时间序列预测算法中的预测概率化笔记
文章目录
- 1 预测概率化的前情提要
- 2 预测概率化的代码示例
- 3 预测概率化在实际商业应用场景探索
- 3.1 智能库存与供应链优化
1 预测概率化的前情提要
笔者看到【行业SOTA,京东首个自研十亿级时序大模型揭秘】提到:
预测概率化组件:由于大部分纯时序大模型输出的是确定性的预测,没有预测的概率,这样无法计算RL中KL散度,策略概率的损失,我们构建了一个公用的组件,适配所有的时序模型(不限于大模型),我们利用分布建模的方法,将时序的预测以及好坏的预测假设服从N(μ,1)的正态分布,对于均值的计算则直接利用输出的预测的均值则可以计算而成,这样可以快速输出预测的概率。
大多数传统时序模型只输出一个确定性预测值,假设是预测销量,实际上,真实销量很少会正好是100件,它可能在98到102之间波动,或者有更宽的范围。
强化学习(RL)在做决策时,比如决定备多少货,它不仅想知道“最可能”的销量是多少,更想知道各种可能销量发生的“概率”。比如,备100件货,亏损的概率是多大?备105件货,过剩的风险有多高?这些都离不开概率信息。
文章中提到,多元时序模型给出一个确定性预测值(比如100件)时,这个组件并不会直接用这个100。它会把这个100视为一个中心点或均值。
然后,它假设实际的销量会以这个中心点为基础,在一个钟形曲线(即正态分布)的范围内波动。
“钟形曲线” N(μ,1) 的解读:
- μ(均值): 这个就是你的时序模型预测出来的那个确定性销量值。比如,如果时序预测是100件,那么这个概率分布的中心就是100。
- 1(方差): 它强制规定这个钟形曲线的“胖瘦”(即不确定性)是固定的,方差永远是1。为什么要固定为1? 是为了简化和标准化,为了让所有预测都能快速转换为RLHF所需的概率格式,组件选择了一个固定的、简单的方差,让RLHF能够统一地处理这些概率信息,从而方便地计算KL散度
2 预测概率化的代码示例
让大模型给出一些多元时序预测的案例:
import numpy as np
import pandas as pd
import xgboost as xgb # 用于模拟XGBoost模型
from sklearn.model_selection import train_test_split
from scipy.stats import norm # 用于构建N(μ,1)正态分布
import matplotlib.pyplot as plt
import seaborn as sns# 设置绘图风格
sns.set_theme(style="whitegrid")# --- 1. 模拟多元时间序列数据 ---
# 假设我们有销量、价格、促销活动(0/1)作为特征
np.random.seed(42) # 为了结果可复现# 创建时间索引
dates = pd.date_range(start='2023-01-01', periods=100, freq='D')# 模拟目标变量:销量
sales = 100 + np.sin(np.arange(100) / 10) * 20 + np.random.normal(0, 5, 100)
# 模拟特征:价格(与销量负相关),促销活动(与销量正相关)
price = 50 - np.cos(np.arange(100) / 10) * 10 + np.random.normal(0, 2, 100)
promotion = np.random.randint(0, 2, 100) # 0: 无促销, 1: 有促销# 创建DataFrame
data = pd.DataFrame({'sales': sales, 'price': price, 'promotion': promotion}, index=dates)print("--- 模拟多元时间序列数据 (部分) ---")
print(data.head())
print("\n")# --- 2. 模拟XGBoost模型进行预测 ---
# 在多元时间序列预测中,通常会构建滞后特征 (lag features)
def create_lag_features(df, target_col, lags):"""为目标列创建滞后特征"""df_lagged = df.copy()for lag in lags:df_lagged[f'{target_col}_lag_{lag}'] = df_lagged[target_col].shift(lag)return df_lagged# 为销量创建滞后特征
lags = [1, 2, 7] # 假设考虑前1天、前2天和前7天的销量
data_with_lags = create_lag_features(data, 'sales', lags)# 移除含有NaN的行 (由于滞后特征导致)
data_with_lags = data_with_lags.dropna()# 定义特征 (X) 和目标 (y)
features = [f'sales_lag_{lag}' for lag in lags] + ['price', 'promotion']
X = data_with_lags[features]
y = data_with_lags['sales']# 划分训练集和测试集 (简单的时间序列划分,通常是按时间点划分)
# 这里为了演示简单,我们取最后1行为测试集进行预测
X_train = X.iloc[:-1]
y_train = y.iloc[:-1]
X_test = X.iloc[-1:] # 用于预测的最新一行数据print("--- XGBoost 模型训练与预测 ---")
# 初始化并训练XGBoost回归模型
xgb_model = xgb.XGBRegressor(objective='reg:squarederror', n_estimators=100, random_state=42)
xgb_model.fit(X_train, y_train)# 使用训练好的XGBoost模型进行预测
# .predict() 方法会返回一个确定性的预测值数组
xgboost_deterministic_prediction = xgb_model.predict(X_test)[0] # 取第一个预测值print(f"XGBoost模型预测的未来销量 (确定性预测): {xgboost_deterministic_prediction:.2f} 件")
print("\n")# --- 3. 【预测概率化组件】的实现 ---
def probabilistic_prediction_component(deterministic_forecast: float):"""【预测概率化组件】的核心逻辑:将一个确定性预测值转换为一个N(μ, 1)的正态概率分布。Args:deterministic_forecast (float): 从时序模型(如XGBoost)获得的确定性预测值。Returns:scipy.stats._distn_infrastructure.rv_continuous_frozen:一个表示N(μ, 1)正态分布的frozen分布对象。"""# 均值 (μ):直接使用时序模型(XGBoost)给出的确定性预测值。# 这是构建正态分布的中心点。mean_of_distribution = deterministic_forecast# 方差固定为1,因此标准差 (σ) 也是1。# 这是该组件的标准化处理,意味着所有预测的“不确定性宽度”是统一的。std_dev_of_distribution = 1.0# 构建并返回一个正态分布对象。# norm(loc=mean, scale=std_dev) 创建一个正态分布,# loc是均值,scale是标准差。probabilistic_dist = norm(loc=mean_of_distribution, scale=std_dev_of_distribution)return probabilistic_distprint("--- 应用【预测概率化组件】 ---")
# 应用组件,将XGBoost的确定性预测转化为概率分布
sales_prob_distribution = probabilistic_prediction_component(xgboost_deterministic_prediction)print(f"经组件处理后,销量预测被表示为一个均值为 {sales_prob_distribution.mean():.2f},")
print(f"标准差为 {sales_prob_distribution.std():.2f} 的正态分布。")# --- 4. 如何利用这个概率分布进行强化学习相关计算 (示例) ---# 例如,计算某个销量值(例如95.0件)在当前分布下的概率密度
target_sales_value = 95.0
pdf_at_target = sales_prob_distribution.pdf(target_sales_value)
print(f"\n在当前概率分布下,销量为 {target_sales_value:.1f} 件的概率密度: {pdf_at_target:.4f}")# 计算销量在某个范围内的概率(例如,销量在 90.0 到 100.0 之间)
lower_bound = 90.0
upper_bound = 100.0
# CDF (Cumulative Distribution Function) 给出小于或等于某个值的累积概率
probability_in_range = sales_prob_distribution.cdf(upper_bound) - sales_prob_distribution.cdf(lower_bound)
print(f"销量在 {lower_bound:.1f} 到 {upper_bound:.1f} 件之间的概率: {probability_in_range:.4f}")# --- 5. 可视化这个概率分布 ---
# 生成一系列可能的销量值,用于绘制概率密度函数 (PDF) 曲线
# 范围通常取均值上下几个标准差(这里取均值±4个标准差)
x_values = np.linspace(xgboost_deterministic_prediction - 4, xgboost_deterministic_prediction + 4, 500)# 计算每个销量值对应的概率密度
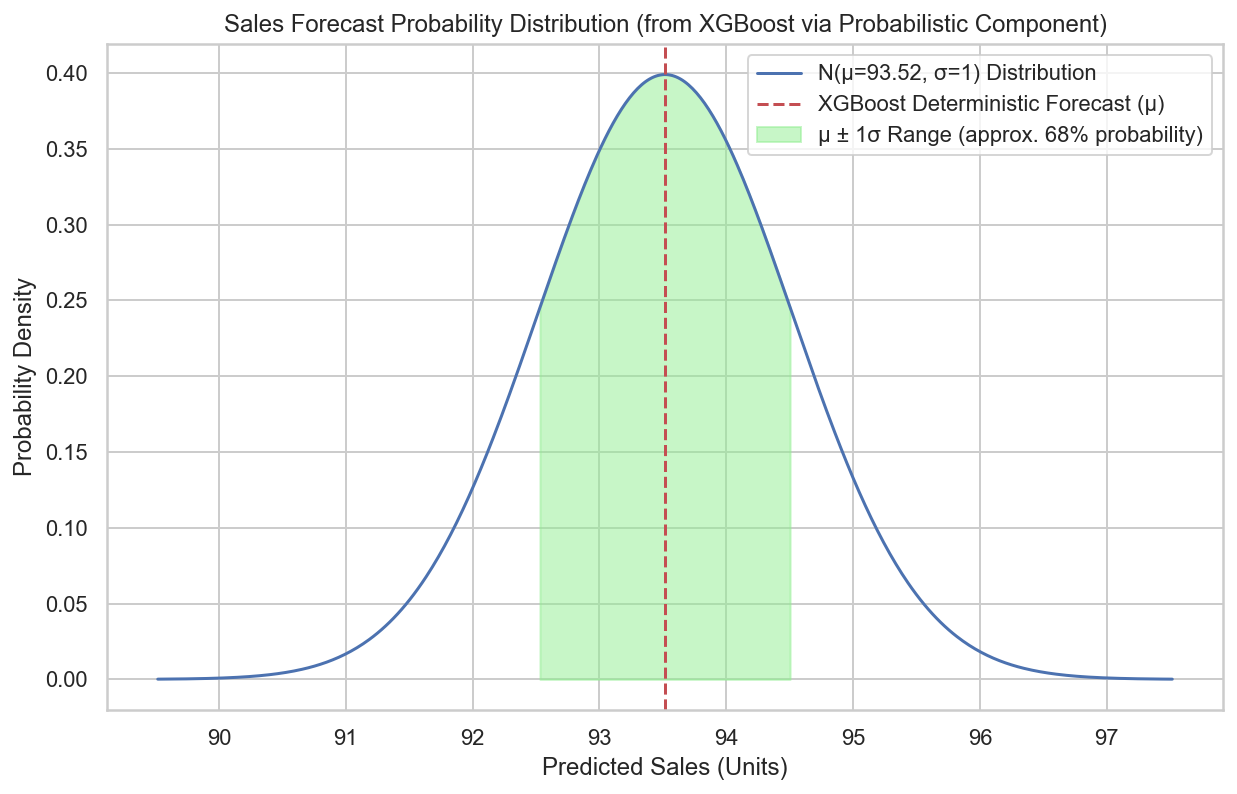
pdf_values = sales_prob_distribution.pdf(x_values)plt.figure(figsize=(10, 6))
plt.plot(x_values, pdf_values, label=f'N(μ={xgboost_deterministic_prediction:.2f}, σ=1) 分布')plt.title('XGBoost预测销量经【预测概率化组件】处理后的概率分布')
plt.xlabel('预测销量 (件)')
plt.ylabel('概率密度')
plt.axvline(xgboost_deterministic_prediction, color='r', linestyle='--', label='XGBoost确定性预测值 (μ)')
plt.fill_between(x_values, 0, pdf_values,where=(x_values >= (xgboost_deterministic_prediction - 1)) & (x_values <= (xgboost_deterministic_prediction + 1)),color='lightgreen', alpha=0.5, label='μ ± 1σ 范围 (约68%概率)')
plt.legend()
plt.grid(True)
plt.show()
最终会输出:
--- 模拟多元时间序列数据 (部分) ---sales price promotion
2023-01-01 102.483571 37.169259 1
2023-01-02 101.305347 39.208668 1
2023-01-03 107.211829 39.513905 0
2023-01-04 113.525553 38.842081 1
2023-01-05 106.617600 40.466819 0--- XGBoost 模型训练与预测 ---
XGBoost模型预测的未来销量 (确定性预测): 93.52 件--- 应用【预测概率化组件】 ---
经组件处理后,销量预测被表示为一个均值为 93.52,
标准差为 1.00 的正态分布。在当前概率分布下,销量为 95.0 件的概率密度: 0.1328
销量在 90.0 到 100.0 件之间的概率: 0.9998
3 预测概率化在实际商业应用场景探索
3.1 智能库存与供应链优化
举例思考:在化妆品公司如何应用这一组件
预测概率化组件的核心在于将一个单一的、确定的销量预测(比如“下个月卖出1000支口红”),转化成一个包含不确定性信息的概率分布(比如“下个月有95%的几率销量在950到1050支之间”)。
如果销量预测模型预测下个月销量是15,000支,传统上可能会直接安排生产15,000支。如果实际销量是15,500支,就可能卖断货;如果是14,500支,就会有500支积压。
假设: 对于明星产品,公司决定将缺货风险控制在2%。这意味着,他们希望有98%的几率能够满足所有客户的需求。
利用步骤2得到的 N ( 15000 , 1 ) N(15000,1) N(15000,1)概率分布,找到其累积概率达到98%时的销量值(这个值被称为98%分位数)。这个值就是为了确保98%的需求都能被满足,我们总共需要准备的库存量。
来看看一个较为完整的利用该组件数据驱动步骤步骤:
- 我们知道销量分布是 N ( 15000 , 1 ) N(15000,1) N(15000,1)。
- 通过统计计算(例如使用Python的
scipy.stats.norm.ppf(0.98, loc=15000, scale=1)),可以得出大约是 15,001.95支。 - 向上取整,为确保98%的需求满足几率,公司需要的总库存量是15,002支。
- 缓冲库存量 = 15,002支 - 15,000支 = 2支。这2支就是为了应对那2%的“销量超出预测”的风险而准备的。
- 最终生产/补货量决策:假设目前仓库中“明星产品”的现有库存为 500支,下个月需要安排生产的量 = 15,002支(目标总库存) - 500支(当前库存) = 14,502支