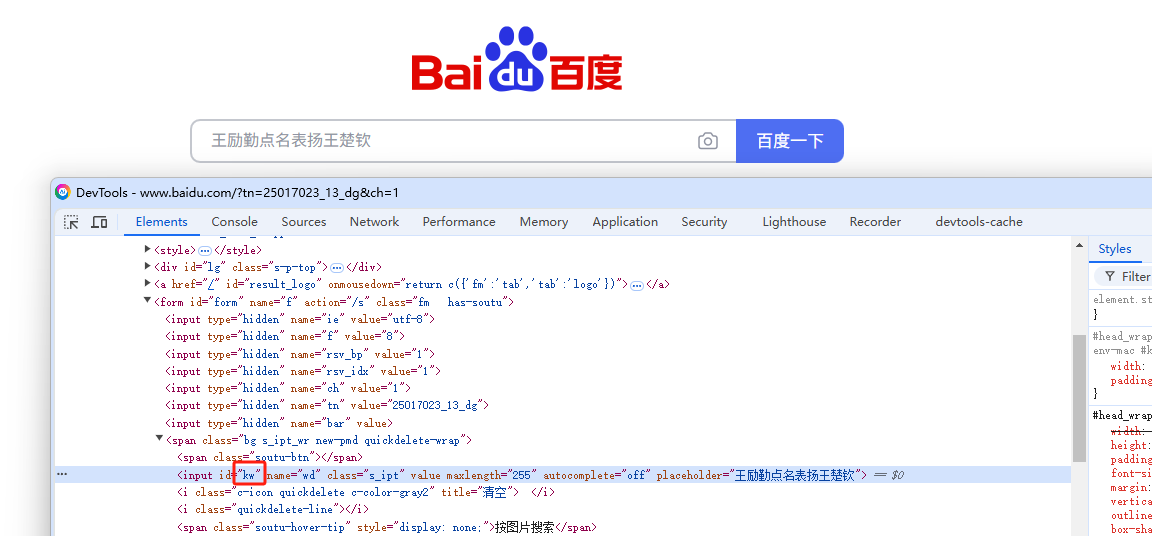
实现查找输入框,并输入查询内容语句:

特点:
高效、准确、简单,但需要注意的是,在实际应用中要确保 id 的唯一性,因为有的项目在实际的开发中id不是唯一的,或者id是动态生成的。而且有的元素,没有id这个属性值。如果页面结构复杂或存在动态内容,可以结合其他定位策略(如 class name、xpath 或 css selector)以提高定位的灵活性和可靠性。
2.NAME
通过name值来查找元素,语句如下:
a1.find_element(By.NAME,'wd')
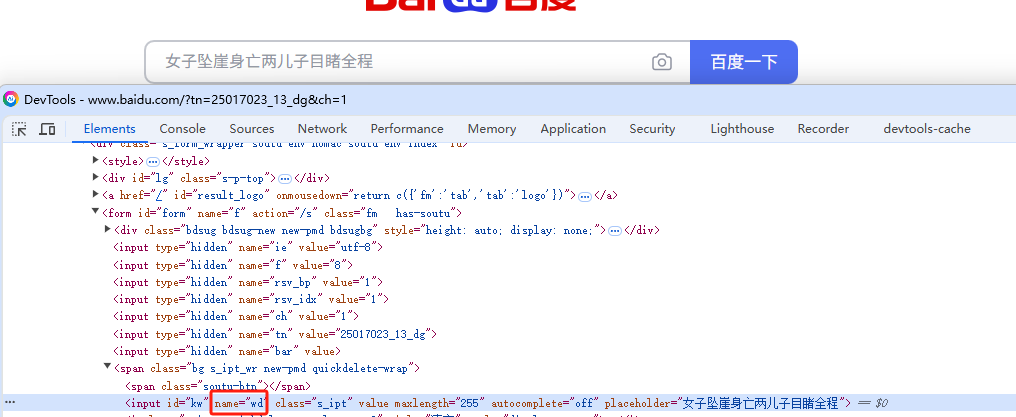
先验证按照name值查找,匹配的有几个,下图显示1个,那么就可以通过name值进行元素定位

实现查找输入框,并输入查询内容语句:
![]()
特点:
简便有效,尤其适用于表单元素的自动化测试。然而,由于 name 可能不是唯一的,所以在使用时需要注意以下两点:
- 确保你的 name 属性值确实是唯一的,或者你明确知道你想操作的是第一个匹配的元素。
- 在存在多个相同 name 的情况下,考虑结合其他定位策略(例如 xpath 或 css selector),以提高定位的准确性和灵活性。
3.CLASS_NAME
1)通过class_name值来查找元素,语句如下:
a1.find_element(By.CLASS_NAME,'s_ipt')
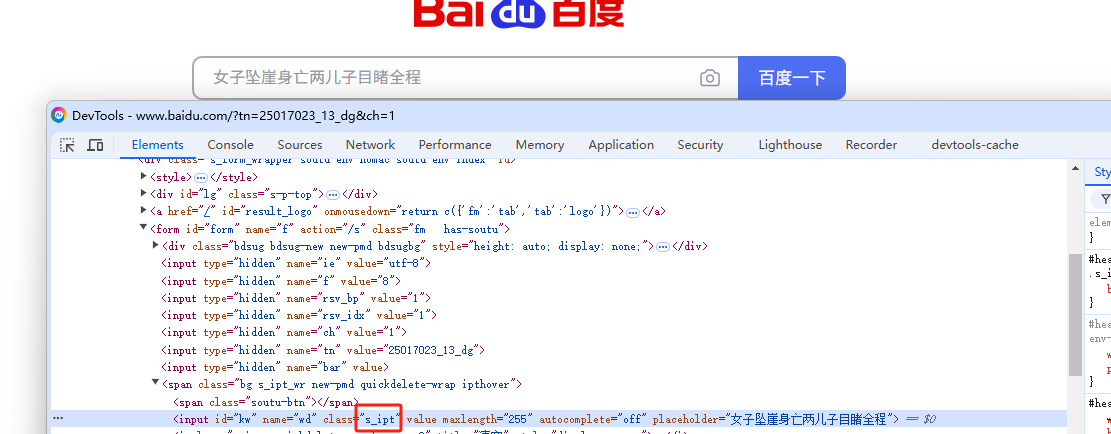
![]()
2)特点:
- class_name值不能有空格,有空格时报错,定位不到元素,见下图
![]()
- class_name值有重复时,需要做切片操作
- class值有的网站是随机的,此时就不能用class_name进行定位
3)切片步骤
1)找到元素,并按照class_name查找,同名的有几个
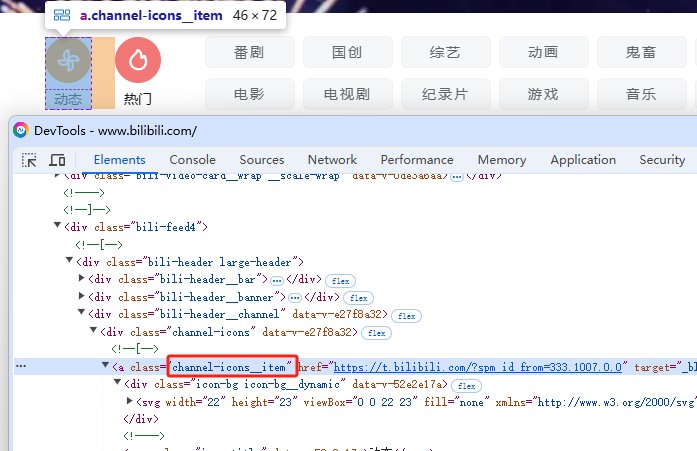
控制台显示,同名的是两个(默认情况下,控制台限制直接复制代码,输入allow pasting回车即可更改)

2)编写代码如下,代表点击【热门】按钮
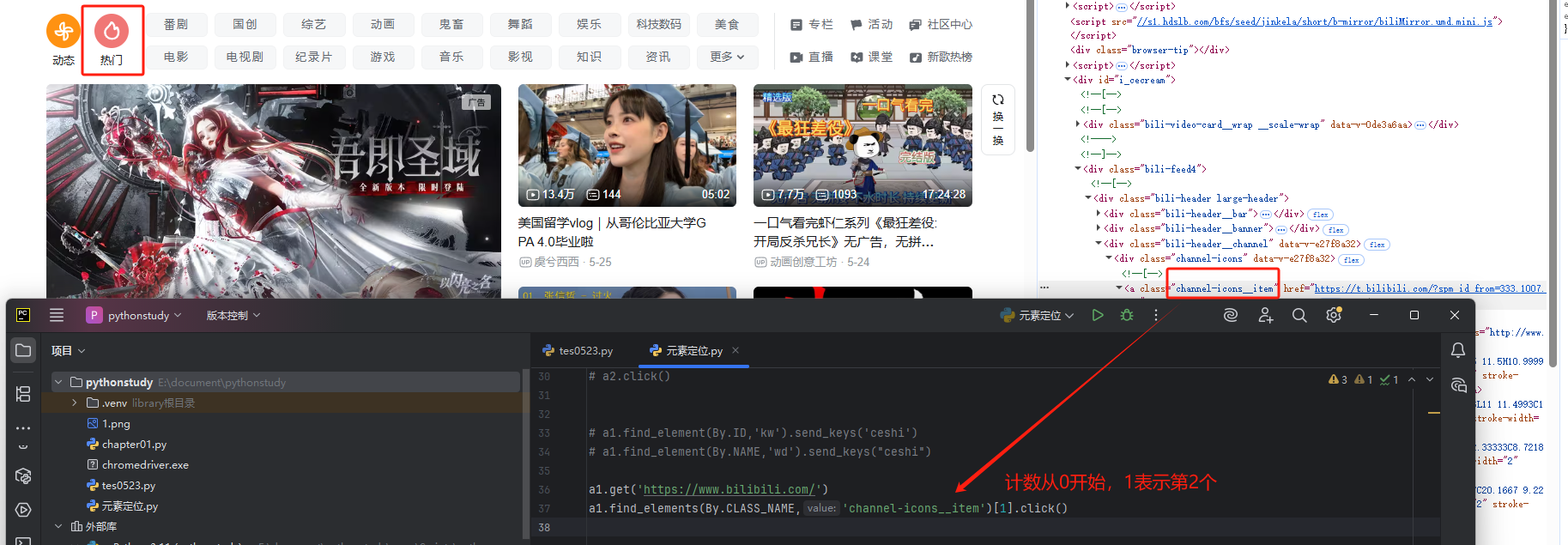
3)执行代码,查看,功能可正常实现
4)记录一条今天遇到的问题
昨天执行代码,都是能正常执行的,今天打开Pycharm后执行(代码,配置等等并没有更改),发现未执行,控制台都没有输出,操作了使缓存失效,弹窗页面直接点击【重启】,重启后可以了
4.TAG_NAME
查找的是<>标签开头的名字,如下图的input,标签名基本上都不是唯一的
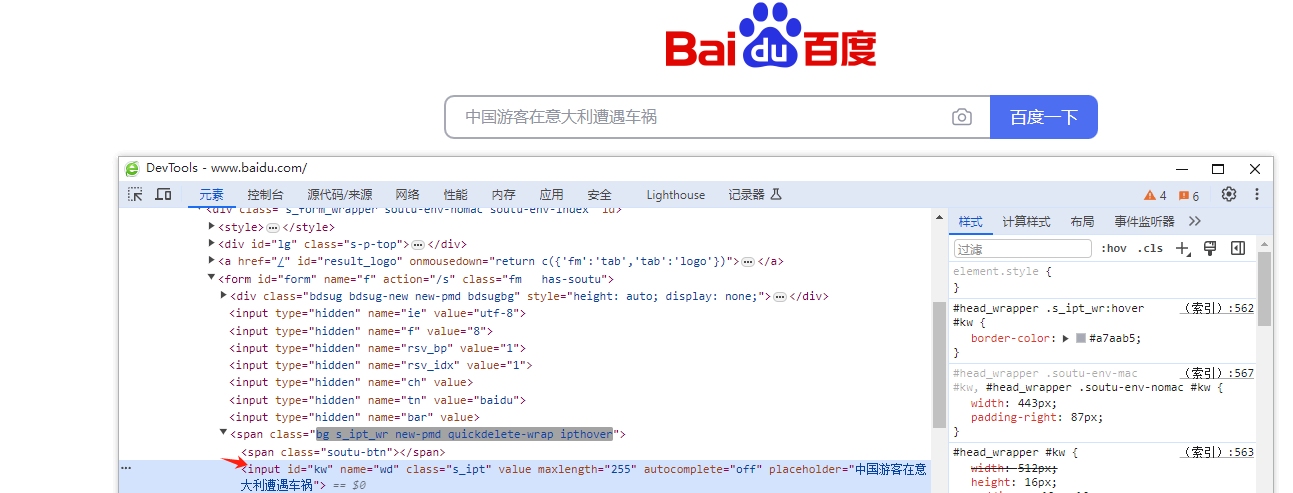
语句
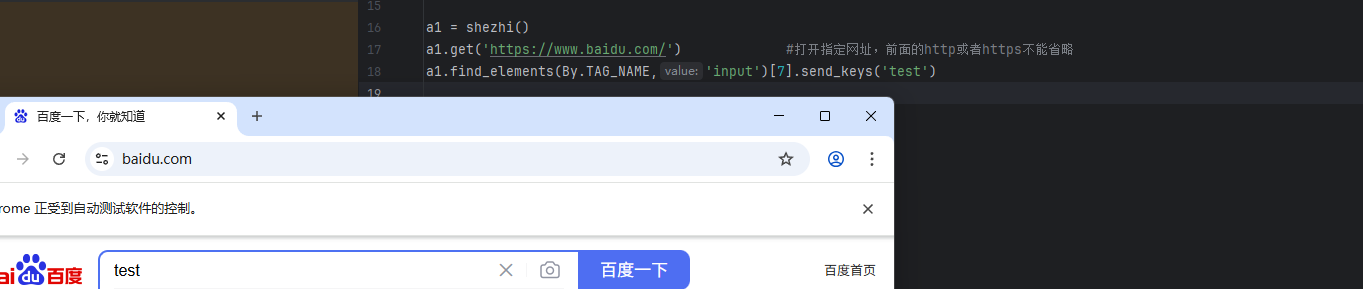
a1.find_elements(By.TAG_NAME,'input')[7]
执行结果成功
特点
- 基本上都有重复名
- 需要做切片处理,当重复名太多时,就不便用这个方法查找元素了
5.LINK_TEXT
查找a标签的文本内容来定位
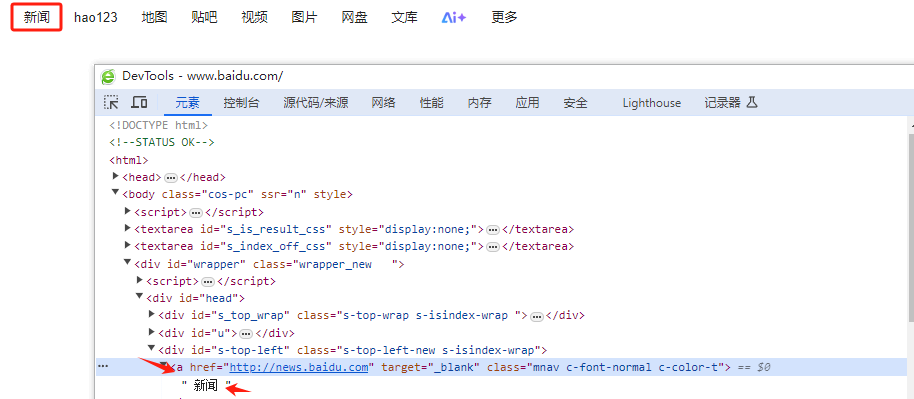
语句
a1.find_element(By.LINK_TEXT,'新闻')
执行结果,点击了【新闻】并打开新页面
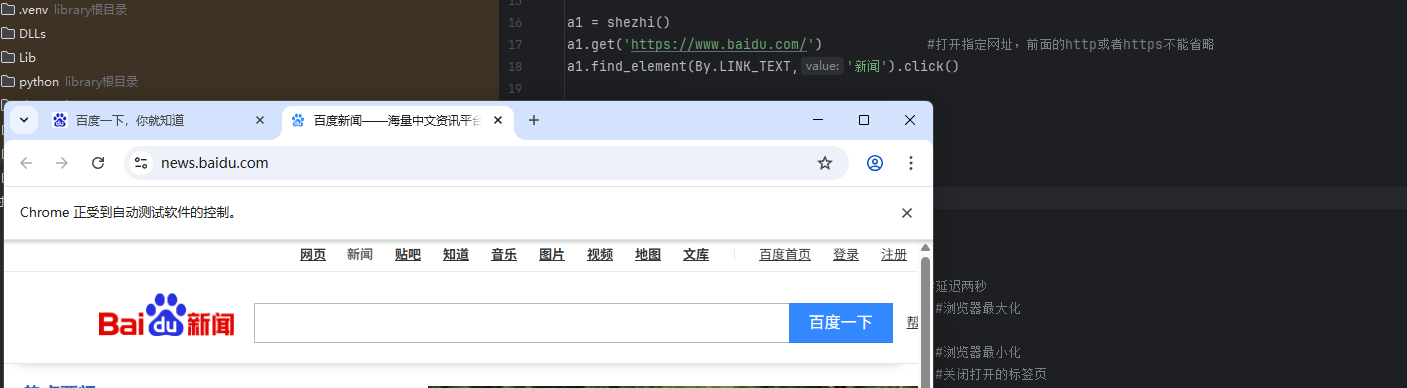
特点:
- 通过A标签的链接文本名查找
- 有重复的文本名时,需要做切片处理
6.PARTIAL_LINK_TEXT
模糊文本定位
语句:
a1.find_element(By.PARTIAL_LINK_TEXT,'新')
运行结果,打开了新闻页

特点:
- 其实就是LINK_TEXT的模糊搜索,存在多个时,做切片处理
7.CSS_SELECTOR
多功能定位(id、class、tag)
1)#id值 通过id进行定位
语句:
a1.find_element(By.CSS_SELECTOR,'#kw')
2).class 通过class定位
a1.find_element(By.CSS_SELECTOR,'.s_ipt')
运行结果
3)不加修饰符,通过标签头查找
a1.find_elements(By.CSS_SELECTOR,'input')[7]
4)通过任意类型定位
a1.find_element(By.CSS_SELECTOR,"[autocomplete='off']")


支持的几种查找格式:
"[类型='精准值']" ——> a1.find_element(By.CSS_SELECTOR,"[autocomplete='off']")
"[类型*='模糊值']" ——> a1.find_element(By.CSS_SELECTOR,"[autocomplete*='of']")
"[类型^='开头值']" ——> a1.find_element(By.CSS_SELECTOR,"[autocomplete^='o']")
"[类型$='结尾值']" ——> a1.find_element(By.CSS_SELECTOR,"[autocomplete$='f']")
5)其他方式
选择需要定位的输入框,右键-复制-复制selector
这种方法简单易操作,但是个别元素定位值会比较长
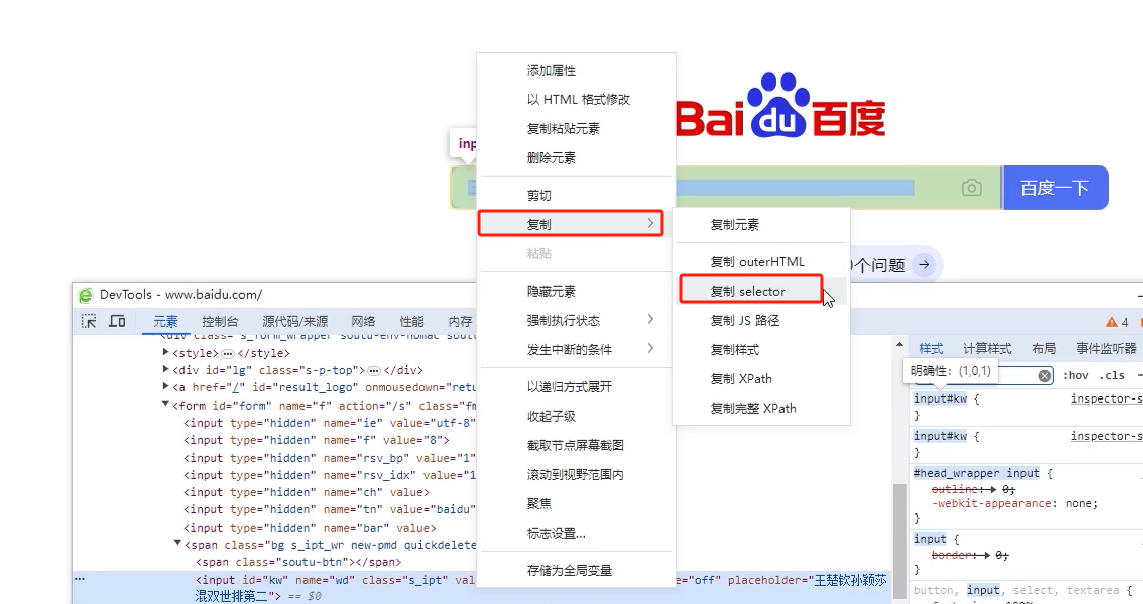
然后CTRL+V,直接显示在value值内,默认粘贴的就是按照id进行定位的
![]()
8.XPATH
1)选择需要定位的输入框,右键-复制-复制xpath(属性+路径定位,属性如果是随机的,此种定位方式就定位不到了)
a1.find_element(By.XPATH,'//*[@id="s-top-left"]/a[1]')
2)选择需要定位的输入框,右键-复制-复制完整xpath(全路径定位,定位准确,但是有时定位值会比较长)
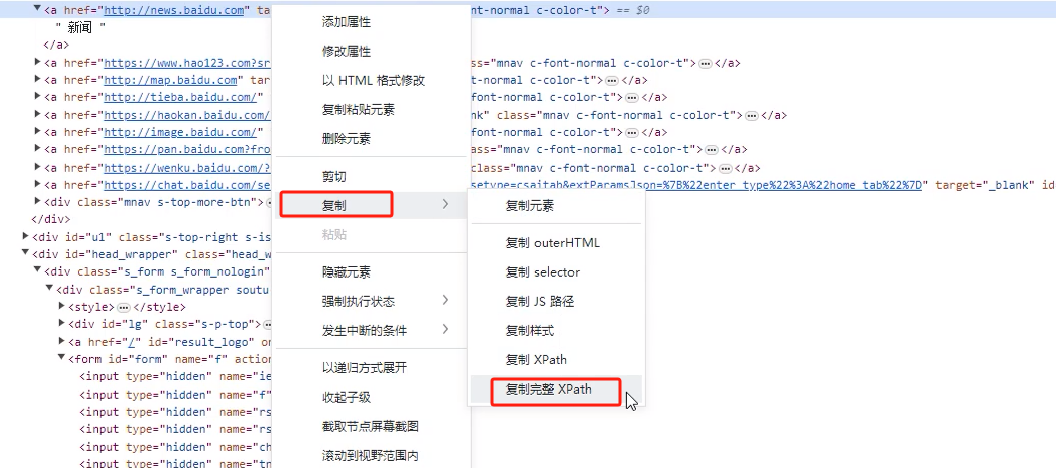
a1.find_element(By.XPATH,'/html/body/div[2]/div[1]/div[3]/a[1]')
3)手写xpath
前面是通过浏览器直接复制xpath路径,方法简单,但是会存在浏览器方式抓取不到元素的场景,元素属性动态变化,直接复制路径不稳定等问题,下面讲解手写xpath来进行元素定位的相关知识。
- 基本语法
| 序号 | 符号 | 解释 |
| 1 | / | 根节点 |
| 2 | // | 任意位置 |
| 3 | * | 任意元素 |
| 4 | @ | 属性 |
| 5 | . | 当前节点 |
| 6 | .. | 父级节点 |
| 7 | text | 文本值 |
| 8 | contains | 模糊查询 |
| 9 | starts-with | 匹配一个属性开始位置的关键字 |
| 举例 | //*[@属性='属性值'] 如://*[@class='mnav c-font-normal c-color-t'] | |
| //*[text()='文本值'] 如://*[text()='新闻'] | ||
| [contains(@属性/text(),值)] 如://*[contains(text(),'新闻')]表示任意位置任意元素,模糊查找文本值是'新闻'的元素 | ||
| [starts-with(@属性/text(),值)] 如://*[starts-with(@id,success)]表示任意位置任意元素,查找id值以success开始的元素 | ||
| //*[@type='password']/../../../div[2]表示任意位置任意元素查找type值是password的父级的父级的父级的下级div的第二个元素(适用于元素没有任何属性,不好直接定位,通过查找父级的方式来进行定位) | ||
| //*[@class='manv and @type='password'']表示同时使用多个条件查询 | ||
| //*[name()='svg'] 对于svg属性的元素,无法通过xpath进行定位,所以要用此方式来查找定位 | ||
- 浏览器中验证xpath
F12,Elenents页面输入CTRL+F,在最下方显示了xpath路径验证输入框,输入语句后回车,即可查看到同名路径的有几个
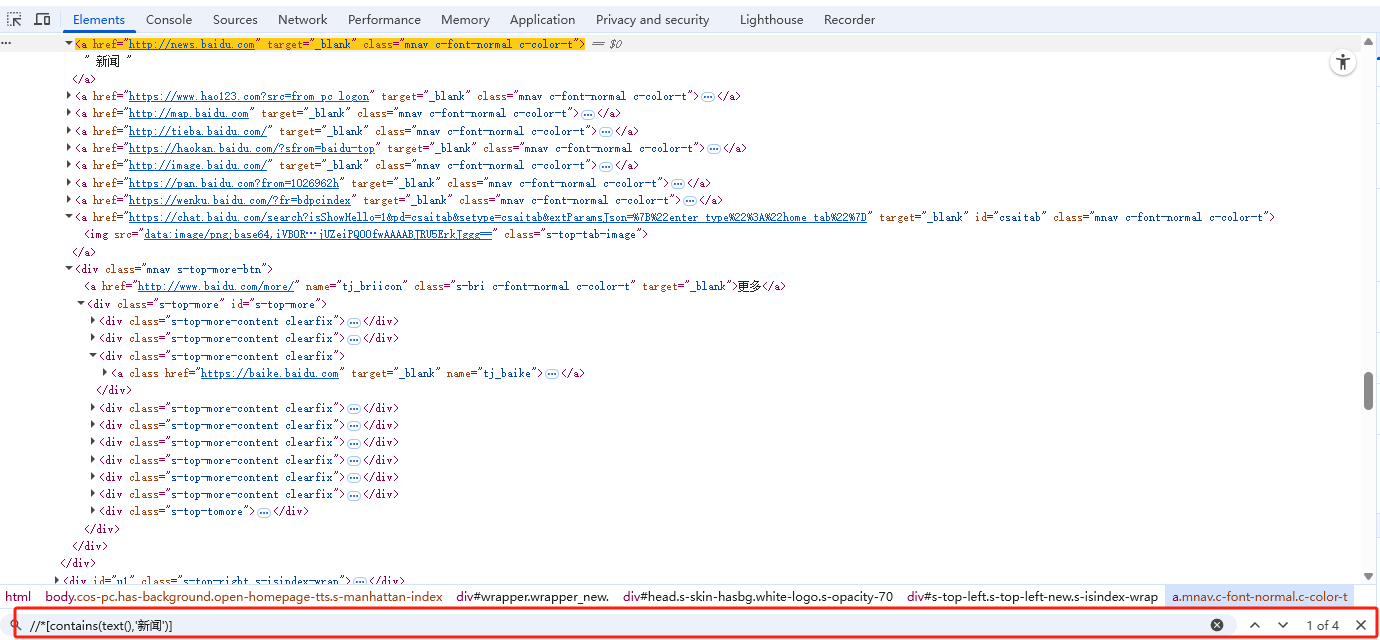
svg元素的定位验证
