经典查找算法合集(上)
一、顺序查找
1. 核心原理
顺序查找(又称线性查找)是最基础的查找算法,适用于无需预处理的线性数据结构(如数组、链表)。其原理是:从数据结构的起始位置开始,逐个比较元素与目标值,直到找到匹配项或遍历完所有元素。
2. 算法步骤
- 初始化指针:从第一个元素开始扫描。
- 遍历比较:逐个比较当前元素与目标值。
- 终止条件:
- 找到目标值 → 返回元素位置。
- 遍历完所有元素未找到 → 返回特定标记(如 -1)。
3. 时间复杂度与空间复杂度
| 维度 | 说明 |
|---|---|
| 时间复杂度 | O(n)(最坏情况需遍历全部元素) |
| 空间复杂度 | O(1)(仅需常数级别额外空间存储指针) |
| 最佳情况 | O(1)(目标元素在第一个位置) |
4. 代码实现
Python :
def sequential_search(arr, target):for index in range(len(arr)):if arr[index] == target:return index # 找到目标,返回索引return -1 # 未找到# 示例调用
arr = [4, 2, 7, 1, 9, 5]
target = 7
result = sequential_search(arr, target)
print(f"元素 {target} 的索引位置: {result}") # 输出: 元素 7 的索引位置: 2Python 优化版(增加监控哨兵,减少循环次数):
def sequential_search_optimized(arr, target):arr.append(target) # 添加哨兵index = 0while arr[index] != target:index += 1arr.pop() # 移除哨兵return index if index < len(arr) else -1java:
public class SequentialSearch {public static int search(int[] arr, int target) {for (int i = 0; i < arr.length; i++) {if (arr[i] == target) {return i; // 找到目标,返回索引}}return -1; // 未找到}public static void main(String[] args) {int[] arr = {4, 2, 7, 1, 9, 5};int target = 7;int result = search(arr, target);System.out.println("元素 " + target + " 的索引位置: " + result); // 输出: 2}
}php :
<?php
function sequentialSearch(array $arr, $target) {// 遍历数组元素for ($i = 0; $i < count($arr); $i++) {if ($arr[$i] == $target) {return $i; // 找到目标,返回索引}}return -1; // 未找到
}// 示例调用
$arr = [4, 2, 7, 1, 9, 5];
$target = 7;
$result = sequentialSearch($arr, $target);
echo "元素 $target 的索引位置: " . $result; // 输出: 元素 7 的索引位置: 2
?>go:
package mainimport "fmt"func sequentialSearch(arr []int, target int) int {// 遍历切片元素for i := 0; i < len(arr); i++ {if arr[i] == target {return i // 找到目标,返回索引}}return -1 // 未找到
}func main() {arr := []int{4, 2, 7, 1, 9, 5}target := 7result := sequentialSearch(arr, target)fmt.Printf("元素 %d 的索引位置: %d", target, result) // 输出: 元素 7 的索引位置: 2
}5、优缺点分析
| 优点 | 缺点 |
|---|---|
| - 实现简单,无需额外数据结构 | - 效率低,时间复杂度 O(n) |
| - 适用于无序数据和小规模数据集 | - 数据量大时性能急剧下降 |
| - 无需预处理(如排序) | - 不适合频繁查找的场景 |
6、适用场景
- 小规模数据(如数组长度 < 100)。
- 数据无序且仅需单次查找。
- 链表结构(无法随机访问,必须顺序遍历)。
- 算法学习或简单原型开发(快速验证逻辑)。
实际应用示例
- 文本编辑器查找:在未索引的文档中逐行搜索关键词。
- 通讯录查找:在未排序的联系人列表中按顺序查找姓名。
- 硬件调试:在内存转储中逐字节查找特定信号值。
二、二分查找
1、原理
二分查找又叫折半查找,对数搜索。
二分查找(Binary Search) 是一种在 有序数组 中快速查找目标值的算法,通过不断将搜索范围减半来定位元素。
核心步骤:
- 初始化指针:设左指针
left = 0,右指针right = 数组长度 - 1。 - 循环查找:
- 计算中间索引
mid = left + (right - left) // 2(避免整数溢出)。 - 比较
nums[mid]与目标值target:- 若
nums[mid] == target,找到目标,返回索引。 - 若
nums[mid] < target,目标在右半部分,更新left = mid + 1。 - 若
nums[mid] > target,目标在左半部分,更新right = mid - 1。
- 若
- 计算中间索引
- 终止条件:当
left > right时,未找到目标,返回-1。
示例:
在数组 [2, 4, 6, 8, 10] 中查找 8 的过程:
- 初始范围:
left=0,right=4→mid=2(值为6) → 6 < 8 →left=3。 - 新范围:
left=3,right=4→mid=3(值为8) → 找到目标,返回索引3。
图解:
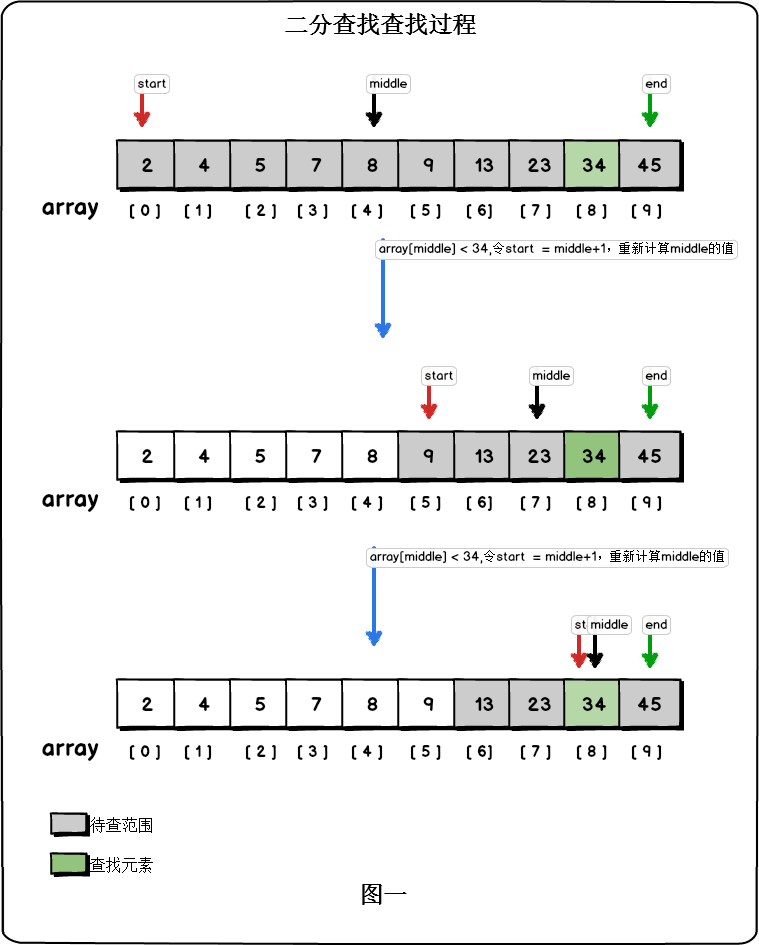
2、 性能分析
- 时间复杂度:O(log n),每次循环将搜索范围缩小一半。
- 空间复杂度:O(1)(迭代实现)或 O(log n)(递归实现)。
- 稳定性:结果唯一,但要求数组有序。
3、 代码实现
java:
public int binarySearch(int[] nums, int target) {int left = 0, right = nums.length - 1;while (left <= right) {int mid = left + (right - left) / 2;if (nums[mid] == target) {return mid;} else if (nums[mid] < target) {left = mid + 1;} else {right = mid - 1;}}return -1;
}php:
function binarySearch($nums, $target) {$left = 0;$right = count($nums) - 1;while ($left <= $right) {$mid = $left + intdiv(($right - $left), 2);if ($nums[$mid] == $target) {return $mid;} elseif ($nums[$mid] < $target) {$left = $mid + 1;} else {$right = $mid - 1;}}return -1;
}python:
def binary_search(nums, target):left, right = 0, len(nums) - 1while left <= right:mid = left + (right - left) // 2if nums[mid] == target:return midelif nums[mid] < target:left = mid + 1else:right = mid - 1return -1go:
func binarySearch(nums []int, target int) int {left, right := 0, len(nums)-1for left <= right {mid := left + (right-left)/2if nums[mid] == target {return mid} else if nums[mid] < target {left = mid + 1} else {right = mid - 1}}return -1
}4、适用场景
- 有序数组查找:如数据库索引、日志时间戳查询。
- 边界查找:寻找第一个/最后一个等于目标的位置(需稍作修改)。
- 数值范围问题:如求平方根(保留整数)、旋转排序数组查找。
5、常见问题
常见问题
- 重复元素:默认返回任意匹配位置,若需首个/末个位置,需修改逻辑。
- 整数溢出:计算
mid时使用left + (right - left)/2而非(left + right)/2。- 未排序数组:二分查找失效,需先排序(排序成本 O(n log n))。
三、哈希查找
1、原理
哈希查找(Hash Search) 是一种通过哈希函数将键(Key)直接映射到存储位置的数据结构访问技术。核心依赖 哈希表(Hash Table) 实现,由以下部分组成:
- 哈希函数:将键转换为哈希值(通常为整数),决定数据存储的桶(Bucket)位置。
- 冲突解决机制:处理不同键映射到同一位置的情况,常用方法包括:
- 链地址法:每个桶存储链表或红黑树,冲突元素链接在同一个桶内。
- 开放寻址法:通过线性探测、二次探测等方式寻找下一个可用位置。
操作步骤:
- 插入:通过哈希函数计算键的桶位置,存入对应位置(解决冲突后)。
- 查找:计算键的哈希值,定位桶,解决冲突后找到目标元素。
- 删除:类似查找,找到元素后移除。
2、性能分析
- 时间复杂度:
- 平均情况:O(1)(理想哈希函数,冲突少)。
- 最坏情况:O(n)(所有键冲突,退化为链表)。
- 空间复杂度:O(n)(实际需额外空间减少冲突,如负载因子控制)。
3、适用场景
- 快速查找/插入/删除:如数据库索引、缓存系统(Redis)、字典结构。
- 去重操作:如统计唯一用户ID。
- 频率统计:如统计单词出现次数。
- 不适合场景:有序数据遍历、范围查询。
4、关键优化技术
- 负载因子(Load Factor):
定义:负载因子 = 元素数量 / 桶数量。
通常设置阈值(如0.75),超过时触发扩容(Rehashing)。 - 动态扩容:
扩容时重新分配桶,减少冲突概率。 - 优质哈希函数:
目标:均匀分布键,减少冲突。常用算法如MurmurHash、SHA-256(加密场景)。
5、代码实现
java(链地址法)
class HashTable {private LinkedList<Entry>[] table;private int capacity;public HashTable(int capacity) {this.capacity = capacity;table = new LinkedList[capacity];for (int i = 0; i < capacity; i++) {table[i] = new LinkedList<>();}}private int hash(int key) {return key % capacity;}public void put(int key, String value) {int index = hash(key);for (Entry entry : table[index]) {if (entry.key == key) {entry.value = value;return;}}table[index].add(new Entry(key, value));}public String get(int key) {int index = hash(key);for (Entry entry : table[index]) {if (entry.key == key) {return entry.value;}}return null;}static class Entry {int key;String value;Entry(int key, String value) {this.key = key;this.value = value;}}
}php (内置关联数组)
$hashTable = [];
$hashTable["apple"] = 1;
$hashTable["banana"] = 2;echo $hashTable["apple"] ?? "Not Found"; // 输出 1python(字典实现):
class HashTable:def __init__(self, size=10):self.size = sizeself.table = [[] for _ in range(size)]def _hash(self, key):return hash(key) % self.sizedef put(self, key, value):bucket = self.table[self._hash(key)]for i, (k, v) in enumerate(bucket):if k == key:bucket[i] = (key, value)returnbucket.append((key, value))def get(self, key):bucket = self.table[self._hash(key)]for k, v in bucket:if k == key:return vreturn None# 示例
ht = HashTable()
ht.put("key1", "value1")
print(ht.get("key1")) # 输出 value1go(内置map)
package mainimport "fmt"func main() {hashTable := make(map[string]int)hashTable["apple"] = 1hashTable["banana"] = 2value, exists := hashTable["apple"]if exists {fmt.Println(value) // 输出 1}
}综合对比
| 算法 | 时间复杂度 | 空间复杂度 | 数据要求 | 适用场景 |
|---|---|---|---|---|
| 顺序查找 | O(n) | O(1) | 无序 | 小数据、简单实现 |
| 二分查找 | O(log n) | O(1) | 必须有序 | 大规模有序数据 |
| 哈希表查找 | O(1) | O(n) | 哈希函数设计 | 高频查找、无范围查询 |