第 85 场周赛:矩阵重叠、推多米诺、新 21 点、相似字符串组
Q1、[简单] 矩阵重叠
1、题目描述
矩形以列表 [x1, y1, x2, y2] 的形式表示,其中 (x1, y1) 为左下角的坐标,(x2, y2) 是右上角的坐标。矩形的上下边平行于 x 轴,左右边平行于 y 轴。
如果相交的面积为 正 ,则称两矩形重叠。需要明确的是,只在角或边接触的两个矩形不构成重叠。
给出两个矩形 rec1 和 rec2 。如果它们重叠,返回 true;否则,返回 false 。
示例 1:
输入:rec1 = [0,0,2,2], rec2 = [1,1,3,3] 输出:true示例 2:
输入:rec1 = [0,0,1,1], rec2 = [1,0,2,1] 输出:false示例 3:
输入:rec1 = [0,0,1,1], rec2 = [2,2,3,3] 输出:false提示:
rect1.length == 4rect2.length == 4-109 <= rec1[i], rec2[i] <= 109rec1和rec2表示一个面积不为零的有效矩形
2、解题思路
-
问题分析:
- 两个矩形重叠的条件是它们在
x轴和y轴上的投影都有重叠。 - 具体来说,矩形
rec1和rec2在x轴上的投影分别为[x1, x2]和[x3, x4],在y轴上的投影分别为[y1, y2]和[y3, y4]。 - 两个矩形重叠的条件是:
- 在
x轴上:rec1的右边界大于rec2的左边界,且rec1的左边界小于rec2的右边界。 - 在
y轴上:rec1的上边界大于rec2的下边界,且rec1的下边界小于rec2的上边界。
- 在
- 两个矩形重叠的条件是它们在
-
算法设计:
- 直接检查上述条件是否同时满足。
-
优化:
- 使用简单的条件判断,时间复杂度为 O(1)。
3、代码实现
C++
class Solution {
public:bool isRectangleOverlap(vector<int>& rec1, vector<int>& rec2) {// 检查 x 轴和 y 轴上的投影是否重叠if (rec1[2] > rec2[0] && rec1[3] > rec2[1] && rec1[0] < rec2[2] && rec1[1] < rec2[3]) {return true; // 如果重叠,返回 true}return false; // 否则返回 false}
};
Java
class Solution {public boolean isRectangleOverlap(int[] rec1, int[] rec2) {// 检查 x 轴和 y 轴上的投影是否重叠if (rec1[2] > rec2[0] && rec1[3] > rec2[1] && rec1[0] < rec2[2] && rec1[1] < rec2[3]) {return true; // 如果重叠,返回 true}return false; // 否则返回 false}
}
Python
class Solution:def isRectangleOverlap(self, rec1: List[int], rec2: List[int]) -> bool:# 检查 x 轴和 y 轴上的投影是否重叠if rec1[2] > rec2[0] and rec1[3] > rec2[1] and rec1[0] < rec2[2] and rec1[1] < rec2[3]:return True # 如果重叠,返回 Truereturn False # 否则返回 False
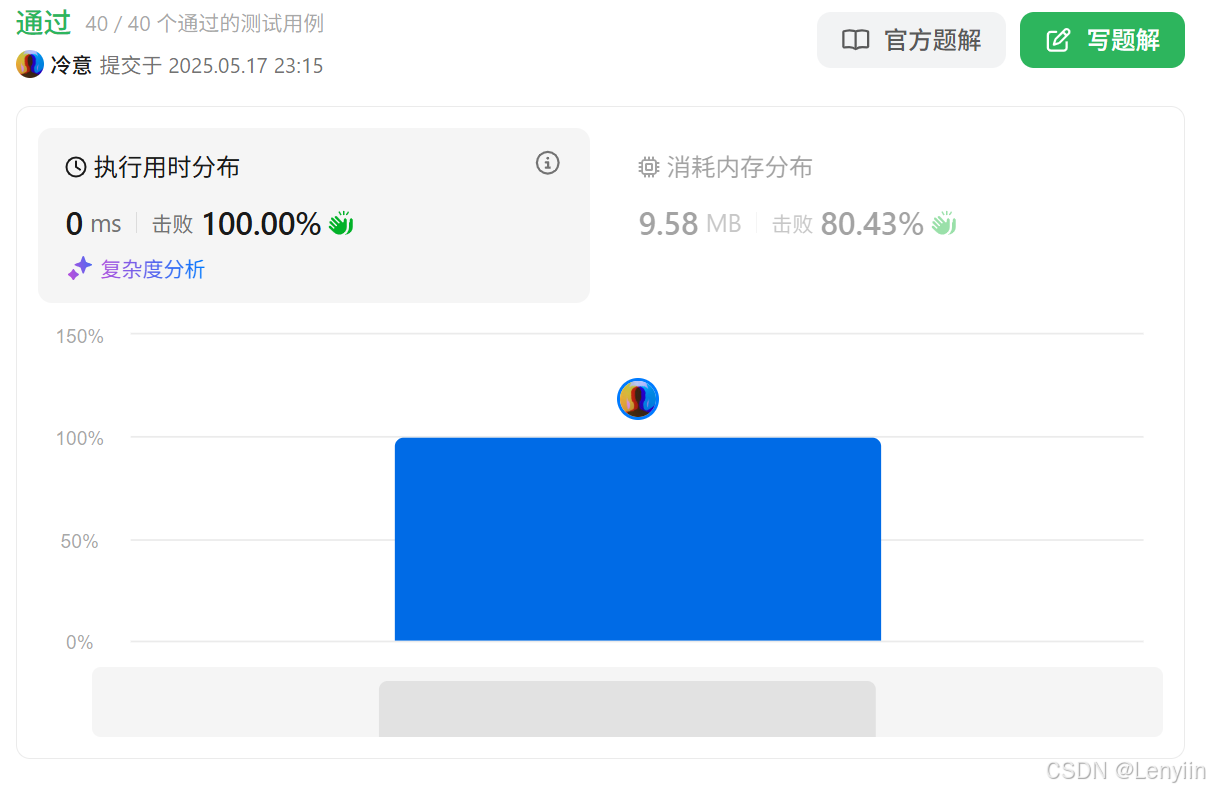
4、复杂度分析
- 时间复杂度:
- 仅需进行常数次比较操作,时间复杂度为 O(1)。
- 空间复杂度:
- 仅使用常数级别的额外空间,空间复杂度为 O(1)。
Q2、[中等] 推多米诺
1、题目描述
n 张多米诺骨牌排成一行,将每张多米诺骨牌垂直竖立。在开始时,同时把一些多米诺骨牌向左或向右推。
每过一秒,倒向左边的多米诺骨牌会推动其左侧相邻的多米诺骨牌。同样地,倒向右边的多米诺骨牌也会推动竖立在其右侧的相邻多米诺骨牌。
如果一张垂直竖立的多米诺骨牌的两侧同时有多米诺骨牌倒下时,由于受力平衡, 该骨牌仍然保持不变。
就这个问题而言,我们会认为一张正在倒下的多米诺骨牌不会对其它正在倒下或已经倒下的多米诺骨牌施加额外的力。
给你一个字符串 dominoes 表示这一行多米诺骨牌的初始状态,其中:
dominoes[i] = 'L',表示第i张多米诺骨牌被推向左侧,dominoes[i] = 'R',表示第i张多米诺骨牌被推向右侧,dominoes[i] = '.',表示没有推动第i张多米诺骨牌。
返回表示最终状态的字符串。
示例 1:
输入:dominoes = "RR.L" 输出:"RR.L" 解释:第一张多米诺骨牌没有给第二张施加额外的力。示例 2:
输入:dominoes = ".L.R...LR..L.." 输出:"LL.RR.LLRRLL.."提示:
n == dominoes.length1 <= n <= 105dominoes[i]为'L'、'R'或'.'

2、解题思路
- 问题分析:
- 多米诺骨牌的倒下是一个动态过程,需要模拟每一秒的变化。
- 每个被推动的骨牌会影响其相邻的骨牌,直到所有骨牌的状态稳定。
- 算法设计:
- 使用广度优先搜索(BFS)模拟多米诺骨牌的倒下过程。
- 初始化一个队列,将所有初始被推动的骨牌加入队列,并记录它们被推动的时间和方向。
- 对于每个骨牌,根据其被推动的方向,更新其相邻骨牌的状态,并将新被推动的骨牌加入队列。
- 如果某个骨牌同时受到两个方向的力,则它保持不动。
- 优化:
- 使用 BFS 确保按时间顺序处理骨牌的倒下过程。
- 使用
time数组记录每个骨牌被推动的时间,使用force数组记录每个骨牌受到的力。
3、代码实现
C++
class Solution {
public:string pushDominoes(string dominoes) {int n = dominoes.size(); // 获取骨牌的数量queue<int> q; // 用于 BFS 的队列vector<int> time(n, -1); // 记录每个骨牌被推动的时间vector<string> force(n); // 记录每个骨牌受到的力// 初始化队列,将所有初始被推动的骨牌加入队列for (int i = 0; i < n; ++i) {if (dominoes[i] != '.') {q.emplace(i);time[i] = 0;force[i].push_back(dominoes[i]);}}string res(n, '.'); // 初始化结果字符串while (!q.empty()) { // BFS 过程int i = q.front();q.pop();if (force[i].size() == 1) { // 如果当前骨牌只受到一个方向的力char f = force[i][0]; // 获取力的方向res[i] = f; // 更新结果int ni = (f == 'L') ? (i - 1) : (i + 1); // 计算相邻骨牌的索引if (ni >= 0 && ni < n) { // 检查相邻骨牌是否在范围内int t = time[i];if (time[ni] == -1) { // 如果相邻骨牌未被推动过q.emplace(ni); // 加入队列time[ni] = t + 1; // 记录被推动的时间force[ni].push_back(f); // 记录受到的力} else if (time[ni] == t + 1) { // 如果相邻骨牌在同一时间被推动force[ni].push_back(f); // 记录受到的力}}}}return res; // 返回最终结果}
};
Java
class Solution {public String pushDominoes(String dominoes) {int n = dominoes.length(); // 获取骨牌的数量Queue<Integer> q = new LinkedList<>(); // 用于 BFS 的队列int[] time = new int[n]; // 记录每个骨牌被推动的时间Arrays.fill(time, -1);List<Character>[] force = new ArrayList[n]; // 记录每个骨牌受到的力for (int i = 0; i < n; i++) {force[i] = new ArrayList<>();}// 初始化队列,将所有初始被推动的骨牌加入队列for (int i = 0; i < n; i++) {char c = dominoes.charAt(i);if (c != '.') {q.offer(i);time[i] = 0;force[i].add(c);}}char[] res = new char[n]; // 初始化结果数组Arrays.fill(res, '.');while (!q.isEmpty()) { // BFS 过程int i = q.poll();if (force[i].size() == 1) { // 如果当前骨牌只受到一个方向的力char f = force[i].get(0); // 获取力的方向res[i] = f; // 更新结果int ni = (f == 'L') ? (i - 1) : (i + 1); // 计算相邻骨牌的索引if (ni >= 0 && ni < n) { // 检查相邻骨牌是否在范围内int t = time[i];if (time[ni] == -1) { // 如果相邻骨牌未被推动过q.offer(ni); // 加入队列time[ni] = t + 1; // 记录被推动的时间force[ni].add(f); // 记录受到的力} else if (time[ni] == t + 1) { // 如果相邻骨牌在同一时间被推动force[ni].add(f); // 记录受到的力}}}}return new String(res); // 返回最终结果}
}
Python
class Solution:def pushDominoes(self, dominoes: str) -> str:n = len(dominoes) # 获取骨牌的数量q = deque() # 用于 BFS 的队列time = [-1] * n # 记录每个骨牌被推动的时间force = [[] for _ in range(n)] # 记录每个骨牌受到的力# 初始化队列,将所有初始被推动的骨牌加入队列for i, c in enumerate(dominoes):if c != '.':q.append(i)time[i] = 0force[i].append(c)res = ['.'] * n # 初始化结果数组while q: # BFS 过程i = q.popleft()if len(force[i]) == 1: # 如果当前骨牌只受到一个方向的力f = force[i][0] # 获取力的方向res[i] = f # 更新结果ni = i - 1 if f == 'L' else i + 1 # 计算相邻骨牌的索引if 0 <= ni < n: # 检查相邻骨牌是否在范围内t = time[i]if time[ni] == -1: # 如果相邻骨牌未被推动过q.append(ni) # 加入队列time[ni] = t + 1 # 记录被推动的时间force[ni].append(f) # 记录受到的力elif time[ni] == t + 1: # 如果相邻骨牌在同一时间被推动force[ni].append(f) # 记录受到的力return ''.join(res) # 返回最终结果
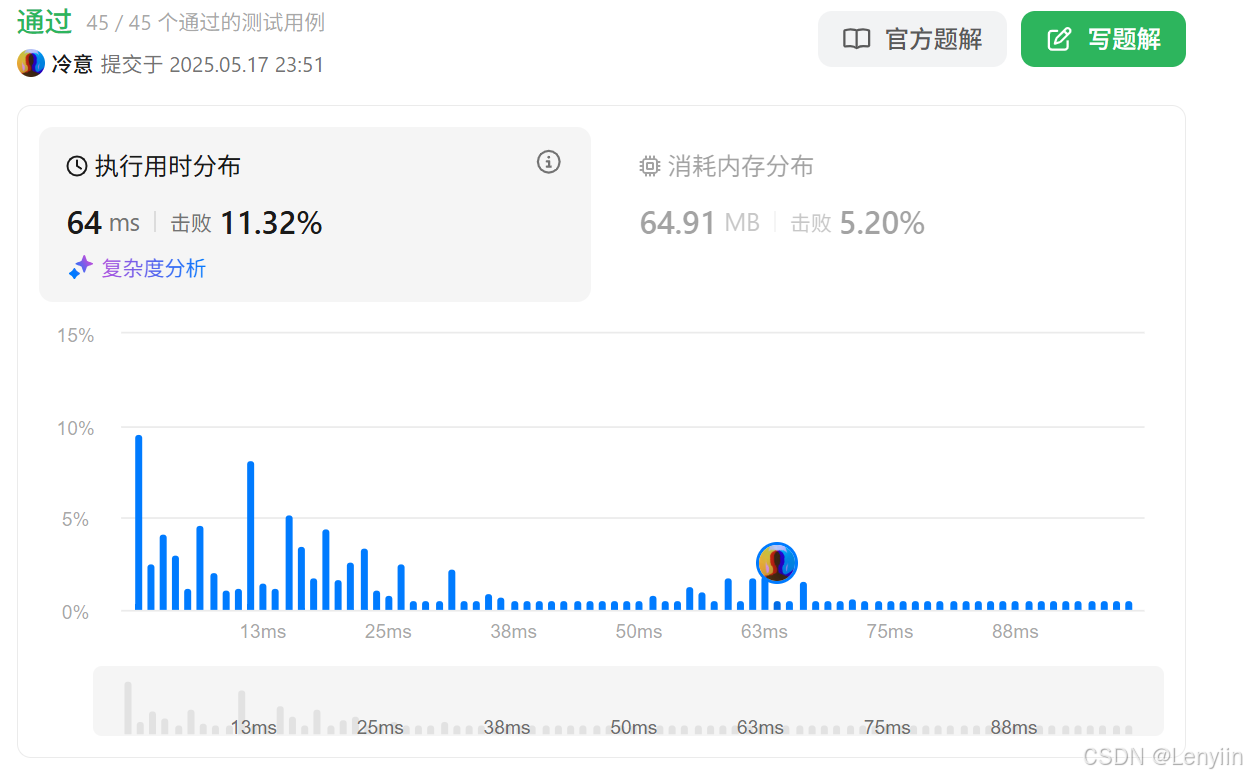
4、复杂度分析
- 时间复杂度:
- 每个骨牌最多被处理一次,时间复杂度为 O(n)。
- 空间复杂度:
- 使用队列、
time数组和force数组,空间复杂度为 O(n)。
- 使用队列、
Q3、[中等] 新 21 点
1、题目描述
爱丽丝参与一个大致基于纸牌游戏 “21点” 规则的游戏,描述如下:
爱丽丝以 0 分开始,并在她的得分少于 k 分时抽取数字。 抽取时,她从 [1, maxPts] 的范围中随机获得一个整数作为分数进行累计,其中 maxPts 是一个整数。 每次抽取都是独立的,其结果具有相同的概率。
当爱丽丝获得 k 分 或更多分 时,她就停止抽取数字。
爱丽丝的分数不超过 n 的概率是多少?
与实际答案误差不超过 10-5 的答案将被视为正确答案。
示例 1:
输入:n = 10, k = 1, maxPts = 10 输出:1.00000 解释:爱丽丝得到一张牌,然后停止。示例 2:
输入:n = 6, k = 1, maxPts = 10 输出:0.60000 解释:爱丽丝得到一张牌,然后停止。 在 10 种可能性中的 6 种情况下,她的得分不超过 6 分。示例 3:
输入:n = 21, k = 17, maxPts = 10 输出:0.73278提示:
0 <= k <= n <= 1041 <= maxPts <= 104
2、解题思路
-
问题分析:
- 爱丽丝的得分是一个随机过程,每次抽取的分数是
[1, maxPts]中的一个整数。 - 我们需要计算爱丽丝的得分不超过
n的概率。
- 爱丽丝的得分是一个随机过程,每次抽取的分数是
-
动态规划:
- 定义
dp[i]表示当爱丽丝当前得分为i时,最终得分不超过n的概率。 - 如果
i >= k,则爱丽丝停止抽取,dp[i] = 1(如果i <= n)或0(如果i > n)。 - 如果
i < k,则爱丽丝会继续抽取,dp[i]是dp[i+1]到dp[i+maxPts]的平均值。
- 定义
-
优化:
- 使用滑动窗口优化动态规划的计算,避免重复计算。
3、代码实现
C++
class Solution {
public:double new21Game(int n, int k, int maxPts) {if (k == 0) {return 1.0; // 如果 k 为 0, 爱丽丝直接停止, 得分不超过 n 的概率为 1}vector<double> dp(k + maxPts); // 定义 dp 数组for (int i = k; i <= n && i < k + maxPts; ++i) {dp[i] = 1.0; // 当 i >= k 且 i <= n 时, dp[i] = 1}// 计算 dp[k-1]dp[k - 1] = 1.0 * min(n - k + 1, maxPts) / maxPts;// 从 k-2 开始倒序计算 dp[i]for (int i = k - 2; i >= 0; i--) {dp[i] = dp[i + 1] - (dp[i + maxPts + 1] - dp[i + 1]) / maxPts;}return dp[0]; // 返回 dp[0], 即从 0 分开始的概率}
};
Java
class Solution {public double new21Game(int n, int k, int maxPts) {if (k == 0) {return 1.0; // 如果 k 为 0,爱丽丝直接停止,得分不超过 n 的概率为 1}double[] dp = new double[k + maxPts]; // 定义 dp 数组for (int i = k; i <= n && i < k + maxPts; i++) {dp[i] = 1.0; // 当 i >= k 且 i <= n 时,dp[i] = 1}// 计算 dp[k-1]dp[k - 1] = 1.0 * Math.min(n - k + 1, maxPts) / maxPts;// 从 k-2 开始倒序计算 dp[i]for (int i = k - 2; i >= 0; i--) {dp[i] = dp[i + 1] - (dp[i + maxPts + 1] - dp[i + 1]) / maxPts;}return dp[0]; // 返回 dp[0],即从 0 分开始的概率}
}
Python
class Solution:def new21Game(self, n: int, k: int, maxPts: int) -> float:if k == 0:return 1.0 # 如果 k 为 0,爱丽丝直接停止,得分不超过 n 的概率为 1dp = [0.0] * (k + maxPts) # 定义 dp 数组for i in range(k, min(n + 1, k + maxPts)):dp[i] = 1.0 # 当 i >= k 且 i <= n 时,dp[i] = 1# 计算 dp[k-1]dp[k - 1] = 1.0 * min(n - k + 1, maxPts) / maxPts# 从 k-2 开始倒序计算 dp[i]for i in range(k - 2, -1, -1):dp[i] = dp[i + 1] - (dp[i + maxPts + 1] - dp[i + 1]) / maxPtsreturn dp[0] # 返回 dp[0],即从 0 分开始的概率
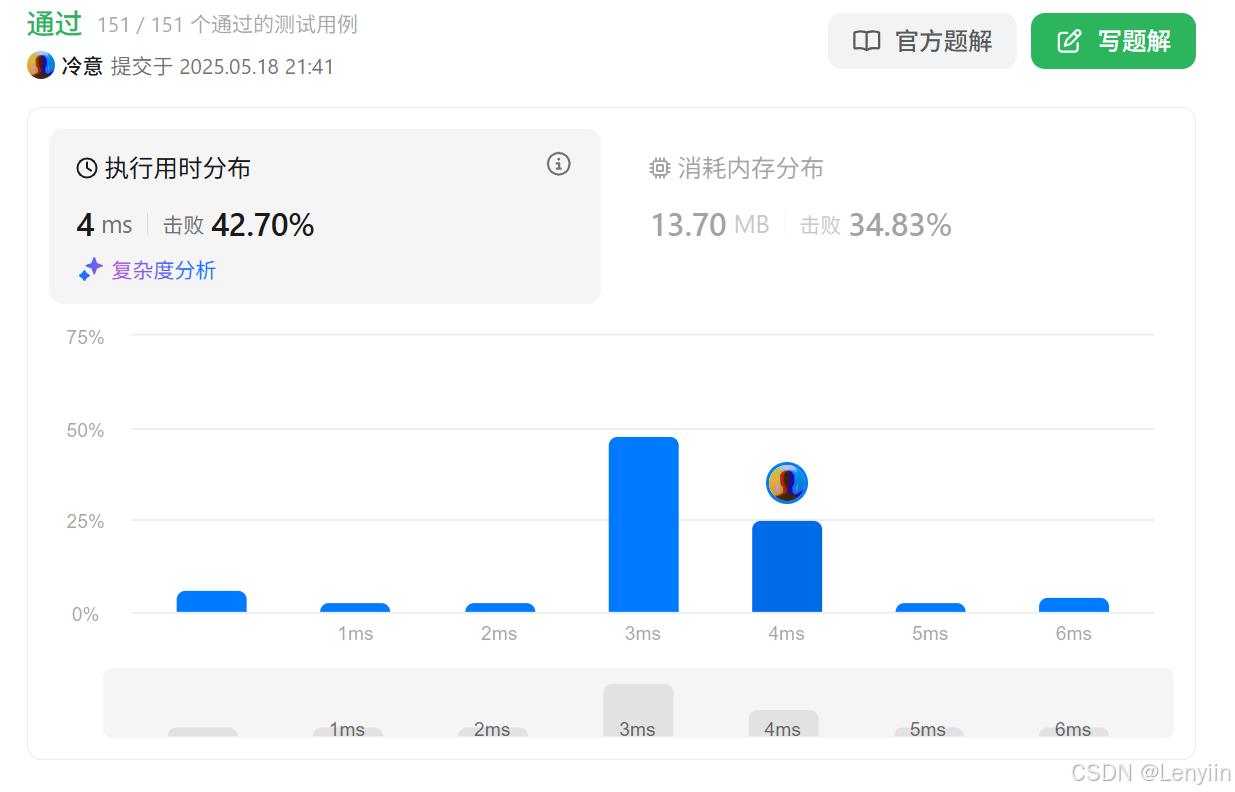
4、复杂度分析
- 时间复杂度:
- 初始化
dp数组的时间复杂度为 O ( k + m a x P t s ) O(k+maxPts) O(k+maxPts)。 - 计算
dp数组的时间复杂度为 O ( k ) O(k) O(k)。 - 总时间复杂度为 O ( k + m a x P t s ) O(k+maxPts) O(k+maxPts)。
- 初始化
- 空间复杂度:
- 使用
dp数组,空间复杂度为 O ( k + m a x P t s ) O(k+maxPts) O(k+maxPts)。
- 使用
Q4、[困难] 相似字符串组
1、题目描述
如果交换字符串 X 中的两个不同位置的字母,使得它和字符串 Y 相等,那么称 X 和 Y 两个字符串相似。如果这两个字符串本身是相等的,那它们也是相似的。
例如,"tars" 和 "rats" 是相似的 (交换 0 与 2 的位置); "rats" 和 "arts" 也是相似的,但是 "star" 不与 "tars","rats",或 "arts" 相似。
总之,它们通过相似性形成了两个关联组:{"tars", "rats", "arts"} 和 {"star"}。注意,"tars" 和 "arts" 是在同一组中,即使它们并不相似。形式上,对每个组而言,要确定一个单词在组中,只需要这个词和该组中至少一个单词相似。
给你一个字符串列表 strs。列表中的每个字符串都是 strs 中其它所有字符串的一个字母异位词。请问 strs 中有多少个相似字符串组?
示例 1:
输入:strs = ["tars","rats","arts","star"] 输出:2示例 2:
输入:strs = ["omv","ovm"] 输出:1提示:
1 <= strs.length <= 3001 <= strs[i].length <= 300strs[i]只包含小写字母。strs中的所有单词都具有相同的长度,且是彼此的字母异位词。
2、解题思路
- 问题分析:
- 每个字符串都是其他字符串的字母异位词,意味着它们的字符组成完全相同。
- 相似性关系是传递的,即如果
A和B相似,B和C相似,那么A和C也属于同一组。 - 可以使用并查集(Union-Find)来管理相似字符串的组。
- 算法设计:
- 初始化并查集,每个字符串初始时属于自己所在的组。
- 遍历所有字符串对,检查它们是否相似。如果相似,则将它们所在的组合并。
- 最终,统计并查集中根节点的数量,即为相似字符串组的数量。
- 优化:
- 使用路径压缩和按秩合并优化并查集的性能。
3、代码实现
C++
class Solution {
private:vector<int> f; // 并查集数组// 查找根节点, 带路径压缩int find(int x) { return f[x] == x ? x : f[x] = find(f[x]); }// 检查两个字符串是否相似bool check(const string& a, const string& b, int len) {int num = 0; // 记录不同字符的数量for (int i = 0; i < len; ++i) {if (a[i] != b[i]) {++num;if (num > 2) // 如果不同字符超过 2 个, 则不相似{return false;}}}return true; // 不同字符不超过 2 个, 相似}public:int numSimilarGroups(vector<string>& strs) {int n = strs.size(); // 字符串的数量int m = strs[0].length(); // 每个字符串的长度f.resize(n); // 初始化并查集数组for (int i = 0; i < n; ++i) {f[i] = i; // 每个字符串初始时属于自己所在的组}// 遍历所有字符串对, 检查是否相似for (int i = 0; i < n; ++i) {for (int j = i + 1; j < n; ++j) {int fi = find(i), fj = find(j); // 查找根节点if (fi == fj) {continue; // 如果已经在同一组, 跳过}if (check(strs[i], strs[j], m)) // 如果相似, 合并组{f[fi] = fj;}}}// 统计并查集中根节点的数量int ret = 0;for (int i = 0; i < n; ++i) {if (f[i] == i) {++ret;}}return ret; // 返回相似字符串组的数量}
};
Java
class Solution {private int[] f; // 并查集数组// 查找根节点,带路径压缩private int find(int x) {return f[x] == x ? x : (f[x] = find(f[x]));}// 检查两个字符串是否相似private boolean check(String a, String b, int len) {int num = 0; // 记录不同字符的数量for (int i = 0; i < len; i++) {if (a.charAt(i) != b.charAt(i)) {num++;if (num > 2) { // 如果不同字符超过 2 个,则不相似return false;}}}return true; // 不同字符不超过 2 个,相似}public int numSimilarGroups(String[] strs) {int n = strs.length; // 字符串的数量int m = strs[0].length(); // 每个字符串的长度f = new int[n]; // 初始化并查集数组for (int i = 0; i < n; i++) {f[i] = i; // 每个字符串初始时属于自己所在的组}// 遍历所有字符串对,检查是否相似for (int i = 0; i < n; i++) {for (int j = i + 1; j < n; j++) {int fi = find(i), fj = find(j); // 查找根节点if (fi == fj)continue; // 如果已经在同一组,跳过if (check(strs[i], strs[j], m)) { // 如果相似,合并组f[fi] = fj;}}}// 统计并查集中根节点的数量int ret = 0;for (int i = 0; i < n; i++) {if (f[i] == i) {ret++;}}return ret; // 返回相似字符串组的数量}
}
Python
class Solution:def numSimilarGroups(self, strs: List[str]) -> int:n = len(strs) # 字符串的数量m = len(strs[0]) # 每个字符串的长度f = [i for i in range(n)] # 初始化并查集数组# 查找根节点,带路径压缩def find(x):if f[x] != x:f[x] = find(f[x])return f[x]# 检查两个字符串是否相似def check(a, b):num = 0 # 记录不同字符的数量for i in range(m):if a[i] != b[i]:num += 1if num > 2: # 如果不同字符超过 2 个,则不相似return Falsereturn True # 不同字符不超过 2 个,相似# 遍历所有字符串对,检查是否相似for i in range(n):for j in range(i + 1, n):fi, fj = find(i), find(j) # 查找根节点if fi == fj: continue # 如果已经在同一组,跳过if check(strs[i], strs[j]): # 如果相似,合并组f[fi] = fj# 统计并查集中根节点的数量ret = 0for i in range(n):if f[i] == i:ret += 1return ret # 返回相似字符串组的数量
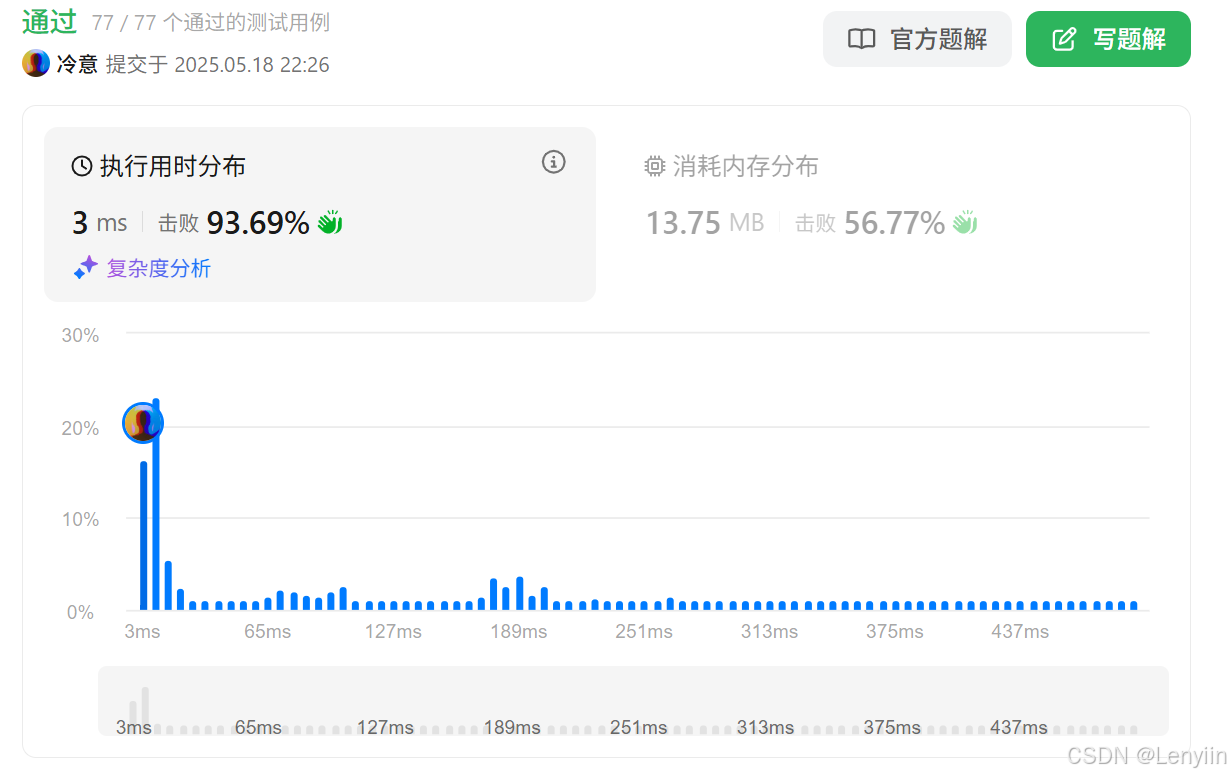
4、复杂度分析
- 时间复杂度:
- 初始化并查集:O(n)。
- 遍历所有字符串对:O(n2)。
- 检查相似性:每次检查 O(m),其中
m是字符串的长度。 - 总时间复杂度:O(n2⋅m)。
- 空间复杂度:
- 并查集数组:O(n)。