误差反向传播法
文章目录
- 误差反向传播法
- 计算图
- 案例:使用计算图
- 反向传播
- 链式法则
- 反向传播与计算图
- 神经网络中的反向传播
- 加法操作与乘法操作
- 激活函数层的实现
- ReLu层
- sigmoid层
- Affine/Softmax层的实现
- Affine层
- Softmax层
- 梯度确认
- 自动求导-代码
- 标量的反向传播
- 非标量变量的反向传播
- 将某些计算移动到计算图之外
误差反向传播法
计算图
计算图将计算过程用由边和节点组成的图形表示,操作写在节点中,数据的传递写在边上。
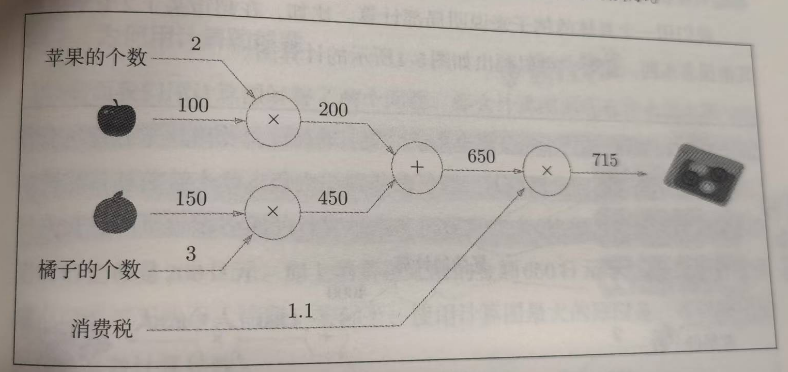
假设问题:在超市买了2个100元的苹果和3个150元的橘子,需要支付消费税10%,最后需要支付多少钱?
计算公式: ( 2 ∗ 100 + 3 ∗ 150 ) ∗ 1.1 = 715 (2*100+3*150)*1.1=715 (2∗100+3∗150)∗1.1=715
正向传播:构建计算图后,按照箭头顺序从做到右计算,从计算图出发点到结束点的传播。
案例:使用计算图
计算图的特征通过局部计算获得最终结果,各个节点的计算都是局部的,不在乎该节点传入的数据如何得到的,只关注这个节点该怎么计算这两个数据。
在下图的+节点,我们要执行两个数字相加200+450,但并不关注200怎么来的,450怎么来的。
计算图通过正向传播可以保存计算的中间值(边上的值)
优点
- 使用局部计算简化问题
- 保存中间结果
- 可以通过反向传播高校计算导数
反向传播
链式法则
定义:如果某个函数由符合函数表示,则该符合函数的导数可以用构成复合函数的各个函数的导数乘积表示。
案例
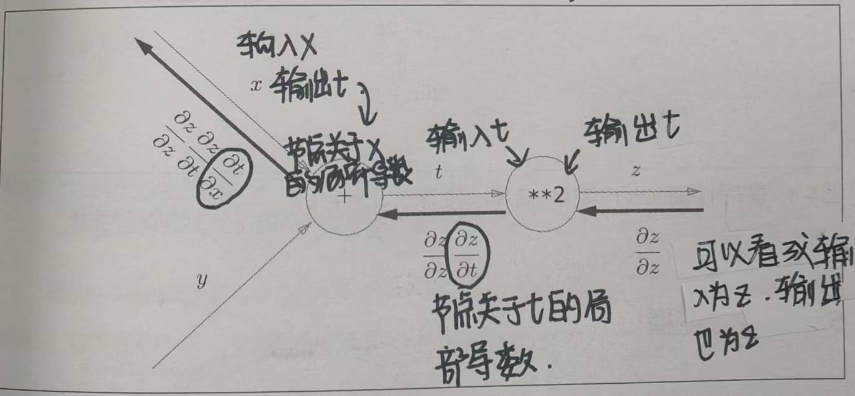
假设函数 z = ( x + y ) 2 z=(x+y)^2 z=(x+y)2,该函数由 z = t 2 z=t^2 z=t2和 t = x + y t=x+y t=x+y两个式子构成。
根据链式法则: ∂ z ∂ x = ∂ z ∂ t ∂ t ∂ x \frac{\partial z}{\partial x} = \frac{\partial z}{\partial t} \frac{\partial t} {\partial x} ∂x∂z=∂t∂z∂x∂t
反向传播与计算图
反向传播:在计算图中,从右往左传播信号,输入的信号*节点的偏导数,然后传递给下一个节点。
神经网络中的反向传播
在反向传播中,链式法则的起点始终是损失函数L对网络最终输出的梯度。
反向传播的目标
计算损失函数 L L L 对网络中所有参数(或输入)的梯度。其过程是从损失函数开始,沿着计算图反向逐层求导,通过链式法则将梯度从输出端(损失)传递到输入端。
加法操作与乘法操作
| 操作 | 特点 | 描述 |
|---|---|---|
| 加法操作 | 加法节点的反向传播将上游的值原封不动地输出到下游 | z = x + y z=x+y z=x+y的偏导数 ∂ z ∂ x = 1 , ∂ z ∂ y = 1 \frac{\partial z}{\partial x} = 1,\frac{\partial z}{\partial y} = 1 ∂x∂z=1,∂y∂z=1 对于加法节点来说 反向传播的输出 = 上游信号 ∗ ( ∂ z ∂ x 或者 ∂ z ∂ y ) = 上游信号 反向传播的输出=上游信号*(\frac{\partial z}{\partial x}或者\frac{\partial z}{\partial y}) = 上游信号 反向传播的输出=上游信号∗(∂x∂z或者∂y∂z)=上游信号 |
| 乘法操作 | 乘法节点的反向传播会将上游的值乘以正向传播时输入信号的“翻转值”,翻转值表示一种反转关系。 | z = x y z=xy z=xy的偏导数 ∂ z ∂ x = y , ∂ z ∂ y = x \frac{\partial z}{\partial x} = y,\frac{\partial z}{\partial y} = x ∂x∂z=y,∂y∂z=x 对于乘法节点来说 反向传播的输出 = 上游信号 ∗ ( ∂ z ∂ x 或者 ∂ z ∂ y ) = 上游信号 ∗ ( y 或者 x ) 反向传播的输出=上游信号*(\frac{\partial z}{\partial x}或者\frac{\partial z}{\partial y}) = 上游信号*(y或者x) 反向传播的输出=上游信号∗(∂x∂z或者∂y∂z)=上游信号∗(y或者x) |
激活函数层的实现
ReLu层
激活函数ReLU( Rectified Linear Unit) y = { x x > 0 0 x ≤ 0 y=\begin{cases} x & x>0 \\ 0 & x\leq 0 \end{cases} y={x0x>0x≤0,可以求出y关于x的导数 ∂ y ∂ x = { 1 x > 0 0 x ≤ 0 \frac {\partial y}{\partial x}=\begin{cases} 1 & x>0 \\ 0 & x\leq 0 \end{cases} ∂x∂y={10x>0x≤0
- 如果正向传播时的输入
x>0,那么反向传播会将上游的值原封不动(上游*1)地传递给下游。 - 如果正向传播时的输出x小于等0,那么反向传播中传递给下游的信号将停止在此处(上游*0)。
使用Python实现****ReLU层
out[self.mask]其中self.mask是一个布尔数组,所以这里使用了布尔索引。
概念:布尔索引是一种通过布尔值数组选择数据子集的操作。
规则:1.布尔数组必须与目标数组(这里是out)的形状完全一致。2.对于布尔数组中为True的位置,目标数组对应位置的元素会被选中。
class Relu:def __init__(self):# 初始化一个 mask 属性,用于记录输入张量中哪些元素小于等于 0self.mask = None# 在前向传播时mask被赋值def forward(self, x):# 生成一个布尔矩阵,Ture的位置对应输入小于等于0self.mask = (x <= 0)# 创建输入 x 的副本,避免直接修改原始数据。out = x.copy()# 实现ReLu激活函数,小于等于0的输入,输出会被置为0out[self.mask] = 0return outdef backward(self, dout):# 将上游传递的dout数组中,前向传播中大于小于0的位置的梯度置0dout[self.mask] = 0dx = doutreturn dx
sigmoid层
sigmoid函数 y = 1 1 + e x p ( − x ) y=\frac{1}{1+exp(-x)} y=1+exp(−x)1
用计算图表示sigmoid函数的正向传播
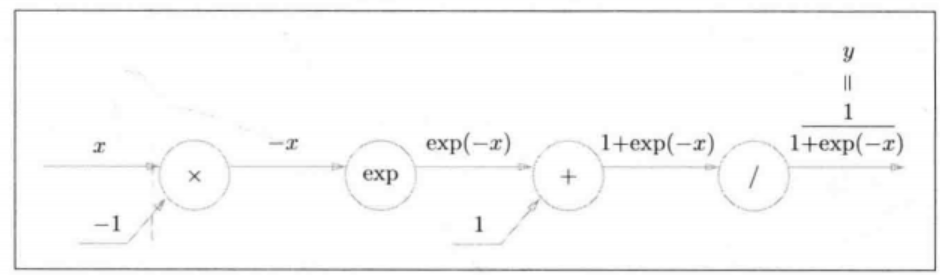
新节点/,该节点表示 y = 1 x y=\frac{1}{x} y=x1,其导数 ∂ y ∂ x = − 1 x 2 = − y 2 \frac{\partial y}{\partial x} = - \frac{1}{x^2} = -y^2 ∂x∂y=−x21=−y2。
新节点exp,该节点表示 y = e x p ( x ) = e x y=exp(x)=e^x y=exp(x)=ex,其导数 ∂ y ∂ x = e x = e x p ( x ) \frac{\partial y}{\partial x} = e^x=exp(x) ∂x∂y=ex=exp(x),所以在反向传播时这里的输出是 上游 ∗ 该节点的正向输出 上游*该节点的正向输出 上游∗该节点的正向输出
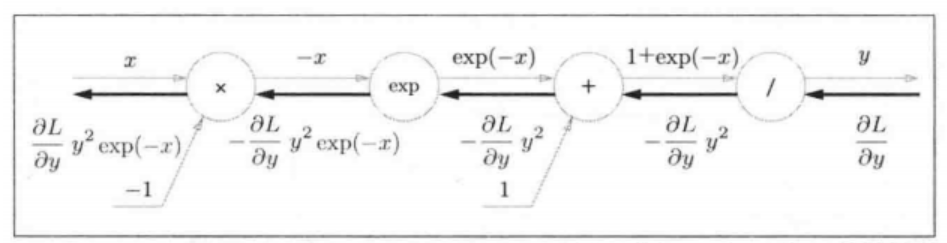
用计算图表示sigmoid函数的反向传播
在反向传播中,链式法则的起点始终是损失函数 L 对网络最终输出的梯度,而 ∂ L ∂ y \frac{∂L}{∂y} ∂y∂L 表示的是损失函数对 sigmoid 层输出 y y y_ _ 的梯度。 ∂ L ∂ y \frac{∂L}{∂y} ∂y∂L 的值它由 sigmoid 层之后的网络层(例如全连接层、损失层等)计算并反向传递而来。
我们可以得到sigmoid层反向传播的最终结果为
∂ L ∂ y y 2 e x p ( − x ) = ∂ L ∂ y 1 ( 1 + e x p ( − x ) ) 2 e x p ( − x ) = ∂ L ∂ y 1 1 + e x p ( − x ) e x p ( − x ) 1 + e x p ( − x ) = ∂ L ∂ y y ( 1 − y ) \frac{\partial L}{\partial y} y^2exp(-x) = \frac{\partial L}{\partial y} \frac{1}{(1+exp(-x))^2}exp(-x) = \frac{\partial L}{\partial y} \frac{1}{1+exp(-x)}\frac{exp(-x)}{1+exp(-x)} = \frac{\partial L}{\partial y} y(1-y) ∂y∂Ly2exp(−x)=∂y∂L(1+exp(−x))21exp(−x)=∂y∂L1+exp(−x)11+exp(−x)exp(−x)=∂y∂Ly(1−y),从这个公式看,sigmoid反向传播的结果只与正向传播最后的输出y相关。
使用Python实现****Sigmoid层
class Sigmoid:def __init__(self):self.out = Nonedef forward(self, x):out = sigmoid(x)self.out = outreturn outdef backward(self, dout):dx = dout * (1.0 - self.out) * self.outreturn dx
Affine/Softmax层的实现
Affine层
神经网络的正向传播中,为了计算加权信号的总和,使用了矩阵的乘积运算。
神经网络的正向传播中进行矩阵的乘法运算在几何学领域被称为仿射变换,这里讲进行仿射变换的处理实现为Affine层。几何中仿射变化包括一次线性变换和一次平移,分别对应神经网络的加权和运算与加偏置运算。
将乘积运算用 dot节点表示,那么 X W + B XW+B XW+B的前向计算图如下
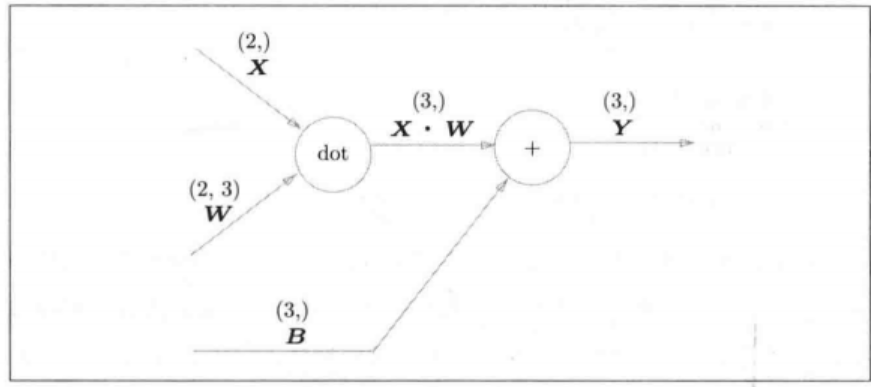
∂ L ∂ X = ∂ L ∂ Y ∗ ∂ Y ∂ X = ∂ L ∂ Y ∗ ∂ X W ∂ X = ∂ L ∂ Y ∗ W T \frac{\partial L}{\partial X}=\frac{\partial L}{\partial Y}*\frac{\partial Y}{\partial X}=\frac{\partial L}{\partial Y}*\frac{\partial XW}{\partial X}=\frac{\partial L}{\partial Y}*W^T ∂X∂L=∂Y∂L∗∂X∂Y=∂Y∂L∗∂X∂XW=∂Y∂L∗WT, ∂ L ∂ W = ∂ L ∂ Y ∗ ∂ Y ∂ W = ∂ L ∂ Y ∗ ∂ X W ∂ W = X T ∗ ∂ L ∂ Y \frac{\partial L}{\partial W}=\frac{\partial L}{\partial Y}*\frac{\partial Y}{\partial W}=\frac{\partial L}{\partial Y}*\frac{\partial XW}{\partial W}=X^T*\frac{\partial L}{\partial Y} ∂W∂L=∂Y∂L∗∂W∂Y=∂Y∂L∗∂W∂XW=XT∗∂Y∂L
这里L是标量,深度学习默认采用的是分母布局,所以 ∂ L ∂ X \frac{\partial L}{\partial X} ∂X∂L和X的形状相同, ∂ L ∂ W \frac{\partial L}{\partial W} ∂W∂L和W的形状相同, ∂ L ∂ Y \frac{\partial L}{\partial Y} ∂Y∂L和Y的形状相同。就可以根据矩阵乘法维度对齐的规则得到顺序。
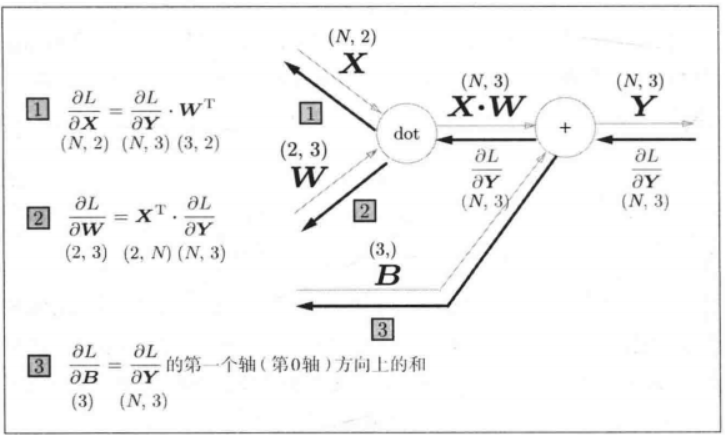
在正向传播时,假设偏置为的形状为1*3,偏置在计算时会被自动复制扩展(每行数据一致)到与XW的维度匹配,偏置的形状变成了N*3,这里Y的形状也是N*3(这里是N个数据一起的情况),
# 案例1--------------
X_dot_W =np.array([[0,0,0],[10,10,10]])
B=np.array([1,2,3])
X_dot_W+B #B=[[1,2,3],[1,2,3]]
# array([[1,2,3],[11,12,13]])
在神经网络中,偏置b的梯度计算与普通节点不同,反向传播时,每个样本的梯度都会对同一偏置 b 产生贡献,因此需要将所有样本的梯度累加。
∂ L ∂ B = ∂ L ∂ Y 跨行相加的结果 \frac{\partial L}{\partial B} = \frac{\partial L}{\partial Y}跨行相加的结果 ∂B∂L=∂Y∂L跨行相加的结果,
这里暂时没看懂为什么,搜了一下也不知道为什么。猜测可能是 ∂ L ∂ B \frac{\partial L}{\partial B} ∂B∂L的形状为13,而 ∂ L ∂ Y \frac{\partial L}{\partial Y} ∂Y∂L的形状为N3,所以这里压缩?
>>> dY = np.array([[1, 2, 3,],[4, 5, 6]])
>>> dY
array([[1, 2, 3],
[4,5, 6]])
>>> # axis=0表示跨行加,axis=1表示跨列加
>>> dB = np.sum(dY, axis=0)
>>> dB
array([5,7, 9])使用Python实现Affine****层
class Affine:def __init__(self, W, b):self.W =Wself.b = bself.x = None# 权重和偏置参数的导数self.dW = Noneself.db = Nonedef forward(self, x):self.x = xout = np.dot(self.x, self.W) + self.breturn outdef backward(self, dout):dx = np.dot(dout, self.W.T) # 第二个参数是W转置的意思self.dW = np.dot(self.x.T, dout)self.db = np.sum(dout, axis=0)return dxSoftmax层
Softmax层的反向传播得到了 ( y 1 − t 1 , y 2 − t 2 , y 3 − t 3 ) (y_1 - t_1,y_2 - t_2,y_3 - t_3) (y1−t1,y2−t2,y3−t3)这样“漂亮”的结果(故意设计的),其中 y y y表示softmax输出的预测值, t t t表示真实标签的one-hot编码。
神经网络的反向传播会把这个差分表示的误差传递给前面的层,这是神经网络学习中的重要性质。
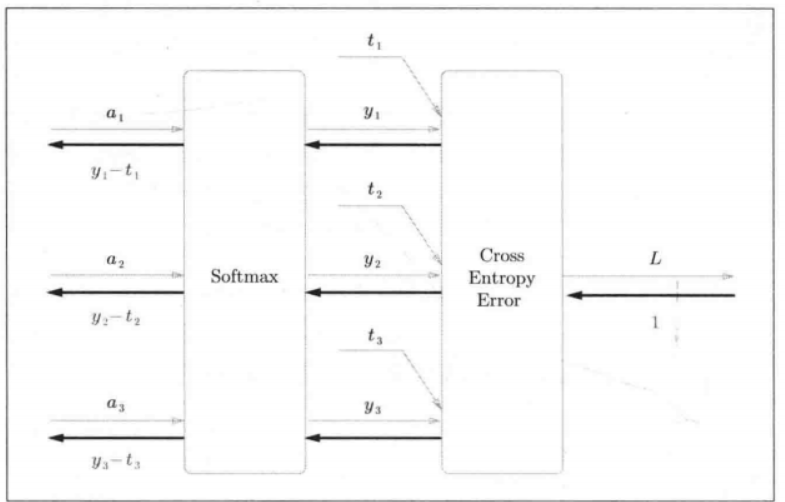
选择特定损失函数与输出层函数的组合,目的是让反向传播的梯度形式尽可能简洁。
- 分类问题:softmax+交叉熵误差
正向传播
- 输出层:使用 Softmax函数,将输出转换为概率分布(和为1)。
- 损失函数:使用 交叉熵误差(Cross-Entropy Loss),衡量预测概率与真实标签的差异。
反向传播:损失函数对输出层输入的 y i − t i y_i-t_i yi−ti,其中 y i y_i yi是softmax层的输出, t i t_i ti是真实标签的one-hot编码。
- 回归问题:恒等函数+平方和误差
正向传播
- 输出层:使用 恒等函数),直接输出原始值。
- 损失函数:使用平方和误差,衡量预测值与真实值的差异。
反向传播:输出的梯度和分类问题的梯度一致。
使用Python实现Softmax****层
问题:为什么需要除以样本数量
解答:https://blog.csdn.net/for_balanced/article/details/120372725
正向传播时,交叉熵损失函数计算的是批量样本的平均损失,有一个节点 L ∗ 1 b a t c h _ s i z e L*\frac{1}{batch\_size} L∗batch_size1
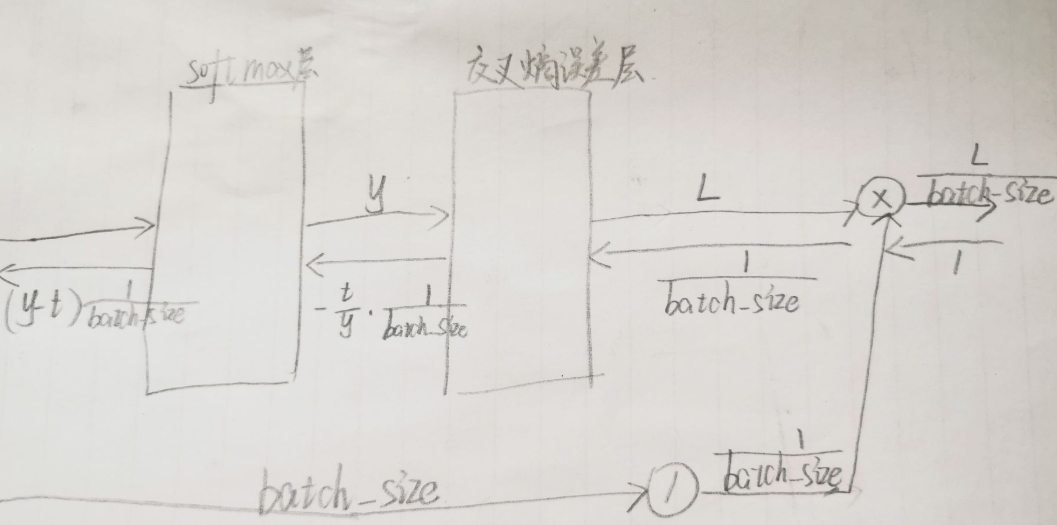
class SoftmaxWithLoss:def __init__(self):self.loss = Noneself.y = None # softmax的输出self.t = None # 监督数据def forward(self, x, t):self.t = tself.y = softmax(x)self.loss = cross_entropy_error(self.y, self.t)return self.lossdef backward(self, dout=1):batch_size = self.t.shape[0] dx = (self.y - self.t) / batch_sizereturn dx
梯度确认
梯度确认(gradient check):数值微分的优点是实现简单,一般情况下不太容易出错。误差反向传播法的实现很复杂,容易出错。所以,经常会比较数值微分的结果和误差反向传播法的结果,以确认误差反向传播法的实现是否正确。
确定方式:各个参数矩阵中元素差的绝对值求平均。
自动求导-代码
标量的反向传播
案例:假设对函数 y = 2 x T x y=2x^Tx y=2xTx关于列向量x求导
1.首先初始化一个向量
x = torch.arange(4.0) # 创建变量x并为其分配初始值
print(x) #tensor([0., 1., 2., 3.])
2.计算y关于x的梯度之前,需要一个地方来存储梯度。
x.requires_grad_()等价于x=torch.arange(4.0,requires_grad=True),这样PyTorch会跟踪x的梯度,并生成 grad 属性,该属性里记录梯度。
None通常用于表示某个变量或返回值“有意为空”或"暂时没有值",已经初始化但是没有值
x.requires_grad_(True)
print(x.grad) # 默认值是None,存储导数。
3.计算y的值,y是一个标量,在python中表示为tensor(28., ),并记录是通过某种乘法操作生成的。
y = 2 * torch.dot(x, x)
print(y) # tensor(28., grad_fn=<MulBackward0>)
4.调用反向传播函数来自动计算y关于x每个分量的梯度。
y.backward()
print(x.grad) # tensor([ 0., 4., 8., 12.])
我们可以知道根据公式来算, y = 2 x T x y=2x^Tx y=2xTx关于列向量x求导的结果是4x,根据打印结果来看结果是正确的。
5.假设此时我们需要继续计算x所有分量的和,也就是 y = x . s u m ( ) y=x.sum() y=x.sum()
在默认情况下,PyTorch会累计梯度,我们需要调用grad.zero_清空之前的值。
x.grad.zero_()
y = x.sum() # y = x₁ + x₂ + x₃ + x₄
print(y)
y.backward()
print(x.grad) # tensor([1., 1., 1., 1.])
非标量变量的反向传播
在深度学习中,大部分时候目的是 将批次的损失求和之后(标量)再对分量求导。
y.sum() 将 y 的所有元素相加,得到一个标量 s u m ( y ) = ∑ i = 1 n x i 2 sum(y)=\sum_{i=1}^n x_i^2 sum(y)=∑i=1nxi2
y.sum().backward()等价于y.backward(torch.ones(len(x)):
x.grad.zero_()
y = x * x # y是一个矩阵
print(y) # tensor([0., 1., 4., 9.], grad_fn=<MulBackward0>) 4*1的矩阵
# 等价于y.backward(torch.ones(len(x)))
y.sum().backward()
print(x.grad) # [0., 2., 4., 6.]
将某些计算移动到计算图之外
假设 y = f ( x ) , z = g ( y , x ) y=f(x),z=g(y,x) y=f(x),z=g(y,x),我们需要计算 z z z关于 x x x的梯度,正常反向传播时,梯度会通过 y y y和 x x x 两条路径传播到 x x x: ∂ z ∂ x = ∂ g ∂ y ∂ y ∂ x + ∂ g ∂ x \frac{\partial z}{\partial x} = \frac{\partial g}{\partial y} \frac{\partial y}{\partial x} +\frac{\partial g}{\partial x} ∂x∂z=∂y∂g∂x∂y+∂x∂g。但由于某种原因,希望将 y y y视为一个常数, 忽略 y y y对 x x x的依赖: ∂ z ∂ x ∣ y 常数 = ∂ g ∂ x \frac{\partial z}{\partial x} |_{y常数} =\frac{\partial g}{\partial x} ∂x∂z∣y常数=∂x∂g。
通过 detach() 方法将 y y y从计算图中分离,使其不参与梯度计算。
z . s u m ( ) 求导 = ∂ ∑ z i ∂ x i = u i z.sum() 求导 = \frac{\partial \sum z_i}{\partial x_i} = u_i z.sum()求导=∂xi∂∑zi=ui
x.grad.zero_()
y = x * x
print(y) # tensor([0., 1., 4., 9.], grad_fn=<MulBackward0>)
u = y.detach() # 把y看成一个常数从计算图中分离,不参与梯度计算,但值还是x*x
print(u) # tensor([0., 1., 4., 9.])
z = u * x # z是一个常数*x
print(z) # tensor([ 0., 1., 8., 27.], grad_fn=<MulBackward0>)
z.sum().backward() print(x.grad == u) # tensor([True,True,true,True])执行y.detach()返回一个计算图之外,但值同y一样的tensor,只是将函数z中的y替换成了这个等价变量。
但对于y本身来说还是一个在该计算图中,就可以在y上调用反向传播函数,得到 y = x ∗ x y=x*x y=x∗x关于 x x x的导数 2 x 2x 2x
x.grad.zero_()
y.sum().backward()
print(x.grad == 2 * x) # tensor([True,True,true,True])