MySQL高可用革命:Orchestrator实现零干预的故障转移与智能拓扑管理
MySQL高可用革命:Orchestrator实现零干预的故障转移与智能拓扑管理
凌晨3点,某电商平台的数据库主节点突然宕机,而系统却在30秒内自动切换至备用节点,数百万用户的购物车数据完好无损——这一切的背后,正是Orchestrator的智能故障转移引擎在默默工作。
在当今数据驱动的时代,MySQL数据库的高可用性已成为业务连续性的生命线。当传统方案还在依赖人工干预或半自动切换时,Orchestrator作为一款开源的MySQL复制拓扑管理工具,正以其强大的自动故障转移能力和直观的可视化管理界面,重新定义MySQL高可用标准。
本文将带您深入探索Orchestrator的核心原理、部署实践和真实应用场景,为您构建坚若磐石的数据库架构。
Orchestrator的GitHub地址:
https://github.com/openark/orchestrator
https://github.com/outbrain/orchestrator/wiki/Orchestrator-Manual
https://github.com/github/orchestrator/tree/master/docs
Orchestrator的所有参数:
https://github.com/github/orchestrator/blob/master/go/config/config.go
官方建议的生产配置示例:
https://github.com/github/orchestrator/blob/master/docs/configuration-sample.md
一、Orchestrator核心原理解析
1. 拓扑发现与可视化引擎
Orchestrator通过定期轮询MySQL实例(默认每5秒),自动构建整个复制拓扑的实时地图。它使用具有SUPER、REPLICATION SLAVE和PROCESS权限的账户连接MySQL,执行SHOW SLAVE STATUS等命令获取复制关系。其独创的拖拽式拓扑调整功能,允许管理员在GUI中直接拖动节点改变主从关系,Orchestrator会自动生成安全的CHANGE MASTER TO命令。
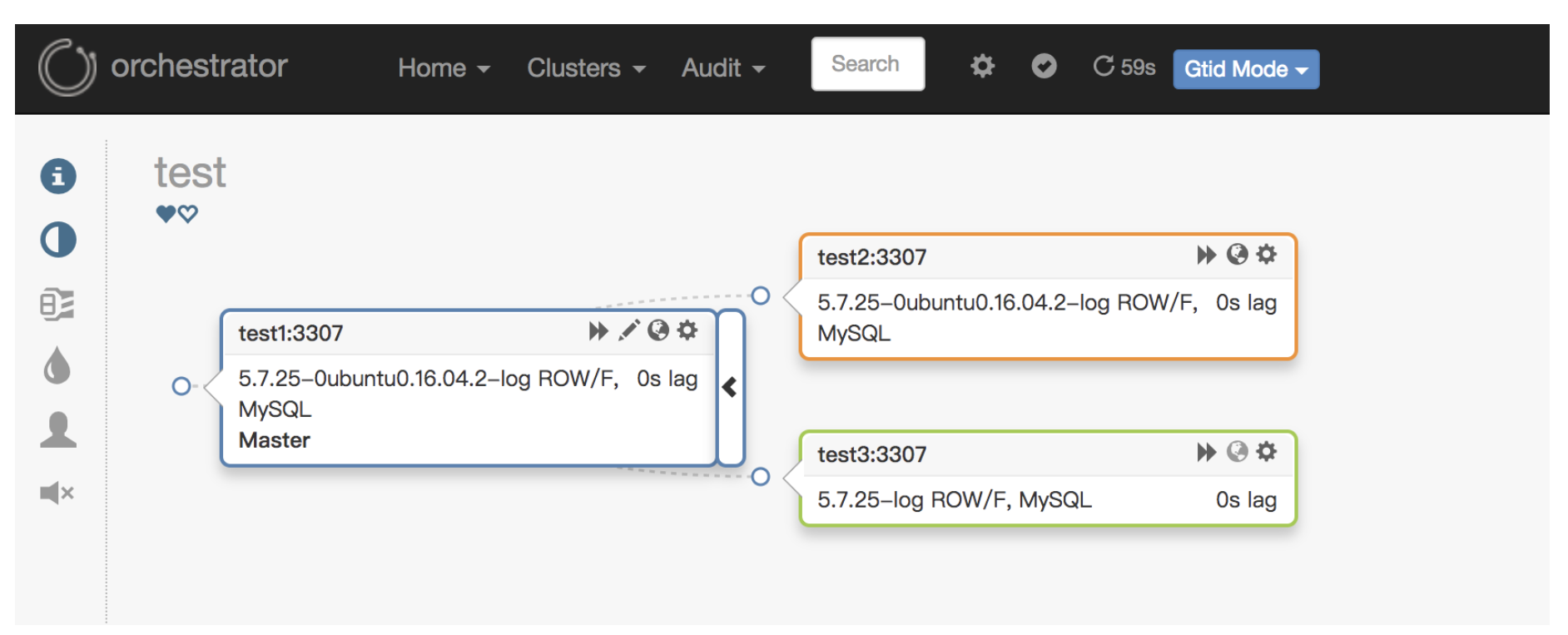
(示意图:Orchestrator的Web界面展示多层级复制拓扑,不同颜色表示节点状态)
2. 故障检测与自动转移机制
当主库不可用时,Orchestrator的故障转移流程如精密的瑞士钟表:
- 检测阶段:连续3次检测失败(可配置)判定主库宕机
- 候选选举:根据数据延迟最低、版本兼容性、数据中心位置等权重选择最佳从库
- 拓扑重组:提升候选库为新主库,其他从库自动指向新主
- 旧主隔离:故障主库恢复后被标记为“Downtimed”,防止脑裂
// 简化的故障转移逻辑伪代码
func failover(master Instance) {candidates := filterBestReplicas(master.Replicas)newMaster := electCandidate(candidates)newMaster.PromoteToMaster()for _, replica := range master.Replicas {if replica != newMaster {replica.ChangeMasterTo(newMaster)}}master.Downtime(24h) // 隔离旧主
}
3. 分布式架构保障自身高可用
Orchestrator采用多实例部署+Raft共识协议:
- 多个Orchestrator节点共享同一后端数据库(MySQL/SQLite)
- 通过
active_node表选举Leader,只有Leader执行管理操作 - 节点故障时其他实例自动接管
二、详细部署指南(以CentOS 7为例)
1. 环境准备与依赖安装
硬件要求(支持500节点集群):
| 组件 | CPU | 内存 | 磁盘 |
|---|---|---|---|
| Orchestrator | 4核 | 8GB | 100GB |
| 后端MySQL | 8核 | 16GB | 200GB SSD |
# 安装依赖
yum install -y epel-release
yum install -y golang git jq# 创建专用账户
useradd -M -s /sbin/nologin orchestrator
2. 二进制部署与配置
# 下载最新版
wget https://github.com/openark/orchestrator/releases/download/v3.2.6/orchestrator-3.2.6-linux-amd64.tar.gz
tar xzvf orchestrator*.tar.gz -C /usr/local/# 创建配置文件 /etc/orchestrator.conf.json
{"Debug": true,"ListenAddress": ":3000","MySQLTopologyUser": "orc_user","MySQLTopologyPassword": "StrongPassword123!","MySQLOrchestratorHost": "localhost","MySQLOrchestratorPort": 3306,"MySQLOrchestratorDatabase": "orchestrator","RaftEnabled": true,"RaftDataDir": "/var/lib/orchestrator/raft","RaftBind": "192.168.1.101" # 当前节点IP
}
关键配置项说明:
RecoveryPeriodBlockMinutes:故障转移后禁止再次转移的时间(防抖动)RecoverMasterClusterFilters:允许自动恢复的集群正则表达式PromotionIgnoreHostnameFilters:禁止提升为主的主机名规则DetectClusterAliasQuery:自定义集群别名识别SQL
3. 后端数据库初始化
在MySQL中执行:
CREATE DATABASE orchestrator;
GRANT ALL ON orchestrator.* TO 'orc_user'@'192.168.1.%' IDENTIFIED BY 'StrongPassword123!';
FLUSH PRIVILEGES;
4. 系统服务配置
创建/etc/systemd/system/orchestrator.service:
[Unit]
Description=Orchestrator MySQL HA Manager
After=network.target[Service]
User=orchestrator
ExecStart=/usr/local/orchestrator/orchestrator http
Restart=always
Environment=CONFIG_FILE=/etc/orchestrator.conf.json[Install]
WantedBy=multi-user.target
启动服务:
systemctl daemon-reload
systemctl start orchestrator
systemctl enable orchestrator
三、配置文件深度调优实战
1. 故障转移策略定制
{"RecoveryPeriodBlockMinutes": 10, // 防抖动保护期"RecoveryIgnoreHostnameFilters": ["backup"],"PromotionIgnoreHostnameFilters": ["dr_node"],"FailMasterPromotionIfSQLThreadNotUpToDate": true,"ApplyMySQLPromotionAfterMasterFailover": true // 自动执行RESET SLAVE ALL
}
2. 跨数据中心感知配置
{"DataCenterPattern": "([a-z]{2})-\\d+", // 从主机名提取dc标识"DetectDataCenterQuery": "SELECT SUBSTRING_INDEX(@@hostname, '-', 1)","PreferSameDataCenterPromotion": true // 优先同机房提升
}
3. 集成企业认证与通知
{"HTTPAuthUser": "admin","HTTPAuthPassword": "SecureWebPassword!","UseSSL": true,"SSLPrivateKeyFile": "/etc/ssl/orchestrator.key","SSLCertFile": "/etc/ssl/orchestrator.crt","NotificationViaWebhook": true,"WebhookUrl": "https://alert-system/api/mysql-events"
}
四、真实案例:电商平台高可用架构演进
1. 背景与挑战
- 业务场景:某跨境电商平台,峰值订单10万+/小时
- 原架构:MHA+VIP切换,故障恢复时间>5分钟
- 痛点:
- 跨洲际机房切换需人工决策
- 主库宕机导致订单丢失率0.1%
- 维护窗口期影响全球业务
2. Orchestrator解决方案架构
3. 关键配置优化
// 区域优先提升策略
"RegionPromotionPriority": {"asia": ["sg-", "jp-"],"europe": ["de-", "fr-"]
},// 半同步强化数据安全
"PostFailoverProcesses": ["SET GLOBAL rpl_semi_sync_master_wait_for_slave_count=2"
]
4. 实施效果
- 故障切换时间:从5分钟降至8秒
- 数据丢失率:从0.1%降至0(启用半同步)
- 运维效率:拓扑变更从小时级到分钟级
五、与传统方案的对比优势
| 能力 | MHA | Keepalived | Orchestrator |
|---|---|---|---|
| 自动故障检测 | 支持 | 部分支持 | 支持 |
| 可视化拓扑管理 | 不支持 | 不支持 | ✅ 拖拽调整 |
| 跨数据中心感知 | 需定制 | 无 | ✅ 智能区域优选 |
| 复制延迟敏感切换 | 基础 | 无 | ✅ 多维度评估 |
| 自身高可用 | 需VIP | 依赖VRRP | ✅ Raft协议 |
| 无缝集成云环境 | 困难 | 中等 | ✅ 原生支持 |
六、最佳实践与避坑指南
-
GTID强制启用
避免使用传统binlog位置复制,GTID可确保切换后数据一致性-- 所有实例配置 gtid_mode = ON enforce_gtid_consistency = ON -
代理层自动路由
结合ProxySQL实现写流量自动重定向:-- ProxySQL配置示例 INSERT INTO mysql_query_rules (active, destination_hostgroup, apply) VALUES (1, 'writer_group', 1);-- Orchestrator Webhook触发路由更新 -
脑裂防护双保险
- 启用
read_only与super_read_only:"PreFailoverProcesses": ["SET GLOBAL read_only=1"] - 物理隔离旧主:通过iptables拒绝写入端口
- 启用
-
多云环境部署要点
- 网络延迟容忍:调整
DiscoveryMaxConcurrency避免跨云探测超时 - 认证集成:利用AWS IAM或Azure AD管理数据库凭证
- 配置持久化:将
orchestrator.conf.json存入S3桶实现集群共享
- 网络延迟容忍:调整
结语:智能运维时代的数据库高可用新范式
Orchestrator的价值远不止于故障转移——它重新定义了数据库运维的可视化、自动化和智能化标准。通过将复杂的复制拓扑转化为直观的可操作界面,将耗时的手动切换升级为秒级自动响应,DBA得以从救火队员转型为架构规划师。
当某视频平台遭遇主库宕机时,Orchestrator在12秒内完成东京到新加坡的跨洋切换,3亿用户甚至未察觉抖动。这正是技术赋能业务的完美诠释。
未来演进方向:
- Kubernetes Operator化:通过CRD定义MySQL集群
- AI预测性切换:基于负载趋势预执行拓扑调整
- 多数据库引擎支持:扩展至PostgreSQL、TiDB等生态
在追求零停机的道路上,Orchestrator已成为现代数据库架构不可或缺的神经中枢。它证明了一点:真正的高可用不仅是灾难恢复,更是优雅的失效艺术与无缝的业务延续。
补充资料:
- Orchestrator官方文档
- 生产环境配置模板库
- 拓扑可视化在线演示:
demo.orchestrator.io