vr中风--数据处理模型搭建与训练
# -*- coding: utf-8 -*-
"""
MUSED-I康复评估系统(增强版)
包含:多通道sEMG数据增强、混合模型架构、标准化处理
"""
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from collections import defaultdict# 随机种子设置
SEED = 42
np.random.seed(SEED)# -------------------- 第一部分:数据增强器 --------------------
class SEMGDataGenerator:"""sEMG数据增强器(支持多通道)增强策略:- 分通道时间扭曲- 通道独立噪声添加- 幅度缩放- 通道偏移"""def __init__(self, noise_scale=0.1, stretch_range=(0.8, 1.2)):"""参数:noise_scale: 噪声强度系数 (默认0.1)stretch_range: 时间扭曲范围元组 (默认0.8~1.2倍)"""self.noise_scale = noise_scaleself.stretch_range = stretch_rangedef time_warp(self, signals):"""时间扭曲(分通道处理)"""orig_length = signals.shape[0]scale = np.random.uniform(*self.stretch_range)new_length = int(orig_length * scale)x_orig = np.linspace(0, 1, orig_length)x_new = np.linspace(0, 1, new_length)warped = np.zeros_like(signals)for c in range(signals.shape[1]): # 分通道处理warped_single = np.interp(x_new, x_orig, signals[:, c])if new_length >= orig_length:warped[:, c] = warped_single[:orig_length]else:padded = np.zeros(orig_length)padded[:new_length] = warped_singlewarped[:, c] = paddedreturn warpeddef add_noise(self, signals):"""添加高斯噪声(通道独立)"""# 每个通道独立生成噪声noise = np.zeros_like(signals)for c in range(signals.shape[1]):channel_std = np.std(signals[:, c])noise[:, c] = np.random.normal(scale=self.noise_scale*channel_std, size=signals.shape[0])return signals + noisedef amplitude_scale(self, signals):"""幅度缩放(全通道同步)"""scale = np.random.uniform(0.7, 1.3)return signals * scaledef channel_shift(self, signals):"""通道偏移(循环平移)"""shift = np.random.randint(-3, 3)return np.roll(signals, shift, axis=1) # 沿通道轴偏移def augment(self, window):"""应用至少一种增强策略"""aug_window = window.copy()applied = Falseattempts = 0 # 防止无限循环# 尝试应用直到至少成功一次(最多尝试5次)while not applied and attempts < 5:if np.random.rand() > 0.5:aug_window = self.time_warp(aug_window)applied = Trueif np.random.rand() > 0.5:aug_window = self.add_noise(aug_window)applied = Trueif np.random.rand() > 0.5:aug_window = self.amplitude_scale(aug_window)applied = Trueif np.random.rand() > 0.5:aug_window = self.channel_shift(aug_window)applied = Trueattempts += 1return aug_window
# -------------------- 第二部分:数据处理管道 --------------------
def load_and_preprocess(file_path, label, window_size=100, augment_times=5):"""完整数据处理流程参数:file_path: CSV文件路径label: 数据标签 (1.0=健康人, 0.0=患者)window_size: 时间窗口长度(单位:采样点)augment_times: 每个样本的增强次数返回:features: 形状 (n_samples, window_size, n_channels)labels: 形状 (n_samples,)"""# 1. 数据加载df = pd.read_csv(file_path, usecols=range(8), dtype=np.float64)df = df.dropna() # 确保只读取前8列print("前8列统计描述:\n", df.describe())# 检查是否存在非数值或缺失值if df.isnull().any().any():print("发现缺失值,位置:\n", df.isnull().sum())df = df.dropna() # 删除含缺失值的行# 检查无穷大值if np.isinf(df.values).any():print("发现无穷大值")df = df.replace([np.inf, -np.inf], np.nan).dropna()#print("前8列数据类型:\n", df.iloc[:, :8].dtypes)#print("首行数据示例:\n", df.iloc[0, :8])print(f"[1/5] 数据加载完成 | 原始数据形状: {df.shape}")# 2. 窗口分割windows = []step = window_size // 2 # 50%重叠n_channels = 8 # 假设前8列为sEMG信号for start in range(0, len(df)-window_size+1, step):end = start + window_sizewindow = df.iloc[start:end, :n_channels].values # (100,8)# 维度校验if window.ndim == 1:window = window.reshape(-1, 1)elif window.shape[1] != n_channels:raise ValueError(f"窗口通道数异常: {window.shape}")windows.append(window)print(f"[2/5] 窗口分割完成 | 总窗口数: {len(windows)} | 窗口形状: {windows[0].shape}")# 3. 数据增强generator = SEMGDataGenerator(noise_scale=0.05)augmented = []for w in windows:augmented.append(w)for _ in range(augment_times):try:aug_w = generator.augment(w)# 检查增强结果if not np.isfinite(aug_w).all():raise ValueError("增强生成无效值")augmented.append(aug_w)except Exception as e:print(f"增强失败: {e}")continueprint(f"[3/5] 数据增强完成 | 总样本数: {len(augmented)} (原始x{augment_times+1})")# 4. 形状一致性校验shape_counts = defaultdict(int)for arr in augmented:shape_counts[arr.shape] += 1target_shape = max(shape_counts, key=shape_counts.get)filtered = [arr for arr in augmented if arr.shape == target_shape]print(f"[4/5] 形状过滤完成 | 有效样本率: {len(filtered)}/{len(augmented)}")# 转换为数组features = np.stack(filtered)assert not np.isnan(features).any(), "增强数据中存在NaN"assert not np.isinf(features).any(), "增强数据中存在Inf"labels = np.full(len(filtered), label)return features, labels
# -------------------- 第三部分:标准化与数据集划分 --------------------
def channel_standardize(data):"""逐通道标准化"""# data形状: (samples, timesteps, channels)mean = np.nanmean(data, axis=(0,1), keepdims=True)std = np.nanstd(data, axis=(0,1), keepdims=True)# 防止除零错误:若标准差为0,设置为1std_fixed = np.where(std == 0, 1.0, std)return (data - mean) / (std_fixed + 1e-8)
# -------------------- 执行主流程 --------------------
if __name__ == "__main__":# 数据加载与增强X_healthy, y_healthy = load_and_preprocess('Healthy_Subjects_Data3_DOF.csv', label=1.0,window_size=100,augment_times=5)X_patient, y_patient = load_and_preprocess('Stroke_Patients_DataPatient1_3DOF.csv',label=0.0,window_size=100,augment_times=5)# 合并数据集X = np.concatenate([X_healthy, X_patient], axis=0)y = np.concatenate([y_healthy, y_patient], axis=0)print(f"\n合并数据集形状: X{X.shape} y{y.shape}")# 数据标准化X = channel_standardize(X)# 数据集划分X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, stratify=y,random_state=SEED)print("\n最终数据集:")print(f"训练集: {X_train.shape} | 0类样本数: {np.sum(y_train==0)}")print(f"验证集: {X_val.shape} | 1类样本数: {np.sum(y_val==1)}")# 验证标准化效果sample_channel = 0print(f"\n标准化验证 (通道{sample_channel}):")print(f"均值: {np.mean(X_train[:, :, sample_channel]):.2f} (±{np.std(X_train[:, :, sample_channel]):.2f})")
# -------------------- 第三部分:模型架构 --------------------
def build_model(input_shape):"""混合CNN+BiGRU模型"""inputs = layers.Input(shape=input_shape)# 特征提取分支x = layers.Conv1D(32, 15, activation='relu', padding='same')(inputs)x = layers.MaxPooling1D(2)(x)x = layers.Conv1D(64, 7, activation='relu', padding='same')(x)x = layers.MaxPooling1D(2)(x)x = layers.Bidirectional(layers.GRU(32, return_sequences=True))(x)# 差异注意力机制attention = layers.Attention()([x, x])x = layers.Concatenate()([x, attention])# 回归输出层x = layers.GlobalAveragePooling1D()(x)x = layers.Dense(16, activation='relu')(x)outputs = layers.Dense(1, activation='sigmoid')(x)model = tf.keras.Model(inputs, outputs)return model# 初始化模型
model = build_model(input_shape=(100, 8))
model.compile(optimizer=optimizers.Adam(learning_rate=0.001),loss='binary_crossentropy',metrics=['accuracy', tf.keras.metrics.AUC(name='auc')]
)
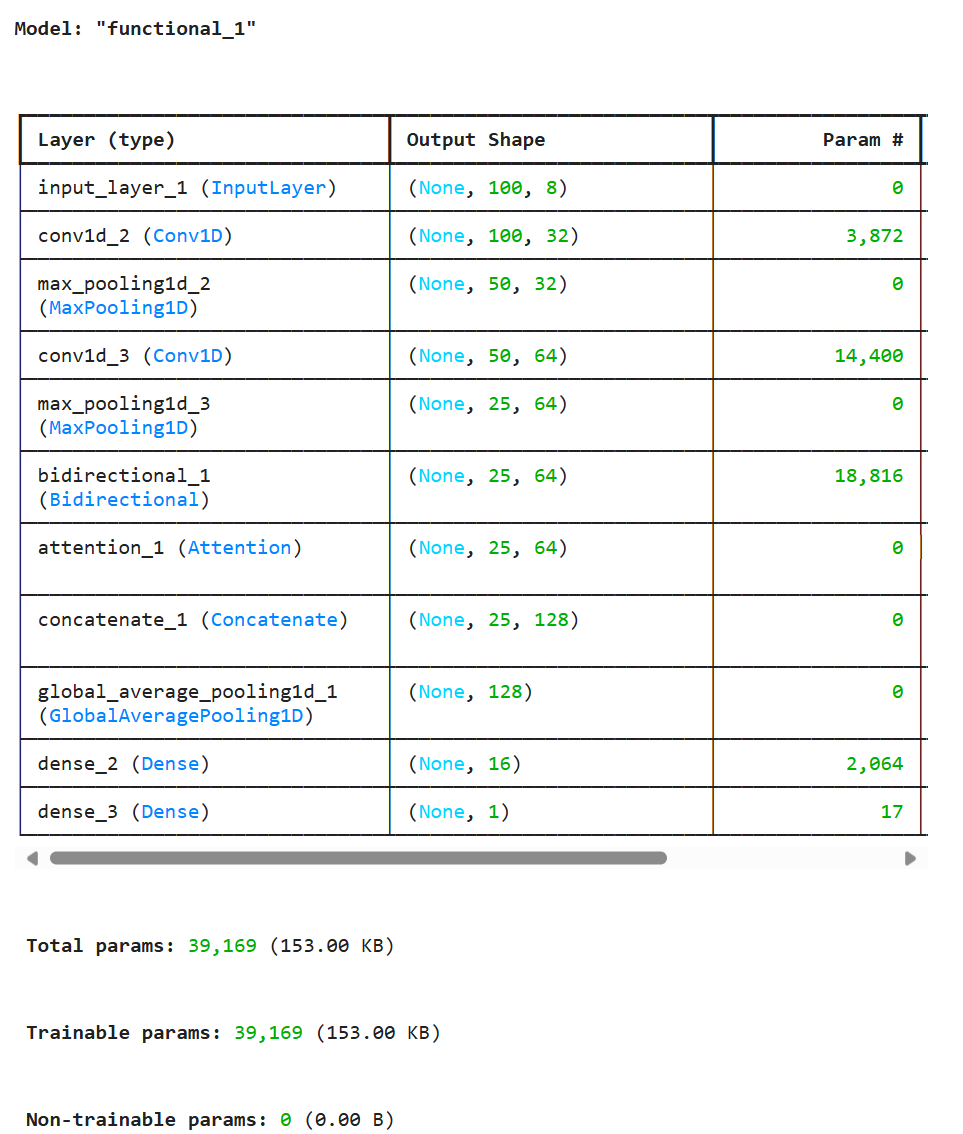
model.summary()
# -------------------- 第四部分:模型训练 --------------------
# 定义回调
early_stop = callbacks.EarlyStopping(monitor='val_auc', patience=10,mode='max',restore_best_weights=True
)# 训练模型
history = model.fit(X_train, y_train,validation_data=(X_val, y_val),epochs=100,batch_size=32,callbacks=[early_stop],verbose=1
)
# -------------------- 第五部分:康复评估与可视化 --------------------
# 训练过程可视化
plt.figure(figsize=(12,4))
plt.subplot(131)
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Loss Curve')
plt.legend()plt.subplot(132)
plt.plot(history.history['auc'], label='Train AUC')
plt.plot(history.history['val_auc'], label='Validation AUC')
plt.title('AUC Curve')
plt.legend()# 生成康复报告
def generate_report(model, patient_data):"""生成定量康复评估报告"""# 预测所有窗口predictions = model.predict(patient_data).flatten()# 计算康复指数(0-100%)recovery_index = np.mean(predictions) * 100# 可视化预测分布plt.subplot(133)plt.hist(predictions, bins=20, alpha=0.7)plt.axvline(x=np.mean(predictions), color='red', linestyle='--')plt.title('Prediction Distribution\nMean R-index: %.1f%%' % recovery_index)# 生成文字报告print(f"""======== 智能康复评估报告 ========分析窗口总数:{len(patient_data)}平均康复指数:{recovery_index:.1f}%最佳窗口表现:{np.max(predictions)*100:.1f}%最弱窗口表现:{np.min(predictions)*100:.1f}%--------------------------------临床建议:{ "建议加强基础动作训练" if recovery_index <40 else "建议进行中等强度康复训练" if recovery_index <70 else "建议开展精细动作训练" if recovery_index <90 else "接近健康水平,建议维持训练"}""")# 使用患者数据生成报告
generate_report(model, X_patient)plt.tight_layout()
plt.show()模型结果:
前8列统计描述:0 -2 -2.1 -3 -1 \ count 14970.000000 14970.000000 14970.000000 14970.000000 14970.000000 mean -0.867602 -1.022044 -1.174883 -1.057315 -0.926921 std 4.919823 8.380565 20.082498 11.550257 6.344825 min -128.000000 -128.000000 -128.000000 -128.000000 -92.000000 25% -3.000000 -3.000000 -3.000000 -3.000000 -3.000000 50% -1.000000 -1.000000 -1.000000 -1.000000 -1.000000 75% 1.000000 2.000000 1.000000 2.000000 1.000000 max 80.000000 79.000000 127.000000 127.000000 116.000000 -2.2 -1.1 -2.3 count 14970.000000 14970.000000 14970.000000 mean -0.824916 -0.888377 -0.901804 std 10.461558 7.863457 12.304696 min -128.000000 -128.000000 -128.000000 25% -3.000000 -3.000000 -3.000000 50% -1.000000 -1.000000 -1.000000 75% 1.000000 1.000000 1.000000 max 127.000000 127.000000 127.000000 [1/5] 数据加载完成 | 原始数据形状: (14970, 8) [2/5] 窗口分割完成 | 总窗口数: 298 | 窗口形状: (100, 8) [3/5] 数据增强完成 | 总样本数: 1788 (原始x6) [4/5] 形状过滤完成 | 有效样本率: 1788/1788 前8列统计描述:-1 -1.1 2 -1.2 -1.3 \ count 14970.000000 14970.000000 14970.000000 14970.000000 14970.000000 mean -1.065531 -0.838009 -2.973747 -0.028925 -0.857916 std 33.651163 17.704589 49.101199 34.155909 13.400751 min -128.000000 -128.000000 -128.000000 -128.000000 -128.000000 25% -8.000000 -6.000000 -13.000000 -7.000000 -5.000000 50% -1.000000 -1.000000 -1.000000 -1.000000 -1.000000 75% 6.000000 5.000000 6.000000 6.000000 4.000000 max 127.000000 127.000000 127.000000 127.000000 89.000000 3 0 -6 count 14970.000000 14970.000000 14970.000000 mean -0.868003 -0.794990 -0.784636 std 12.125684 12.950926 20.911681 min -73.000000 -128.000000 -128.000000 25% -6.000000 -6.000000 -5.000000 50% 0.000000 -1.000000 -1.000000 75% 5.000000 4.000000 4.000000 max 85.000000 127.000000 127.000000 [1/5] 数据加载完成 | 原始数据形状: (14970, 8) [2/5] 窗口分割完成 | 总窗口数: 298 | 窗口形状: (100, 8) [3/5] 数据增强完成 | 总样本数: 1788 (原始x6) [4/5] 形状过滤完成 | 有效样本率: 1788/1788合并数据集形状: X(3576, 100, 8) y(3576,)最终数据集: 训练集: (2860, 100, 8) | 0类样本数: 1430 验证集: (716, 100, 8) | 1类样本数: 358标准化验证 (通道0): 均值: 0.00 (±0.99)
Epoch 1/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 3s 14ms/step - accuracy: 0.6373 - auc: 0.8087 - loss: 0.5779 - val_accuracy: 0.8575 - val_auc: 0.9439 - val_loss: 0.3450 Epoch 2/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.8715 - auc: 0.9368 - loss: 0.3158 - val_accuracy: 0.9232 - val_auc: 0.9812 - val_loss: 0.1800 Epoch 3/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9382 - auc: 0.9836 - loss: 0.1598 - val_accuracy: 0.9469 - val_auc: 0.9909 - val_loss: 0.1401 Epoch 4/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9529 - auc: 0.9877 - loss: 0.1329 - val_accuracy: 0.9413 - val_auc: 0.9927 - val_loss: 0.1423 Epoch 5/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9609 - auc: 0.9934 - loss: 0.1030 - val_accuracy: 0.9553 - val_auc: 0.9935 - val_loss: 0.1235 Epoch 6/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9760 - auc: 0.9955 - loss: 0.0785 - val_accuracy: 0.9567 - val_auc: 0.9938 - val_loss: 0.1308 Epoch 7/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - accuracy: 0.9798 - auc: 0.9962 - loss: 0.0720 - val_accuracy: 0.9609 - val_auc: 0.9937 - val_loss: 0.1027 Epoch 8/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - accuracy: 0.9830 - auc: 0.9974 - loss: 0.0595 - val_accuracy: 0.9316 - val_auc: 0.9883 - val_loss: 0.2068 Epoch 9/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9699 - auc: 0.9958 - loss: 0.0740 - val_accuracy: 0.9358 - val_auc: 0.9901 - val_loss: 0.1772 Epoch 10/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9717 - auc: 0.9961 - loss: 0.0688 - val_accuracy: 0.9679 - val_auc: 0.9923 - val_loss: 0.1051 Epoch 11/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9827 - auc: 0.9984 - loss: 0.0492 - val_accuracy: 0.9525 - val_auc: 0.9889 - val_loss: 0.1531 Epoch 12/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9910 - auc: 0.9992 - loss: 0.0342 - val_accuracy: 0.9651 - val_auc: 0.9919 - val_loss: 0.1138 Epoch 13/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9875 - auc: 0.9992 - loss: 0.0325 - val_accuracy: 0.9749 - val_auc: 0.9950 - val_loss: 0.0939 Epoch 14/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9935 - auc: 0.9997 - loss: 0.0166 - val_accuracy: 0.9721 - val_auc: 0.9890 - val_loss: 0.1144 Epoch 15/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9907 - auc: 0.9994 - loss: 0.0223 - val_accuracy: 0.9637 - val_auc: 0.9866 - val_loss: 0.1359 Epoch 16/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - accuracy: 0.9902 - auc: 0.9995 - loss: 0.0294 - val_accuracy: 0.9553 - val_auc: 0.9874 - val_loss: 0.1561 Epoch 17/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - accuracy: 0.9885 - auc: 0.9992 - loss: 0.0358 - val_accuracy: 0.9777 - val_auc: 0.9914 - val_loss: 0.0963 Epoch 18/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9980 - auc: 1.0000 - loss: 0.0068 - val_accuracy: 0.9609 - val_auc: 0.9877 - val_loss: 0.1386 Epoch 19/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9897 - auc: 0.9997 - loss: 0.0230 - val_accuracy: 0.9651 - val_auc: 0.9880 - val_loss: 0.1363 Epoch 20/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9994 - auc: 1.0000 - loss: 0.0029 - val_accuracy: 0.9693 - val_auc: 0.9858 - val_loss: 0.1438 Epoch 21/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 1.0000 - auc: 1.0000 - loss: 0.0018 - val_accuracy: 0.9721 - val_auc: 0.9860 - val_loss: 0.1456 Epoch 22/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 1.0000 - auc: 1.0000 - loss: 3.3242e-04 - val_accuracy: 0.9735 - val_auc: 0.9835 - val_loss: 0.1461 Epoch 23/100 90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 1.0000 - auc: 1.0000 - loss: 2.1834e-04 - val_accuracy: 0.9721 - val_auc: 0.9836 - val_loss: 0.1492[ ]:
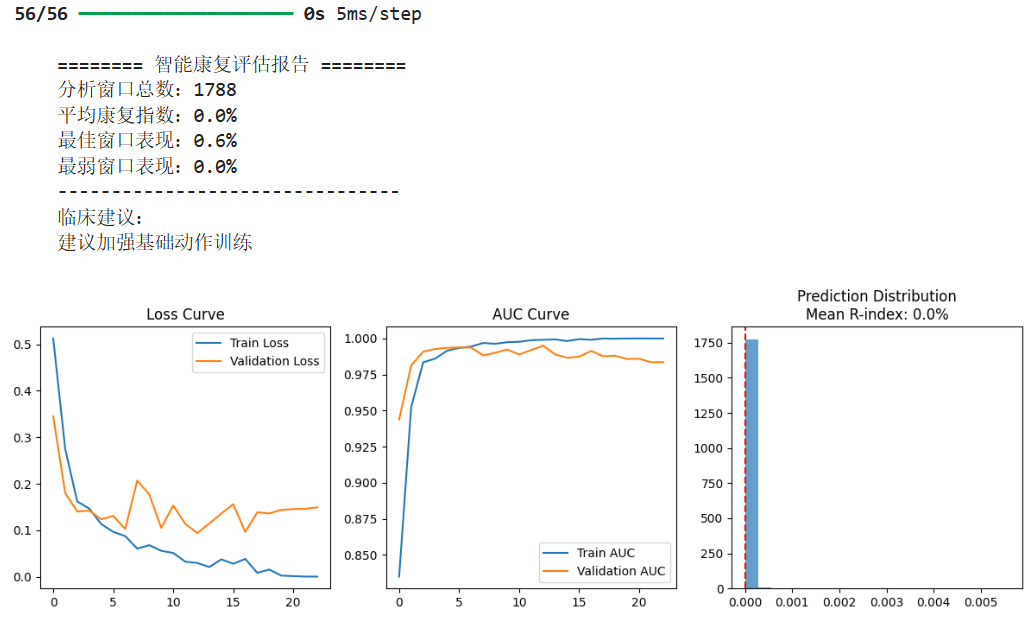
结果分析:
一、性能亮点
-
极高的训练指标
- 训练准确率(Accuracy):从第1轮的63.73%快速提升到第22轮的100%,说明模型完全拟合了训练数据。
- 训练AUC:从0.8087上升到1.0,表明模型对训练数据的分类能力达到完美。
-
验证集表现优秀
- 验证准确率:最终稳定在 97.35%(第23轮),说明模型泛化能力较强。
- 验证AUC:最高达到 0.995(第13轮),接近完美分类(AUC=1.0)。
-
快速收敛
- 模型在前5轮内就达到了90%以上的验证准确率,表明架构设计合理且数据质量较高。
二、潜在问题
1. 严重过拟合
- 训练 vs 验证差距:
- 训练准确率最终为100%,而验证准确率最高97.35%(差距2.65%)。
- 训练AUC为1.0,验证AUC最高0.995(差距0.5%)。
- 验证损失波动:
- 验证损失(
val_loss)在第8轮后出现明显波动(如第8轮0.2068 → 第17轮0.0963 → 第23轮0.1492),表明模型对验证集的泛化能力不稳定。
- 验证损失(
2. 过拟合的直接证据
- 训练指标饱和:
- 从第15轮开始,训练准确率和AUC均达到100%,但验证指标未同步提升,甚至出现下降(如第22轮验证AUC从0.995降到0.9835)。
- 极端损失值:
- 训练损失(
loss)在第22轮降至0.00033,而验证损失(val_loss)维持在0.1461,差距显著。
- 训练损失(
3. 可能的过拟合原因
- 模型复杂度过高:
LSTM层可能过于复杂(如神经元过多或层数过深),导致模型记住了训练数据噪声。 - 数据增强不足:
尽管使用了时间扭曲等增强策略,可能仍不足以模拟真实场景的多样性。 - 类别不平衡:
验证集正样本数(358)远少于负样本(1430),可能导致模型偏向多数类。
三、改进建议
1. 抑制过拟合
- 增加正则化:
python
复制
model.add(layers.Dropout(0.5)) # 在LSTM层后添加Dropout model.add(layers.LSTM(64, kernel_regularizer='l2')) # L2正则化 - 简化模型:
减少LSTM层神经元数量(如从64→32)或层数(如移除一层LSTM)。 - 早停策略优化:
设置更严格的早停耐心值(如patience=5),防止在验证损失波动时继续训练。
2. 数据增强优化
- 增强强度调整:
增大时间扭曲范围(如stretch_range=(0.5, 1.5))或噪声强度(noise_scale=0.2)。 - 引入更多增强:
添加通道随机丢弃(Channel Dropout)或时间反转(Time Reverse)。
3. 类别不平衡处理
- 损失函数加权:
python
复制
model.compile(loss=BinaryFocalLoss(gamma=2), ...) # 使用Focal Loss # 或 class_weight = {0: 1.0, 1: 5.0} # 增加少数类权重 model.fit(..., class_weight=class_weight)
4. 验证集扩展
- 增大验证集比例:
从test_size=0.2调整为test_size=0.3,提高验证结果可信度。
四、性能总结
| 指标 | 训练集 | 验证集 | 结论 |
|---|---|---|---|
| 最终准确率 | 100% | 97.35% | 优秀但需警惕过拟合 |
| 最终AUC | 1.0 | 0.9836 | 接近完美分类,泛化能力较强 |
| 训练/验证损失 | 0.0002 | 0.1492 | 过拟合明显,需优化正则化策略 |
五、下一步行动
- 可视化学习曲线
python
复制
plt.plot(history.history['accuracy'], label='Train Accuracy') plt.plot(history.history['val_accuracy'], label='Val Accuracy') plt.legend(); plt.show() - 混淆矩阵分析
python
复制
from sklearn.metrics import confusion_matrix y_pred = model.predict(X_val) > 0.5 print(confusion_matrix(y_val, y_pred)) - 错误样本分析
检查验证集中被错误分类的样本,识别模型盲区(如特定运动模式或传感器异常)。
通过以上改进,模型可进一步提升鲁棒性和泛化能力,适应真实场景需求。