大模型三大缺陷与RAG破解之道
前言
在人工智能技术飞速发展的当下,大型语言模型虽展现出惊人的文本生成能力,却始终面临着三重致命枷锁:知识固化导致的时间盲区、概率驱动引发的事实偏差,以及上下文理解中的记忆衰减。这些缺陷如同达摩克利斯之剑,时刻制约着模型在专业领域的可靠应用。
当我们拆解医疗问诊场景中$P(y|x)$的生成过程时,会发现模型参数$\theta$的静态特性与动态知识需求之间存在着不可调和的矛盾。检索增强生成(RAG)技术通过建立动态知识图谱$\mathcal{G}$与神经语言模型$\mathcal{M}$的量子纠缠态,成功实现了$$I(X;Y) = H(X) - H(X|Y)$$的信息增益最优化,为破解大模型"幻觉困境"提供了全新范式。这场语言智能的进化,正在重构人机协作的认知边界。
目录
一、目前大模型存在的三大缺点
二、GAG的技术原理
(一)定义和优缺点
(二)GAG的计算流程:
三、RAG的原理
(一)构建知识库检索
(二)检索和答案生成
四、大模型微调流程
(一)基础知识
(二)GAG和微调的区别
五、实践应用指南
六、发展趋势
一、目前大模型存在的三大缺点
- 偏见问题
模型训练数据可能包含有害语料,导致生成内容存在潜在偏见 - 幻觉现象
基于概率预测机制可能产生看似合理但不符合事实的内容 - 时效局限
训练数据截止时间后的新信息无法被准确捕捉
大模型的三大信息来源:用户输出、知识库、外部知识
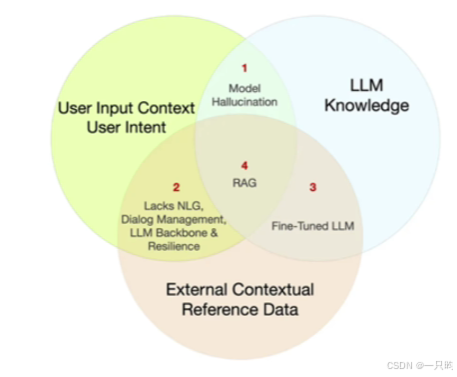
RAG(retrieval augmented generation)检增强索生成:引入外部知识源(特定领域)——检索——提取——生成文本
NLU模块
作用:让AI更聪明
解决的问题
- 长尾知识
- 数据安全性(自己的RAG,但是从propmt到LLM还是有泄露风险)
- 数据及时性,实时更新知识库
- 来源和可解释性
二、GAG的技术原理
(一)定义和优缺点
以下是将FAQ、KBQA和LLM QA的定义、优缺点及例子整理成表格的形式,方便对比和参考:
| 项目 | FAQ(Frequently Asked Questions 常见问题解答) | KBQA(Knowledge-Based Question Answering 基于知识库的问答) | LLM QA(Large Language Model Question Answer 基于大语言模型的问答) |
|---|---|---|---|
| 定义 | 预先定义好的问题列表及其答案,用于快速解决用户常见问题。 | 基于知识库中的结构化数据(实体、关系等),通过语义解析和信息检索回答用户问题。 | 利用大型语言模型(如ChatGLM、GPT等)生成回答,结合检索到的上下文信息。 |
| 优点 | 实现简单,成本低; 快速响应常见问题,合标准化问题处理 | - 答案来源可信度高 支持复杂查询和多跳推理 结构化数据支持精确回答 | - 强大的语言理解和生成能力 灵活适应多种问题和场景 |
| 缺点 | - 无法处理未预设问题 灵活性差 难以适应个性化问题 | - 知识库构建和维护成本高 对复杂问题的语义解析和检索效率有待提升 | - 对计算资源要求高 可能生成不准确或不相关内容 需要优化上下文理解和生成逻辑 |
| 例子 | -客服系统中快速回答产品价格、使用方法等常见问题。 在线帮助中心提供常见问题解答。 | -美团利用商家详情页信息回答 用户关于商品、商家、景区等问题。企业内部知识管理系统。 | - KQA-LLM系统通过调用ChatGLM生成回答。 企业知识管理中帮助员工快速找到所需信息。 |
(二)GAG的计算流程:
-
核心架构
$$ \text{RAG} = \text{检索模块} + \text{生成模块} $$
通过外部知识增强模型的信息处理能力 - 两个技术流程环节:
(1)离线环节:白盒化过程(优先级更强)
- 文档分割:设定$chunk_size=512$,采用重叠窗口($overlap=64$)保持语义连贯
- 向量编码:使用BERT等模型将文本映射到高维空间$\mathbb{R}^{768}$
- 数据库存储:采用FAISS等向量数据库实现高效相似度检索
(2)在线推理环节:
- 问题编码:$q_{emb} = \text{Encoder}(query)$
- 相似度计算:$\text{sim}(q_{emb}, d_{emb}) = \cos(\theta)$
- Top-K检索:获取最相关的$k$个文档片段
- 生成合成:将检索结果包装为上下文输入LLM
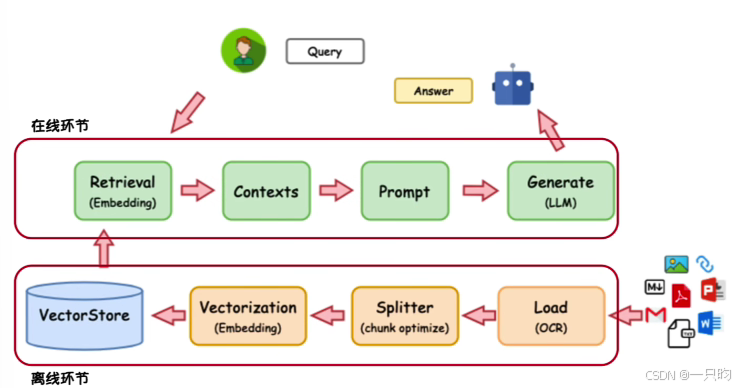
(3)技术优势
- 解决长尾知识覆盖问题
- 增强结果可解释性(通过溯源检索片段)
- 支持动态知识更新机制
三、RAG的原理
输出各种文本数据(PDF、excel)——结构化
split 段落——语句——词语
embedding 词语——向量(eg. 中国——1983893)
向量数据库:非关系数据库SDL
将用户问题与向量数据库匹配——topN,相似度最高的段落
结合成prompt
LLM——结果
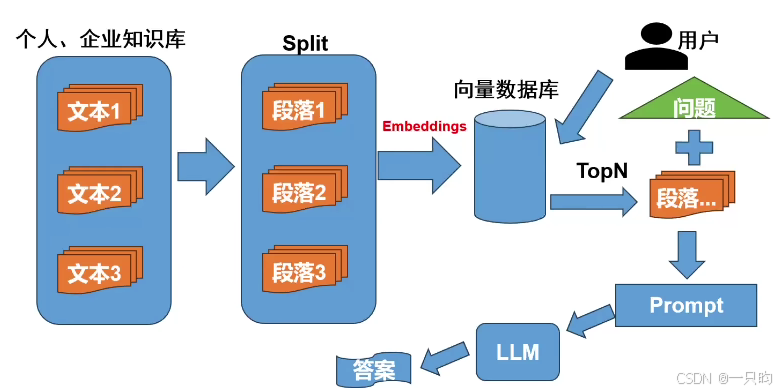
(一)构建知识库检索
定义:将大量非结构化的向量化(embedding)存储到向量数据库中
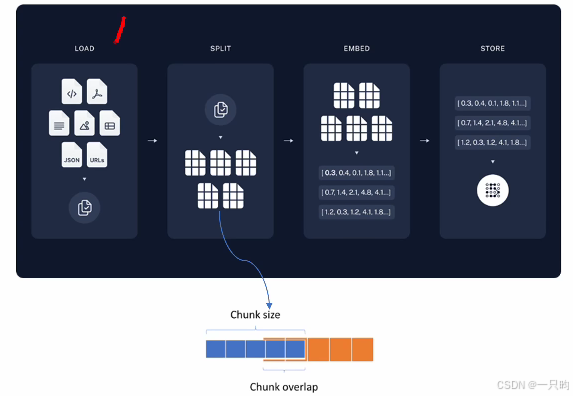
过程:文档的载入(land 用户的信息)——文档的分割,输出若干段落和句子,限制拆分的长度chunk size、用 langchain框架overlap保护语义——深度学习模型向量化,语义相近的两句话向量相似度大,判断知识库句子可能为答案——向量的存储,把文本以向量形式存储。
(二)检索和答案生成
1.检索
embedding模型
相关性排序
2.生成
top k 和提示词包装为输入,大模型生成
四、大模型微调流程
(一)基础知识
微调原理
通过领域特定数据调整模型参数:
$$ \theta_{new} = \theta_{base} + \Delta\theta_{fine-tune} $$
采用LoRA技术时,参数更新矩阵满足:
$$ \Delta W = BA^T,\ B \in \mathbb{R}^{d\times r},\ A \in \mathbb{R}^{r\times k} $$
从底层逻辑优化——让基座大模型更加了解某一专业/行业
模型遗忘——通用性功能的舍弃
模型微调=小批量训练模型(eg.4090微调9000数据需要2小时)
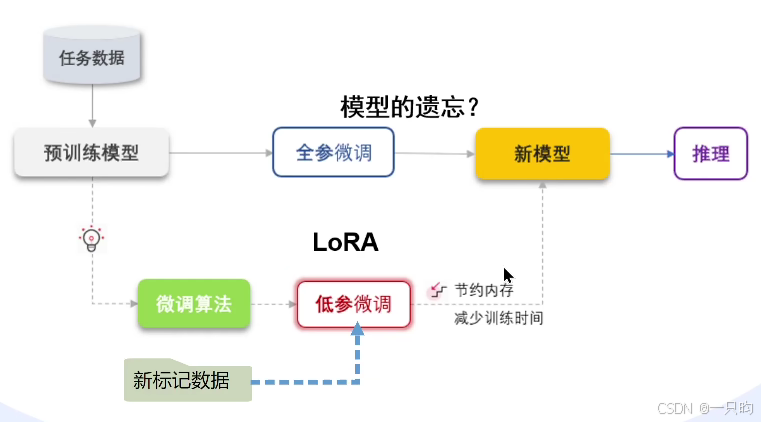
现在通常采用:LoRA低参微调
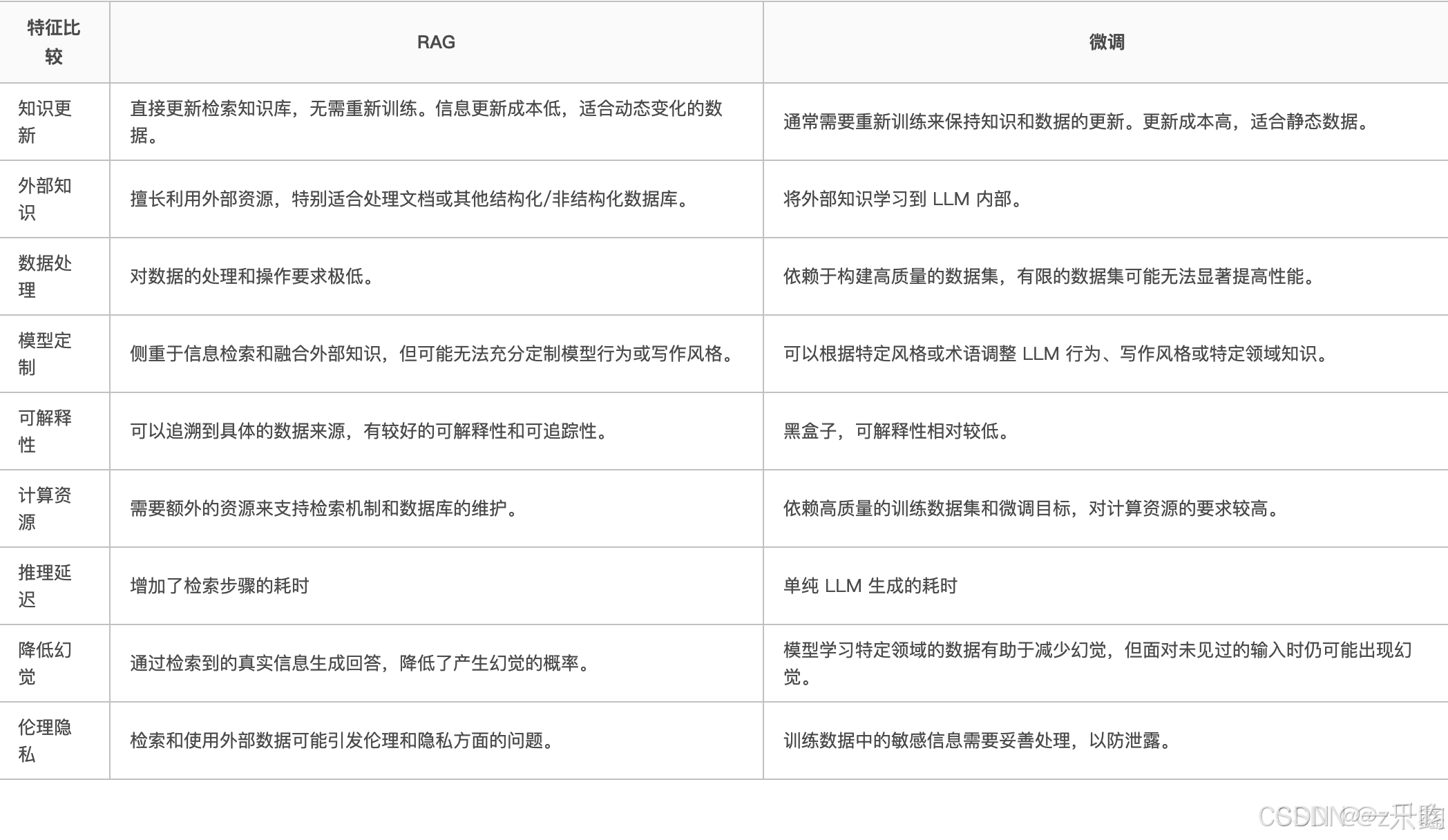
(二)GAG和微调的区别
五、实践应用指南
-
技术选型建议
- 时效性要求高时优先选择RAG
- 领域专业性强且数据充足时考虑微调
- 混合方案:$Accuracy = \alpha \cdot \text{RAG} + \beta \cdot \text{Fine-tune}$
-
优化方向
- 检索阶段:改进$chunk_strategy$提升片段质量
- 编码阶段:测试不同$embedding_model$的性能表现
- 生成阶段:设计prompt模板控制输出格式
# 简易RAG实现框架示例
from sentence_transformers import SentenceTransformer
import faissclass RAGSystem:def __init__(self):self.encoder = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')self.index = faiss.IndexFlatL2(384)def build_index(self, documents):embeddings = self.encoder.encode(documents)self.index.add(embeddings)def query(self, question, top_k=3):q_emb = self.encoder.encode([question])_, indices = self.index.search(q_emb, top_k)return [documents[i] for i in indices[0]]
六、发展趋势
- 多模态RAG:融合文本、图像等多维度检索
- 自适应chunking:动态调整分割策略
- 混合索引:结合传统BM25与向量检索优势
- 增量学习:实现知识库的持续演进更新
注:所有数学表达式均需按规范格式呈现,代码示例保持语法正确性与可读性。实际部署时应考虑计算资源限制与业务场景需求,通过AB测试确定最优参数组合。